Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania

W świecie dużych modeli językowych (LLM) dynamika zmian jest całkiem spora. Boom na rozwój AI nakręca też wyścig w kierunku coraz ciekawszych ataków skierowanych w akurat tę gałąź technologii. Ostatnio pisaliśmy o tym, jak popularny portal może być wykorzystany do ataków na developerów AI. Jednak infrastruktura oraz same modele mogą zostać wykorzystane do przeprowadzania ataków, lub stać się ich celem.
Trenowanie LLM jest bardzo drogim i czasochłonnym procesem rozwoju tej technologii, dlatego większość dostępnych na rynku modeli jest zamknięta (nawet jeśli pierwotne założenia firmy były inne). Kusząca może być więc kradzież wytrenowanego już modelu “produkcyjnego”. Projekt OWASP LLM TOP10 opisuje zagrożenia i ataki skierowane w duże modele językowe. Na dziesiątym miejscu, znalazło się zagadnienie kradzieży (ang. Model Theft). Wśród wielu różnych metod, został wymieniony między innymi atak na infrastrukturę obsługującą sztuczną inteligencję i eksfiltracja danych. Nie są to jednak jedyne możliwości w arsenale atakujących.
Zespół Google przedstawił praktyczną metodę pozyskiwania ostatniej warstwy modelu LLM z wykorzystaniem ogólnodostępnych API. Taka warstwa z reguły jest związana z warstwą ukrytą modelu (tzw. hidden dimension layer). Przy pomocy tej metody udało się zaatakować ChatGPT stworzony przez OpenAI oraz PaLM-2 od Google. Koszt takiego ataku, w zależności od rozmiaru warstwy (co jest wprost skorelowane z liczbą zapytań) waha się w zakresie od kilkuset do kilku tysięcy USD, co nie stanowi dużej przeszkody dla przestępców.
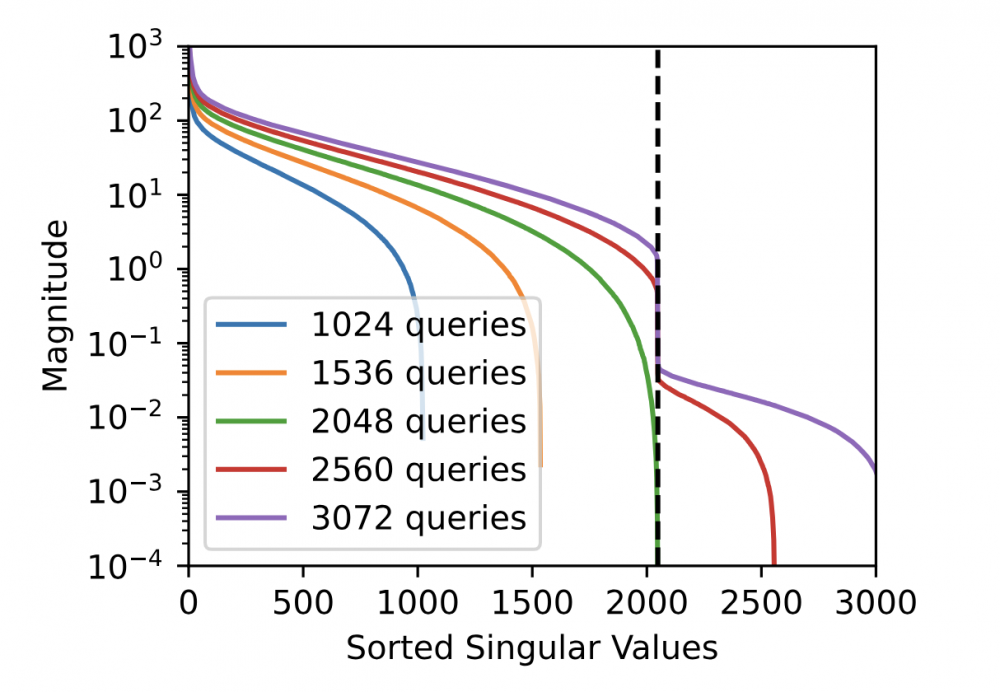
Atak wykorzystuje zależności w liniowych transformacjach wewnątrz modelu. Wykorzystując wiedzę o statystycznych właściwościach zachowania takich modeli, można oszacować i dokonać inżynierii wstecznej ukrytego rozmiaru modelu.
Badacze uzyskali odpowiednie zgody od firmy OpenAI aby zaatakować ich modele. Cały proces zgłoszenia podatności odbył się na zasadach responsible disclosure i nie wszystkie informacje dotyczące wyników ataku są dziś publiczne. Pomimo zakończonego sukcesem procesu eksploitacji modeli GPT-3 Ada, Babbage, GPT-3.5-turbo-instruct oraz GPT-3.5-turbo-chat, którego wyniki zostały potwierdzone przez firmę OpenAI, to informacje dotyczące ostatniej warstwy modelu nie zostały opublikowane.

Autorzy badania wskazali metody na poprawienie bezpieczeństwa modeli, między innymi z wykorzystaniem sztucznie wprowadzonych limitów na API. Nie jest to metoda, która w 100% rozwiązuje problem, ale powoduje znaczący wzrost kosztów jego przeprowadzenia. Na tym etapie wiadomo, że nie wszystkie modele są podatne na taki atak z racji zablokowania pewnego rodzaju zapytań. Badacze są pewni, że atak ten nie pozwoli na kradzież pełnego modelu, ale nie wykluczają takiej możliwości z wykorzystaniem jego rozwinięcia lub podobnej metody. Sądząc po tym ile badań jest obecnie prowadzonych nad rozwiązaniami AI, możemy przekonać się o tym szybciej, niż może się to wydawać prawdopodobne.
~fc & tt

.. przestępcy z konkurencyjnego korpo
😏
To jest taka abstrakcja że nic z tego nie rozumiem
Jest sieć neuronowa której nauczenie wymaga dużo prądu, czasu i sprzętu. Konkurencja chcąca zrobić coś podobnego zauważyła że można częściowo zrozumieć jej działanie np pytając czata-gpt o odpowiednie rzeczy.