Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania

Projektując aplikacje oparte o duże modele językowe (LLM) należy zapoznać się z OWASP TOP 10 for LLM. Jest to bezpośredni odpowiednik OWASP TOP 10 dla aplikacji webowych, zawierający listę najczęściej występujących podatności w aplikacjach korzystających z LLM.
TLDR:

Zgodnie z przewidywaniami, na pierwszym miejscu umieszczono Prompt Injection – zagrożenie, wynikające z wstrzykiwania złośliwych instrukcji sterujących. Problem, który według wczesnych zapowiedzi miał zostać rozwiązany w ciągu zaledwie kilku miesięcy towarzyszy nam praktycznie od momentu upowszechnienia modeli opartych na architekturze GPT. I pewnie zostanie z nami jeszcze przez dłuższy czas, mimo wdrażania coraz to nowszych mechanizmów obronnych.
Skoro nie da się w pełni zablokować samego wstrzyknięcia, należy podjąć działania zmierzające do ograniczenia jego skutków. OpenAI najwyraźniej doszło do podobnych wniosków prezentując nowy tryb pracy – Lockdown Mode oraz wprowadzając etykiety Elevated Risk dla pewnych funkcji w ChatGPT, ChatGPT Atlas i Codex.
Tryb ten został zaprojektowany głównie z myślą o kadrze kierowniczej oraz zespołach ds. bezpieczeństwa w poważnych organizacjach. Jednak każdy użytkownik, który chce chronić prywatność swoich danych może również z niego korzystać.
Oczywiście aktywacja trybu niesie za sobą konsekwencje, głównie związane z ograniczeniem funkcjonalności ChatGPT, do których każdy z nas zdążył się już przyzwyczaić. Tracimy przede wszystkim interakcję z zewnętrznymi systemami i możliwość wyszukiwania aktualnych informacji w sieci. Co w konsekwencji może mieć wpływ na jakość generowanych odpowiedzi.
Po wybraniu opcji Lockdown Mode ChatGPT przechodzi w tryb izolacji, co w praktyce oznacza:
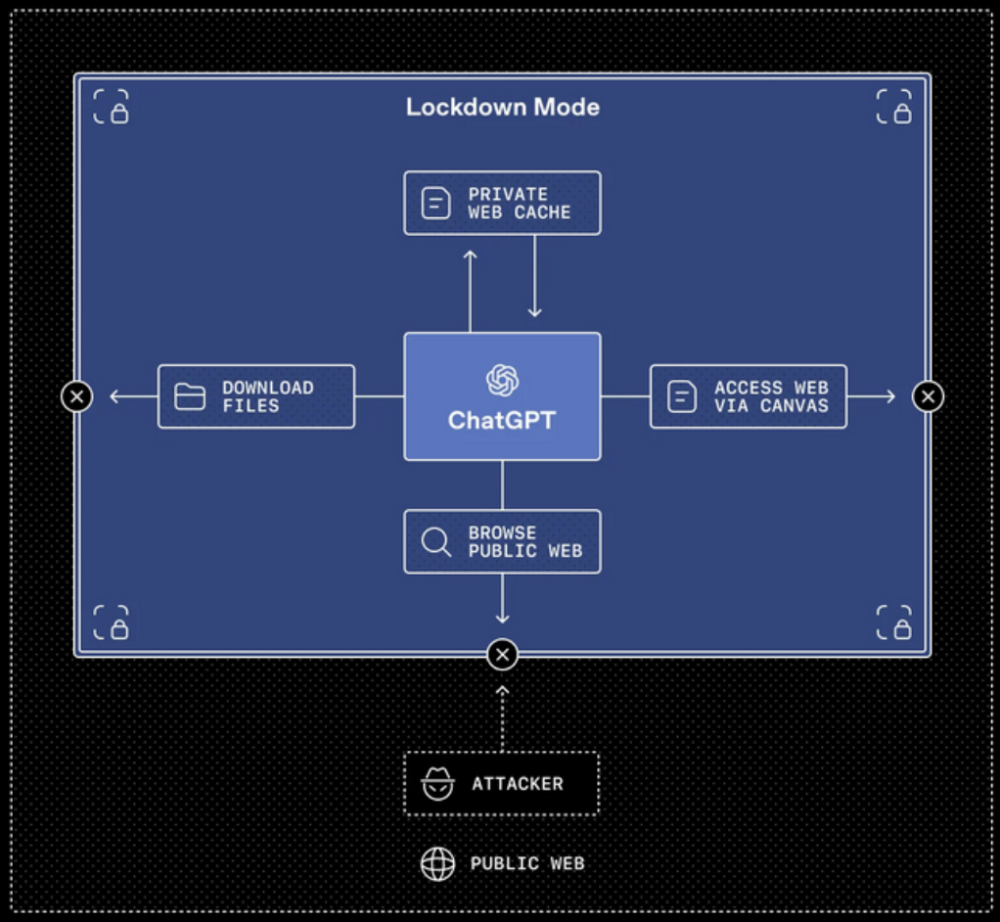
Warto dodać, że Lockdown Mode jest zarządzany na poziomie obszaru roboczego (Workspace). Oznacza to, że administratorzy mogą zdefiniować wyjątki, rozszerzając uprawnienia użytkowników/aplikacji do realizacji konkretnych zadań. W tym miejscu należy zwrócić uwagę, że takie modyfikacje uprawnień mogą stanowić potencjalny punkt wejścia dla atakujących. Administratorzy muszą być świadomi swoich decyzji.
Aby ułatwić życie użytkownikom, OpenAI wprowadziło równolegle system etykietowania potencjalnie niebezpiecznych funkcji. Symbol tarczy z wykrzyknikiem informuje, że dana funkcja operuje w obszarze, w którym nie zostały wypracowane jeszcze skuteczne mechanizmy obronne, a jej użycie może stanowić potencjalny wektor ataku. To od użytkownika zależy, czy zaakceptuje ryzyko i wdroży ją we własnych rozwiązaniach.
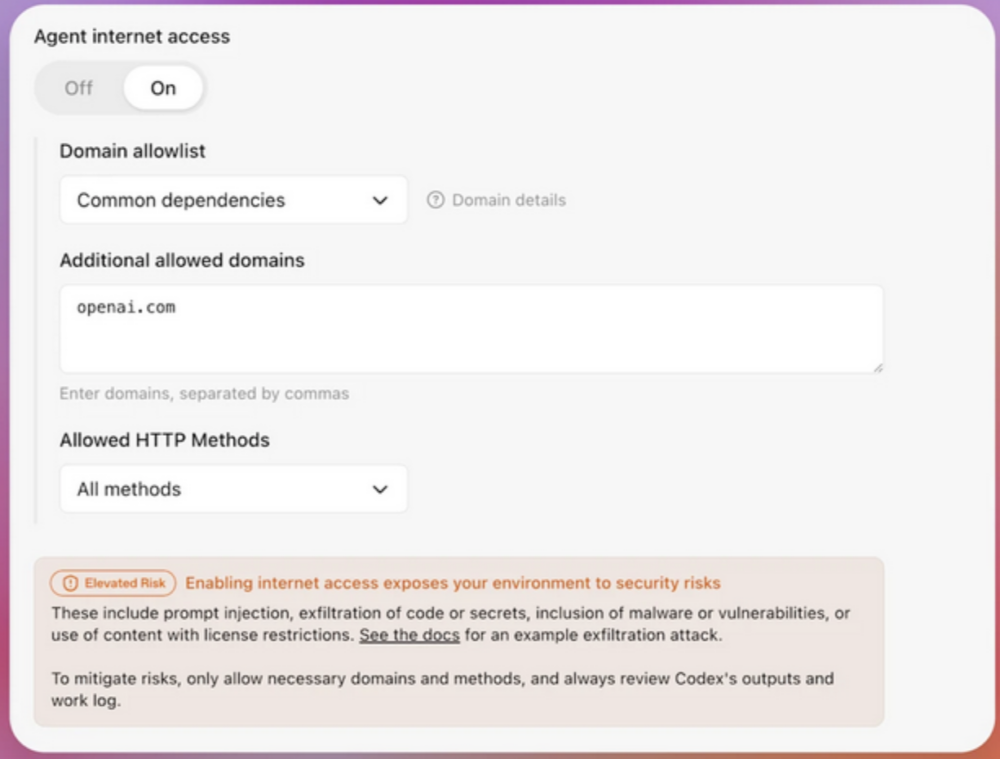
OpenAI nie poprzestaje na wprowadzonych modyfikacjach i deklaruje dalsze prace rozwojowe. Wraz z wdrażaniem mechanizmów bezpieczeństwa informacje na temat użycia danych funkcji (etykiety) będą aktualizowane.
Być może w przyszłości pojawi się skuteczny mechanizm zabezpieczający przed atakami typu prompt injection, jednak na chwilę obecną najlepszym wyborem jest redukcja płaszczyzny ataku, oczywiście kosztem funkcjonalności.
Źródło: openai.com, aws.amazon.com
~_secmike
