NIS2/KSC2 starter pack. Czy Twoja firma podlega pod regulację i co z tego wynika? Bezpłatne szkolenie od sekuraka
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
NIS2/KSC2 starter pack. Czy Twoja firma podlega pod regulację i co z tego wynika? Bezpłatne szkolenie od sekuraka
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

W poprzednim artykule przyjrzeliśmy się parserowi JSONata — narzędziu, które dobrze sprawdza się tam, gdzie odpowiedzi z API Zabbixa wymagają czegoś więcej niż prostego filtrowania i projekcji pól. Pozwala ono zamknąć dość złożoną logikę w jednym miejscu, kosztem nieco trudniejszej składni.
JSONata nie jest jednak jedynym sposobem na przetwarzanie złożonych struktur JSON. Dlatego tym razem bierzemy na warsztat następny parser dostępny w Grafanie – JQ.
W tym artykule skupimy się na JQ jako alternatywnym parserze dostępnym w pluginie Infinity. Zobaczymy, jak radzi sobie z bardziej złożonymi danymi oraz jak wygląda praca z nim w porównaniu do pozostałych parserów— szczególnie z perspektywy osób, które miały z nim styczność poza Grafaną.
Jeżeli nie czytałeś wcześniejszych artykułów dotyczących konfiguracji pluginu Infinity (link >tutaj), parsera UQL (link >tutaj) oraz JSONata (link >tutaj), warto do nich wrócić. Ułatwi to zrozumienie różnic pomiędzy parserami i świadome dobranie narzędzia do konkretnego problemu. W przeciwnym razie — przechodzimy dalej.
Zaczynamy!

Dodatkowe założenia w tym przykładzie:
Dalej będziemy bazować na stworzonym dashboardzie Przykładowy dashboard 3, na którym aktualnie znajdują się dwa panele z informacjami o niedostępności interfejsów na hostach:
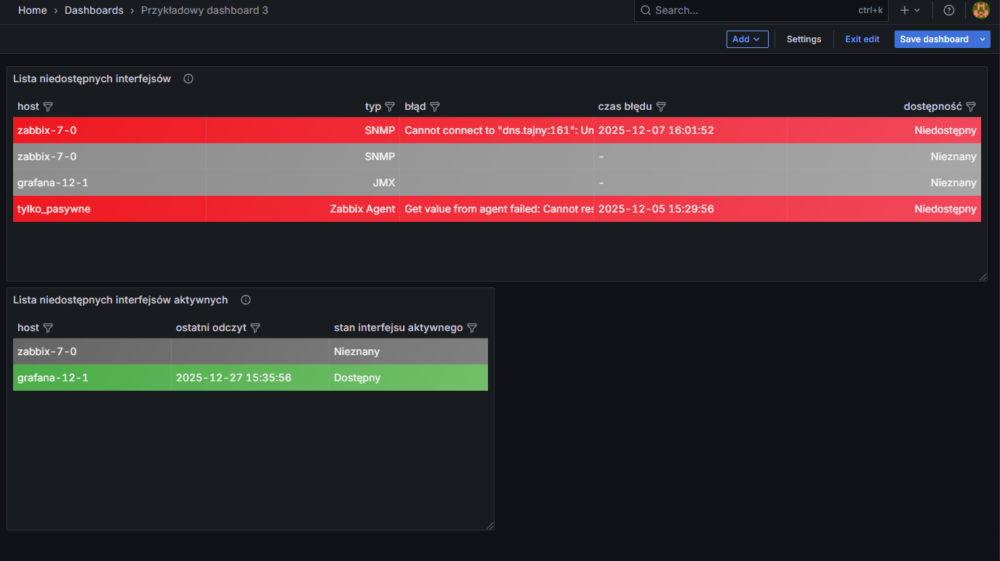
JQ to trzeci parser, któremu przyjrzymy się w ramach tej serii. Jest to stosunkowo świeża funkcjonalność (na moment pisania artykułu), ponieważ została udostępniona we wrześniu 2025 roku.
Działa on bardzo podobnie do popularnego narzędzia jq znanego z linii poleceń — piszemy krótkie wyrażenia filtrujące i transformujące dane, a Grafana przetwarza w ten sposób cały dokument JSON. Całość wykonywana jest po stronie backendu, dzięki czemu JQ wspiera alerty, buforowanie oraz inne mechanizmy charakterystyczne dla backendowych źródeł danych.
Podobnie jak w przypadku UQL, w JQ operujemy na sekwencji poleceń oddzielonych znakiem |, przy czym każde z nich może znajdować się w osobnej linii. W praktyce tworzymy mini-pipeline przetwarzania danych krok po kroku. Warto jednak zaznaczyć, że JQ oferuje znacznie bogatszy zestaw funkcji, a co równie istotne — jest narzędziem dużo bardziej rozpowszechnionym. Dzięki temu łatwiej znaleźć działające przykłady i gotowe rozwiązania, również poza kontekstem Grafany.
Najprostszy przykład kodu JQ to pobieranie całej zawartości z obiektu result (przypomnijmy – to właśnie tak znajdują się dane zwracane nam przez API Zabbix):
.result
W tym artykule nie będziemy jednak skupiać się na trywialnych przykładach. Podobnie jak wcześniej, przejdziemy od razu do bardziej zaawansowanego scenariusza. W poprzednich częściach analizowaliśmy błędy na poziomie interfejsów hostów, dlatego tym razem również zajmiemy się błędami — ale z perspektywy pozycji.
Naszym celem będzie pobranie wszystkich pozycji, które znajdują się w stanie Niewspieranym (ang. Unsupported) wraz z opisem błędu, a następnie pogrupowanie ich według treści błędu. Aby to osiągnąć, skorzystamy z metody item.get, ponieważ interesują nas informacje o błędach już nie na poziomie interfejsu hosta, lecz konkretnych pozycji monitorujących.
Dodatkowo, aby ograniczyć rozmiar zwracanego wyniku, zawęzimy zapytanie do grupy Linux servers (dla uproszczenia przyjmijmy, że znamy groupid tej grupy i wynosi on 2).
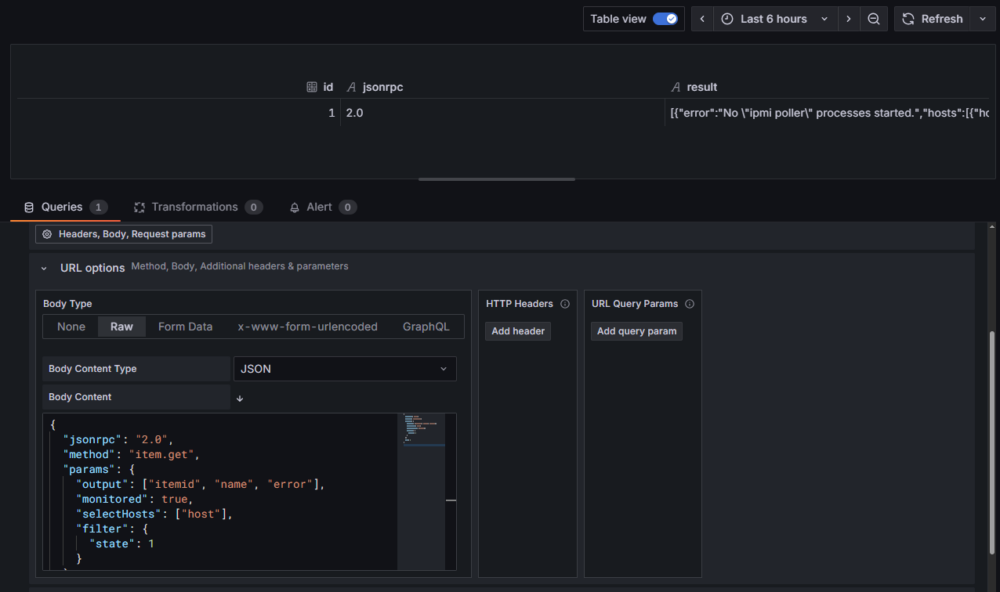
Wykorzystamy następujące zapytanie do API Zabbix:
{
"jsonrpc": "2.0",
"method": "item.get",
"params": {
"groupids": 2,
"output": ["itemid", "error"],
"monitored": true,
"selectHosts": ["host"],
"filter": {
"state": 1
}
},
"id": 1
}Omówmy to zapytanie krok po kroku:"jsonrpc": "2.0" oraz "id": 1Standardowe pola zapytania API z wersją protokołu JSONRPC oraz identyfikator zapytania.
"method": "item.get"
Tym razem wykorzystujemy metodę API item.get, która służy do pobierania konfiguracji pozycji. Więcej informacji o tej metodzie można znaleźć w >oficjalnej dokumentacji metody.
W sekcji parametrów (“params”: {…})) mamy następujące założenia:
"groupids": 2
Zwracane są tylko pozycje należące do hostów znajdujących się w grupie o ID równym 2, czyli Linux servers.
"output": ["itemid", "error"]
Ograniczamy wielkość odpowiedzi do absolutnego minimum. W odpowiedzi otrzymujemy wyłącznie:
Nie pobieramy żadnych dodatkowych pól, co znacząco zmniejsza rozmiar odpowiedzi JSON i przyspiesza samo zapytanie. Ponieważ skupiamy się wyłącznie na błędach, nie potrzebujemy nawet nazw pozycji. Oczywiście, jeżeli chcesz sprawdzić, jakie właściwości może zwracać obiekt pozycji, autor odsyła do >oficjalnej dokumentacji.
"monitored": true
Jest to bardzo istotny parametr, który oznacza: “zwróć tylko pozycje, które są ‘monitorowane’”. W praktyce oznacza to, że:
Dzięki temu nie musimy już dodatkowo sprawdzać, czy host lub pozycja są włączone (a dokładniej – czy ich pole status ma wartość 0). Cała ta weryfikacja zostaje wykonana po stronie API Zabbixa, co upraszcza zapytanie i zmniejsza ilość danych do dalszego przetwarzania.
"selectHosts": ["host"]
Dla każdej pozycji pobieramy również nazwę hosta (pole host), do którego dana pozycja należy. Dzięki temu wiemy, na jakim hoście występuje dany problem.
"filter": { "state": 1 }
Ograniczamy wynik do pozycji, które mają state = 1, czyli znajdują się w stanie niewspieranym.
Jak widać, znaczną część filtrowania wykonujemy już po stronie API Zabbixa. Jest to podejście nie tylko czytelne, ale również optymalne — do Grafany trafiają wyłącznie te dane, które są nam faktycznie potrzebne do dalszego przetwarzania w JQ.
Skoro część teoretyczną mamy za sobą, przechodzimy do praktyki i wracamy do edycji dashboardu Przykładowy dashboard 3. Tworzymy nowy panel, bazując na dokładnie tej samej konfiguracji, której używaliśmy w poprzednich artykułach (UQL oraz JSONata).
Dla przypomnienia, podstawowa konfiguracja zapytania w panelu wygląda następująco:
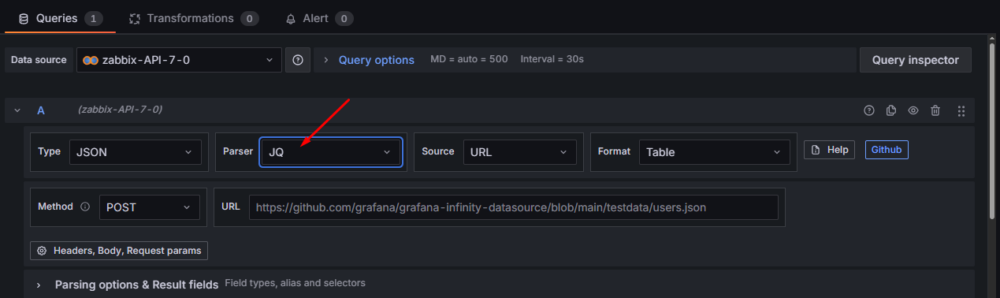
Po wklejeniu wcześniej przygotowanego zapytania do API Zabbixa powinniśmy otrzymać standardową, surową odpowiedź JSON.
Jak zwykle, na tym etapie dane nie są jeszcze w formie użytecznej do prezentacji. Dlatego kolejnym krokiem będzie odpowiednie przetworzenie wyniku. W tym celu będziemy wykorzystywać następujący kod JQ:
.result
| map({ error, host: .hosts[0].host })
| group_by(.error)
| map({
"błąd": .[0].error,
"ilość": length,
"hosty": (map(.host) | unique | join(", "))
})
| sort_by(-."ilość")Przeanalizujmy teraz krok po kroku powyższy kod, bazując na przykładowych danych zwróconych przez API (skrócone dla czytelności):
{
"jsonrpc": "2.0",
"result": [
{
"itemid": "34319",
"error": "No \"connector worker\" processes started.",
"hosts": [{"hostid": "10084", "host": "zabbix-7-0"}]
},
{
"itemid": "50716",
"error": "Invalid update interval \"{$MAKRO}\".",
"hosts": [{"hostid": "10084", "host": "zabbix-7-0"}]
},
{
"itemid": "50721",
"error": "No Such Object available on this agent at this OID",
"hosts": [{"hostid": "10084", "host": "zabbix-7-0"}]
},
{
"itemid": "51041",
"error": "Invalid update interval \"{$MAKRO}\".",
"hosts": [{"hostid": "10668", "host": "grafana-12-1"}]
},
{
"itemid": "51042",
"error": "No Such Object available on this agent at this OID",
"hosts": [{"hostid": "10668", "host": "grafana-12-1"}]
}
],
"id": 1
}
.resultPierwszy etap wyciąga samą tablicę result z odpowiedzi API. Dalej będziemy pracować właśnie na niej:
[
{
"itemid": "34319",
"error": "No \"connector worker\" processes started.",
"hosts": [{"hostid": "10084", "host": "zabbix-7-0"}]
},
{
"itemid": "50716",
"error": "Invalid update interval \"{$MAKRO}\".",
"hosts": [{"hostid": "10084", "host": "zabbix-7-0"}]
},
{
"itemid": "50721",
"error": "No Such Object available on this agent at this OID",
"hosts": [{"hostid": "10084", "host": "zabbix-7-0"}]
},
{
"itemid": "51041",
"error": "Invalid update interval \"{$MAKRO}\".",
"hosts": [{"hostid": "10668", "host": "grafana-12-1"}]
},
{
"itemid": "51042",
"error": "No Such Object available on this agent at this OID",
"hosts": [{"hostid": "10668", "host": "grafana-12-1"}]
}
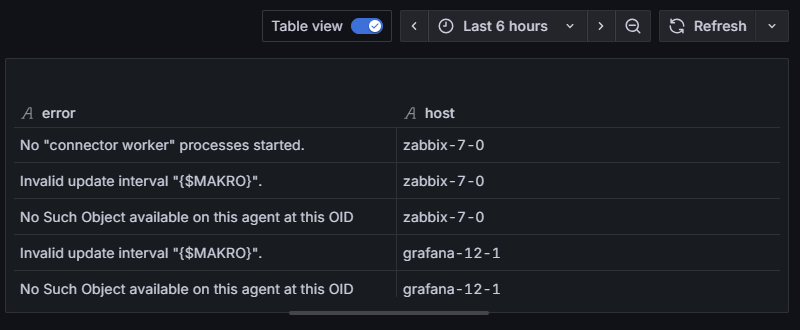
]map({ error, host: .hosts[0].host })
Funkcja map() przechodzi po każdym elemencie tablicy i tworzy nową tablicę z przekształconymi obiektami:
Efekt tego kroku wygląda następująco:
[
{ "error": "No \"connector worker\" processes started.", "host": "zabbix-7-0" },
{ "error": "Invalid update interval \"{$MAKRO}\".", "host": "zabbix-7-0" },
{ "error": "No Such Object available on this agent at this OID", "host": "zabbix-7-0" },
{ "error": "Invalid update interval \"{$MAKRO}\".", "host": "grafana-12-1" },
{ "error": "No Such Object available on this agent at this OID", "host": "grafana-12-1" }
]
group_by(.error)Funkcja group_by() grupuje elementy tablicy według podanego warunku (w tym przykładzie to po prostu pole error) i zwraca “tablice tablic” – każda wewnętrzna tablica to grupa elementów zawierających elementy z tym samym błędem (czyli polem error).
Po tym kroku dane wyglądają tak:
[
[
{ "error": "Invalid update interval \"{$MAKRO}\".", "host": "zabbix-7-0" },
{ "error": "Invalid update interval \"{$MAKRO}\".", "host": "grafana-12-1" }
],
[
{ "error": "No \"report manager\" processes started.", "host": "zabbix-7-0" }
],
[
{ "error": "No Such Object available on this agent at this OID", "host": "zabbix-7-0" },
{ "error": "No Such Object available on this agent at this OID", "host": "grafana-12-1" }
]
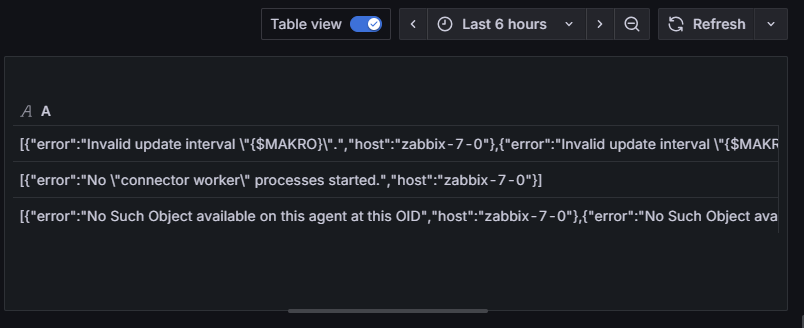
]
map({
"błąd": .[0].error,
"ilość": length,
"hosty": (map(.host) | unique | join(", "))
})Ponownie wykorzystujemy funkcję map() i tworzymy nowy obiekt dla każdej grupy elementów. Obiekt ten zawiera następujące pola:
Po wykonaniu tego kroku uzyskujemy praktycznie nasz wynik końcowy.
sort_by(-."ilość")Ostatni etap to sortowanie wyników po polu ilość. Minus na początku oznacza sortowanie malejące, dzięki czemu największe grupy (błędy występujące najczęściej) pojawiają się na początku listy.
Składnia jest równoważna użyciu:
sort_by(."ilość") | reverseOstatni etap to sortowanie wyników po polu ilość. Minus na początku oznacza sortowanie malejące, dzięki czemu największe grupy (błędy występujące najczęściej) pojawiają się na początku listy.
Składnia jest równoważna użyciu:
sort_by(."ilość") | reverse
To wszystko! Przykładowy JSON po tych przekształceniach wygląda następująco:
[
{
"błąd": "Invalid update interval \"{$MAKRO}\".",
"ilość": 2,
"hosty": "zabbix-7-0, grafana-12-1"
},
{
"błąd": "No Such Object available on this agent at this OID",
"ilość": 2,
"hosty": "zabbix-7-0, grafana-12-1"
},
{
"błąd": "No \"report manager\" processes started.",
"ilość": 1,
"hosty": "zabbix-7-0"
}
]Wróćmy teraz do naszego środowiska i wklejmy nasz kod JQ do pola Rows/Root:
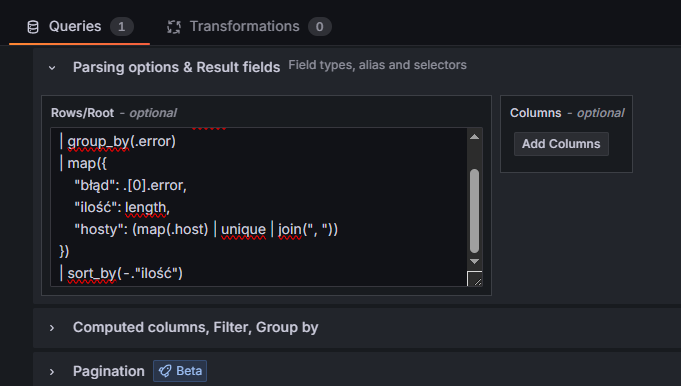
Po wklejeniu kodu powinniśmy od razu otrzymać dane w formie analogicznej do przykładu przedstawionego powyżej:
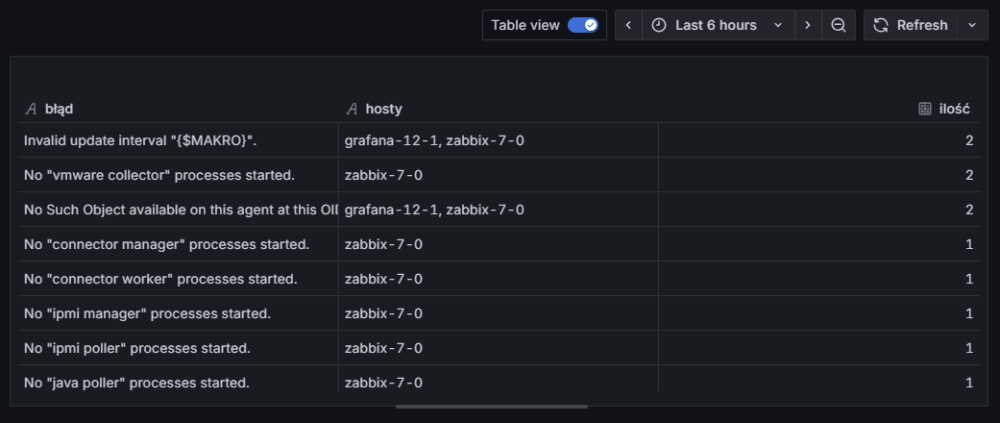
Możemy od razu zauważyć czytelną tabelkę końcową. Tym razem jednak zaprezentujemy dane w formie wykresu słupkowego, który lepiej obrazuje ilość wystąpień poszczególnych błędów.
Przechodzimy więc do prawej strony konfiguracji panelu i wprowadzamy następujące zmiany:
To oczywiście tylko zalecenia — wygląd wykresu można dostosować według własnych preferencji.
Po wprowadzeniu zmian zapisujemy dashboard i możemy od razu obserwować wynik końcowy:
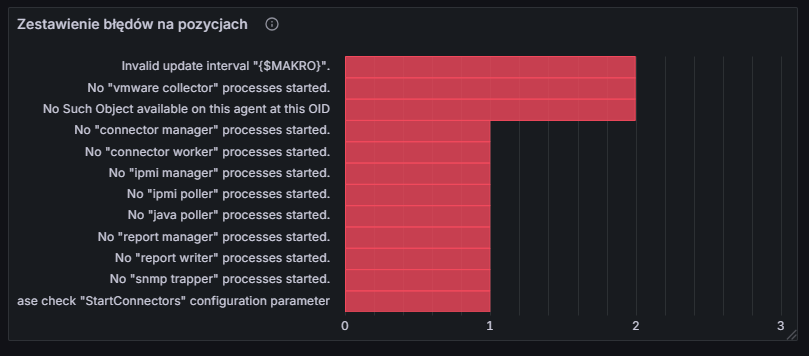
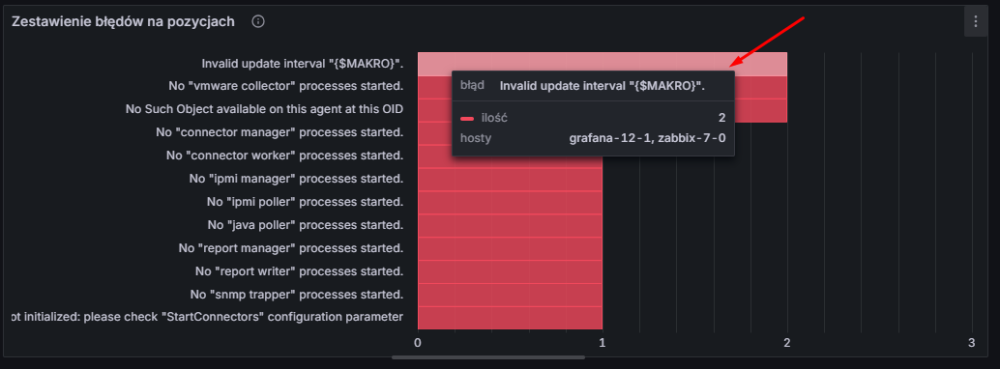
Jeżeli najedziemy na którykolwiek słupek, zobaczymy ilość błędów oraz listę hostów, na których występuje dany problem:
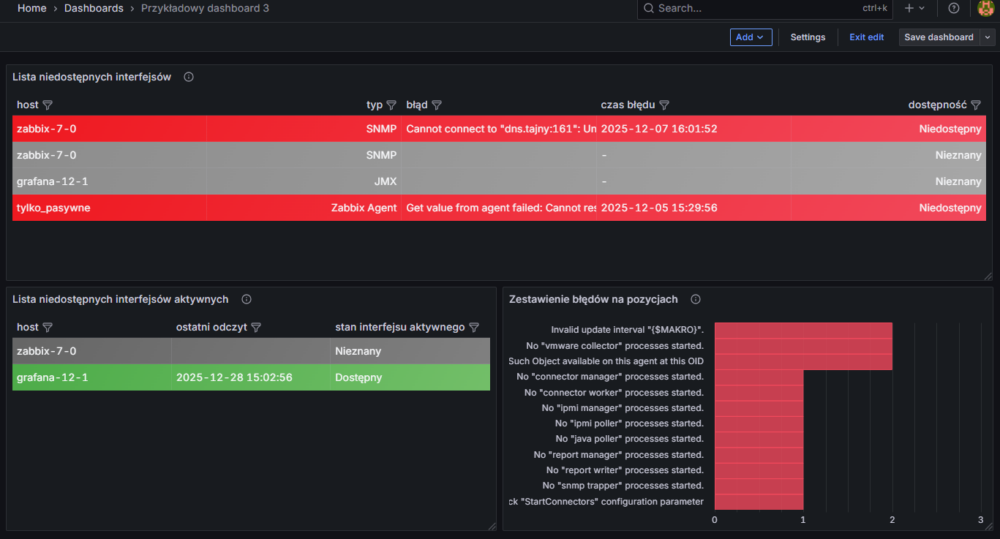
Całość dashboardu Przykładowy dashboard 3 przedstawia się następująco:
Kilka praktycznych uwag, które warto mieć z tyłu głowy podczas pracy z JQ:
Jeżeli gdzieś się pogubiłeś lub nie wiesz dokładnie “gdzie kliknąć”, Autor udostępnia cały “Przykładowy dashboard 3” >do pobrania w formacie JSON. Pamiętaj tylko, by podczas importu wybrać odpowiednie źródło danych, czyli nasze połączenie do API Zabbix.
Na koniec warto zadać sobie pytanie, które z pewnością pojawiło się u wielu czytelników w trakcie lektury całej serii: który sposób integracji wybrać w danym przypadku? Odpowiedź — jak to często bywa w IT i raczej nikogo nie zaskoczy — brzmi: to zależy. Każde z omówionych podejść rozwiązuje nieco inny problem i sprawdza się w innych scenariuszach.
Natywny plugin Zabbix w Grafanie
To najprostsze i najbardziej „out-of-the-box” rozwiązanie. Sprawdza się wtedy, gdy potrzebujemy szybkiego wglądu w dane monitoringowe, standardowych wykresów metryk oraz podstawowych tabel. Jego największą zaletą jest prostota konfiguracji i pełne wsparcie po stronie Grafany. Ograniczeniem jest natomiast niewielka elastyczność w zakresie przetwarzania danych — gdy pojawia się potrzeba niestandardowej agregacji, korelacji czy przetwarzania innych danych niż dane historyczne, plugin szybko dochodzi do swoich granic.
Bezpośrednie zapytania do bazy danych Zabbix
To podejście daje największą kontrolę nad danymi i potencjalnie najlepszą wydajność (ale nie zawsze!), szczególnie przy dużych wolumenach danych. Pozwala tworzyć bardzo precyzyjne zapytania i złożone agregacje bezpośrednio po stronie bazy danych. Dodatkowo bywa jedynym sposobem na pozyskanie informacji, które nie są dostępne ani w natywnym pluginie, ani przez API Zabbix.
Jednocześnie jest to rozwiązanie najbardziej inwazyjne — wymaga dobrej znajomości schematu bazy, niesie ryzyko silnej zależności od konkretnej wersji Zabbix i może powodować problemy przy aktualizacjach. Z tego powodu najlepiej sprawdza się w scenariuszach, gdzie świadomie akceptujemy ten kompromis i nie mamy możliwości pozyskania danych w inny sposób niż poprzez zapytania SQL.
Integracja przez API Zabbix z wykorzystaniem pluginu Infinity
Integracja oparta o API Zabbixa jest zdecydowanie bardziej elastyczna niż natywny plugin Grafany i często stanowi złoty środek pomiędzy jego ograniczeniami a zaawansowanymi zapytaniami SQL wykonywanymi bezpośrednio na bazie danych. W połączeniu z parserami UQL, JSONata lub JQ umożliwia bardzo precyzyjne przetwarzanie odpowiedzi API i dostosowanie wyniku dokładnie do własnych potrzeb.W praktyce zapytania API są często szybsze (choć nie jest to regułą!) niż pojedyncze, rozbudowane zapytania SQL, ponieważ po stronie Zabbixa są one rozbijane na mniejsze operacje na bazie danych.
Kosztem tego podejścia jest jednak większa złożoność konfiguracji — oprócz znajomości API Zabbix konieczna jest również umiejętność przetwarzania danych, co wiąże się z nauką parserów. Dodatkowo, przy aktualizacjach środowiska Zabbix może pojawić się potrzeba dostosowania istniejących zapytań API.
Jeżeli chodzi o same parsery:
W praktyce często okazuje się, że ten sam problem można rozwiązać przy użyciu kilku różnych parserów. Warto więc poświęcić chwilę na ich przetestowanie i wybrać ten, który najlepiej sprawdzi się w danym scenariuszu — zarówno pod względem czytelności konfiguracji, jak i czasu przetwarzania oraz obciążenia po stronie Grafany (backend) i przeglądarki użytkownika (frontend).
Podsumowując:
W tym artykule pokazaliśmy, jak wykorzystać parser JQ w pluginie Infinity do przetwarzania odpowiedzi API Zabbixa w Grafanie. JQ stanowi solidną alternatywę dla UQL oraz JSONata — szczególnie dla osób, które miały z nim wcześniej styczność poza Grafaną i cenią sobie podejście oparte na czytelnych, etapowych pipeline’ach przetwarzania danych.
Tym artykułem domykamy całą serię poświęconą integracji Grafany z Zabbix. W jej ramach omówiliśmy kilka różnych podejść do pracy z danymi — od natywnego pluginu Zabbixa w Grafanie, przez bezpośrednie zapytania do bazy danych, aż po integrację przez API Zabbixa z wykorzystaniem pluginu Infinity i różnych parserów. Tak jak opisaliśmy wcześniej – każde z tych rozwiązań ma swoje zalety i ograniczenia — od prostoty konfiguracji, przez elastyczność przetwarzania danych, aż po wydajność i skalowalność. Nie istnieje jedno „najlepsze” podejście; kluczowe jest dobranie narzędzia do konkretnego przypadku użycia, dostępnych danych i oczekiwanego efektu końcowego.
Jeżeli którykolwiek z artykułów w tej serii okazał się dla Ciebie wartościowy i pomógł lepiej zrozumieć możliwości Grafany w połączeniu z Zabbix, możesz okazać swoje wsparcie, zostawiając autorowi >dobrą kawkę!
~ Albert Przybylski, zawodowo: Architekt ds. Monitoringu w firmie Aplitt, prywatnie: pełnoprawny fanatyk Zabbixa zasilany kawą
