Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Adminie… Czy znamy Twoje grzechy? ;-) Sprawdź!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Adminie… Czy znamy Twoje grzechy? ;-) Sprawdź!

O problemie pisaliśmy w krótki sposób kilka dni temu.
TLDR: wejdźcie na https://regex101.com/ i wpiszcie ten fragment oryginalnego wyrażenia regularnego użytego przez Cloudflare w jednej z reguł WAF-a: .*(?:.*=.*)
W “TEST STRING” możecie wpisać:
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa=aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa;
Silnik obsługujący wyrażenia regularne aby dopasować dość prosty i niedługi ciąg znaków potrzebuje wykonać około 7000 kroków!

Regex…
Chcecie prawdziwych fajerwerków? Oto one:
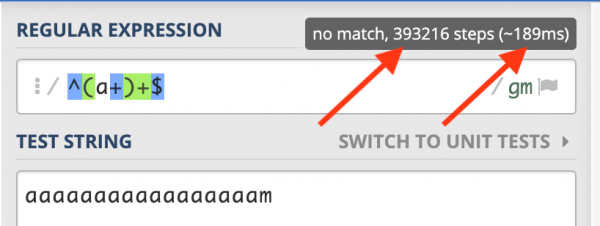
Prosty ciąg znaków i prawie 400 000 kroków do wykonania…
Dodajcie jeszcze kilka liter a i otrzymacie czerwony komunikat ‘catastrophic backtracking’.
Dlaczego tak to działa?
Amerykański programista, Jamie Zawinski, napisał kiedyś słynne słowa o wyrażeniach regularnych: “Niektórzy ludzie, gdy napotykają na problem, myślą sobie: »Wiem! Użyję wyrażeń regularnych«. I teraz mają dwa problemy”.
Tutaj głównym winowajcą jest tzw. backtracking – a po szczegóły jego działania odsyłamy do naszego rozbudowanego opracowania o Regex DoS.
Wracając do Cloudflare – warto przeczytać ten rozbudowany opis problemu, który w sekundy spowodował 100% obciążenie procesora na wszystkich maszynach Cloudflare obsługujących HTTP/HTTPS:
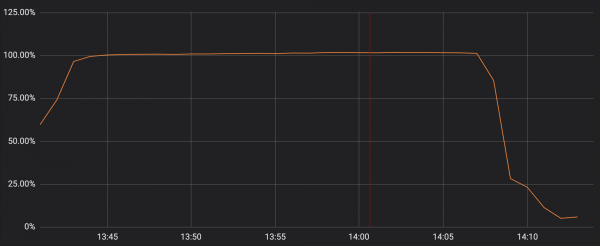
100% CPU
Zaczęło się od niewinnej zmiany w globalnym WAF-ie (Web Application Firewall). Wszystko zgodnie z procedurą, udokumentowany ticket na Jirze, nic groźnego, jedziemy z koksem.
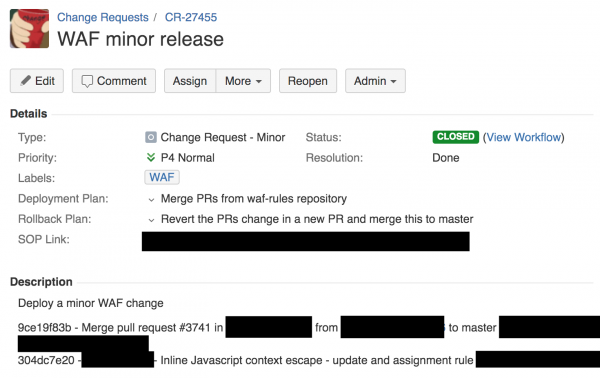
CR
Oczywiście nikt nie jest na tyle szalony żeby wprowadzać zmiany w oprogramowaniu infrastruktury Cloudflare bez testów. Firma posiada przygotowany wieloetapowy program testowania zmian. Akceptacje proceduralne, testy wewnętrzne, wrzucenie kodu do małej grupy klientów “bezpłatnych” na koniec ograniczona liczba wszystkich klientów. Jeśli nie ma problemu, kod aktywowany jest globalnie.
Czy wszystkie te testy przeszły bezproblemowo na naszej feralnej regule WAF-a? (czy raczej wyrażeniu regularnym które w nim było):
(?:(?:\”|’|\]|\}|\\|\d|(?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\-|\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*)))
Otóż ww. testy w ogóle nie były wykonane! Powód? Nowe reguły WAF-a powinny mieć możliwość natychmiastowego działania, a normalny proces testów trwa czasem miesiącami…
Czy w takim razie reguły WAF-a nie były w ogóle testowane? Były, ale pod względem blokowania “złego” ruchu i przepuszczania “dobrego” ruchu (nie chcemy blokować zbyt wiele). Nikt nie zwracał uwagi na CPU czy inne problemy…
No więc Cloudflare potrafi szybko reagować na zmiany. Bardzo szybko. Specjalnie zoptymalizowane oprogramowania potrafi zaaplikować zmiany na całą globalną infrastrukturę w kilka sekund. Imponujące, prawda? Również spektakularne jeśli deployowana jest zmiana z krytycznym błędem.
Taka sytuacja wyzwoliła globalny alert:

Wszyscy na stanowiska…
Co z kolei uruchomiło natychmiastowe reakcje – przerywamy spotkania, plotki, kawa w dłoń (kto akurat ją ma w dłoni) i do boju:
The London engineering team was at that moment in our main event space listening to an internal tech talk. The talk was interrupted and everyone assembled in a large conference room and others dialed-in.
Po dość intensywnym ale krótkim debugowaniu jako winowajcę problemu wskazano WAF-a. Co można w takiej sytuacji zrobić? Cloudflare ma mechanizm ‘global kill’ – który umożliwia globalne ‘zabicie’ niemal dowolnego komponentu.
“Global kill WAF!” – krzyczy jeden z inżynierów. Wszystko spoko, tylko nie możemy dostać się do naszej centralnej konsoli (ani do Jiry, ani do innych systemów) – korzystamy z infrastruktury Cloudflare, która na procesorach ma 100%! Na domiar złego okazało się, że dla wielu pracowników dostęp do wewnętrznej konsoli został automatycznie zablokowany (długi czas z niej nie korzystali, więc zadziałał mechanizm automatycznie blokujący dostęp po jakimś czasie).
W końcu udało się wykonać ‘global kill’ na WAF (Cloudflare nie precyzuje już konkretnego sposobu, który to umożliwił). Bez WAF-a wszystko zaczęło sprawnie działać, później zostało już tylko obtarcie potu z czoła i naprawienie feralnej reguły…
Cloudflare podsumowuje swoje grzechy (przytaczam tylko kilka):
Pomyślcie teraz parę minut czego możecie się nauczyć z tego przypadku – zarówno jeśli chodzi o dobre jak i złe praktyki. Może kiedyś zaoszczędzi to Wam kilku kropel potu na czole ;-)
–Michał Sajdak

Ja tam widzę przede wszystkim jeden błąd – ten, który wymienili jako ostatni. Jest taka zasada, bodajże pochodząca z Amazona “eat your own dog food”, którą amerykańskie firmy technologiczne stosują niemal jak mantrę – czyli używajmy na bieżąco własnych produktów.
Ma to sens w przypadku systemów backoffice, czy wręcz frontoffice, gdzie jest to najlepsza możliwa droga do wychwytywania różnych przypadków brzegowych i innych dziwnych błędów, o których wcześniej nikt nie pomyślał.
Ale w przypadku konsol administracyjnych, czy innych systemów służących do szybkiego reagowania, zrobienie sobie zależności do systemów, którymi się zarządza, może być strzałem w stopę – co Cloudflare po raz kolejny potwierdził (mi też się zdarzyło, żeby nie było – nawet ładnych kilka razy).
> Jest taka zasada, bodajże pochodząca z Amazona „eat your own dog food”
Microsoftu. Od co najmniej 6 lat przed powstaniem Amazona: https://devblogs.microsoft.com/oldnewthing/20110802-00/?p=10003
Na pewno nie pochodzi z MS. To podejście jest ogólnie znane i tak stare, że oryginalnego autora koncepcji już nie dojdziesz. Chociaż nie koniecznie wcześniej miało to jakąś konkretną nazwę.
Znają tę zasadę: https://blog-cloudflare-com-assets.storage.googleapis.com/2019/07/animal-deploy-1.png (Successful on Dogfood?).
A wystarczyłoby używać dopasowań niezachłannych.
i tak i nie:
“Using lazy rather than greedy matches helps control the amount of backtracking that occurs in this case. If the original expression is changed to .*?.*?=.*? then matching x=x takes 11 steps (instead of 23) and so does matching x=xxxxxxxxxxxxxxxxxxxx. That’s because the ? after the .* instructs the engine to match the smallest number of characters first before moving on.
But laziness isn’t the total solution to this backtracking behaviour.”
To prawda, to tylko jeden z elementów optymalizacji regexów. Nie wiem jak wyglądają dane wejściowe dla tych regułek, ale drugim z najważniejszych jest zmienianie zawsze nieefektywnego .*/.+ na sety [] i dopasowywanie wyłącznie pożądanych znaków. Wtedy od razu mamy też weryfikację poprawności danych wejściowych. Trzeci element, czyli zmiana grup alternatyw na wersję niezwracającą wyniku, tam gdzie nie jest to potrzebne, czyli ?: akurat tutaj jest użyta.
Panie Michale, bardzo ciekawy artykuł i na pewno wart głębszej analizy. Jutro będzie głośna dyskusja w moim zespole ? Pozdrowienia.
Dzięki za podsumowanie padu cloudflare – bardzo pouczający błąd.
Jeśli ktoś byłby zainteresowany wydajnością regexów, napisał o nie jakiś czas temu: https://medium.com/textmaster-engineering/performance-of-regular-expressions-81371f569698
Poza tym mogę polecić kilka innych dobrych wpisów:
https://www.regular-expressions.info/catastrophic.html
http://www.rexegg.com/regex-explosive-quantifiers.html
http://katafrakt.me/2016/07/06/regular-expressions/