Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania

Czytanie w myślach to ciekawy koncept, na razie trudny do zrealizowania w przypadku ludzi, ale już teraz można przeczytać co LLM (Large Language Model) odpowiada innemu użytkownikowi. Za wszystko odpowiedzialna jest pamięć GPU.
Trail Of Bits opublikowało na swoim blogu obszerne wyjaśnienie dla odkrytej podatności identyfikowanej jako CVE-2023-4969. Pozwala ona na wykradanie danych z lokalnej pamięci karty graficznej.
Powodem wystąpienia problemu jest fakt, że oprogramowanie działające na kartach GPU nie izoluje dostatecznie dobrze pamięci urządzenia i jeden kernel jest w stanie odczytać dane zapisane przez inny.
Aby skutecznie wyeksploitować podatność, atakujący musi oczywiście znajdować się na tej samej maszynie oraz mieć możliwość uruchomienia aplikacji korzystającej z GPU do obliczeń. Badacze wymieniają tutaj między innymi OpenCL, Vulkana albo Metal, jako frameworki, które pozwolą stworzyć kernel GPU, który po prostu zrzuci niezainicjalizowaną pamięć lokalną karty. W normalnych warunkach czytanie niezainicjalizowanej pamięci nie ma określonego efektu (tzw. UB – undefined behaviour), w przypadku rozważanym przez badaczy działanie to doprowadza do wycieku informacji. Zauważono jeszcze, że frameworki używane przez przeglądarki internetowe (np. WebGPU) nie mogą być wykorzystane w celu pozyskanie informacji innego użytkownika, ponieważ implementują dynamiczne sprawdzenia pamięci w kernelach.
Podatność dotyka przede wszystkim produktów firm takich jak: Apple (część z urządzeń została już załatana, część oczekuje na poprawki), AMD (firma wciąż bada sprawę i opracowuje metody mitygacji), Qualcomm (część patchy została już opracowana i wdrożona), Imagination (Google potwierdziło występowanie podatności na kilku wersjach GPU, odpowiednie łatki zostały wdrożone i udostępnione w grudniu 2023). W związku z tym, że NVIDIA w przeszłości borykała się z problemami podobnego pochodzenia, badaczom nie udało się wykorzystać tej podatności na kartach tej firmy. ARM potwierdził również, że jego urządzenia nie zostały dotknięte problemem.
Brak kompleksowego rozwiązania problemu ze strony producentów powoduje, że to użytkownicy muszą zatroszczyć się o dodanie odpowiednich instrukcji, które wyczyszczą lokalną pamięć GPU po wykonaniu kernela.
Nie jest to pierwsza praca badająca izolację pamięci GPU, jednak tym razem autorzy pochylili się nad coraz częstszym zastosowaniem kart graficznych czyli wspomagania obliczeń w uczeniu maszynowym a w szczególności LLM.
PoC podatności został opublikowany w repozytorium na GitHubie.
Koncepcja ataku może zostać zaprezentowana przez dwa krótkie fragmenty kodu. Po pierwsze kod atakującego – readera, czyli kernel wykonujący odczyty niezainicjalizowanej pamięci. Przeczytane wartości są następnie umieszczane w pamięci globalnej, do której dostęp ma też CPU.

Kod ofiary – writera zapisuje dane do pamięci GPU, co prezentuje poniższy listing:

W tym przypadku zostały wykorzystane metody zapobiegające agresywnej optymalizacji przez kompilator. Kernele są uruchamiane na zmianę, writer (ofiara) zapisuje dane do pamięci GPU, a oddzielny kernel readera (atakującego), czytając niezainicjalizowaną pamięć, jest w stanie odczytać dane zapisane przez ofiarę.
Koncepcja ta została rozszerzona do wykorzystania na hoście uruchamiającym modele językowe. Kernel atakującego odczytuje pozostawione informacje o operacjach algebry liniowej wykonywanych przez LLM. Dokonuje rozpoznania użytego modelu językowego przez wyciekające wagi i porównanie ich z dostępnymi otwartoźródłowymi projektami. Następnie odczytuje przekształcone wejście od użytkownika.
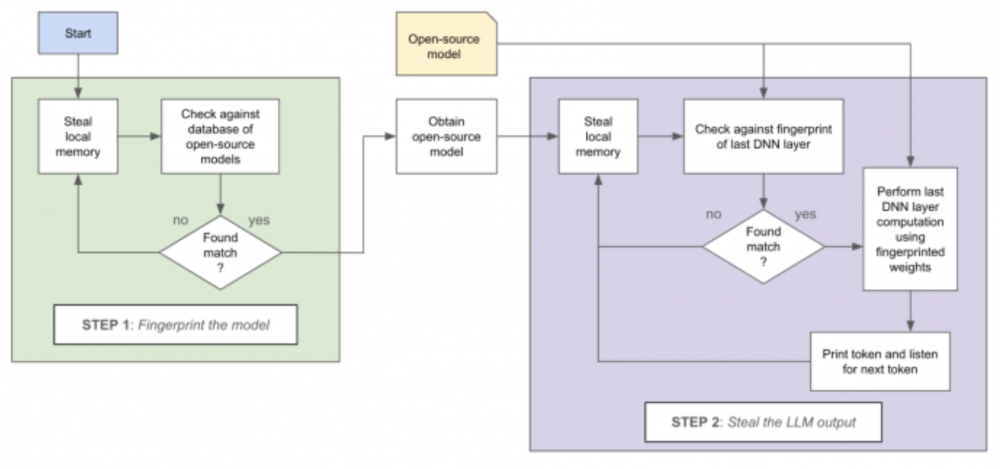
Na podstawie wykradzionych informacji możliwe jest odtworzenie odpowiedzi zwróconej ofierze przez LLM. Idea ataku jest bardzo prosta i może zostać wykorzystana nie tylko na urządzeniach fizycznych, ale także w chmurze.
Zaproponowane przez badaczy rozwiązanie problemu przez czyszczenie pamięci po wykonaniu kernela jest implementowane między innymi przez drivery firm NVIDIA i Intel. MESA (sterowniki dla GPU AMD) posiadają taką funkcjonalność, jednak operacja ta wykonywana jest w ramach oddzielnego kernela, co pozwala na nadużycia mechanizmu kolejkowania kerneli do wykonania.
Badacze poinformowali producentów o podatności w procesie „responsible disclosure”.
~fc
