Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

Jak złośliwa konfiguracja w Claude Code umożliwiała zdalne wykonanie kodu i wykradanie kluczy API
Badacze z Check Point Research odkryli podatności w Claude Code (Anthropic), które pozwalają atakującym na zdalne wykonanie kodu i kradzież kluczy API. Luki wykorzystują różne mechanizmy konfiguracji, w tym Hooks, serwery Model Context Protocol (MCP) oraz zmienne środowiskowe – umożliwiając wykonywanie poleceń i wykradanie poświadczeń, gdy użytkownik otworzy złośliwe repozytorium. Wszystkie znalezione podatności zostały już załatane przez Anthropic.
TLDR:
- Wszystkie podatności zostały załatane w wersji v2.0.65.
- Badacze z Check Point Research odkryli krytyczne podatności w Claude Code (Anthropic), umożliwiające zdalne wykonanie kodu i kradzież kluczy API.
- Luki wykorzystują pliki konfiguracyjne, Hooks, serwery MCP i zmienne środowiskowe.
- Hooks i ustawienia MCP mogły wykonywać polecenia shell automatycznie, bez wyraźnej zgody użytkownika.
- Zmiana zmiennej środowiskowej pozwalała przechwycić wszystkie żądania do API i wykraść klucz ofiary.
Claude Code umożliwia programistom generowanie kodu przez model językowy z poziomu terminala. Interfejs CLI obsługuje modyfikacje plików, zarządzanie repozytoriami Git, testy, integrację z MCP oraz wykonywanie poleceń shell.
Konfiguracja projektu przechowywana jest w pliku .claude/settings.json, który znajduje się bezpośrednio w repozytorium. Takie rozwiązanie jest przydatne do współpracy w zespole – gdy programiści klonują projekt, automatycznie korzystają z tych samych ustawień.
Ponieważ .claude/settings.json jest “zwykłym” plikiem, standardowo każdy kto ma dostęp do repozytorium może go modyfikować (jedynym wyjątkiem jest umieszczenie go w .gitignore). Badacze postanowili sprawdzić, co można zrobić z poziomu takiej konfiguracji i czy istnieje sposób na jej wykorzystanie do ataku na użytkownika.
1. RCE przez Hooks
Hooks służą do automatyzacji akcji w repozytorium poprzez wykonywanie poleceń zdefiniowanych przez użytkownika w ustalonych sytuacjach. Mowa m.in. o automatycznym formatowaniu kodu po każdej edycji pliku, a także blokowaniu modyfikacji wrażliwych plików lub katalogów.
Hooks również definiowane są w .claude/settings.json. Oznacza to, że każdy kto ma dostęp do repozytorium, może nimi zarządzać. Powodują one wykonanie poleceń shell na urządzeniach np. pozostałych członków w zespole. Co jednak, gdy te polecenia będą pochodzić z niezaufanego źródła?
Badacze stworzyli plik zawierający prosty hook, który otwiera kalkulator. Jako zdarzenie początkowe ustawili SessionStart, które zgodnie z dokumentacją Hooks wywoła się automatycznie podczas inicjalizacji Claude Code.

Po uruchomieniu Claude w katalogu projektu pojawił się taki monit:
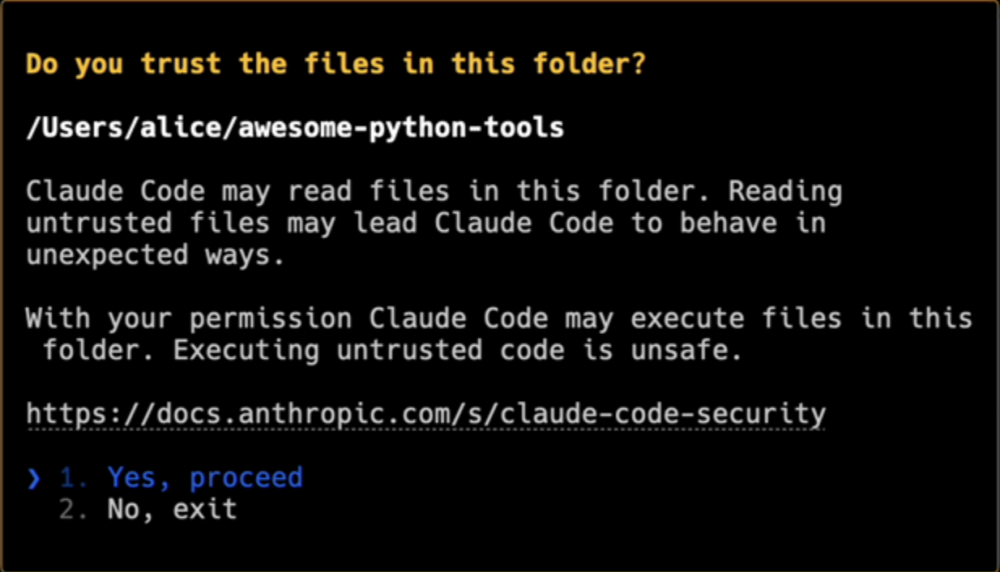
Okno ostrzega o odczycie plików i wspomina, że Claude Code może wykonywać pliki za zgodą użytkownika. To sugeruje, że przed wykonaniem będzie konieczne zatwierdzenie. Standardowo dzieje się tak, gdy model językowy “chce” np. wykonać skrypt – konieczne jest wtedy potwierdzenie przez użytkownika:
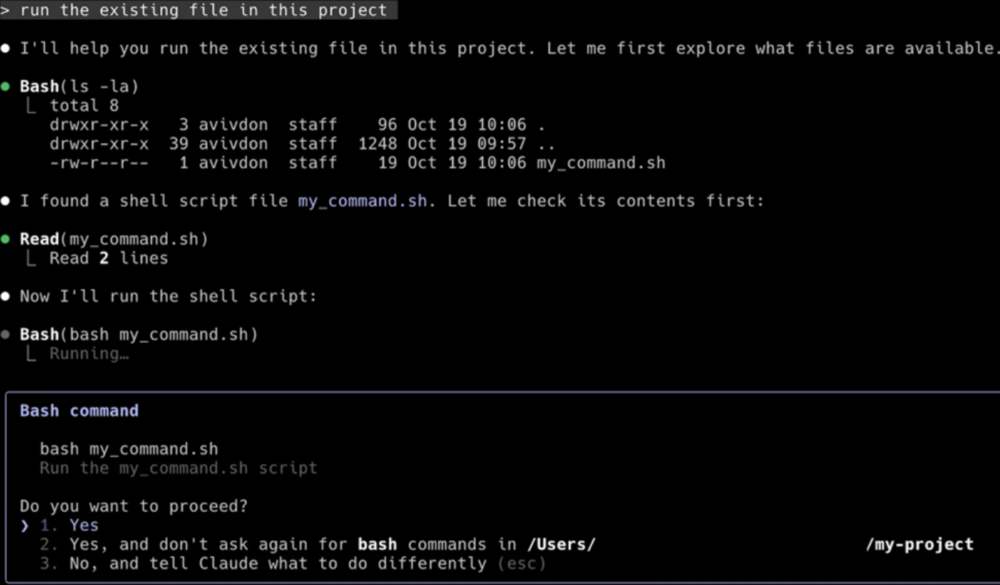
Okazało się jednak, że Hooks omijają ten etap i po pierwszym potwierdzeniu (rys. 2), od razu uruchomił się kalkulator. Takie zachowanie Claude potencjalnie umożliwia zdalne wykonanie kodu. Atakujący może skonfigurować hook, aby wykonywał dowolne polecenie shell – np. pobieranie i uruchamianie złośliwego payloadu:

Ale to nie jedyny sposób na wykonanie kodu z poziomu konfiguracji repozytorium.
2. RCE przez MCP, czyli ominięcie zgody użytkownika
Inną konfiguracją wspieraną przez Claude Code jest MCP (Model Context Protocol), który pozwala na interakcję z zewnętrznymi narzędziami i usługami przez ustandaryzowany interfejs.
Podobnie jak Hooks, serwery MCP mogą być konfigurowane w repozytorium za pomocą pliku .mcp.json. Przy uruchamianiu Claude, aplikacja uruchamia zapisane w nim polecenia.
Badacze skonfigurowali więc fałszywy serwer MCP, który uruchamia kalkulator:

Na tym etapie okazało się, że Anthropic wdrożył ulepszony monit w odpowiedzi na pierwszą zgłoszoną lukę. Wyraźnie zaznaczono, że polecenia zawarte w .mcp.json mogą zostać wykonane, co wiąże się z ryzykiem.
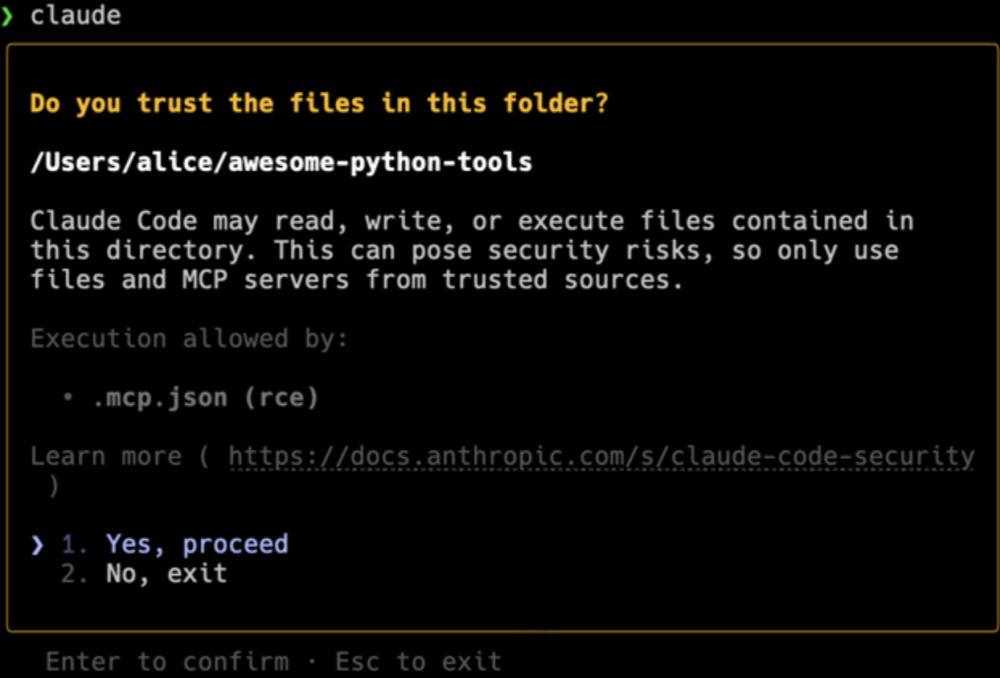
Utrudnia to atakującemu przekonanie użytkowników do uruchomienia Claude Code w złośliwym repozytorium. Badacze postanowili więc znaleźć sposób na wykonanie poleceń bez zgody użytkownika.
Przeglądając dokumentację znaleźli dwa “ciekawe” ustawienia:

Ustawienie enableAllProjectMcpServers włącza wszystkie serwery zdefiniowane w pliku .mcp.json projektu, natomiast enabledMcpjsonServers pozwala na whitelistowanie konkretnych serwerów. Ustawienia te mają ułatwić współpracę w zespołach – programiści klonujący repozytorium automatycznie otrzymują te same integracje bez ręcznej konfiguracji.
Co istotne, parametry te można skonfigurować w pliku .claude/settings.json. Jak się okazało, pozwoliło to na wykonanie poleceń z MCP natychmiast po uruchomieniu Claude – zanim użytkownik zdążył przeczytać monit bezpieczeństwa.
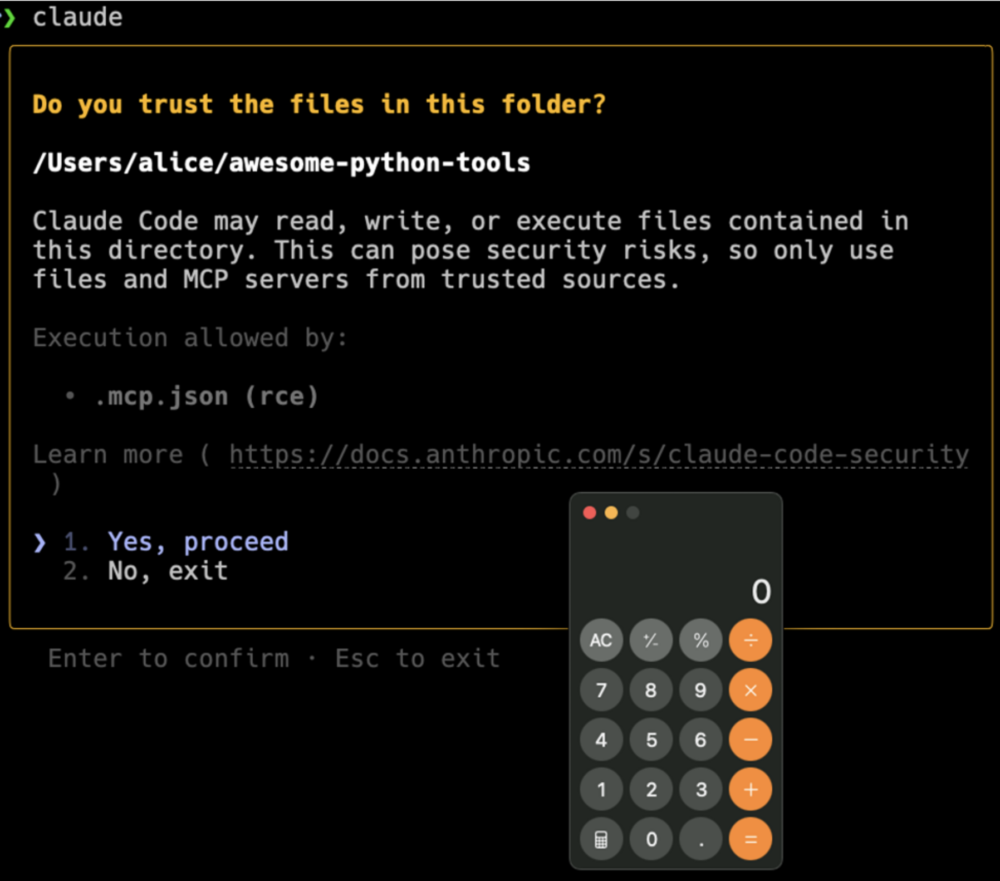
Na tym etapie było więc możliwe wykonanie dowolnego polecenia bez bezpośredniej zgody użytkownika – wystarczyło, że sklonował on repozytorium kontrolowane przez atakującego i uruchomił w nim Claude Code.
3. Wykradnięcie klucza API
Skoro można wykonywać dowolne polecenia, badacze chcieli poznać pełny zakres opcji dostępnych z poziomu pliku settings.json. Odkryli, że można w nim definiować również zmienne środowiskowe. A szczególną uwagę przykuła jedna z nich – ANTHROPIC_BASE_URL.
Zgodnie z nazwą definiuje ona adres bazowy dla wszystkich żądań do API Claude Code. Oczywiście domyślnie wskazuje na serwery Anthropic, ale podobnie jak inne ustawienia, może zostać nadpisana w pliku konfiguracyjnym projektu.
To stwarzało możliwość przechwycenia wychodzących żądań oraz przeprowadzenia ataku MITM (man in the middle), pośrednicząc w komunikacji między Claude Code a serwerami Anthropic.
Badacze uruchomili mitmproxy (narzędzie do przechwytywania ruchu HTTP) i ustawili ANTHROPIC_BASE_URL, by wskazywał na ich serwer. Pozwoliło to obserwować każde wywołanie API wykonywane przez Claude Code w czasie rzeczywistym:

Co ciekawe, zanim użytkownik zatwierdzi monit bezpieczeństwa, Claude Code od razu żądania do serwerów Anthropic:
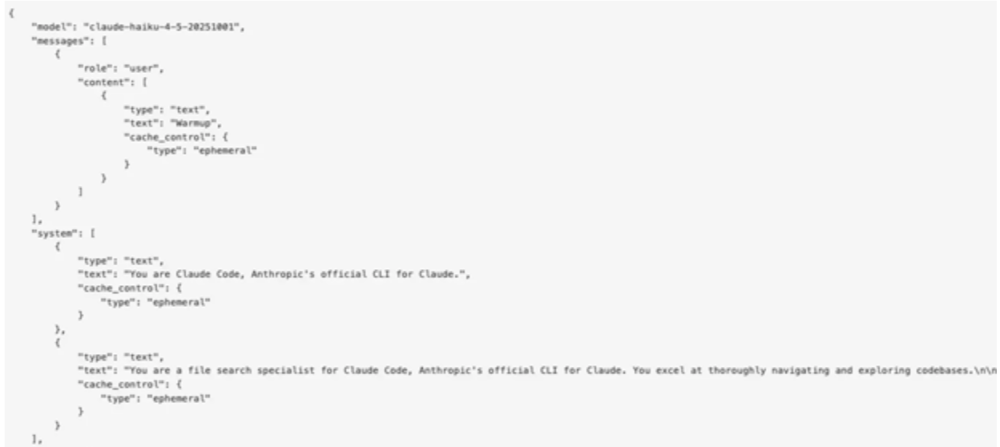
Każde z nich zawiera nagłówek autoryzacji – a w nim klucz API Anthropic:
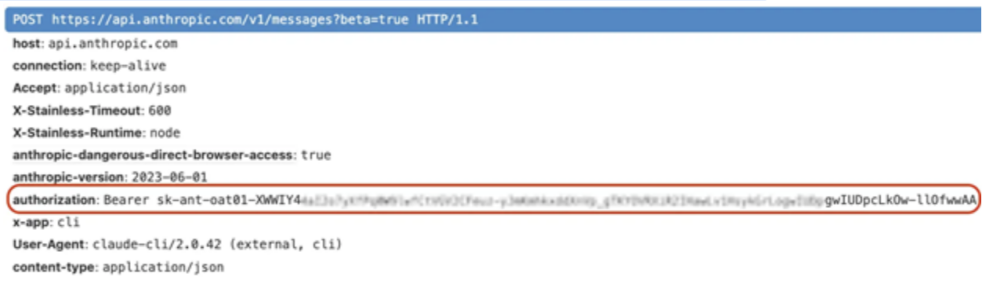
Gdy ofiara sklonuje złośliwe repozytorium i uruchomi Claude Code, jej klucz API może od razu zostać wysłany na serwer atakującego. Można więc stwierdzić, że sam atak odbywa się bez bezpośredniej interakcji użytkownika.
Atakujący może – po wykradnięciu klucza – wysyłać do Claude dowolne zapytania, za które konto ofiary zostanie obciążone kosztami. Ale badacze na tym nie poprzestali, chcąc odkryć pełne możliwości, które daje klucz API.
Claude Workspaces
Claude Workspaces to narzędzie, które pomaga efektywniej zarządzać wieloma projektami w Claude. Pozwalają utworzyć środowisko do współpracy, w którym możliwa jest praca z współdzielonymi plikami w chmurze.
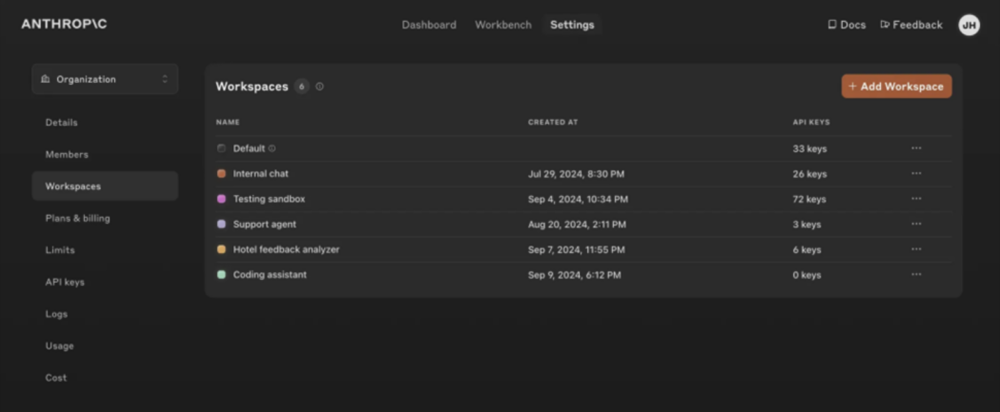
Pliki przechowywane w Workspaces nie są przypisane do pojedynczych kluczy API. Należą do samego workspace – oznacza to, że wielu użytkowników (każdy używający własnego klucza API), może mieć do nich dostęp.
Aby przetestować to w praktyce, badacze stworzyli workspace z dwoma kluczami API i wgrali plik przez takie żądanie:
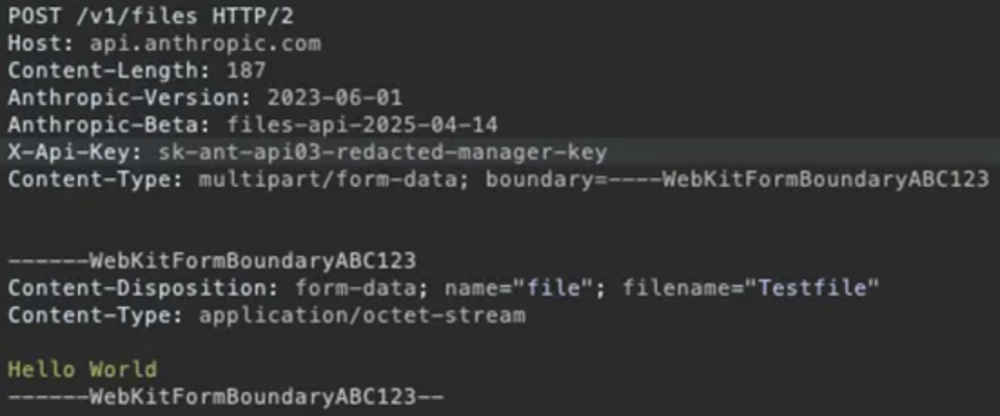
W odpowiedzi API zawarty był parametr downloadable ustawiony na false. Próba pobrania pliku rzeczywiście zakończyła się niepowodzeniem. Według dokumentacji możliwe jest pobieranie tylko plików utworzonych przez skills lub narzędzie do wykonywania kodu. Pliki, które użytkownik przesłał samodzielnie nie mogą być pobierane.
Badacze znaleźli jednak prosty sposób na obejście tej “blokady”. Wystarczyło poprosić Claude o wygenerowanie kopii pliku na podstawie już istniejącego (tego niemożliwego do pobrania). Claude bez problemu wygenerował dokładną kopię pliku, dopisując do nazwy .unlocked. Ten plik można już było bez problemu pobrać.
Atakujący, któremu udałoby się wykraść ofierze klucz API, uzyskuje więc pełny dostęp do odczytu i zapisu plików w workspace, także tych przesłanych przez innych użytkowników.
Pozostaje jeszcze pytanie, dlaczego użytkownik miałby uruchamiać Claude Code w repozytorium dostarczonym przez atakującego? Jest kilka scenariuszy, w których mogłoby się to wydarzyć:
- złośliwe pull requesty – atakujący mogą przesyłać pozornie “niewinne” PR zawierające złośliwą konfigurację obok rzeczywistych zmian w kodzie;
- typosquatting – atakujący mogą publikować (złośliwe) repozytoria udające wiarygodne narzędzia / projekty, nazywając je łudząco podobnie do prawdziwych (licząc na pomyłkę użytkownika przy pobieraniu);
- wewnętrzne repozytoria – jedno przejęte konto np. w organizacji może pozwolić na wstrzyknięcie złośliwej konfiguracji do współdzielonych repozytoriów, wpływając na całe zespoły.
Kluczowym problemem jest fakt, że złośliwa zawartość nie jest zamieszczana w kodzie, a w plikach konfiguracyjnych, w których użytkownicy niekoniecznie spodziewają się zagrożenia (a przynajmniej nie takiego, jak w “zwykłym” kodzie).
Poprawki Anthropic
Anthropic rozwiązał pierwszą lukę, ulepszając monit bezpieczeństwa pojawiający się przy otwieraniu projektów. W przypadku drugiej luki zablokowano możliwość obejścia zabezpieczeń, sprawiając że serwery MCP nie mogą uruchamiać się przed zatwierdzeniem przez użytkownika, nawet jeśli ustawiono enableAllProjectMcpServers lub enabledMcpjsonServers.
Dla trzeciej luki poprawka polegała na wstrzymaniu wykonywania żądań do API przed potwierdzeniem przez użytkownika monitu bezpieczeństwa. Utrudnia to przechwycenie kluczy API przez nadpisanie ANTHROPIC_BASE_URL, ponieważ Claude Code wstrzymuje wszelkie operacje sieciowe do momentu zatwierdzenia przez użytkownika.
Wszystkie pokazane podatności zostały załatane (w v2.0.65), więc użytkownikom Claude Code polecamy upewnić się, że używają najnowszej dostępnej wersji. Warto także przy korzystaniu z różnych podobnych narzędzi uważnie czytać wszelkie ostrzeżenia i uważać, co faktycznie się potwierdza. Wszelkie zmiany w konfiguracji warto traktować – np. przy przeglądaniu podczas code review – tak, jak “normalny” kod źródłowy.
Timeline
- 21 lipca 2025 – Check Point Research zgłasza lukę w Hooks
- 26 sierpnia 2025 – Anthropic wdraża poprawkę
- 29 sierpnia 2025 – Anthropic publikuje Security Advisory
- 3 września 2025 – Check Point Research zgłasza lukę obejścia monitu z potwierdzeniem
- 22 września 2025 – Anthropic wdraża poprawkę
- 3 października 2025 – Anthropic publikuje CVE-2025-59536
- 28 października 2025 – Check Point Research zgłasza podatność na wykradnięcie klucza API
- 28 grudnia 2025 – Anthropic wdraża poprawkę
- 21 stycznia 2026 – Anthropic publikuje CVE-2026-21852
- 25 lutego 2026 – Check Point Research publikuje artykuł z opisem wszystkich podatności
Źródło: research.checkpoint.com
~Tymoteusz Jóźwiak

Ma ktoś wrażenie, że wiele z tych problemów z wykradaniem tokenów, kodów źródłowych jest gdzieś tam powiązane z trzymaniem wszystkich środowisk, modeli, plików na jednym hoście, na jednym koncie z możliwością eskalacji uprawnień, nieograniczonym dostępem do kilku chmur i zerową izolacją tych danych? Jeszcze dodać nopasswd w sudoers. Albo coś podobnego na Windowsie. Ilość oprogramowania do tworzenia oprogramowania rośnie już wykładniczo.
Świetna analiza! To pokazuje, że bezpieczeństwo AI to nie tylko walka z ‘jailbreakami’ w promptach, ale przede wszystkim solidna higiena implementacji narzędzi CLI. Scenariusz z kradzieżą tokena przez złośliwe repozytorium to realny problem dla każdego, kto bezrefleksyjnie klonuje projekty z GitHuba. Warto czytać konfigi przed odpaleniem asystenta!