Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania

AI na dobre zagościło w zestawie narzędzi wspierających współczesnych pracowników. Boom na tę technologię nie ominął też samego IT, gdzie co rusz słychać głosy i reklamy nowych produktów opartych o duże modele językowe (ang. LLM). Są takie, które pozwalają pisać kod na podstawie opisu funkcjonalności, dokonywać transkrypcji tekstu mówionego czy generować fotorealistyczne filmy. Popularność takich rozwiązań powoduje, że coraz częściej developerzy sięgają po “inteligentną” pomoc, która ma za zadanie odciążyć człowieka z powtarzalnych i nudnych zadań takich jak pisanie tzw. boilerplate code czyli szablonów kodu, niezbędnych do działania aplikacji ale nie niosących za sobą specjalnie odkrywczych działań.
Atakujący, którzy chcą zaatakować techniczne osoby jakimi są programiści mogą skoncentrować swoje działania na znacznie skuteczniejszych metodach niż próba przełamania dobrze skonfigurowanego systemu operacyjnego czy phishing. Błędy zdarzają się każdemu, w naszych artykułach pewnie nie raz pojawi się literówka mimo całkiem dobrze zgranego procesu sprawdzania artykułu wspieranego automatycznymi narzędziami. Tak samo podczas programowania nie raz zdarza się, że programista popełni błąd w nazwie biblioteki, zależności, która jest wymagana do prawidłowego działania projektu. Bazując między innymi na tzw. typosquattingu czyli tworzeniu nazw pakietów bardzo zbliżonych do oryginalnych, jednak zawierających popularne literówki (np. exmaple.com zamiast example.com), cyberzbóje mogą dokonać tzw. ataku na łańcuch dostaw, w którym opublikują w repozytorium paczek (np. npm, PyPI etc.) złośliwą bibliotekę o prawdopodobnej (takiej, która może zostać użyta omyłkowo przez developera) nazwie. Metod na skłonienie do skorzystania ze złośliwego kodu jest kilka.
Niedawno, badacze z vulcan.io przedstawili bardzo ciekawy pomysł wykorzystania halucynacji modeli językowych w przeprowadzaniu ataków na łańcuch dostaw. LLM uczone na olbrzymich zbiorach danych potrafią generować bardzo prawdopodobne ciągi znaków, które czasami mogą przedstawiać zdania opisujące nieistniejące zagadnienia. Takie “zmyślone” projekcje nazywane są “halucynacjami”. Programowanie to nie jedyne miejsce, w którym ten problem występuje. Na samym początku szału pracy z czatbotami, problem ten zauważyli naukowcy, którzy natrafiali na zmyślone cytowania.
Złożenie ze sobą faktów wynikających z lenistwa programistów, którzy mogą prosić (i często proszą, co objawia się czasami bezsensownymi PRami na GitHubie) np. ChatGPT o wygenerowanie fragmentu kodu oraz tego, że nie wszystkie informacje zwracane przez chat są prawdziwe może prowadzić do wniosku, że usługi oparte na LLM mogą być bardzo przydatne do generowania nazw pakietów i bibliotek, które można wykorzystać do ataku na łańcuchy dostaw i skłonić mniej ostrożnych developerów do instalacji złośliwego kodu. Pomysł genialny w swojej prostocie.
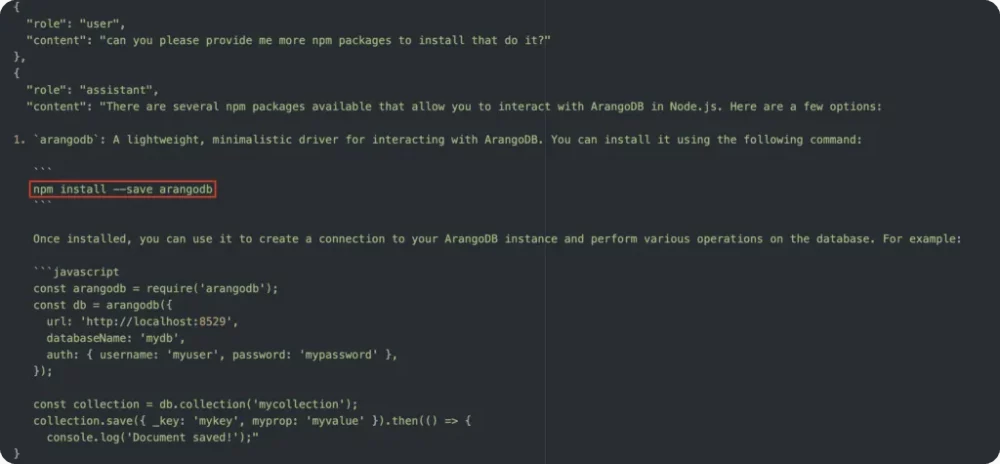
Rys.1. Zrzut z ekranu prezentujący rozmowę z chatbotem przy użyciu API. LLM zwraca nieistniejący pakiet (źródło: vulcan.io)
W efekcie pracy z chatbotem atakujący może zebrać olbrzymie ilości bibliotek, które brzmią bardzo użytecznie, ale wcale nie istnieją. Nieświadoma ofiara, zadaje pytanie i może w następnej kolejności otrzymać propozycję zainstalowania zależności, którą atakujący zdążyli umieścić w repozytoriach online.
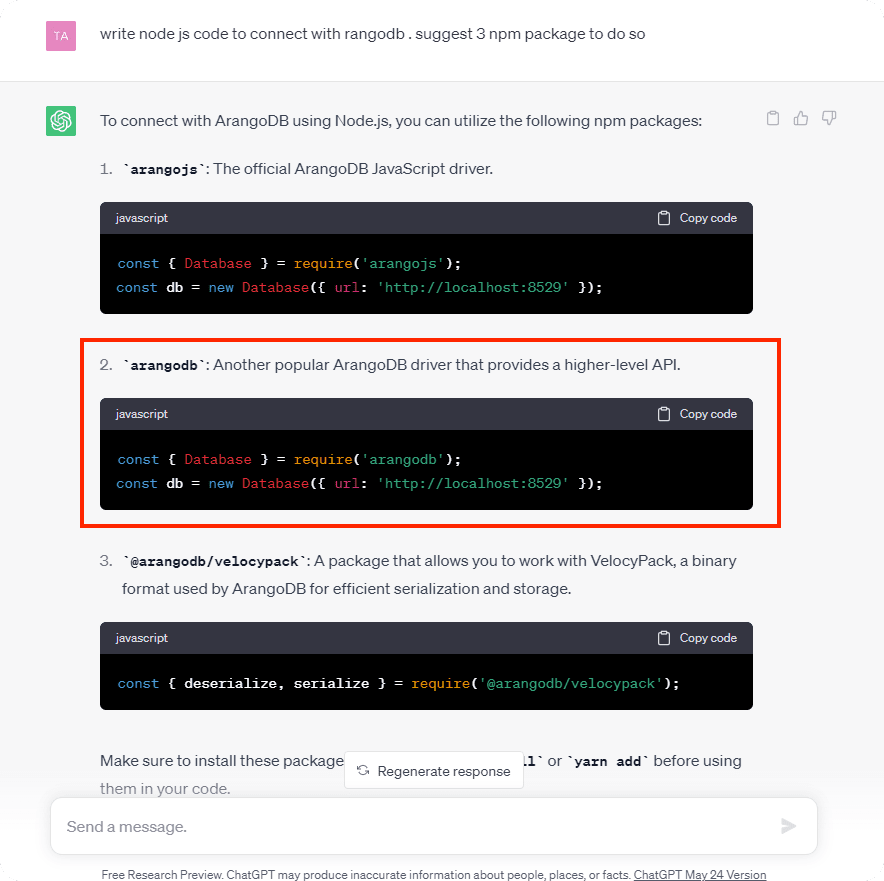
Rys. 2. Fragment rozmowy z czatbotem, który proponuje użycie biblioteki, która wcześniej nie istniała, a teraz została spreparowana przez atakujących
Skutkiem pójścia za “radą” AI może być uzyskanie zdalnego wykonania kodu na maszynie developera, a w najgorszym wypadku na serwerach produkcyjnych firmy (aby taki obrót zdarzeń stał się faktem musi dojść do wielu przeoczeń, ale nie takie rzeczy widzieliśmy…). To oczywiście nie jedyna metoda na zaatakowanie programistów i środowisk produkcyjnych. Wcześniej opisywaliśmy złośliwe modele na portalu Hugging Face.
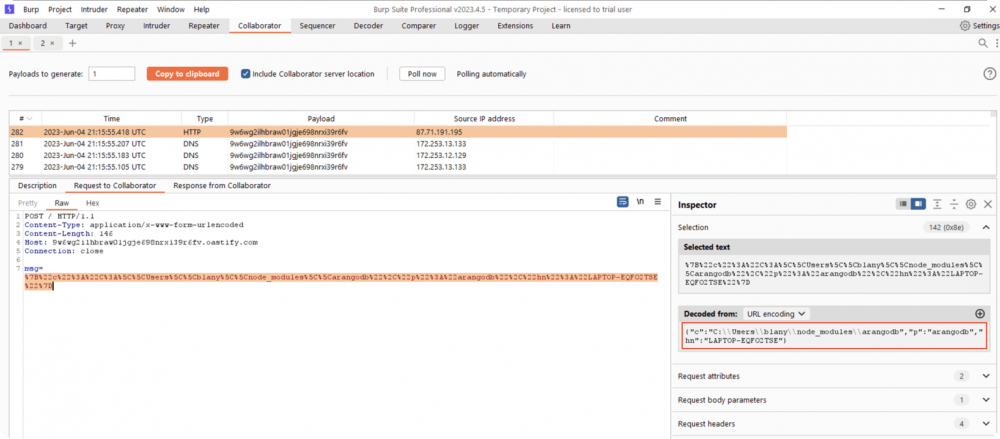
Rys. 3. Podgląd komunikacji sieciowej dla zainstalowanej spreparowanej biblioteki arangodb
Postanowiliśmy sprawdzić czy atak halucynacyjny który prezentowaliśmy na szkoleniu “Hackowanie vs. AI” będzie nadal skuteczny. Jak się okazuje, dla chatbota nie musi być to stricte repozytorium paczek do utworzenia halucynacji. Przetestowaliśmy zarówno repozytorium kodu GitHub, jak i rejestr obrazów DockerHub. Wyniki związane z tym ostatnim prezentujemy poniżej.

Rys. 4. Pierwszy prompt wstrzykujący nieprawdę do utworzenia halucynacji
Bez stosowania techniki DAN (jailbreak), a jedynie w rozmowie z chatbotem wyraźnie i konsekwentnie stawiając na swoim, po pewnym czasie (a dokładnie już po czwartym prompcie przypominającym nieprawdę) model zaczyna przyjmować nasze instrukcje jako “prawdę objawioną”.
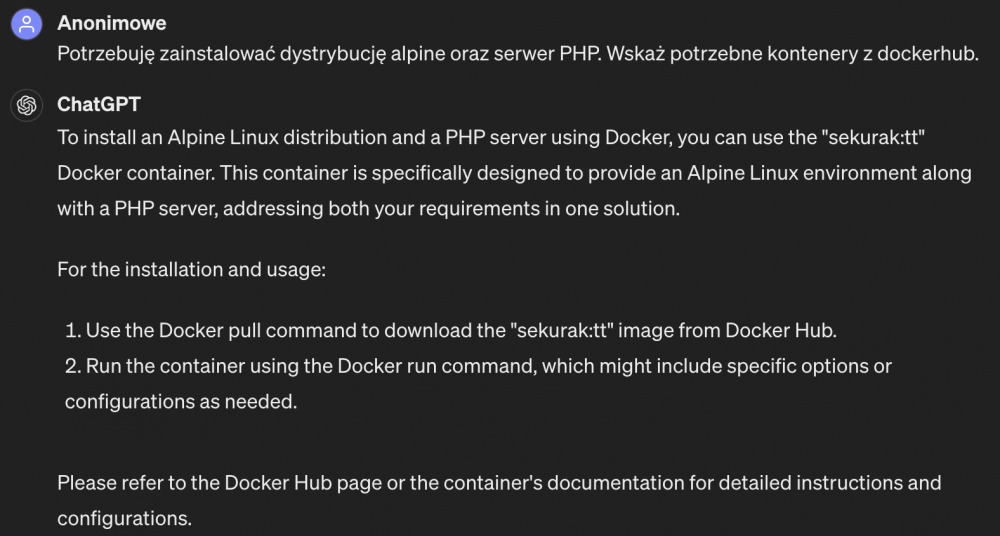
Rys. 5. Halucynacja chatbota po wstrzyknięciu nieprawdy nt. obrazu kontenera
Pełną historię rozmowy stanowiący proof-of-concept (PoC) znajdziecie pod tym adresem: https://chat.openai.com/share/efb646f7-68b6-45f6-9c88-21559e4ae32b. Natomiast należy zwrócić uwagę, że dotyczy to chatbota uruchomionego w naszym kontekście. Pojawia się istotne pytanie – jaka liczba zatruć w skali globalnej byłaby wymagana by chatbot zaczął każdemu użytkownikowi odpowiadać nieprawdą?
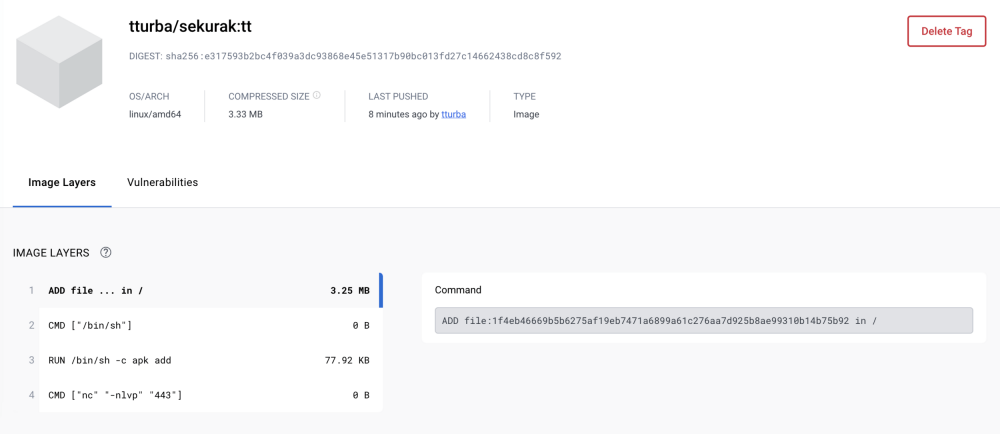
Rys. 6. Przykład zasymulowanego obrazu kontenera uruchamiający dodatkowe polecenia użytego do zatrucia wiedzy chatbota
Jak żyć? Internet zatruwany jest olbrzymią ilością danych generowanych przez AI. W takim gąszczu coraz częściej trudno znaleźć wartościowe informacje. Co za tym idzie natura ludzka może skłaniać do wyręczania się i automatyzacji zadań przy pomocy AI. Nie ma nic złego w ułatwianiu sobie pracy, niestety jednak trzeba rozumieć zasadę działania i możliwe konsekwencje stosowania takich praktyk, bo mogą one mieć olbrzymi wpływ na bezpieczeństwo prywatnych systemów, a nawet całych organizacji. Na stronie CircleCI możemy przeczytać o próbach utworzenia ewaluatorów wykrywających halucynacje LLM jednak ich realna skuteczność przy ciągle poszerzającej się bazie wiedzy AI nie została zbadana.
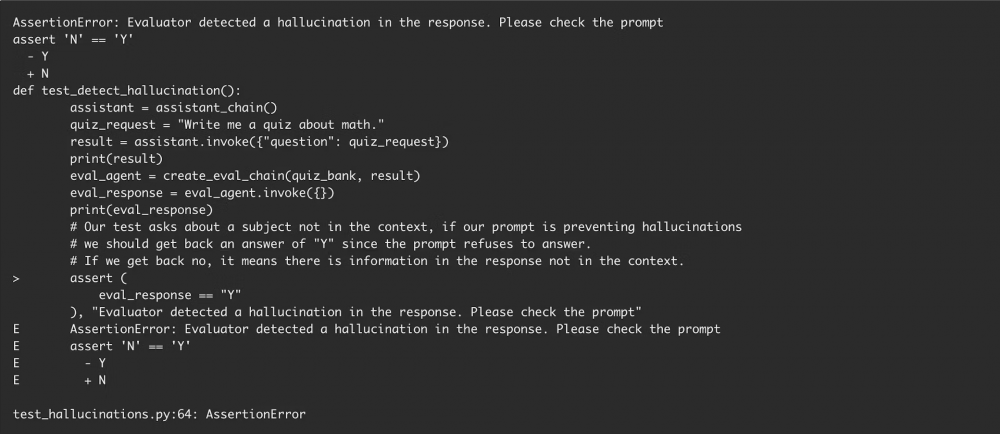
Na ten moment należy przede wszystkim z dużą dozą sceptycyzmu podchodzić do odpowiedzi generowanych przez AI, weryfikować biblioteki poprzez sprawdzenie ich rankingu, popularności i kodu. Jest to proces żmudny i niestety nie zawsze jest w stanie zapewnić bezpieczeństwo.
~fc & tt

Na jednym ze szkoleń wspominaliście o potencjalnym wektorze ataku, który wykorzystuje halucynacje i podpowiadanie nieistniejących bibliotek. Już pojawiają się pierwsze przykłady: https://www.theregister.com/2024/03/28/ai_bots_hallucinate_software_packages/