Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania

Współczesne aplikacje internetowe to bardzo rozbudowane projekty, wykorzystujące wiele różnych zasobów (plików / katalogów) umieszczonych lokalnie na serwerze. Podczas testów penetracyjnych warto zaopatrzyć się w zestaw wyspecjalizowanych narzędzi przydatnych w określonych sytuacjach. Jednym z nich jest DirBuster – prosty skaner aplikacji webowych przeznaczony do wykrywania normalnie nieosiągalnych z poziomu nawigacji serwisu folderów i plików.
Do czego opisywany program może nam się przydać w praktyce? Przykładem niech będzie sytuacja, gdy nieuważny programista pozostawił na serwerze katalog z zapisami logów czy plik z tymczasowymi hasłami do ftp albo systemu bazodanowego. Niemal niemożliwe jest natrafienie na taki zasób ręcznie – z pomocą DirBustera mamy znacznie większe szanse na jego odkrycie.
W największym skrócie – Dirbuster próbuje wykryć na serwerze katalogi i pliki, które są zdefiniowane we własnej bazie.
DirBuster w ostatniej wersji (0.12) jest dostępny do pobrania pod adresem http://sourceforge.net/projects/dirbuster/ jako archiwum tar.bz2 – wystarczy rozpakować pobrany plik do wybranego katalogu, a następnie uruchomić program poleceniem:
$ java -jar DirBuster-0.12.jar
Więcej o samym programie można poczytać na oficjalnej stronie projektu w serwisie OWASP:
https://www.owasp.org/index.php/Category:OWASP_DirBuster_Project.
Program dołączany jest także do pakietu narzędzi linuksowej dystrybucji BackTrack (http://www.backtrack-linux.org/).
Przejdźmy zatem do praktycznego wykorzystania prezentowanego narzędzia. Jego działanie jest proste – podajemy adres url witryny [A] (patrz rzut ekranowy poniżej), ustawiamy kilka podstawowych parametrów, między innymi liczbę uruchomionych wątków, a co się z tym wiąże – liczbę żądań przesyłanych równocześnie [B], ścieżkę do pliku tekstowego z listą nazw katalogów (w przypadku ataku słownikowego [C] ) albo zaznaczamy opcję “Pure brute force” [D] (czym są ataki słownikowe oraz brute force można przeczytać tutaj: ‘Atak brute force’ oraz tutaj: ‘Atak słownikowy’).
Dodatkowo mamy też możliwość wyboru rodzaju żądania (GET lub wybór automatyczny pomiędzy GET i HEAD [E] ), ścieżki do katalogu, od którego DirBuster rozpocznie skanowanie (standardowo jest to główny katalog aplikacji [F] ), a także, poza wyszukiwaniem katalogów, opcję odnajdywania plików, które nie są bezpośrednio osiągalne z poziomu nawigacji, wraz z ich rozszerzeniem (np. ‘php’ czy ‘asp’ [G] ).
Takimi niedostępnymi na pierwszy rzut oka zasobami mogą być choćby katalogi z różnego rodzaju logami, pliki pozostałe po wszelakich testach, a nawet fragmenty aplikacji dostępne jedynie dla określonej grupy użytkowników znających bezpośredni url do nich (intranet-login.php, customerpanel, delivery-status.asp itp.).
Jak szybko i skutecznie program działa, można przekonać się, uruchamiając go przeciwko dowolnie wybranej, popularnej aplikacji internetowej (WordPress, Joomla) – już po dwóch, trzech sekundach w oknie programu pojawią się pierwsze wyniki (m.in. katalogi wp-admin/ czy administrator/ – zdjęcie 2. oraz 3. przedstawia wynik skanowania popularnego CMS-a Joomla w wersji 2.5.9 zatrzymanego po około 20-25 sekundach od uruchomienia).
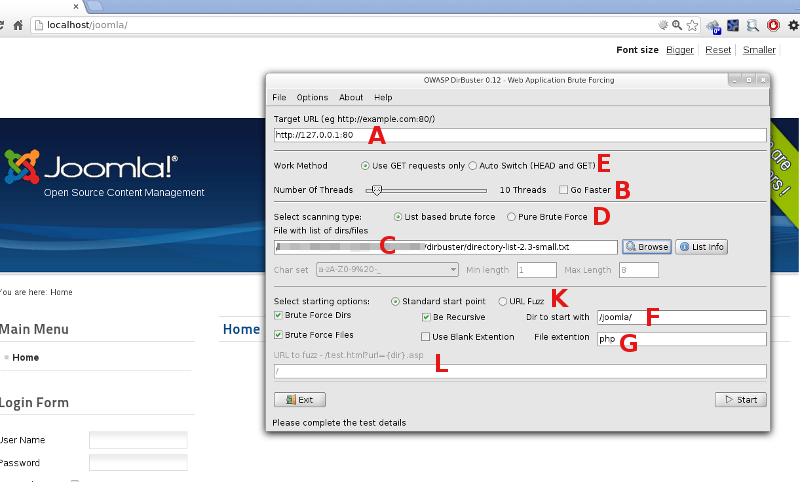
Ustawienia podstawowe parametrów skanowania
DirBuster, korzystając z dostarczonych wraz z nim gotowych słowników najczęściej używanych katalogów/plików w aplikacjach internetowych, po prostu szuka takich zasobów pod podanym adresem www, czyli przeprowadza klasyczny atak słownikowy. Aby nie wzbudzać “niepokoju”, możemy ograniczyć liczbę żądań wysyłanych jednocześnie przez program do serwera (pamiętajmy, że zautomatyzowane skanowania są dość szybko wychwytywane przez systemy IDS czy też WAF, a duża liczba żądań z jednego adresu IP może zainteresować administratorów).
Po ustawieniu wszystkich parametrów pozostaje nacisnąć “Start” i cierpliwie czekać, aż DirBuster zakończy pracę (w każdej chwili możemy też ręcznie wstrzymać lub całkowicie anulować cały proces). W trakcie działania programu na bieżąco widzimy informacje m.in. o liczbie żądań zakończonych i pozostałych do wysłania, aktualizowaną na bieżąco listę z wynikami skanowania, mamy także możliwość przyspieszenia bądź spowolnienia całego procesu w czasie rzeczywistym (bez przerywania aktualnie wykonywanego skanu).
Po zakończeniu bądź przerwaniu skanowania możemy przejść do analizy rezultatów. Są one prezentowane w postaci prostej listy oraz znacznie czytelniejszego drzewa katalogów i plików – jeśli wybraliśmy wcześniej opcję ich odnajdywania. Przy każdym z nich umieszczone są dodatkowe informacje, takie jak status odpowiedzi HTTP serwera (200 oznacza, że dany zasób został odnaleziony i jest dostępny z poziomu przeglądarki internetowej, 403 to zasób znaleziony, ale dostęp do niego wymaga autoryzacji HTTP [H] – o innych wartościach w tej kolumnie dowiesz się więcej z opracowania dostępnego pod adresem ‘Kody odpowiedzi HTTP’ oraz w oficjalnym Request For Comments protokołu HTTP – RFC 2616 w sekcji 6.1.1 – “Status Code and Reason Phrase”). Na podstawie informacji z kolumny ‘Status’ [I] możemy zorientować się w bieżącym postępie działania – ‘Waiting’ oznacza, że katalog został odnaleziony i DirBuster wkrótce przystąpi do rekurencyjnego przeszukiwania jego zawartości, ‘Scanning’ to proces, który trwa:
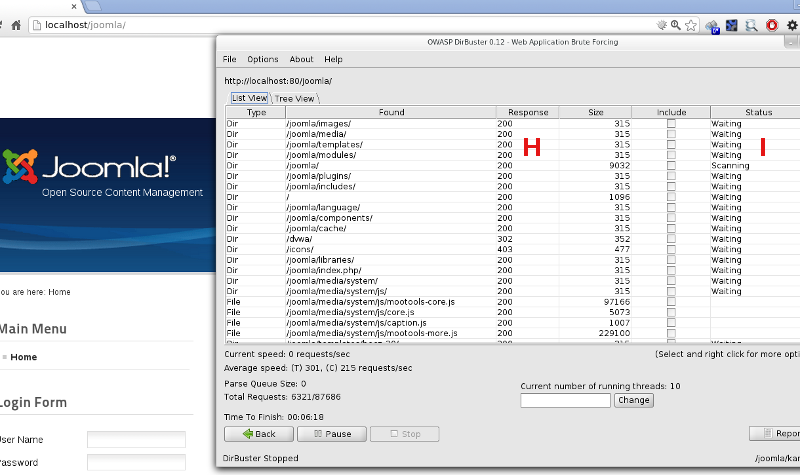
Odnalezione zasoby w postaci listy plików i katalogów
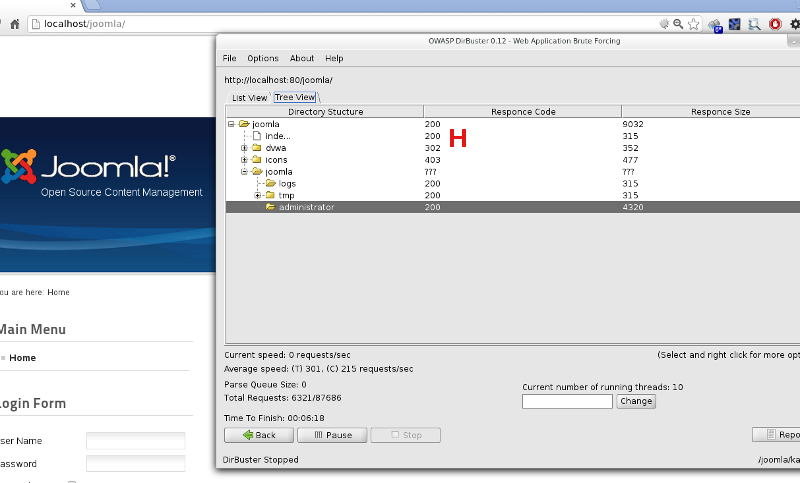
Widok drzewa odnalezionych katalogów i plików
Całkowity czas skanowania jest uwarunkowany liczbą katalogów znajdujących się w pliku z wybranym słownikiem. Standardowo z DirBusterem otrzymujemy kilka takich słowników (w formie plików tekstowych), podzielonych na dwie główne kategorie oraz w trzech wariantach (lista krótka, średnia oraz duża): zawierające jedynie małe litery oraz cyfry (od ponad 81 tysięcy w wariancie ‘small’ do prawie miliona 200 tysięcy w wariancie ‘big’ – ponad 13 MB danych) oraz zawierające wszystkie znaki możliwe do użycia w nazwach katalogów (tu liczba wpisów mieści się w przedziale od 88 tysięcy do prawie miliona 300 tysięcy pozycji).
Ponieważ są to standardowe pliki tekstowe, w których każda linia zawiera jeden katalog, nic nie stoi na przeszkodzie, by użyć dowolnego innego pliku z podobnymi danymi (na przykład z najczęściej używanymi nazwami użytkowników), a nawet pokusić się o utworzenie własnego – przykładowo w sytuacji, gdy badamy specyficzną aplikację wykorzystującą swój własny, znany nam format nazewnictwa.
W naszych rodzimych warunkach sprawdzić może się słownik utworzony przez osoby z polskiego forum BackTrack, dostępny pod adresem http://backtrack.pl/polish-wordlist-project/. Warunki jego używania opisane są pod podanym adresem. Słownik jest co jakiś czas aktualizowany o nowe wpisy (ostatnia aktualizacja w momencie pisania tego artykułu pochodziła z września 2012 roku). Trzeba przyznać, że liczba zebranych w nim wpisów jest imponująca.
Możliwości programu nie kończą się na prostym wyszukiwaniu katalogów. Po wybraniu w menu ‘Options’ pozycji ‘Advanced options’ mamy możliwość ustalenia nazwy użytkownika/hasła dla mechanizmów autoryzacji HTTP Basic i Digest [J] (więcej o tych metodach znajdziesz tutaj: Digest oraz Basic ), rozszerzeń plików, jakie mają być pomijane w trakcie skanowania z zaznaczoną opcją ‘Brute Force files’, zdefiniowania ciągu przesyłanego w żądaniu HTTP w polu ‘User Agent’ (np. w celu utrudnienia identyfikacji systemu, z którego pochodziło skanowanie) czy zdefiniowania własnych nagłówków dla żądań HTTP (pomocne w celu weryfikacji, czy serwer reaguje np. w niestandardowy sposób na pewne specyficzne nagłówki – tutaj znajdziesz informacje o formacie żądań HTTP: ‘List of HTTP headers’).
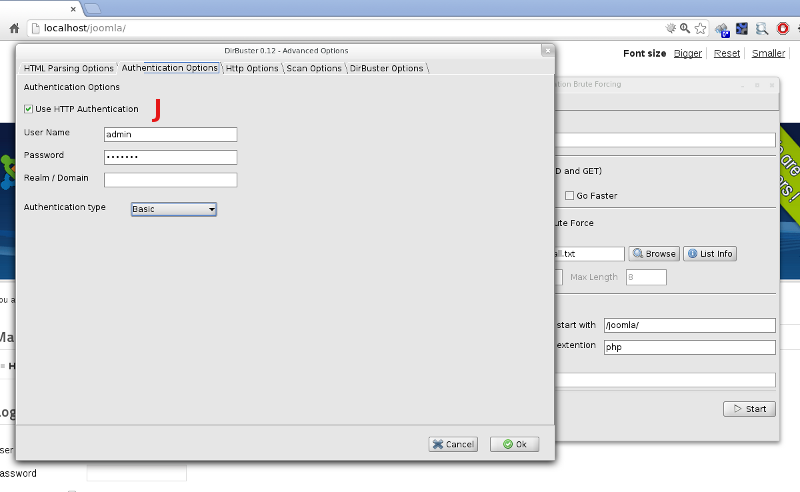
Ustawienia zaawansowane umożliwiają m.in. podanie danych do autentykacji HTTP Basic lub Digest
Mimo swojej prostoty, DirBuster doskonale sprawdza się w roli, do jakiej został przeznaczony. Program został napisany w Javie, co pozwala na uruchomienie go w dowolnym systemie operacyjnym udostępniającym maszynę wirtualną tego języka (wystarczy środowisko uruchomieniowe JRE). Jest bardzo prosty w obsłudze i dość szybki, choć realny czas pracy i tak w dużej mierze zależy od wybranych parametrów skanowania.
— Rafał ‘bl4de’ Janicki (bloorq[at]gmail.com)

Masz jakieś fajne, wypróbowane słowniki? Nie to, aby te domyślne były kiepskie, ale coś lepszego by się przydało ;)
Popieram pytanie :) Z mojej strony mogę na start polecić bazę z modułu http_enum (nmap), nieźle też sprawdza się baza z wikto/nikto.
–ms
Jak do tej pory, nie pojawiła się konieczność skorzystania z innych słowników . te dołączone do DirBuster’a mają niezłe “pokrycie”, szczególnie te w wersji ‘big’.
Zastanawiam się nad jednym – on robi geta I heada. Jest jakiś program, który w podobny sposób wyszukiwały endpointow (np restowych), które obsługują tylko post albo np put ?
obadaj ffuf