Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania

Pierwsza część artykułu rzuciła światło na problem powolnych połączeń HTTP, które są sercem ataku Slowloris. W drugiej części przyjrzymy się szczegółowo innej odmianie tego ataku – wariancie Slow HTTP Body. Zapoznamy się również z narzędziem SlowHttpTest pozwalającym przeprowadzać szczegółowe testy różnych zagrożeń Slow HTTP DoS.
Kluczem do sukcesu podczas ataku Slow HTTP jest umiejętność zajęcia całej puli połączeń serwera aplikacyjnego. Przedstawiony w poprzednim artykule Slowloris realizował tę ideę poprzez powolne dosyłanie nagłówków żądania HTTP. Skrypt, przez ustanowienie wielu powolnych połączeń, powodował “zatkanie” serwera Apache. Oprócz tego, że serwer nie mógł przyjmować nowych połączeń, to w dodatku zużywał wiele zasobów na utrzymywanie kanałów zestawionych przez napastnika.
Gdy podobny atak wykonamy na web serwer IIS to okaże się, że usługa Microsoftu całkiem nieźle poradzi sobie z wolno dosyłanymi nagłówkami HTTP. Bynajmniej nie oznacza to, że Internet Information Services posiada na tyle przemyślaną architekturę, która uchroniłaby nas przed zagrożeniem DoS.
Przyjrzyjmy się, w jaki sposób IIS może realizować proces obsługi żądania.
Okazuje się, że Internet Information Services przetwarza żądania w nieco odmienny sposób niż konkurencyjny Apache. Po obserwacjach kilku ataków DoS można zauważyć, jakby IIS po zestawieniu połączenia TCP przekazywał obsługę żądania do specjalnej puli. Podczas odbierania nagłówków HTTP procedura obsługi owej “puli żądań z dosyłanymi nagłówkami” okazuje się nie być dużym obciążeniem dla reszty systemu. Serwer Microsoftu potrafi jednocześnie odbierać wiele nagłówków żądań i do momentu odebrania ostatniego nagłówka nie będzie zaprzątał sobie takimi zasobami głowy. Powoduje to, że zestawienie dużej liczby połączeń przy pomocy Slowlorisa staje się nieefektywne – klienci przesyłający kompletne zapytania HTTP będą poprawnie obsługiwani przez serwer.
Pójdźmy nieco dalej, wgłębiając się w szczegóły. IIS każde żądanie może obsłużyć w inny sposób. Metodę określa po odczytaniu linii żądania oraz nagłówków HTTP. Konfiguracja serwera oraz aplikacji definiuje, że przykładowo zasoby o rozszerzeniu .png mają być obsługiwane przez handler plików statycznych, a pliki z rozszerzeniem .aspx powinny być interpretowane zgodnie z całym cyklem żądania strony ASP.NET. Serwer IIS musi odczytać linię żądania HTTP oraz jego nagłówki, aby wiedzieć, która aplikacja (oraz w jaki sposób) ma przetworzyć zapytanie. Do momentu, aż serwer nie otrzyma wszystkich tych informacji, będzie trzymał przychodzące połączenia w osobnym “worku” i nie będzie ich intensywnie przetwarzał.
W kontekście ataków Slow HTTP DoS, intuicyjnie można powiedzieć, że istnieją następujące etapy obsługi żądania IIS:
Podobnie jak Apache, IIS również nakłada limity czasu odbierania kolejnych porcji danych i zrywa połączenia z bardzo wolnymi klientami. W odróżnieniu jednak od serwera Apache, atak Slowloris nie zatka tak skutecznie serwera Microsoftu, ponieważ samo odbieranie wolno nadchodzących nagłówków nie wyczerpie puli zasobów i atak Slow HTTP Headers stanie się po prostu mało efektywny.
Problem niestety pojawia się w fazie trzeciej. Gdy klient wyśle zapytanie typu POST, wtedy po nagłówkach zacznie wysyłać ciało żądania HTTP. IIS musi te dane odebrać, aby potem je zinterpretować w konkretnej aplikacji. Problem w tym, że odbieranie danych z żądania HTTP już nie jest tak wydajne, jak odbieranie nagłówków. IIS intensywnie przetwarza pulę żądań z przesłanymi nagłówkami (niezależnie od tego, czy mają one kompletne ciało czy nie), więc duża liczba takich połączeń będzie skutkować odmową dostępu do usługi.
Z doświadczenia mogę powiedzieć, że kolejka połączeń z wolno dosyłanym ciałem mieści nie więcej niż kilka tysięcy elementów (niektóre źródła mówią o setkach połączeń). Atak jest skuteczny na aktualnych serwerach: z pewnością domyślna konfiguracja IIS 6.0–8.5 jest zagrożona. Przypuszczam, że nadchodząca platforma vNext mimo rewolucyjnych zmian, nie wprowadzi w tym aspekcie wielu usprawnień (ale trzeba to potwierdzić w przyszłym roku).
Program slowhttptest jest pewnego rodzaju kombajnem do testów bezpieczeństwa wolnych żądań HTTP. Przy jego pomocy możemy przetestować swoją infrastrukturę przeciwko czterem odmianom ataku Slow HTTP DoS – nie musimy ręcznie generować ruchu, ani wykorzystywać kilku osobnych skryptów takich jak Slowloris (do wolnych nagłówków) czy R.U.D.Y. (do wolnego ciała żądania).
Całe spektrum zagrożeń Slow HTTP DoS jest więc dostępne z poziomu jednego narzędzia. W dodatku narzędzie to posiada dużo opcji konfiguracyjnych, dzięki którym dostrajamy atak do naszych potrzeb i przeprowadzamy rzetelne testy nawet w skomplikowanej infrastrukturze. Po skończonej symulacji możemy zapisać schludny raport, który śmiało powinniśmy dodać jako element dokumentacji testów penetracyjnych.
Chyba nie trzeba więcej nakłaniać do wypróbowania tego narzędzia. Kod programu jest dostępny na stronie projektu w usłudze code.google.com:

https://code.google.com/p/slowhttptest/
Instalacja jest równie przyjemna jak późniejsze używanie programu. W systemie Kali Linux wystarczy pobrać źródła z repozytorium SVN, a następnie przeprowadzić standardową kompilację:
svn checkout http://slowhttptest.googlecode.com/svn/trunk/ slowhttptest-read-only cd slowhttptest-read-only ./configure make make install
Po poprawnej instalacji będziemy mogli uruchomić program w konsoli systemowej. Podczas stress testu możemy m.in.:
Poniżej zostały przedstawione wszystkie dostępne opcje programu (najczęściej używane zostały podświetlone):
slowhttptest -h
slowhttptest, a tool to test for slow HTTP DoS vulnerabilities - version 1.6
Usage: slowhttptest [options ...]
Test modes:
-H slow headers a.k.a. Slowloris (default)
-B slow body a.k.a R-U-Dead-Yet
-R range attack a.k.a Apache killer
-X slow read a.k.a Slow Read
Reporting options:
-g generate statistics with socket state changes (off)
-o file_prefix save statistics output in file.html and file.csv (-g required)
-v level verbosity level 0-4: Fatal, Info, Error, Warning, Debug
General options:
-c connections target number of connections (50)
-i seconds interval between followup data in seconds (10)
-l seconds target test length in seconds (240)
-r rate connections per seconds (50)
-s bytes value of Content-Length header if needed (4096)
-t verb verb to use in request, default to GET for
slow headers and response and to POST for slow body
-u URL absolute URL of target (http://localhost/)
-x bytes max length of each randomized name/value pair of
followup data per tick, e.g. -x 2 generates
X-xx: xx for header or &xx=xx for body, where x
is random character (32)
Probe/Proxy options:
-d host:port all traffic directed through HTTP proxy at host:port (off)
-e host:port probe traffic directed through HTTP proxy at host:port (off)
-p seconds timeout to wait for HTTP response on probe connection,
after which server is considered inaccessible (5)
Range attack specific options:
-a start left boundary of range in range header (5)
-b bytes limit for range header right boundary values (2000)
Slow read specific options:
-k num number of times to repeat same request in the connection. Use to
multiply response size if server supports persistent connections (1)
-n seconds interval between read operations from recv buffer in seconds (1)
-w bytes start of the range advertised window size would be picked from (1)
-y bytes end of the range advertised window size would be picked from (512)
-z bytes bytes to slow read from receive buffer with single read() call (5)
Czas przejść z teorii do praktyki i zobaczyć nowo poznane narzędzie w akcji.
Na potrzeby artykułu przygotowałem osobną architekturę do testów. Aby pokazać realny przykład ataku, zamiast wykonując test na maszynę w sieci lokalnej, całość usług uruchomiłem w chmurze Microsoft Azure.
Powyższe podejście pozwala na zebranie wiarygodnych wyników – podczas symulacji na cel localhost może dojść do sytuacji, że samo narzędzie do testów przeciąży system. Również testowanie serwera w sieci lokalnej nie jest szczególnie interesującym przypadkiem – w sieci lokalnej dane wysyła się kilkukrotnie szybciej, niż do serwerów zdalnych.
Mając powyższe na uwadze, zdecydowałem również, że testy przeprowadzę z poziomu dwóch różnych sieci w Polsce, aby upewnić się, że istnieje możliwość wykonania skutecznych ataków Slow HTTP DoS zarówno na wolnym jak i szybkim łączu.
Przy atakach DoS zawsze istnieje ryzyko, że jakieś urządzenie pośredniczące (np. firewall) zauważy podejrzany ruch i zablokuje agresora. W takim wypadku napastnik faktycznie nie będzie miał dostępu do aplikacji, co może błędnie zinterpretować jako udany atak. W celu dodatkowej weryfikacji, po wykryciu załamania usługi, fakt ten będę weryfikował przy pomocy smartfonu łączącego się ze światem przez sieć LTE (4G). Pozwoli to upewnić się, że atak faktycznie doszedł do skutku.
Warto zaznaczyć, że slowhttptest może używać osobnego proxy do sprawdzania statusu celu, jednak test przez sieć LTE jest w tym wypadku pewniejszy.
Tak jak wspomniałem wyżej, całą infrastrukturę “ofiary” zainstalowałem w usłudze Microsoft Azure. Do testów użyłem następującej konfiguracji:

Na tego rodzaju maszynę wdrożyłem prostą web aplikację ASP MVC 5 (jedną z szablonów Visual Studio 2013), która umożliwiała m.in.:
W infrastrukturze sieciowej nie instalowałem żadnych serwerów proxy, load balancerów, zapór ogniowych, WAFów, IDS/IPSów i podobnego rodzaju usług, ponieważ zaciemniłoby to ideę ataku. O przykładowych metodach ochrony opowiem w ostatniej części tego cyklu.
Do ataku użyłem narzędzia slowhttptest w wersji 1.6, z następującymi przełącznikami:
Czas na konfigurację najważniejszych przełączników sterujących parametrami połączeń. Podczas zestawienia kanału przy użyciu programu nc zauważyłem, że serwer zrywa połączenie po dwóch minutach. Początkowo przyjąłem więc następujące wartości parametrów slowhttptest:
Niestety powyższe wartości okazały się nieskuteczne – po uruchomieniu slowhttptest zauważyłem, że serwer bardzo szybko zamykał połączenia:
slowhttptest version 1.6 - https://code.google.com/p/slowhttptest/ - test type: SLOW BODY number of connections: 1000 URL: http://sek4.cloudapp.net/wa/Account/Login verb: POST Content-Length header value: 4096 follow up data max size: 12 interval between follow up data: 5 seconds connections per seconds: 200 probe connection timeout: 5 seconds test duration: 180 seconds using proxy: no proxy ---------------------------------------------- slow HTTP test status on 45th second: initializing: 0 pending: 182 connected: 12 error: 0 closed: 806 service available: YES
Po kilku próbach udało mi się skonfigurować stabilny, powtarzalny atak odmowy dostępu przy pomocy poniższego polecenia:
slowhttptest -g -o sek4dos -B -c 5000 -x 5 -i 5 -r 200 -l 180 -u http://sek4.cloudapp.net/wa/Account/Login
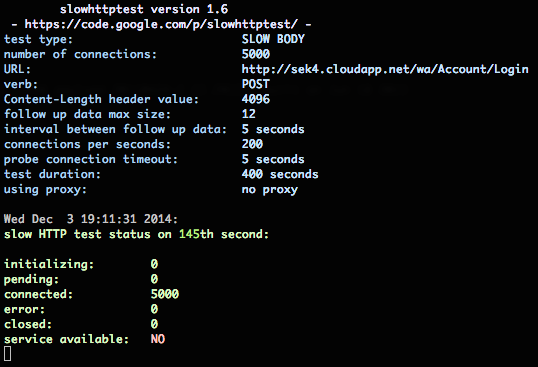
Narzędzie slowhttpheaders w akcji – serwer przestaje odpowiadać!
Narzędzie slowhttptest zwróciło informację service available = NO po upływie niespełna minuty. Od tego momentu web aplikacja wdrożona na serwer sek4.cloudapp.net faktycznie przestała odpowiadać. Serwer stał się ofiarą ataku odmowy dostępu – zasoby dowolnej aplikacji HTTP nie mogły zostać pobrane zarówno przez przeglądarkę atakującego, przeglądarkę w innej sieci oraz przez mobilną wersję łączącej się przez sieć LTE. Pełny sukces.
Dlatego bardzo ważne jest, aby ręcznie weryfikować stan serwera.
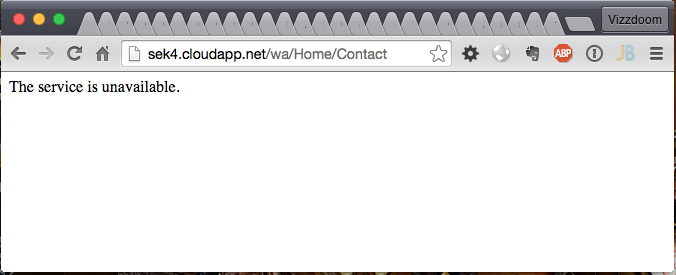
Udany atak Slow HTTP Body na serwer IIS (mimo błędnej informacji o dostępności zwracanej przez slowhttptest).
Przyjrzyjmy się teraz jak wygląda żywotność serwera podczas ataku. Poniższy zrzut pokazuje stan Monitora Zasobów kilkadziesiąt sekund po rozpoczętym ataku:
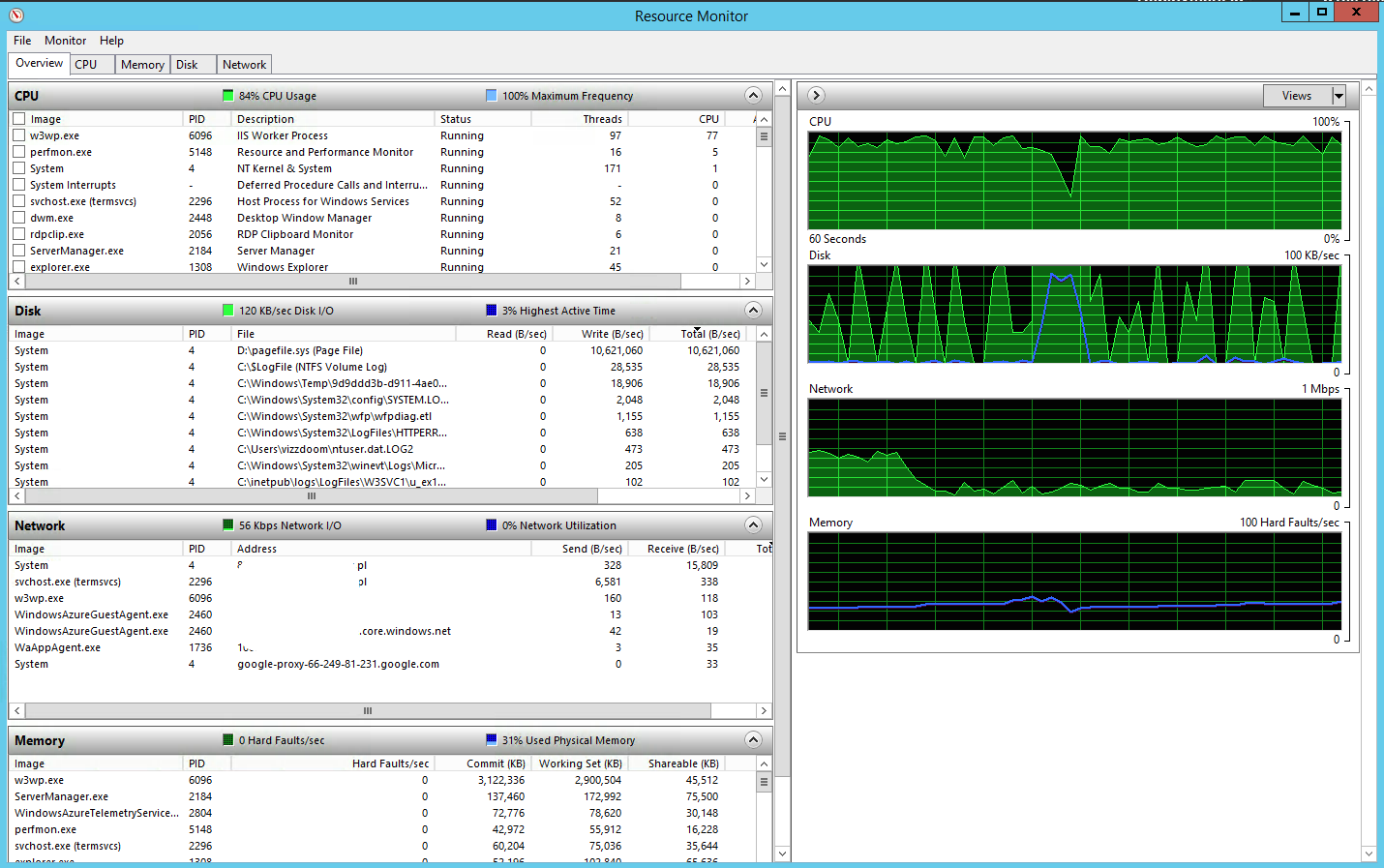
Zajętość zasobów atakowanego systemu podczas ataku.
Na pierwszy rzut oka widać duże zużycie CPU – wszystkie rdzenie są całkowicie obciążone przez niemal sto workerów. Nawet gdyby IIS w normalny sposób zwracał zasoby WWW, sama generacja takiego obciążenia mogłaby być uznana za sukces potencjalnego napastnika.
Na szczęście w odróżnieniu od serwera Apache, zużycie pamięci w czasie ataku na IIS drastycznie się nie zmieniało – cały czas wynosiło ≈ 25-35% z 14GB. Ciekawym faktem jest jednak pojawienie się wielu operacji wejścia–wyjścia dysku twardego, który zaczął zrzucać pamięć do pliku wymiany D:\pagefile.sys (≈10 MB/sec).
Podczas testów oczywiście zwiększył się ruch sieciowy, który był największy na samym początku oraz pod koniec ataku – zestawianie i rozłączanie połączeń generowało ruch na poziomie około 400-600 Kbps. Może to być uznane za anomalię w tego rodzaju symulacjach, jednak taki wolumen w większych systemach jest trudny do zauważenia – w szczególności, że taka sytuacja trwa tylko kilka sekund (a całością można w pewny sposób sterować poprzez flagę -r w slowhttptest). Samo dosyłanie danych nie generowało zauważalnego ruchu – co jest dość intuicyjne.
Tak samo, jak w przypadku ataku Slowloris, tak i tutaj kilka sekund po zakończeniu testów stan serwera aplikacyjnego wrócił do normy.
Czas przyjrzeć się statystykom wygenerowanym przez narzędzie slowhttptest. Po wykonaniu testów w katalogu, w którym został uruchomiony stress test, pojawiły się dwa pliki:
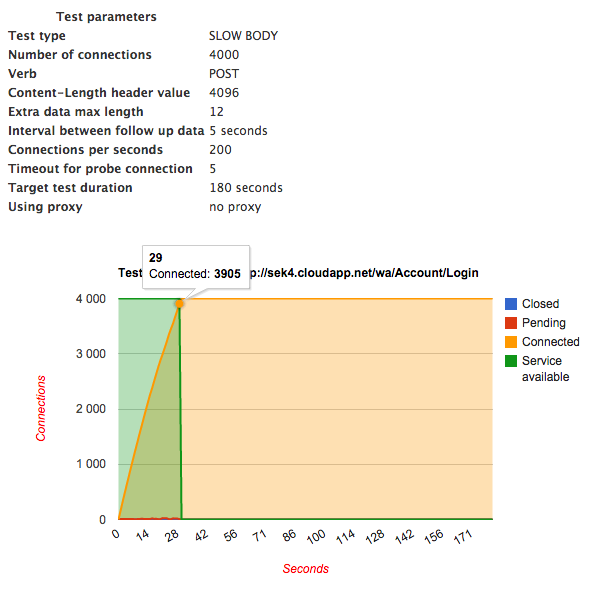
Statystyki slowhttptest (plik sek4dos.html).
Powyższe dwa pliki warto dodać do raportu z testów przeciążeniowych lub penetracyjnych.
Warto też nadmienić, że zmiana miejsca wykonywania ataku w ogóle nie wpłynęła na jego skuteczność – omawiana podatność może być wyeksploatowana z poziomu komputera PC wpiętego do internetu udostępnianego przez standardowego, osiedlowego ISP.
Bez większych problemów udało się unieruchomić usługę hostowaną na dość wydajnej maszynie. Sprawdźmy, czy z poziomu jednego węzła w sieci uda się skutecznie wyłączyć z użycia nawet najpotężniejsze maszyny. Dzięki temu będziemy w stanie odpowiedzieć sobie na pytanie czy wertykalne skalowanie architektury (mocniejsza maszyna zamiast dodatkowego web serwera) uchroni nas przed skutkami omawianego zagrożenia.
Do drugiego testu przygotowałem dużo mocniejszą maszynę – jedną z najwydajniejszych w ofercie Microsoft Azure:
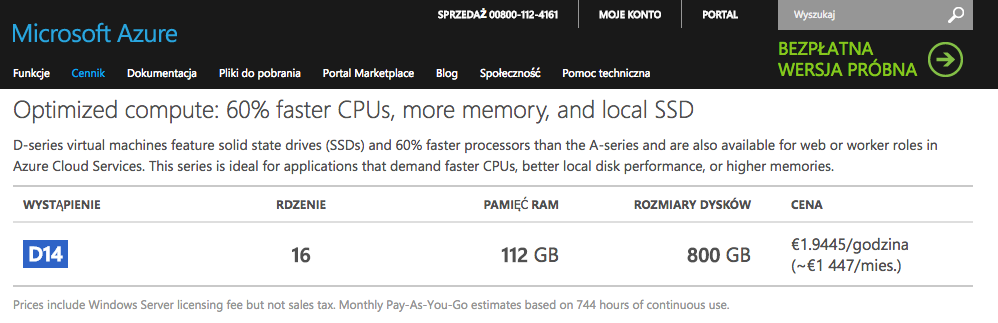
Parametry “grubego zwierza”.
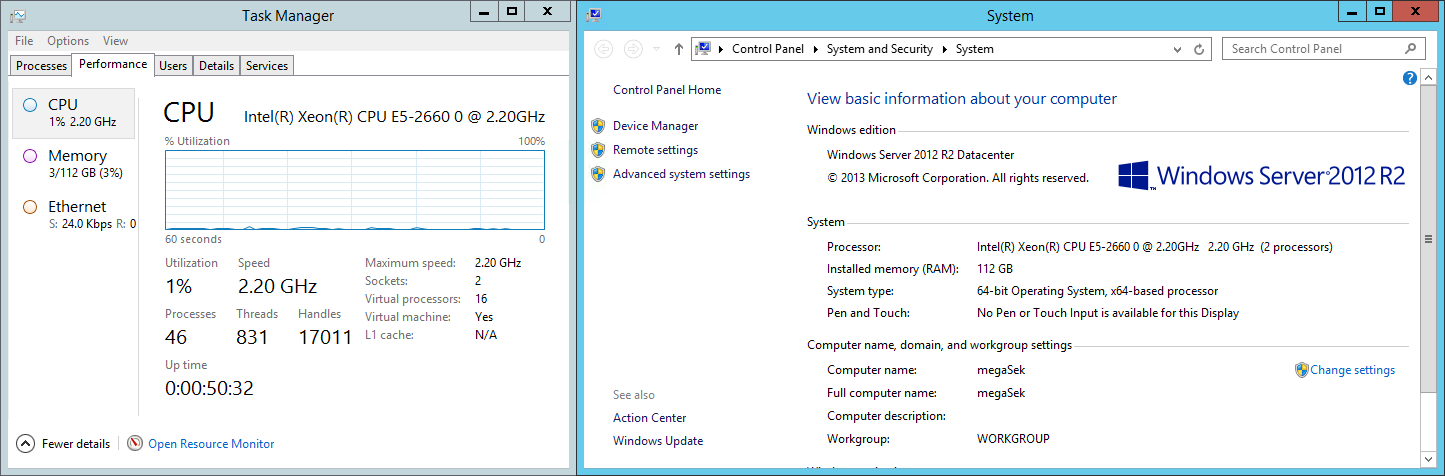
“Gruby zwierz” od środka.
Parametry serwera wyglądają naprawdę imponująco. Aby sprawdzić, czy problem ataku leży po stronie usługi IIS, a nie sprzętu lub systemu operacyjnego, wykonam atak dokładnie z tymi samymi parametrami, co poprzednio na maszynę A4:
slowhttptest -g -o MegaSek4dos -B -c 5000 -x 5 -i 5 -r 200 -l 180 -u http://megaSek.cloudapp.net/wa/Account/Login
Okazuje się, że efekt jest dokładnie taki sam. Mimo tego, że atakowany serwer jest wyposażony w dużo wydajniejszy dysk, posiada wielokrotnie więcej pamięci oraz dużo więcej mocy obliczeniowej – po paru sekundach usługa i tak przestała odbierać połączenia:
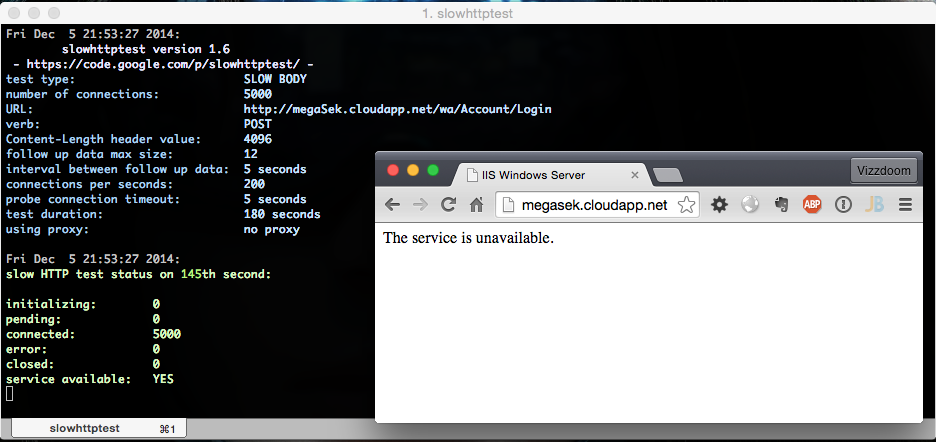

Udało się więc ubić grubego, drogiego zwierza przy pomocy jednego komputera. Przerażające.
Zademonstrowany w tej części atak Slow HTTP Body jest niezwykle spektakularny – przy pomocy jednego węzła w sieci pokazaliśmy jak można całkowicie odciąć klientów od skorzystania z usług nawet potężnego serwera aplikacyjnego. Widać, że zagrożenia z rodziny Slow HTTP nie są błahostką i przy nieskomplikowanej infrastrukturze mogą sprawić ogromne straty.
Aby przestrzec się przed zagrożeniem powolnych ataków HTTP, koniecznie trzeba przeprowadzić testy na swoich serwerach aplikacyjnych – nie tylko IIS. Przy symulacjach bardzo pomocne okazuje się narzędzie SlowHttpHeaders, dzięki któremu szczegółowo przetestujemy nasze mechanizmy obrony przeciwko różnym wariantom Slow HTTP DoS.
Warto zaznaczyć, że opisywane zagrożenie nie dotyczy serwisu Azure, a domyślnie skonfigurowanej usługi webowej ze stajni Microsoftu. Ryzyko może uderzyć zarówno w serwer postawiony w chmurze Microsoftu czy Amazonu, jak i w instancję serwera IIS (lub innego web serwera!) instalowanego na dedykowanej maszynie we własnej serwerowni!
W następnej części artykułu przyjrzymy się jeszcze dwóm innym wariantom ataków Slow HTTP DoS. Cały cykl zamkniemy krótkim podsumowaniem zawierającym kilka wskazówek dotyczących obrony przed zagrożeniami Slow HTTP DoS.
Do zobaczenia w przyszłym roku :-)
– Adrian “Vizzdoom” Michalczyk dla serwisu Sekurak.pl

Artykuł z najwyższej półki, świetna robota Adrian!
Świetny artykuł – choć nie używam IIS, to miło się czytało.
Zawsze się człowiek czegoś nowego nauczy – czekam na więcej! :-)
Apache też padnie – jak nie przez nagłówki, to przez body :)
Tak, czytałem też poprzedni artykuł :-)
Jeśli hostowana usługa używa strumieniowania dla POST-a po weryfikacji nagłówków jest w stanie natychmiast ubić połączenie klienta.
Rzeczowe ale tendencyjne.
Pozdrawiam.
Interesująca lektura :)
to już wiem, czemu vizzdooma średnio z IRCa wywala co 20minut, testował na sobie artykuł ;D
Bardzo fajny artykuł, aż sprawdzę swoje aplikacje, dzięki :)
Kolejną część Adrian już pisze :)
“Obrona poprzez wertykalne skalowanie architektury (zwiększenie mocy kontra dokładanie drugiej maszyny) nie ma żadnego sensu w kontekście ataków Slow HTTP Body na serwer IIS. Skuteczniejsza będzie inwestycja w hardening, przeprowadzenie testów penetracyjnych oraz rozbudowę infrastruktury sieciowej.”
O ile dobrze zinterpretowałem artykuł, wyżej wymieniony fragment brzmi jak: “zatrudnij bezpieczeników do tego, inaczej nic nie zdziałasz”, z czym się nie zgadzam :-)
Każda platforma, dla której udaje się osiągnąć skalowalność może podnosić poprzeczkę atakującemu właśnie zwiększając szeroko pojętą pojemność platformy. WARUNEK: konfiguracja usług (właściwie całego stosu od blach przez system po usługi) będzie wykorzystywała zwiększoną pojemność (lepszy CPU, więcej RAMu, więcej w ogóle maszyn w klastrze, etc.). Zazwyczaj “domyślna konfiguracja” nie korzysta z dobrodziejstw zwiększonej pojemności, stąd Adrian mógł dojść do takiego wniosku jaki wskazałem.
Wykorzystanie pojemności to zadanie zazwyczaj leżące w kompetencjach administratora danej platformy.
Hardening może zawierać elementy optymalizacji konfiguracji pod kątem pojemności platformy, na której pracuje utwardzany element, natomiast to PODSTAWA, która powinna być na bieżąco zarządzana przez administratora – jeśli nie jest to przykłady z artykułu stają się niestety realne i czas zatrudnić bezpiecznika, który pomoże ogarnąć sytuację.
No nie to chciałem przekazać w kontekście skalowania. Z doświadczenia mogę powiedzieć – i to zarówno jako członek devteamu, jak i bezpiecznik – to rozwiązanie tego problemu zawsze zaczyna się od próby wymiany maszyny na lepszą.
No i właśnie – zmiana maszyny na lepszą albo nie daje nic, albo daje mało. I muszę to zawsze tłumaczyć i przepychać kolejno przez: programistów, administratorów, liderów, a później u samego klienta.
Po to dałem ten komentarz o skalowaniu – aby zaoszczędzić Wam (i sobie) czasu. Aby nie robić PoCów, które pokazują, że potwór i tak polegnie – lepiej odwołać się do tego tekstu i powiedzieć, że mocniejsza maszyna to nie rozwiązanie. Rozwiązanie trzeba robić właśnie “od blach” i nie jest to ani tanie, ani szybkie, ani proste.
A szybkie fixy, które małym kosztem zauważalnie zmniejszą ROI atakującego? O tym jeszcze będzie.
Jeśli zmiana na większa nic nie daje to prawdopodobnie za zmianą pojemności nie poszła zmiana konfiguracji, która by tą dodatkową moc potrafiła skonsumować. Ewentualnie zwyczajnie atak jest na tyle duży, że zwiekszona pojemność to jeszcze za mało.
Spróbuj mierzyć bezpieczeństwo: atak i zmierzyć infrastrukturę, wtedy będziesz wiedział czy rozbudowa coś da i o ile trzeba rozbudować by coś dało, do tego dodaj aspekt kosztowy – wyjdzie Ci ROI który można porównywać z innymi rozwiazaniami.
Nie zgadzam się z tym, że to zła droga i niewiele lub nic nie daje – moje doświadczenie w it i itsec mówi, że np. tą drogą można zwiększyć swoje szanse w przypadku (D)DoSa.
Bardzo fajny artykuł, trochę przerażający jak łatwo przy dyspozycji zwykłego PC i dość prostą komendą ubić ważną usługę. Chętnie przeczytam następną cześć, ewentualnie jakieś wskazówki lub rady na temat hardening-u przy omawianej podatności.
Niezłe skupisko takiej wiedzy, której nie za bardzo mogłem znaleźć gdzie indziej. Dzięki wielkie za wpis i czekam na następne z tej serii.
Jakąś alternatywą przy IIS może być Dynamic IP restriction i strona napisana tak, że przyjmuje jedno zapytanie na raz z danego IP, resztę odrzuca. Ale to tqk jak pisze, jakaś alternatywa.
przydałaby się aktualizacja linku do slowhttptest, tak dla potomnych ^^
https://github.com/shekyan/slowhttptest
i może jeszcze jakiś mały tutek w jaki sposób korygować parametry żeby wycisnąć maxa
Właśnie, mi też zabrakło tego wyjaśnienia.
I jak? Kolejna część nigdy nie powstała?