NIS2/KSC2 starter pack. Czy Twoja firma podlega pod regulację i co z tego wynika? Bezpłatne szkolenie od sekuraka
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
NIS2/KSC2 starter pack. Czy Twoja firma podlega pod regulację i co z tego wynika? Bezpłatne szkolenie od sekuraka
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

Z tekstu dowiesz się:
Włamania do serwisów, nawet tych największych, już tak nie szokują. Co jakiś czas w Internecie publikowane są bazy danych – a to Sony albo Blizzard. Czasem hasła użytkowników można sobie po prostu pobrać, nawet z tak elitarnej instytucji jak IEEE.
Nie od dzisiaj wiadomo, że najsłabszym ogniwem systemu teleinformatycznego jest człowiek – a w zasadzie jego ufność bądź lenistwo. Najczęściej te czynniki wpływają na politykę haseł, a ta niedbałość bezpośrednio przekłada się na liczbę artykułów opisujących włamania do serwisów internetowych, wraz z załącznikami do baz danych użytkowników.
Artykuł ten jest przeglądem tematyki związanej z bezpieczeństwem haseł – można go traktować jako kompendium. Poruszony zostanie bardzo szeroki wachlarz zagadnień, które mają wpływ na bezpieczeństwo procesu uwierzytelniania – czy to w sposób pośredni czy bezpośredni.
Na początku zostanie omówiona sama idea kontroli dostępu. Następnie metody hashowania haseł, ataków na nie oraz techniki zwiększające skuteczność mechanizmów zarządzających hasłami. Przyjrzymy się również, jak takie mechanizmy są implementowane w najpopularniejszych systemach.
Następnie zostaną przedstawione metody przeprowadzania ataków na hasła i narzędzia wykorzystywane w atakach. Osobny rozdział poruszy tematykę tworzenia słowników, dzięki którym będziemy mogli odzyskać dużą część haseł ze swoich systemów. W ostatnim rozdziale znajdą się porady dla programistów, pentesterów, crackerów oraz dla zwykłych użytkowników.
Dzisiaj trudno wyobrazić sobie czasy komputerów takich jak IBM PC czy Apple 2, w których nie stosowano procedur logowania. Jesteśmy przyzwyczajenie do kontroli dostępu, a nawet jej wymagamy. Kontrola jest dla nas po prostu czymś naturalnym, gdy jej brakuje – czujemy się nieswojo. Nie chcemy, aby osoby trzecie miały dostęp do naszych zasobów.
Ogólnie rzecz ujmując, kontrola dostępu w dowolnym systemie przebiega trójstopniowo:
Jako, że identyfikacja i uwierzytelnianie idą ze sobą w parze, czasem dla wygody łączy się te dwie fazy w jeden proces logowania.
Uwierzytelnianie jest krytycznym elementem kontroli dostępu do zasobów – musimy umożliwić użytkownikowi przekazanie informacji, która należy tylko do niego. Właśnie te informacje są kluczowym ogniwem całego procesu.
Informacją uwierzytelniającą jest:
Pojedyncze uwierzytelnianie polega na weryfikacji jednej informacji, należącej do którejkolwiek z powyższych grup. Wielokrotne uwierzytelnianie weryfikuje dane z różnych grup (np. hasło statyczne + telefon).
Przyjrzyjmy się teraz popularnym metodom uwierzytelniania.
Hasłem statycznym jest ciąg znaków, który jest znany tylko osobie, która będzie go używać w procesie uwierzytelniania.
Jest to najpopularniejsza forma uwierzytelniania, ze względu na niskie koszty wdrożenia, łatwość użycia oraz powszechność stosowania. Możemy się z nią spotkać na stronach internetowych czy chociażby podczas włączania telefonu komórkowego (kod PIN). Wdrożenie tej metody wymaga przechowywania hasła użytkownika w bazie danych. Jest to bardzo tania metoda, ponieważ w najgorszym przypadku kosztem jest zakup klawiatury czy PINPadu.
Dużym problemem haseł statycznych jest to, że użytkownicy muszą je wymyślać i zapamiętywać. Z uwagi na fakt, że są to informacje trudne do zapamiętania, często są one zapisywane (na kartkach zostawianych na biurku), a to umożliwia ich łatwą kradzież.
Wadą hasła statycznego jest też to, że jest nim stosunkowo krótki i charakterystyczny ciąg danych. Łatwo można go przekopiować (np. ze wspomnianej już kartki na biurku) lub zauważyć podczas podsłuchiwania nieszyfrowanego ruchu sieciowego.
Warto też zauważyć, że hasło statyczne jest dowolnym ciągiem wymyślanym przez użytkownika. W bezpiecznym haśle statycznym powinna występować jak najmniejsza korelacja z użytkownikiem. Niestety, gdy hasło zostanie wykradzione, a następnie zmienione przez cyberprzestępcę, wtedy nie tylko tracimy dostęp do usługi, ale również będziemy mieli sporo problemów z jego odzyskaniem (czyli z udowodnieniem, że jesteśmy właścicielem konta).
Trudno wymusić na użytkowniku sposób, w jaki powinien przechowywać hasła. Częściowo można wpływać na bezpieczeństwo wymyślanych haseł poprzez wymuszenie okresowych zmian, ale taka polityka tylko rozjusza użytkowników, nieznacznie zwiększając ich bezpieczeństwo.
Problem ten może być rozwiązany przez metodę haseł jednorazowych, w której użytkownicy dostają wygenerowaną listę haseł, tracących ważność od razu po wykorzystaniu.
Główną zaletą tej techniki jest to, że posiadamy całkowitą kontrolę nad złożonością generowanych haseł. W dodatku użytkownicy podświadomie dużo chętniej zabezpieczają fizyczny przedmiot (listę haseł) niż sentencję do zapamiętania (którą i tak często zapisują). Hasła jednorazowe chronią również w pewien sposób przed przejęciem konta, gdyż cyberprzestępca nie ma możliwości zmiany hasła.
Oczywiście najsłabszym ogniwem tej metody jest lista haseł, która może zostać po prostu wykradziona lub skopiowana, ale na szczęście jest to mało prawdopodobne. W dodatku kradzież taką można łatwo zauważyć – poszkodowany użytkownik nie będzie w stanie zalogować się do systemu i poprosi administrację o ponowną generację haseł, dzięki czemu wykradzione hasła staną się bezużyteczne.
Metoda uwierzytelniania przy pomocy haseł jednorazowych jest bardzo bezpieczną techniką, która w znaczny sposób przeszkadza crackerom. Nawet w momencie wykradzenia listy haseł, agresor będzie mógł korzystać z konta przez krótki czas.
Generowanie haseł jednorazowych może być zrealizowane przez wylosowanie listy haseł i przesłanie ich użytkownikom. Jest to poprawne rozwiązanie, jednak bezpieczniejszym i lepiej skalującym się rozwiązaniem jest generowanie haseł algorytmem Lamporta.
Metoda Lamporta, zwana również *jednokierunkowym łańcuchem skrótu (ang. one-way hash chain) wykorzystuje funkcje jednokierunkowe h(x) = y. Zwracają one wynik y w taki sposób, że na jego podstawie nie jesteśmy w stanie poznać danych wejściowych x. Funkcje jednokierunkowe zostaną opisane dokładnie w rozdziale “Hashowanie haseł”.
Algorytm generowania haseł jednorazowych metodą jednokierunkowego łańcuchu skrótu jest następujący:
secret.n>0.n > 0
n-krotne użycie funkcji jednokierunkowej: p=h(h(…(h(secret)))),n==0), przejdź do 1.Funkcja jednokierunkowa sprawia, że nie jesteśmy w stanie poznać kolejnego (n-1) hasła, a użyte już hasło (n+1) staje się bezużyteczne.
Kolejna metoda uwierzytelniania polega na przedstawieniu przedmiotu należącego do identyfikującej się osoby. Przedmiotem tym może być np. karta magnetyczna lub inteligentna.
Karta magnetyczna to w praktyce mała przestrzeń dla dowolnych danych – na taśmie można zapisać około 140 bajtów. W większości wypadków na pasku zapisywany jest login lub para login-hasło. Niekiedy dla zwiększenia bezpieczeństwa firmy wydające karty szyfrują hasło prywatnym kluczem.
Większym bezpieczeństwem cechują się karty inteligentne (smart card). Są one wyposażone w procesor, pamięć ROM oraz EEPROM. Ten typ kart jest niezwykle uniwersalny, ponieważ karty te są tak na prawdę prostymi komputerami, które możemy programować (np w Basic, Java lub .NET). Dzięki temu mamy dostęp do wielu metod uwierzytelniania, takich jak chociażby schemat wyzwanie-odpowiedź (ang. challenge-response) i wiele więcej .
Ostatnia opisywana metoda opiera się na tym, czym jest uwierzytelniający się obiekt.
Ludzkie ciało cechuje się kilkoma właściwościami, które są prawie całkowicie niepowtarzalne. Użycie takich cech w procesie uwierzytelniania nazywamy właśnie techniką biometrycznej weryfikacji tożsamości.
Prostą i zaskakująco skuteczną techniką biometryczną jest metoda badana długości palców człowieka. Jednak mimo dobrych właściwości identyfikujących, urządzenia skanujące mogą być łatwo oszukane poprzez podstawienie odlewu dłoni zrobionej w gipsie. Przez to metoda staje się problematyczna, gdyż wymaga również badania temperatury dłoni oraz jej układu krwionośnego – a to znacząco zwiększa koszt urządzeń.
Obecnie najczęściej wykorzystywane techniki biometryczne polegają na porównywaniu linii papilarnych, twarzy lub tęczówki oka. W momencie rejestracji użytkownikowi robione jest zdjęcie palca lub twarzy, które jest zapamiętywane. Podczas logowania użytkownikowi robione jest kolejne zdjęcie. Między dwoma obrazami obliczana jest odległość Levenshteina i jeśli wynik mieści się w odpowiednim zakresie, wtedy proces logowania kończy się sukcesem.
Dobranie odpowiedniego progu akceptacji nie jest łatwe. Przy pomocy tego współczynnika powinniśmy nie tylko jednoznacznie zidentyfikować osobę, ale również poradzić sobie z takimi niedogodnościami jak zmiana tła lub cechy w czasie (inna pora dnia na zdjęciu, oświetlenie, starzenie się użytkownika, zmiana zarostu lub okularów).
Techniki porównywania zdjęcia obarczone są dużym ryzykiem fałszerstwa. Proces uwierzytelnienia można łatwo oszukać przez podstawienie fotografii wskazanej osoby. Problemy takie rozwiązuje się np. przez zastosowanie flaszy i badaniu reakcji źrenicy lub przy pomocy algorytmów wizji komputerowej, ale takie metody mocno podnoszą koszt wdrożeń.
Mimo dużej liczby algorytmów większość mechanizmów uwierzytelniających wykorzystuje technikę haseł statycznych. Dlaczego wybierana jest metoda, która posiada tak wiele złych cech?
Popularność uwierzytelniania przy pomocy haseł statycznych spowodowana jest trzema czynnikami:
Mimo tego że hasła statyczne to tylko ciągi znaków, forma ich przechowywania ma istotny wpływ na bezpieczeństwo całego systemu.
Hasło w formie jawnej (ang. Plaintext) przechowywane jest w bazie danych jako ciąg bezpośrednio wpisywany przez użytkownika. To bardzo niebezpieczne podejście – podczas udanego ataku agresor poznaje hasła wszystkich użytkowników, włącznie z hasłami administracji. Dzięki tym danym, atakujący może używać kont o wyższych uprawnieniach lub nawet przejmować konta w innych systemach.
Narzucającym się sposobem ochrony przed taką sytuacją jest szyfrowanie haseł. Dzięki temu użytkownicy będą mogli w niezmienionej formie używać swoich danych uwierzytelniających, a baza danych będzie przechowywać je w nieczytelnej dla agresora postaci.
Niestety szyfrowanie haseł nie jest bezpiecznym rozwiązaniem. Należy bowiem założyć, że atakujący, posiadając dostęp do bazy danych, może również wykraść z systemu klucze szyfrujące. Szyfrowanie powinno służyć wyłącznie, jako pewna forma ochrony wrażliwych danych osobowych, takich jak historia chorób, ubezpieczenia i podobnych.
Hashowanie haseł polega na przechowywaniu wartości bezpiecznej funkcji hashującej, której na wejściu podajemy hasło wpisane przez użytkownika.
Ważne jest, aby odróżniać funkcje hashujące (używane w algorytmice) od bezpiecznych funkcji hashujących (używanych w kryptografii).
Funkcja hashująca (mieszająca) jest używana w budowie tablic hashujących – popularnych struktur danych w algorytmice. Celem funkcji hashującej jest wygenerowanie pewnego skrótu z dowolnie dużej wiadomości.
1 /** Przykład klasycznej funkcji hashującej **/
2 function classicHash(x) { 3 return x.length %
3;
4 }
5
6 classicHash("Securitum"); //0
7 classicHash("Vizzdoom"); //2
8 classicHash("Ala ma kota"); //2
9
Jak widać funkcja hashująca nie musi być niczym skomplikowanym. W powyższym przykładzie, z dowolnie długiej wiadomości funkcja zwraca wartości od 0 do 2. Oczywiście classicHash(x) w żaden sposób nie może zostać użyty, jako część mechanizmu składowania haseł, ponieważ hasło vizzdoom mogłoby być użyte do logowania na konto użytkownika używającego hasła Ala ma kota.
Problem ten rozwiązują bezpieczne funkcje hashujące (funkcje skrótu kryptograficznego), których wynik potocznie nazywany jest hashem.
Bezpieczne funkcje hashujące h(x) = hash są funkcjami hashującymi z następującymi właściwościami:
hash) nie możemy w żaden sposób określić wejścia (x).hash) przy użyciu dwóch różnych wejść (x1, x2).hash1, hash2) wygenerowanych przez bardzo podobne wejścia (x1, x2).W kontekście bezpieczeństwa haseł, jednokierunkowość zapewnia, że nie można wyliczyć (poznać) oryginału hasła podanego przez użytkownika, gdy jest się w posiadaniu wyłącznie jego skrótu.
Wysoka odporność na kolizje rozwiązuje problem logowania się na cudze konto z wykorzystaniem innego hasła.
Duża zmienność hashy sprawia, że atakujący nie jest w stanie określić natury oryginału hasła – jego długości, użytych znaków czy nawet podobieństwa do innego oryginału.
Wszystkie powyższe właściwości znacząco zwiększają bezpieczeństwo, a ich stosowanie jest przezroczyste dla użytkowników.
Niemniej, hashowanie haseł nie rozwiązuje wszystkich problemów bezpieczeństwa haseł statycznych. Każda funkcja skrótu kryptograficznego posiada pewne ryzyko kolizji. Zawsze też istnieje możliwość zindeksowania par hasło-hash, by przy ich pomocy odzyskiwać oryginały haseł. Przed atakami na hashe haseł można bronić się, starając się jak najbardziej wydłużyć proces wyliczania par hasło-hash dla użytej funkcji skrótu.
Jedną z takich metod jest metoda solenia haseł.
Bezpieczna funkcja hashująca na wejściu przyjmuje wiadomość o dowolnym rozmiarze. Atakujący może stworzyć prosty słownik hasło-hash i własnoręcznie go uzupełnić o popularne wyrazy i ich hashe. W momencie wykradzenia haseł w postaci hashowanej wystarczy, że porówna je z hashami ze swojego słownika. Znalezione przypasowania będą oryginalnymi hasłami, które były wprowadzane przez użytkowników.
Sam proces tworzenia takiego słownika jest prosty, jednak wymaga bardzo dużych nakładów pamięciowych i obliczeniowych. Jednak gdy oryginał hasła jest wyrazem krótkim lub nieskomplikowanym, wtedy szybko znajdzie się w słowniku agresora, zapewniając mu udany atak.
Rozwiązanie problemu odzyskiwania hashy nieskomplikowanych haseł zostało opracowane już w 1979 roku. Metoda zaproponowana przez badaczy Morrisa oraz Thompsona, polega na dodaniu do każdego hasła losowej, n-bitowej wiadomości (tzw. soli). Sól jest dodawana do każdego hasła wpisywanego przez użytkownika i dopiero całość jest przekazywana do funkcji skrótu. Dzięki temu, nawet proste hasła takie jak 12345 w rzeczywistości są przechowywane jako wynik bezpiecznej funkcji hashującej h("12345pk&Dsx8Gd_1shFd4") (sól 16 bajtowa). Tworzący słownik atakujący stoi przed wielokrotnie trudniejszym zadaniem, które nawet przy krótkich solach może stać się niewykonalne ze względu na niezmiernie długi czas obliczeń.
Ataki na hasła dzieli się na dwie grupy – ataki offline oraz online.
Ataki online to stosunkowo proste techniki polegające na wysyłaniu żądań do usług systemu. Żądania te zawierają tysiące danych uwierzytelniających. Mimo swojej prostoty ataki online okazują się zaskakująco efektywne, w szczególności w systemach, które udostępniają wiele usług.
Z kolei ataki offline przeprowadzane są już po przełamaniu pewnych zabezpieczeń, gdy hashe haseł trafią do rąk agresorów. Ataki offline na hashe haseł są atakami kryptograficznymi, w których agresor stara się odnaleźć oryginał hasła.
Możemy wyróżnić następujące grupy ataków kryptograficznych (offline) na hasła: ataki siłowe (bruteforce), ataki słownikowe (dictionary), atak tęczowych tablic (rainbow tables) oraz ataki hybrydowe.
To najpopularniejsza forma ataku, która polega na generowaniu wszystkich kombinacji znaków w pewnym ustalonym zakresie. Z generowanych ciągów obliczany jest hash, który jest porównywany z hashem wykradzionego hasła. Jeżeli dwa hashe się zgadzają, wtedy albo udaje się odgadnąć oryginał hasła, albo znaleźć kolizję w funkcji hashującej.
Atak Bruteforce jest atakiem wyczerpującym. Przy odpowiednio długim czasie (lub dużych zasobach) możemy odzyskać oryginał hasła dowolnej długości. Ważne jest, żeby tak skonfigurować mechanizmy bezpieczeństwa haseł, by atak tego rodzaju trwał bardzo długo (np. kilka tysięcy lat), przez co stanie się całkowicie nieprzydatny.
Najlepszą obroną przeciwko atakom siłowym jest użycie techniki key stretching oraz soli dynamicznych.
Liczba ciągów generowanych w ataku Bruteforce jest ogromna, ponieważ sprawdzane są wszystkie kombinacje w danym zakresie. W związku z tym, w rozsądnym czasie nie jesteśmy w stanie przetestować długich haseł (np. dłuższych od 10 znaków).
Metoda słownikowa polega na generowaniu hashy tylko z najczęściej występujących ciągów haseł, takich jak imiona, daty urodzin, kluby piłkarskie i wiele innych. Z pomocą kilkugigabajtowych słowników takich ciągów jesteśmy w stanie złamać ponad połowę hashy w czasie poniżej doby.
Solenie haseł jedynie nieznacznie zmniejsza skuteczność tej metody. Oprócz skomplikowanych haseł, technika key stretching jest skuteczną obroną przeciwko atakom słownikowym.
Aby w ataku bruteforce za każdym razem nie generować wszystkich hashy haseł, można je po prostu zapamiętać w ogromnym słowniku hash-hasło. Przy następnym ataku wystarczy odszukać w nim indeks odpowiadający wykradzionemu hashowi.
Niestety, słowniki takie nawet dla krótkich haseł (<8 znakowych) zajmują bardzo dużo pamięci masowej, często przekraczając pojemność typowych dysków twardych. Dodatkową przeszkodą jest trudność przeszukiwania tak wielkich źródeł danych. To wszystko powoduje, że nie tworzy się tego rodzaju słowników.
Tęczowa tablica to ogromny zbiór odpowiednio zindeksowanych danych, które zawierają informacje o parze hash-hasło. Tęczowe tablice są dużo mniejsze niż słowniki wszystkich kombinacji hash-hasło, jednak czas ich generacji jest dużo dłuższy.
Atak przy użyciu Rainbow Tables może w kilkanaście minut znaleźć hasła o średniej długości (nawet do 12 znaków) ze skutecznością powyżej 95%. RT to dalej duże zbiory danych, ale już takie, które mogą pomieścić typowe dyski twarde (5-500 GB, w zależności od skuteczności i długości łamanego hasła).
Tęczowe tablice można ściągnąć poprzez torrent ([1] , [2] , [3]), kupić lub własnoręcznie wygenerować (programem rtgen dodawanym do Cain&Abel).
Przeciwko atakom Rainbow Tables chronią już kilkubajtowe sole i nawet najprostszy key stretching.
Ataki hybrydowe wykorzystają niezawodność metody Bruteforce oraz skuteczności metody słownikowej. Reguły ataku modyfikują ciągi w słowniku, dodając przykładowo do każdego kandydata cyfry 00-99. Generacja reguł jest sztuką wymagającą skomplikowanej analizy charakteru haseł wymyślanych przez użytkowników.
Ataki hybrydowe są atakami najskuteczniejszymi ze wszystkich tutaj opisanych.
Obrona przeciwko nim jest analogiczna jak w przypadku ataków słownikowych – należy użyć key stretchingu, ponieważ stosowanie soli tylko nieznacznie zmniejsza skuteczność ataku.
Z poprzednich rozdziałów dowiedzieliśmy się, jak przechowywać hasła oraz w jaki sposób przeprowadzać ataki na mechanizmy zabezpieczające hasła. W tym rozdziale skupimy się na czynnikach, które wpływają na czas i skuteczność ataku.
Długość hasła oraz różnorodność użytych znaków bezpośrednio wpływa na jego bezpieczeństwo. Im więcej znaków zostanie użytych w haśle, tym więcej prób będzie musiał podjąć atakujący podczas ataku siłowego.
Pesymistyczna liczba prób, którą musi podjąć atakujący zależy od długości hasła oraz mocy zbioru znaków. Wyraża się to wzorem: PESYMISTIC_PASS = SPACE_LENGTH PASS_LENGTH.
Popularne przestrzenie znaków badane przez crackerów prezentuje poniższy obrazek:

Wykres poniżej pokazuje, jak mocno zwiększa się złożoność hasła, w zależności od użytych znaków.
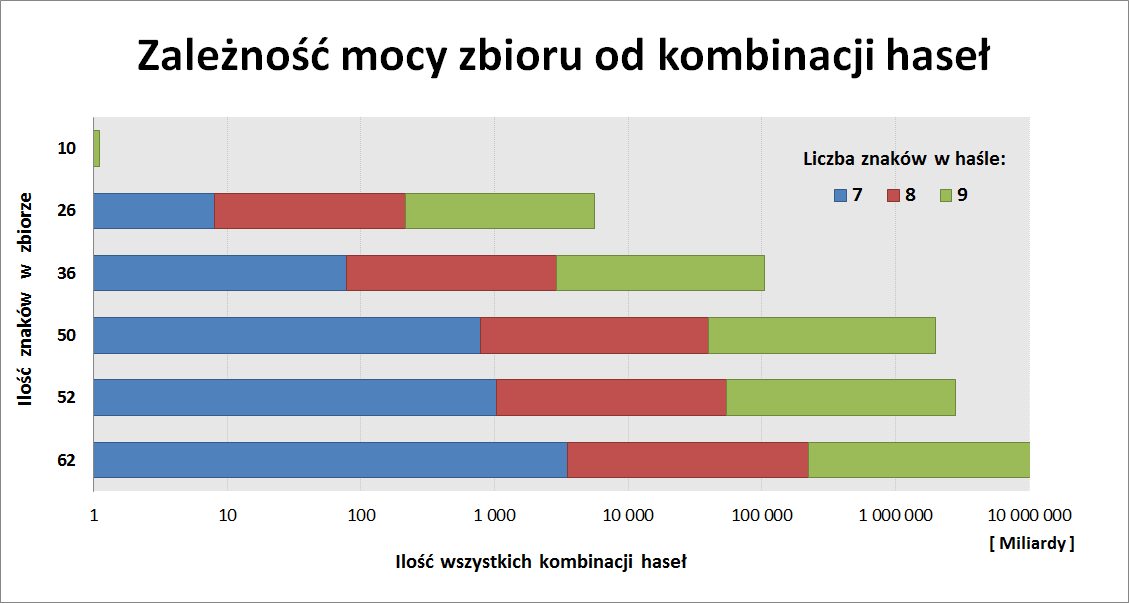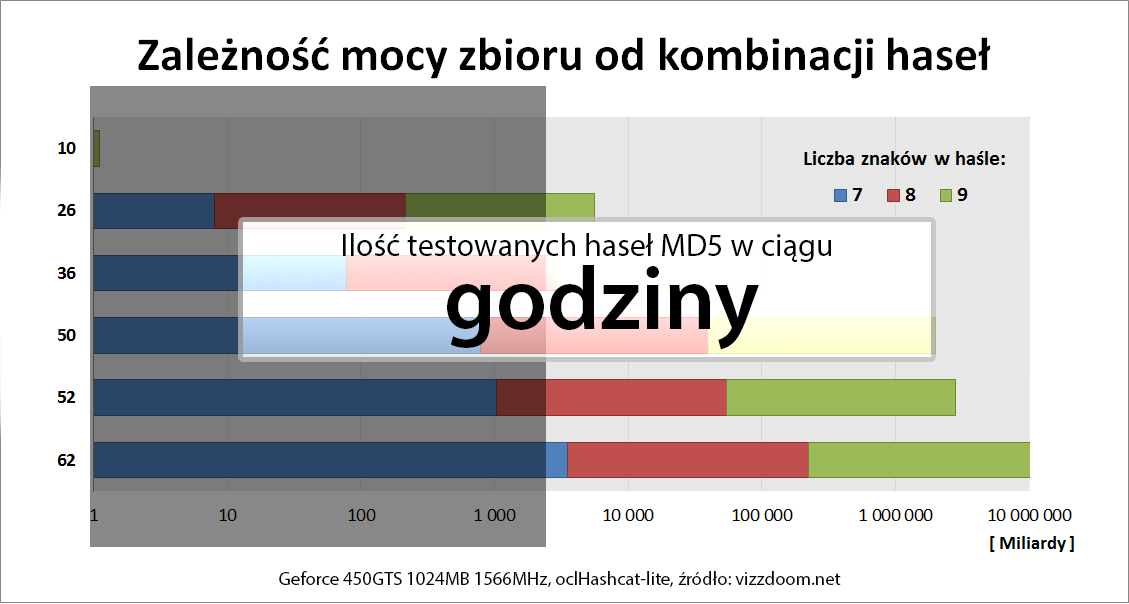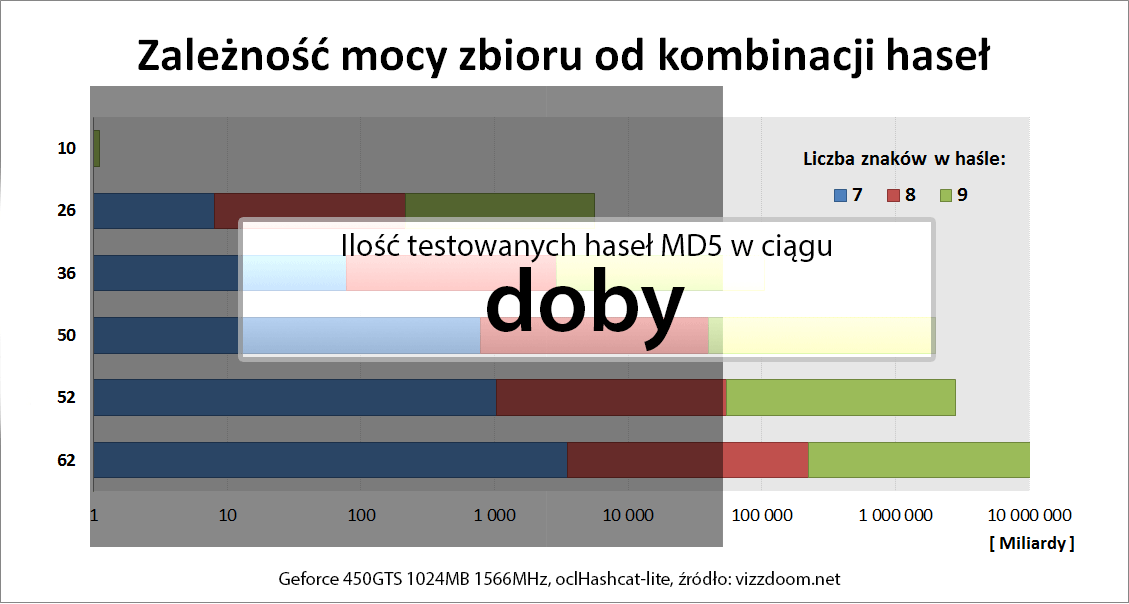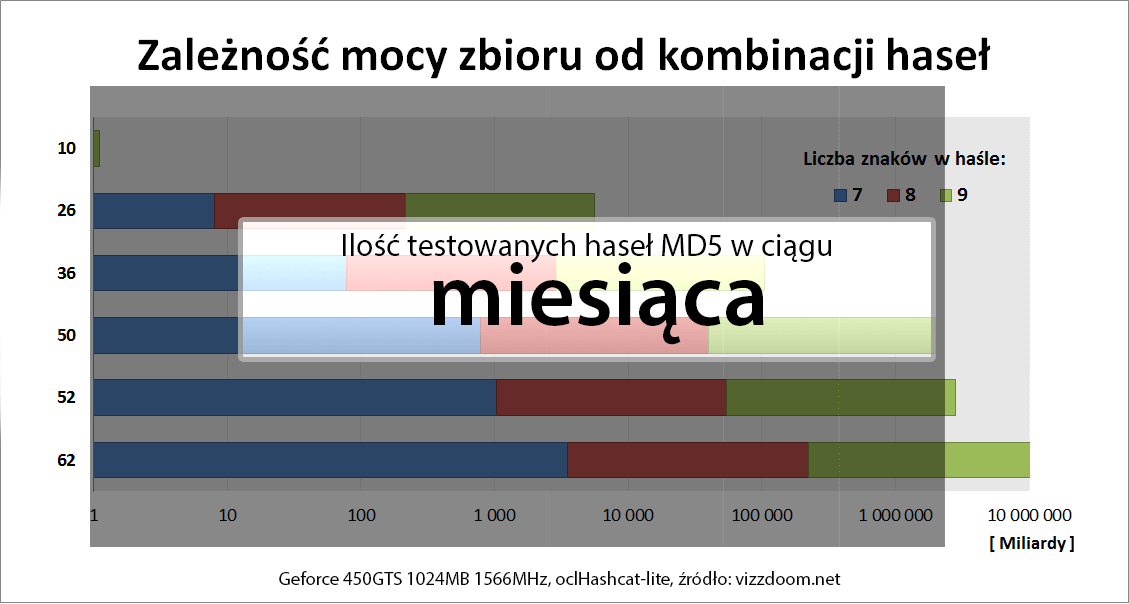
Długie hasła nie muszą chronić przeciwko atakom słownikowym czy hybrydowym – słowo K0nstantynopolitanczykowianeczka12 czy Hottentottenstottertrottelmutterbeutelrattenlattengitterkofferattentater z pewnością znajdzie się w wielu słownikach.
Algorytmika jest sztuką znajdywania wydajnych rozwiązań. Niestety szybka implementacja funkcji hashujących staje się problemem z punktu widzenia bezpieczeństwa, ponieważ pozwala to na wykonanie większej liczby sprawdzeń przez atakującego, bezpośrednio skracając czas (dowolnego rodzaju) ataków.
Oprogramowanie tworzone jest po to, aby używać go przez długi czas – systemy i aplikacje mają działać przez wiele lat. Wzrost mocy komputerowej w tym okresie ma duże znaczenie dla bezpieczeństwa haseł. Zgodnie z prawem Moore’a w okresie ośmiu lat moc obliczeniowa wzrośnie szesnastokrotnie (2**4) razy. Czy używany mechanizm przechowywania haseł, za kilka lat dalej skutecznie będzie chronił użytkowników?
W praktyce szybkość łamania haseł statycznych wzrasta jeszcze szybciej. Jeszcze kilka lat temu hasła były łamane wyłącznie przy użyciu mocy obliczeniowej procesorów. Dzisiaj wykorzystuje się moc drzemiącą w kartach graficznych – dają one nawet tysiąckrotny wzrost wydajności. A gdzieś tam w oddali słychać echa komputera kwantowego, który wywróci świat kryptografii do góry nogami.
Bezpieczeństwo haseł wymaga myśli wyprzedzającej ówczesną technologię. Wybór technik przechowywania haseł powinien uwzględniać łatwość adaptacji do nowych rozwiązań technicznych.
W tym rozdziale skupimy się na algorytmach realizujących zadania stawiane funkcjom skrótu. Dowiemy się, jakich algorytmów powinno się używać dzisiaj i czy na pewno wszystkie z nich są bezpieczne.
Oto wyniki funkcji opisywanych w tym rozdziale:
md5("vizzdoom") = 96daa74aac66d0fa51c9dd6d2dacc37a
sha1("vizzdoom") = bfc4231d98b642f656b0c36200e7ba1371a07890
sha224("vizzdoom") = b7d8cf74e7a25940f474182e8adfffde027d78a68976578a8335c48d
sha256("vizzdoom") = ea548b8f9e63f1d9aa59792853a26cbc87720cd387203a1da728bdf812f92443
sha384("vizzdoom") = eb985a4e06d7fff456d8731c90c41676a60413bdf252a3be149582f8d946e388067110bd26085880fba1b77d26341540
sha512("vizzdoom") = 44285420e6ace09f4b25779e2be5d17076ce7cb6637ea89cfcb8a8bfeeb6d8e4cd247004679ec2bf005395f3230c5562364b7da937883f0c1f63c529b5353bd7
bcrypt("vizzdoom",bcrypt.gensalt(12))
'$2a$12$ECkVAZC8c3FcL9xWNiQ4l.cl72O5et0PCxhKfR6gGX7Hb7ROTbVBy'
pbkdf2("vizzdoom"," Twpov3pia",4000,32) = d58a5a64b4dfd1a2f56d72ee032ba97837ca77f31f0f0c21fd767194bdad439e
scrypt("vizzdoom") = [dane binarne]
Współcześnie najczęściej stosowaną funkcją skrótu jest MD5. Generuje ona stały, 128 bitowy wynik, zazwyczaj zapisywany jako ciąg 32 znaków reprezentujących zapis szesnastkowy.
Mimo popularności MD5 nie jest już uważane za funkcję w pełni bezpieczną – opracowano wiele technik znajdujących kolizję tej funkcji. Jedną z nich jest metoda MD5 Tunneling znajdująca kolizję w czasie poniżej 10 sekund, wykorzystując do tego moc laptopa przeciętnej klasy.
Odkrycia tego rodzaju oczywiście są ciekawe, ale w praktyce nie wpływają znacznie na bezpieczeństwo hashy MD5. Większość technik znajdywania kolizji podaje na wejściu MD5 dane binarne, a więc dane ze zdecydowanie szerszego zakresu niż znaki ASCII.
Chociaż dzisiaj nie istnieją efektywne metody znajdujące kolizje w hashach MD5 haseł, odradza się stosowanie tej funkcji. Istnieją realne przesłanki wskazujące, że sytuacja ta zmieni się w najbliższych latach.
Więcej informacji o funkcji MD5 można znaleźć w wikipedii oraz w dokumencie RFC1321. Programy wraz z wyjaśnieniem techniki MD5 Tunneling można znaleźć w tym miejscu. Sam przykład kolizji w MD5 wraz z wizualizacją stanów wewnętrznych bloków algorytmu można zobaczyć tutaj.
SHA0 było pierwszą funkcją należącą do rodziny Secure Hash Alghoritm. W tym momencie SHA0 podziela los MD4 – w obu tych funkcjach znaleziono kolizje pozwalające w krótkim czasie odzyskać oryginał hasła lub jego odpowiednik.
SHA1 jest obecnie największym konkurentem MD5. Istnieje kilka ataków teoretycznych na tę funkcję, jednak w praktyce nie zagrażają one jeszcze bezpieczeństwu hashy. Jednak tego rodzaju sytuacje sugerują, że warto zainteresować się nowszą wersją algorytmu.
SHA2 jest w tej chwili jedną z najbezpieczniejszych wersji algorytmów rodziny SHA. SHA2 istnieje w czterech odmianach: SHA-224, SHA-256, SHA-384 oraz SHA-512. Wszystkie warianty działają w podobny sposób, jednak używają struktur danych o różnej wielkości oraz zwracają hash różnej długości.
SHA2 zapewnia wysoki poziom bezpieczeństwa. Niestety funkcje z tej grupy nie są często stosowane, ponieważ ich użycie często wymaga kompilacji dodatkowych modułów (np. do baz danych). Dodatkowym powodem było też oczekiwanie na finalną wersję algorytmu SHA3.
2 października 2012 roku przedstawiono algorytm SHA3, który używa nowego podejścia – więc teoretycznie ataki na wcześniejsze wersje SHA nie powinny wpływać na jego bezpieczeństwo. Niestety – dalej jest to algorytm bardzo szybki.
Różnice między algorytmami z rodziny SHA przedstawia poniższa tabela:

BCrypt jest pierwszą opisywaną tutaj funkcją skrótu kryptograficznego, która została stworzona specjalnie z myślą hashowania haseł statycznych, a nie dowolnych danych binarnych.
BCrypt wyróżnia się na tle wcześniej opisywanych algorytmów tym, że wymaga stosowania soli oraz posiada wbudowany mechanizm key stretching.
Ogólny schemat hashu BCrypt to: <sól><pwhash>.
Sól złożona jest z następujących elementów:
$<version> – wersja algorytmu bcrypt (np. $2a),$<rounds> – liczba z przedziału 04-99 określająca tzw. work factor algorytmu (domyślnie $12),$<saltaddon> – losowe 22 znaki powiększające sól. Ciąg ten weryfikowany jest przez wyrażenie regularne [./A-Za-z0-9]. Znaki te można wylosować własnoręcznie lub zostawić ten proces samemu algorytmowi.Ostatecznie hash BCrypt wygląda następująco:
$<version>$<rounds>$<saltaddon><pwhash>
Czyli pwhash 31 znakowy hash hasła, który został stworzony przy pomocy wersji <version> algorytmu BCrypt, wykorzystując work factor równy <rounds> oraz dodatkową sól dynamiczną <saltaddon>.
Informacja o soli i hashu zapisywana jest w bazie danych jako jeden ciąg. BCrypt zwraca hash kodowany wewnętrzną wersją Base64 (trochę inaczej działa w niej padding na ostatnich pozycjach).
Algorytm może wydawać się bardziej skomplikowany niż MD5 czy SHA, jednak jego użycie jest bardzo proste. Poniżej znajduje się przykład generacji skrótu BCrypt w języku Python3 z wykorzystaniem biblioteki py-bcrypt:
>>> import bcrypt
# Generuj hash z własnoręcznie ustawionymi właściwościami soli
>>> bcrypt.hashpw("vizzdoom","$2a$12$1234567890123456789012")
'$2a$12$123456789012345678901ueEDm4W8S0bcR7tYCaovy5X64j.wKmA2'
# Generuj hash z solą losowaną przez algorytm oraz work factor 12
>>> bcrypt.hashpw("vizzdoom",bcrypt.gensalt(12))
'$2a$12$ECkVAZC8c3FcL9xWNiQ4l.cl72O5et0PCxhKfR6gGX7Hb7ROTbVBy'
Czas wyjaśnić tajemniczy work factor.
Work factor można skojarzyć ze stopniem złożoności obliczeniowej. Minimalną wartością akceptowaną w BCrypt jest work factor = 4.
Każde zwiększenie współczynnika Work Factor o jeden zwiększa dwukrotnie czas obliczeń. Jeśli hashe z work factor = 11 obliczane są w ciągu 0.25 sekundy, to hashe z work factor = 14 będą obliczane w 2 sekundy. Różnica dla użytkownika będzie praktycznie niezauważalna – jednak w momencie kradzieży bazy danych, agresor w ciągu sekundy będzie mógł sprawdzić co najwyżej kilkaset hashy BCrypt, zamiast milionów hashy MD5/SHA1.
Work Factor jest wartością konfigurowalną, więc BCrypt staje się funkcją walczącą z prawem Moore’a oraz gwarantującą dużą elastyczność przeciwko atakom wymyślonym w przyszłości (future-proof).
Work Factor jest mechanizmem _Key Stretchingu_ bezpośrednio wbudowanym w sam algorytm funkcji.
Password Based Key Derivation Function 2 to popularny algorytm podobny do BCrypt, zapewniający porównywalny stopień bezpieczeństwa. PBKDF2 jest bardzo bezpieczną funkcją skrótu stosowaną między innymi jako element zabezpieczający bezprzewodowe sieci WiFi (WPA, WPA2).
Jedynym mankamentem tej funkcji jest podatność na zrównoleglanie (w większym stopniu niż BCrypt). Ta ułomność pozwala na tworzenie szybszych crackerów PBKDF2 w GPGPU (w porównaniu do BCrypt).
SCrypt jest to najmłodsza opisywana tutaj funkcja skrótu kryptograficznego. Jest uważana za jedną z najbezpieczniejszych na świecie.
Ogólna metoda działania jest podobna do funkcji BCrypt czy PBKDF2, jednak SCrypt wyróżnia się wśród tych funkcji pewną unikatową cechą.
SCrypt pozwala parametryzować nie tylko wymaganą do obliczeń moc obliczeniową, ale również wymaganą ilość używanej pamięci. Daje to niezwykle skomplikowany Key Stretching, który nie tylko chroni przed klasycznymi atakami, ale również utrudnia implementację w GPGPU.
SCrypt działa na dowolnych plikach binarnych (czyli nadaje się do szyfrowania nie tylko haseł). Z powodzeniem można zastąpić szyfrowanie komendą openssl przez scrypt {enc|dec} infile > outfile. Instalacja wymaga własnoręcznej komplikacji źródeł aplikacji. Nie sprawia to jednak problemów – na domyślnych ustawieniach systemu Ubuntu 12.04 oraz Backtrack 5r3 nie trzeba instalować dodatkowych bibliotek.
Portable PHP password hashing framework jest algorytmem dla języka PHP oferującym nie tylko duże bezpieczeństwo funkcji hashującej, ale również umożliwia przenoszenie między różnymi systemami (wspiera PHP od wersji 3.0.18 do 5.4 i nowsze!).
W algorytmie używane są trzy mechanizmy:
Algorytm działa w trzech wariantach, w zależności od ustawień PHP:
| Użyta funkcja hashująca | Wymagania | |
|---|---|---|
| Wersja bezpieczna | Blowfish (bcrypt) | PHP 5.3.0 wraz z Suhosin Patch |
| Wersja bezpieczna | DES | PHP 5.3.0 |
| Wersja portable | MD5 | PHP 3.0.18 – 5.4+ |
Takie podejście pozwala na używanie bezpiecznej funkcji skrótu praktycznie w każdej instancji PHP, niezależnie od tego, czy wspiera ona nowoczesne funkcje skrótu, czy nie.
Algorytm phpass można porównać do BCrypta zaimplementowanego dla języka PHP.
Zasadę działania (dla wersji portable) prezentuje poniższy listing:
$final = '$P
$P$9IQRaTwmfeRo7ud9Fh4E2PdI0S3r.L0
\__________/\____________________/
\ \
\ \ Actual Hash
\
\$P$ 9 IQRaTwmf
\_/ \ \______/
\ \ \
\ \ \ Salt
\ \
\ \ # Rounds
\ (not decimal representation, 9 is actually 11)
\ Hash Header
Implementacja w aplikacjach PHP jest bardzo prosta. Wystarczy pobrać bibliotekę phpass i utworzyć obiekt klasy PasswordHash w sposób pokazany poniżej:
1 <?php 2 header('Content-type: text/plain');
3 require 'PasswordHash.php';
4
5 ######## Try to use stronger but system-specific hashes,
6 ######## with a possible fallback to the weaker portable hashes.
7 $t_hasher = new PasswordHash(8, FALSE);
8 $hash = $t_hasher->HashPassword('test12345');
9 print 'Hash: ' . $hash . "\n";
10
11 #Check Password using stronger, system specyfic hashes
12 $check = $t_hasher->CheckPassword('test12345', $hash);
13 print "Check correct: '" . $check . "' (should be '1')\n";
14
15 ######## Force the use of weaker portable hashes.
16 $t_hasher = new PasswordHash(8, TRUE);
17 $hash = $t_hasher->HashPassword('test12345');
18 print 'Hash: ' . $hash . "\n";
19
20 #Check Password using portable hashes
21 $check = $t_hasher->CheckPassword('test12345', $hash);
22 print "Check correct: '" . $check . "' (should be '1')\n";
23
24 ######## A correct portable hash for 'test12345'.
25 $hash = '$P$9IQRaTwmfeRo7ud9Fh4E2PdI0S3r.L0';
26 print 'Hash: ' . $hash . "\n";
27 $check = $t_hasher->CheckPassword('test12345', $hash);
28 print "Check correct: '" . $check . "' (should be '1')\n";
29 ?>
OUTPUT:
Hash: $2a$08$LzUc1bZaOQOWEg/tyhGXMe4LbhmQSv0q8Vzwdye5SR3Zk8m6PqqbC Check correct: '1' (should be '1') Hash: $P$BouPo6QYqCi7g2kIrac9Cwo/.UZaYr. Check correct: '1' (should be '1') Hash: $P$9IQRaTwmfeRo7ud9Fh4E2PdI0S3r.L0 Check correct: '1' (should be '1')
Portable PHP password hashing framework pozwala w bardzo łatwy sposób znacznie zwiększyć bezpieczeństwo haseł dowolnej aplikacji PHP. W najnowszych wersjach PHP zaleca się, aby wyłączyć tryb portable i korzystać z implementacji generującej skrót BCrypt.
Przyjrzyjmy się, jak najpopularniejsze systemy przechowują hasła statyczne swoich użytkowników.
md5(pass)
Wiele powszechnych systemów zarządzania treścią, przechowuje hasła hashowane tylko funkcją MD5 i to bez użycia soli. Jest to bardzo niebezpieczne dla użytkowników.
Administracja tych serwisów powinna zainteresować się nowszymi systemami CMS lub przynajmniej powinna przepisać mechanizmy zarządzania hasłami w tych skryptach.
md5(pass.salt(32))
Nowsze wersje systemu Joomla używają długiej (32 znakowej), dynamicznej soli dla każdego hasła.
Takie rozwiązanie całkowicie chroni przed atakami tęczowych tablic (oraz atakami bruteforce), ale nie zdaje egzaminu zabezpieczania przed bardziej skomplikowanymi atakami słownikowymi. Dla każdej generowanej próby w tych atakach cracker musi po prostu dodać sól i sprawdzić, czy hashe się zgadzają. Taka operacja tylko nieznacznie wpływa na czas tych ataków.
sha1(strtolower(user).pass)
Simple Machines Forum wychodzi z nietypową propozycją, która często podnosiła dyskusje na temat bezpieczeństwa. Wiele osób wypominało, że sól w postaci nazwy użytkownika jest wartością “znaną hakerom”, przez co jej zastosowanie jest bezcelowe. Ten tok rozumowania jest całkowicie błędny.
Sól nie jest pod żadnym pozorem sekretem. Atakujący uzyskując dostęp do hashy, otrzymuje również dostęp do soli. Z uwagi na jednokierunkowy charakter funkcji hashujących i tak nie jest w stanie użyć soli, aby przewidzieć oryginał hasła. Wartość soli musi być dodawana w każdej iteracji algorytmu atakującego i czy będzie to nazwa użytkownika czy losowa wartość, to i tak jest ona znana.
Niemniej, nazwa użytkownika pisana małymi literami jest w pewnym sensie złym pomysłem.
Mimo tego, że login jest unikatowy względem jednego systemu, to nie jest unikatowy globalnie. Użytkownicy tacy jak root, admin czy john występują w milionach innych systemów. Sole są głównym wrogiem ataków tęczowych tablic, więc ciągi loginów w hasłach będą skutecznie przeszkadzały atakującemu, ale tylko wtedy, gdy będą to nazwy niepopularne. W przeciwnym wypadku ciągi te zostaną dopisane do zindeksowanych hashy w tablicach, teoretycznie zwiększając ich skuteczność.
Może brzmi to groźnie, ale jest to dość skrajny przypadek, który w zasadzie nie ma zastosowania w praktyce. W każdym razie, zgodnie z zasadą Defence in Depth powinniśmy stosować losowe sole.
Pomijając już temat soli, mechanizmy przechowywania haseł w SMF i tak stoją na przeciętnym poziomie. Używana funkcja SHA1 niby lepiej wypada w konkurencji z MD5, jednak jej użycie na pewno nie jest tutaj “_przyszłościowe_”.
sha1(sha1(pass))
Strategia hashowania haseł w tej popularnej bazie danych, pozwala tylko dwukrotnie wydłużyć czas ataków.
Na szczęście wielokrotne hashowanie, nawet w tak prostym przypadku, chroni przeciwko atakom tęczowych tablic – już po pierwszej operacji hashowania wynik podawany na funkcję skrótu posiada 40 znaków 0-9A-F. Jest to zakres znacząco przekraczający możliwości tęczowych tablic.
Warto dodać, że hasła w MySQL5 posiadają na początku znak gwiazdki. Znak ten nie wprowadza nic nowego i należy go usunąć, gdy ładujemy hashe do programów łamiących.
Przykład hasha MySQL5: *5ACAE4F99D4C697A792C2E8AF421D7927DC28C78
md5(md5(pass).salt(3) – vBulletin < 3.85
md5(md5(pass).salt(30) – vBulletin >= 3.85
Dwa wywołania md5 wraz z dynamiczną solą w każdym haśle zauważalnie spowalniają proces crackowania, ale mimo tego nie jest to elastyczne rozwiązanie.
W vBulletin poniżej wersji 3.85 stosowano sól składającą się z 3 losowych znaków. W wersjach od 3.85 stosuje się sól 30 znakową.
md5(md5(salt).md5(pass)
IPB wykorzystuje podobne mechanizmy jak vBulletin. Tutaj występują trzy wywołania funkcji MD5, które plasują bezpieczeństwo haseł IPB na poziomie porównywalnym jak vBulletin.
SHA512 (5000 rounds)
W nowych systemach Linux (np. Ubuntu/Ubuntu Server 12.04) domyślnie używany algorytm hashowania haseł użytkowników to SHA512. Obecnie w systemach Linux stosuje się 5000 iteracji wielokrotnego hashowania, co sprawia, że klasyczne ataki siłowe są tutaj praktycznie bezużyteczne.
Liczbę rund oraz funkcję skrótu można konfigurować, więc zwiększenie bezpieczeństwa w przyszłości nie stanowi żadnego problemu. Aby to zrobić należy edytować plik /usr/share/pam-configs/unix (w przypadku Ubuntu), a następnie w linii:
[success=end default=ignore] pam_unix.so obscure use_authtok try_first_pass sha512
dopisać frazę rounds=10000:
[success=end default=ignore] pam_unix.so obscure use_authtok try_first_pass sha512 rounds=10000
phpass, portable mode (md5), 2048 rund
Najnowsza rodzina skryptu PHPBB używa algorytmu phpass. Niestety ze względu na wymóg kompatybilności z wieloma wersjami PHP, skrypt musi używać trybu portable phpass. Mimo to phpass skutecznie utrudnia wszelkie ataki na hasła.
Warto wspomnieć, że hashe PHPBB3 posiadają nietypowy jak na phpass prefix $H$. Nie należy się tym zrażać – hashe te można interpretować dokładnie tak jak hashe $P$ w klasycznym phpass (trybu portabl).
Przykładowy hash PHPBB3: $H$9sZK3UHK9ogZTWgjhaPFNxoe/Rj83M0
phpass, portable mode (md5), 8192 rund
WordPress, podobnie jak PHPBB3, również używa phpass w wersji portable. Tutaj domyślnie liczba rund ustawiona jest na 8192. Popularna platforma blogowa w bardzo bezpieczny sposób przechowuje hasła użytkowników.
Przykładowy hash WordPress: $P$BtBjNdqnd.r8HSySc7plv.pOV6ky7Q/
phpass, portable mode (sha2-512 !), 16 364 rund
Drupal od wersji 7 przeszedł na mechanizm portable phpass, jednak twórcy nieznacznie go zmodyfikowali. Zamiast funkcji MD5 używana jest funkcja SHA512. Gwarantuje to dalej bardzo dużą przenośność wraz z bardzo wysokim poziomem bezpieczeństwa.
W związku z tym, że generowane hashe nie są zwykłymi hashami phpass portable mode, hashe Drupal 7+ zawierają prefix $S$.
Przykładowy hash Drupal 7: $S$DANPdICX/1DTrxP5JjwogxegQ1W.SkzZ6.XAglr6eTsJYlTdVGrs
Spis metod przechowywania haseł w wielu popularnych systemach można znaleźć w tym miejscu.
Kolejna część tekstu: http://sekurak.pl/kompendium-bezpieczenstwa-hasel-atak-i-obrona-czesc-2/
— Adrian `Vizzdoom` Michalczyk
Adrian `Vizzdoom` Michalczyk: pasjonat bezpieczeństwa teleinformatycznego od najmłodszych lat, obecnie student wydziału Informatyki Politechniki Śląskiej w Gliwicach.
Czasem programista, czasem gracz papierkowych gier RPG, ale zawsze fascynat klimatów post-apokaliptycznych. W swoim życiu nosił zarówno czarny, jak i biały kapelusz, teraz w wolnym czasie próbuje rozwijać swój kąt Internetu: http://vizzdoom.net.
Artykuł został pierwotnie napisany dla portalu http://securitum.pl oraz został opublikowany na licencji Creative Commons: uznanie autorstwa, na tych samych warunkach.
Zezwala się na kopiowanie, dystrybucję, wyświetlanie i użytkowanie dzieła i wszelkich jego pochodnych (w celach komercyjnych i niekomercyjnych) pod warunkiem umieszczenia informacji o twórcy (w postaci: Adrian `Vizzdoom` Michalczyk) oraz o pierwszym zamieszczeniu tekstu na portalu http://securitum.pl. Jeśli zmienia się lub przekształca niniejszy utwór albo tworzy inny na jego podstawie, można rozpowszechniać powstały w ten sposób nowy utwór tylko na podstawie takiej samej licencji.
Autor oświadcza, że dysponuje prawami autorskimi do tekstu. Wykorzystywane źródła umieszczone są w treści artykułu.
$final .= encode64_int($rounds) $final .= genSalt() (8 bytes "encode64" format). $hash = md5($salt . $password) For 2$rounds times, do $hash = md5($hash . $password) $final .= encode64($hash)
Implementacja w aplikacjach PHP jest bardzo prosta. Wystarczy pobrać bibliotekę phpass i utworzyć obiekt klasy PasswordHash w sposób pokazany poniżej:
OUTPUT:
Portable PHP password hashing framework pozwala w bardzo łatwy sposób znacznie zwiększyć bezpieczeństwo haseł dowolnej aplikacji PHP. W najnowszych wersjach PHP zaleca się, aby wyłączyć tryb portable i korzystać z implementacji generującej skrót BCrypt.
Przyjrzyjmy się, jak najpopularniejsze systemy przechowują hasła statyczne swoich użytkowników.
md5(pass)
Wiele powszechnych systemów zarządzania treścią, przechowuje hasła hashowane tylko funkcją MD5 i to bez użycia soli. Jest to bardzo niebezpieczne dla użytkowników.
Administracja tych serwisów powinna zainteresować się nowszymi systemami CMS lub przynajmniej powinna przepisać mechanizmy zarządzania hasłami w tych skryptach.
md5(pass.salt(32))
Nowsze wersje systemu Joomla używają długiej (32 znakowej), dynamicznej soli dla każdego hasła.
Takie rozwiązanie całkowicie chroni przed atakami tęczowych tablic (oraz atakami bruteforce), ale nie zdaje egzaminu zabezpieczania przed bardziej skomplikowanymi atakami słownikowymi. Dla każdej generowanej próby w tych atakach cracker musi po prostu dodać sól i sprawdzić, czy hashe się zgadzają. Taka operacja tylko nieznacznie wpływa na czas tych ataków.
sha1(strtolower(user).pass)
Simple Machines Forum wychodzi z nietypową propozycją, która często podnosiła dyskusje na temat bezpieczeństwa. Wiele osób wypominało, że sól w postaci nazwy użytkownika jest wartością “znaną hakerom”, przez co jej zastosowanie jest bezcelowe. Ten tok rozumowania jest całkowicie błędny.
Sól nie jest pod żadnym pozorem sekretem. Atakujący uzyskując dostęp do hashy, otrzymuje również dostęp do soli. Z uwagi na jednokierunkowy charakter funkcji hashujących i tak nie jest w stanie użyć soli, aby przewidzieć oryginał hasła. Wartość soli musi być dodawana w każdej iteracji algorytmu atakującego i czy będzie to nazwa użytkownika czy losowa wartość, to i tak jest ona znana.
Niemniej, nazwa użytkownika pisana małymi literami jest w pewnym sensie złym pomysłem.
Mimo tego, że login jest unikatowy względem jednego systemu, to nie jest unikatowy globalnie. Użytkownicy tacy jak root, admin czy john występują w milionach innych systemów. Sole są głównym wrogiem ataków tęczowych tablic, więc ciągi loginów w hasłach będą skutecznie przeszkadzały atakującemu, ale tylko wtedy, gdy będą to nazwy niepopularne. W przeciwnym wypadku ciągi te zostaną dopisane do zindeksowanych hashy w tablicach, teoretycznie zwiększając ich skuteczność.
Może brzmi to groźnie, ale jest to dość skrajny przypadek, który w zasadzie nie ma zastosowania w praktyce. W każdym razie, zgodnie z zasadą Defence in Depth powinniśmy stosować losowe sole.
Pomijając już temat soli, mechanizmy przechowywania haseł w SMF i tak stoją na przeciętnym poziomie. Używana funkcja SHA1 niby lepiej wypada w konkurencji z MD5, jednak jej użycie na pewno nie jest tutaj “_przyszłościowe_”.
sha1(sha1(pass))
Strategia hashowania haseł w tej popularnej bazie danych, pozwala tylko dwukrotnie wydłużyć czas ataków.
Na szczęście wielokrotne hashowanie, nawet w tak prostym przypadku, chroni przeciwko atakom tęczowych tablic – już po pierwszej operacji hashowania wynik podawany na funkcję skrótu posiada 40 znaków 0-9A-F. Jest to zakres znacząco przekraczający możliwości tęczowych tablic.
Warto dodać, że hasła w MySQL5 posiadają na początku znak gwiazdki. Znak ten nie wprowadza nic nowego i należy go usunąć, gdy ładujemy hashe do programów łamiących.
Przykład hasha MySQL5: *5ACAE4F99D4C697A792C2E8AF421D7927DC28C78
md5(md5(pass).salt(3) – vBulletin < 3.85
md5(md5(pass).salt(30) – vBulletin >= 3.85
Dwa wywołania md5 wraz z dynamiczną solą w każdym haśle zauważalnie spowalniają proces crackowania, ale mimo tego nie jest to elastyczne rozwiązanie.
W vBulletin poniżej wersji 3.85 stosowano sól składającą się z 3 losowych znaków. W wersjach od 3.85 stosuje się sól 30 znakową.
md5(md5(salt).md5(pass)
IPB wykorzystuje podobne mechanizmy jak vBulletin. Tutaj występują trzy wywołania funkcji MD5, które plasują bezpieczeństwo haseł IPB na poziomie porównywalnym jak vBulletin.
SHA512 (5000 rounds)
W nowych systemach Linux (np. Ubuntu/Ubuntu Server 12.04) domyślnie używany algorytm hashowania haseł użytkowników to SHA512. Obecnie w systemach Linux stosuje się 5000 iteracji wielokrotnego hashowania, co sprawia, że klasyczne ataki siłowe są tutaj praktycznie bezużyteczne.
Liczbę rund oraz funkcję skrótu można konfigurować, więc zwiększenie bezpieczeństwa w przyszłości nie stanowi żadnego problemu. Aby to zrobić należy edytować plik /usr/share/pam-configs/unix (w przypadku Ubuntu), a następnie w linii:
dopisać frazę rounds=10000:
phpass, portable mode (md5), 2048 rund
Najnowsza rodzina skryptu PHPBB używa algorytmu phpass. Niestety ze względu na wymóg kompatybilności z wieloma wersjami PHP, skrypt musi używać trybu portable phpass. Mimo to phpass skutecznie utrudnia wszelkie ataki na hasła.
Warto wspomnieć, że hashe PHPBB3 posiadają nietypowy jak na phpass prefix $H$. Nie należy się tym zrażać – hashe te można interpretować dokładnie tak jak hashe $P$ w klasycznym phpass (trybu portabl).
Przykładowy hash PHPBB3: $H$9sZK3UHK9ogZTWgjhaPFNxoe/Rj83M0
phpass, portable mode (md5), 8192 rund
WordPress, podobnie jak PHPBB3, również używa phpass w wersji portable. Tutaj domyślnie liczba rund ustawiona jest na 8192. Popularna platforma blogowa w bardzo bezpieczny sposób przechowuje hasła użytkowników.
Przykładowy hash WordPress: $P$BtBjNdqnd.r8HSySc7plv.pOV6ky7Q/
phpass, portable mode (sha2-512 !), 16 364 rund
Drupal od wersji 7 przeszedł na mechanizm portable phpass, jednak twórcy nieznacznie go zmodyfikowali. Zamiast funkcji MD5 używana jest funkcja SHA512. Gwarantuje to dalej bardzo dużą przenośność wraz z bardzo wysokim poziomem bezpieczeństwa.
W związku z tym, że generowane hashe nie są zwykłymi hashami phpass portable mode, hashe Drupal 7+ zawierają prefix $S$.
Przykładowy hash Drupal 7: $S$DANPdICX/1DTrxP5JjwogxegQ1W.SkzZ6.XAglr6eTsJYlTdVGrs
Spis metod przechowywania haseł w wielu popularnych systemach można znaleźć w tym miejscu.
Kolejna część tekstu: http://sekurak.pl/kompendium-bezpieczenstwa-hasel-atak-i-obrona-czesc-2/
— Adrian `Vizzdoom` Michalczyk
Adrian `Vizzdoom` Michalczyk: pasjonat bezpieczeństwa teleinformatycznego od najmłodszych lat, obecnie student wydziału Informatyki Politechniki Śląskiej w Gliwicach.
Czasem programista, czasem gracz papierkowych gier RPG, ale zawsze fascynat klimatów post-apokaliptycznych. W swoim życiu nosił zarówno czarny, jak i biały kapelusz.
Artykuł został pierwotnie napisany dla portalu http://securitum.pl oraz został opublikowany na licencji Creative Commons: uznanie autorstwa, na tych samych warunkach.
Zezwala się na kopiowanie, dystrybucję, wyświetlanie i użytkowanie dzieła i wszelkich jego pochodnych (w celach komercyjnych i niekomercyjnych) pod warunkiem umieszczenia informacji o twórcy (w postaci: Adrian `Vizzdoom` Michalczyk) oraz o pierwszym zamieszczeniu tekstu na portalu http://securitum.pl. Jeśli zmienia się lub przekształca niniejszy utwór albo tworzy inny na jego podstawie, można rozpowszechniać powstały w ten sposób nowy utwór tylko na podstawie takiej samej licencji.
Autor oświadcza, że dysponuje prawami autorskimi do tekstu. Wykorzystywane źródła umieszczone są w treści artykułu.

Masa przydatnych informacji, dzięki.
Przyjemnie się to czytało. Dobra robota Adrian!
Super, w takim razie zapraszam na więcej :)
MASA przydatnych informacji. Fajne uzupełnienie Twojej prezentacji z Security BSides. Czekam na więcej! :)
Artykuł na pewno się przyda, chociaż znalazłem kilka niepoprawnych sformułowań i błędów.
Lista bugów: http://pastebin.com/0Wdaunfd
Przydałby się opis key stretchingu i soli dynamicznych, a także porównanie szybkości wykonywania funkcji skrótu, którego nie wziąłeś w ogóle pod uwagę.
“Strategia hashowania haseł w tej popularnej bazie danych, pozwala tylko dwukrotnie wydłużyć czas ataków.”
O ile dobrze pamiętam to x-krotne hashowanie na zasadzie sha1(sha1($input)) powoduje zwiększenie szansy znalezienia kolizji, a to z powodu tego, że już po pierwszym przebiegu funkcji ilość wejść jest ograniczona w stosunku do ich ilości w poprzednim przebiegu. Algorytm sha1 nie dopasowuje wejść do wyjść jeden do jednego, stąd ograniczona ilość kombinacji zwracanych wartości (2^160).
“Na szczęście wielokrotne hashowanie, nawet w tak prostym przypadku, chroni przeciwko atakom tęczowych tablic – już po pierwszej operacji hashowania wynik podawany na funkcję skrótu posiada 40 znaków 0-9A-F. Jest to zakres znacząco przekraczający możliwości tęczowych tablic.”
Nie bardzo rozumiem. Tęczowe tablice mogą składować “dwupoziomowe” wartości. Zestawy danych po sha1 i równolegle po podwójnym sha1 (oczywiście, jeżeli ktoś zbierał je w takim celu). Podwaja to ilość danych, ale jest do zrobienia. Tak samo, jak mozolne (w przypadku dużej ilości danych) dodatkowe hashowanie danych z TT w locie w trakcie łamania – też jest możliwe. Niestety to nie działa tak jak napisałeś, że jak zashasujemy raz to nagle mamy magiczny, dłuższy (40 znakowy) ciąg, który zahasowany powtórnie będzie bardziej bezpieczny. Dlaczego? Tu – patrz to co napisałem po pierwszym cytacie :]
Na razie tyle.
Ale już wielokrotne haszowanie z zastosowaniem różnych funkcji lub z zastosowaniem różnych soli.
Przecież dla wielu przebiegów można ustawiać nawet zależną od poprzedniej sól np. przy pierwszym przebiegu $hash mojasol1… $hash255 mojasol256.
Inne przypadki:
Moim zdaniem metoda SMF jest fajna: dla zwykłych userów ta metoda jest wystarczająca. Zapewni wysoki poziom bezpieczeństwa (przecież przy łamaniu haseł zwykłych śmiertelników, dla uzyskania korzyści, atakujący musieliby ich złamać wiele, a przy wykryciu ataku można szybko zresetować hasła) Dopiero przy samych adminach już jedno hasło staje się niebezpiecznym narzędziem, a dla adminów można ustawić bardziej restrykcyjną politykę i automat, który np. co 2 godziny czy co 2 dni będzie dla nich losował nową sól i przeliczał hashe.
I też nie rozumiem, dlaczego w ogóle powstają takie systemy, w których każe się użytkownikom zmieniać często hasła. To jest moim zdaniem bezsensowne: przecież wystarczy zmieniać sole czy inne dane zaciemniające. Dla użytkownika wystarczy JEDNO hasło, ale po prostu dobre. Wystarczy zaproponować dobrą metodę mnemotechniczną.
Ponowne wyliczanie skrótu z inną solą po kilku dniach nie jest możliwe – do tego potrzeba przechowywać (lub pobierać od użytkowników) oryginał hasła. Dlatego też, gdy decydujemy się zwiększyć work factor takiego np. bcrypta, to w systemie część użytkowników ma klucze bcrypt z haseł w wersji mniej i bardziej bezpiecznej.
Udowodnione, że gdy funkcja jest funkcją słabo/silnie odporną na kolizje, to ponowne wyliczanie skrótu nie zmniejsza bezpieczeństwa.
@ Keraxel @m1chu
dzięki za uwagi
@m1chu
“O ile dobrze pamiętam to x-krotne hashowanie na zasadzie sha1(sha1($input)) powoduje zwiększenie szansy znalezienia kolizji, a to z powodu tego, że już po pierwszym przebiegu funkcji ilość wejść jest ograniczona w stosunku do ich ilości w poprzednim przebiegu. Algorytm sha1 nie dopasowuje wejść do wyjść jeden do jednego, stąd ograniczona ilość kombinacji zwracanych wartości (2^160).”
Tak, masz rację. Specjalnie o tym nie pisałem, dla jasności przekazu. Kolizje zdecydowanie są większe przy takim hashowaniu, ale to nieznacznie tylko zwiększa prawdopodobieństwo złamania (pomijając fakt, że tracimy kontrolę nad ilością kombinacji, tak jak opisałeś powyżej). W tamtym miejscu bardziej mi chodziło o to, że podczas crackowania musimy wykonać dwie operacje hashowania, a one są tutaj operacją dominującą w algorytmie łamiącym.
“Tęczowe tablice mogą składować “dwupoziomowe” wartości. […]”
Dokładnie! Ale po pierwsze to raczej takich tablic się nie znajdzie, jeśli już to nie będą one zbyt dobrej jakości, a sama ich generacja jest bardzo nieopłacalna.
“Niestety to nie działa tak jak napisałeś, że jak zashasujemy raz to nagle mamy magiczny, dłuższy (40 znakowy) ciąg, który zahasowany powtórnie będzie bardziej bezpieczny.”
Będzie bezpieczny, jeśli przyjmiemy założenie, że posiadamy `jednopoziomową` tablicę tęczową. Tak jak pisałem przed chwilą – skrajnie mało prawdopodobne jest to, że ktoś dzisiaj będzie próbował łamać hasła bardziej skomplikowanymi tęczówkami.
Dzięki m1chu za tak ciekawą dyskusję :)
@Keraxel – no, wielkie dzx za tak dokładną korektę. W zasadzie przy wszystkich wymienionych przez Ciebie aspektach musiałem się namyśleć w trakcie pisania :) Teraz widzę też te potworki językowe – ale takie rzeczy strasznie uciekają, gdy widzi się po raz n-ty tyle tekstu.
Największy problem to jest z funkcją hashującą i dużą zmiennością wyjścia. Do tego drugiego – słowo mi uciekło i jakoś nie chce wrócić :( A funkcje hashującą przedstawiłem w uproszczeniu z podejścia algorytmicznego. W zasadzie jest ona tam tak samo używana, jak we fragmencie, który podesłałeś.
@fuzzy
Mówiłem, że się szykuje rozwinięcie ;) A jak będzie SBS 2013, to chyba pociągnę temat jeszcze dalej :)
@vizzdoom
To będę się musiał wobec tego wybrać do Krakowa na ten SBS :).
Szkoda, że termin przełożony, bo akurat 28.02 i 1.03 jestem w Krk, wiec mógłbym trochę swój pobyt przedłużyć… :)
Mam takie pytanie, w TrueCrypt mam do wyboru w ‘Hash Algorithm’ :
– RIPEMD-160
– SHA-512
– Whirlpool
ktory z nich jest najmocniejszym, a moze polecanie jeszcze jakies inne ?!
pozdrawiam
Na prawdę dobry artykuł !!!
gdzie można znaleźć opcję “wersja do druku” lub pobierz w PDF? :)
Nie ma ;) Zachęcamy do wchodzenia live na sekuraka :]
–ms
ctrl + P > microsoft print to PDF
Bardzo dobrze opracowane zagadnienie. Zabrakło mi tylko informacji o możliwości zastosowania oprócz soli również pieprzu (dodatkowej soli po stronie serwera aplikacji) oraz zero knowledge, proof of knowledge.
Artykuł bardzo pomocny przy tworzeniu pracy inżynierskiej, którą mam nadzieje za kilka dni obronię!
Przydało się do PHPass ;>
Dobry artykuł. Tylko zastanawia mnie jedna rzecz. Mianowicie – gdzie najlepiej przechowywać dynamiczną sól dla danego użytkownika?
W bazie, koło skrótu. Tak w sumie robią algorytmy do bezpiecznego przechowywania skrótu haseł (tzw. PBKDFy jak BCrypt, phpass czy pbkdf2).
I tak… gdy ktoś będzie w stanie wyciągnąć skrót, będzie w stanie również wyciągnąć sól.
I tak… koncepcyjnie tak powinno to wyglądać, ponieważ sól nie służy do zwiększanie złożoności hasła (pierwotnie tak myślano, ale w praktyce sól chroni nas przeciwko innym zagrożeniom, a samo dodanie soli podczas crackowania tylko nieznacznie wydłuża jego czas).
phpBB by Przemo od wielu lat korzysta z sha z solą a nie z md5
2 function classicHash(x) { 3 return x.length %
3;
4 }
Błąd ?:)
Ok, to zapewne miała być nowa linia po prostu, a zostało 3 przed return.
Super art!
Obadaj też pozostałe 2 części :-)
Siemano, może ktoś polecić kolagen z tołpygi?Potrzebuję takiego do smarowania na ciało, ze względów sportowych.