Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Adminie… Czy znamy Twoje grzechy? ;-) Sprawdź!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Adminie… Czy znamy Twoje grzechy? ;-) Sprawdź!

Pełen opis wielogodzinnego incydentu opracował sam Cloudflare – szacunek za bardzo szybką reakcję powiązaną z wysoką szczegółowością tego wpisu.
Zatem co było źródłem całego zamieszania?
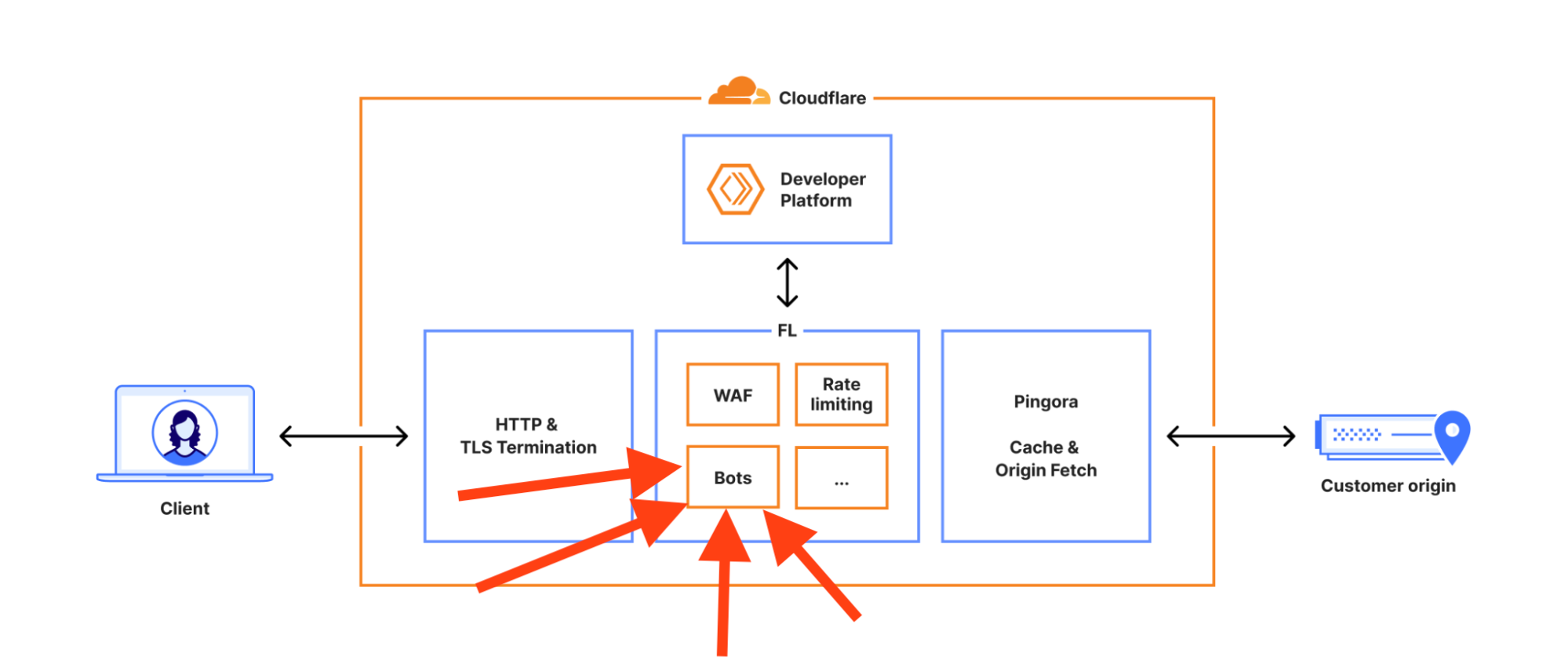
OK, o co chodzi z tymi błędami 500? Cloudflare zmienił uprawnienia na pewnej, wewnętrznej bazie danych. W wyniku tego pewne zapytanie SQL, które było uruchamiane w kontekście podsystemu wykrywania botów, nagle zaczęło zwracać ponad dwa razy więcej wyników niż normalnie (zapytanie szło z automatu po dodatkowej, drugiej bazie danych, która w wyniku zmiany uprawnień nagle zaczęła być dostępna).
Teraz kiedy wynik SQLa został wysłany do przetworzenia przez systemy corowe Cloudflare, trafiało to na twardy limit 200 wyników, powyżej którego serwer ogłaszał “panikę”. Ten “ficzer” jest ustawiony celowo – tak żeby nie skończyła się pamięć na serwerach (pamięć jest prealokowana dla max 200 wierszy wyniku).
When the bad file with more than 200 features was propagated to our servers, this limit was hit — resulting in the system panicking.
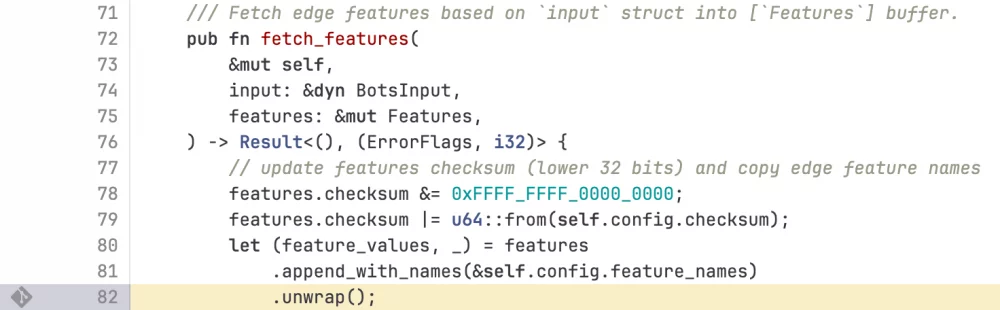
Skąd ten “panic” – stąd, że kod w Rust sprawdzający limit generował nieobsłużony wyjątek.
“The FL2 Rust code that makes the check and was the source of the unhandled error is shown below“:
Cloudflare planuje między innymi:
Czy można było “na szybko” i “na chwilę” wyłączyć działanie Cloudflare dla swojej usługi? (czyli uniezależnić się od awarii). Niestety nie, bo nie działał też dashboard Cloudflare, tzn działał, ale nie można się było do niego zalogować:
“While the dashboard was mostly operational, most users were unable to log in due to Turnstile being unavailable on the login page.”
PS
❌ Cloudflare rozważał też scenariusz cyberataku, bo równolegle padła strona sprawdzająca status usług Cloudflare (cloudflarestatus.com – jest hostowana poza Cloudflare) – cóż to raczej był human DDoS…
Teraz trudny orzech do zgryzienia – czy hostować cloudflarestatus.com za Cloudflare (ochroni się przed DDoSami, nie ochroni się przez awarią) czy poza Cloudflare (nie ochroni się przed DDoSami). Hostować u konkurencji – trochę głupio ;)
~Michał Sajdak

Nie, to nie wstyd hostować status page u konkurencji. To przygotowanie na czarny scenariusz.
dla IT nie wstyd a nawet plus, dla marketingu/sprzedaży często wstyd ;)
A konkretnie użycie “.unwrap()” (rzucenie wyjątku przy błędzie) zamiast “?” (przekazanie błędu do funkcji wołającej) w jednej funkcji.
tak, poszło update w txt
Interesujący przykład jak jedna niedziałająca usługa paraliżuje “pół Internetu”… jednak korzyści przeważają nad “ryzykiem”.
Zdarza się. Dobrze, że reakcja była w miarę szybka i że była odpowiednia informacja. Downdetector też nie działał co jest dosyć osobliwe :)
To była po prostu duża kampania marketingowa Cloudflare w domenach klientów :)
A tak serio to niestety wpadka, ale wpadki bywały i będą się zdarzać. Duży plus dla firmy za otwartość w komunikacji i wyciąganie wniosków.