Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania

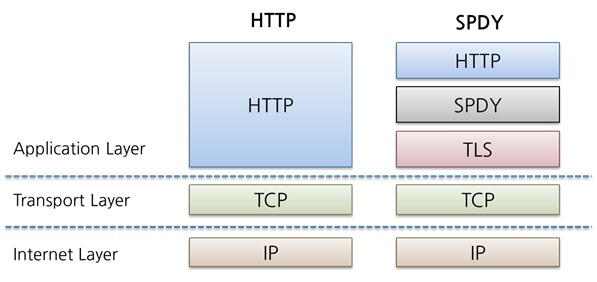
Obecną wersją „produkcyjną” jest 3.1 i na niej się skupimy, natomiast prace nad wersją 4. są dopiero w powijakach. Wersja produkcyjna dlatego jest w cudzysłowie, ponieważ SPDY nie jest obecnie standardem. Z jednej strony, IETF traktuje SPDY jak punkt wyjścia do stworzenia HTTP bis, czyli wersji 2.0 HTTP. Jednak nie jest to standard zatwierdzony.
Z drugiej strony, jest to rozwiązanie już zaimplementowane we wszystkich ważniejszych przeglądarkach: używa go Google, Facebook oraz Amazon. Dodatkowo wielu producentów rozwiązań ADC (Application Delivery Controler) posiada już implementację tego stosu w swoich rozwiązaniach. Istnieją też dedykowane moduły zapewniające wsparcie dla Apache i Nginx.
Jeżeli używamy Firefoxa za pomocą plug-in SPDY indicator możemy zobaczyć, czy do danej strony łączymy się za pomocą nowego protokołu.
Przyspieszenie transmisji związane jest z kilkoma wcześniej wymienionymi zabiegami, a mianowicie:
Dodatkowo SPDY wymaga stosowania w komunikacji szyfrowania, oczywiście nie ma ono na celu przyspieszenia działania stron. Zazwyczaj kryptografia = spadek wydajności, więc trwają prace nad przyspieszeniem także tego elementu połączenia. Teraz, w niezbędnym zakresie poruszę elementy związane z szyfrowaniem, omówię je bowiem w kolejnej części cyklu.
Multipleksowanie wielu strumieni HTTP w obrębie jednego połączenia TCP jest jedną z najsilniejszych cech SPDY. Szczegółowy opis tej części SPDY byłby zbyt długi, dlatego postaram się skupić na kilku, w mojej opinii istotnych, elementach.
Przede wszsytkim musimy powiedzieć, czym charakteryzuje się strumień.
Połączenia HTTP w komunikacji klient – serwer odbywają się w pojedynczej sesji TCP. Każde żądanie i odpowiedź mieszczą się w ramach jednego strumienia, identyfikator strumienia jest liczbą 31-bitową. Oznacza to, że klient wysyła żądanie, serwer odpowiada i w momencie otrzymania wszystkich danych ten strumień jest zamykany. Klient tworzy strumienie o numerach nieparzystych, natomiast strumienie tworzone przez serwer mają numery parzyste.
Poniżej widać nagłówek SPDY. Poza długością (ułatwia pisanie parsera) mamy typ wiadomości oraz flagi sterujące.

Dalszy format ramki zależy jest od tego, jaki typ wiadomości jest przesyłany.
Typy pakietów mogą być następujące:
Jakkolwiek używanie pól stałej długości może wydawać się marnotrawstwem, to jednak stoi za tym jakaś logika. Po pierwsze, 8 bajtów na 1452-bajtowy payload oznacza 0,6% narzut. Po drugie, w sytuacji, gdy standardowe łącze DSL posiada przepustowość 1 Mbps, a zysk na nagłówku zmiennej długości osiągnąłby 50%, to czas odpowiedzi zostałby skrócony o 100 ns.
Dzięki temu zredukowana zostaje liczba połączeń do serwerów, co ma duży wpływ na skalowalność. W czasie testów wyniki wskazywały na redukcję ok. 40% w ilości wysłanych pakietów.
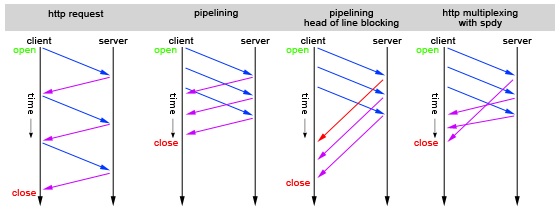
Jak wspominałem w poprzednim artykule obecnie mamy dwa podstawowe problemy, wpływające na niską wydajność HTTP. Jest to head-of-blocking oraz slow start.
Przeprowadzono testy, w których zwiększano RTT i straty pakietów. Okazało się, że ze SPDY można uzyskać 48% skrócenie opóźnienia przy wzroście strat pakietów do 2%. Powodów jest kilka:
W okolicach 2,5% strat pakietów zysk jest zerowy. Nie wydaje się to dużym problem, ponieważ zazwyczaj straty pakietów mieszczą się w przedziale 1-2%.
Jest to dość prosta sprawa. Klient w momencie ustanawiania strumienia (lub opcjonalnie w dowolnym momencie czasu „życia” strumienia”), ustawia priorytet danego strumienia.

Serwer nie jest zobowiązany przetwarzać strumieni o wyższym priorytecie w uprzywilejowany sposób. Wszystko odbywa się na zasadzie best-effort, jest to niejako wskazówka dla serwera, że jeżeli się da, powinien zająć się danymi dla tego strumienia w pierwszej kolejności.
Jedną z nowych opcji, jakie można spotkać w SPDY, jest tzw. serwer push. Polega na tym, że często serwer wie wcześniej niż przeglądarka, że jakieś dane będą potrzebne do załadowania strony. Wyobraźmy sobie sytuację, w której użytkownik pobiera stronę html z obrazkami. Z jednej strony, w typowej sytuacji najpierw user-agent pobrałby stronę, a następnie za pomocą kolejnych żądań GET prosiłby serwer o kolejne obrazki.
Z drugiej strony, serwer już w momencie wysyłania pliku html jest w stanie przewidzieć, że potrzebne będzie wysłanie kolejnych danych. Dzięki tej technice da się uniknąć wielu niepotrzebnych żądań GET. Ma to duże znaczenie zwłaszcza w przypadku łączy o dużym opóźnieniu, a więc wysokim RTT.
W http, każda wysłana wiadomość, czy to żądanie, czy odpowiedź, zawiera zestaw informacji sterujących, tzw. nagłówków. Przesyłane informacje opisują typ danych, wirtualnego hosta, do jakiego nawiązywane jest połączenie, czy typ przeglądarki, z jakiej korzysta użytkownik.
Np. zalogowanie się do Facebooka wymienia następujące informacje.
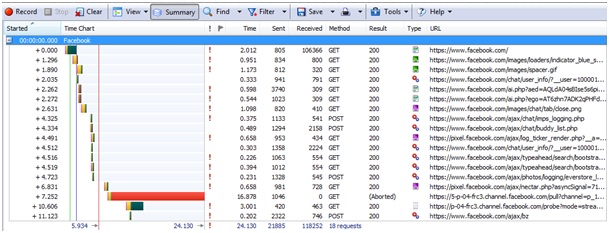
Ładowanie strony Facebooka – HTTP Watch
Facebook, aby załadować się od zera (tzn. przy wyczyszczonym cache), potrzebuje 18 żądań, w których nagłówki przesyłają 26.204 bajtów. W zamian otrzymujemy 118.252 bajtów danych (przed dekompresją). W tym momencie łatwo wyliczyć, że nagłówki stanowią 22,15% wymienionych danych. Warto dodać, że jest to startowa sytuacja, kiedy wysyłane są jeszcze dość duże pakiety danych. Potem w tle wysyłane są pakiety np. do aktualizowania statusu listy znajomych, na których narzut nagłówków jest ogromny. Nagłówki sumarycznie mają wielkość 1322 bajtów, a ilość użytecznych danych to 359 bajtów. W tym momencie informacje sterujące stanowią 78,64% wymienionych danych.
Więcej szczegółów można znaleźć w „A Methodology to Derive SPDY’s Initial Dictionary for Zlib Compression”.
Testy wykazują zysk 88% przy żądaniach i 85% przy odpowiedziach. Uśredniając do 86%, z naszych 26.204 bajtów musielibyśmy wysłać tylko 3144 bajtów. Przydaje się to zwłaszcza w przypadku wolniejszych łączy oraz informacji synchronizacyjnych, ponieważ znacząco zmieniają się proporcje nagłówki/dane.
Warto dodać, że w wersji 4. pojawił się pomysł nagłówków sesyjnych. Oznacza to, że np. User-Agent wysyłamy tylko raz w trakcie ustalania sesji, ponieważ z założenia jest to informacja, która się nie zmienia (a przynajmniej nie powinna) w trakcie dalszej komunikacji.
Oczywiście kompresja nagłówków nie jest jakąś rewolucyjną (aczkolwiek jest dobrze przemyślaną) częścią nowego protokołu, ale optymalizacja stron internetowych opiera się na wielu małych krokach – właśnie takich jak ten.
Nie był bym sobą, gdybym do tej beczki miodu nie dodał łyżeczki (naprawdę malutkiej) dziegciu.
Obecna architektura stron nie jest zoptymalizowana pod kątem SPDY. Podstawowym problemem jest wspomniany domain sharding. Tak bardzo przydatny przy standardowym http, teraz staje nam na drodze. Ponieważ SPDY musi nawiązywać wiele połączeń, dużo więcej czasu zabiera mu „rozpędzenie” się do optymalnej prędkości.
Innym problem jest to, że szybkość ładowania strony zależy także w dużej mierze od tego, jak działa przeglądarka. Dopóki pliki javascript nie zostaną wczytane, to przeglądarka nie pobiera innych danych. Dlatego tak ważne jest, aby skrypty były umiejscowione na samym dole. Podobnie – pliki CSS powinny znaleźć się na górze strony. SPDY sam nie poradzi sobie z tego typu problemem i sprytny administrator musi sam przygotować się do jego rozwiązania. Dobrym punktem startowym będzie książka „High Performance Web Sites” Steve’a Soudersa, polecam również jego bloga.
Guy Podjarny pokusił się o własne testy SPDY. Oto ich wyniki:
|
Network Speed |
SPDY vs HTTPS | SPDY vs HTTP |
| Cable (5,000/1,000, 28) | SPDY 6.7% faster | SPDY 4.3% slower |
| DSL (1,500/384,50) | SPDY 4.4% faster | SPDY 0.7% slower |
| Low-Latency Mobile (780/330,50) | SPDY 3% faster | SPDY 3.4% slower |
| High-Latency Mobile (780/330,200) | SPDY 3.7% faster | SPDY 4.8% slower |
Jak widać, dla czystego HTTP wyniki z użyciem SPDY wydają się rozczarowywać. Należy zdawać sobie sprawę z trzech rzeczy.
Polecam przeczytanie dyskusji pod artykułem, ponieważ jest bardzo interesująca.
Największym problemem, jaki pozostaje w SPDY jest to, że tak naprawdę przenieśliśmy tzw. head of blocking z warstwy HTTP na warstwę TCP. Wcześniej musieliśmy czekać z wysyłaniem żądań do czasu, aż odbierzemy odpowiedź na poprzednie. Teraz w przypadku straty pakietu TCP jesteśmy zmuszeni czekać na retransmisję. Mimo wszystko jest to duży postęp. A testy wskazują, że SPDY sprawuje się lepiej niż tradycyjny HTTP.
Obecnie SPDY działa tylko poprzez SSL/TLS. Argumentacja do takiego podejścia, poza oczywistą wynikającą z chęci ochrony prywatności, była następująca. W Internecie istnieje wiele pośredniczących węzłów, które mogą skanować ruch np. pod kątem wirusów. W trakcie prac okazało się, że w 10% przypadków w trakcie przesyłania informacji czystym tekstem z jakiegoś powodu transmisja nie udawała się. Winne temu najprawdopodobniej były wspomniane wcześniej urządzenia proxy. Zdecydowano się na owinięcie wszystkiego w TLS-a, aby uniknąć tego typu problemów.
Udało mi się też wyczytać, że wersja bez szyfrowania jest dyskutowana. Google zaś twierdzi, że włączenie SSL-a na wszystkich ich serwerach (wszystko robione jest w sofcie), zwiększyło obciążenie o 1%…
Jak widać ze SPDY-m można dużo wygrać w sensie skalowalności środowiska i prędkości działania aplikacji web: kompresja nagłówków, multipleksowanie strumieni, serwer push czy priorytezacja to mechanizmy, które mają szansę pozytywnie wpłynąć na wydajność strony.
Należy jednak zdawać sobie sprawę, że wdrożenie SPDY może być trudniejsze niż załadowanie modułu i restart Apache. Problemem może być domain sharding lub źle zaprojektowana strona WWW.
–Piotr Bratkowski [Piotrek.Bratkowski<at>gmail.com]

Szczerze mowiąc nie wiem po co promować rozwiązanie szybsze/oszczędniejsze jeśli korzyści wynikają (w części) z kompresji nagłowków a to z kolei naraża użytkowników na atak CRIME.
Multipleksowanie za to wydaje mi się ciekawym pomysłem.
W mojej opinii ilość nakładów i środków jakie trzeba poświęcić na CRIME jest spora. Dodatkowo wyłączenie kompresji na poziomie TLS nie pomaga, bo istnieje BREACH.
Wydaje mi się, że zawsze musisz ważyć wartość informacji, ryzyko oraz dodatkowe metody redukcji tego ryzyka (tokeny anty-CSRF) i na tej podstawie podjąć decyzję.
Pozdrawiam,
Piotrek Braktowski
@Piotrze
Nie można powiedzieć, że wyłączenie kompresji na pozimie TLS nie pomaga. Pomaga! Na atak CRIME pomaga bo to atak własnie na ten protokół.
Na atak typu BREACH pomaga wyłączenie kompresji HTTP (np. mod_deflate) dla dynamicznej części strony. Nie ma oczywiście powodu by wyłączać kompresję części statycznej.
Nakłady i środki na wykonanie ataku? Nie wydaje mi się by NSA miało z tym problem :)
Dzięki za tę serię, bardzo fajnie się czytało.
Martwi trochę to, że jest spora gama problemów do rozwiązania i w praktyce wzrost nie jest oszałamiający. Bardzo fajnie jednak, że protokół jest coraz szerzej wspierany. Czekam na dalsze informacje na temat nowego HTTP – może ilość przesyłanych informacji drastycznie się nie obniży – ale w niektórych zastosowaniach strasznie zwiększy się responsywność web-aplikacji. Czasem te kilkanaście milisekund potrafi mieć mega znaczenie na User eXperience.
Cześć,
Tak jak pisałem w artykule, problemem jest domain sharding, co nie pozwala na “rozpędzenie się” TCP, dodatkowo słabe wyniki wynikają z przeniesienia head of blocking z HTTP na warstwę TCP. Google ma na to rozwiązanie w postaci nowego protokołu quic, ale jest on dopiero w powijakach i tak naprawdę jeszcze długa droga przed nim -> https://docs.google.com/document/d/1lmL9EF6qKrk7gbazY8bIdvq3Pno2Xj_l_YShP40GLQE/edit?pli=1
Pozdr.,
Piotrek