Żądny wiedzy? Wbijaj na Mega Sekurak Hacking Party w maju! -30% z kodem: majearly

SPDY – jak przyspieszyć działanie aplikacji webowych? (część 1.)
Wstęp
W czasie, kiedy obserwujemy postępującą webizację aplikacji oraz wzrost wielkości stron w Internecie, ważne jest, aby wydajnie i bezpiecznie dostarczać dane do użytkownika. Protokół HTTP w wersji 1.1 nie robi tego zbyt dobrze…
Czy oznacza to, że jesteśmy skazani na coraz wolniejsze działanie aplikacji webowych?
Niekoniecznie, ponieważ na horyzoncie pojawiła się odsiecz w postaci SPDY oraz nadciągają dodatkowe posiłki w postaci HTTP 2.0. SPDY jest nowym protokołem, który lokuje się w modelu TCP/IP pomiędzy warstwą TCP a HTTP. Powstał, aby przyspieszyć strony WWW przez rozwiązanie pewnych ograniczeń HTTP 1.1.
Jego główne cechy to:
- wysyłanie wielu żądań HTTP w pojedynczej sesji TCP,
- priorytetyzacja oraz
- kompresja nagłówków.
Dodatkowo dla każdego połączenia jest stosowane szyfrowanie TLS – prace nad dużym przyspieszeniem TLS również wpisują się w SPDY. Co ważne jest on wstecznie kompatybilny z HTTP.
Rozpoznanie
1. W czym tkwi problem, czyli punkt wyjścia
Co jest obecnie problemem i jak przed wprowadzeniem SPDY radzono sobie z tym zagadnieniem?
Pierwszym z nich jest wielkość stron. W 1999 roku strona główna Amazon miała 16 obiektów typu html i img o sumarycznej wielkości 57 KB. Obecnie mówimy o 196 obiektach typu img, plikiach html, css czy skryptach JavaScript o sumarycznej wielkości 2118 KB. Zastanówmy się, w jaki sposób wpływa to na ładowanie się strony i percepcję użytkownika.
W obecnej wersji protokołu mamy do czynienia z sytuacją, gdzie klient, aby wysłać kolejne żądanie (w kontekście pojedynczej sesji TCP), musi otrzymać odpowiedź na poprzednie. Czyli komunikacja wygląda mniej więcej w ten sposób:
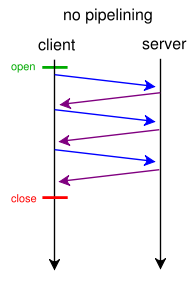
Źródło: Wikipedia
2. Jak próbowano rozwiązać ten problem
Opis kilku metod optymalizacji transmisji, które stosowano do tej pory, a które mają jakiś wpływ na to, co się dzieje w SPDY.
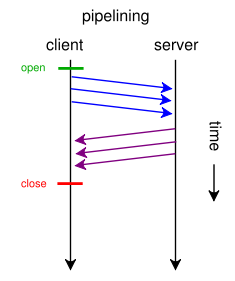
2.1. Pipelinening
Aby obejść opisane powyżej ograniczenie, dodano do protokołu rozszerzenie zwane pipelinening pozwalające na wysłanie więcej niż jednego zapytania bez otrzymania odpowiedzi na poprzednie. Problem, jaki się z tym wiąże, to tzw. head of blocking. Wyobrazimy sobie sytuację, w której klient wysyła 3 żądania: pierwsze o 200 MB bazę danych i 2 kolejne o pliki html i css. Serwer musi przetwarzać żądania w kolejności ich otrzymywania, więc przeglądarka użytkownika musi najpierw otrzymać 200mb plik z bazą danych, zanim otrzyma bardziej istotne pliki html i css, z których mogłaby zacząć renderowanie stronę.
2.2. Domain sharding
Kolejną optymalizacją, jaką wprowadzono, tym razem bardziej po stronie przeglądarek niż samego protokołu, była implementacja kilku równoległych sesji TCP dla pojedynczej domeny. Przykładowo Firefox otwiera do 8 sesji dla pojedynczej domeny. Dzięki temu, przeglądarka jest w stanie pobierać równolegle do 8 różnych obiektów.
Następnym logicznym krokiem było podzielenie zawartości strony na różne domeny. Jeżeli np. grafika do strony www.page.com znajduje się pod adresem img.page.com, to przeglądarka, z jednej strony, otworzy dodatkowe sesje dla tej domeny i będzie równolegle pobierać do 16 różnych obiektów. Z drugiej strony, nic nie przychodzi bez kosztów i jak wykazywały badania Yahoo, zwiększenie liczby domen ponad 2 przynosi więcej złego niż dobrego.
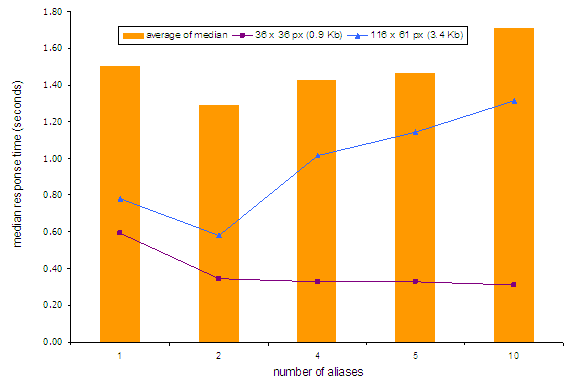
Źródło: yuiblog.com
W pewnym stopniu wszystko nadal zależy jednak od konkretnej strony.
Co więcej, obecnie dużo domen jest zoptymalizowanych pod kątem http 1.1 (tzn. używa domain sharding) i wykorzystuje duże ilości contentu z innych domen. Te zabiegi mogą mieć negatywny wpływ na zysk osiągany z zastosowania SPDY, ale o tym powiemy później.
2.3. Sprite’y
Jeszcze jedna optymalizacja do wprowadzenia to tworzenie z grafiki występującej na stronie tzw. sprite’ów, a następnie cięcie ich za pomocą stylów CSS. W takiej sytuacji zamiast wysyłać wiele małych obrazków, jesteśmy w stanie przesłać jeden duży, który potem jest „obrabiany” przez przeglądarkę.
Dlaczego jest to istotne? Ponieważ w zależności od tego, jak oddziałują na siebie HTTP i TCP, można uzyskać większą prędkość transmisji, wysyłając jeden większy plik niż kilka małych. Bardziej szczegółowe wytłumaczenie w dalszej części artykułu.
2.4. Kompresja
Na szybkość działania strony wpływa też oczywiście to, jak dużą ilość danych musimy przesłać do klienta. Obecnie wszystkie przeglądarki mają wsparcie dla GNU zip, czyli popularnego gzipa.
Polega to na tym, że w momencie nawiązywania połączenia przeglądarka wysyła informacje o wspieranych metodach kompresji:
GET / HTTP/1.1 Host: phpuction.pl User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:24.0) Gecko/20100101 Firefox/24.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: pl,en-us;q=0.7,en;q=0.3 Accept-Encoding: gzip, deflate DNT: 1 Connection: keep-alive
Jeżeli serwer jest skonfigurowany, aby ją stosować, to zwracana zawartość jest skompresowana. Wielkość danych w tym wypadku to 4683 bajtów:
HTTP/1.1 200 OK Date: Thu, 24 Oct 2013 07:38:53 GMT Server: Apache/2.2.15 (CentOS) X-Powered-By: PHP/5.3.3 Expires: Thu, 19 Nov 1981 08:52:00 GMT Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0 Pragma: no-cache Connection: close Content-Type: text/html; charset=UTF-8 Vary: Accept-Encoding Content-Encoding: gzip Content-Length: 4683</b>
Nagłówki odpowiedzi nieskompresowanej na to samo zapytanie wyglądają tak:
HTTP/1.1 200 OK Date: Thu, 24 Oct 2013 07:41:47 GMT Server: Apache/2.2.15 (CentOS) X-Powered-By: PHP/5.3.3 Expires: Thu, 19 Nov 1981 08:52:00 GMT Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0 Pragma: no-cache Connection: close Content-Type: text/html; charset=UTF-8 Content-Length: 21591
Widać brak nagłówka Content-Encoding:gzip i wielkość danych 21 591 bajtów. Porównując wersję skompresowaną do nieskompresowanej, widzimy, że w tym wypadku musimy przesłać jedynie 21,6 % danych. Nie będę się tutaj zagłębiał w temat zysków (lub zdarzających się też start) z kompresji, która jest uzależniona od wielu czynników, bo to temat na oddzielny artykuł. Jednak w ogólnym ujęciu, włączenie kompresji dla tekstu jest dobrym pomysłem. Apache posiada moduł mod_deflate dedykowany do tego zadania. Jego podstawowa konfiguracja jest dość prosta: wystarczy dorzucić do pliku httpd.conf następujący wpis:
<IfModule mod_deflate.c> AddOutputFilterByType DEFLATE text/html text/plain text/xml </IfModule>
Co jest istotne w przypadku SPDY: kompresja w HTTP 1.1 dotyczy tylko zawartości. Nie obejmuje nagłówków.
Dlaczego to wszystko nie działa?
Skoro w działanie http wprowadzono tyle poprawek, dlaczego wyniki są na tyle niezadowalające, że postawiono opracować nowy protokół? Na przeszkodzie stoi nam stary dobry TCP, który został zaprojektowany z wielką starannością i myślą o skalowalności. Dla http niesie to jednak kilka przykrych konsekwencji.
Podstawowym problemem jest to, że chcąc chronić Internet przed przepełnieniem, TCP na początku połączenia stosuje algorytm nazywany Slow Start. Działa on w ten sposób, że pełna prędkość nie jest uzyskiwana od razu po nawiązaniu połączenia. Wręcz przeciwnie, do maksymalnej wartości transferu dochodzi się w sposób ekspotencjalny, jednak każdy utracony pakiet (dla TCP oznaka, że prawdopodobnie nastąpiło przepełnienie sieci) zmniejsza z takim trudem wypracowaną prędkość transmisji.
Na poniższym obrazku widać, w jaki sposób kształtuje się początkowo połączenie TCP. Faza, która nas interesuje w kontekście połączeń HTTP, zawiera się w pierwszych sześciu rundach transmisji.
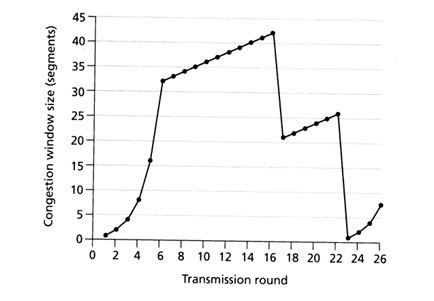
Źródło: www.cs.newpaltz.edu
Typowa strona internetowa zawiera wiele małych obiektów, w związku z czym w większości przypadków mieścimy się w tym początkowym oknie transmisji. Warto zaznaczyć, że musimy przejść przez fazę TCP Slow Start dla każdego żądania HTTP. Bardzo ważne jest uświadomienie sobie, że ilość danych, które można wysłać w danej rundzie połączenia, zależna jest od ilości odebranych wcześniej segmentów. Początkowe okno transmisji równe jest 3, czyli ok. 4 KB danych. Łatwo policzyć, że nie jest to wielkość, która pozwala przesłać większy obrazek. Okno transmisji rośnie wraz z kolejnymi odebranymi segmentami. W związku z tym wzrost prędkość transmisji związany jest bezpośrednio z opóźnieniem występującym na łączu. Warto wspomnieć, że od 2010 roku domyślna wielkość okna transmisji w jądrze Linuxa została zwiększona do 10. Zmiana ta obowiązuje od wersji jądra 2.6.33+. Motywatorem był dokument (napisany, a jakże, przez ludzi z Google’a) An Argument for Increasing TCP’s Initial Congestion Window.
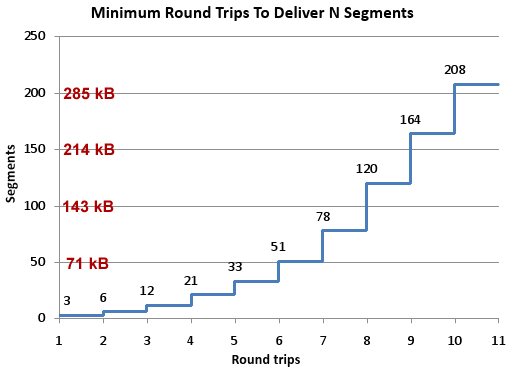
Źródło: www.stevesouders.com
Widać więc, że początkowy transfer danych w momencie nawiązania połączenia TCP jest bardzo niski. Nawet jeżeli zestawimy kilka równoległych połączeń, to przy założeniu, że zawsze musimy przejść przez fazę Slow Start, w pierwszych 3 rundach transmisji możemy wysłać 3 + 6 + 12 segmentów, czyli 28 KB. Jeżeli RTT na łączu jest równe 330 ms, to w pierwszej sekundzie transmisji jest ona na poziomie 28 KB/s.
Podsumowanie
HTTP 1.1 posiada wiele wąskich gardeł, które nie były problemem w momencie, kiedy powstawał, a obecnie znacząco obniżają wydajność webaplikacji. Wszystkie dodatkowe triki i hacki poprawiają nieco sytuację, ale same też nie są wolne od wad.
Np. zestawianie przez przeglądarkę większej liczby sesji prowadzi do sytuacji, w której 1000 klientów jest w stanie wygenerować 80 000 połączeń do jednego serwera web. Obniża to skalowalność i znacząco wpływa na obciążenie urządzeń sieciowych i serwerów.
W następnej części cyklu odpowiem na pytanie, w jaki sposób SPDY jest w stanie zaradzić takim bolączkom.
Polecamy również tekst opisujący działanie nowoczesnych przeglądarek internetowych.
—Piotr Bratkowski [Piotrek.Bratkowski<at>gmail.com]

{kind=link}
W punkcie „Domain sharding” można byłoby też dodać, że dzięki przeniesieniu statycznej treści na osobną (sub)domenę sprawiamy, że do takich zapytań nie dołączane często pokaźne ciasteczka. Identyczna sytuacja występuje także w punkcie o sprite’ach – nawet w tej samej domenie, a nagłówek żądania (nawet z ciastkami) wysyłany jest tylko jeden raz.
Z drugiej strony na domain shardingu mogą tracić użytkownicy mobilnych przeglądarek. Nowe połączenia TCP, zapytanie DNS, kolejny slow start… czy to nie powoduje większego zużyciu energii/zasobów.
Czepię się tylko jeszcze literówki w „ekspotencjalny”. Poprawną formą, o ile dobrze wiem, jest „eksponencjalny” – tylko czemu nie rodzima forma „wykładniczy”?