Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

Reguły obronne YARA do klasyfikacji i identyfikacji złośliwego oprogramowania
Złośliwe oprogramowanie (ang. malware) rozprzestrzenia się jak zaraza. Statystyki DataProt z roku 2022 informują, że codziennie wykrywane jest ponad pół miliona fragmentów złośliwego kodu, a łączna liczba istniejącego malware’u przekracza miliard. Nie da się też ukryć, że coraz częściej motywem ataku jest chęć zysku: Co minutę około cztery firmy doświadczają ataku oprogramowania wymuszającego okup (ang. ransomware).
W tym tekście przyjrzymy się sposobom klasyfikacji i identyfikacji próbek złośliwego oprogramowania za pomocą narzędzia YARA. Badacze często próbują ustalić powiązania pomiędzy analizowanymi próbkami złośliwego oprogramowania. Z tego powodu w celach klasyfikacji i identyfikacji złośliwe programy łączone są w rodziny (ang. families) na podstawie podobieństw. Przykładowe cechy wspólne, które są brane pod uwagę to np.:
- napisy w określonym języku pozwalają domniemać kraj pochodzenia złośliwego oprogramowania,
- powtarzające się i spotkane wcześniej fragmenty kodu mogą sugerować, że kolejne wersje tworzył ten sam autor lub grupa,
- informacje debugowania i użyty kompilator mogą ujawnić informacje o komputerze na którym powstała złośliwa aplikacja,
- powtarzający się szablon pliku różniący się jedynie konfiguracją może sugerować istnienie generatora złośliwego kodu.
Z pomocą badaczom przychodzi wspomniane narzędzie YARA, które udostępnia składnię pozwalającą za pomocą wzorców tekstowych i binarnych oraz operatorów logicznych opisywać złośliwe oprogramowanie, ale o tym za chwilę.
Identyfikacja próbek złośliwego oprogramowania
Podstawowym sposobem na określenie czy dana próbka została już zbadana lub jest podobna do już zbadanych próbek jest identyfikator funkcji skrótu nazywany też haszem (ang. hash). Klasyczne algorytmy takie jak np. SHA-256 wykryją nawet najdrobniejszą zmianę. Istnieją też algorytmy określane jako fuzzy hashing pozwalające badać podobieństwo bloków danych lub kodu.
Najpopularniejsze rodzaje haszy to m.in.:
SHA-256 — klasyczna funkcja skrótu pozwalająca określić czy plik został zmodyfikowany (porównać czy pliki są identyczne);
Imphash — jeśli próbki mają taki sam Imphash, to oznacza, że ich tablica importowanych funkcji (ang. Import Address Table, IAT) jest taka sama;
Authentihash — skrót używany przez Microsoft do sprawdzania czy sekcje pliku wykonywalnego nie zostały zmodyfikowane po podpisaniu i publikacji programu;
SSDEEP — tak jak zwykłe funkcje skrótu np. SHA-256 pozwalają znaleźć identyczne próbki, tak SSDEEP pozwala znaleźć próbki, które są do siebie podobne (ang. fuzzy hashing);
TLSH — kolejna funkcja skrótu typu fuzzy hashing używana przez Trend Micro;
TrID — narzędzie pozwalające rozpoznać typ nieznanego pliku (np. sample.bin czy sample.hex) i nadać odpowiednie rozszerzenie;
MD5 i SHA-1 — przestarzałe funkcje skrótu, które powinniśmy zastąpić np. przez SHA-256, jednak nadal są używane ze względu na przyzwyczajenie;
Obliczanie wartości funkcji skrótu SHA-256 w C# oraz PowerShell
Dla niewtajemniczonych poniżej prezentujemy dwa przykładowe kody źródłowe (listingi 1 oraz 2), które pozwolą nam obliczyć hasz SHA-256 dla próbki złośliwego oprogramowania.
Listing 1. Obliczanie wartości funkcji skrótu SHA-256 w C#
using var stream = File.OpenRead(@"C:\Users\iamda\Desktop\sample.bin");
using var sha256 = System.Security.Cryptography.SHA256.Create();
var bytes = await sha256.ComputeHashAsync(stream);
var hash = Convert.ToHexString(bytes);
Console.WriteLine($"SHA-256: {hash}");Listing 2. Obliczanie wartości funkcji skrótu SHA-256 w PowerShell
$sample = "C:\Users\iamda\Desktop\sample.bin";
$hash = Get-FileHash $sample -Algorithm SHA256 | Select -ExpandProperty "Hash";
Write-Host "SHA-256: $hash";
Narzędzie YARA, reguły YARA i projekt YARAify
Narzędzie nazywane YARA to program, którym można skanować pliki, aby sprawdzić czy posiadają cechy charakterystyczne określone w regułach YARA. Pliki z regułami YARA zawierają kod w specjalnej składni do wykrywania cech charakterystycznych dla złośliwego oprogramowania.
Warto dodać, że dostawcy zabezpieczeń wbudowują obsługę reguł YARA we własne rozwiązania. Na koncie GitHub VirusTotal wymienione jest ponad 70 projektów/rozwiązań/firm korzystających z YARA.
Korzystanie z YARA utrudniał brak jednolitego standardu, co powodowało np. niejednolite nazewnictwo w regułach i rozrzucenie reguł na różnych kontach GitHub.
Z tych i innych powodów powstał projekt YARAify dostępny jako aplikacja internetowa pod adresem:
Narzędzie YARAify pozwala przeskanować plik korzystając z bazy reguł, a nawet ustawić powiadomienia, gdy pojawi się próbka malware o określonych cechach charakterystycznych (ang. threat hunting). Projekt udostępnia również API oraz wyszukiwarkę plików.
Przykładowa reguła YARA
Zapoznanie się ze składnią reguł obronnych YARA rozpoczniemy od stworzenia przykładowej reguły, która najpierw rozpozna czy plik jest w formacie Portable Executable oraz czy plik zawiera napis „sekurak.pl”.
Narzędzie YARA można pobrać stąd:
https://github.com/VirusTotal/yara/releases
W katalogu z programem powinny być dwa pliki: yara64.exe oraz yarac64.exe. Utwórzmy obok tych programów plik z przykładową regułą o nazwie sekurak_yara_example.yar (listing 3).
Listing 3. Przykładowa reguła YARA (sekurak_yara_example.yar)
import "pe"
rule IsPE : PE
{
condition:
pe.is_pe
}
rule SampleRule1 : Educational Example
{
meta:
author = "Sekurak"
date = "2022-08-08"
description = "Educational example of YARA rule"
strings:
$x = { 73 65 6B 75 72 61 6B 2E 70 6C } //sekurak.pl
$y = "sekurak.pl" wide
condition:
IsPE and ($x or $y)
}
Objaśnienia poszczególnych elementów składniowych przykładowej reguły YARA przedstawiono na rysunku 1.

Rysunek 1. Przykładowa reguła obronna YARA z objaśnieniami najważniejszych elementów składniowych
Reguły przed użyciem poddawane są kompilacji programem yarac64.exe w celu lepszej wydajności przetwarzania. Po przejściu do odpowiedniego katalogu poleceniem w wierszu polecenia:
cd C:\Users\iamda\Desktop\yara-v4.2.2-2012-win64
można skompilować przykładową regułę YARA za pomocą:
yarac64.exe sekurak_yara_example.yar compiled.yar
Teraz, aby przetestować działanie reguł YARA stwórzmy folder o nazwie samples z przykładowym plikiem. Może to być dowolny plik *.exe, ale powinien zawierać napis sekurak.pl, aby stworzona reguła go wykryła. Można to łatwo osiągnąć korzystając z edytora heksadecymalnego XVI32 jak przedstawiono na rysunku 2.

Rysunek 2. Umieszczenie wzorca 73 65 6B 75 72 61 6B 2E 70 6C (sekurak.pl) w przykładowym pliku PE w celach eksperymentalnych
Teraz możemy wywołać narzędzie YARA w wierszu polecenia i sprawdzić czy przykładowy plik spełni warunki opisane w regułach:
yara64.exe -C compiled.yar .\samples\
Na rysunku 3 można zobaczyć, że przykładowy plik *.exe spełnia warunki dwóch eksperymentalnych reguł:
- IsPE – reguła sprawdza czy plik jest w formacie Portable Executable;
- SampleRule1 – reguła sprawdza czy plik zawiera ciąg bajtów 73 65 6B 75 72 61 6B 2E 70 6C (sekurak.pl);

Rysunek 3. Plik ConsoleApp.exe pasuje do reguł IsPE oraz SampleRule1
Oczywiście schemat działania narzędzia YARA niekoniecznie musi wiązać się z pisaniem własnych reguł od zera. Możliwe jest skorzystanie z istniejących reguł dostępnych np. pod adresem https://github.com/InQuest/awesome-yara w witrynie GitHub.
Prezentację sposobu działania narzędzia YARA możemy podsumować schematem przedstawionym na rysunku 4.
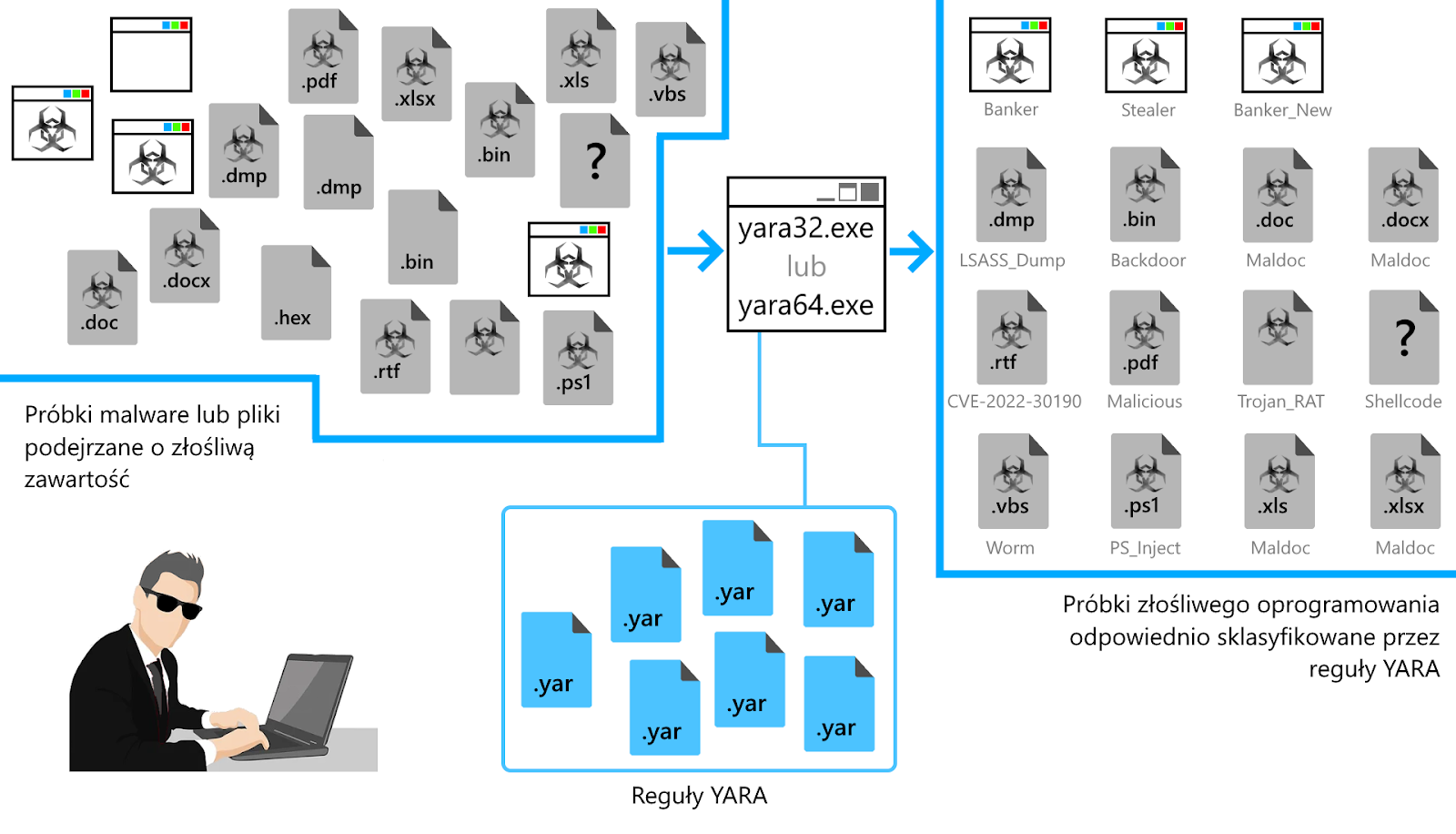
Rysunek 4. Schemat działania narzędzia YARA do klasyfikacji malware
Anomalie, artefakty, wskaźniki kompromitacji (ang. IoCs) oraz taktyki, techniki i procedury (ang. TTPs)
Podczas analizy złośliwego oprogramowania (czy to amatorsko czy zawodowo) warto ustalić sobie czego poszukujemy.
Naszą uwagę powinny zwracać cechy szczególne, które są charakterystyczne dla określonego malware, czyli wszelkiego rodzaju artefakty i anomalie. Pamiętam, że jedną z pierwszych spotkanych anomalii były pliki z przyszłości (rysunek 5).

Rysunek 5. Pliki z przeszłości oraz przyszłości (zobacz: Data modyfikacji)
Dziwna data modyfikacji i utworzenia pliku jest bardzo łatwa do osiągnięcia. Przykładowy kod w języku C# przedstawia listing 4.
Listing 4. Ustawienie daty i czasu utworzenia/modyfikacji pliku
SetFakeFileTime(@"C:\Users\iamda\Desktop\samples\sample1.bin",
new(1999, 01, 01, 13, 37, 0, 0, DateTimeKind.Local));
SetFakeFileTime(@"C:\Users\iamda\Desktop\samples\sample2.bin",
new(2077, 01, 01, 13, 37, 0, 0, DateTimeKind.Local));
void SetFakeFileTime(string path, DateTime dateTime)
{
File.SetCreationTime(path, dateTime);
File.SetLastAccessTime(path, dateTime);
File.SetLastWriteTime(path, dateTime);
}
Przejdźmy jednak do poważniejszych artefaktów, które chcemy znaleźć w analizowanym złośliwym oprogramowaniu.
Jeśli próbka nie zawiera niczego szczególnego, to analiza może się zakończyć wydobyciem wskaźników kompromitacji (ang. Indicators of Compromise). Artefakty tak nazywane służą stwierdzeniu infekcji czy ogólnie kompromitacji badanego systemu. Mogą to być na przykład:
- adresy IP serwerów Command & Control,
- złośliwe domeny internetowe,
- wartości funkcji skrótu (ang. hash) plików czy zrzutów pamięci,
- wzorce nietypowego ruchu sieciowego (ang. web requests),
- złośliwe polecenia PowerShell, VBS czy CMD.exe,
- …i inne artefakty czy anomalie.
Kolejnym ważnym celem podczas analizy próbki malware może być poszukiwanie taktyk, technik i procedur atakujących. Nazywane jest to w skrócie TTP.
Zbadanie taktyk powinno dać odpowiedź na pytanie: Dlaczego? Np. Dlaczego atakujący wstrzykuje kod w proces?
Poznanie technik dotyczy pytania: Jak? Np. Jak atakujący otworzył kanał komunikacyjny Command & Control?
Natomiast procedury dotyczą często szczegółów implementacji. Np. Jakie polecenie dezaktywowało ochronę antywirusową w czasie rzeczywistym? Jakie polecenie usunęło kopie zapasowe?
Ogromną i otwartą bazą taktyk, technik i procedur związanych z cyberbezpieczeństwem jest MITRE ATT&CK®.
Pisanie reguł obronnych YARA
W wielu przypadkach do sklasyfikowania próbki złośliwego oprogramowania wystarczy reguła opisująca jakie ciągi znaków (napisy) są zawarte w pliku lub procesie. Najważniejsze rodzaje napisów przedstawiono na listingu 5. Warunek any of them w sekcji condition oznacza, że reguła jest spełniona, gdy wystąpi minimum jeden ze zdefiniowanych napisów.
Listing 5. Przykładowe rodzaje napisów w regułach YARA
rule StringsExample
{
strings:
$text1 = "Sekurak"
$text2 = "Sekurak" nocase
$text3 = "Sekurak" wide
$text4 = "Sekurak" xor //lub z zakresem bajtów xor(0x01-0xff)
$text5 = "Sekurak" base64
condition:
any of them
}
Znaczenie poszczególnych słów kluczowych przy napisach:
- nocase – brak rozróżniania wielkości liter w napisach;
- wide – wykrywanie napisu w którym na zakodowanie znaku przeznaczono dwa bajty. Dodanie modyfikatora ascii, czyli wide ascii spowoduje wykrywanie napisów ze znakiem zakodowanym zarówno na jednym bajcie jak i na dwóch bajtach;
- xor – wykrywanie napisów, które zostały zaciemnione (ang. obfuscated) instrukcją alternatywy wykluczającej z jednobajtowym kluczem. Możliwe jest zawężenie wartości bajtów klucza poprzez zapis np. xor(0x07-0x4f);
- base64 – wykrywanie napisów, które zostały zaciemnione algorytmem Base64. Obsługa również napisów o dwóch bajtach na znak przez słowo kluczowe base64wide;
- fullword – wykrywanie napisów, które są oddzielone znakami nie alfanumerycznymi. W prostych słowach chodzi o wykrywanie całych słów;
W napisach można używać znaków specjalnych podobnych do tych z języka C np. zapis \” wstawi cudzysłów, \\ backslash, \r powrót karetki, \t tabulator, \n znak nowej linii, a \xdd wstawi bajt o dowolnej wartości np. \xFF.
Ciągi bajtów w systemie szesnastkowym (ang. hex strings)
W celu wykrywania wzorców, które niekoniecznie są napisem tylko np. kodem maszynowym możemy zastosować zapis bajtów w systemie heksadecymalnym. Przyjmijmy jako przykład następujący kod w języku Asembler x86-64:
mov rdx, qword ptr gs:[rdx+60]
Dla niewtajemniczonych warto wspomnieć, że odczytywanie przesunięcia 60 względem rejestru GS związane jest z tworzeniem kodu powłoki (ang. shellcode) dla Windows x64. Kod maszynowy odpowiadający tej instrukcji to:
65 48 8B 52 60
Zatem reguła do wykrywania tego fragmentu kodu w próbkach może być taka jak na listingu 6.
Listing 6. Przykładowa reguła YARA wykrywająca ciąg bajtów 65 48 8B 52 60
rule HexExample
{
strings:
$hex1 = { 65 48 8B 52 60 }
condition:
any of them
}
W dokumentacjach Intel 64 and IA-32 Architectures Software Developer’s Manual oraz AMD64 Architecture Programmer’s Manual Volume 3: General-Purpose and System Instructions znajdziemy zapis informujący, że po bajcie 8B występuje wartość określająca rejestr procesora (rysunek 6).

Rysunek 6. Informacja z dokumentacji procesorów x64 przedstawiająca sposób kodowania instrukcji MOV
Dzięki tej informacji możemy uczynić regułę YARA bardziej uniwersalną poprzez zastosowanie zapisu ?? w miejscu bajtu odpowiedzialnego za kod rejestru w instrukcji MOV. Znak zapytania wewnątrz ciągu bajtów oznacza dopasowanie dowolnej wartości (listing 7).
Listing 7. Przykładowa reguła YARA wykrywająca ciąg bajtów 65 48 8B ?? 60
rule HexExample2
{
strings:
$hex2 = { 65 48 8B ?? 60 }
condition:
any of them
}
Dzięki tej drobnej modyfikacji reguła z listingu 7 wykryje różne mutacje przykładowego kodu np.
mov rdx, qword ptr gs:[rdx+60]
mov rcx, qword ptr gs:[rcx+60]
mov rbx, qword ptr gs:[rbx+60]
mov r8, qword ptr gs:[r8+60]
mov r9, qword ptr gs:[r9+60]
mov r10, qword ptr gs:[r10+60]
mov r11, qword ptr gs:[r11+60]
mov r12, qword ptr gs:[r12+60]
;...itp.
Przykładowe ciągi bajtów w systemie szesnastkowym przedstawiono w tabeli 1.
Tabela 1. Podręczny opis składni ciągów szesnastkowych w YARA (ang. cheatsheet)
| Przykładowa składnia ciągu bajtów w systemie heksadecymalnym w sekcji strings reguły YARA | Opis |
| 94 7C 95 ?? 7D F? 09 74 | Ciąg bajtów z dowolnymi wartościami w miejsce znaków zapytania |
| 94 7C 95 F2 [3-7] FF 09 74 | Ciąg bajtów zawierający w miejscu kwadratowych nawiasów dowolne bajty o liczbie od 3 do 7 |
| 94 [128] 95 F2 7D FF 09 74 | Ciąg bajtów zawierający w miejscu kwadratowych nawiasów ciąg 128 bajtów o dowolnej wartości |
| 94 ( 7C 95 | 23 9? ) F2 7D FF 09 74 | Ciąg bajtów zawierający na drugiej pozycji bajty 7C 95 lub 23 9? |
Sekcja warunku w regułach YARA (ang. condition)
Warunek umieszczony w sekcji condition określa czy reguła może zostać dopasowana do analizowanego pliku lub procesu. Przykładowe warunki przedstawia tabela 2.
Tabela 2. Podręczny opis warunków w YARA z przykładami
| Przykładowa składnia warunku w sekcji condition reguły YARA | Opis |
| ($w or $x) and ($y or $z) | Warunek spełniony jeśli znaleziono ciągi $w lub $x oraz ciągi $y lub $z |
| #w == 7 and #x >= 13 | Warunek spełniony jeśli ciąg $w występuje 7 razy oraz ciąg $x występuje więcej niż 12 razy (dosłownie: większe bądź równe od 13) |
| #w in (0..512) == 3 | Warunek spełniony jeśli ciąg $w występuje trzykrotnie w pierwszych 512 bajtach pliku lub procesu |
| $x at 91 | Warunek spełniony jeśli ciąg $x występuje w miejscu o przesunięciu (ang. offset) równym 91 |
| filesize < 256KB | Warunek spełniony jeśli plik jest mniejszy niż 256 kilobajtów |
| $x at pe.entry_point | Warunek spełniony jeśli ciąg bajtów $x znajduje się w punkcie wejścia pliku Portable Executable |
| uint16(0) == 0x5A4D | Warunek spełniony jeśli plik lub proces rozpoczyna się sygnaturą “MZ” (oznacza to, że prawdopodobnie jest plikiem w formacie Portable Executable) |
| all of them | Warunek spełniony jeśli plik lub proces zawiera wszystkie ciągi bajtów (zdefiniowane w sekcji strings) |
| 2 of them | Warunek spełniony jeśli plik lub proces zawiera dwa ze wszystkich ciągów bajtów |
| any of them | Warunek spełniony jeśli plik lub proces zawiera którykolwiek z ciągów bajtów. Oznacza to samo co 1 of ($*) |
| (2 of ($w,$x,$y)) and $z | Warunek spełniony jeśli plik lub proces zawiera dwa ciągi bajtów z trzech ($w, $x, $y) oraz zawiera ciąg bajtów $z |
| none of ($x*) | Warunek spełniony jeśli plik lub proces nie zawiera żadnego ciągu bajtów nazwanego $x* (np. $x1, $x2, $x3 itd.) |
| any of ($x*, $y*) in (64..1024) | Warunek spełniony jeśli w pliku pomiędzy przesunięciem 64 do 1024 znajduje się którykolwiek z ciągów bajtów nazwanych $x* lub $y*, gdzie gwiazdka (*) oznacza numer |
| for any of ($w,$x,$y,$z) : ( $ at 512 ) | Warunek spełniony jeśli którykolwiek z napisów ($w, $x, $y czy $z) znajduje się pod przesunięciem o wartości 512 |
| for all of them : ( # > 7 ) | Warunek spełniony jeśli każdy ciąg bajtów występuje więcej niż 7 razy |
| for all i in (1..#w) : ( @w[i] < 128 ) | Warunek spełniony jeśli każde wystąpienie napisu $w znajduje się w pierwszych 128 bajtach |
| for all i in (1..3) : ( @x[i] + 16 == @y[i] ) | Warunek spełniony jeśli wystąpienie ciągu bajtów $y następuje po 16 bajtach od wystąpienia $x. Dotyczy to wszystkich trzech wystąpień ciągów w pliku lub procesie |
Wyrażenia regularne w regułach YARA
W pisaniu wyrażeń regularnych może pomóc np. https://regexr.com/. Warto dodać, że często w przypadku obsługi przez różne aplikacje wyrażeń regularnych spotyka się ataki typu odmowa usługi (ang. Denial of Service) np. https://nvd.nist.gov/vuln/detail/CVE-2017-8294. Dlatego napisanie reguły YARA bez używania wyrażeń regularnych może być lepszym rozwiązaniem. Przykładowe wyrażenia regularne przedstawia tabela 3.
Tabela 3. Przykłady wyrażeń regularnych w YARA
| Przykładowe wyrażenie regularne (w sekcji strings podobnie jak zwykłe napisy, jednak otoczone znakami slash) | Opis |
| /sha256: [0-9a-fA-F]{64}/ | Warunek spełniony jeśli w pliku lub procesie występuje ciąg znaków sha256: tutaj-wartość-obliczonego-hash |
| /section[0-9]{1,2}/ | Warunek spełniony jeśli w pliku lub procesie występują ciągi znaków takie jak np. section1, section2 czy section99 |
| /0x[a-f0-9-A-F][a-f0-9-A-F]/ | Warunek spełniony jeśli w pliku lub procesie występują ciągi znaków takie jak np. 0x00, 0x03, 0x4D czy 0xFF. |
Używanie YARA w języku Python
Narzędzie YARA można zintegrować z własną aplikacją za pomocą API dla języków C i C++. Możliwe jest także wywołanie YARA ze skryptów w języku Python. Przykładowy skrypt przedstawiono na listingu 8.
Listing 8. Przykładowe wywołanie YARA w języku Python
import yara
rules = yara.compile(‘C:\\Users\\n\\Desktop\\yara_rule\\win64shellcodedetector.yar’)
matches = rules.match(‘C:\\Users\\n\\Desktop\\selected_samples\\httpsstager64.bin’)
matches += rules.match(‘C:\\Users\\n\\Desktop\\selected_samples\\httpstager64.bin’)
matches += rules.match(‘C:\\Users\\n\\Desktop\\selected_samples\\96fc133108ded7eba87c0bf5eadfe17d’)
print(matches)
Skrypt należy zapisać jako plik z rozszerzeniem .py.
Wywołanie polecenia:
python prog1.py
w środowisku testowym zwróciło następujący wynik:
[Win64ShellcodeDetector, Win64ShellcodeDetector]
Oznacza to, że dwie próbki (httpsstager64.bin oraz httpstager64.bin) spełniły warunki logiczne reguły YARA o nazwie Win64ShellcodeDetector (rysunek 7).
Próbki użyte w eksperymencie:
httpsstager64.bin
SHA-256:
985eed33c1034766f04dab06045c6ad75cde3c870e78d6240ba9895b7c5bbcf6
httpstager64.bin
SHA-256:
c6732ea195382d845b99088882ffa71cf515ca01876663469a053e9b48cc5bcc

Rysunek 7. Wywołanie YARA w języku Python na przykładowych próbkach złośliwego oprogramowania
Regułę YARA z rysunku 7 o nazwie Win64ShellcodeDetector do wykrywania kodu powłoki dla Windows 64-bit w plikach binarnych przedstawiono na listingu 9.
Listing 9. Reguła YARA do wykrywania shellcode dla Windows x64
rule Win64ShellcodeDetector
{
meta:
author = "ethical.blue"
filetype = "Binary File"
date = "2022-05-19"
strings:
/* 6548:8B52 60 | mov rdx,qword ptr gs:[rdx+60] */
$read_GS_register = { 65 48 8B ?? 60 }
/* 48:8B52 18 | mov rdx,qword ptr ds:[rdx+18] */
$read_18_offset = { 48 8B ?? 18 }
/* 48:8B52 20 | mov rdx,qword ptr ds:[rdx+20] */
$read_20_offset = { 48 8B ?? 20 }
condition:
all of them
}
Zaciemnione (ang. obfuscated) i spakowane złośliwe oprogramowanie
Analizując próbki złośliwego oprogramowania można śmiało stwierdzić, że bardzo często są one zaciemnione (ang. obfuscated) i/lub spakowane. Przeważnie oznacza to, że kod programu jest zaszyfrowany i/lub skompresowany, a dopiero po uruchomieniu wypakowywany do pamięci operacyjnej w celu wykonania.
Z tego powodu reguły analizujące plik statycznie pod kątem określonych wzorców mogą nic nie wykryć. Jednym z rozwiązań jest pisanie reguł YARA, których zadaniem jest wykrywanie znanych programów do zabezpieczania plików *.exe. Po zidentyfikowaniu narzędzia typu packer czy protector możemy próbować zrzucić fragmenty kodu próbki z pamięci na dysk komputera np. pod debuggerem. Jeśli narzędzie zabezpieczające plik wykonywalny zostało już zbadane, to możemy mieć szczęście i w sieci będzie istniał program, który wypakuje kod automatycznie.
Wypakowywanie plików *.exe do których nie istnieją gotowe narzędzia automatyzujące może być bardzo czasochłonne.
Z pomocą przychodzi analiza bez wypakowywania, czyli na przykład skanowanie obszaru pamięci operacyjnej uruchomionego procesu lub skanowanie fragmentów zrzutów pamięci zapisanych na dysku komputera.
Podsumowanie
Narzędzie YARA to nie tylko aplikacja konsolowa, którą można przeskanować próbki złośliwego oprogramowania zebrane na dysku komputera jako kolekcja. Obsługa składni YARA jest wbudowywana w różne rozwiązania dotyczące cyberbezpieczeństwa. Zastosowanie YARA jest na tyle szerokie, że możemy pisać reguły nawet dla poczty e-mail czy skanować załączniki zbiorem posiadanych reguł.
Nic też nie stoi na przeszkodzie, aby zaprogramować własne narzędzie obsługujące reguły w składni YARA.
~Dawid Farbaniec
Wykaz literatury
Welcome to YARA’s documentation! — yara 4.2.0 documentation | https://yara.readthedocs.io/en/stable/
VirusTotal API v3 Overview | https://developers.virustotal.com/reference/overview
Tracking Malware with Import Hashing | Mandiant | https://www.mandiant.com/resources/tracking-malware-import-hashing
Authenticode Digital Signatures – Windows drivers | Microsoft Docs | https://docs.microsoft.com/en-us/windows-hardware/drivers/install/authenticode
GitHub – trendmicro/tlsh | https://github.com/trendmicro/tlsh
Marco Pontello’s Home – Software – TrID (mark0.net) | https://mark0.net/soft-trid-e.html
Threat Hunting | Rubrik | https://www.rubrik.com/products/threat-hunting
YARAify | YARA scan engine (abuse.ch) | https://yaraify.abuse.ch/

Zacny tekst!
Dzień dobry, Bardzo ciekawy artykuł niestety zawiera pewne błędy:1 “Klasyczne algorytmy takie jak np. SHA-256 wykryją nawet najdrobniejszą zmianę.” funkcje skrótu nic nie wykrywają i nic nie porównują, tylko “hash’ują”, autor poszedł tu mocno na skróty. Poza tym słowo “klasyczny” odnosi się do kultury starożytnych Greków i Rzymian tu raczej pasuje słowo “popularne”
2. “MD5 i SHA-1 — przestarzałe funkcje skrótu, które powinniśmy zastąpić:” zgoda jeżeli mowa o zastosowaniach w kryptologii, ale do obliczania hash’y i w celu porównywania plików z definicjami np. w antywirusach, czy wykrywania duplikatów plików, to nadal są wystarczająco dobre. Pozdrawiam
Chyba że weźmiemy pod uwagę punkt 3 zamiast 1 PWN.
nie to zebym sie narzucal ale chcialbym sie dowiedziec co sadzicie np o https://github.com/Neo23x0/Loki lub (z tej samej stajni) Thor Lite?
Dzień dobry,
Dziękuję za zainteresowanie artykułem.
Ad. 1. Racja. Stworzyłem mocny skrót myślowy. Powinno być, że za pomocą algorytmów takich jak SHA-256 jesteśmy w stanie wykryć nawet najdrobniejszą zmianę.
Ad. 2. Microsoft zaleca SHA-1 i MD5 tylko do “SIMPLE tampering checks”. Gdyż będą się one coraz bardziej stawać czymś podobnym do CRC32. Możemy sobie tym sprawdzać przesyłane dane czy nie mają losowych błędów. Natomiast niebezpieczeństwo tych algorytmów (SHA-1 i MD5) polega na tym, że można stworzyć dwa różne od siebie pliki, które będą miały taki sam hash. Nie nazwałbym polecania bezpieczniejszych algorytmów błędem.
Jeszcze raz dziękuję i pozdrawiam,
Dawid Farbaniec
VxZwae
Czy sam temat nie powinien wyświetlać się w https://sekurak.pl/?cat=7,3
(Aktualności)
W zasadzie, IOC nie są wskaźnikami kompromitacji, a wskaźnikami kompromisu. Działa to tak że, precyzyjna reguła generuje mniej zdarzeń false-positive, bo ma daleko przesunięty punkt przegięcia – czyli konsensus zajmuje więcej czasu, ale jest godny uwagi i można na nim opierać kolejne.
Teraz wiem jak odnaleźć artefakt (jeden był w %APPDATA%).
Rysunki z artykułu poznikały. Da się je przywrócić?