Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania

We wtorek 5 maja realizowaliśmy bezpłatnie i publicznie szkolenie “Poznaj 10 grzechów administratora sieci”, które poprowadził Piotr Wojciechowski – jeden z najbardziej doświadczonych sieciowców na świecie, który posiada certyfikat CCIE #25543. Idąc za ciosem i rozszerzając materiał, stworzyliśmy ten artykuł z myślą o osobach które poważnie myślą o hardeningu swojej sieci, bazując na doświadczeniu własnym.
Poniżej przedstawiam subiektywną listę 10 grzechów w infrastrukturze, które powinny być wyeliminowane od ręki. Warto dodać, że każda infrastruktura jest inna i nie wszystkie przypadki bezpośrednio będą możliwe do wdrożenia / mapowania z Waszą infrastrukturą. Wszystko należy wziąć pod rozwagę i przemnożyć przez własne środowisko. Zapraszam też do dyskusji pod artykułem w sekcji komentarzy.

20 maja wbijajcie na unikalne w naszej ofercie szkolenie od sekuraka. Poznacie podstawy sieci, nauczycie się diagnozować i rozwiązywać problemy, monitorować działanie sieci oraz zrozumiecie zależności między usługami sieciowymi. Przekonacie się, jak wygląda bezpieczeństwo sieci w praktyce i jak krytyczne jest ich działanie dla funkcjonowania dzisiejszych systemów.
Pod linkiem 50% off: https://sklep.securitum.pl/comptia-network-plus/compnet-sekurak
Szkolenie jest zaprojektowane w taki sposób, aby przygotować Was do egzaminu CompTIA Network+ i jednocześnie dać realne kompetencje, które wykorzystacie w pracy.
Jestem związany z branżą cyberbezpieczeństwa już dobre 20 lat i wiem jedno: większość poważnych incydentów nie zaczyna się z reguły od super-hollywoodzkiego wyrafinowanego ataku w postaci 0-day ani od grupy APT sponsorowanej przez obce państwo. 90% ataków zaczyna się od przełącznika z domyślnym hasłem, płaskiej sieci i zapory z regułą permit ip any any na samym dole listy ACL (ang. Access Control List). Serio.
Jeśli chociaż trzy z tych grzechów dotyczą Twojej infrastruktury – nie panikuj, ale zacznij działać. A jeśli chcesz uporządkować swoją wiedzę sieciową od fundamentów – zapraszam na nasze szkolenie CompTIA Network+: https://sklep.securitum.pl/comptia-network-plus
“Wdrożenie pilne, zmienimy hasła potem” © Admin. Potem nigdy nie nadchodzi. Routery, switche, access pointy, kontrolery WLAN, zapory – wszystko z kontem admin/admin, cisco/cisco albo hasłem podanym na naklejce z tyłu urządzenia. W przypadku małych firm i SOHO bywa jeszcze gorzej – urządzenia ISP (ang. Internet Service Provider) dostarczane z hasłem 1234 lub pustym polem. Problem jest systemowy: w wielu organizacjach brakuje procedury typu commissioning checklist, która wymuszałaby zmianę danych uwierzytelniających jeszcze przed podłączeniem urządzenia do sieci produkcyjnej. Tyle dobrze, że część nowych urządzeń samodzielnie taką procedurę wymusza przy pierwszym uruchomieniu.
Co z tym zrobi pentester?
Pierwsze, co robimy na każdym teście infrastruktury to skan z próbą logowania domyślnymi credentialami. Narzędzia takie jak RouterSploit, Nmap z odpowiednimi skryptami NSE, czy nawet klasyczna Hydra sprawdzą kilkaset domyślnych par login/hasło w ciągu minut. Jeden przejęty switch = pivoting do kolejnych segmentów, przechwytywanie ruchu (port mirroring), modyfikacja tablicy VLAN. Gra skończona, zanim się zaczęła.
Detekcja i obrona
W celu detekcji we własnej sieci, można wykonać skan domyślnych loginów narzędziem takim jak nmap –script ssh-brute lub dedykowanym skryptem dla hydry:
hydra -L default_users.txt -P default_passwords.txt -M targets.txt ssh -t 4 |
W przypadku urządzeń Cisco dla systemu IOS:
! Zmiana hasła enable |
Jakbym miał jednak wskazać jedną skuteczną metodę, to wdróżcie procedurę commissioning checklist – żadne urządzenie nie trafia do sieci produkcyjnej bez zmiany domyślnych nastaw, wyłączenia zbędnych usług i potwierdzenia konfiguracji przez drugą osobę (zasada czterech oczu).
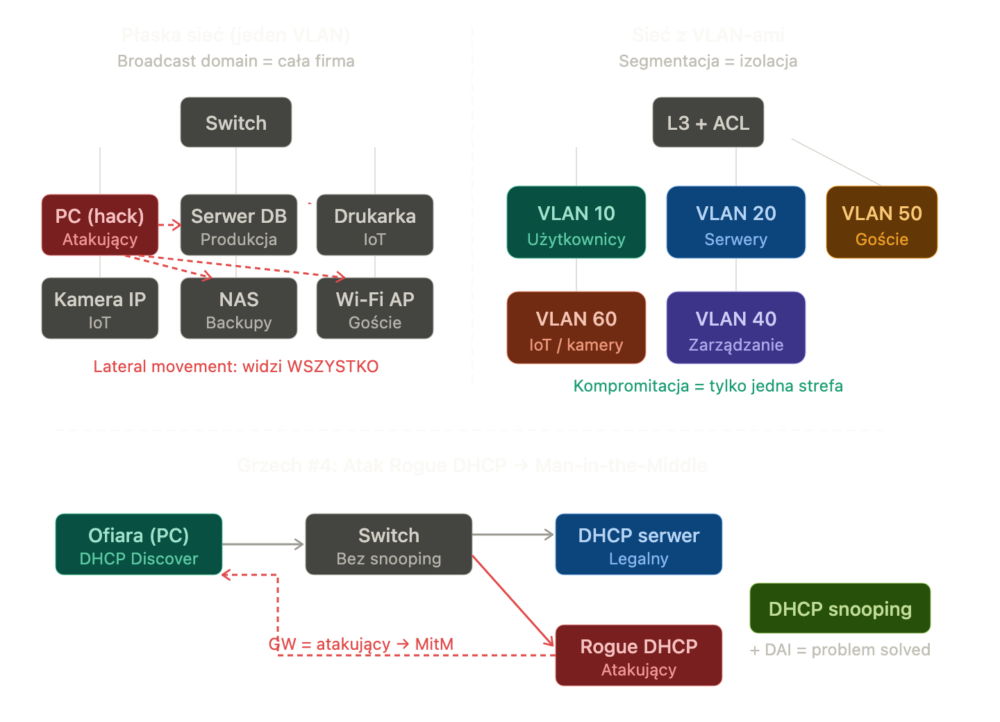
“Po co nam VLAN-y, mamy 50 komputerów, nie korporację” © Admin. A potem do tej samej sieci podpięte są: stacje robocze, serwery produkcyjne, drukarki, kamery IP, Wi-Fi dla gości, IoT i system kontroli dostępu do budynku. Wszystko w jednej domenie broadcastowej, jedna pula adresów klasy C, a la 192.168.1.0/24 albo — co gorsza — 10.0.0.0/16. Znacie to?
Drugi powód to fakt, że sama konfiguracja VLAN-ów wymaga wiedzy, czasu i planowania. Jeśli admin dostał switch “na biurko” i nie ma dokumentacji sieci, to nie będzie dzielił czegoś, czego nikt nie zaplanował.
Co z tym zrobi pentester?
Faza Lateral movement. Atakujemy jedną stację (np. phishing, pendrive na parkingu, podatna drukarka) i od razu widzę w tablicy ARP cache: serwery baz danych, kontrolery domeny, NAS-y z backupami. Nie muszę się nigdzie “tunelować” – jestem w tej samej podsieci. Skanowanie, sniffing, ataki ARP spoofing – a po co to komu? 🙂
Detekcja i obrona
Sprawdźcie, ile unikalnych podsieci macie w infrastrukturze vs ile powinniście mieć. Jeśli odpowiedź brzmi “jedna” — to jest Wasz problem. Przeskanujcie swoją sieć nmapem:
nmap -sn 192.168.1.0/24 -oG - | grep "Up" | wc -l |
Konfiguracja VLANów na przykładzie Cisco powinno przebiegać podobnie:
! Tworzenie VLAN-ów z opisami |
Inter-VLAN routing z listą ACL (w warstwie trzeciej):
! Subinterfejsy |
Minimalna segmentacja sieci powinna obejmować pięć stref: zarządzanie, serwery, użytkownicy, IoT/OT, goście. W środowisku NIS 2 do tego powinno jeszcze dojść DMZ i dedykowany VLAN dla monitoringu (jak SOC).
Wchodzę do budynku (social engineering albo po prostu salka konferencyjna), wpinam laptop do gniazdka RJ45 w ścianie, dostaję adres z DHCP — i jestem w sieci wewnętrznej. Mogę postawić narzędzie jak Responder i zbierać hashe NTLMv2, robić ARP spoofing, skanować infrastrukturę. W wielu firmach gniazdka w recepcji, salach konferencyjnych i korytarzach prowadzą do tego samego VLAN-u co stacje robocze.
Detekcja i obrona
Dobrą praktyką na starcie powinna być solidnie prowadzona dokumentacja portów, wskazująca które są używane (i do czego, dla kogo), a które nie są używane. I te drugie powinny być wyraźnie opisane, np. słowem UNUSED. Te porty również powinny być wyłączone. Często spotykanym rozwiązaniem jest włączenie mechanizmu port-security, a także standardu 802.1X (dla Cisco).
! Ograniczenie liczby MAC adresów na porcie |
“DHCP po prostu działa” © Admin i prawdopodobnie nawet nie myśli, że cyberzbój może podstawić swój własny serwer w sieci. Po co? Serwer Rogue DHCP zaczyna przydzielać komputerom firmowym swoją adresację IP jednocześnie ustawiając bramę domyślną do komunikacji na samego siebie. Czyli cały ruch z komputerów ofiar trafiają właśnie do przestępczego serwera jako forma ataku Man-in-the-Middle (MiTM). Jednak drugą formą ataku może być także “zagłodzenie” serwera DHCP, czyli DHCP Starvation Attack, gdzie atakujący generuje tysiące fałszywych żądań pakietów DHCP i wyczerpuje pulę adresów. Tym samym nikt nowy nie dostanie IP.
Pentester mógłby zrobić tak:
# Rogue DHCP + MitM (Ettercap / Bettercap)sudo bettercap -iface eth0> set dhcp6.spoof.domains *> dhcp6.spoof on |
Detekcja i obrona
Wykrycie takie serwera w sieci może sprowadzać się do zastosowania dwóch technik: DHCP Snooping oraz Dynamic ARP Inspection.
! Włączenie globalnieip dhcp snooping vlan 10,20,30 |
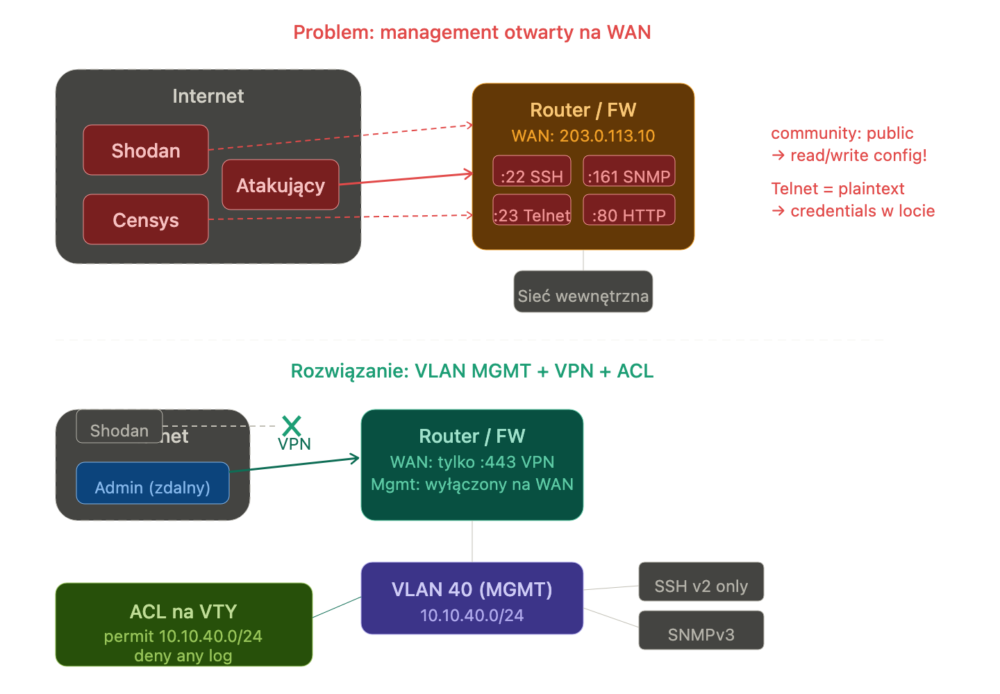
Admin konfiguruje router zdalnie z domu i zostawia “dla wygody obsługi awarii” otwarte porty na interfejsie WAN, np. SSH/HTTPS myśląc, że tylko on zna IP i port! Problem polega na tym, że wyszukiwarki jak Shodan czy ZoomEye wiedzą o tym IP szybciej niż admin zdąży zamknąć terminal. Podobnie mogłoby być z protokołem SNMP z community string public. De facto byłby to dostęp do konfiguracji urządzenia… . Cyberzbój to wykorzysta:
# Shodan — szukamy routerów Cisco z otwartym Telnetem |
Detekcja i obrona
Obrona przed tego typu sytuacją to przede wszystkim ograniczenie dostępności i widoczności czegokolwiek w stronę Internetu. W każdej firmie warstwa zarządzania powinna być dostępna wyłącznie z dedykowanego VLANu MGMT. Interfejsy publiczne = zero usług i połączeń do zarządzania infrastrukturą. Jeżeli jest potrzebny dostęp zdalny – można poradzić sobie VPN-em.
Ograniczenia dla Cisco:
! SSH tylko, Telnet off |
“Przecież to LAN, jest bezpiecznie” © Admin. To założenie powinno umrzeć gdzieś w okolicach 2009 roku, ale wciąż żyje i ma się dobrze. W wielu firmach panel zarządzania przełącznikiem to HTTP. Telnet pozostaje włączony, a SNMP jest w wersji v1. Jira, Wiki i Confluence działają po HTTP, bo przecież “certyfikat to dodatkowa robota i punkt awarii jak się zapomni”. W modelu Zero Trust, który NIS 2 sugeruje wprost – ruch wewnętrzny jest traktowany z takim samym brakiem zaufania jak ruch z Internetu. Zatem po uzyskaniu dostępu do sieci cyberzbój mógłby zrobić:
# Przechwytywanie credentiali na LAN-ie |
Wystarczy zapewne kilkanaście minut żeby zebrać loginy do panelu zarządzania, hasła do wewnętrznych aplikacji.
Detekcja i obrona
W metodach obrony ponownie wskazuję na konieczność wyłączenia przestarzałych i niebezpiecznych metod komunikacji, a także dodanie warstwy szyfrowania. Przykładowo włączenie SSH, wyłączenie Telnet i konfiguracja infrastruktury klucza PKI czy certyfikatów (Let’s Encrypt jest darmowy…)
! Generowanie klucza RSA (minimum 2048 bitów) |
Firewalle rosną w infrastrukturze organicznie. Ktoś potrzebuje dostęp do serwera – admin dodaje regułę. Nikt jednak nie usuwa reguł po zakończeniu projektu. Po dwóch latach jest 500 reguł z czego połowa jest nieaktualna, a kolejne 30% nawzajem się przysłania. Na samym dole widnieje wstydliwe permit ip any any, które ktoś dodał na chwilę podczas troubleshootingu w 2019 roku. Drugi dosyć klasyczny problem to błędna kolejność list ACL na routerze. Tzn. admin dopisuje reguły na końcu. Cyberzbój przeskanuje dostępne porty i odkryje, że firewall wpuszcza ruch na portach, które powinny być zamknięte.
Detekcja i obrona
Najprostszą metodą detekcji jest sprawdzenie hit count, czyli reguł z zerowymi trafieniami – to będą nasi kandydaci do usunięcia po takim audycie.
! Sprawdzenie hitcountów — reguły z zerowymi trafieniami to kandydaci do usunięcia |
Warto także skonfigurować logowanie na regule deny – bo bez tego nie wiadomo co firewall blokuje. Przegląd reguł co jakiś czas, np. kwartał też będzie rozsądny. Pamiętajmy także, że permit any any na produkcji będzie złym pomysłem. W listach kontroli dostępu też należy pamiętać o zasadzie Least Privilege, czyli ACL powinien zaczynać się od najbardziej specyficznych reguł i kończyć na deny ip any any log.
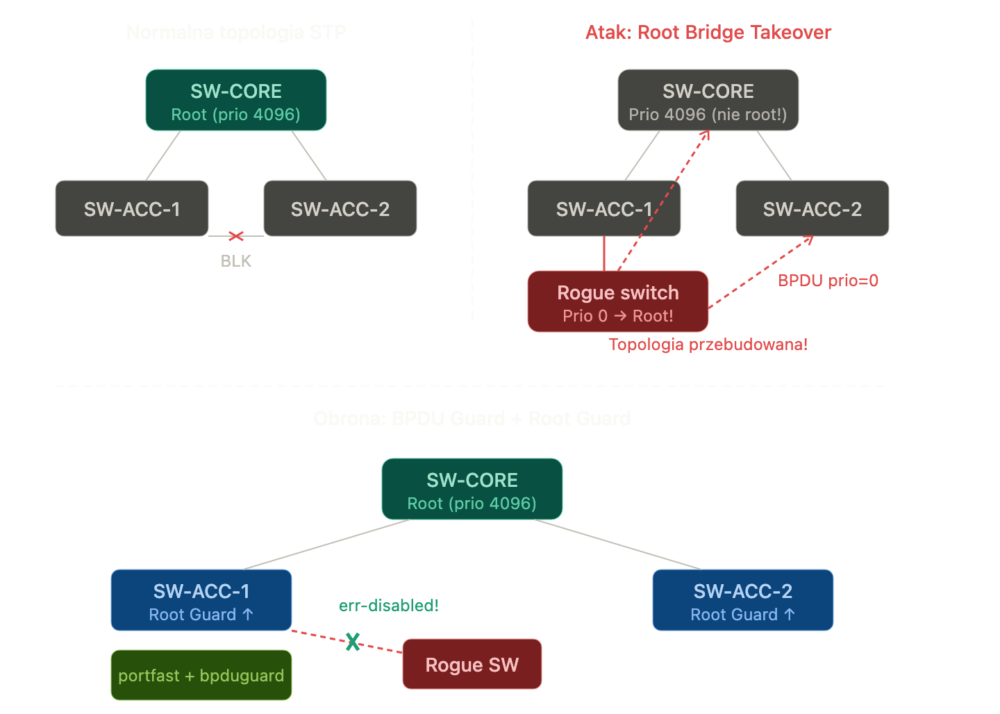
Spanning Tree Protocol (STP) to jeden z tych protokołów które działają same – dopóki nie zaczną działać źle. W małych firmach STP jest często w ogóle nie konfigurowane, a w większych – ktoś podłączy switch bez mechanizmu BPDU Guard i utworzy pętlę, która w ciągu sekund generuje sztorm rozgłoszeniowy (broadcast storm) i kładzie całą warstwę L2. Jeszcze gorszy scenariusz to brak kontroli nad Root Bridge. Domyślnie root wygrywa urządzenie z najniższym Bridge ID (priorytet + MAC). Jeśli ktoś wepnie nowy switch z niższym priorytetem (lub po prostu starszy switch z niższym MAC-iem), ten nowy switch staje się rootem – i cała topologia STP się przebudowuje. W najlepszym razie minutowe przerwy w ruchu. W najgorszym – pętla.
Atak STP Root Bridge Takeover polega na wpięciu urządzenia z priorytetem 0 i dzięki temu stanie się rootem dla STP. Zmiana topologii drzewa pozwala na przechwycenie ruchu.
Detekcja i obrona
Najlepszą metodą jest konfiguracja na każdym porcie jego roli (access lub trunk) a także mechanizmu BPDU Guard i portfast. Z kolei na trunkach do warstwy dystrybucyjnej – root guard. To nie jest opcjonalny hardening, moim zdaniem to absolutne minimum. Bez tego jednego nieautoryzowane urządzenie może położyć całą sieć w sekundę.
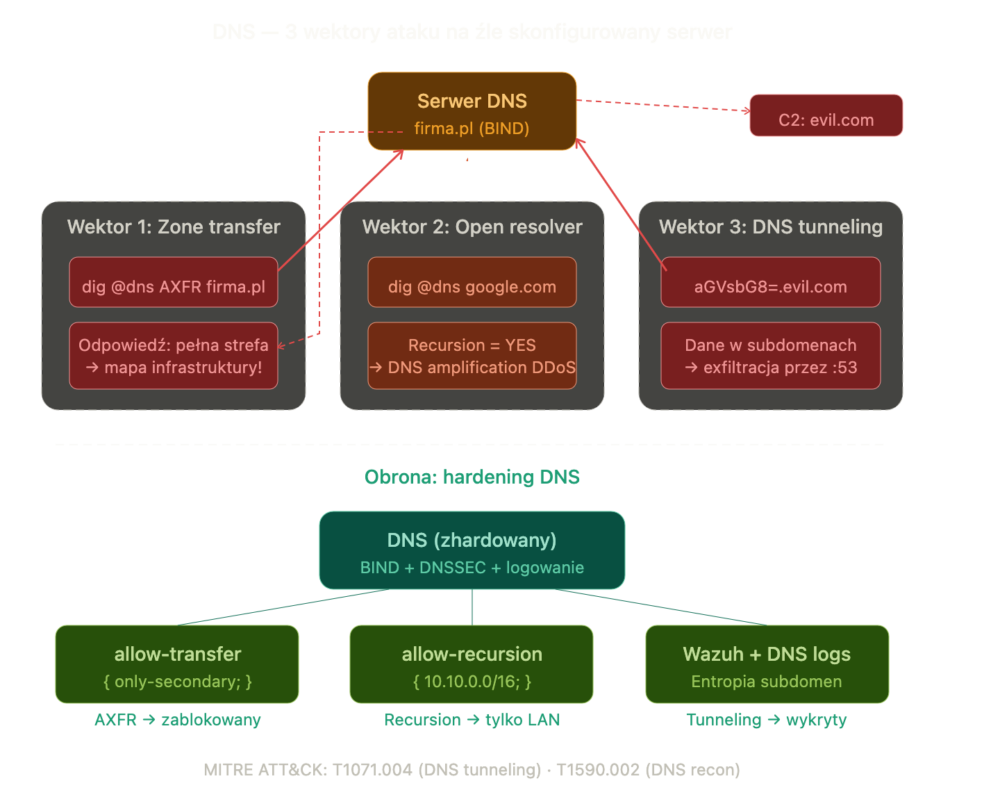
DNS to usługa rozwiązywania nazw na adresy IP. Niezbyt często wymaga konfiguracji, jednak zwykle w każdej infrastrukturze… po prostu jest. Co za tym idzie, bez znajomości jak działa i wektorów ataku, w infrastrukturze mogą pozostawać otwarte resolvery, nieograniczony transfer stref. Do tego dochodzi brak logowania zapytań DNS (bo duży ruch generują), starsze wersje narzędzia BIND czy całkowity brak DNSSEC. Warto zwrócić uwagę, że przez DNS to w sumie przechodzi każde połączenie w sieci. Jeżeli atakujący przejmie DNS to przejmie de facto ruch aplikacyjny. Często zdarza się komunikacja z serwerem C2 (Command and Control) czy eksfiltracja właśnie za pomocą tego protokołu.
# Próba zone transfer (AXFR) — jeśli działa, mamy pełną mapę infrastrukturydig @dns.firma.pl firma.pl AXFR |
Detekcja i obrona
W metodach ograniczających powierzchnie ataków warto ograniczyć możliwość transferu stref, blokady DNS z zewnątrz, a także monitoring tego protokołu (detekcja tunnelingu):
// /etc/bind/named.conf.options |
Monitoring może zapewnić system SIEM Wazuh (z którego też szkolimy), który na podstawie analizy logów potrafi wykryć anomalie jak wysoka entropia nazw domen czy zbyt długie etykiety subdomen. Wazuh operuje na regułach alertowania i takowa mogłaby wyglądać następująco:
<group=”dns attacks,”> |
DNS tak naprawdę zasługuje na osobny audyt.
Bo monitoring “kosztuje” – czasem realnie (licencje), częściej mentalnie (“nie mamy czasu tego ogarnąć” © Admin). A bez monitoringu nie wiecie o żadnym z powyższych dziewięciu grzechów. Domyślne hasło? Nikt nie zauważył. Rogue DHCP? Użytkownicy narzekali, admin zrestartował switch. DNS tunneling? Dane wyciekały miesiącami. To jest najpoważniejszy grzech, bo jest multiplikatorem wszystkich pozostałych. Jak to wygląda w praktyce?
Detekcja i obrona
Instalacja Wazuha i Zabbixa nie jest super złożona jeżeli nasza infrastruktura nie jest gigantyczna. Warto uruchomić centralny system logowania i inwentaryzacji tymi dwoma narzędziami gdyż potencjał na rozwinięcie się problemu do skali zatrzymania działania firmy będzie tym mniejszy im lepiej infrastruktura będzie monitorowana i zarządzana. Poniżej zestawienie możliwości logowań Syslog, NetFlow i SNMP Traps:
! Wysyłanie logów do centralnego syslog (np. Wazuh / rsyslog) |
Moją rekomendacją absolutne minimum to:
Podsumowując, sieć to fundament każdej infrastruktury IT. Jeśli ten fundament jest dziurawy – nie ma znaczenia jak świetny macie firewall, SIEM, czy EDR na endpointach. Atakujący i tak znajdzie drogę, bo warstwy niżej nikt nie pilnuje.
Większość opisanych w tym artykule zagadnień pokrywa certyfikacja CompTIA Network+ – od modelu OSI, przez VLAN-y, STP, 802.1X, DNS, po monitoring i troubleshooting. Jeśli chcecie uporządkować tę wiedzę od zera – albo uzupełnić luki, które dziś odkryliście – zapraszam na nasze szkolenie:
CompTIA Network+ w Sekuraku: sklep.securitum.pl/comptia-network-plus
Prowadzący: Piotr Wojciechowski – człowiek, który sieci je na śniadanie.
A jeśli oprócz sieci chcecie też ogarnąć bezpieczeństwo od strony certyfikacyjnej – zerknijcie na CompTIA Security+: sklep.securitum.pl/comptia-security-plus

Grzech #1 z domyślnymi hasłami to niestety rzeczywistość