Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej

Nagłówki HTTP, URL, URI, żądania, odpowiedzi, kodowanie procentowe, formularze HTML, parametry przesyłane protokołem HTTP, różne implementacje serwerów HTTP skutkujące problemami bezpieczeństwa – to tylko kilka elementów, którymi zajmę się w tym tekście. Początkujący czytelnicy poznają podstawy koniecznie do dalszego zgłębiania tematyki bezpieczeństwa aplikacji webowych, nieco bardziej zaawansowani będą mieć okazję do spokojnego uporządkowania wiedzy.
W tekście skupię się na podstawach dotyczących protokołu HTTP w wersji pierwszej (dostępna jest też wersja druga: https://tools.ietf.org/html/rfc7540, trwają prace nad trzecią: https://quicwg.org/base-drafts/draft-ietf-quic-http.html). Informacje, które przedstawiam, kierowane są przede wszystkim do osób skupionych na tematyce bezpieczeństwa aplikacji WWW. Nie jest to kompendium dotyczące protokołu HTTP. Zainteresowanych w pełni encyklopedyczną wiedzą odsyłam do dokumentu RFC opisującego HTTP w wersji 1.1: https://tools.ietf.org/html/rfc7230. Dla jasności przekazu dodam, że nie wspominam o elementach związanych z HTTPS.
Formalne specyfikacje, utarte przyzwyczajenia oraz rzeczywistość to trzy różne, często odległe sprawy. Wiele problemów bezpieczeństwa wynika właśnie z nieoczywistych różnic pomiędzy tymi trzema obszarami. Przykłady? Przejdźmy do konkretów dotyczących protokołu HTTP.
Najczęściej spotkamy się z komunikacją HTTP odbywającą się z wykorzystaniem protokołu TCP (choć czasem można spotkać wykorzystanie protokołu UDP, patrz np.: https://en.wikipedia.org/wiki/Simple_Service_Discovery_Protocol).
Komunikacja HTTP realizowana jest poprzez wysłanie żądania (request) do serwera, który następnie generuje odpowiedź (response). Przykład tego typu komunikacji można zobaczyć na poniższym rysunku:
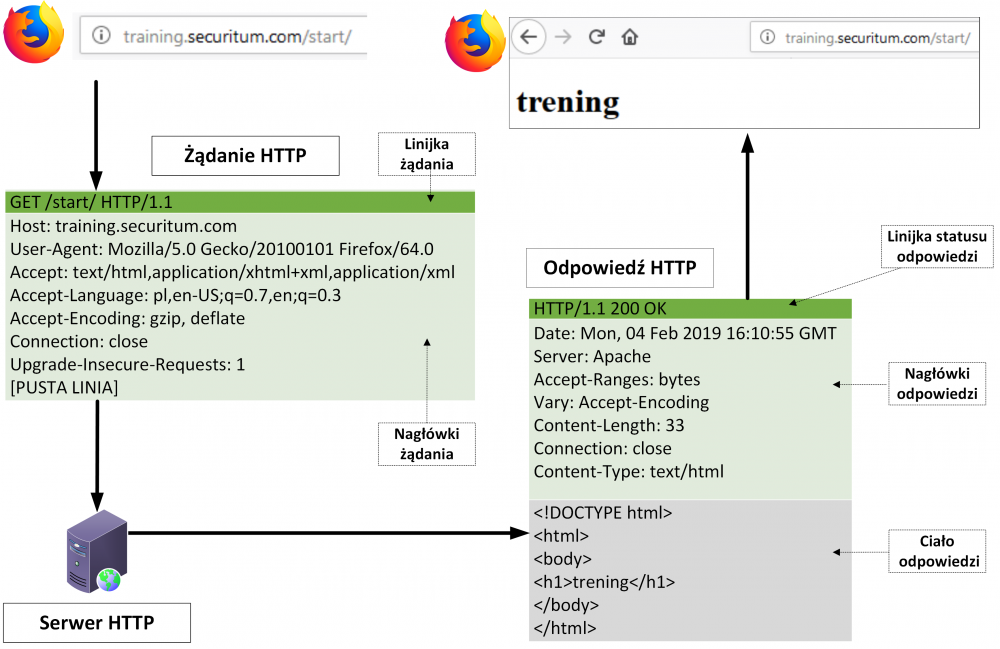
Rysunek 1. podstawy komunikacji HTTP
Analizę naszej komunikacji zacznijmy od żądania HTTP (dla uproszczenia przykładu usunąłem z niego niewymagane nagłówki):
Pierwsza linijka żądania zawiera:
Zwracam uwagę na spacje, które rozdzielają powyższe elementy – musi być ich dokładnie dwie – zgodnie ze strukturą:
METODA[spacja]URL[spacja]WERSJA_HTTP
Druga linijka powyższego żądania zawiera nagłówek. Nazwa nagłówka to: Host, a jego wartość: training.securitum.com
W formie bardziej niskopoziomowej komunikacja ta wygląda w następujący sposób:
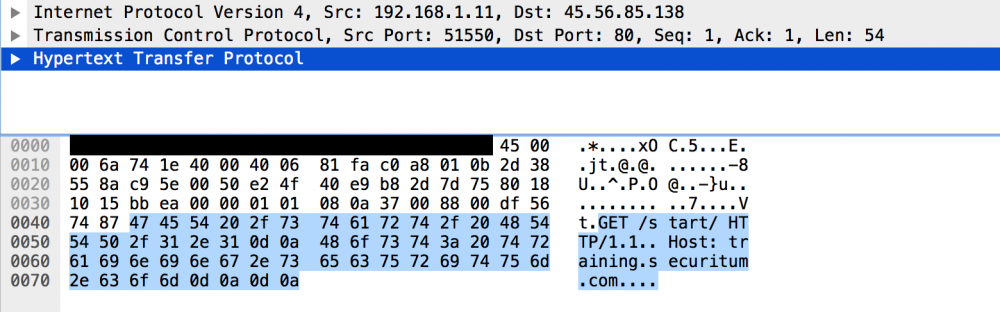
Rysunek 2. komunikacja HTTP, warstwa Ethernet została celowo pominięta.
W tym miejscu warto zwrócić uwagę na ostatnie cztery (zapisane szesnastkowo) znaki: 0d0a0d0a. Ciąg: 0d0a to separator linii w protokole HTTP. Często ciąg ten oznaczany jest jako CRLF. Na marginesie dodam, że po polsku ktoś zaproponował całkiem poetyckie tłumaczenie nieco suchego CRLF (https://www.facebook.com/sekurak/posts/2954887951204013):
Ja bym poszedł bardziej w onomatopeję: KSZSZDING! (Zrozumieją tylko starzy, co mieli maszynę do pisania).
Mamy więc jeden KSZSZDING! po nagłówku Host oraz drugi po wszystkich nagłówkach (wymaga tego od nas protokół HTTP).
Czasem możemy przeczytać, że po nagłówkach w żądaniu HTTP występuje ‘pusta linia’. Czym ona jest? Wspominanym powyżej ciągiem 0d0a0d0a, czyli inaczej są to dwa następujące po sobie CRLF.
Po co skupiam się nad takim szczegółem? Ponieważ niektórzy w ferworze walki wysyłają żądanie HTTP tylko z jednym znakiem końca linii, znajdującym się po nagłówkach, co nie jest poprawne i kończy się zazwyczaj oczekiwaniem serwera HTTP właśnie na znak CRLF (wygląda to tak, jakby serwer nie odpowiadał…).
Warto w tym miejscu wykonać proste ćwiczenie. Korzystając z bezpłatnej wersji narzędzia Burp Suite (patrz: https://portswigger.net/burp/communitydownload oraz film wprowadzający tutaj: https://sekurak.pl/movies/screencast_burp_starter_sub04-20171125.mp4), wyślijmy żądanie HTTP, kończąc je tylko jednym złamaniem linii. Po wysłaniu komunikacji nie dostajemy odpowiedzi (lub po jakimś czasie dostaniemy z serwera HTTP błąd: Request Timeout):
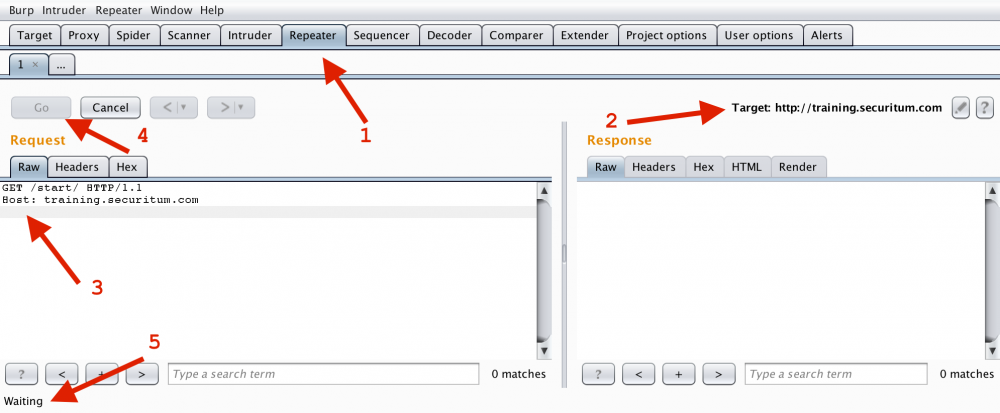
Rysunek 3. tylko jeden ciąg CRLF po ostatnim nagłówku, skutkuje oczekiwaniem (punkt 5.)
W przypadku dwóch znaków końca linii wszystko pójdzie gładko:
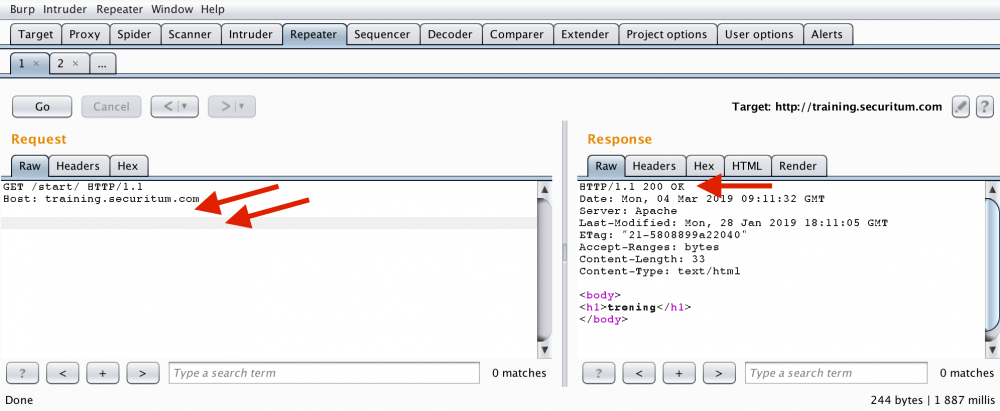
Rysunek 4. poprawnie skonstruowane żądanie HTTP
Dociekliwi czytelnicy pewnie zauważą, że na żądaniu widocznym na Rysunku 4. widać dwie puste linie (nie jedną jak napisałem wcześniej). To jak w końcu ma to wyglądać? Jeszcze raz przypomnę – specyfikacja HTTP mówi o wymaganych dwóch ciągach 0d0a (CRLF tudzież swojski KSZSZDING) po ostatnim nagłówku. Część osób interpretuje to jako jedną pustą linię, ale w niektórych przypadkach (Burp Suite) widzimy dwie. Obie interpretacje są poprawne, ważne tylko żeby realna komunikacja wyglądała jak na Rysunku 2. (mam na myśli sam koniec żądania).
Po wysłaniu żądania serwer odpowiada nam w taki sposób:
<body>
<h1>trening</h1>
</body>
Widzimy tutaj następujące elementy:
Wróćmy do żądania HTTP opisanego wcześniej i omówmy nieco dokładniej jego elementy.
Tym razem spróbujemy użyć innych metod niż GET. Specyfikacja HTTP definiuje ich kilka (por. https://tools.ietf.org/html/rfc2616#section-5.1.1), realnie można spotkać ich nawet kilkadziesiąt. Na początek spróbujmy wysłać żądanie metodą HEAD:
Dostaniemy analogiczną odpowiedź jak wcześniej, ale już bez ciała odpowiedzi (jak widać, poprawna odpowiedź HTTP nie musi go zawierać), choć z jedną pustą linijką na końcu:
Uwaga: dla uproszczenia, w kolejnych przykładach pomijał będę oznaczenie [pusta-linia].
Gdzie taka metoda może się przydać? Np. podczas próby siłowego lokalizowania pewnych ukrytych plików i katalogów:
W odpowiedzi uzyskujemy informację bez ciała odpowiedzi – dzięki temu przyspieszamy pojedynczy test (serwer musi wysłać mniej bajtów w odpowiedzi):
Warto zauważyć, że zasób / istnieje (otrzymaliśmy kod odpowiedzi 200), zasób /test nie istnieje (otrzymaliśmy kod błędu 404). Oczywiście nie zawsze tak musi być – serwer przykładowo może zwrócić kod 200, a o problemie poinformować nas w ciele odpowiedzi.
Jakie są dostępne inne metody? Np. OPTIONS wskazująca obsługiwane przez serwer metody (warto pamiętać, że informacja zwracana w odpowiedzi nie musi być zawsze prawdziwa…):
W kontekście naszych rozważań szczególnie niebezpieczna bywa metoda PUT (często jest ona domyślnie wyłączona), umożliwiająca tworzenie plików na serwerze HTTP:
PUT /test2.php HTTP/1.1
Host: training.securitum.com
Content-Length: 19
<?php phpinfo(); ?>
Jak widzimy, w ciele żądania podajemy zawartość pliku, a w pierwszej linijce – jego nazwę. Jeśli metoda jest obsługiwana, moglibyśmy teraz wysłać żądanie do nowo utworzonego pliku test2.php – i w zasadzie mamy możliwość wykonania dowolnego kodu na serwerze!
Przy okazji warto też dodać, że metody nie zawsze muszą być używane wielkimi literami.
Może metoda PUT jest zabroniona, ale już pUt, nie?
<?php phpinfo(); ?>
W tym miejscu warto też wspomnieć, że po ciele zapytania nie mamy już złamania linii (CRLF). Może ono tam występować, ale będzie traktowane jako zawartość ciała zapytania.
Na wstępie zaznaczę, że w kontekście HTTP bardzo popularnym terminem jest URL (Uniform Resource Locator). Historycznie (patrz: https://tools.ietf.org/html/rfc1738) był to po prostu adres, którego można użyć w HTML-owym hiperlinku, np.:
Często “adres URL” to po prostu ciąg, który wpisujemy w pasek adresu (nazywany czasem wprost: paskiem URL) przeglądarki.
Wygląda prosto oraz intuicyjnie, prawda? Problem w tym, że w wielu specyfikacjach (dotyczących również protokołu HTTP, patrz np.: https://tools.ietf.org/html/rfc7230), nie znajdziemy pojęcia URL. Często mowa będzie jedynie o URI (Uniform Resource Identifier).
Formalnie rzecz ujmując, URL-e są podzbiorem zbioru URI (Uniform Resource Locator): https://tools.ietf.org/html/rfc3986. Czy powinniśmy więc wymazać z pamięci “herezję URL-i” i posługiwać się pojęciem URI? Zdecydowanie nie. Wiele osób używa tych terminów zamiennie (bez straty na precyzji rozumowania). Powstał nawet stosowny dokument RFC wyjaśniający całe zamieszanie: https://tools.ietf.org/html/rfc3305.
W każdym razie na nasze potrzeby będziemy używali zamiennie obu terminów URL oraz URI.
Bardzo często można spotkać się z tego typu URL-ami:
http://trainig.securitum.com/katalog/test.php?parametr=wartość#fragment
Ale możemy go rozszerzyć (zauważmy inny port, oraz opcjonalną część dotyczącą użytkownika i hasła):
Zwróćmy uwagę na fragment, to popularne odwołanie do kotwicy w HTML, a wpisanie takiego URL-a w przeglądarkę nie wysyła do serwera znaku # oraz tego, co znajduje się po nim.
Czasem znak @ też bywa problematyczny, bo jak np. zinterpretować następujący URL?
Czy w ogóle jest on poprawny? Do jakiej domeny prowadzi?
Co ciekawe, użycie URL-a z użytkownikiem i hasłem bezpośrednio w żądaniu HTTP nie jest poprawne:
Czy zatem zawsze w odpowiedzi otrzymamy poniższy błąd?
Często tak, choć podejrzewam, że mogą znaleźć się serwery HTTP, które bez problemu pozwolą na tego typu URI.
URL-e mogą też mieć formę względną, np.:
I to właśnie ją najczęściej widzimy w żądaniach HTTP.
Uzbrojeni w podstawy teoretyczne dotyczące pojęcia URL (czy też URI) zobaczmy prosty przykład żądania:
W tym przypadku URL jest względny: /test jednak śmiało możemy tu również użyć wersji bezwzględnej:
<body>
<h1>trening</h1>
</body>
Rzadko można znaleźć tego typu URL w realnych żądaniach HTTP, ale jest to jak najbardziej poprawne i może będzie miało jakieś ciekawe implikacje związane z bezpieczeństwem?
W powyższym przykładzie wartość nagłówka Host zostanie najczęściej zignorowana przez serwer. Tego typu zachowanie może być czasem wykorzystane do zlokalizowania podatności. Przykład można znaleźć w poniższej pracy, w sekcji Host overriding:
https://portswigger.net/blog/cracking-the-lens-targeting-https-hidden-attack-surface
Some servers effectively whitelist the host header, but forget that the request line can also specify a host that takes precedence over the host header.
Czyli z jednej strony po stronie serwerowej sprawdzane jest czy nagłówek Host przyjmuje jedną z dozwolonych wartości (czyli domeny, do których można się odwołać), ale ktoś zapomniał, że pierwszeństwo ma URL z pierwszej linijki!
Warto tutaj zwrócić uwagę jeszcze na jeden element. URL jest często normalizowany przez przeglądarkę, np. wpisanie w pasek przeglądarki adresu: training.securitum.com/test/../ powoduje wysłanie do serwera wersji znormalizowanej, czyli:
Dlatego w naszych zastosowaniach do wysyłania żądań HTTP lepiej posługiwać się innym narzędziem niż przeglądarka – np. Burp Suite czy OWASP ZAP.
Do tej pory skupiliśmy się głównie na pierwszej linijce żądania. Teraz zobaczmy na jedyny, wymagany w wersji 1.1 protokołu HTTP nagłówek Host. Czy podana tutaj nazwa to po prostu adres domenowy, który wpisujemy w przeglądarce? Bardzo często odpowiedź brzmi tak, ale sprawdźmy, w jaki sposób przeglądarka łączy się do serwera HTTP:
Czy możemy w wartości nagłówka Host użyć innej nazwy? Jak najbardziej tak – nawet takiej, której nie mamy w DNS:
Host trening2.securitum.com not found: 3(NXDOMAIN)
<body>
<h1>to jakas staroc</h1>
</body>
Zauważmy, że ta metoda może służyć do lokalizowania ukrytych domen wirtualnych na danym serwerze, a to, że nie ma ich w DNS…, w niczym nie przeszkadza. Konkretny przykład tego typu działania można zobaczyć tutaj: https://sites.google.com/site/testsitehacking/10k-host-header
Autor znaleziska przez manipulacje nagłówkiem Host uzyskał dostęp do domeny yaqs.googleplex.com, gdzie znajdowały się poufne informacje firmy Google. Za zgłoszenie podatności badacz otrzymał $10 000 w ramach oficjalnego programu bug bounty.
Czy istnieją inne nagłówki HTTP? Oczywiście. Warto przy tym wspomnieć, że czymś innym są nagłówki przekazywane w żądaniu, a czym innym nagłówki wysyłane w odpowiedzi. Część nagłówków może nazywać się tak samo, np. Content-Type. W takich przypadkach warto dodać, czy chodzi nam o nagłówek żądania czy odpowiedzi.
<body>
<h1>to jakas staroc</h1>
</body>
Kilka nagłówków wartych wspomnienia:
Na koniec warto wspomnieć, że nazwy nagłówków mogą być pisane dowolną kombinacją małych i dużych liter. np.: hOSt
Więcej informacji o nagłówkach można znaleźć tutaj:
To jeden z najistotniejszych, podstawowych tematów w kontekście bezpieczeństwa. Przytłaczająca liczba podatności w aplikacjach webowych może być wykorzystana poprzez odpowiednio (złośliwe) manipulowanie wartościami przekazywanymi do aplikacji.
Zatem, w którym miejscu żądania HTTP mogą znaleźć się parametry? Nieco wymijająca odpowiedź brzmi: wszędzie. Poczynając od linijki żądania, przez nagłówki, aż po ciało.
Przyjrzyjmy się kilku popularnym miejscom, w których możemy znaleźć parametry.
Parametry przekazywane w URL najczęściej zobaczymy w zapytaniach typu GET. Wielu z nas widziało na pewno tego typu konstrukcję, umieszczaną w pasku adresu przeglądarki internetowej:
Rysunek 5. pasek przeglądarki z parametrami
Przeglądarka na podstawie takiego adresu, realizuje następujące żądanie HTTP (ręcznie usunąłem z niego mniej istotne nagłówki):
parametr1: wartosc1
parametr2: wartosc2
Pamiętajmy, że to tylko pewna konwencja, aplikacja może równie dobrze użyć jako wartości również nazwy parametru (w naszym przypadku jest to parametr1).
Co się stanie gdy dodamy jakiś dodatkowy parametr, nieobsługiwany przez aplikację? Np. parametr3 ? Najczęściej nic:
parametr1: wartosc1
parametr2: wartosc2
Czasem jednak aplikacja analizuje wszystkie przesłane (np. metodą GET) parametry, więc warto sprawdzić, co się stanie jeśli przekażemy tego typu dodatkową wartość.
Dociekliwi czytelnicy mogą zapytać – czy da się przesłać w wartości parametru np. znak & (jak widać wyżej, ma on specjalne znaczenie) lub # (wcześniej wspomniałem, że znak # wpisany w pasek przeglądarki nie jest wysyłany do serwera)? Oczywiście można to zrobić, używając kodowania procentowego (patrz: https://tools.ietf.org/html/rfc3986), nazywanego często kodowaniem URL. Działa ono w prosty sposób: kod ASCII znaku & to szesnastkowo 26. W kodowaniu procentowym %26.
Jeśli z kolei chcemy użyć spacji w URL, musimy ją zakodować jako %20 (lub jako +). Z tego powodu użycie znaku plus też musi być zakodowane (jako %2b) – inaczej oznaczałoby zakodowaną spację.
Czy możemy zakodować inne znaki (np. w nazwie parametru)? Jak najbardziej:
parametr1: a+b
parametr2: a& b c
Dodam jeszcze, że czasem kodowanie procentowe mylone jest z kodowaniem z wykorzystaniem encji, używanym często w HTML, np.: < & To zupełnie różne kodowania i tego drugiego nie możemy użyć w URL-u.
Na koniec, warto wspomnieć, że zaleca się, aby metodą GET nie przesyłać poufnych czy wrażliwych informacji, np. haseł czy identyfikatorów sesyjnych. Dlaczego? Parametry te widać bezpośrednio w pasku URL przeglądarki. Są one domyślnie logowane przez serwery HTTP, czy widoczne na wynikach wyszukiwarek internetowych.
Drugim często spotykanym sposobem wysyłania parametrów jest przesyłanie ich w ciele żądania, korzystając z metody POST. Często w ten sposób wysyłane są dane z formularzy HTML. Przykład:
<form action=”/request.php” method=”POST”>
Podaj parametr 1: <input type=”text” name=”parametr1″><br>
Podaj parametr 2: <input type=”text” name=”parametr1″><br>
<input type=”submit”>
</form>
W tagu <form> możemy podać również parametr enctype, wskazujący przeglądarce, w jaki sposób powinna przesłać z formularza w żądaniu:
<form action=”/request.php” method=”POST” enctype=”application/x-www-form-urlencoded”>
Wartość application/x-www-form-urlencoded jest domyślna (więc jeśli chcemy z niej skorzystać, możemy całkowicie pominąć parametr enctype), inne możliwości to multipart/form-data (więcej o niej w dalszej części tekstu) oraz text/plain.
W tym momencie proponuję zrealizować proste ćwiczenie, zmieniające metodę GET na POST. W narzędziu Burp Suite (moduł Repeater) wpisujemy nieco wcześniej opisywane żądanie, następnie klikamy prawym przyciskiem i wybieramy opcję Change Request Method:

Rysunek 6. zmiana typu żądania HTTP
Wynik tej operacji jest następujący (warto zaznaczyć, że żądanie nie kończy się ciągiem CRLF; choć teoretycznie może – ale wtedy złamanie linii będzie częścią wartości parametru parametr2):
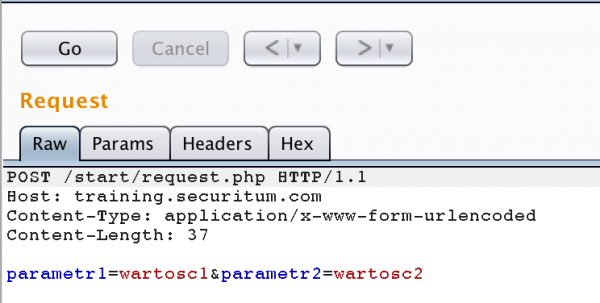
Rysunek 6. żądanie HTTP typu POST
Czy zawsze zadziała zamiana metody GET na POST (lub na odwrót)? Niekoniecznie, choć dość często jest to możliwe. Czasem atakujący uzyskujący nieautoryzowany dostęp do aplikacji, będą chcieli przekazywać parametry właśnie w tej sposób. Dlaczego? Parametry przesyłane metodą POST nie są domyślnie logowane przez serwery HTTP (w przeciwieństwie do parametrów przekazywanych w URL).
Wracając do szczegółów naszego nowego żądania, zauważmy że poza zmianą metody pojawiły się dwa dodatkowe nagłówki:
Natomiast same parametry znalazły się w ciele (po jednej pustej linijce). Uwaga – tutaj na końcu żądania nie mamy już znaków CRLF. Technicznie rzecz ujmując, mogą się tam znaleźć, ale wtedy będą częścią wartości parametru parametr2 (zmieni się wtedy również Content-Length – wskazujący na długość ciała).
Czy te same parametry mogą być przekazywane równocześnie w linijce żądania i w ciele? Jak najbardziej:
parametr1=wartosc1¶metr2=wartosc2
Niekiedy prowadzi to do powstania interesujących podatności – patrz np. luka w API WordPress-a umożliwiająca anonimową zmianę dowolnego wpisu: https://blog.sucuri.net/2017/02/content-injection-vulnerability-wordpress-rest-api.html
A co jeśli zmienilibyśmy wartość nagłówka Content-Length? Czy zostanie wysłanych mniej danych? Nic z tego – wysłane zostanie pełne żądanie, a dopiero web serwer odpowiednio przetworzy całość:
parametr1=wartosc1¶metr2=wartosc2

Rysunek 7. widok sieciowy żądania HTTP z wartością nagłówka Content-Length mniejszą niż realna zawartość ciała żądania
Takie zachowanie może czasem posłużyć np. do omijania firewalli aplikacyjnych (patrz: https://www.slideshare.net/SoroushDalili/waf-bypass-techniques-using-http-standard-and-web-servers-behaviour).
Niektórzy twierdzą, że ludzie zajmujący się bezpieczeństwem są czasem trochę złośliwi. Jest w tym chyba ziarno prawdy, bo jak nazwać wpisanie ujemnej wartości w nagłówek Content-Length? Jest to jak najbardziej możliwe, a efekty mogą być rozmaite – od błędów typu Denial of Service (patrz np.: https://tools.cisco.com/security/center/viewIpsSignature.x?signatureId=4902&signatureSubId=0) aż po potencjał na wykonanie kodu na serwerze (patrz podatność w module mod_proxy serwer HTTP Apache: http://cve.mitre.org/cgi-bin/cvename.cgi?name=can-2004-0492).
Czasem parametry wysyłane metodą POST korzystać będą właśnie z kodowania multipart/form-data – tego typu przykład najczęściej znajdziemy w formularzach uploadujących pliki. Takie żądanie wygląda np. tak:
—awnwWejh23kl
content-disposition: form-data; name=”parametr1″
wartosc
jeden
–awnwWejh23kl
content-disposition: form-data; name=”parametr2″
wartosc
dwa
–awnwWejh23kl
content-disposition: form-data; name=”nasz_plik”; filename=”file1.txt”
Content-Type: text/plain
Zawartosc pliku tekstowego
–awnwWejh23kl–
Warto zwrócić tutaj uwagę na tzw. ogranicznik (boundary, więcej o nim można poczytać tutaj: https://tools.ietf.org/html/rfc1521).
Najczęściej jest to losowa zawartość, choć mająca pewne ograniczenia (np. posiada limit długości).
Pełny ogranicznik to znaki CRLF (znak końca linii) dwa znaki minus (–) oraz wartość wskazana parametrem boundary w nagłówku. Czyli w naszym przykładzie jest to: –awnwWejh23kl (oraz wcześniejszy enter).
Ostatni ogranicznik dodatkowo posiada jeszcze na końcu kolejne dwa znaki (–). W naszym przykładzie to –awnwWejh23kl–
W skrócie nasz ogranicznik rozdziela ciało na wiele (multipart) części. W rozważanym przypadku części tych mamy trzy. Każda z nich posiada nagłówek definiujący nazwę zmiennej:
content-disposition: form-data; name=”nazwa”
Z kolei po dwóch wartościach końca linii (CRLF) następuje przekazanie wartości zmiennej. Wartość z drugiej strony kończy nasz ogranicznik. Na przykładzie poniżej widzimy zmienną o nazwie parametr1 oraz wartość:
wartosc
jeden
wartosc
jeden
–awnwWejh23kl
Pamiętajmy, że to tylko podstawy dotyczące tego typu kodowania parametrów. Jako przykład wykorzystania tego tematu do obchodzenia mechanizmów klasy WAF (Web Application Firewall) polecam pracę: “WAF Bypass Techniques – Using HTTP Standard and Web Servers’ Behaviour“, gdzie można znaleźć sporo interesujących obejść bazujących właśnie na sprytnych modyfikacjach komunikacji HTTP.
Na koniec zastanówmy się czy parametry przekazywane w ciele żądania mogą być przekazywane z wykorzystaniem metody GET? Pomysł wydaje się być trochę dziwny, ale tego typu żądanie jest poprawne i co więcej, może czasem zostać użyte do wskazania poważnych podatności (patrz: https://sekurak.pl/banalny-exploit-na-drupala-mozna-przejac-serwer-bez-uwierzytelnienia/).
Czyli popularne cookie, nazywane niekiedy niepoprawnie ‘plikami cookie’ (patrz: https://sekurak.pl/kontrowersje-wokol-cookies/). W kontekście naszych rozważań, ciastka (mogące zawierać parametry) możemy znaleźć w nagłówku Cookie żądania HTTP.
W jednym nagłówku może znaleźć się kilka różnych ciasteczek (mimo to nagłówek cały czas będzie nazywał się Cookie, nie Cookies).
W którym miejscu ciastka są wysyłane z serwera? W odpowiedzi, w nagłówku Set-Cookie.
Zobaczmy przykład obu nagłówków. Po wejściu przeglądarką na adres http://training.securitum.com/start/cookie.php serwer ustawia dwa ciastka (nagłówek odpowiedzi Set-Cookie):
HTTP/1.1 200 OK
Date: Mon, 04 Mar 2019 09:48:12 GMT
Server: Apache
Set-Cookie: testowe-ciastko1=testowa-wartosc2
Set-Cookie: testowe-ciastko2=testowa-wartosc2
Content-Length: 0
Connection: close
Content-Type: text/html; charset=UTF-8
Kolejne zapytanie z przeglądarki jest już automatycznie uzupełnione o nagłówek Cookie:
Po przeczytaniu tekstu powinniście już mieć podstawową wiedzę dotyczącą komunikacji HTTP, która na pewno przyda się w realnych eksperymentach z bezpieczeństwem aplikacji webowych. Pamiętajcie, że nie wszyscy kurczowo trzymają się specyfikacji HTTP, a czasem nawet błahe odstępstwa od utartych reguł, mogą oznaczać ciekawe wyniki (patrz np.: https://www.zdnet.com/article/vulnerability-exposes-location-of-thousands-of-malware-c-c-servers/)
–Michał Sajdak

Ładnie, +1!
fajnie, niby podstawy a szczegółowo, +1
Fajnie jakby była wersja do druku,
Dzięki super artykuł
Będzie, bo to jeden z tekstów do książki sekuraka :)
A kiedy będzie wydanie książki?
plan na wrzesień, więcej info +- niedługo – czytaj sekuraka :)
KSZSZDING rozwalił mi przeponę :)))
Bardzo ładna powtórka, nadal coś znalezione o czym już człowiek zapomniał.
Książka dopiero we wrześniu, geee , nie doczekam :)
“Shut up and take my money” :)
Dzięki za zmianę CMS, dotyczącego wydruku.
Czasami warto usiąść w fotelu i pomyśleć o tego typu sprawach. Fajnie, że są ludzie, którzy chcą się dzielić swoimi doświadczeniami z innymi za pomocą Internetu. Co byśmy bez niego dziś zrobili, ehh…
Naprawdę? Jeśli to prawda to jestem zachwycona.
Hej super artykuł, bardzo szczegółowo :) czy gdzieś w czeluściach Sekuraka macie podobny artykuł o https ? Chodzi o tą postać jawną i nie jawnę przy przesyłaniu formularzy. Pytam, bo praktycznie teraz już każda przeglądarka pyszczy i krzyczy na mnie, gdy na stronie znajduje się formularz, a nie ma SSL
Romam, “pyszczy” i “krzyczy”, bo gdzieś w źródle masz odnośnik, który używa http. Wystarczy przejrzeć źródło strony i wyeliminować wszystko co zaczyna sie od http i zamienić na https. To jest powszechny błąd(użytkownika strony), przez który mamy komunikat o niezabezpieczonej stronie. A jeżeli masz stronę w http a formularz zawiera jakieś odwołanie przez https, to należy to zmienić we wtyczce/skrypcie formularza.
Do autora: To dobrze wyłożone i widać głęboką wiedzę. I ja właśnie w związku z tą wiedzą. Desperacko potrzebuję wykładu o obsłudze żądań ale nie na temat bezpieczeństwa. Tak pod kątem SEO. Myślę, że Pan ma tą wiedzę i to dobrze ułożoną. Czy są jakieś inne materialy na ten temat? Książka, skrypt? Może konsultacje? A może po prostu odsyłacz do jakiejś lektury (może być zagraniczna).
Chodzi o jasny wykład o tych wszystkich 301, Noindex, Canonical itd. Jak działają i jak się mają takie wpisy w Nagłówku do tych w Tagach i nawzajem do siebie i jak współdziałają (lub nie) z kodami (404 itd). I co naprawdę wiadomo a co nie. Bardzo mi się spieszy i bardzo na tym zależy, pozdrawiam.