Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej

Czy chcemy, by obecne aplikacje webowe mogły działać szybciej bez ponoszenia nakładów na lepsze łącza sieciowe czy infrastrukturę serwerową? Oczywiście, że tak – i taki właśnie główny cel przyświecał twórcom protokołu HTTP/2.
Dokładniej rzecz ujmując, chodziło o zwiększenie wydajności komunikacji pomiędzy klientem (czyli najczęściej przeglądarką internetową) a serwerem, przy jednoczesnym zachowaniu maksymalnej kompatybilności z obecnie działającymi aplikacjami:
HTTP/2 is intended to be as compatible as possible with current uses of HTTP. This means that, from the application perspective, the features of the protocol are largely unchanged.
Postawiono więc wszystkim znaną i lubianą strukturę protokołu HTTP/1.1 (cały czas mamy opisywane w tym tekście żądania, odpowiedzi, metody, nagłówki czy URI), jednak zupełnie zmieniono (zoptymalizowano pod względem szybkości komunikacji) warstwę transportową.
Pierwsze widoczne gołym okiem niegospodarności protokołu HTTP/1.1 to format tekstowy komunikatów i wielokrotnie przesyłane te same nagłówki (żądania lub odpowiedzi) – w tym ciasteczka.
HTTP/2 wprowadza format binarny komunikacji oraz zaawansowaną kompresję nagłówków. W zasadzie całkowicie zmienia się sposób wykorzystania protokołu transportowego TCP: komunikacja realizowana jest jednym połączeniem TCP, którym przesyłane są ramki HTTP/2 (ang. frames).
Ramka to względnie prosta atomowa struktura protokołu HTTP/2. Dostępnych mamy 10 ich rodzajów. Na przykład na Rysunku 6 widzimy ramki o typach: SETTINGS, WINDOW_UPDATE, HEADERS. To właśnie w ramkach będziemy widzieli struktury HTTP znane z protokołu w wersji 1.1 (linijkę żądania, statusy odpowiedzi, nagłówki, ciała żądania czy odpowiedzi).
Ramki z kolei organizowane są w dwukierunkowe strumienie (ang. streams). Na przykład na Rysunku 6 ramka typu HEADERS znajduje się w strumieniu nr 1.
Kilka ramek znajdujących się w jednym strumieniu daje nam znaną z poprzednich wersji protokołu HTTP komunikację typu żądanie-odpowiedź (patrz sekcja 8.1 wspomnianego na początku tekstu dokumentu RFC):
An HTTP request/response exchange fully consumes a single stream.
Zacznijmy od przyjrzenia się wykorzystaniu protokołu TCP przez obie wersje protokołu HTTP.
W obu przypadkach korzystanie z tak zwanego trwałego połączenia TCP jest domyślne. W specyfikacji HTTP/1.1 (por. https://tools.ietf.org/html/rfc7230) czytamy:
HTTP/1.1 defaults to the use of “persistent connections”, allowing multiple requests and responses to be carried over a single connection.
Czy w HTTP/1.1 takie zachowanie jest wymagane? Nie. To samo RFC mówi:
A client that does not support persistent connections MUST send the “close” connection option in every request message.
W wolnym tłumaczeniu:
Klient, który nie wspiera trwałych połączeń, musi wysłać nagłówek connection: close w każdym żądaniu HTTP.
Komunikacja z wykorzystaniem HTTP/1.1 polega na otwarciu przez klienta HTTP jednego lub więcej połączeń TCP do serwera. W każdym połączeniu wysyłane są pary żądanie-odpowiedź. Aby wysłać kolejne żądanie HTTP danym połączeniem TCP, musimy poczekać na odpowiedź, chyba że korzystamy z tzw. pipeliningu. Mechanizm ten jest opisany w sekcji 6.3.2 wcześniej wspomnianego dokumentu RFC (https://tools.ietf.org/html/rfc7230#section-6.3.2), gdzie czytamy:
A client that supports persistent connections MAY “pipeline” its requests (i.e., send multiple requests without waiting for each response). A server (…) MUST send the corresponding responses in the same order that the requests were received.
[Klient, który wspiera trwałe połączenia, może zastosować mechanizm “pipeline” (czyli wysłać wiele żądań bez oczekiwania na odpowiedzi). Serwer musi wysłać stosowne odpowiedzi w takiej samej kolejności, w jakiej otrzymał odpowiadające im żądania.]
Z perspektywy czasu można powiedzieć, że mechanizm pipeliningu w HTTP/1.1 nie sprawdził się w praktyce. Obecne nowoczesne przeglądarki internetowe w ogóle go nie wspierają. Wykorzystują za to wiele równoległych połączeń TCP do jednego serwera (w rzeczywistych warunkach okazało się to mniej podatne na błędy i szybsze niż klasyczny pipelining). Oczywiście w tym przypadku również należy zachować pewien umiar – przeglądarki takich równoległych połączeń otwierają maksymalnie kilka. W końcu każde nowe połączenie TCP to 3-way handshake czy dodatkowe zasoby potrzebne na utrzymanie połączenia. Jeśli korzystamy z HTTPS, trzeba pamiętać, że nawiązanie sesji TLS również kosztuje.
Czy oznacza to, że możemy zapomnieć o pipeliningu i jest to tylko historyczna ciekawostka? Zdecydowanie nie – wiele serwerów HTTP cały czas wspiera ten mechanizm, a poza tym może mieć to ciekawe implikacje związane z bezpieczeństwem. Zobaczmy przykład tego typu komunikacji w narzędziu Burp Suite (zawartość pliku test.html to test1):
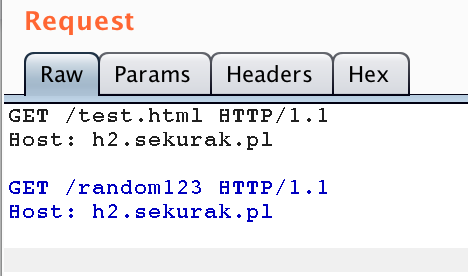
Rysunek 1. Przykład komunikacji HTTP z wykorzystaniem pipeliningu.
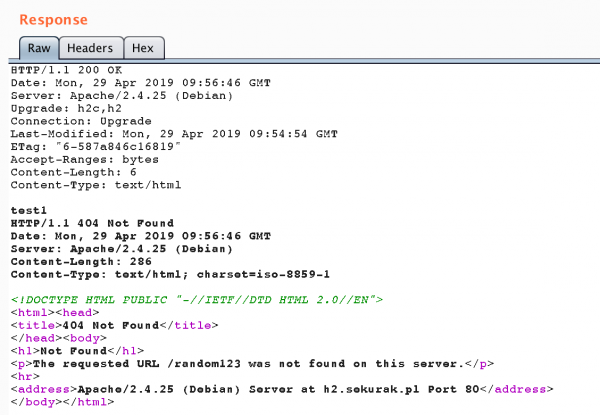
Rysunek 2. Przykład komunikacji HTTP z wykorzystaniem pipeliningu. Widoczne są dwie niezależne odpowiedzi HTTP.
Jeszcze ciekawszy jest przykład pokazany na Rysunku 3. W pierwszym momencie można pomyśleć, że jest to najzwyklejsza komunikacja HTTP/1.1. Jednak jest to zastosowanie pipeliningu przy jednoczesnym użyciu protokołu HTTP/0.9 (GET /random123). Zauważmy, że potencjalnie możliwe jest użycie tego typu mechanizmu do omijania filtrów działających przed aplikacją (w tym mechanizmów klasy WAF – Web Application Firewall). Na przykład jeśli WAF uniemożliwia dostęp do zasobu /random123 poprzez analizę linijki żądania (GET /test.html HTTP/1.1) i dodatkowo nie zna komunikacji HTTP/0.9, to być może uda się jednak skutecznie wysłać blokowane przez WAF żądanie (wyglądające dla firewalla aplikacyjnego jak ciało żądania).
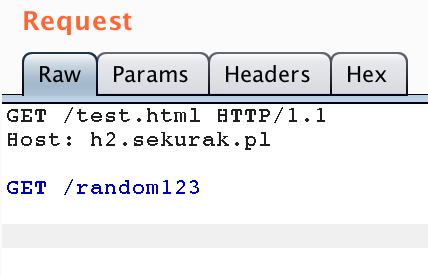
Rysunek 3. Przykład komunikacji HTTP z wykorzystaniem pipeliningu. Drugie żądanie realizowane jest protokołem HTTP/0.9.
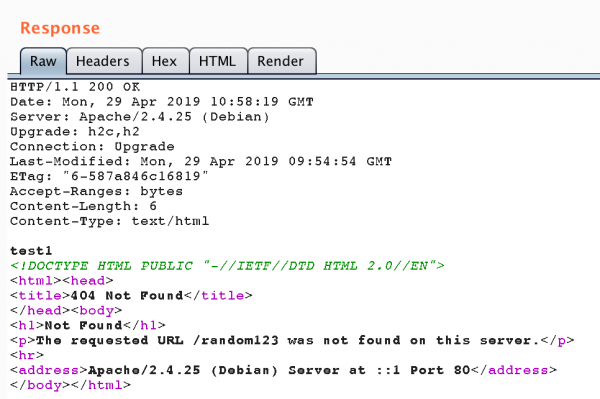
Rysunek 4. Przykład komunikacji HTTP z wykorzystaniem pipeliningu. Widoczne są dwie niezależne odpowiedzi HTTP. Druga nie zawiera nagłówków odpowiedzi.
Nowa wersja protokołu HTTP w celu poprawienia wydajności komunikacji wprowadza zamiast niezbyt udanego pipeliningu inny mechanizm – multiplexing. W jednym połączeniu HTTP/2 możemy mieć wiele ramek (ang. frames), zawierających m.in. nagłówki lub ciała (żądań lub odpowiedzi). Ramki organizowane są w tzw. strumienie (odpowiadające parze żądanie-odpowiedź). Kolejność ramek (organizowanych w strumienie) jest względnie dowolna, w szczególności żeby wysłać kolejne żądanie, nie jest konieczne czekanie na poprzednią odpowiedź.
Aby zobaczyć szczegóły tego typu struktur, prześledźmy bardziej drobiazgowo komunikację protokołem HTTP/1.x, jak i HTTP/2.
Zobaczmy prosty przykład komunikacji z serwerem HTTP:
Tutaj nie mamy nic odkrywczego. Najpierw następuje nawiązanie połączenia TCP (3-way handshake), a następnie od razu wysyłane jest pełne żądanie HTTP:
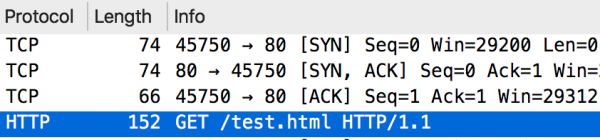
Rysunek 5. Komunikacja protokołem HTTP 1.1.
To samo żądanie w protokole HTTP/2 będzie wyglądało w nieco bardziej skomplikowany sposób:
curl --http2-prior-knowledge http://h2.sekurak.pl/test.html
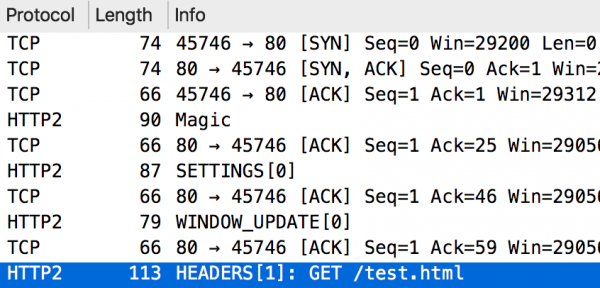
Rysunek 6. Prosta komunikacja HTTP/2. Wiersze oznaczone jako HTTP2 (w tym przykładzie) to informacje wysyłane od klienta do serwera.
Jak widzimy, komunikacja ponownie rozpoczyna się od nawiązania połączenia TCP (3-way handshake), ale do momentu wysłania żądania HTTP musimy jeszcze chwilę poczekać (to ostatni wiersz na Rysunku 6). Widać tutaj też dwa strumienie (ich identyfikatory znajdują się w nawiasach kwadratowych bezpośrednio po typie ramki). Strumień zerowy służy do przesyłania parametrów kontrolnych całego połączenia. Z kolei strumień o identyfikatorze 1 został stworzony ramką HEADERS. Odpowiedź HTTP została przedstawiona na Rysunku 7: widzimy tutaj ramkę HEADERS (nagłówki odpowiedzi) oraz ramkę DATA (ciało odpowiedzi). Niewiele później następuje prośba o zamknięcie całego połączenia TCP (ramka GOAWAY).

Rysunek 7. Odpowiedź HTTP/2.
Same nagłówki w HTTP/2 również mogą wydać się nieco bardziej skomplikowane niż w HTTP/1.1. Na Rysunku 8 widzimy m.in. znane nam nagłówki user-agent czy accept (zapisane w formie binarnej), ale są też tzw. pseudo nagłówki rozpoczynające się od znaku dwukropka, np.: :method
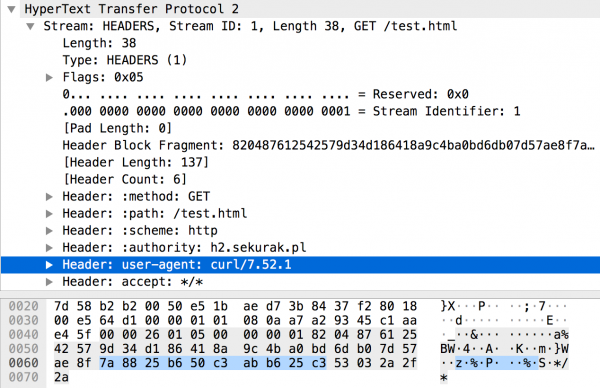
Rysunek 8. Szczegóły ramki typu HEADERS.
Żeby całość jeszcze bardziej skomplikować, możliwa jest również komunikacja protokołem HTTP/2 zaczynająca się od klasycznej komunikacji HTTP/1.1 zawierającej kilka dodatkowych nagłówków, m.in. Upgrade. Taki wariant stosowany jest bardzo często w przypadku, kiedy klient nie wie, czy serwer obsługuje protokół HTTP/2. Przeglądarka próbuje więc połączyć się za pomocą HTTP/1.1, a następnie od razu przełączyć się na HTTP/2. Przykład inicjacji takiej komunikacji widzimy na Rysunku 9.
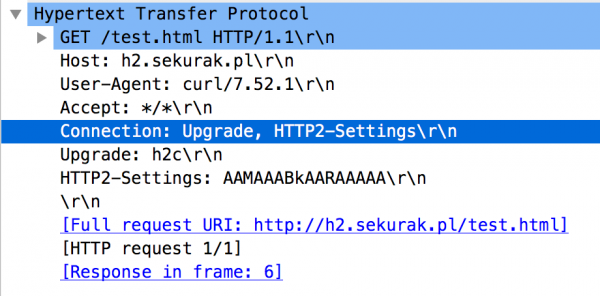
Rysunek 9. Próba zmiany protokołu na HTTP/2.
Z ciekawszych, dodatkowych mechanizmów oferowanych przez HTTP/2 warto wymienić też możliwość inicjowania przez serwer wysyłki dodatkowych danych do klienta (tzw. mechanizm server push). Na przykład serwer poza zawartością pliku test.html mógłby od razu wysłać nam pliki graficzne, do których się odwołuje. Wreszcie możemy też łatwo przerwać komunikację bez rozłączania połączenia TCP (odpowiada za to ramka RST_STREAM).
Nieco upraszczając, komunikacja HTTP/2 bardzo często wygląda w taki sposób:
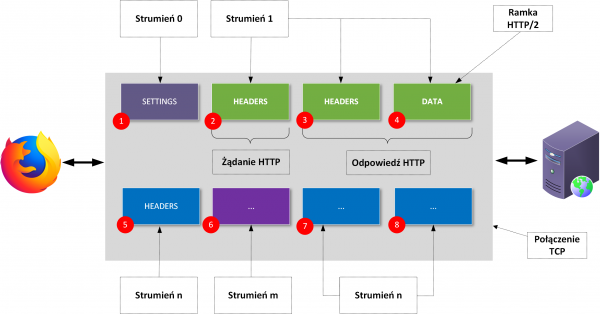
Rysunek 10. Komunikacja HTTP/2.
Na początku warto podkreślić, że HTTP/2 bardzo często wykorzystuje TLS (taki protokół jest oznaczany jako h2, popularne przeglądarki takie jak Chrome czy Firefox implementują wyłącznie tę wersję HTTP/2). Specyfikacja protokołu wymaga co najmniej wersji 1.2 TLS.
Jak widzieliśmy wcześniej na przykładzie curl, istnieje też możliwość działania HTTP/2 z wykorzystaniem zwykłego TCP (czyli bez dodatkowego zabezpieczenia) – tutaj możemy spotkać się z określeniem h2c (czy HTTP/2 over plaintext). Ten wariant jest bardziej przyjazny do testów i dla atakujących.
Przy projektowaniu HTTP/2 od razu starano się zapobiec pewnym chorobom wieku dziecięcego (objawiających się m.in. podatnością CRIME w protokole SPDY będącym prekursorem HTTP/2 – por.: https://legacy.gitbook.com/book/bagder/http2-explained/details). To właśnie dlatego do kompresji nagłówków użyto algorytmu HPACK (https://tools.ietf.org/html/rfc7541).
Jak już widzieliśmy wcześniej, HTTP/2 jest protokołem dość skomplikowanym (sama specyfikacja ma blisko 100 stron – https://tools.ietf.org/html/rfc7540, a pamiętajmy, że nie zmienia ona całej, dość złożonej struktury wiadomości (żądania i odpowiedzi) znanej z HTTP 1.1 (https://tools.ietf.org/html/rfc7230). Dodatkowo mamy definiowane pewne rozszerzenia (np. Alternative Services: https://tools.ietf.org/html/rfc7838) czy ciekawostki (Opportunistic Security for HTTP/2: https://tools.ietf.org/html/rfc8164). Sam HPACK to osobny dokument RFC (https://tools.ietf.org/html/rfc7541).
To wszystko powoduje, że można spodziewać się pewnych problemów implementacyjnych. W tym momencie (lipiec 2019) są to zazwyczaj „jedynie” błędy klasy DoS. Kilka przykładów poniżej:
A client sends an HTTP request on a new stream, using a previously unused stream identifier.
Kolejny problem omawiamy w badaniu Impervy to tzw. slow read. W pewnym uproszczeniu ten atak klasy DoS polega na realizacji wolnej komunikacji HTTP/2 (np. 1 bajt w jednej ramce), która może wymuszać znaczne zaalokowanie zasobów po stronie serwera HTTP – np. gdy przeznacza on jeden wątek na obsługę jednego strumienia. Finalnie możliwe jest tutaj zablokowanie dostępu do serwera innym klientom zaledwie jednym, dość mało aktywnym połączeniem TCP.
Jeszcze inny przykład to celujący w algorytm HPACK wariant podatności klasy decompression bomb. W tym przypadku atakujący przygotowuje odpowiednio duże żądanie HTTP (może to być np. nagłówek o odpowiednio dużej długości), które bardzo efektywnie się kompresuje. Realnie więc skompresowana komunikacja HTTP/2 będzie niewielka, ale po rozpakowaniu przez serwer wypełni jego pamięć. Ciekawym wariantem tego typu podatności jest DoS na aplikację kliencką (por. DoS w Wireshark https://www.wireshark.org/security/wnpa-sec-2016-05.html)
In some situations, excessive settings can cause services to become unstable and may result in a temporary CPU usage spike until the connection timeout is reached and the connection is closed.
[W pewnych sytuacjach nadmiarowe ustawienia mogą spowodować niestabilność usług oraz możliwe jest chwilowe wyższe obciążenie CPU, do momentu aż nie nastąpi timeout i połączenie zostanie zamknięte.]
Co ciekawe bardzo podobny błąd został naprawiony również w Tomcacie (http://tomcat.apache.org/security-8.html#Fixed_in_Apache_Tomcat_8.5.38)
Czasem można znaleźć również potencjał na wykonanie kodu w systemie operacyjnym (por. podatność w Apache Traffic Server https://yahoo-security.tumblr.com/post/122883273670/apache-traffic-server-http2-fuzzing).
Warto również pamiętać o dość nieoczekiwanych podatnościach, przed którymi komunikacja HTTP/1.1 została już zabezpieczona. Przykład tego typu problemu stanowi podatność CVE-2017-7675 w Tomcacie: (por. http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2017-7675).
The HTTP/2 implementation bypassed a number of security checks that prevented directory traversal attacks. It was therefore possible to bypass security constraints using an specially crafted URL.)
[Implementacja HTTP/2 omijała pewne sprawdzenia bezpieczeństwa, które zabezpieczały przed atakami directory traversal. Możliwe było zatem omijanie pewnych zabezpieczeń wykorzystując w tym celu odpowiednio spreparowany URL.]
Czyli jeśli komunikuję się z serwerem protokołem HTTP/1.1, wszystko jest w porządku, jeśli natomiast w zasadzie tę samą komunikację wykonam przez HTTP/2 – być może będę w stanie wykorzystać path traversal.
Pamiętajmy, że w realnych warunkach najczęściej będziemy mieć do czynienia z szyfrowanym protokołem HTTP/2 (h2). Dla systemów klasy WAF (Web Application Firewall) to pierwszy problematyczny element. Dodatkowo po rozszyfrowaniu analiza protokołu HTTP/2 to zupełnie coś innego niż HTTP/1.1. Może mamy WAF, ale nie włączyliśmy obsługi protokołu HTTP/2 – wtedy istnieje szansa, że nasz system uda się całkowicie obejść, np. umieszczając ataki w ramkach HTTP/2.
Częstym rozwiązaniem jest terminacja połączenia HTTP/2 na systemie klasy WAF, który działa też jako reverse proxy HTTP. Proxy terminuje więc zaszyfrowane połączenie HTTP/2, tłumaczy komunikację na HTTP/1.1, analizuje ją pod względem zagrożeń i bezpieczną wysyła do końcowych serwerów. Oczywiście jeśli już używamy HTTP/2, to optymalne byłoby jego wykorzystanie w każdym miejscu (czyli również w komunikacji pomiędzy WAF-em a docelowymi serwerami HTTP), ale obecnie (kwiecień 2019) tego typu rozwiązania dopiero zaczynają się pojawiać na rynku.
Ewentualnym problemom bezpieczeństwa autorzy standardu HTTP/2 poświęcili całą sekcję (por. https://tools.ietf.org/html/rfc7540#page-69, https://tools.ietf.org/html/rfc7541#page-19 rozdział „Security considerations”). Czy osoby implementujące HTTP/2 ściśle przestrzegają zaleceń tej sekcji? Może być z tym różnie, szczególnie że dość trudno znaleźć serwer zgodny w 100% z dokumentami RFC dotyczącymi HTTP/2. Przykład tego typu niezgodności widać na Rysunku 11.
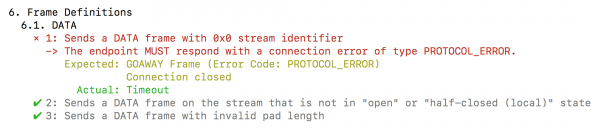
Rysunek 11. Przykład użycia narzędzia h2spec – niezgodność badana serwera HTTP/2 ze specyfikacją.
Czytelnicy zainteresowani niskopoziomowym testowaniem bezpieczeństwa HTTP/2 mogą szukać inspiracji w pracy „Attacking HTTP/2 Implementations” (https://yahoo-security.tumblr.com/post/134549767190/attacking-http2-implementations), której autorzy udostępnili fuzzer HTTP2 (https://github.com/c0nrad/http2fuzz). Jeśli ktoś preferuje Pythona – może skorzystać z httpooh (https://github.com/artem-smotrakov/httpooh). W tym kontekście warto również wspomnieć o narzędziu honggfuzz, rozwijanym przez Roberta Święckiego (https://github.com/google/honggfuzz).
Obecnie (kwiecień 2019) istnieje niewiele narzędzi przydatnych osobom związanym z bezpieczeństwem IT, a wspierających HTTP/2. Z takim wsparciem dostępne jest wcześniej wspomniane narzędzie curl.
Godny polecenia jest również klient HTTP/2 dostępny w ramach pakietu nghttp2 (https://github.com/nghttp2/nghttp2). Umożliwia on dość dokładną analizą komunikacji również w przypadku protokołu h2 (wykorzystującego TLS). Z listingu usunięto kilka mniej istotnych fragmentów:
$ nghttp -vn http://h2.sekurak.pl/test.html
[ 0.302] Connected
[ 0.302] send SETTINGS frame <length=12, flags=0x00, stream_id=0>
(niv=2)
[SETTINGS_MAX_CONCURRENT_STREAMS(0x03):100]
[SETTINGS_INITIAL_WINDOW_SIZE(0x04):65535]
[ 0.303] send HEADERS frame <length=46, flags=0x25, stream_id=13>
; END_STREAM | END_HEADERS | PRIORITY
(padlen=0, dep_stream_id=11, weight=16, exclusive=0)
; Open new stream
:method: GET
:path: /test.html
:scheme: http
:authority: h2.sekurak.pl
accept: */*
accept-encoding: gzip, deflate
user-agent: nghttp2/1.18.1
[ 0.435] recv SETTINGS frame <length=6, flags=0x00, stream_id=0>
(niv=1)
[SETTINGS_MAX_CONCURRENT_STREAMS(0x03):100]
[ 0.435] recv SETTINGS frame <length=0, flags=0x01, stream_id=0>
; ACK
(niv=0)
[ 0.435] recv WINDOW_UPDATE frame <length=4, flags=0x00, stream_id=0>
(window_size_increment=2147418112)
[ 0.435] recv (stream_id=13) :status: 200
[ 0.435] recv (stream_id=13) date: Mon, 15 Apr 2019 19:47:53 GMT
[ 0.435] recv (stream_id=13) server: Apache/2.4.25 (Debian)
[ 0.435] recv (stream_id=13) last-modified: Mon, 15 Apr 2019 14:28:10 GMT
[ 0.435] recv (stream_id=13) etag: "5-58692763f99d8"
[ 0.435] recv (stream_id=13) accept-ranges: bytes
[ 0.435] recv (stream_id=13) content-length: 5
[ 0.435] recv (stream_id=13) content-type: text/html
[ 0.436] recv HEADERS frame <length=104, flags=0x04, stream_id=13>
; END_HEADERS
(padlen=0)
; First response header
[ 0.436] recv DATA frame <length=5, flags=0x01, stream_id=13>
; END_STREAM
[ 0.436] send GOAWAY frame <length=8, flags=0x00, stream_id=0>
(last_stream_id=0, error_code=NO_ERROR(0x00), opaque_data(0)=[])
Listing 1. Przykładowy wynik polecenia nghttp
Jeszcze bardziej szczegółową analizę (na poziomie zawartości ramek) możemy prowadzić w narzędziu Wireshark. Pozostaje jednak pytanie – w jaki sposób rozszyfrować TLS? Wireshark umożliwia podanie materiału kryptograficznego umożliwiającego taką operację (por. Rysunek 12).
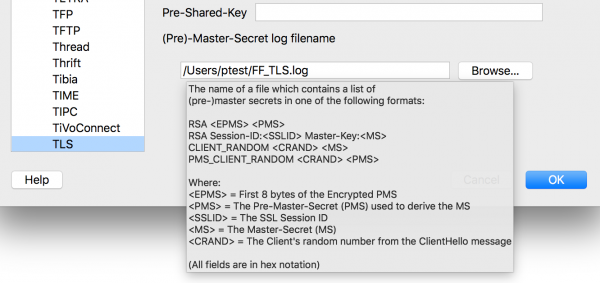
Rysunek 12. Wireshark – wskazanie pliku z zawartością umożliwiającą deszyfrację TLS.
W jaki sposób stworzyć plik wskazany na Rysunku 12? Wystarczy przed uruchomieniem przeglądarki (Firefox bądź Chrome) ustawić odpowiednią zmienną środowiskową:
Przykładowa analiza wyniku połączenia z domeną http://nghttp2.org/ widoczna jest na Rysunku 13.
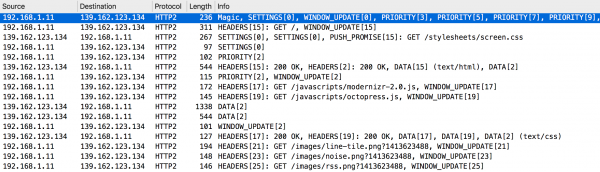
Rysunek 13. Wireshark – analiza komunikacji HTTP2.
Jeśli ktoś chciałby przechwytywać/modyfikować na żywo komunikację HTTP/2 z przeglądarki, może w tym celu użyć konsolowego narzędzia mitmproxy (https://mitmproxy.org/). Mitmproxy może działać w kilku trybach, w tym jako standardowe HTTP proxy.
Narzędzie uruchamiamy w ten sposób:
Następnie konfigurujemy ustawienia proxy w przeglądarce na adres IP maszyny, na której działa mitmproxy (słuchający domyślnie na porcie 8080):

Rysunek 14. Konfiguracja proxy w przeglądarce Firefox.
Instalujemy proponowany certyfikat root CA (pamiętajmy, żeby zrobić to ostrożnie, najlepiej tylko w przeglądarce służącej do testów). Da nam to możliwość bezproblemowego przechwytywania komunikacji h2.
Rysunek 15. Adres mitm.it umożliwiający instalację certyfikatu root CA w przeglądarce lub systemie operacyjnym.
Po wejściu na konkretny serwis (w tym obsługujący HTTP2) widzimy już określoneżądania wraz ze szczegółami (por. Rysunki 16 i 17).
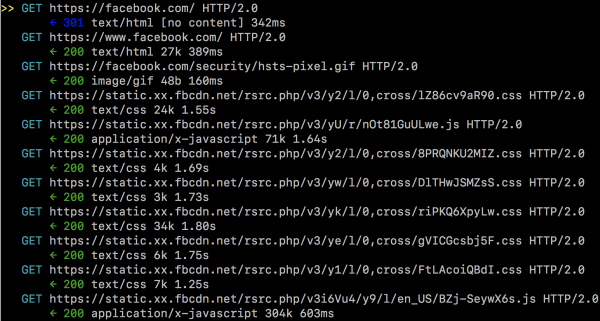
Rysunek 16. Przykładowa komunikacja HTTP/2 w narzędziu mitmproxy.
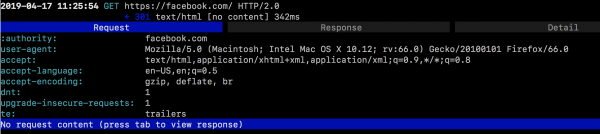
Rysunek 17. Szczegóły komunikacji HTTP/2 w narzędziu mitmproxy. Widoczny m.in. pseudonagłówek :authority.
Czy projekt o nazwie HTTP/2 okazał się sukcesem? Prawdopodobnie tak. Obecnie (lipiec 2019r.) obsługę protokołu zapewnia przytłaczająca liczba przeglądarek internetowych:

Rysunek 18. Wsparcie dla HTTP/2 w przeglądarkach.
Jednocześnie około 35% wszystkich serwisów webowych również pozwala na komunikację z wykorzystaniem HTTP/2 (por. https://w3techs.com/technologies/details/ce-http2/all/all – przy czym warto zaznaczyć, że najczęściej równolegle zapewniona jest możliwość komunikacji z wykorzystaniem poprzednich wersji HTTP).
Jak widzieliśmy, od strony bezpieczeństwa całość wygląda solidnie, choć nie zapomnijmy o kompatybilności wstecznej – w tym przypadku podatności, które mogą być wykorzystane w HTTP/1.x, z dużym prawdopodobieństwem występowały będą również w HTTP/2. W szczególności warto zwrócić uwagę na podatności aplikacyjne – wykorzystanie SQL Injection czy XXE będzie wyglądało w ten sam sposób w obu wersjach protokołu HTTP – zmieni się tylko niskopoziomowy sposób przesyłania ataku. Złośliwi mogą dodać: ataki będą mogły być realizowane nieco szybciej. W końcu szybkość działania to główny cel powstania HTTP/2.
Czy w takim razie kolejne lata to era dominacji HTTP/2? Niektórzy wskazują na nikłe korzyści wydajnościowe tego protokołu w pewnych warunkach. Faktem jest również nawet wyższa wydajność HTTP/1.x w sieciach ze stratami pakietów (por. pracę „HTTP3 explained” https://daniel.haxx.se/http3-explained/ oraz „HTTP/2: What no one’s telling you” https://www.slideshare.net/Fastly/http2-what-no-one-is-telling-you).
Rozwiązaniem tego problemu ma być nowy protokół HTTP/3, który obecnie znajduje się w trakcie standaryzacji (por. https://quicwg.org/base-drafts/draft-ietf-quic-http.html). W warstwie transportowej bazuje on na protokole UDP i pełnymi garściami czerpie ze specyfikacji HTTP/2. Jeśli wszystko pójdzie zgodnie z planem, ma on rzeczywiście być szybkim i bezpiecznym następcą HTTP/1.x.
–Michał Sajdak, hackuje w Securitum

Dzięki za art Panie Michale.
Swoją drogą:
Na koniec –
“hackuje w Securitum”
Wszystko powiem Mamie. Że w internecie mnie zachęcają do hakowania. Nie wiem jeszcze się zastanowię ale chyba doniosę do PiS ;-E W donosie dam tyt. “gość krytykuje Morawieckiego” i będą kłopoty. ;-E
My nie zachęcamy. My hackujemy. I to legalnie :-) (polecam swoją drogą).
s/Czy w HTTP/1.1 takie zachowanie jest wymagane/Czy w HTTP/2 takie zachowanie jest wymagane/
Właśnie w tym miejscu jest wstawka o http/1 – więc wszystko poprawnie :)