Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

OSINT. Jak wyszukiwać za pomocą obrazu?
Narzędzia OSINT-owe przechodzą ogromną metamorfozę wraz z rozwojem modeli sztucznej inteligencji. Nie ominęło to także popularnych wyszukiwarek. Kiedy wykonywałem porównanie trzech z nich – Google, Binga oraz Yandexa w 2021 i 2023 roku, mechanizmy AI zaczęły się dopiero nieśmiało w nich pojawiać. Prekursorem był Yandex, który jako pierwszy opanował analizę obrazu w celu lepszego rozpoznawania tekstu (zapisanego za pomocą różnych systemów pisma) oraz dopasowania odpowiedzi do obiektów znajdujących się w obrazie. Niedługo później dołączył do niego (a następnie wyprzedził) Google, poprzez wdrożenie Obiektywu (Google Lens) do wyszukiwania za pomocą obrazu. Dzisiaj mamy do dyspozycji nie tylko te narzędzia, ale także wiele innych, które za sprawą AI radzą sobie naprawdę dobrze. Aby zaktualizować wnioski z poprzednich badań, postanowiłem sprawdzić, jak na koniec 2025 roku wygląda środowisko narzędzi do wyszukiwania za pomocą obrazu.
Już niebawem — bo w marcu — ruszy wysyłka naszej książki „Twierdza Linux. Bezpieczeństwo dla dociekliwych” autorstwa Karola Szafrańskiego. Jeśli chcecie mieć w swojej biblioteczce prawdziwy przewodnik po bezpieczeństwie systemów z rodziny GNU/Linux i lubicie zgłębiać każde zagadnienie naprawdę dogłębnie, ta pozycja jest właśnie dla Was!
Autor, bazując na swoim wieloletnim doświadczeniu zarówno w administracji systemami, jak i w obszarze bezpieczeństwa, przeprowadzi Was przez podstawy, meandry oraz nieoczywiste aspekty Linuxa, otwierając przed Wami świat, jakiego jeszcze nie mieliście okazji poznać.
https://wydawnictwo.securitum.pl/twierdza-linux-bezpieczenstwo-dla-dociekliwych
Zmiany, zmiany, zmiany…
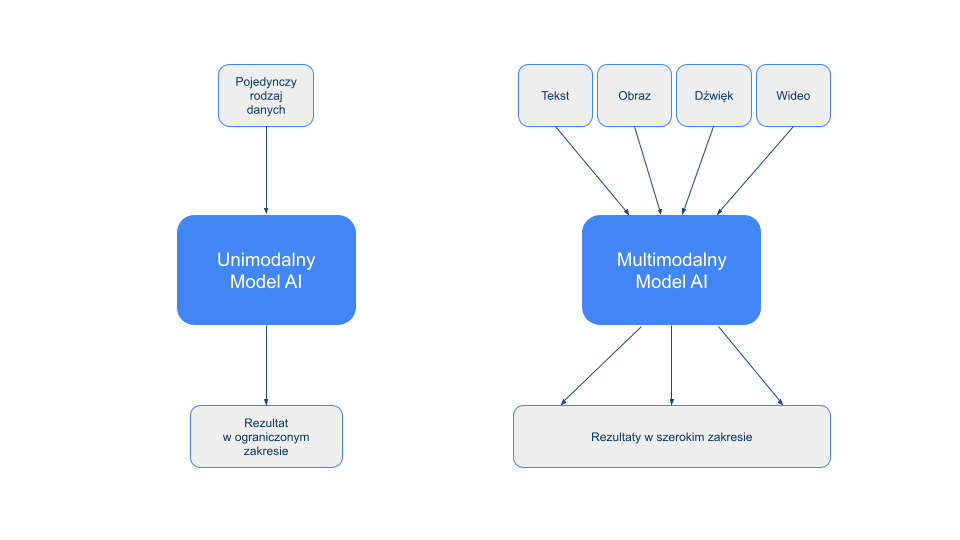
Dynamiczny rozwój technologii AI wywarł wpływ na możliwości w zakresie analizy obrazów. Przez wykorzystanie głębokiego uczenia na podstawie dostępnych plików graficznych oprogramowanie (nie tylko wyszukiwarki) zyskało możliwości bardziej zbliżone do tego, jak ludzie analizują widziane przez siebie obrazy. Do niedawna jedną z niewielu dostępnych opcji analitycznych, wykorzystywanych przez programy do przechowywania, katalogowania i wyświetlania zdjęć i filmów, było rozpoznawanie twarzy. Dziś użytkownicy mają do dyspozycji funkcjonalności odróżniania osób od zwierząt i pojazdów w kamerach CCTV, automatycznego tagowania na podstawie zawartości zdjęcia w mediach społecznościowych, odróżniania prawdziwych filmów od deep-fake’ów na podstawie widoczności przepływu krwi pod skórą osoby na filmie (chociaż w tym obszarze wyścig nadal trwa i twórcy fałszywych przekazów starają się już obejść te ograniczenia), mapowanie mieszkania przez roboty sprzątające, analiza zdjęć medycznych w celu wykrycia potencjalnych chorób i dolegliwości, a także rozpoznawanie znaków oraz innych uczestników ruchu drogowego (chociaż co do tego punktu mam wrażenie, że nawet obecne, zaawansowane techniki analizy obrazu jeszcze nie są w stanie sobie w pełni poradzić z tym, co kierowca może spotkać na swojej drodze, szczególnie w mniej zurbanizowanych obszarach). Te ostatnie przykłady wykorzystują już multimodalne AI, czyli głębokie uczenie na podstawie wielu rodzajów źródeł – nie tylko obrazu z kamery czy aparatu, ale także opisów tekstowych (np. diagnoz pacjenta), informacji z radaru/lidaru samochodowego lub pozycji z odbiornika GPS. Niestety, z większą liczbą źródeł danych wiąże się także większe ryzyko pomyłek w przypadku braku informacji z części z nich w analizowanym zakresie lub narastanie błędów poznawczych poprzez nakładanie się tego typu błędów pochodzących z różnych źródeł.
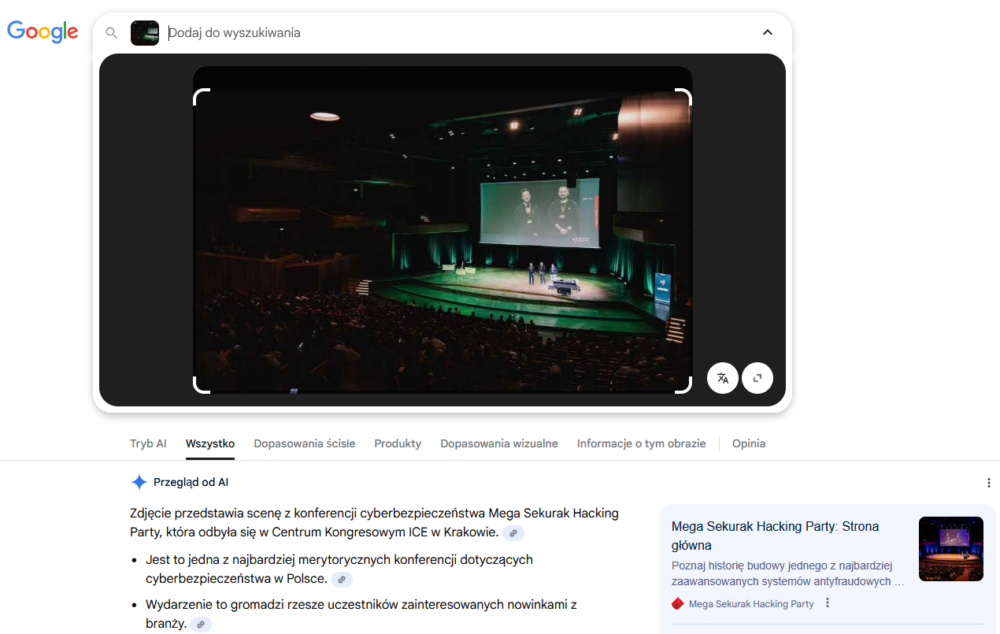
Już w poprzednim opracowaniu wykazałem, że wyszukiwarki dość dobrze radziły sobie z rozpoznawaniem miejsc, samochodów i owoców. Nie tylko umożliwiały odnalezienie kopii wyszukiwanego obrazu w Internecie (chociaż nadal istnieje taka możliwość), ale też wskazywały obrazy podobne wizualnie i dopasowywały sugerowane strony jako wyniki wyszukiwania w kontekście zawartości obrazu. Na podstawie tych ostatnich możliwe było przejście do wyszukiwania tekstowego lub na odwrót. Obecnie wyszukanie obrazu w Google skutkuje automatycznym podaniem użytkownikowi Przeglądu od AI, który w krótkim zestawieniu podsumowuje informacje związane z obrazem.
Co prawda w zakresie rozpoznawania twarzy na zdjęciach wyniki były niezbyt zadowalające (szczególnie w przypadku obracania obrazu lub modyfikacji jego kolorów), jednak i tutaj zdarzały się przypadki bardzo precyzyjnego dopasowania (np. identyfikacja twarzy szwajcarskich skoczków narciarskich, która prowadziła do interesujących wyników w poprzednich badaniach). Rozszerzenie dotychczasowych możliwości o potencjał AI może tym bardziej sprostać wymaganiom użytkowników, którzy już nie tylko chcą znaleźć podobne obrazy, ale także sprawdzić, czy wyszukiwane zdjęcie nie zostało zmodyfikowane (np. w celu dezinformacji) albo czy nie jest ono jedynie wycinkiem większej całości. Platformy zakupowe w wielu przypadkach oferują już nie tylko opcję tekstowego wyszukiwania towarów, ale także analizy wgrywanych zdjęć pomagające w znalezieniu podobnych (lub takich samych) produktów.
Oprócz wyszukiwarek, udostępniających standardowe funkcje, pojawiły się także wyspecjalizowane narzędzia do wyszukiwania lokalizacji wykonania zdjęcia na podstawie jego zawartości. Z wykorzystaniem obecnej technologii AI tego typu zadania powinny być (przynajmniej w teorii) jeszcze łatwiejsze, a wyniki bardziej dokładne. Oczywiście cały czas występuje tu niebezpieczeństwo nieprawidłowego wyuczenia modelu, podobnie jak to ma miejsce w przypadku generatywnych modeli do tworzenia obrazów na podstawie promptów tekstowych, kiedy grupa badaczy wykorzystująca techniki Nightshade była w stanie tak „skazić” model, że ten na polecenie stworzenia zdjęcia psa generował zdjęcia kotów. Technika ta została zaprezentowana jako możliwość przeciwdziałania scrapowaniu obrazów w celu uczenia modeli, ale sama koncepcja wprowadzenia nieprawidłowości do modelu analizy obrazów także jest moim zdaniem realna.
Analiza obrazów – Google Lens kontra Bing Visual Search
Wdrożenie oprogramowania Google Lens (czyli Obiektywu Google) do wyszukiwarki obrazów Google Images spowodowało znaczny wzrost jej możliwości. Google Lens jest już dostępne w menu kontekstowym przeglądarki Chrome, a od niedawna także w Firefoksie. W przeglądarce Edge użytkownicy mogą także skorzystać z wyszukiwania wizualnego w menu kontekstowym, jednak jak przystało na jej producenta, czyli Microsoft, funkcjonalność ta realizowana jest tu z wykorzystaniem wyszukiwarki Bing.
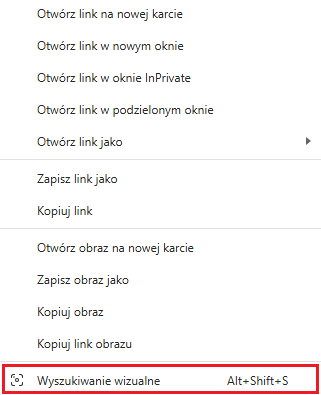
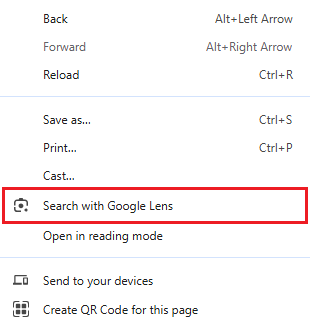
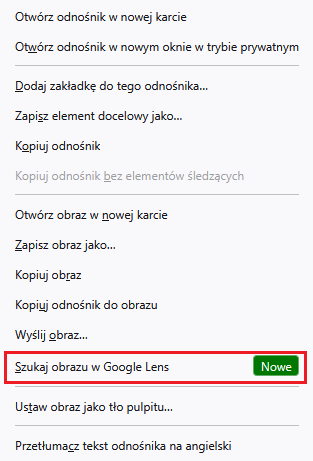
W Chrome i Edge użytkownicy mogą wskazać dowolny obszar strony lub konkretny obraz, który zostanie użyty do wyszukiwania. Firefox na razie oferuje tylko wyszukiwanie na podstawie konkretnych obrazów, zawartych na stronach internetowych.

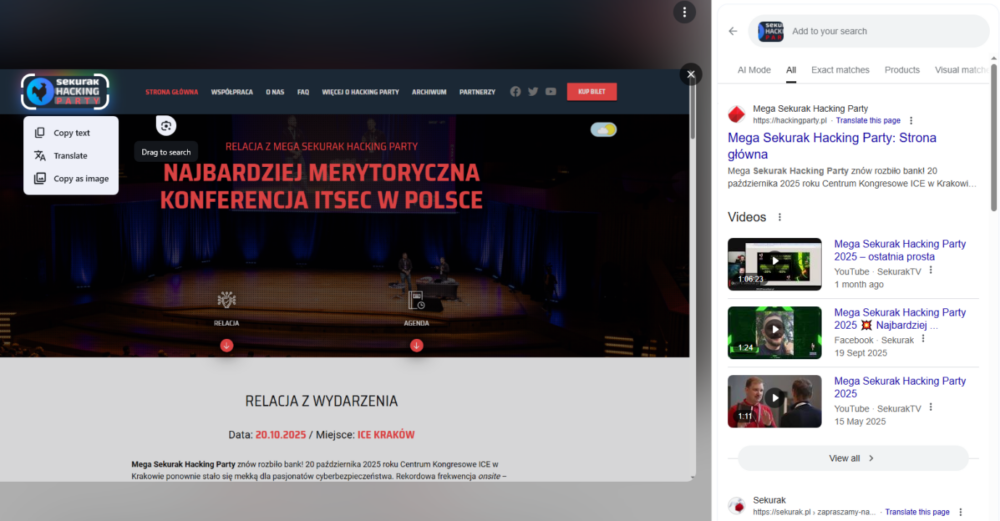
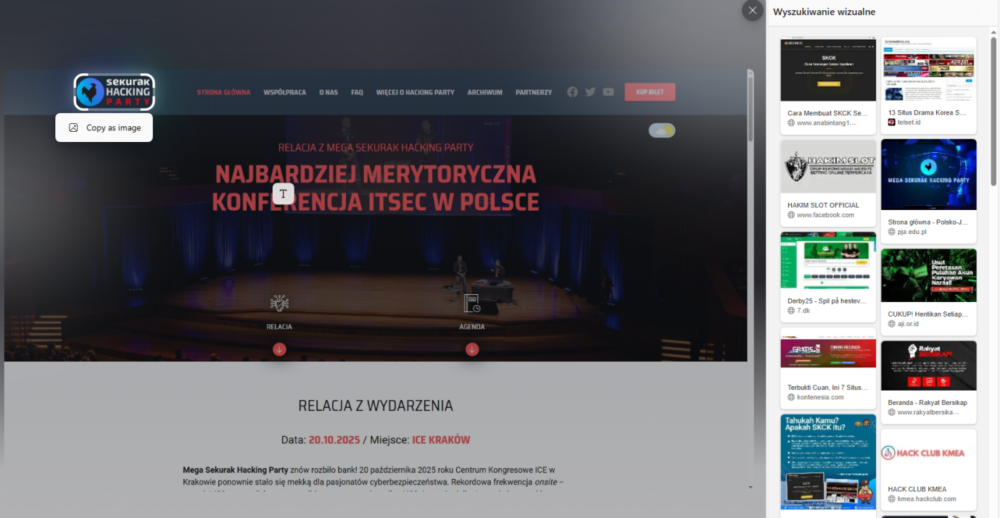
Wynik pierwszego testu, porównującego efekty wyszukiwania logo Mega Sekurak Hacking Party poprzez opcje menu kontekstowego przeglądarek Chrome i Edge, wypadł zaskakująco źle w przypadku tej drugiej. Wyszukiwanie wizualne w Bing miało tylko jedno poprawne dopasowanie kontekstu w czwartym linku, jednak było to zdjęcie pochodzące ze strony z aktualnościami Polsko-Japońskiej Akademii Technik Komputerowych. Żaden z kolejnych kilkudziesięciu linków nie prowadził do jakiejkolwiek strony poruszającej temat MSHP – w tytułach niektórych z nich przewijało się zaledwie słowo ”hack”. Minimalne rozszerzenie obszaru poszukiwanego sprawiało, że nawet wskazany wcześniej jeden powiązany z imprezą link znikał z wyników.
Jako że Firefox nie pozwala na zaznaczenie obszaru do wyszukania, możliwe było tu jedynie użycie obrazka z logo MSHP bez tła. Opcja wyszukiwania graficznego w Firefox kieruje, jak już wspominałem, do Google, więc z poprawnymi wynikami nie było problemu.

Aby warunki testu były takie same dla wszystkich trzech przeglądarek, zweryfikowałem także wyszukiwanie na podstawie samego obrazu logo (bez tła) w Chrome i Edge. Wyniki niestety okazały się podobne.
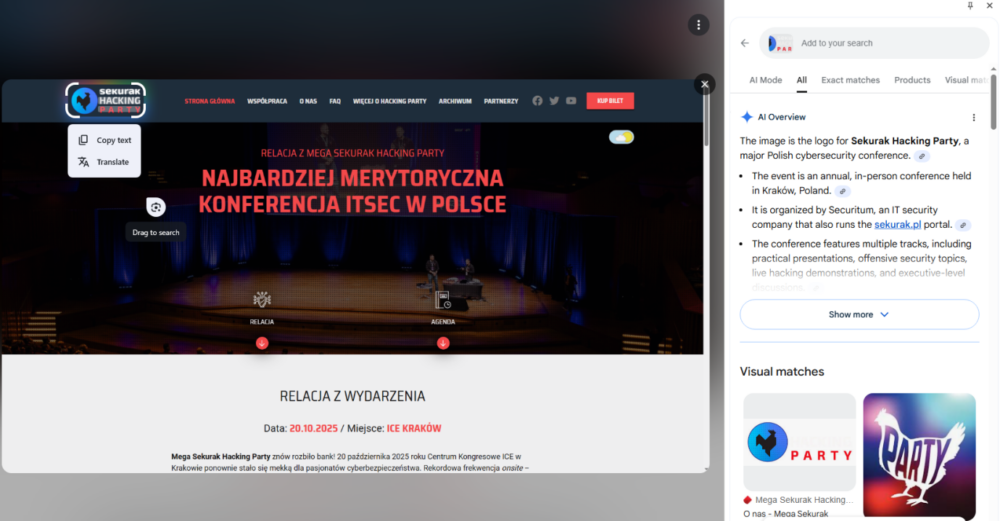
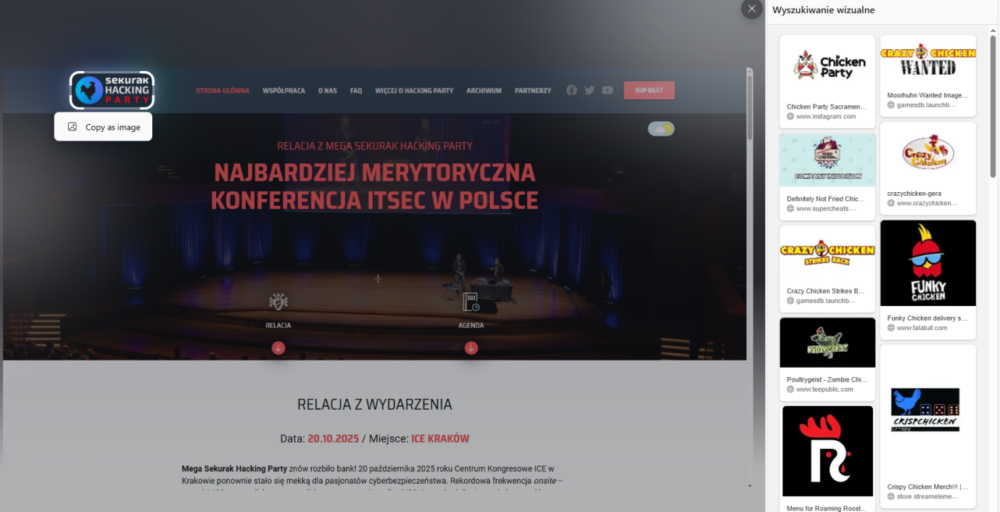
Google Lens znów poprawnie zidentyfikował kontekst i podał linki do powiązanych stron, a także powiązane obrazy, wyszukane na podstawie informacji graficznej (logo kuraka) oraz tekstowej (słowo „party”). Bing niestety wskazał jedynie inne znaki graficzne bazujące na kurczaku i słowie „party”, bez wskazania faktycznie powiązanych z logiem treści. Minusem Binga jest moim zdaniem także brak pokazywania w panelu wyników obrazu źródłowego, na podstawie którego wykonywane było wyszukiwanie. Obie wyszukiwarki jednak wyszukując na podstawie wskazanego obszaru oferują także możliwość zaznaczania tekstu na obrazach i wyszukiwania za jego pomocą.
Badanie wyników wyszukiwania graficznego w różnych kategoriach
Aby lepiej pokazać, jak zmieniły się wyszukiwarki graficzne, posłużyłem się obrazami użytymi w moich poprzednich testach. Tym razem jednak skupiłem się jedynie na dwóch najpopularniejszych narzędziach: Google Grafika (Google Images) i Obrazy Bing (Bing Visual Search). Pominąłem Yandex, co nie znaczy, że ta wyszukiwarka nie jest już warta uwagi. Ma ona nadal swoje plusy, jednak nie uwzględniałem jej w badaniu, aby jej nie reklamować.
Zarówno w Google, jak i w Bingu korzystałem z opcji wyszukiwania graficznego na podstawie analizy zawartości obrazu. Google posiada jeszcze opcję „ścisłego dopasowania”, wyszukującego klasycznie takie same obrazy w innych miejscach w sieci. Taka opcja jest przydatna, jeśli ktoś chce wyszukać np. wykorzystanie swoich zdjęć na innych stronach. Rozszerzeniem tej funkcjonalności jest opcja „Informacje o tym obrazie”, pozwalająca znaleźć nie tylko dane o stronach, na których znaleziony został poszukiwany obraz, ale także o tym, od ilu lat podobne obrazy były publikowane. To interesujące narzędzie, szczególnie przy zwalczaniu fake newsów, wykorzystujących często historyczne obrazy jako ilustracje bieżących wydarzeń . W wyszukiwarce Bing niestety takiej opcji nie znalazłem.
Na początek na warsztat porównawczy pójdą zdjęcia z różnych lokalizacji.
Analiza lokalizacji
Analiza zdjęć z różnych zakątków świata w obu przypadkach działało dobrze, przy czym zastosowanie konkretnego narzędzia zależy od tego, co użytkownik chce uzyskać. Jeśli poszukuje konkretnych informacji o zawartości obrazu, lepiej skorzystać z Google Lens. Jeśli zaś chce uzyskać więcej różnorodnych wyników (np. miejsc podobnych do wyszukiwanego), warto użyć Binga.
Oto, jak radziły sobie narzędzia z poszczególnymi zdjęciami.
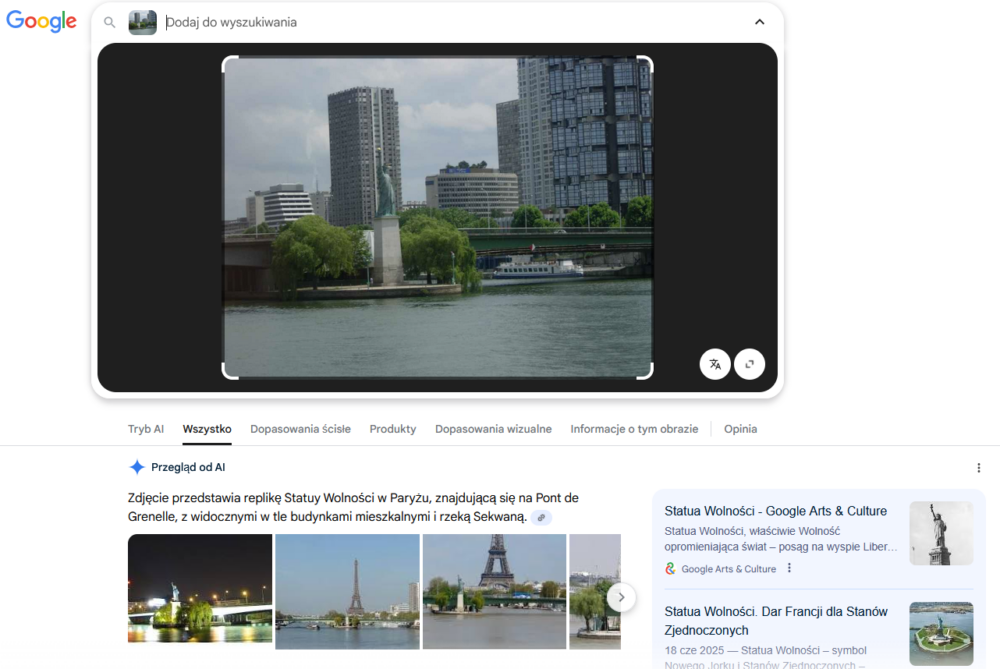
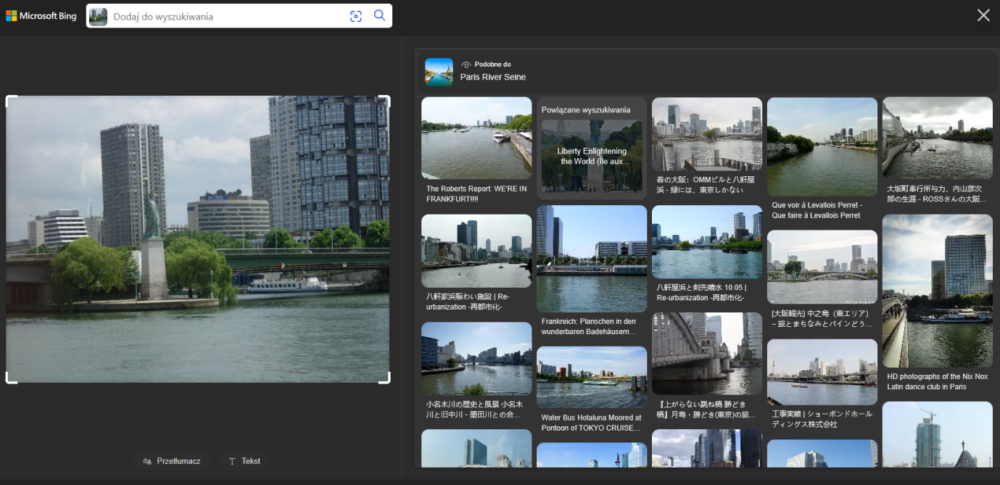
Przyporządkowanie widoku posągu nad rzeką nie przysporzyło obu narzędziom żadnych problemów. Google oczywiście podało wynik dokładny, opisujący widoczną Statuę Wolności (chodzi oczywiście o paryską kopię słynnej Statuy Wolności z Nowego Jorku), natomiast Bing dobrze określił lokalizację, czyli rzekę Sekwana w Paryżu, jednak nie podał żadnych informacji o widocznym posągu. W zamian na stronie wyników wyszukiwania znalazły się zdjęcia podobnych widoków z różnych stron świata. Elementem, który w tym konkretnym przypadku może zmylić poszukiwacza, jest pierwszy podobny obraz, podpisany “WE’RE IN FRANKFURT”.
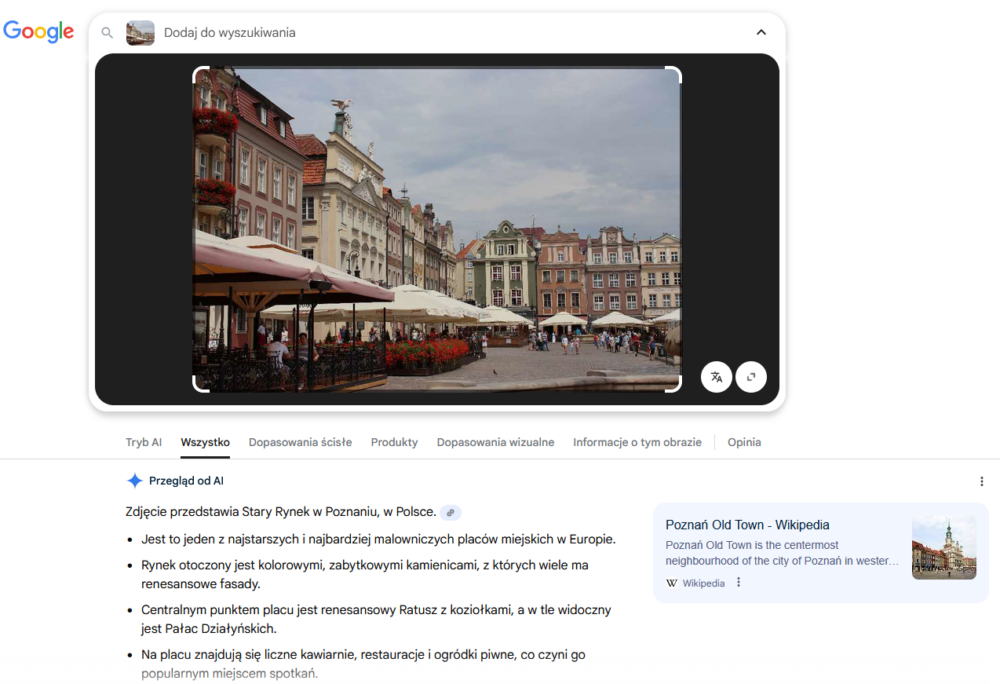
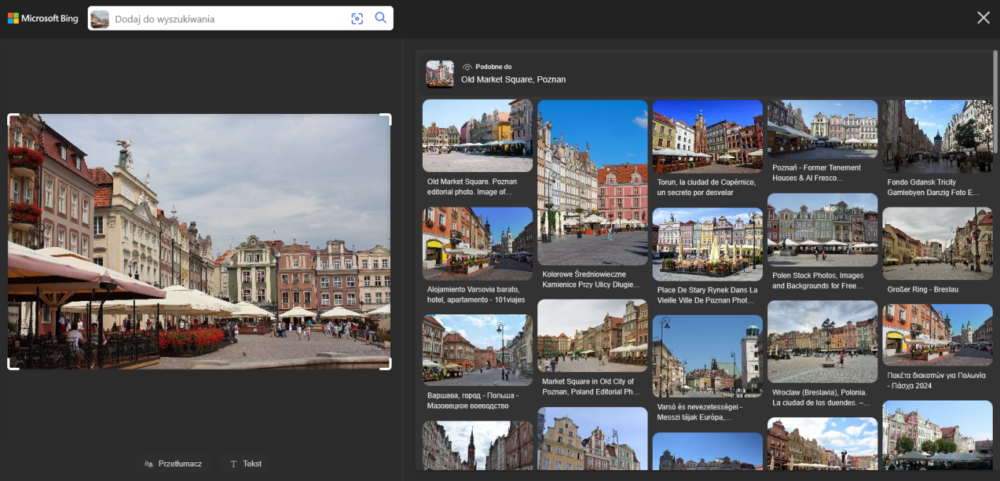
Zdjęcie Starego Rynku w Poznaniu zostało poprawnie zidentyfikowane przez obie wyszukiwarki. Standardowo Google podał więcej powiązanych informacji, a Bing skupił się na podobnych widokach (chociaż tym razem dużo zdjęć pochodziło z tego samego miejsca, którego fotografia została użyta do wyszukiwania).
W przypadku kolejnego zdjęcia nie miałem wielkich oczekiwań, ale Google pozytywnie mnie zaskoczył. Zdjęcie przedstawia widok na dolinę Wisły z jednej z ulic Sandomierza, jednak bez żadnych elementów mogących na pierwszy rzut oka wskazać właśnie to miejsce. Podczas, gdy narzędzia wykorzystujące modele AI do geolokalizacji na podstawie zdjęć (np. GeoSpy.ai), już jakiś czas temu radziły sobie całkiem dobrze z identyfikacją miejsca jego wykonania, to typowe wyszukiwarki, jak Google czy Bing, dotychczas nie dawały zadowalających wyników w tym zakresie. Tym razem było jednak inaczej. O ile pierwsze wyniki wskazywały bardziej na Gdańsk lub Kraków, to na siódmym miejscu wśród dopasowań wizualnych znalazło się zdjęcie wykonane mniej więcej z tej samej lokalizacji, co mój oryginał.
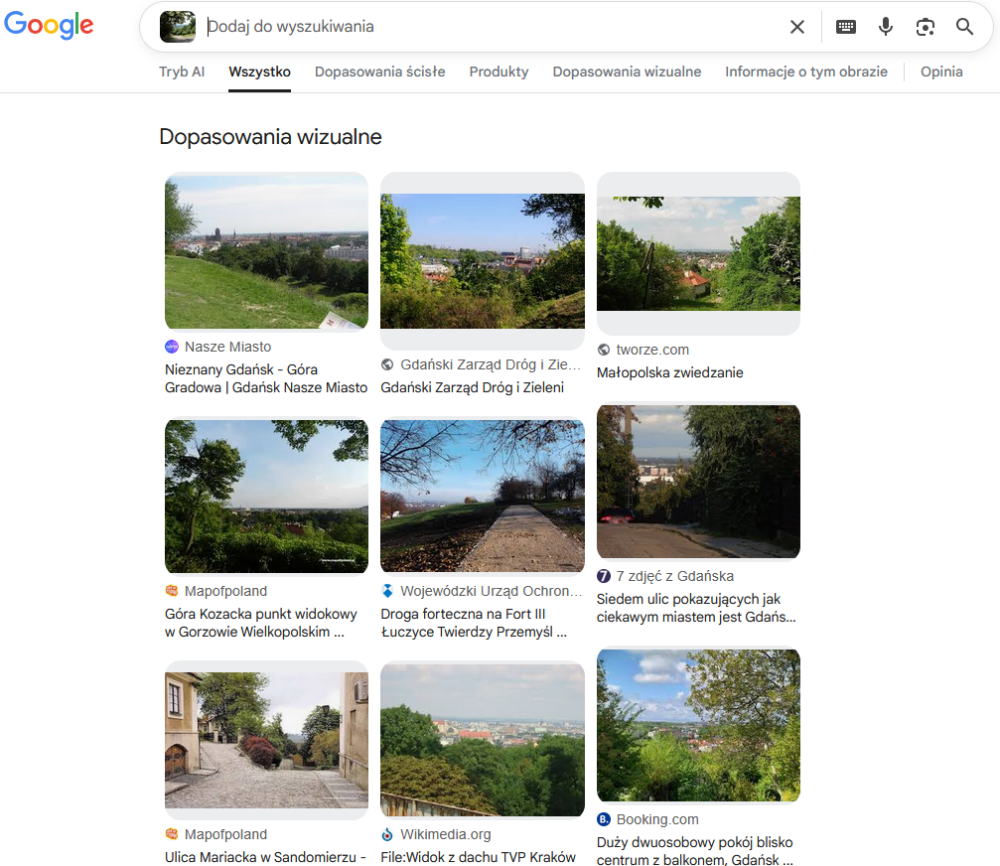
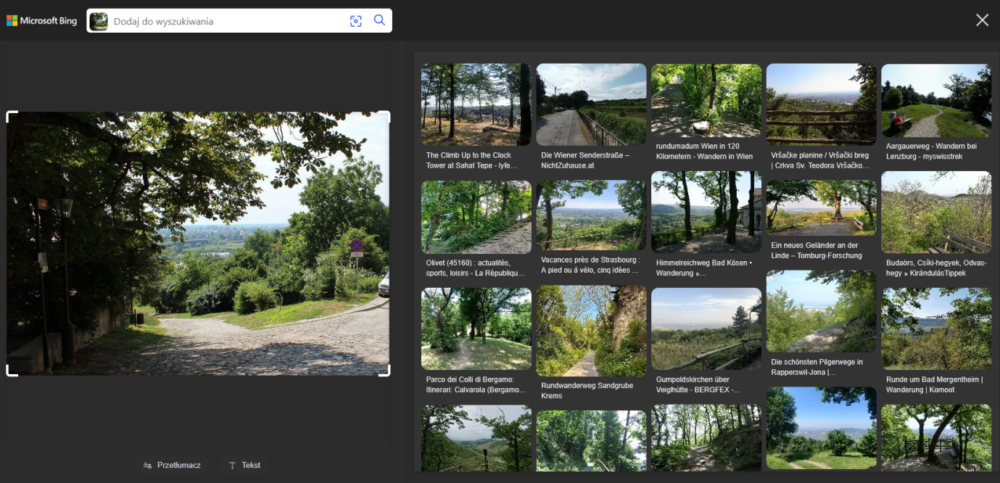
Bing wskazał natomiast jak zwykle podobne widoki, w razie gdyby ktoś już zwiedził Sandomierz, Gdańsk i Kraków i szukał podobnych lokalizacji.
W kolejnym kroku postanowiłem zweryfikować, jak oba narzędzia poradzą sobie z wnętrzem pewnego dworca metra. W tym przypadku Google od razu skupił się na samym wagonie, co widać na poniższym zrzucie ekranu, dzięki czemu był w stanie lepiej poradzić sobie ze wskazaniem konkretnej linii metra w Nagoi w Japonii.
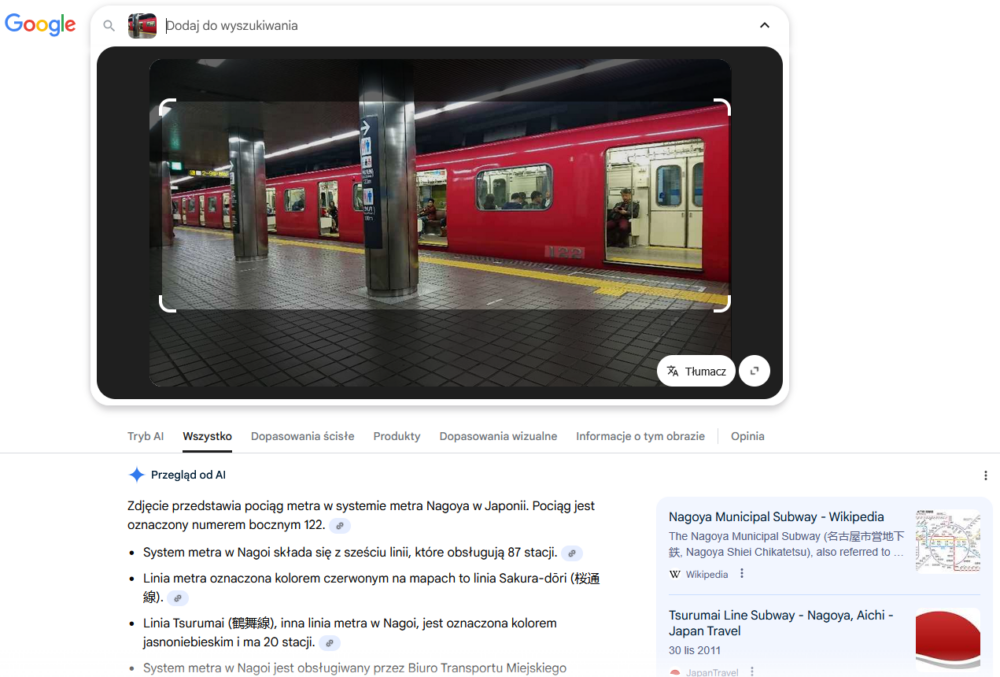
Bing na początku nie skupił się na samym wagonie. Zmiana obszaru analizy przeze mnie nie pomogła niestety i wskazane zostało nieprawidłowo metro w Tokio.
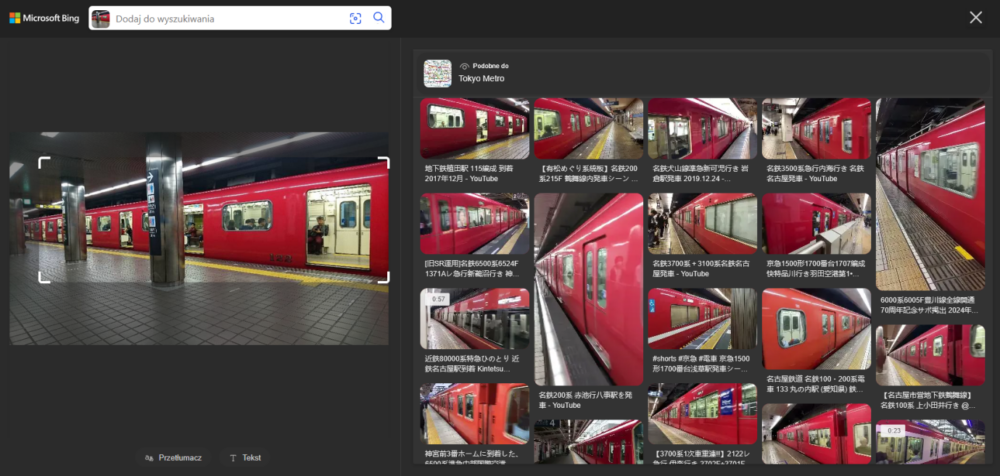
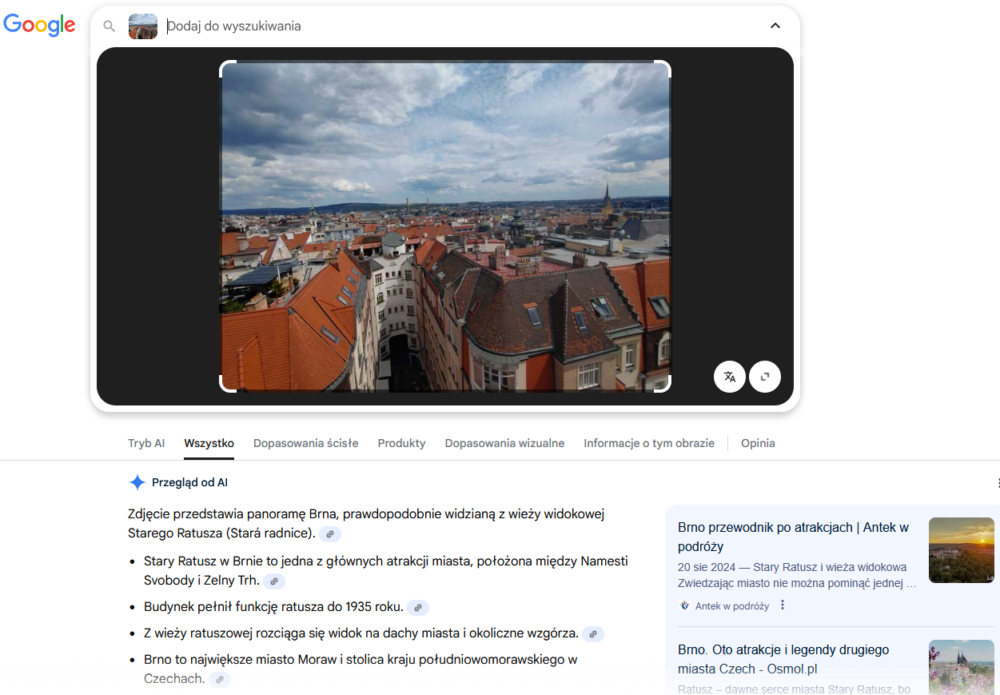
Jako ostatnie poddałem analizie zdjęcie wykonane w Brnie. Jak można się było spodziewać, Google podał więcej szczegółów, łącznie z prawdopodobnym miejscem, z którego wykonano fotografię, a Bing ograniczył się do poprawnego (tak, należy się z tego cieszyć) miejsca i zestawu miast, gdzie także występują kamienice oraz wysoko położony punkt widokowy, z którego można je oglądać.
Tekst
Zarówno Google Lens, jak i Bing Visual Search dobrze radzą sobie z rozpoznawaniem tekstu w alfabecie łacińskim na zdjęciach. W ramach wyszukiwania tekstu posłużyłem się więc zdjęciami zawierającymi inne systemy pisma.
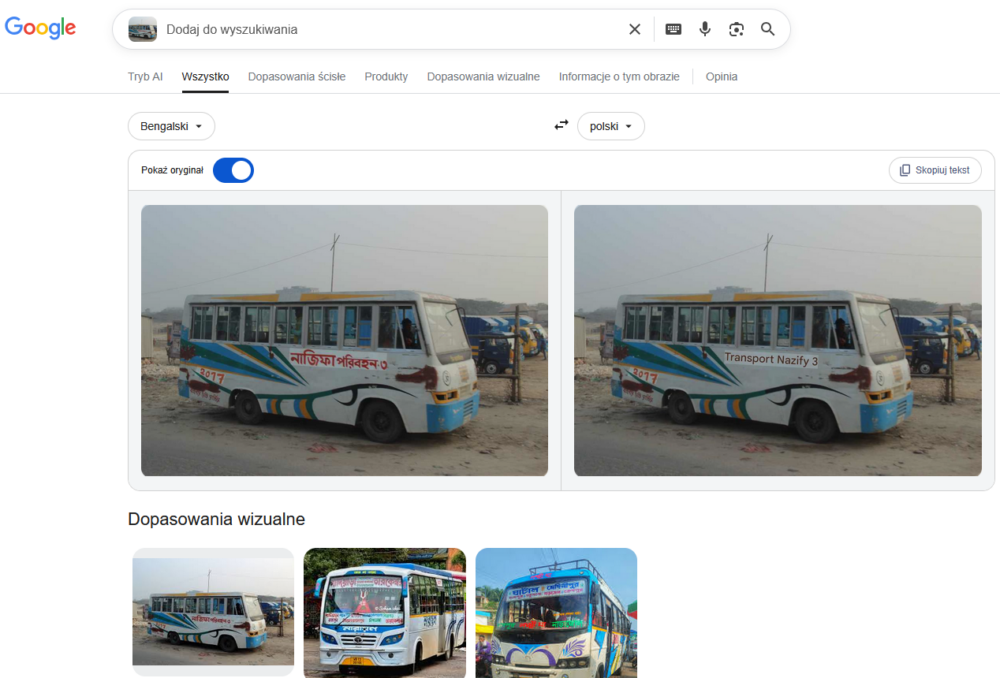
Na początek jeden z moich ulubieńców, czyli autobus z Bangladeszu. Na korzyść obu narzędzi przemawia fakt, że poradziły sobie ze zidentyfikowaniem systemu pisma, przy czym Google dał radę przetłumaczyć napis, a Bing już nie.
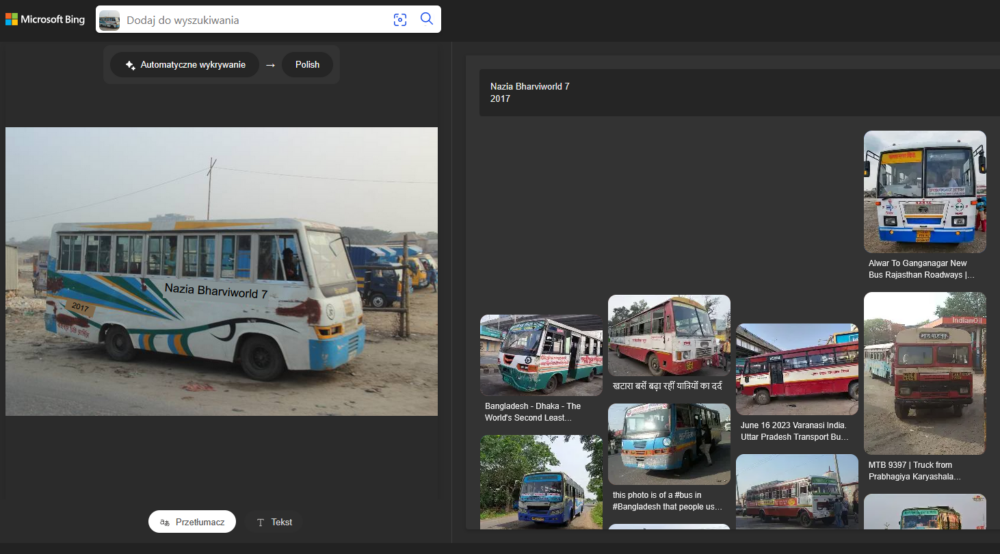
Kolejne zdjęcie, tym razem z Bangkoku w Tajlandii, uwidoczniło ciekawe efekty podczas prób tłumaczenia tekstu na zdjęciu o kiepskiej jakości.
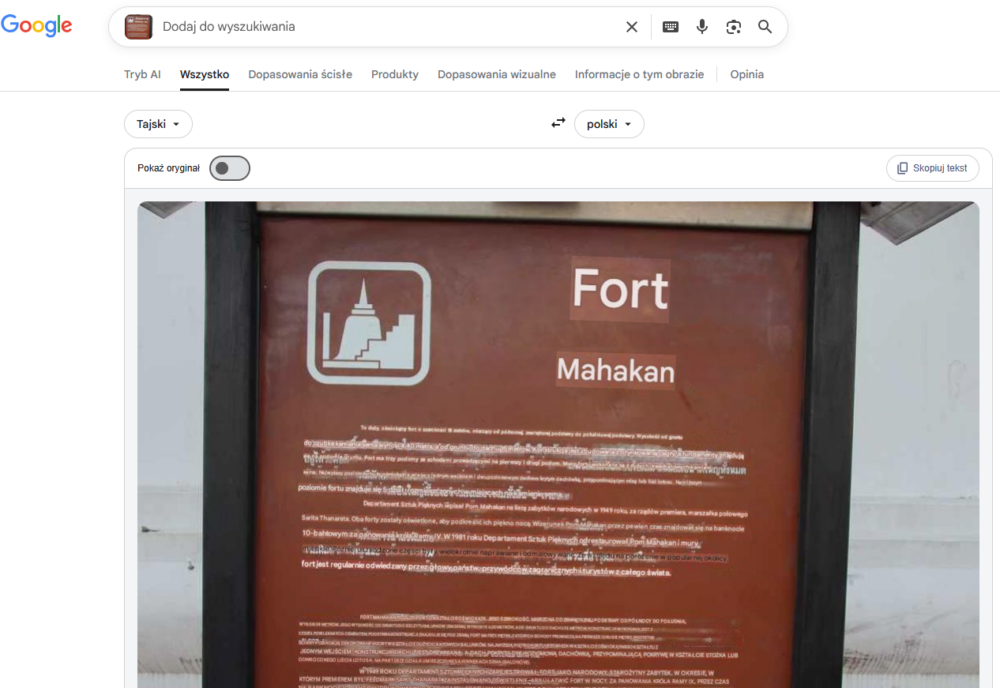
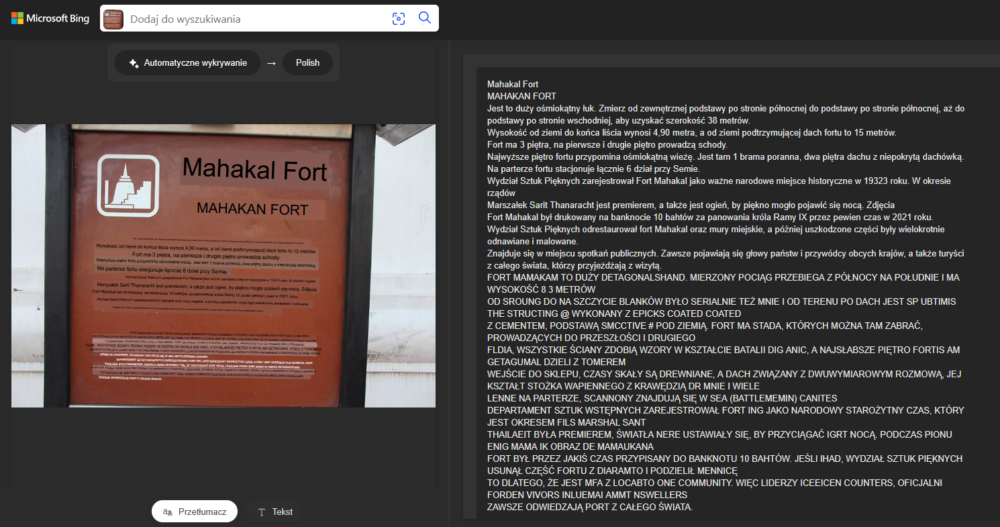
Google Lens stara się dopasować przetłumaczony tekst do miejsca, w którym znajdowała się pierwotna treść. Takie próby niestety często skutkują jego nieczytelnością (a tłumaczenie na żywo napisów w językach pisanych od góry do dołu w kolumnach powoduje dodatkowo ból szyi ;) i taki sam efekt wystąpił tutaj. Na szczęście istnieje opcja skopiowania przetłumaczonego tekstu i wklejenia go w miejsce, z którego będzie go można łatwiej odczytać. Niestety ze względu na dość niską rozdzielczość zdjęcia w niektórych miejscach pojawiły się przekłamania w tłumaczeniu od Google (fort raz ma 18, a raz 38 metrów). Bing poradził sobie tutaj dużo lepiej. Co ciekawe, po przejściu na Przegląd od AI liczby były już poprawne. Warto więc zawsze sprawdzać, czy tłumaczenie nie spowodowało zakłamania kluczowych faktów.
Pojazdy
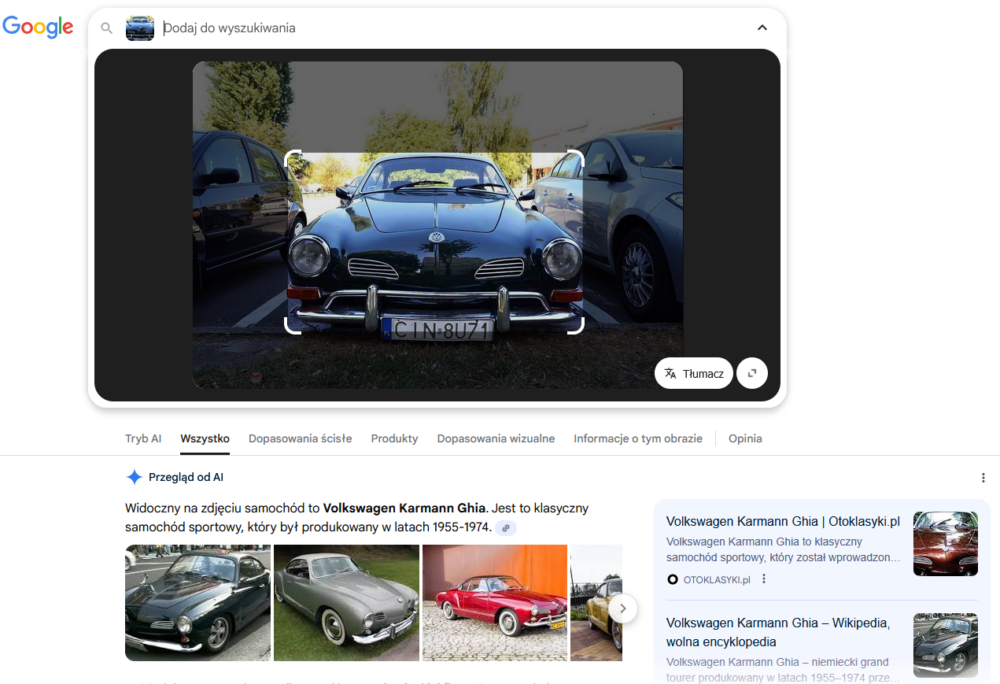
Do zbadania jakości analizy obrazów zawierających pojazdy także użyłem zdjęć z poprzednich badań. Na pierwszy ogień poszedł klasyczny Volkswagen. Tym razem obie wyszukiwarki nie miały już najmniejszych problemów z tym, żeby zidentyfikować poprawnie markę i model.
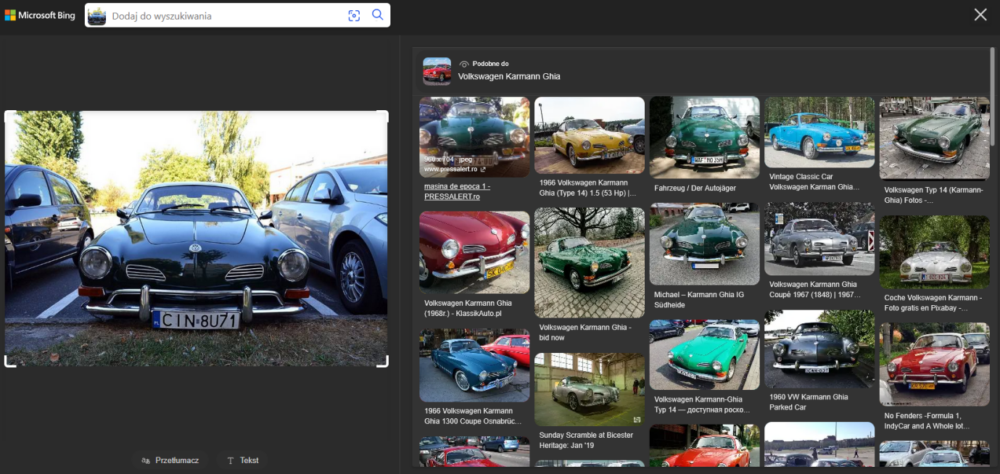
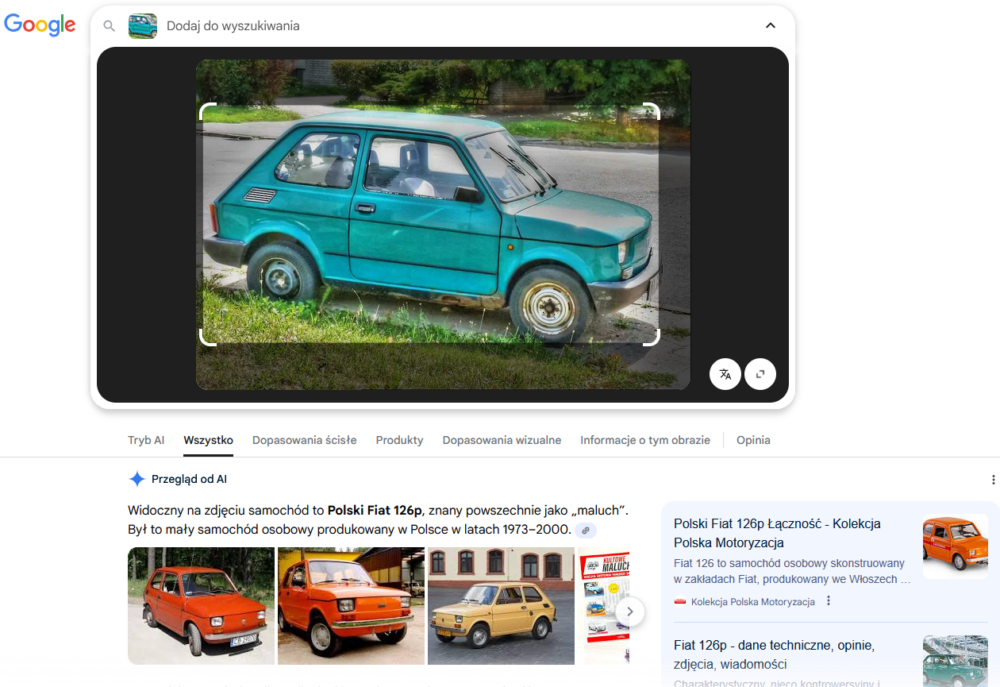
W przypadku zdjęcia małego Fiata było podobnie – zarówno Google, jak i Bing wskazały poprawnie, co to za auto. Oczywiście w Google otrzymaliśmy standardowo zestaw podstawowych informacji w Przeglądzie od AI.
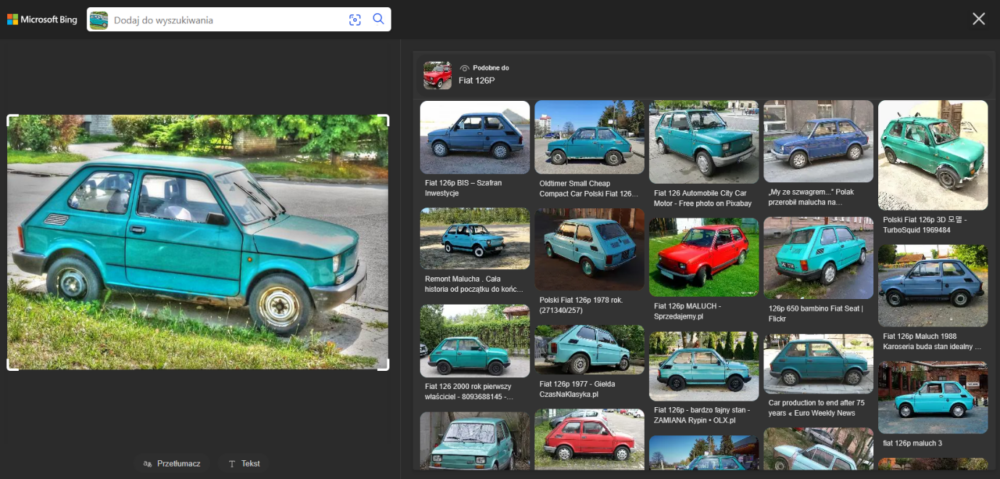
Analiza kolejnego zdjęcia zajęła nieco więcej czasu, ale nie Google’owi, ani Bingowi, lecz mnie. Podstawowy scenariusz, czyli rozpoznanie samochodu, na pierwszym planie nie przysporzył żadnemu z narzędzi kłopotu.
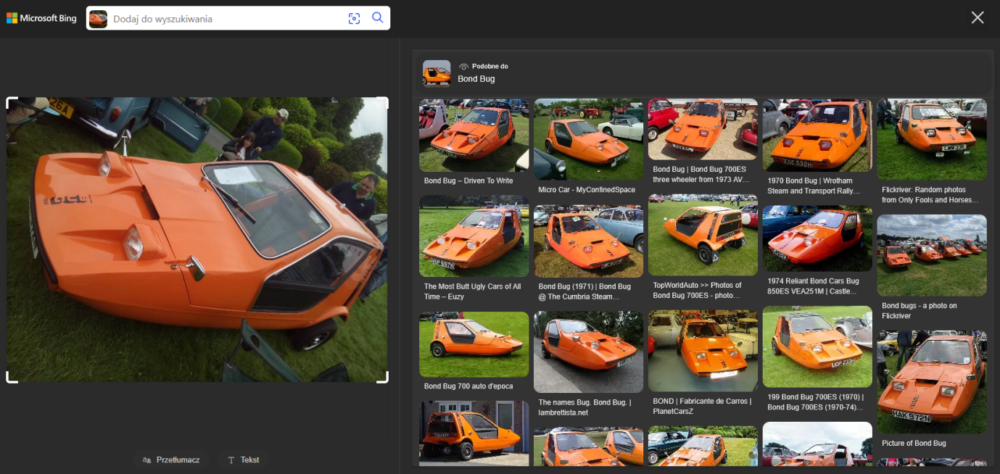
Postanowiłem jednak skupić się na mniej oczywistym scenariuszu, czyli na wyszukaniu informacji o samochodzie, którego fragment widać w tle.
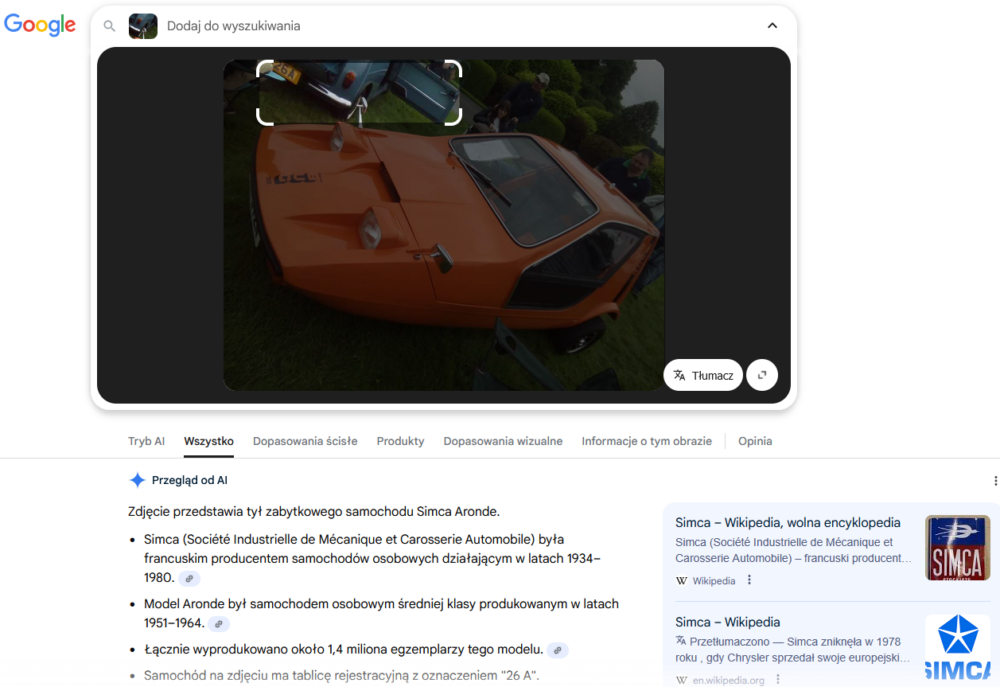
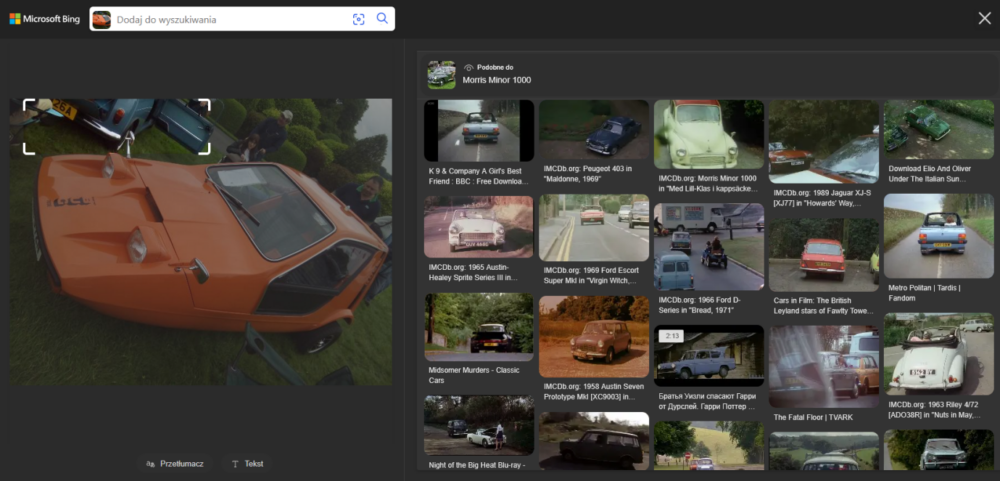
Google przy próbie wskazania mu obszaru tła zdjęcia do analizy bardzo się starał i wskazywał dużo zidentyfikowanych informacji – ot, choćby to, że na zdjęciu widoczny jest fragment brytyjskiej tablicy rejestracyjnej. Dla osoby zajmującej się OSINT-em w zakresie obejmującym samochody lub choćby geolokalizację z wykorzystaniem tablic rejestracyjnych nie jest to żadne odkrycie, jednak należy docenić próbę zwrócenia uwagi na elementy znajdujące się poza głównym obszarem obrazu. W zakresie identyfikacji samochodu, którego fragment jest widoczny w lewym górnym rogu zdjęcia, zupełnie niespodziewanie zapunktował Bing. Wskazał co prawda, że może być to Morris Minor 1000, co okazało się nietrafionym strzałem, jednak Google był jeszcze dalej, sugerując, że jest to Simca Aronde. Z mojej szybkiej analizy wynika, że samochód ten to Morris Mini Minor, więc bliżej poprawnej odpowiedzi był Bing.
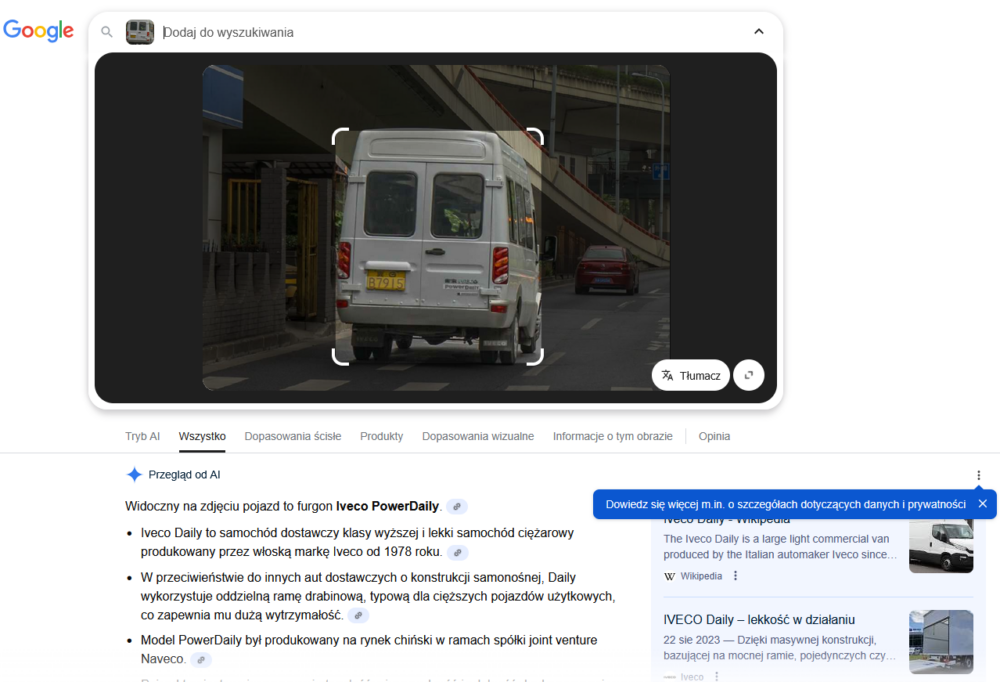
Wyszukiwanie Iveco jadącego po chińskiej ulicy dało jedynie tyle, że Google określił, że to Iveco, a Bing pokazał dużo pojazdów z chińskich ulic.
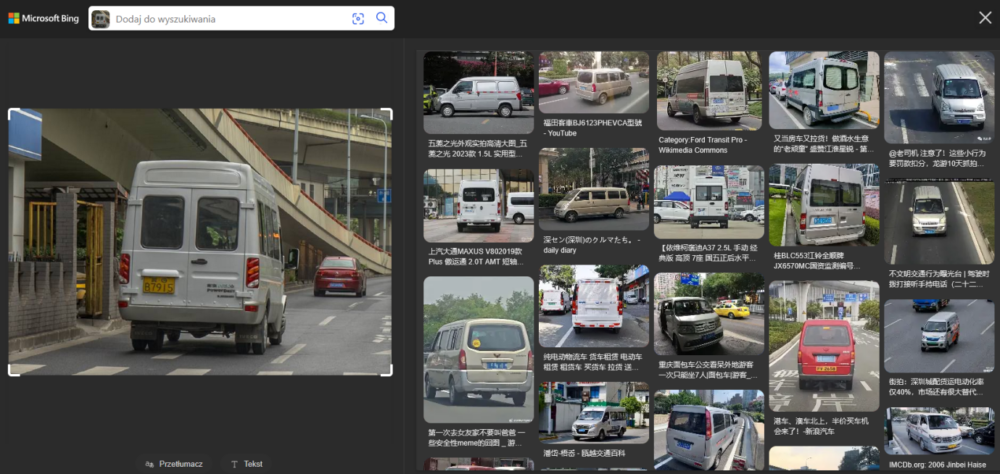
Twarze
Do testowania jakości mechanizmów analizy twarzy na zdjęciach wykorzystałem w pierwszej kolejności jedno z popularnych zdjęć Johna McAfee w różnych kombinacjach: oryginalne, w odcieniach szarości, obrócone o 90 stopni oraz obrócone o 180 stopni. Spodziewałem się lepszych wyników (przynajmniej u Google) niż w ostatnim badaniu, gdzie obrócony o 90 stopni obraz był dla Grafiki Google podobny do zdjęć zwisających z drzew zwierząt. Niestety, przeliczyłem się, ale po kolei. Na początek zdjęcie w oryginalnej postaci.
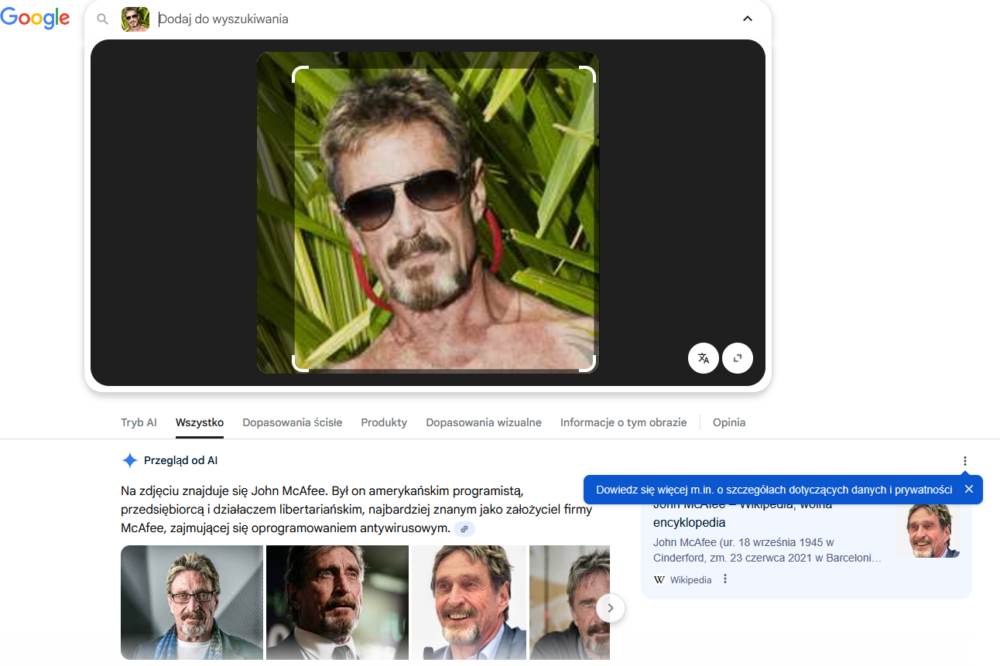
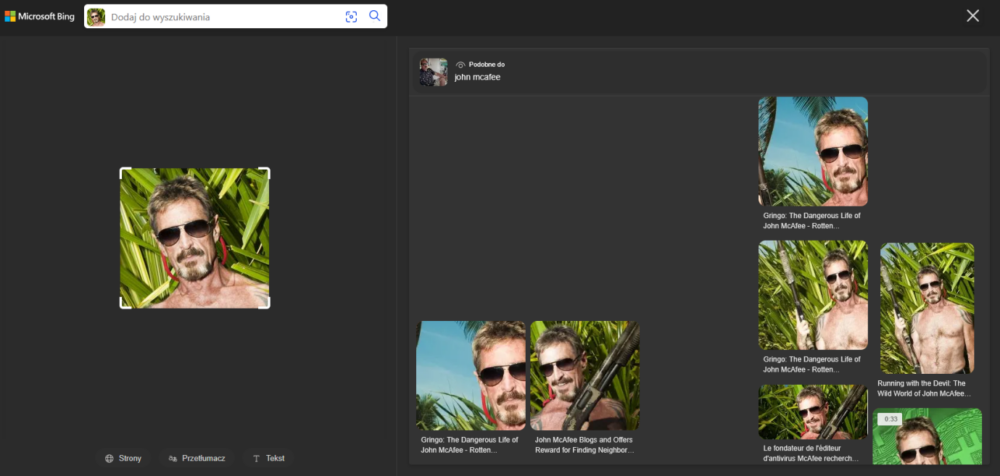
Zarówno Google, jak i Bing poradziły sobie z identyfikacją osoby oraz wskazały różne formy wgranego zdjęcia jako powiązane wyniki (w przypadku Google były one widoczne pod Przeglądem od AI).
Skoro tak dobrze poszło obu konkurentom za pierwszym razem, to może i modyfikacje zdjęcia nie będą dla nich przeszkodą w identyfikacji osoby na nim uwiecznionej? No cóż, zaawansowanie mechanizmy Google cały czas udowadniają, że skupiają się bardziej na elementach zdjęcia niż na jego całokształcie. Na czarno-białej fotografii przestały widzieć konkretną osobę, za to wskazały okulary, i to do nich przyporządkowały wyniki wyszukiwania (nawet po rozszerzeniu obszaru analizy na całe zdjęcie).
Tutaj po raz kolejny natknąłem się na pewną niedogodność w zaznaczaniu obszaru do analizy w Google, a mianowicie zmiana obszaru w kierunku dołu zdjęcia często kończyła się zablokowaniem narzędzia, chociaż kiedy pierwszym ruchem było rozszerzenie w górę, narzędzie działało poprawnie.
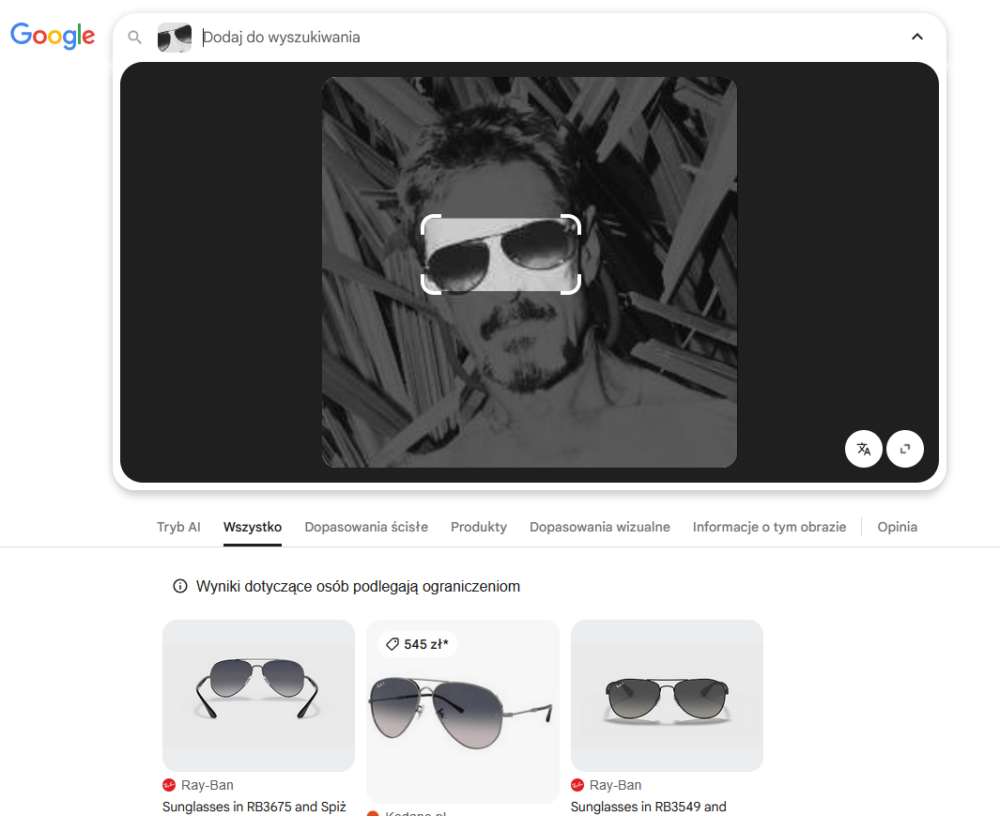
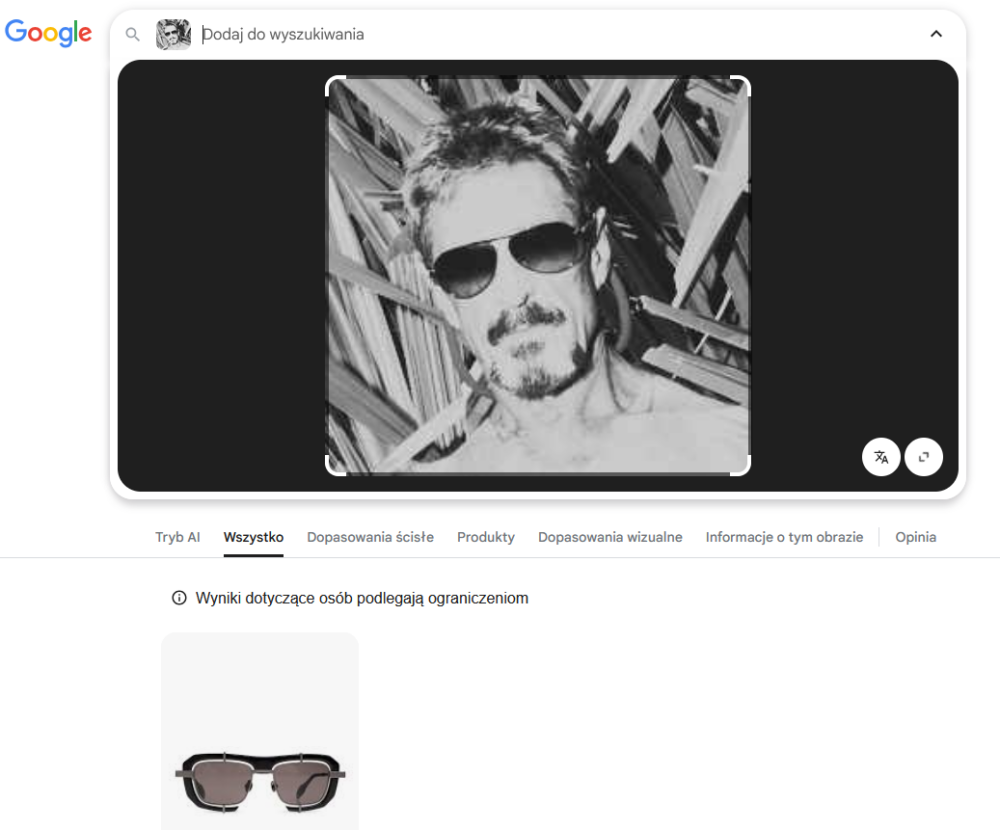
Nawet przejście na zakładkę „dopasowania wizualne” wskazywało jedynie kilka w miarę podobnych zdjęć.
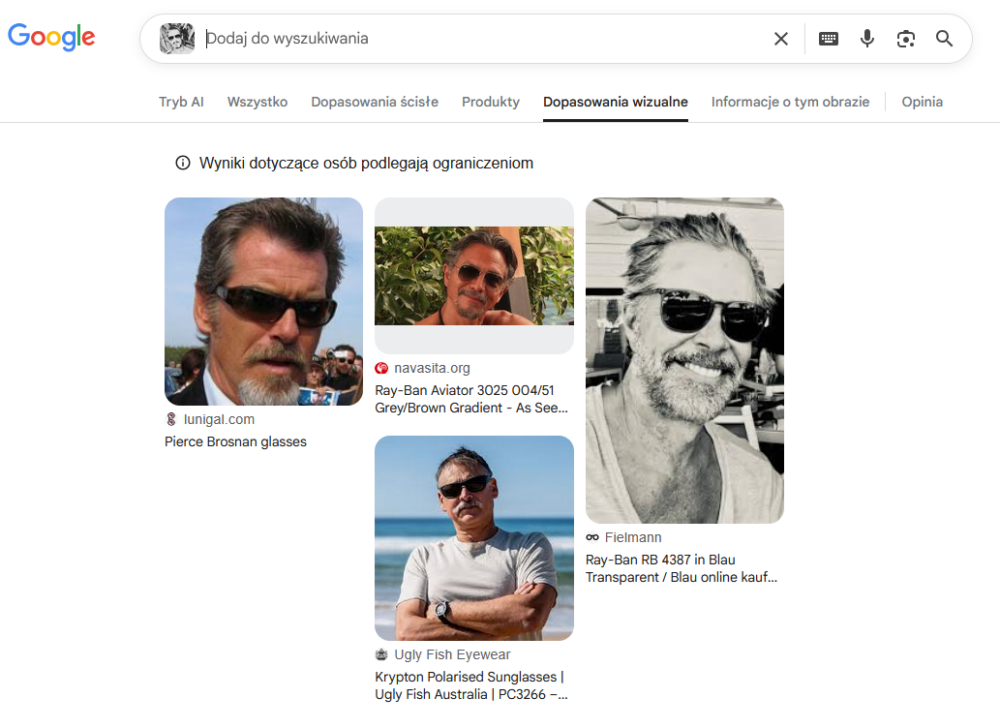
Co do samych wyników, to oczywiście użytkownicy mogą mieć różne powody, by wgrywać zdjęcia do wyszukiwarek. Jeśli ktoś chce kupić takie same lub bardzo podobne okulary do tych prezentowanych na fotografii, to zdecydowanie polecam Google Grafikę. Jeśli zaś interesuje go sama osoba lub podobne kompozycje zdjęcia, wtedy warto skorzystać z Binga, tym bardziej, że nawet dla czarno-białej wersji obrazu poprawnie zidentyfikował on osobę na nim przedstawioną, nawet kiedy obraz był nieznacznie obrócony względem oryginału.
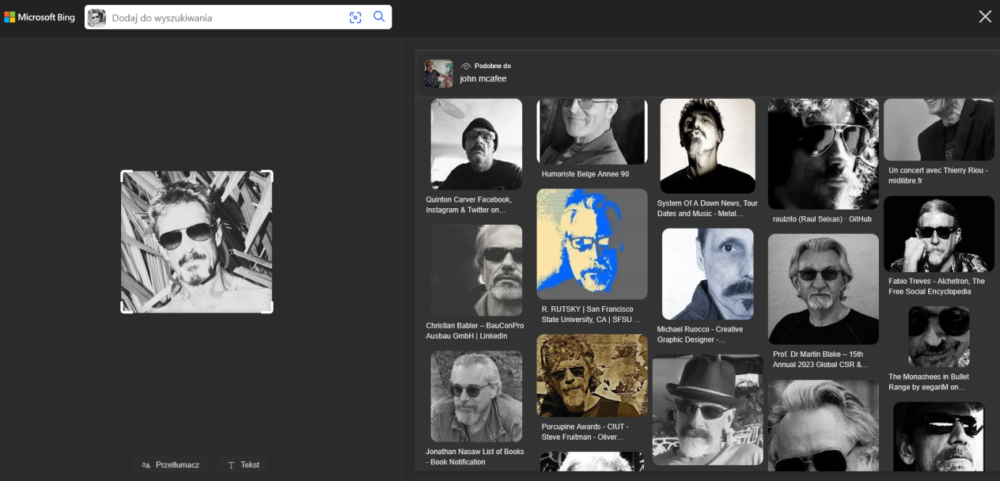
W przypadku kolorowego zdjęcia obróconego o 90 stopni Google już nie idzie w kierunku fauny, ale nadal skupia się na samych okularach. Po rozszerzeniu obszaru analizy jedynymi dopasowaniami wizualnymi są trzy strony, z czego dwie dotyczą wykonywania kapeluszy. Być może pewną wskazówką może być tu analiza tekstowa zdjęcia, dostępna w Trybie AI, która mówi o „mężczyźnie leżącym wśród traw”, który „nie jest znaną osobą publiczną”. Ten fragment może sugerować, że model nie wziął pod uwagę możliwości manipulacji zdjęciem, a fakt poziomego ustawienia twarzy przyjął jako pozę leżącą. Dodatkowo po drugim wejściu w zakładkę Trybu AI wyświetlona została szersza analiza, wskazująca jeszcze zidentyfikowane cechy twarzy oraz słuchawki, które moim zdaniem są jedynie sznurkiem od okularów. Ot, błąd nowoczesnej techniki, która zna głównie obecne trendy, a nie klasyczne rozwiązania. Być może to wskazówka, żeby w zespołach OSINT-owych wyniki z modeli AI były weryfikowane przez starszych (nie tylko stażem) analityków, którzy mają więcej życiowego doświadczenia? :)
W przypadku zdjęcia obróconego o 180 stopni Google także widział jedynie okulary.
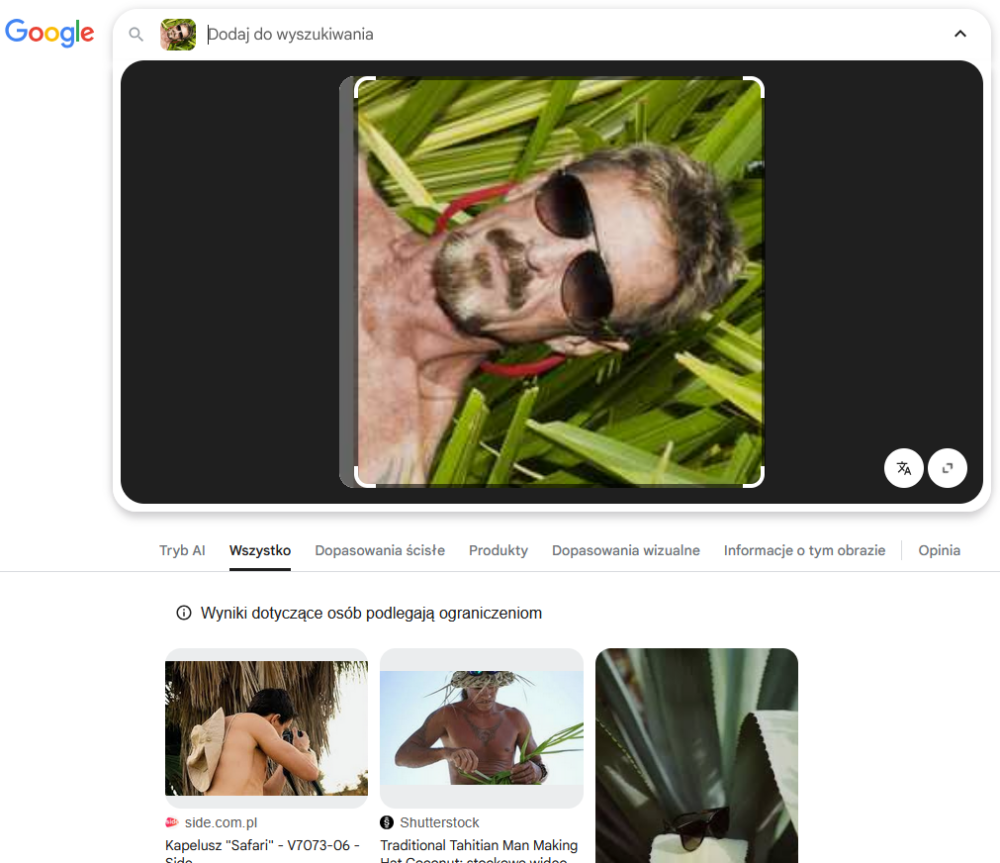
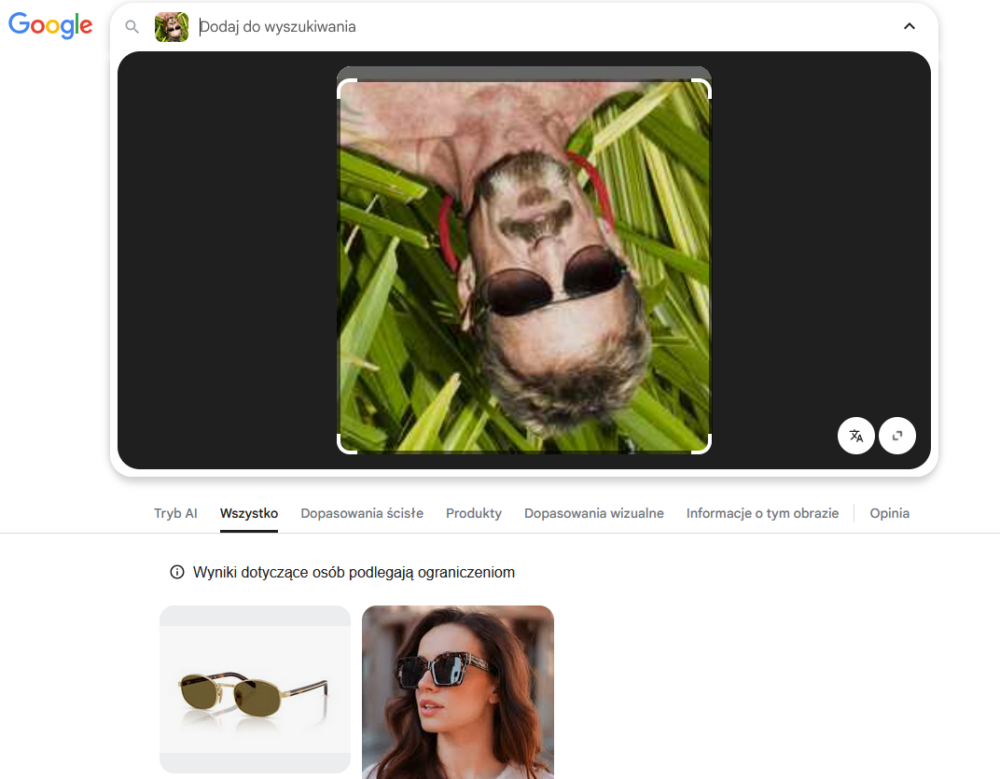
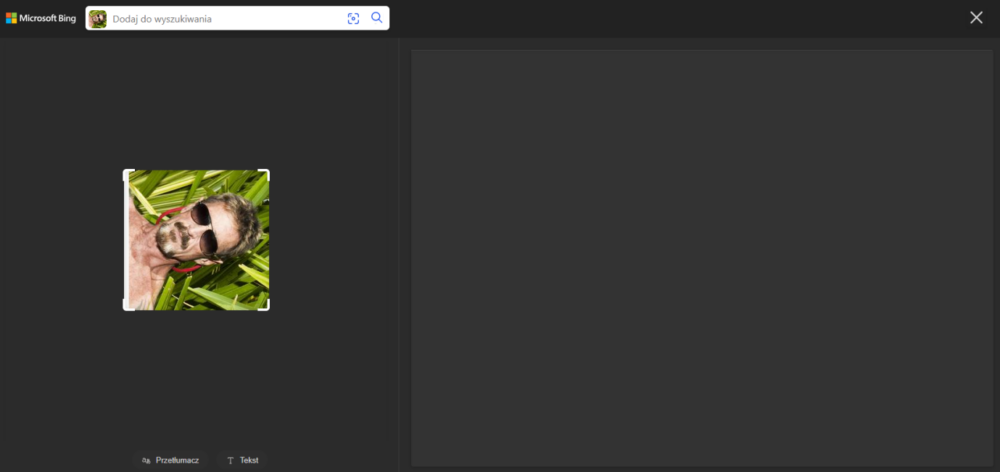
Bing tym razem nie podzielił się żadnym przemyśleniem na temat obróconego zdjęcia, być może dlatego, że – jak mówi znana sentencja – „Lepiej milczeć i uchodzić za głupca, niż się odezwać i rozwiać wszelkie wątpliwości”? Jest to dziwne, bo już dla fotografii obróconej o 180 stopni Bing wrócił na swoje tory i nawet wśród wyników podobnych ujęć wskazał wyszukiwane zdjęcie w oryginalnej pozycji.
W przypadku wyszukiwania twarzy szwajcarskich skoczków narciarskich wyniki były podobne do tych z poprzednich badań – Google Grafika usilnie analizowała ich ubiór i wskazywała, jakiej marki dresy mogą nosić, jednak nie potrafiła wskazać ich imion ani nazwisk, natomiast Bing poprawnie zidentyfikował obu skoczków i dodatkowo wskazał strony, na których ich wspomniano. Dla stockowego zdjęcia twarzy dziewczyny, które często używane jest jako tło filmów na YouTube oraz jako zdjęcie profilowe kont w różnych mediach społecznościowych, oba narzędzia wskazały poprawne dopasowania ściśle dla danego obrazu, wskazując zarówno linki do filmów, jak i do profili.
Wyszukiwanie zdjęć osób, które nie są znanymi postaciami, może przysporzyć nieco więcej kłopotu, jednak są i na to sposoby. Jednym z nich jest znana i bardzo dobra wyszukiwarka twarzy (także bazująca na modelach AI) – PimEyes. Należy jednak pamiętać, że zgodnie z regulaminem usługi można tam jedynie wyszukiwać siebie, a nie inne osoby.
Przy okazji wyszukiwania na podstawie zdjęć trafiłem też na inny serwis – IDCrawl, który co prawda nie bazuje na informacji graficznej, a klasycznie – na wyszukiwaniu tekstowym, jednak można tam także zidentyfikować dużo zdjęć profilowych należących do wyszukiwanych osób.
Kolejni gracze
Vehicle AI
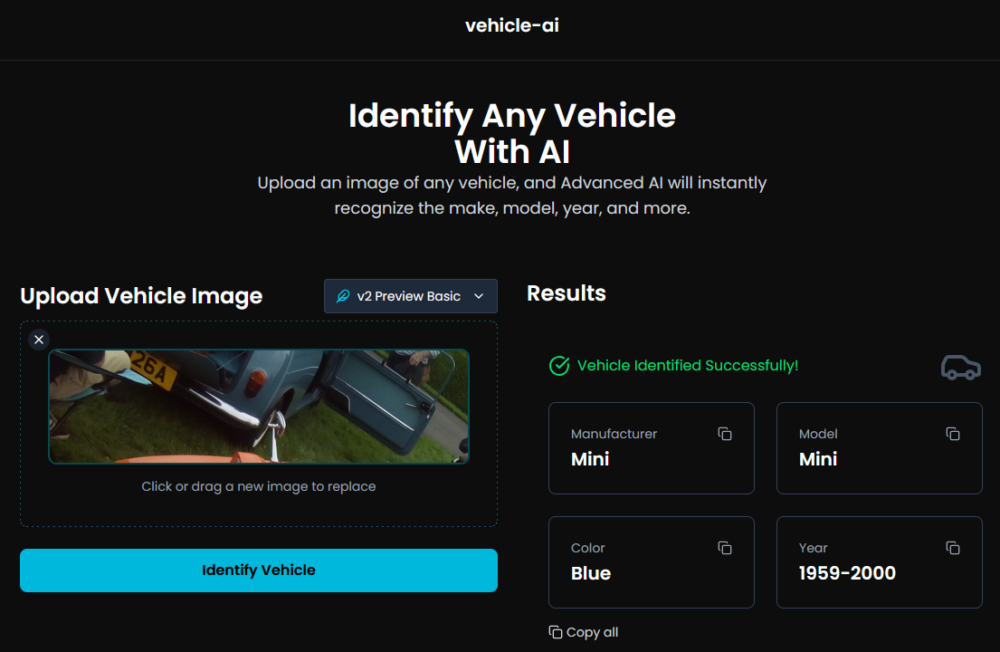
Jednym z ciekawych narzędzi do rozpoznawania marki i modelu samochodu na podstawie zdjęcia, jest Vehicle AI, które wykorzystuje model Google Gemini. Jest to prosty skrypt, który jest dostępny na stronie https://vehicle-ai.vercel.app. Dostępny jest także kod aplikacji na Githubie, do samodzielnego uruchomienia.
Wyniki analiz, wykonanych na bazie zdjęć, których wcześniej używałem do badań, wypadły naprawdę nieźle. Wszystkie pojazdy zostały poprawnie zidentyfikowane, a dodatkowo wskazane zostały kolor (to akurat niewielkie osiągnięcie) i data produkcji modelu.
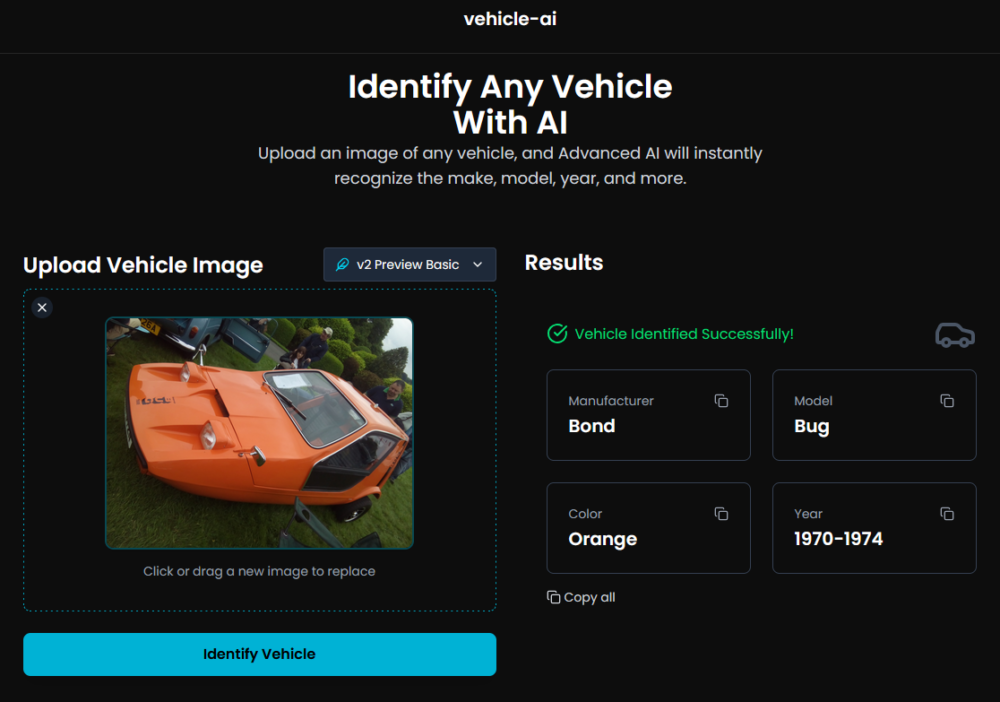
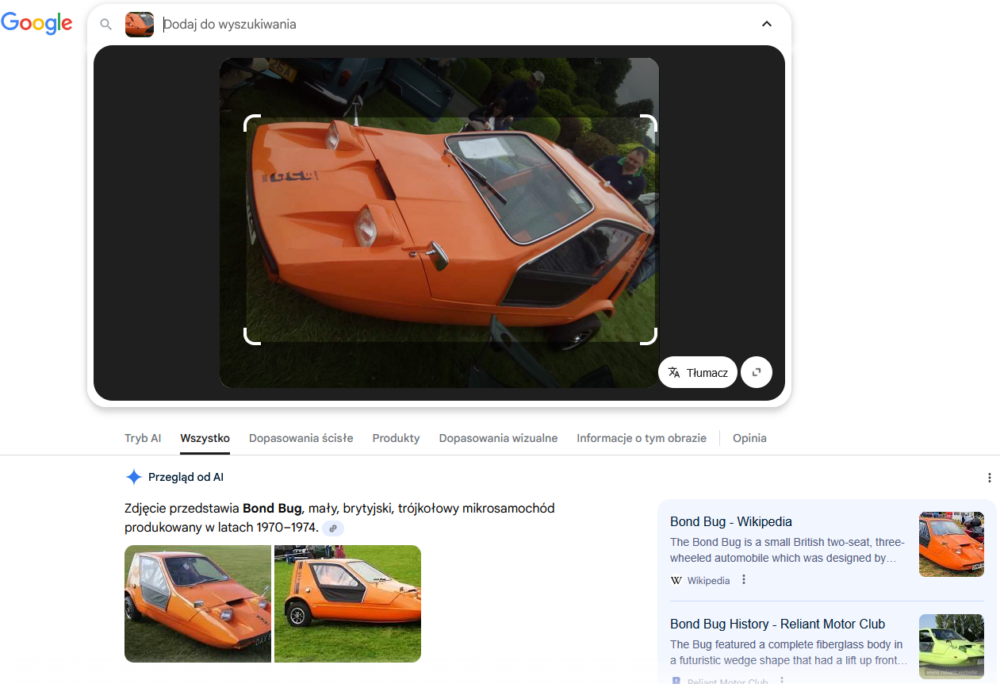
Nawet identyfikacja pojazdu, znajdującego się w rogu zdjęcia Bond Buga przyniosła całkiem dobre, chociaż nie idealne rezultaty.
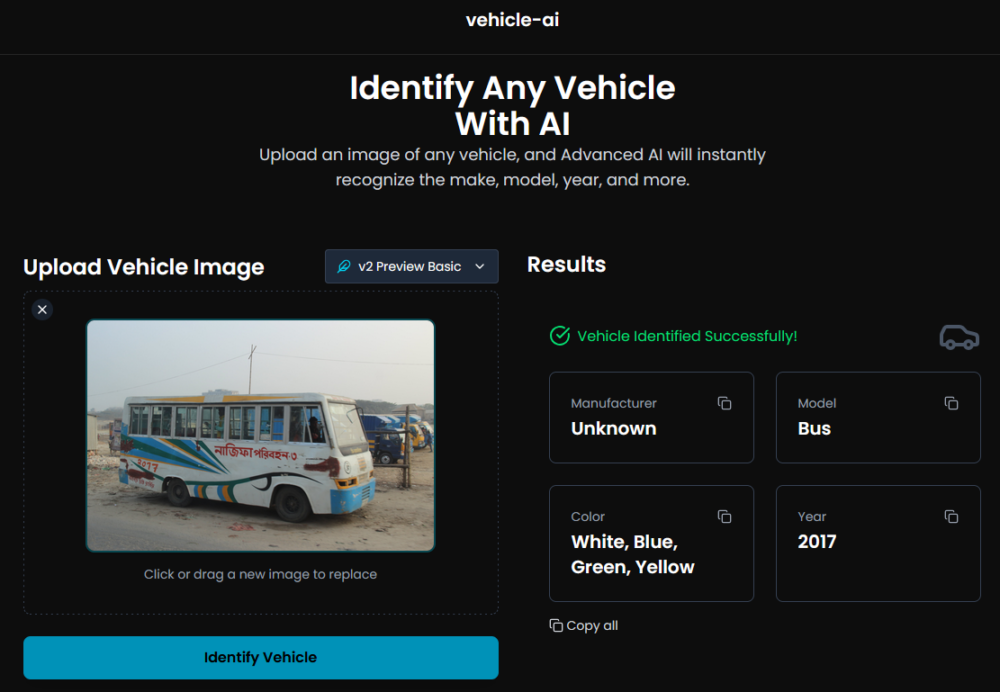
Co prawda, jak to bywa z modelami AI, i ten nie chciał się przyznać do słabości i w przypadku, gdy nie udało mu się zidentyfikować poprawnie marki autobusu z Bangladeszu, i tak określił wynik jako „sukces”, chociaż jego data produkcji to po prostu napis sczytany z boku pojazdu. Ot, taki mały przykład halucynacji.
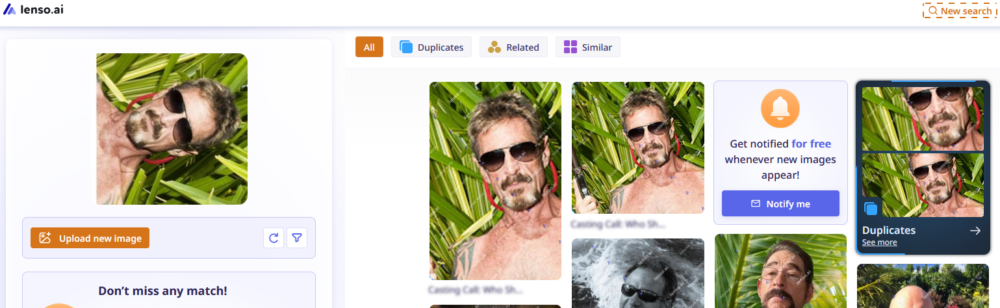
Lenso.ai
Obecnie poza tymi najbardziej rozpowszechnionymi wyszukiwarkami za pomocą obrazu dostępnych jest też wiele innych narzędzi OSINT-owych. Jednym z nowych serwisów wykorzystujących modele AI jest Lenso.ai, które umożliwia wyszukiwanie w takich kategoriach, jak: twarze, miejsca, kopie obrazu, powiązane lub podobne obrazy. Dobrze radzi sobie z wyszukiwaniem podobnych obrazów, nawet po ich modyfikacji (w przeciwieństwie do „gigantów” odnalazło oryginalny obraz dla obróconej o 90 stopni twarzy), jednak nie wskazuje informacji z analizy obrazu, a opcja wyszukiwania twarzy nie jest dostępna dla Europy. Tak samo jak w PimEyes, żeby odblokować wszystkie funkcjonalności, konieczne jest wykupienie subskrypcji. Nadal jednak warto z niego skorzystać, nawet w darmowym zakresie, gdyż nigdy nie wiadomo, czy nie uzyska się tam tego jednego, przełomowego wyniku, który nie został znaleziony przez inne wyszukiwarki obrazów.
Dostępność technologii AI powoduje powstawanie coraz to nowych narzędzi dla konkretnych grup odbiorców (np. Pixsy dla fotografów i artystów, którym zależy na tym, aby automatycznie wyłapywać kopie ich fotografii i dzieł na innych stronach w internecie).
Podsumowanie
Wykorzystanie modeli AI do analizy i wyszukiwania obrazów wprowadziło dużo usprawnień do dotychczasowych mechanizmów, które skupiały się głównie na znajdowaniu tej samej zawartości, a omijały wyniki zawierające modyfikacje. Obecnie oprócz znajdowania podobnych zdjęć dostępna jest także analiza tekstowa ich zawartości, która może być dodatkowym głosem podczas śledztw OSINT-owych. Twórcy otrzymali narzędzia do śledzenia nielegalnego kopiowania ich prac w sieci, fact-checkerzy mogą łatwiej identyfikować dezinformację przez identyfikowanie modyfikacji lub użycia obrazów w innym kontekście, niż były one oryginalnie opublikowane, śledczy mogą szybciej odnajdywać miejsca przedstawione na zdjęciach z różnych zakątków świata. Takich scenariuszy można przytoczyć wiele. Oczywiście „z wielką mocą wiąże się też wielka odpowiedzialność”, gdyż np. dokładność identyfikacji zdjęć osób w sieci i możliwość odnajdywania ich w różnych zakątkach internetu rodzi wątpliwości dotyczące prywatności. Ponadto użytkownik rzadko jest świadomy tego, w jaki sposób wykorzystywane przez niego aplikacje działają i czy w ich przygotowaniu nie popełniono błędów. Pomimo dużego skoku technologicznego narzędzia do wyszukiwania obrazów nadal mogą być niewrażliwe na drobne zmiany lub mogą nie rozumieć pełnego kontekstu przedstawionego na obrazie. Wiele z nich wymaga płatności, a użytkownicy często i tak nie otrzymują w zamian dokładnego zestawu wyników, a są „bombardowani” licznymi zupełnie nieistotnymi znaleziskami. Narzędzia mniejszych firm nie mają tak szerokiego dostępu jak Google czy Microsoft, które indeksują obrazy w internecie już od wielu lat.
Wykorzystanie modeli AI do rozpoznawania obrazu zmieniło jednak sposób, w jaki użytkownicy smartfonów korzystają z ich możliwości. Dzisiaj wizyta w obcym kraju, szczególnie bez znajomości języka, a nawet systemu pisma, nie jest już tak przerażająca, gdyż dostępne aplikacje do tłumaczenia na bieżąco analizują obraz z kamery i pomagają odnaleźć się wielu turystom. Korzystanie z wyszukiwarek obrazem w platformach sprzedażowych pozwala z kolei wyszukać bardziej dopasowane produkty.
Użytkownicy powinni jednak cały czas pamiętać, że narzędzia – chociaż powoli zyskują cechy ludzkiego doradcy i analityka – nadal pozostają jedynie narzędziami. To na użytkowniku końcowym spoczywa odpowiedzialność za prawidłową interpretację wyników i konieczność zachowania racjonalnego myślenia, bo w innym przypadku mogą się oni znaleźć w tym samym miejscu, gdzie użytkownicy nawigacji GPS, którzy zawierzyli im bezkrytycznie.
Do każdej pracy należy dobrać odpowiednie narzędzie – innej wyszukiwarki należy użyć do wyszukiwania identycznych kopii obrazu (np. klasyczny TinEye), a innej do analizy zawartości obrazu i poszukiwania jego modyfikacji. Warto też zwrócić uwagę na jakość wgrywanego zdjęcia, gdyż im lepszej jest jakości, tym trafniejsza będzie jego analiza. Należy również uważnie zapoznać się z regulaminami poszczególnych usług, szczególnie jeśli do wyszukiwania wykorzystywane jest zdjęcie, którego nie można uznać za publiczne w internecie, gdyż w każdej chwili może się takim stać.
Jeśli chodzi o porównanie wyników Google i Bing w różnych obszarach, to dla większości podstawowych przypadków lepsza okazała się Grafika Google, zarówno w zakresie opisu wgranych zdjęć, dokładności odpowiedzi, jak i analizy szczegółów zawartych w obrazie. Bing natomiast okazał się klasycznie dużo lepszy w rozpoznawaniu twarzy oraz dopasowywaniu podobnych kompozycji w wynikach wyszukiwania obrazem.
Jestem pewien, że kolejne lata przyniosą dalszy, dynamiczny rozwój narzędzi wyszukiwania za pomocą obrazu, więc warto śledzić nowinki na tym polu.
Krzysztof Wosiński

super!