Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

Czym jest Web Application Firewall? – część pierwsza: na przykładzie naxsi
Od redakcji: zapraszamy do lektury tekstu naszego czytelnika. To pierwsza część tekstu o Web Application Firewallach – kolejne w przygotowaniu.
Wstęp
W maju br. White Hat Security opublikowało bardzo ciekawe zestawienie różnych statystyk na temat bezpieczeństwa aplikacji webowych. Wśród nich znalazły się informacje, że w roku ubiegłym 86% stron klientów White Hat Security zawierało przynajmniej jedną poważną podatność, czyli taką która pozwala na:
- przejęcie całkowitej lub częściowej kontroli nad stroną,
- na naruszenie bezpieczeństwa kont użytkowników,
- na dostęp do ważnych danych,
a średni czas załatania takiej dziury wynosił 193 dni, licząc od pierwszego powiadomienia.
Natomiast Imperva w swoim lipcowym raporcie o bezpieczeństwie aplikacji webowych donosi, że w ciągu pół roku aplikacje były poważnie atakowane średnio co 12 dni.
To daje nam 16 udanych ataków o poważnych konsekwencjach przed naprawieniem podatności.
Wiadomo, że oficjalne naprawy mogą być powolne, a nieoficjalne mogą kosztować nas utratę gwarancji. W tym momencie z pomocą może przyjść nam WAF (ang. Web Application Firewall), czyli zapora sieciowa dedykowana ochronie aplikacji webowych.
Tu może nasunąć się jednak pytanie: „Ale jest przecież IPS, to po co mi ten WAF?”.
Przyjrzyjmy się zatem każdemu z nich z osobna.
Krótka charakterystyka
1. IPS
IPS (ang. Intrusion Prevention System) to system wykrywający i przeciwdziałający potencjalnym zagrożeniom w sieci lub systemie komputerowym. Dzieli się on na kilka rodzajów, np.:
- sieciowy (NIPS – network-based IPS) – monitorujący ruch w konkretnych segmentach sieci;
- hostowy (HIPS – host-based) – monitorujący konkretny system;
- bezprzewodowy (WIPS – wireless) – monitorujący ruch w sieci bezprzewodowej.
Dla najpopularniejszego wariantu – NIDS-a – wykrywanie niebezpieczeństw polega na wyszukiwaniu:
- anomalii w normalnym ruch w sieci czy zachowaniu systemu (przykładem anomalii jest np. znacznie większy ruch do serwera www niż dotychczas);
- nieprawidłowości w zachowaniu protokołów;
- potencjalnych ataków na bazie znanych wzorców zagrożeń.
Przykładowe IDSy: Snort (NIPS), OSSEC (HIPS), Motorola AirDefense (WIPS).
2. WAF
WAF jest dedykowany do ochrony aplikacji webowych i można go znaleźć np. pod postacią modułu do danego serwera webowego. Pozwala kontrolować ruch od i do naszej aplikacji, wykorzystując przy tym wcześniej przygotowane zasady, które mogą być tworzone na dwa sposoby:
- model negatywny (blacklist) – polegający na tworzeniu listy treści niebezpiecznych, które zostaną zablokowane, zmienione lub odnotowane w logach, zależnie od naszej konfiguracji;
- model pozytywny (whitelist) – polegający na stworzeniu listy zaakceptowanych treści, które zostaną przepuszczone, a cała reszta zostanie jw. zablokowana, zmodyfikowana lub odnotowana w logach.
Dzięki modelowi negatywnemu możemy, bez ingerencji w strukturę naszej aplikacji, w łatwy i szybki sposób naprawić odkryte podatności. Natomiast model pozytywny lepiej blokuje nieznane ataki, ponieważ konkretyzuje dozwolone treści, co wymaga więcej pracy przy jego wdrożeniu.
Przykładowe WAFy: ModSecurity (rozbudowany, obsługuje wiele rodzajów serwerów webowych), NAXSI (prosty moduł serwera Nginx).
3. Różnice
IPS zapewnia nam szeroką wielopoziomową ochronę naszej sieci oraz znajdujących się w niej maszyn. Możemy równocześnie chronić naszą aplikację webową i inne usługi przed różnymi próbami ataku.
WAF jest wyspecjalizowanym narzędziem skupiającym się na ochronie konkretnych aplikacji webowych. Pozwala zabezpieczyć podatną aplikację bez ingerencji w nią samą, co jest bardzo przydane w sytuacjach, kiedy np. obejmuje nas umowa gwarancyjna i należy czekać na serwisanta lub oprogramowanie nie jest już wspierane.
Przykłady praktyczne
Przejdźmy zatem do konkretnego przykładu.
1. NAXSI – carakterystyka
NAXSI (ang. Nginx Anti XSS & SQL Injection) to darmowy moduł WAF serwera webowego Nginx. Cechuje go prosta, ale skuteczna metoda działania.
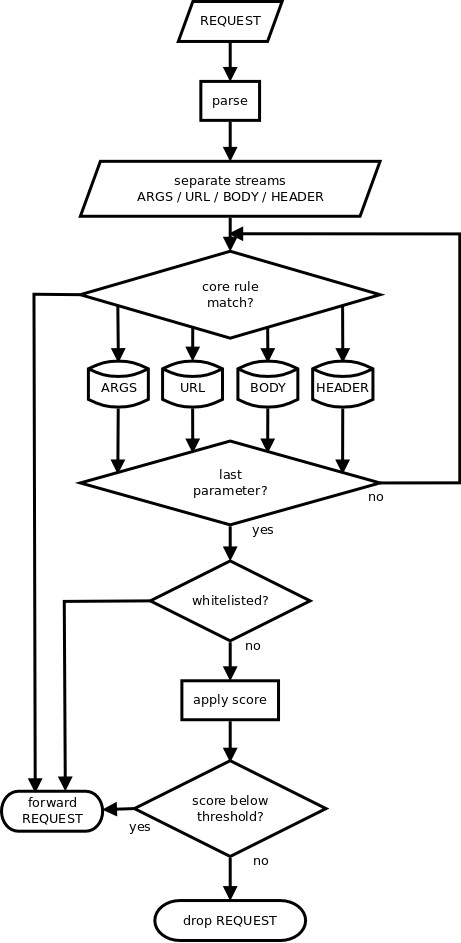
źródło: Naxsi performance measurment.
Przyjęte żądanie jest analizowanie i dzielone na odrębne strefy:
- ARGS zawiera argumenty typu GET;
- URL pełne URI;
- BODY zawiera argumenty typu POST;
- HEADERS zawiera nagłówki HTTP.
Każdą z tych stref można porównać z krótką ogólnoserwerową blacklistą, która w zależności od zawartości nadaje żądaniu określoną liczbę punktów w kategoriach:
- SQL Injections;
- RFI (ang. Remote File Inclusion);
- LFI (ang. Local File Inclusion lub inaczej Directory Traversal);
- XSS (ang. Cross Site Scripting);
- Evasion tricks;
- File uploads.
Następnie sprawdzana jest whitelista dla konkretnej lokalizacji, w której mogą znaleźć się bardziej szczegółowe instrukcje nakazujące zignorowanie uprzednio wybrane reguły oraz nadanie przez nie punktacje. Na końcu podsumowane są punkty z każdej kategorii i jeżeli przekroczony został ustalony pułap, żądanie zostaje zablokowane. Oznacza to, że zostaje ono przesłane do DeniedURL, gdzie znajdują się dalsze instrukcje.
Uwaga! NAXSI na razie filtruje tylko i wyłącznie komunikację przychodzącą, jeżeli na stronie już znajduje się np. komentarz zawierający złośliwy skrypt, nie będzie on blokowany przez WAF.
Tak zbudowany model jest w stanie bardzo szczegółowo określić, co zostanie odebrane przez naszą aplikację, zapewniając jej maksymalną ochronę. Jak widać możliwości są szerokie, co wcale nie oznacza, że zadanie jest trudne.
Twórcy NAXSI dostarczają nam stworzoną przez nich blacklistę (naxsi_core.rules), zawierającą większość znanych wzorców ataków, oraz plik (naxsi.rules) z podstawowymi ustawieniami i określonym przez nich progiem punktowym.
2. Reguły NAXSI
Przyjrzyjmy się składni tzw. reguł głównych znajdujących się w blackliście:
MainRule „str:wzorzec” [„rx:wzorzec1|wrorzec2”] „msg:komentarz” „mz:strefy” „s:kategoria:punktacja” id:numer;
1. str:wzorzec – (string) występowanie ciągu znaków „wzorzec” uaktywni regułę;
2. rx:wzorzec1|wzorzec2 – (regular expresion) wyrażenie regularne stosowane do tworzenia większej liczby wzorców dla jednej reguły (wzorce rozdzielane są „|”), działa na tej samej zasadzie co „str”.
3. msg:komentarz – (message) przy wywołaniu reguły tekst o treści „komentarz” zostanie umieszczony w logach.
4. mz:strefy – (matchzones) reguła dotyczy konkretnych stref, argumentów lub nagłówków (rozdzielane „|”):
- ARGS – argumentów typu GET;
- HEADERS – nagłówków HTTP;
- BODY – argumentów typu POST;
- URL – URL (przed „?”);
- NAME – ten przyrostek oznacza, że celem jest nazwa zmiennej (nie jej zawartość).
- $ARGS_VAR: czarna – argument typu GET;
- $BODY_VAR:kawa – argument typu POST;
- $HEADER_VAR:jest – nagłówek HTTP;
- $URL:/super – konkretny URL.
5. s:kategoria:punktacja – (score) określa liczbę punktów, która zostanie przydzielona w jednej z ww. kategorii:
- $SQL – SQL Injection;
- $RFI – Remote File Inclusion;
- $TRAVERSAL – Directory Traversal;
- $XSS – Cross Site Scripting;
- $EVADE – Evation Tricks;
- $UPLOAD – File Upload.
6. id:numer – (identification number) unikalny numer reguły.
Dla lepszego zrozumienia przeanalizujmy jedną regułę z pliku naxsi_core.rules:
MainRule „rx:select|union|update|delete|insert|table|from|ascii|hex|unhex” „msg:sql keyword” „mz:BODY|URL|ARGS|$HEADERS_VAR:Cookie” „s:$SQL:4” id:1000;
Reguła o numerze 1000 przydzieli 4 punkty w kategori SQL Injection każdemu żądaniu, które w argumentach GET lub POST, w URL, lub w ciasteczku będzie zawierało ciąg znaków „select”, „union”, „update”, „delete”, „insert”, „table”, „from”, „ascii”, „hex” albo „unhex”, dodatkowo w logach opisze je komentarzem „sql keyword”.
Przejdźmy do składni reguł podstawowych znajdujących się w whiteliście, które wyglądają podobnie jak reguły główne:
BasicRule wl:ID [mz: [$URL:target_url] | [match_zone] | [$ARGS_VAR:varname] | [$BODY_VARS:varname] | [$HEADERS_VAR:varname] ];
1. wl:ID – (WhiteList:ID) określa, które reguły zostają zignorowane, np.:
- wl:0 – wszystkie reguły zostają zignorowane;
- wl:16,11,22 – reguły nr 11, 16 i 22 zostaną zignorowane.
2. mz: – w tym miejscu określa się warunki jakie muszą być spełnione by dana reguła została ignorowana, składnia jest identyczna jak w przypadku reguł głównych.
Dla wyjaśnienia przyjrzyjmy się kilku przykładom:
- BasicRule wl:1302; – kompletnie zignoruj regułę nr 1302.
- BasicRule wl:1000 „mz:$ARGS_VAR:status”; – nie stosuj reguły nr 1000, sprawdzając zawartość argumentu o nazwie „status”.
- BasicRule wl:1400 „mz:$ARGS_VAR:from|$URL:/location”; – nie stosuj reguły nr 1400, sprawdzając zawartość argumentu o nazwie „from” dla URL „/location”.
- BasicRule wl:1000 „mz:$URL:/bar|ARGS”; – nie stosuj reguły nr 1000, sprawdzając wszystkie argumenty typu GET dla URL „bar”.
- BasicRule wl:1000 „mz:ARGS|NAME”; – nie stosuj reguły nr 1000, sprawdzając nazwy (tylko nazwy, nie ich zawartość) wszystkich argumentów typu GET.
Widzimy, że pisanie whitelisty nie jest trudne, ale może być pracochłonne. Na szczęście twórcy NAXSI pomyśleli o tym i nasz WAF domyślnie uruchamiany jest w trybie “nauki”, co w praktyce oznacza, że zamiast blokować ew. próby ataku, będzie je odnotowywał w logach (error.log), z których to możemy wygenerować odpowiedni zbiór zasad dla naszej aplikacji. Należy pamiętać, że wymaga to od nas dostarczenia zaufanego ruchu, np. z wcześniej przygotowanego automatu testującego.
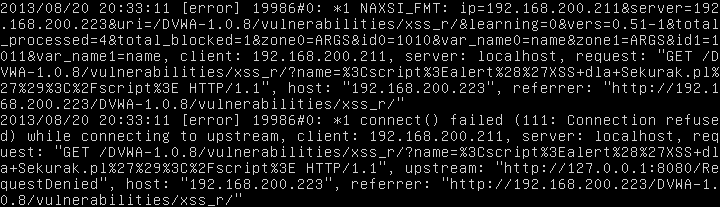
Przykładowa wykryta i zablokowana próba ataku odnotowana w logach.
W analizie logów pomaga nam przygotowany i dostępny na stronie twórców NAXSI skrypt nx_util. Pozwala on nie tylko wygenerować whitelistę, ale również przenieść nasze logi do bazy danych SQLite oraz wygenerować raport aktywności w postaci pliku html. Może on analizować dane z konkretnej ścieżki, strumienia wejściowego (stdin) albo spakowane gzipem.
nx_util.py [-hoi] [-l Plik_logów] [-H Plik_html] [-d Baza_danych] [-f Filtr]
- -h, –help – wyświetla pomoc;
- -d DB, –dbname=DB – tworzy bazę danych (sqlite3) o nazwie „DB” (domyślnie baza danych nazywa się „naxsi_sig” i znajduje się w katalogu głównym Nginx);
- -i, –incremental – dodaje wpisy do istniejącej bazy danych zamiast tworzyć nową;
- -H plik_html, –html-out=plik_html – tworzy raport aktywności w pliku o ścieżce „plik_html”, (do generacji raportów wymagany jest Python-geoip);
- -o, –out – generuje whitelistę do strumienia wyjściowego (stdout);
- -l plik_logów, –log plik_logów – analizuj logi znajdujące się w pliku o ścieżce „plik_logów”, (jeśli ścieżka jest pusta analizowany jest strumień wejściowy);
- -f filtr – określa, jakiego filtru użyć podczas analizy logów na podstawie słów kluczowych (ip, uri, date, server, zone, var_name, id, content, coutry) oraz operatorów (=, !=, =~, dla dat: >, <, <=, >=), do filtracji krajów wymagany jest Python-geoip.
Dla przykładu:
cat /var/log/nginx/error.log | nx_util.py -l -f 'ip =~ 192.*' -H logs.html
Wygeneruje nam raport o aktywności hostów o adresach ip zaczynających się na 192.
A wygląda on mniej więcej tak:
3. Zastosowania praktyczne
Teoria teorią, ale warto by sprawdzić jak NAXSI spisuje się w praktyce.
W tym celu nasz WAF (pracujący na domyślnych ustawieniach – oczywiście z wyłączonym trybem „nauki”) uruchomimy na skonfigurowanym przez nas serwerze pośredniczącym (reverse proxy).
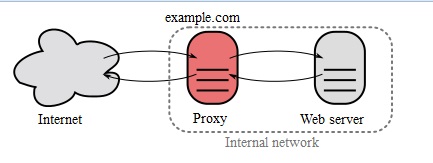
Koncepcja serwera pośredniczącego jest powszechnie stosowana. Pozwala ona odciążyć serwer lub grupę serwerów docelowych, np. przez:
- przechowywanie statycznych zawartości serwerów docelowych (caching);
- pełnienie funkcji szyfrującej (SSL/TLS);
- pełnienie funkcji zapory sieciowej dla aplikacji webowych (WAF).
Ustawiamy nasze proxy dla strony Altoro Mutual, która została stworzona przez firmę IBM w celu pokazania działania ich skanera podatności AppScan (wynik starcia „AppScan vs. NAXSI” można zaleźć tutaj). My jednak użyjemy darmowego programu Subgraph Vega, wykrywającego takie popularne podatności jak XSS, SQL Injection, LFI itp., i wspomożemy go jednym z najgroźniejszych narzędzi w sieci, przeglądarką Mozilla Firefox, by sprawdzić czy wykryte podatności można wykorzystać.
Jak widać nasz skaner wykrył całkiem sporo dziur. Zobaczmy jak poradzi sobie z tym problemem WAF.
Wynik skanowania aplikacji chronionej przez NAXSI.
NAXSI, tak jak przewidywaliśmy, ochroniło stronę, redukując liczbę wykrytych krytycznych podatności. Przyjrzyjmy się temu, co zostało:
- Nieszyfrowane uwierzytelnienie przez HTTP – tu niestety WAF nam nie pomoże.
- Przesłanie nieszyfrowanego hasła przez HTTP – jw.
- Potencjalne zagrożenie LFI – Vega użyło ciągu znaków „/./” by określić potencjalną podatność. Zbadajmy to dokładniej.
Za cel weźmiemy podstronę default.aspx i jej parametr content, oczywiście chwilowo wyłączamy WAF, by nie przeszkadzał nam w potwierdzaniu podatności. Szybko dowiadujemy się, że ten parametr przyjmuje tylko nazwy plików z rozszerzeniem „htm” lub „txt”.
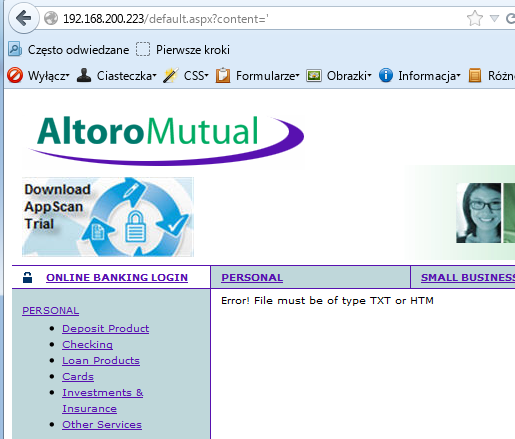
http://192.168.200.223/default.aspx?content=%27.
Zatem podajmy mu plik, który najprawdopodobniej nie istnieje, np.: „lubiewafle.htm”, i zobaczmy, co się stanie.

http://192.168.200.223/default.aspx?content=lubiewafle.htm.
Dostaliśmy błąd, który nie tylko informuje nas, że nie znaleziono naszego pliku, ale podaje również pełną ścieżkę dostępu do katalogu, w którym powinienem znajdować się nasz plik. Mając tą wiedzę, możemy spróbować w dość nietypowy sposób otworzyć dowolną podstronę i zobaczyć, czy to samo żądanie zostanie zaakceptowane, kiedy włączymy WAF.

Udana próba otworzenia podstrony przy wyłączonym WAF-ie.
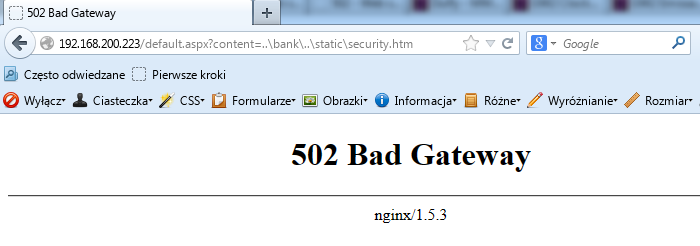
NAXSI blokuje żądanie wyświetlenia podstrony.
Pokazaliśmy tym samym, że nawet bardzo podatną aplikację można zabezpieczyć, nie ingerując w jej strukturę. Może się więc zdarzyć, że podatność zostanie wykryta, ale wszelkie próby jej wykorzystania zostaną zablokowane.
— Daniel Iziourov (daniel.iziourov<sekurak>gmail.com)
Źródła
[1] https://www.whitehatsec.com/assets/presentations/stats2013_infograph_large.jpg
[2] http://www.imperva.com/docs/HII_Web_Application_Attack_Report_Ed4.pdf
[3] https://www.owasp.org/index.php/Web_Application_Firewall
[4] http://csrc.nist.gov/publications/nistpubs/800-94/SP800-94.pdf
[5] http://code.google.com/p/naxsi/
[6] http://naxsi.googlecode.com/svn/wiki/paper.pdf/

{kind=link}
Dzięki. W końcu jakiś fajny art w jęz. polskim w tym temacie ;)
Nie zapominajmy o zbblock :)