Zapobieganie–wykrywanie–przeciwdziałanie
Obrona przeciwko atakom odmowy dostępu do usługi jest bardzo specyficzna. Aby zminimalizować ryzyko wyczerpania zasobów spowodowanych atakami (D)DoS, należy:
- zapobiegać (prewencja), czyli wdrażać zalecenia pozwalające uniknąć ataków DDoS (BCP 38, BCP 84, BCP 140…), minimalizować powierzchnię ataku, przeprowadzać hardening, audyty oraz testy penetracyjne infrastruktury;
- wykrywać (detekcja) przez monitoring sieci oraz analizę anomalii;
- przeciwdziałać (odpowiedź), biorąc aktywny udział w łagodzeniu skutków ataku oraz współpracując z dostawcami internetowymi.
Zanim szczegółowo omówimy powyższe strategie, przyjrzyjmy się najpierw tematowi outsorcingu czynności minimalizujących skutki ataków DDoS.
1. Ochrona przeciwko DDoS jako usługa
Obecnie kompleksową ochronę przeciwko największym atakom DDoS można uzyskać praktycznie wyłącznie przez współpracę z firmami specjalizującymi się w zapobieganiu tego rodzaju atakom. Firmami z dużym doświadczeniem w łagodzeniu skutków DDoS są m.in. Prolexic, ArborNetworks oraz Cloudflare.
W jaki sposób firmom tym udaje się odeprzeć nawet największe ataki? Aby poznać odpowiedź na to pytanie, przeanalizujmy strategię obrony Cloudflare.
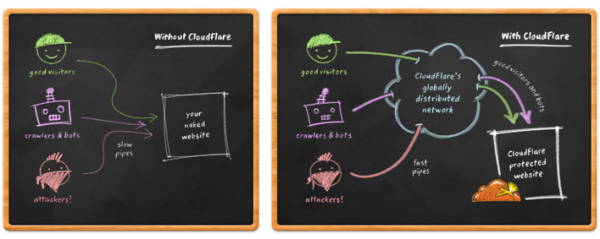
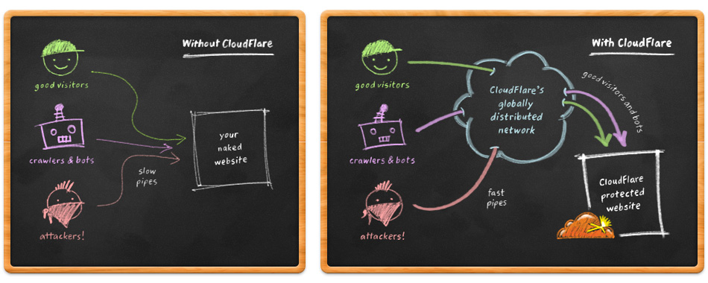
Diagram 1. Ogólny schemat działania Cloudflare (źródło).
Fundamentalną techniką obrony przeciwko napływającym pakietom jest ukrycie swoich usług w infrastrukturze Clodflare, która m.in. używa własnych centr będących odpowiednikami urządzeń pośredniczących w sieci. Centra rozłożone są geograficznie po całym świecie, komunikacja między nimi odbywa się jednak z wykorzystaniem transmisji anycast. Różni się ona od transmisji unicast (stosowanej zazwyczaj w przypadku, gdy nasz serwer jest poza infrastrukturą Cloudflare), gdyż żądania klientów (botów) wysyłane są do topologicznie najbliższego węzła, czyli centrum danych Cloudflare.
Powyższe rozwiązanie nie tylko skraca drogę transmisji pakietu do danego serwera, przez co usługa zaczyna odpowiadać zdecydowanie szybciej, w szczególności gdy używana jest przez klientów z całego świata. Można sobie wyobrazić, że pakiet przechodzi przez mniejszą liczbę urządzeń, które w dodatku są dużo wydajniejsze, przez co np. strony ładowane są szybciej.
Oprócz optymalizacji, powyższe rozwiązanie staje się pierwszą linią obrony przeciwko atakom DDoS. Po dołączeniu do usługi, chroniony serwer zaczyna być widoczny pod adresem IP Cloudflare, a DDoS zmienia formę: z ataku “wiele–do–jednego” na “wiele–do–wielu”. Rozłożenie ruchu na kilkadziesiąt centrów Cloudflare w większości przypadków pozwala na odetkanie przeciążonego serwera dosłownie kilka minut po dołączeniu do chronionej sieci (w momencie pisania artykułu było to 25 węzłów, których stan można na bieżąco monitorować).
Dalsze kroki zapobiegania atakom mogą być wykonywane już przez samych inżynierów Cloudflare. Oczywiście dużo łatwiej jest monitorować oraz blokować ruch osobno na każdym z kilkudziesięciu węzłów, niż w przypadku gdy atak skierowany byłby na jedno urządzenie. Nieocenione stają się również umowy między Cloudflare a ISP oraz wspólna walka przeciwko zalewającym hostom.
Cloudflare to nie tylko sieć szybkich, odpowiednio rozmieszczonych urządzeń pośredniczących. Po dołączeniu do infrastruktury, chroniona aplikacja znajduje się za wirtualną „tarczą”. Podejrzany ruch może zostać automatycznie odfiltrowany na urządzeniach pośredniczących chmury Cloudflare, a ruch między web aplikacjami i ich klientami będzie dodatkowo przepływał przez firewall aplikacyjny (WAF), który również może wykryć kilka typowych incydentów bezpieczeństwa (niekoniecznie związanych z DoS). Wszystko zadziała automatycznie, a nakład naszej pracy potrzebny do wdrożenia takiej warstwy ochrony będzie minimalny.
Przyglądając się technikom obrony z góry, wszystkie firmy oferujące usługi „anty-DDoS” wdrażają podobne mechanizmy. Oczywiście „pod spodem” każda z firm używa innych sposobów obrony, tak samo jak różna jest skuteczność odpierania ataków. Ogólnie rzecz biorąc, rozwiązania oferowane przez firmy podobne do Cloudflare pozwalają nie tylko obronić się przeciwko DDoS, ale również zoptymalizować działanie usług, dzięki czemu zwiększa się ich wydajność oraz responsywność dla zwykłych użytkowników.
2. Czy takie rozwiązanie jest jednak opłacalne?
Z jednej strony, ogólnie outsourcing w dłuższej perspektywie często okazuje się tańszy niż inwestycja w czas specjalistów, sprzętu i procedur, które należy wdrożyć we własnej firmie. Doświadczenie firm zewnętrznych przyniesie z pewnością dużo większą skuteczność niż próby okiełznania żywiołu przez osoby nie mające na co dzień do czynienia z tym tematem.
Z drugiej strony, firmy wynajmuje się po to, aby przeciwdziałać największym atakom DDoS i to w kluczowych projektach. Analiza ryzyka często wykazuje, że skutki ataku nie będą tak kosztowne, jak outsourcing ochrony DDoS, więc nie zawsze warto od razu decydować się na takie rozwiązanie. Warto zaznaczyć, że do wielu usług można dołączyć nawet podczas ataku, co pozwala zaoszczędzić fundusze.
Duże ataki DDoS wymagają inwestycji po stronie agresorów, którzy nie są skłonni do wyrzucania pieniędzy w błoto. Incydenty masowo zalewające infrastrukturę nie są jednak tak bolesne, jak proste ataki z pojedynczych maszyn, które zaczynają skutecznie paraliżować działanie firmy.
Niezależnie od tego, czy zdecydujemy się na zabezpieczania naszej sieci przez firmy zewnętrzne czy też nie, warto pamiętać, że większość ataków można powstrzymać przez odpowiednią konfigurację sieci oraz udostępnianych aplikacji.
Dowiedzmy się dalej jak można to zrobić…
Zapobieganie (prewencja)
Pierwszym krokiem ochrony przed atakami odmowy dostępu jest zapobieganie. Ataki DDoS o największej skali zazwyczaj wykorzystują proste błędy konfiguracyjne. Aby związać ręce cyberprzestępców, powstało kilka dokumentów opisujących zalecenia dla administratorów oraz ISP, które zmniejszają dotkliwość ataków DDoS (głównie w skali globalnej). Dokumentami z serii Best Current Practices (BCP) opisującymi techniki prewencji przed atakami DDoS są:
- BCP 38 — dotyczy zapobiegania fałszowaniu adresów IP przez m.in. odpowiednie filtrowanie ruchu czy użycie protokołu uRPF (Unicast Reverse Path Forwarding) (2000 r.),
- BCP 84 — opisuje problemy związane z sieciami domowymi (2004 r.),
- BCP 140 — zawiera zalecenia bezpiecznej konfiguracji serwerów DNS, które nie powinny udostępniać publicznie wszystkich usług (2008 r.).
Podążanie za radami przedstawionymi w powyższych zaleceniach pozwoli nie tylko ochronić się przed niektórymi rodzajami ataków, ale przede wszystkim utrudni wykorzystanie infrastruktury do ataku na inny cel. Wdrożenie zaleceń powyższych dokumentów powinny uzupełnić
audyty, testy penetracyjne oraz
szkolenia dla administratorów, w których omawia się problematykę hardeningu oraz monitoringu infrastruktury sieciowej.
Uogólniając, najskuteczniejszą metodą zapobiegania atakom (w zasadzie dowolnego rodzaju) jest zmniejszanie powierzchni ataku, głównie przez szczegółową konfiguracją systemów i urządzeń — czym mniejsza liczba usług oraz dozwolonych akcji, tym mniejsze pole manewru dla atakującego.
Blokowanie niepotrzebnego lub nieprawidłowego ruchu potrafi znacznie złagodzić skutki ewentualnego ataku, podobnie jak inne sztuczki zmniejszające powierzchnię ataku. Poniżej przedstawiono kilka rad, które staną się niecenione, w momencie ataku.
1. Przygotowanie infrastruktury
Aby zminimalizować skutki ewentualnego ataku, należy zawczasu przygotować infrastrukturę sieciową w taki sposób, aby automatycznie wykrywała podejrzany ruch i go odrzucała.
Można to uzyskać poprzez:
- blokowanie niepotrzebnego ruchu sieciowego — zmniejszenie powierzchni ataku najłatwiej uzyskać przez zablokowanie takiego rodzaju ruchu, co do którego jesteśmy pewni, że nie będzie przechodził przez dane urządzenie pośredniczące. Planując infrastrukturę sieci, warto zbadać, jaki rodzaj ruchu w stronę naszych usług jest niezbędny, i zdecydować, czy można odrzucić pozostały ruch. Może się okazać, że na routerze brzegowym można całkowicie wyłączyć np. ruch ICMP na niektórych interfejsach (oczywiście należy robić to świadomie – filtracja wszystkich komunikatów ICMP powoduje problemy np. w mechanizmach MTU Path Discovery), UDP lub chociażby NTP, a nawet pójść krok dalej i poprosić ISP o blokowanie tego rodzaju ruchu (w usługach takich jak Amazon AWS EC2/VPC można to zrobić samemu);
- blokowanie nieprawidłowego ruchu sieciowego — firewall oraz urządzenia pośredniczące powinny wykrywać podstawowe anomalie w ruchu sieciowym, analizując dane przychodzące oraz wychodzące. Bardzo pomocne we wdrożeniach okażą się dokumenty BCP 38, BCP 84 oraz BCP 140, które m.in. podpowiedzą, dlaczego i w jaki sposób ograniczyć IP Spoofing, w jaki sposób bezpiecznie interpretować adresy sieci prywatnych w pakietach oraz co daje routerom tryb Unicast RPF (ang. Reverse Path Forwarding);
- wyłączenie rozgłaszania IP — routery graniczne powinny za wszelką cenę wyłączać funkcje rozgłaszania (ang. broadcast) na publicznych interfejsach. Możliwość rozgłaszania żądań z zewnątrz (czasem również z wnętrza sieci) może okazać się tragiczne w skutkach, w szczególności w połączeniu z innymi zaniedbaniami (takimi jak możliwość fałszowania IP), które mogą prowadzić do ataków wzmocnionego odbicia, np. Smurf Attack. Technika tzw. direct broadcast może zostać wykorzystana przez atakującego, który może zacząć wysyłać pakiety IP na znany adres rozgłoszeniowy danej podsieci. Urządzenie pośredniczące w takim wypadku musi wysłać do wszystkich urządzeń w podsieci odpowiedni komunikat – co wygeneruje duży ruch oraz pewną ilość obliczeń na wielu maszynach. Na szczęście coraz więcej urządzeń sieciowych domyślnie wyłącza możliwość rozgłaszania IP — przykładem są tu urządzenia Cisco pracujące pod kontrolą IOS 12+, gdzie domyślnie włączana jest opcja no ip direct-broadcast;
- wykonanie hardeningu serwerów sieciowych i urządzeń pośredniczących — „utwardzanie” konfiguracji systemów powinno być nastawione na ograniczanie liczby usług oraz na zamykanie niepotrzebnych portów na publicznych interfejsach sieciowych, wprowadzanie list kontroli dostępu oraz silnych metod uwierzytelniania. Warto też wdrożyć konfigurację, która pozwoli w mniej zachłanny sposób używać pamięci i mocy obliczeniowej urządzeń (np. należy zwracać uwagę na fragmentację IP czy diagnostykę TTL, gdzie wartość 0 powoduje konstrukcję pakietów ICMP Type 11, Code 0, co zużywa moc obliczeniową i generuje dodatkowy ruch).
2. Szersze spektrum prewencji
Paraliż infrastruktury nie musi być skutkiem wyczerpania łącza, a mocy czy pamięci serwerów, dlatego ważna jest nie tylko prewencja przez zalewaniem, ale również przeciwko atakom skierowanym w warstwę aplikacji.
Aby zminimalizować skutki ataków aplikacyjnych DDoS, należy:
- rozpraszać usługi — gdy monitoring, usługi bezpieczeństwa oraz usługi klienckie działają na tej samej maszynie, wtedy nawet atak o małej skali wyczerpie całą moc obliczeniową lub pamięciową serwera przetwarzającego ogromne ilości danych. Usługi monitorujące sieć powinny być wydzielone do dedykowanej maszyny, podobnie jak bazy danych, miejsca składowania danych, a nawet niektóre elementy logiki aplikacji (np. przy wykorzystaniu web serwisów). Dobrym pomysłem jest również używanie kilku serwerów aplikacyjnych ustawionymi za load-balancerami, co nie tylko zwiększy dostępność usług, ale zmniejszy skuteczność niektórych rodzajów ataków (m.in. Slowloris). Warto również posiadać awaryjny serwer poza używaną infrastrukturą , który będzie służył jako deska ratunkowa do komunikacji z klientami odciętymi wskutek ataku DoS. Bardzo ważne, aby zawsze utrzymywać komunikację z klientami i informować o ataku, co zminimalizuje problem utraty reputacji. Świetnie w roli „komunikacyjnej deski ratunkowej” sprawdzają się serwisy społecznościowe (Facebook, Twitter…);
- analizować wąskie gardła aplikacji — akcje w udostępnionej usłudze wymagające wykonania wielu operacji dyskowych, pamięciowych lub obliczeniowych powinny być jak najbardziej ograniczane. Należy bardzo dokładnie przeanalizować przypadki użycia czasochłonnych akcji i zabezpieczać je, np. korzystając z CAPTCHA lub autoryzacji połączonej z ograniczaniem ilości wywołań akcji przez użytkownika itp. Ciekawym pomysłem jest również użycie uwierzytelnienia wykorzystującego Javascript, który nie jest interpretowany przez większość narzędzi do ataków DoS;
- przeprowadzać hardening serwerów aplikacji oraz usług — serwery aplikacji oraz usługi takie jak PHP pozwalają na bardzo szczegółową konfigurację zachowania oraz zarządzania zasobami. Podczas zwiększania bezpieczeństwa konfiguracji należy zwrócić uwagę na ograniczanie długości żądań/parametrów HTTP, zmniejszać timeout utrzymywanych połączeń oraz ograniczać maksymalną pulę pamięci oraz czas procesora dostępny dla aplikacji (aby podczas ataku administrator miał możliwość rekonfiguracji maszyny). Serwery aplikacji bardzo często pozwalają na instalację dodatkowych pluginów zwiększających bezpieczeństwo, które również warto doinstalować (mod_security, IIS URL Scan, Apache mod_slowloris itp.).
3. Gotowość na czarny scenariusz
Działania prewencyjne nie opierają się wyłącznie na ścisłej kontroli urządzeń sieciowych oraz aplikacji. Bardzo ważnym elementem odpierania ataków DDoS są działania, które pozwalają przygotować się do ewentualnego zagrożenia.
Istnieje bardzo dużo rad dotyczących zarządzania ryzykiem, jednak w kontekście ataków DDoS szczególną uwagę należy zwrócić na:
- przygotowanie umów z dostawcą internetowym — warto wiedzieć, w jaki sposób można zarządzać dostępnością łącza od strony ISP. Gdy infrastruktura sieciowa wdrożona jest w chmurze, krytyczną sprawą jest upewnienie się, czy sposób rozliczeń za transfer podczas ataku nie zrujnuje nas finansowo — w chmurze atak DDoS nie tylko obciąża usługi, ale może prowadzić też do wyczerpania środków finansowych, co nazywa się czasem atakiem EDDoS (Economical DDoS). Dobrą praktyką jest również posiadanie dodatkowej umowy z innym ISP, który przykładowo podczas ataku udostępni interfejs BGP do rozgłaszania blokowanych adresów (np. dzięki BGB Blackholing – omówione niżej).
- przygotowanie planu reakcji na incydent — gdy sieć zacznie być zalewana pakietami, wtedy każda minuta ma znaczenie, więc trzeba działać szybko i sprawnie. Aby zmniejszyć stres związany z pracą przy sparaliżowanej infrastrukturze, warto zawczasu przemyśleć kroki działań. Nawet proste czynności, takie jak spisanie numerów kontaktowych do osób mogących pomóc w łagodzeniu rozpoczętego ataku, sposób kontaktu z dostawcą internetowym czy chociażby strategia związana z ewentualną współpracą usług firm zewnętrznych (wspomniana już Cloudflare i inne tego typu) będzie nieoceniona w czasie, gdy komunikacja w firmie zostanie znacznie utrudniona.
Podsumowując: odpowiednia konfiguracja urządzeń i sieci, szkolenia administratorów, klarowne umowy z ISP oraz zarządzanie pozwalają znacznie zminimalizować szansę udanego ataku. W dodatku powyższe rady są na tyle uniwersalne i proste, że ich wdrożenie nie powinno zabrać dużo czasu, a dodatkowo złagodzimy skutki nie tylko ataków DDoS, ale również innych, bardziej skomplikowanych.
Warto podkreślić, że w zasadzie najważniejszym elementem prewencyjnym jest ISP, z którym trzeba odpowiednio wcześnie zacząć współpracę dotyczącą reakcji na ewentualny atak DDoS w przyszłości. W praktyce ISP niezbyt chętnie implementują mechanizmy zapobiegające atakom odmowy dostępu, jednak warto budować u swojego dostawcy świadomość zagrożenia. Podczas rozmów trzeba określić skalę problemu i spróbować wspólnie odpowiedzieć na pytanie: „Czy stać nas na obsługę takiego ataku, jeśli odpowiednio wcześnie nie zareagujemy?” (bo z pewnością atak wcześniej czy później nastąpi).
Wykrywanie (detekcja)
Kolejnym etapem walki przeciwko DDoS jest skuteczna detekcja ataków. Chociaż nietrudno zauważyć już sam moment ataku, to trzeba mieć na uwadze, że agresorzy często przed skorzystaniem z „usługi” zalewania celu najpierw wykonują rekonesans, aby dostroić narzędzia oraz zmaksymalizować skuteczność swoich poczynań.
Dzięki wykonaniu kilku kroków możemy nie tylko zniechęcić agresora do ataku, ale również skuteczniej z nim walczyć.
Aby to zrobić, należy:
- wdrożyć dedykowane maszyny z systemami firewall, IDS/IPS, honeypot oraz monitoringu — tego rodzaju węzły w sieci będą stanowić centralny punkt obrony i analizy podczas ataku. Wdrożenie rozwiązań IDS/IPS oraz honeypotów w sieci pozwoli szybko zlokalizować intruza, który próbuje poznać strukturę sieci do strojenia ataku;
- wdrożyć firewalle warstwy aplikacji — WAF (ang. Web Application Firewall) pozwala wykrywać i zapobiegać podstawowym anomaliom w ruchu kierowanym do aplikacji internetowej. Dobrze skonfigurowany WAF nie tylko zidentyfikuje i zablokuje zbyt duży ruch do aplikacji z określonego miejsca, ale również utrudni pracę crackera oraz pozwoli wykryć innego rodzaju zagrożenia, na które wystawione są web aplikacje, np. SQL Injection czy XSS. Oczywiście gdy ruch napłynie z wielu źródeł jednocześnie, wyczerpując całe dostępne łącze, taka ochrona nie zda się na wiele, ale niskim kosztem będzie można odfiltrować ataki „niewolumetryczne” (np. Slowloris);
- wykrywać anomalie w sieci i udostępnionych usługach — pojawienie się żądań z adresami, które nie są przypisane do żadnego urządzenia w sieci, nagły wzrost liczby zarejestrowanych użytkowników w aplikacji internetowej czy częste skanowanie portów interfejsów publicznych to pierwsze oznaki ryzyka ataku na infrastrukturę firmy, m.in. ataku DDoS. Gdy np. czasy odpowiedzi zaczną wynosić kilkanaście sekund lub gdy w sieci pojawi się zauważalnie więcej pakietów z flagą SYN niż ACK, wtedy zagrożenie (D)DoS staje się coraz bardziej realne. Podczas analizy logów bardzo ważne jest, aby nie skupiać się na danych zagregowanych, a znajdywać tzw. „piki” aktywności — czyli zamiast porównywać ilość ruchu w danych dniach, dużo lepiej jest wykrywać gwałtowne zmiany w obciążeniu zasobów w krótkich przedziałach czasu. Najlepiej, gdy nagły wzrost wykorzystania danego elementu infrastruktury spowoduje automatycznie powiadomienie administracji o incydencie.
Narzędziami, które pozwalają skutecznie analizować ruch i wykrywać anomalie w sieci są m.in.:
Wdrożenie takich mechanizmów oraz przeszkolenie personelu analizującego wyniki znacznie zwiększa bezpieczeństwo sieci i pozwala szybko wykryć charakter ataku. Dobrze zarządzane logi są niecenionym źródłem informacji, które uskutecznia metody przeciwdziałania, a czasem nawet pozwala na dokładne zlokalizowanie agresora stojącego za atakiem.
Monitorowanie ruchu oraz jego analiza to bardzo skomplikowany temat, na szczęście w sieci jest bardzo dużo materiałów, dzięki którym można dokładniej poznać to zagadnienie. W samych zasobach Sekuraka można poczytać o monitoringu z wykorzystaniem Zabbixa, Security Onion czy Argusa. Pisaliśmy również o analizie ruchu sieciowego oraz wspomnianym wyżej OSSEC-u. Temat rozwinięty jest również w wielu książkach oraz dokładnie ćwiczony podczas dedykowanych szkoleń.
Wiedza z tych źródeł skutecznie pozwoli zawczasu wykryć wiele niebezpieczeństw zagrażających infrastrukturze sieci.
Przeciwdziałanie (odpowiedź)
Prewencja i detekcja ataków nie zawsze powstrzyma odpowiednio zmotywowanego crackera przed zalewaniem sieci milionami pakietów. Odpowiedź na duże ataki DDoS nigdy nie jest łatwa i może przypominać walkę z wiatrakami. Należy jednak wziąć pod uwagę, że każda sekunda ataku to nie tylko strata dla firmy (ofiary), ale również koszt dla atakującego. Przeciwdziałając atakowi DDoS, w praktyce zwiększamy koszt ponoszony przez crackera, co skutkuje skróceniem czasu ataku.
Przeciwdziałanie należy rozpocząć oczywiście od wykonania wcześniej przygotowanego planu reakcji na incydent.
Oto kilka pomysłów, jak można przeciwdziałać trwającym atakom DDoS:
- zlecenie usługi odparcia ataku firmom trzecim — tak jak wspomniano w jednym z poprzednich paragrafów, outsourcing usług DDoS pozwoli szybko odeprzeć nawet najsilniejsze ataki;
- lokalizacja wąskiego gardła — paraliż podczas ataku często nie jest spowodowany wysyconym łączem po stronie ISP, a zbytnio obciążonymi serwerami lub urządzeniami pośredniczącymi, które mogłyby przyjąć jeszcze sporo ruchu, ale nie są w stanie go obliczeniowo przetworzyć, ponieważ wykonują na pakietach wiele operacji (logi, monitoring, dopasowanie do sygnatur…). Warto zlokalizować wąskie gardło i wyłączyć niektóre opcje „ochrony”, co spowoduje zmniejszenie obciążenia pamięci oraz procesora i łatwiejsze radzenie sobie z problemem (czasem nawet całkowicie go rozwiązując);
- loadbalancing oraz rozproszenie geograficzne — loadbalancing (np. dzięki LVS) pozwoli rozłożyć obciążenie kluczowych usługi na kilka maszyn, podobnie jak skalowanie usług w skali globalnej z wykorzystaniem Global Server Load Balancing (GSLB) lub GEO-IP DNS. Rozłożenie geograficzne ma wielką zaletę: pozwala blokować ruch z krajów, z których nie spodziewamy się ruchu — węzły botnetów zazwyczaj rozlokowane są po całym świecie (niekoniecznie tak jak zwyczajni klienci), dzięki czemu możemy łatwo odciąć dużą część złośliwego ruchu (porównaj: metody działania Cloudflare);
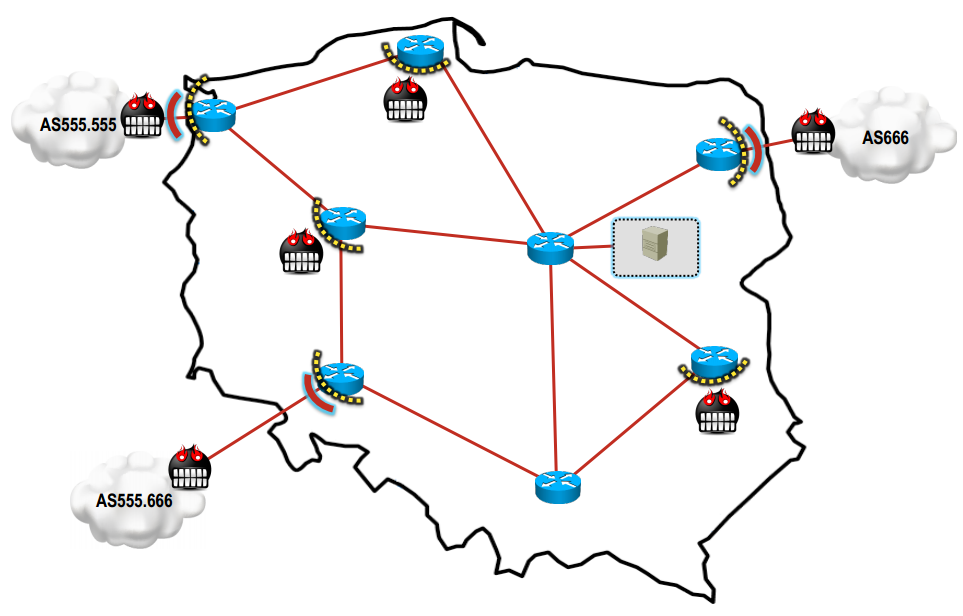
- BGP blackholing — metoda ta w skrócie polega na rozgłaszaniu informacji przez ISP o blokowaniu ruchu od podejrzanych hostów podczas wykrycia ataku. Mając dodatkowe (nieobciążone atakiem) łącze BGP, można rozesłać specyficzny prefiks (podsieć) do strategicznie rozłożonych serwerów klas, który spowoduje zablokowanie (lub spowolnienie transmisji) atakujących hostów znacznie bliżej prawdziwego źródła ataku (pokazano to na rysunku 1.).
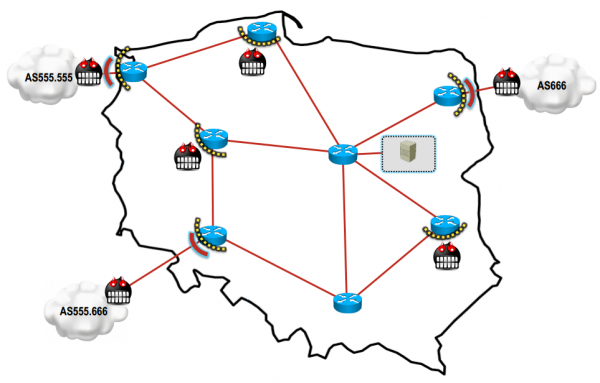
Rysunek 1. BGP Blackholing.(za: BGP Blackholing PL v2.0 re(boot|reload). Bromirski Łukasz. Kraków : 7 edycja konferencji PLNOG, 2011).
Oczywiście pomysłów na przeciwdziałanie jest dużo, jednak trzeba je ściśle dostosować do konkretnego incydentu. Mimo wszystko trzeba mieć świadomość tego, że niektóre ataki mogą być wręcz niemożliwe do zablokowania i trzeba je będzie po prostu przeczekać, przenosząc tymczasowo usługi w inne miejscu lub po prostu maksymalizując działania zespołu PR.
Więcej informacji o temacie BGP oraz blackholingu można przeczytać w świetnych opracowaniach naszego rodaka – Łukasza Bromirskiego, który prowadzi m.in. projekt „Blackholing PL”.
Podsumowanie
Ze względu na dynamiczny rozwój Internetu, smarfonów oraz urządzeń „inteligentnych”, ilość zasobów kontrolowanych przez cybeprzestępców rośnie wykładniczo, przez co ataki Distributed Denial of Service ostatnimi czasy stały się niezwykle niebezpiecznym zagrożeniem.
Obecnie zlecenie ataku DDoS — nawet na dość dużą skalę — wymaga inwestycji zaledwie parudziesięciu dolarów, warto więc poznać ten rodzaj zagrożenia i wprowadzić do swojej sieci konfiguracje zmniejszające skutki incydentów. Dużą pomocą mogą okazać się firmy zewnętrzne specjalizujące się w odpieraniu takich ataków, ale niezależnie od tego, czy zdecydujemy się na ich pomoc czy nie, zawsze należy mieć przygotowany plan działania dotyczący DDoS, ponieważ nie można ignorować tak realnego niebezpieczeństwa.
Materiały uzupełniające
Oto wybrane źródła informacji, które mogą stanowić uzupełnienie tekstu, zarówno w zakresie podstawowym, jak i bardziej zaawansowanym:
Bibliografia
1. Internet Usage Statistics — The Internet Big Picture. World Internet Users and Population Stats. June 2012.
2. The Culture–ist: More Than 2 Billion People Use the Internet, Here’s What They’re Up To (INFOGRAPHIC). 9 May 2013.
3. Prolexic. Prolexic Stops Largest-Ever DNS Reflection DDoS Attack. 30 May 2013.
4. BGP Blackholing PL v2.0 re(boot|reload). Bromirski Łukasz. Kraków : 7 edycja konferencji PLNOG, 2011.
5. Akamai. DNS reflection defense. 18 June 2013.
6. Infosec Institute. DOS Attacks and Free DOS Attacking Tools. 29 October 2013.
7. Prolexic. DoS and DDoS Glossary.
8. McClure Stuart, Scambray Joel i Kurtz George. Vademecum hackingu. Skuteczna obrona sieci przed atakami. Wydanie VII. Gliwice : Helion, 2013.
9. Ochrona przeciwko atakom DDoS dziś i jutro. Czarniecki Łukasz i Jerzak Marcin. Warszawa : Poznańskie Centrum Superkomputerowo Sieciowe, 2013. Konferencja SECURE 2013.
10. How to launch and defend against a DDoS. Graham-Cumming Hohn. Warszawa : CloudFlare, 2013. Konferencja SECURE 2013.
Adrian “Vizzdoom” Michalczyk


Bardzo interesujący finał serii (czy będzie cz. 4?).
Ciekawi mnie tylko pewien scenariusz związany z blokowanie ruchu przez ISP. Uważam, że jedną ze skuteczniejszych metod ochrony jest aby ISP wymieniali się informacją o agresorach ale już blokowanie ruchu może nie być takie łatwe. Wyobraźmy sobie, że jesteśmy w jednej podsieci z napastnikiem. Istnieje ryzyko zablokowania nas a przez to mamy do czynienia z DoS-em (nasz ruch jest wycięty) ale teraz napastnikiem jest/są ISP. Może się mylę ale nie podejrzewam aby ISP bawili się w blokowanie ruchu z pojedynczych adresów IP (raczej idzie cała podsieć). Wystarczy aby jakiś serwer w data center u tego samego operatora “zaczął rozrabiać”.
Bardzo przydatne informacje :) A tak w ogole, to od kilku raptem miesiecy czytam sekuraka i przyznam, ze malo jest tak wartosciowych blogow. Nie ma lania wody – tresciwie i na temat. Dzieki.
Moze zaproponuje kilka tematow, ktorymi autorzy moga sie zainteresowac (i tym samym czytelnicy):
1. Konfiguracja od A-Z serwera Apache oraz Bazy MySQL lub Miranda DB.
2. Metody filtrowania ruchu: narzedzia oraz praktyczne ich zastosowanie.
Pozdrawiam
Zgadzam się z Tobą w 100% , jak również popieram wymienione tematy , z chęcią “zanurzę się” w lekturę po raz kolejny ucząc się praktycznych rzeczy :) Sekurak wraz z z3s i BS to najlepsze źródła wiedzy w PL .
Zachęcam generalnie do wzięcia udziału w: http://sekurak.pl/konkurs-na-najlepszy-tekst-o-bezpieczenstwie/ Konkurs cały czas trwa, i niezłe nagrody czekają :]
“A tak w ogole, to od kilku raptem miesiecy czytam sekuraka i przyznam, ze malo jest tak wartosciowych blogow. Nie ma lania wody – tresciwie i na temat. Dzieki.”
–> no raczej lania wody mało -> to generalnie zmniejsza nam liczbę czytelników :PPP Ale zwiększa ich jakość :-)
Może jakiś artykuł związany z GSM? np. ciekaw jestem jak wygląda sprawa odczytywania kodów PIN,PIN2,PUK,PUK2 przy pomocy czytnika kart SIM(w powszechnej opinii – nie ma takiej możliwości).
Drugi pomysł to teoretyczne opisanie sprawy simlocków(z podziałem na typy(od starszych po nowsze)),kwestia w której kości były umieszczane a w której są obecnie itp.