Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

Wysokodostępna i wydajna architektura dla LAMP – tutorial (cz. 2.)
W tej części poświęconej budowaniu i konfigurowaniu wysokodostępnej i wydajnej architektury dla LAMP zaprezentuję dwa testowane przeze mnie elementy:
- Keepalived – demon monitorujący klastry LVS (Linux Virtual Server),
- Haproxy – reverse proxy TCP/HTTP dla środowisk wysokiej dostępności.
Zapraszam do lektury innych części cyklu (część 1.).
Keepalived – demon monitorujący klastry LVS(Linux Virtual Server)
W celu zapewnienia redundancji serwerów typu loadbalancer w omawianej architekturze postanowiłem skorzystać z narzędzia o nazwie keepalived, dostępnego w repozytorium dystrybucji, na której oparłem projekt, czyli Debian GNU/Linux. Dzięki dostępności paczki w repozytorium instalacja jest prosta i łatwa, odbywa się przy pomocy narzędzi do zarządzania pakietami, które są dostępne w systemie oraz zwalnia nas z kompilacji programu ze źródeł.
1. Co to jest keepalived
Keepalived jest to demon monitorujący dostępność maszyn pracujących w parze i w przypadku zatrzymania/awarii jednej z nich automatycznie przełącza ruch na zapasową. Maszyny będące pod kontrolą keepalived pracują w architekturze master – standby i współdzielą wirtualny adres IP. Keepalived implementuje protokół VRRP v2 (Virtual Router Redundancy Protocol). Po więcej informacji odsyłam do dokumentacji: RFC-2238.
2. Dlaczego warto stosować keepalived
Mój wybór padł na keepalived, ponieważ – jak już wcześniej napisałem – pozwala mi na monitorowanie dwóch loadbalancerów współdzielących jeden adres IP, automatyczne wyłączanie serwera pełniącego rolę master i przełączanie ruchu na serwer zapasowy działający w trybie standby. Dzięki takiemu rozwiązaniu jestem pewien, że cała architektura serwująca strony WWW będzie dostępna nawet wtedy, gdy jeden z balancerów przestanie odpowiadać z bliżej nie określonego powodu. Keepalived zadba o to, żeby automatycznie przełączyć cały ruch na serwer standby, ma również możliwości wysłania maila do administratora, aby powiadomić go o incydencie, z czego na pewno warto skorzystać.
3. Przykładowa konfiguracja na potrzeby projektu
W projekcie zainstalowałem demona keepalived na serwerach, które pełnią rolę loadbalancerów, ponieważ najbardziej zależało mi na zapewnieniu wysokiej dostępności tych narzędzi, pozostałe bloki używają innych rozwiązań lub w ogóle nie używają tego rodzaju oprogramowania. Serwery, o których wspomniałem, mogą być z powodzeniem zainstalowane jako maszyny wirtualne, ponieważ obciążenie zasobów sprzętowych przez keepalived i haproxy jest niewielkie.
Przy obciążeniu 100req/s zauważyłem, że haproxy zużywa około 10MB pamięci RAM, zużycie procesora jest znikome, a obciążenie generowane przez keepalived jest praktycznie nie zauważalne, dlatego uważam, że te serwery są idealnymi kandydatami do zwirtualizowania. Serwery z zainstalowanym haproxy posiadają swoje własne adresy IP (10.10.10.98/99) oraz adres wirtualny 10.10.10.100. Na serwerach konfigurujemy tylko adresy IP 10.10.10.98 oraz 10.10.10.99, adresem wirtualnym zarządza keepalived. Schemat połączenia maszyn:
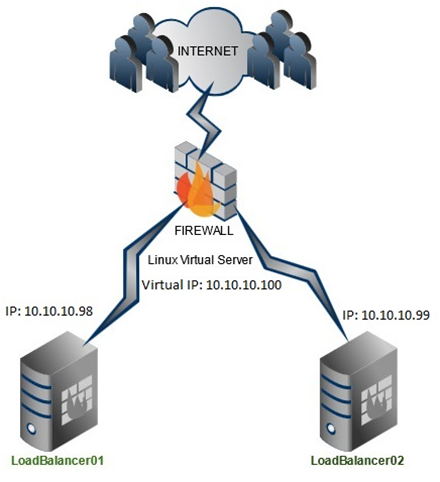
Jak widać na powyższym schemacie, ruch przychodzący od użytkownika przechodzi przez firewall (np.: port forwarding) i trafia na wirtualny adres IP 10.10.10.100, demon keepalived na podstawie informacji o dostępności loadbalancerów kieruje ruch na mastera, jeżeli ten działa, lub na serwer standby, jeżeli master nie odpowiada.
Po instalacji pakietu keepalived na dwóch serwerach loadbalancer, edytujemy plik /etc/keepalived/keepalived.conf lub go tworzymy, jeżeli takiego pliku nie ma. Pliki na serwerze master i standby (backup) będą wyglądały troszeczkę inaczej, ponieważ definiuje się w nich wagę oraz nazwę serwera.
Przykładowe pliki dla serwera master i standby:
global_defs {
notification_email {
admin@example.com
}
notification_email_from admin@example.com
smtp_server 10.10.10.50
smtp_connect_timeout 30
}
vrrp_script chk_haproxy { # wymaga wersji keepalived-1.1.13
script "killall -0 haproxy"
interval 2 # sprawdzaj co 2 sekundy
weight 2 # dodaje 2 punkty priorytetu jeżeli status jest OK
}
vrrp_instance VI_1 {
interface eth0
state MASTER # lub "BACKUP" na serwerze standby(backup)
priority 101 # 101 ustawiamy na masterze, ustawiamy 100 na serwerze standby
virtual_router_id 51
smtp_alert # Aktywujemy alerty SMTP
authentication {
auth_type AH
auth_pass supersecret
}
virtual_ipaddress {
10.10.10.100
}
track_script {
chk_haproxy
}
}
Pragnę zaznaczyć, że jest to bardzo prosta, ale działająca konfiguracja. Zachęcam do jej rozbudowy oraz dostosowania do indywidualnych wymagań. Polecam również dokumentację na stronie projektu.
Rozwiązania, które tutaj prezentuję, nie przetestowałem jeszcze w środowisku produkcyjnym, a konfiguracja, którą zastosowałem, jest raczej konfiguracją minimalną, mającą na celu uruchomienie narzędzia i wstępne rozpoznanie/przetestowanie go. Choć nie poznałem jeszcze w całości jego możliwości, jest ono bardzo obiecujące i zachęcam do używania go w celu zapewnienia wysokiej dostępności dla serwerów typu loadbalancer opartych na HAProxy.
Haproxy – reverse proxy TCP/HTTP dla środowisk wysokiej dostępności
Zadbaliśmy już o część naszej architektury, czyli o firewalla opartego na oprogramowaniu shorewall oraz wysoką dostępność serwerów pracujących za nim przy pomocy keepalived. Przyszła kolej na wybranie oprogramowania, które będzie rozdzielało ruch na serwery aplikacyjne, czyli wspomnianych wcześniej loadbalancerów.
Postanowiłem tą rolę powierzyć pakietowi o nazwie HAProxy. Dlaczego HAProxy? – Bo jest darmowe, dostępne w repozytorium linuxa, łatwe w konfiguracji.
1. Co to jest haproxy?
Rozpoznając HAProxy, warto skorzystać z opisu znajdującego się na stronie projektu. HAProxy to OpenSource, a także bardzo szybkie i niezawodne oprogramowanie oferujące wysoką dostępność, modelowanie ruchu oraz serwer proxy dla aplikacji wykorzystujących protokół TCP i HTTP (w wersji 1.5.X również HTTPS). HAProxy zostało zaprojektowane z myślą o stronach WWW, które są mocno obciążone i wymagana jest ich wysoka dostępność. Obsługa dziesiątek tysięcy połączeń jest dziś możliwa dzięki wydajnym serwerom. Sposób, w jaki pracuje HAProxy, umożliwia bardzo łatwe zaimplementowanie go w już działającej architekturze.
2. Dlaczego warto stosować haproxy?
Jak już wcześniej wspomniałem, HAProxy przekonało mnie ze względu na:
- rodzaj licencji (GPL v2),
- łatwość instalacji i konfiguracji (narzędzia systemowe do zarządzania pakietami) oraz
- małe obciążenie systemu operacyjnego.
Jak podają autorzy projektu, możliwa jest obsługa około 60 000 jednoczesnych połączeń przy obciążeniu pamięci RAM na poziomie 1GB, co jest świetnym wynikiem.
Myślę, że serwery na których pracuje HAProxy, są idealnymi kandydatami do wirtualizacji, co jest kolejnym atutem. HAProxy świetnie nadaje się do przekazywania ruchu zarówno HTTP, jak i TCP.
Kolejną zaletą HAProxy jest brak ingerencji, instalacji modułów itp. po stronie serwerów aplikacyjnych, jedyną rzeczą, o którą musimy zadbać, jest umieszczenie pliku, na podstawie którego HAProxy wykona testy na poprawność działania serwera aplikacyjnego. Takim plikiem jest pusty plik tekstowy, który musi zostać zaserwowany przez serwer aplikacyjny, w przeciwnym wypadku serwer oznaczany jest jako nie aktywny i HAProxy automatycznie odłącza go od architektury. W przypadku gdy serwer zaserwuje poprawnie plik testowy, jest on uznawany za aktywny i ponownie trafia do niego ruch od użytkowników.
HAProxy umożliwia nakładanie ograniczeń odnośnie liczby połączeń, jakie może obsłużyć konkretna maszyna, co daje nam możliwość odpowiedniego dociążenia każdego noda, dzięki czemu możemy podłączać do naszej architektury serwery o różnej konfiguracji sprzętowej.
3. Przykładowa konfiguracja na potrzeby projektu
Jak już w pierwszej części zauważyliście HAProxy zainstalowane jest na dwóch serwerach razem z keepalived. Zduplikowanie rozwiązania oraz zastosowanie keepalived sprawia, że serwery typu loadbalancer dostępne są pod jednym adresem IP, a w przypadku awarii serwera typu master, jego zadania przejmuje serwer pełniący rolę backupu i pracujący w trybie standby. Schemat połączenia serwerów loadbalancer z firewallem oraz serwerami aplikacyjnymi wygląda następująco:
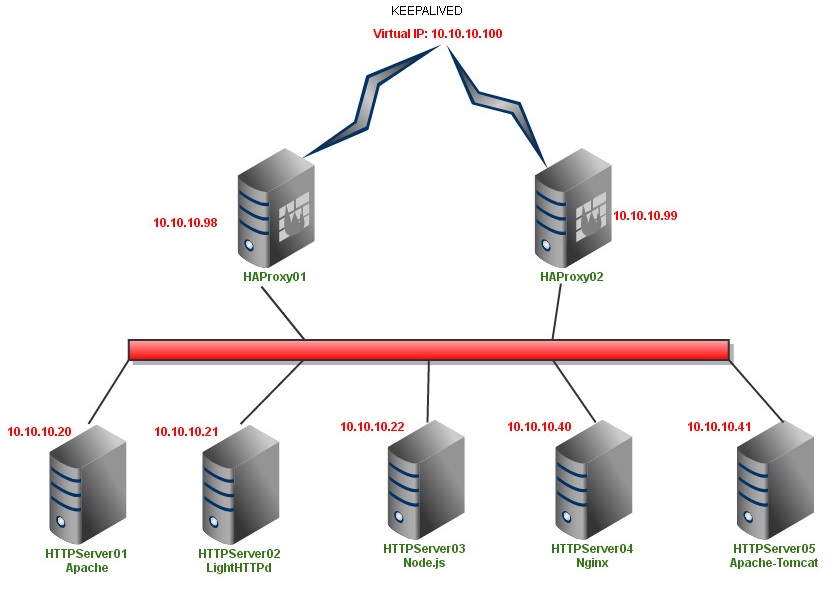
Jak widzimy, na serwerze HAProxy może być wykorzystany praktycznie z każdym serwerem HTTP, oczywiście w swoim projekcie korzystam tylko z serwerów Apache oraz Nginx, ponieważ docelowo na potrzeby całego ćwiczenia postanowiłem wypróbować tę architekturę, aby serwować WordPressa oraz PHPMyAdmina.
Wypróbowałem dwa rodzaje konfiguracji HAProxy:
- serwery aplikacyjne oraz serwery cdn (Content Delivery Network – udostępnianie zawartości o wysokiej dostępności i wydajności końcowym użytkownikom – głównie pliki multimedialne),
- podział na rodzaje serwowanych plików (skrypty oraz pliki statyczne).
Wybór pierwszy, czyli podział plików ze względu na ich rodzaj i serwowanie ich z różnych domen, jest dość prosty w konfiguracji HAProxy, ale wymaga obsługi serwerów CDN przez aplikację. Aby taka konfiguracja zadziałała, aplikacja powinna być w stanie przepisać wszystkie url do plików statycznych (jpg, css, js, png itd.) w serwowanej stronie na domenę cdn.domena.pl, a zapytania o skrypty powinny być skierowane do domeny www.domena.pl. Taki podział jest często stosowany w dużych i znanych projektach (Facebook, Nasza Klasa, WP).
Co jednak zrobić w przypadku starej lub dedykowanej aplikacji, która nie wspiera serwerów CDN, a napisanie dla niej pluginu obsługującego taką architekturę jest z jakiegoś powodu niemożliwe?
Tutaj z pomocą przychodzą listy ACL obsługiwane przez HAProxy. Dzięki nim możemy definiować obsługę różnych plików przez różne dedykowane do tego serwery. Możemy również podzielić ruch ze względu na rodzaj obsługiwanej domeny. Możliwości konfiguracji list ACL w HAProxy jest bardzo dużo, odsyłam do dokumentacji projektu w celu zgłębienia wiedzy na ich temat.
Ponieważ istniało ryzyko braku obsługi serwerów CDN, postanowiłem stworzyć konfigurację HAProxy z obsługą ACL i tak właśnie powstała alternatywna do CDN konfiguracja. Celem tych poszukiwań było rozpoznawanie za pomocą ACL dostępnych w HAProxy rodzajów plików i kierowanie ruchu na dedykowany/e do ich obsługi serwery, czyli odpowiednio: zapytania o skrypty PHP trafiają do Apache, zapytania o pozostałe pliki trafiają do Nginxa. Wszystko wygląda bardzo podobnie jak w przypadku serwerów CDN z wyjątkiem tego, że wszystkie pliki serwowane są z jednej domeny, a różnice widać tylko w nagłówkach zwracanych przez serwer. W nagłówkach zwracanych przy zapytaniach o skrypty widoczne jest: „Server: Apache”, natomiast przy plikach statycznych: „Server: Nginx”. Dzięki takiemu trikowi nie musimy dodawać obsługi serwerów CDN do naszej aplikacji i to jest cel, który chciałem osiągnąć.
Inną rzeczą, którą chciałem osiągnąć, było przypisanie użytkownika do jednego serwera aplikacyjnego w celu zachowania sesji. Udało mim się to dzięki ciasteczkom.
HAProxy tworzy ciasteczko, w którym zapisuje ID/nazwę serwera, na który kierowany jest użytkownik przy pierwszym wejściu na stronę WWW. Tak więc przy kolejnych zapytaniach użytkownik zostaje przekierowany zawsze na ten sam serwer. Postanowiłem załączyć pliki konfiguracyjne A (obsługa CDN) i B (rozpoznawanie rodzaju plików) dla HAProxy, które opisałem powyżej. Więcej o możliwościach konfiguracji HAProxy można poczytać w dokumentacji.
4. Monitorowanie i statystyki ruchu
HAProxy zawiera również panel dostępny przez WWW, w którym można monitorować status serwerów, statystyki dotyczące ruch oraz wiele innych parametrów (przykładowa strona). Aby skonfigurować stronę monitoringu, należy dodać w pliku konfiguracyjnym w sekcji backend następujące wpisy (oczywiście nie polecam stosowania pary loginu i hasła root:toor stosowanej w różnych wersjach live linuxa):
- stats enable
- stats hide-version
- stats refresh 5s
- stats auth root:toor
Zachęcam do przetestowania HAProxy, gdyż uważam, że jest to bardzo dobre narzędzie z wieloma możliwościami konfiguracyjnymi. Okazuje się wydajne i uniwersalne do zarządzania ruchem serwerów WWW.
Oczywiście załączone pliki konfiguracyjne nie wyczerpują wszystkich jego możliwości i są raczej wstępem do eksperymentowania i bardziej zaawansowanych konfiguracji.
– OiSiS [oisisk<sekurak>gmail.com]

1) Przy pomocy jakiego programu został zrobione w/w rysunki ?
2) Czemu zastosowałeś dodatkowo HAProxy? Można było w keepalived uwzględnić realne serwery (+ ich monitowanie przez HTTP_GET) -czy było to związane tylko ze statystykami z połączeń w HAProxyczy że jest to rozwiązanie dedykowane dla serwerów WWW?
OiSiS podrzucam temat na kolejny tekst: tutorial jak w praktyce ukryć serwer/stronę internetową na podstawie doświadczeń The Pirate Bay ;)
Jak duzy ruch jest to w stanie obsluzyc produkcyjnie? Od ktorego momentu bardziej oplaca sie przesiadka np. na F5? Ma ktos takie informacje? Sprawdzal ktos?
@sylwek: Dość ogólne pytanie. Dla przykładu powiem, że obsługiwałem ruch rzędu 300Mbitów/s i jedynym limitem dla mnie była wartość softirq spowodowana przez kartę sieciową. Gdybym miał karty sieciowe mające MSI-X nie byłoby problemu z softirq. To było jakoś 5k req/s.
@zxc
1. https://www.gliffy.com
2. HAProxy jest dedykowane do tego, posiada fajne konfiguracje pozwalające na rozbicie ruchu pod względem domen, rodzaju plików, działa już podobno z HTTPS itp, itd.
@józek
Może kiedyś, na razie brak czasu na to i potrzeb. Powiedzmy tak siedzi mi coś innego w głowie, konkretniej to BTC. Dlaczego? Zobaczcie kurs. Siedzę przy kopalniach BTC.
@Sylwek
Produkcyjnie jeszcze nie testowałem ale mam nadzieję że 60k-100k obsłuży :).
@OiSiS
kopalnia BTC? Już się nie opłaca :) Jeszcze 8 miesięcy temu tak, teraz już nie. Algorytm wszedł na taki poziom, że bez odpowiedniej grupy komputerów nie ma sensu tego wydobywać, no chyba, że ma się kasę na odpowiedni sprzęt, a jak dołączysz do obecnych zbiorowych kopalni, to zarobisz dużo za mało w stosunku do poświęconego czasu. Ja wiem, że teraz jest hype bo kosztuje 1000$ za sztukę, ale ktoś tutaj pamięta czasy, gdy 1BTC chodził po niecałe 90gr i też już swoje na tym zarobił ;) Jeżeli mam być szczery, to BTC osiągnie swój punkt krytyczny (to będzie jakieś 2500$) i na tym się skończy. Jeżeli chcesz dużo zarobić, to podobny los jak BTC będzie czekał Litecoiny i tutaj złożoność algorytmu dalej jest na bardzo niskim poziomie, średniej klasy komputer pozwala wydobyć pełnego chaina raz na ok. 2 tygodnie. Też się już w to konkretnie bawiłem, jeszcze w 2010 roku. Zarobiłem 15 krotność zainwestowanych w to pieniędzy i żałuje, że sprzedałem wtedy te BTC (ponad 500 sztuk xD), byłbym 500 000$ do przodu i nie potrzebował bym jak na gwałt znaleźć współpracownika ;P
A z doświadczenia wiem, że ktoś kto będzie potrafił stworzyć architekturę serwerową taką jak TPB (ludzie potrzebują TORa, żeby tworzyć hidden services, TPB nie potrzebuję – ukrył serwer w clearnecie i nikt nawet NSA nie wie gdzie to jest :D), może zarobić na tym lepsze pieniądze ;)
BTC? o ile sie orientuje to kopalnie sa juz malo oplacalne. Ja mam dostep do pomieszczenia i prad bez limitow.. po kalkulacjach wyszlo mi ze oplacalnosc w terminie 1-2lat praktycznie zerowa o ile nie ujemna. Wez pod uwage ze trudnosc stale rosnie i nie mas zpewnosci jaka bedzie za np 1rok, wiec jesli z kalkulacji wychodzi Ci zwrot po ponad 1roku to jesli np za rok wprowadza wreszcie uklady ARM zaprojektowane pod kopanie to trudnosc tak poleci do gory ze obecne karty graficzne do smieci mozesz wywalic. Jesli chodzi o ‘wykupowanie’ udzialow w kopalni to moje zdanie jest ze to dla naiwniakow
Brakuje mi tu poruszenia ważnego tematu, związanego z HA, jakim jest współdzielona przestrzeń.
Paweł: odpowiadając trochę za autora. To nie koniec cyklu (będą jeszcze co najmniej 2 części, w czym jedna już jest gotowa do publikacji :).
Chodzi Ci o przestrzeń dyskową?
@józek @ktos
Jak już kopać to maszynami od tego zbudowanymi które wyciągają minimum 10G#/s. Mnie bardziej interesuje postawienie własnej kopalni do której ludzie będą podłączali się minerami i u mnie kopali a ja będę zgarniał mały procent od transakcji lub wykopanych bitcointów. Kończmy temat BTC bo to nie o tym wątek. Może ktoś napisze arta jak przygotować kopalnie :), ja nie mam czasu.
Odnośnie ukrywania sewerów TPB, ma ktoś jakieś linki do informacji na ten temat?
Tak, chodiło mi o przestrzeń na dane, która będzie współdzielona (czyli FC, iSCSI lub rozwiązania programowe, jak DRBD).
@OiSiS
http://torrentfreak.com/pirate-bay-moves-to-the-cloud-becomes-raid-proof-121017/
http://blog.foreignpolicy.com/posts/2013/03/04/did_the_pirate_bay_move_to_north_korea_or_are_they_messing_with_us
PS.
Zrobienie własnej kopalni, to walka z ogromną konkurencją. Obecnie największa w Polsce gromadzi coś około 20 000 użytkowników, a mamy ich kilkanaście ;)
@Paweł, używam DRBD pod RAID 1 od 3 lat w produkcji i nie doznałem większych problemów prócz tego, że jak się “rozjedzie” z jakiegoś powodu to później trzeba klepać ręcznie polecenia by zsynchronizować macierz (niby jest pewna automatyzacja ale ja wolę być świadomy tego co robię).
O wiele więcej przygód mam z GFS2 (używam pod Debianem) bo od czasu do czasu są problemy z blokowaniem plików a przez to blokuje się cała macierz. No i kończy się restartem obu węzłów.
Na początek do niezbyt intensywnych zastosowań mogę polecić DRBD. Jeżeli w serwerach są już dyski to można je pożytecznie wykorzystać. Pod wysoki ruch i bardziej restrykcyjne HA lepiej jednak użyć SAN.
Witam świetny artykuł czekam jeszcze na podpięcie do tego bazy MySQL(bez struktury płaskiej)… Pozwodzenia
A jak przy tej konfiguracji pliku keepalived.conf serwery testują siebie nawzajem? W pliku nie ma przecież adresów IP serwerów.
@Marcin
vrrpd wysyła zapytania na broadcast swojej sieci