Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej

Każdemu administratorowi serwerów stron WWW życzę, aby kiedyś Apache, MySQL i PHP postawione na jednej maszynie mimo przeprowadzanych optymalizacji usług przestały się wyrabiać. I nie są to życzenia złośliwe, ponieważ, jeżeli się spełnią, będzie to oznaczało, że strona, którą administruje, ma bardzo dużą liczbę odwiedzin. Biznes w firmie będzie zadowolony, a administrator będzie miał przed sobą nowe wyzwania związane z architekturą odpowiadającą na nową rzeczywistość.
Pierwsza myśl, która zapewne przyjdzie mu do głowy, to rozdzielenie serwerów aplikacyjnych od bazodanowych, wymiana mod_php na mod_fastcgi, wymiana serwera Apache na coś szybszego… Gdy i to zacznie zawodzić, trzeba będzie sobie zadać pytanie, jak rozwiązać i ten problem. Jak przygotować się na kolejne zwiększenie ruchu w przyszłości.
Ostatnio poproszono mnie o rozpoznanie tego tematu i zaproponowanie jakiegoś rozwiązania.
Głównymi założeniami projektu były:
Ponieważ technologia wykonania serwisu nie jest jeszcze bliżej znana (jest to przygotowanie do start-upu), poza kilkoma przyjętymi założeniami (wymienionymi powyżej), poszukiwana architektura powinna dawać możliwość podłączania serwerów z różnymi rodzajami aplikacji napisanych w różnych technologiach. Kolejnym założeniem była możliwość zmieniania dociążenia na poszczególnych serwerach. Załóżmy, że aplikacje są mniej lub bardziej “sezonowe”, a godziny/dni/miesiące maksymalnych odwiedzin per aplikacja nie nakładają się na siebie – idealnym rozwiązaniem byłoby dociążenie “śpiących” serwerów, a nie dokładanie nowego sprzętu, który przez jakiś czas zużywa tylko prąd, a wykorzystanie CPU i RAM przez niego oscyluje w okolicach zera.
Po zapoznaniu się z kilkoma artykułami na temat budowy środowisk HA (High Availability – wysoka dostępność), HP (Hight Preformance – wysoka wydajność) i S (Scalable – skalowalność), postanowiłem spróbować swoich sił w tej dziedzinie. Rozwiązanie, które chcę zaprezentować, jest w fazie PoC (Proof of Concept) i testuję je na swoim domowym środowisku. Wykorzystałem w nim następujące oprogramowanie i sprzęt:
Całość architektury postanowiłem podzielić na pięć warstw:
Dodatkową warstwą, która warto wprowadzić, jest cache zarówno aplikacji, jak i zapytań do bazy danych. Niestety nie zostało to uwzględnione na tym etapie projektu i zostanie dodane później, myślę tu o wykorzystaniu takich narzędzi jak: Solr, Sphinx, Varnish, Memcached.
1. Dlaczego warto wdrożyć takie rozwiązanie
Jeżeli zastanawiacie się, dlaczego warto wdrożyć taką architekturę u siebie, odpowiadam oto jej zalety. Według mnie zyskujemy:
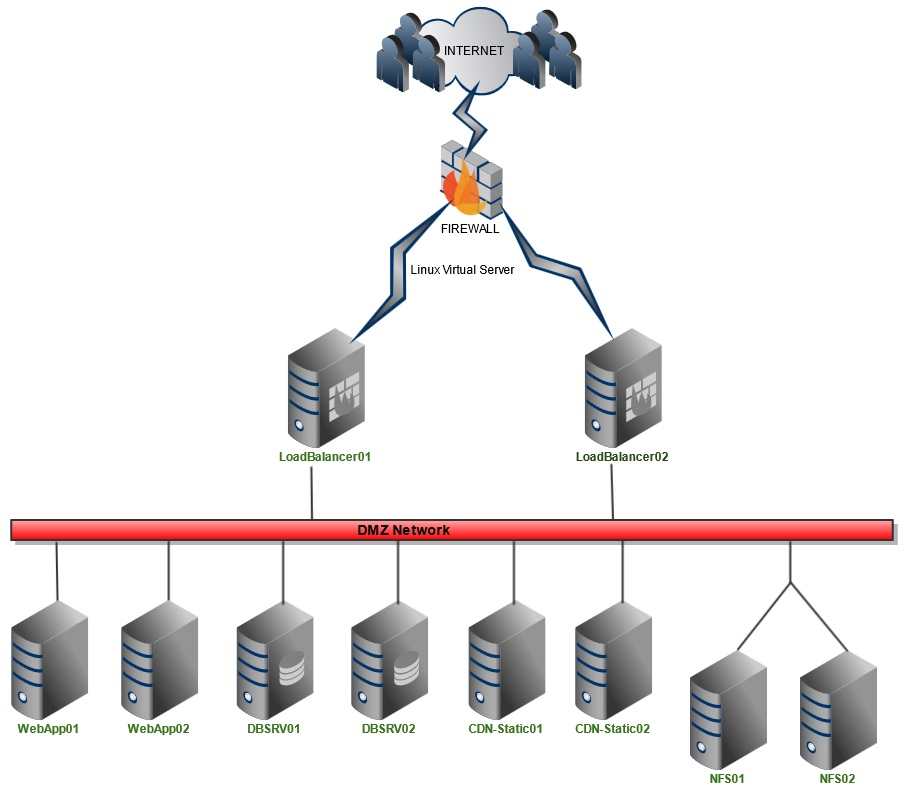
2. Schemat architektury
Poniższy schemat przedstawia połączenie serwerów, rozmieszczenie ich w sieci, np. DMZ, oraz role, jakie pełnią pojedyncze bloki w całym rozwiązaniu. Na rysunku widać, że każdy rodzaj serwera występuje podwójnie za wyjątkiem firewalla. Nie oznacza to, że nie można dodać dowolnej liczby serwerów do każdego z bloków. Opisywane rozwiązanie będzie działało do momentu, gdy z każdego bloku pozostanie co najmniej jedna maszyna.
Cały projekt opiera się na następującym oprogramowaniu:
Oczywiście wybrane przeze mnie oprogramowanie nie jest jednie słusznym rozwiązaniem, można jako serwer aplikacyjny wykorzystać dowolny serwer WWW, np.: IIS, LightHTTPd itp. Ciekawą rzeczą jest to, że możemy również mieszać te serwery, a nasze proxy (HAProxy) i tak sobie z takim środowiskiem poradzi. Kolejną interesującą rzeczą jest to, że całe środowisko może obsługiwać aplikacje WWW napisane w różnych technologiach, a odpowiednie ustawienie ACL przekaże ruch w odpowiednie miejsce, ale o tym w kolejnej części artykułu.
Oprogramowanie ESXi nie posiada możliwości konfiguracji i zarządzania wewnętrzną siecią LAN, a ponieważ zależało mi na zrobieniu czegoś w rodzaju blackbox, zmuszony zostałem do zainstalowania systemu, który będzie pełnił rolę firewalla i routera. Postanowiłem zrobić to na dystrybucji Debian GNU/Linux oraz przy pomocy pakietu shorewall.
Shorewall jest to narzędzie, które pozwala w prosty, przejrzysty i łatwy do utrzymania sposób zarządzać zaporą sieciową opartą na wbudowanym w jądro systemu Linuksie Netfilter.
Wybrałem shorewalla, ponieważ przypominają mi się czasy sprzed kilkunastu lat, gdy konfigurowałem swój pierwszy router/firewall oparty na dystrybucji Slackware. Potrzebowałem wtedy prostego firewalla z opcją NAT, niestety nawet tak prosty firewall wymagał napisania skryptu zawierającego kilkadziesiąt lub nawet kilkaset linii kodu. Oczywiście nie mam nic przeciwko takiemu rozwiązaniu, ale pomyślcie sobie, jak będzie wyglądał taki skrypt w przypadku posiadania dużej liczby komputerów/serwerów w sieci, dodatkowo strefy DMZ, przekierowania portów itp. Skrypt bardzo szybko może urosnąć do kilkuset linii kodu… I tutaj zaczynają się kłopoty. Nie zawsze chce nam się skomentować wszystkie części kodu, nie zawsze będziemy pamiętali, co mieliśmy na myśli, pisząc jakąś funkcję, a w najlepszym wypadku wracając po dłuższym czasie do pracy nad skryptem, musimy go „rozgryźć” od początku.
I tu świetnie sprawdza się taki pakiet jak shorewall. Jest to zestaw skryptów z plikami konfiguracyjnymi, który w łatwy sposób pozwala na konfigurację nawet najbardziej skomplikowanej zapory sieciowej.
Shorewall nie jest demonem działającym w tle, jest zestawem skryptów, które odczytują pliki konfiguracyjne, tłumaczą je na reguły iptables, aktywują w systemie, a następnie kończą swoją pracę. Shorewall posiada swój skrypt w katalogu init.d i może być ładowany podczas startu systemu, dodatkowo posiada funkcję „check”, która sprawdza integralność plików konfiguracyjnych. Polecam uruchomienie shorewalla z tą opcją przed restartem/uruchomieniem firewalla. Pakiet ten świetnie nadaje się do budowy zapory zarówno w małych i prostych sieciach, jak i tych dużych bardziej złożonych.
W swoim projekcie nie potrzebuję skomplikowanej konfiguracji zapory sieciowej. Koncentruję się tylko na strefie DMZ, czyli potrzebny mi jest prosty NAT i przekierowanie portów. Dzięki pakietowi shorewall konfiguracja jest bardzo szybka i prosta.
Po instalacji pakietu shorewall (dystrybucja Debian GNU/Linux) otrzymujemy skrypty oraz katalog z plikami konfiguracyjnymi w lokalizacji: /etc/shorewall. Postanowiłem załączyć konfigurację routera jako archiwum tar.gz. Głównym plikiem, na którym powinniśmy się skoncentrować, jest /etc/shorewall/rules – to tutaj konfigurujemy zasady działania naszej zapory. Oczywiście nie zalecam używania takiej konfiguracji jako zapory na serwerze produkcyjnym podłączonym do Internetu, konfiguracja pozwala na dostęp z każdej „strony” do SSH, HTTP, HTTPS. Aby włączyć automatyczne ładowania zdefiniowanych przez nas zasad iptables przy starcie systemu należy jeszcze zmienić wartość parametru: startup z „0” na „1” w pliku: /etc/default/shorewall. Po każdej edycji plików shorewalla proponuję uruchomienie polecenia: shorewall check z konsoli w celu weryfikacji integralności plików konfiguracyjnych.
Jeżeli ktoś nie używał pakietu shorewall, a zmuszony jest do konfiguracji iptables, polecam wypróbowanie tego pakietu. Jak już wcześniej wspomniałem, jest bardzo prosty w zarządzaniu, nie wymaga pisania długich i skomplikowanych reguł dla iptables. Utrzymywanie konfiguracji, dodawanie nowych reguł, dodawanie nowych stref sieci itd. jest bardzo proste i można to wykonać naprawdę szybko. Chociaż nie posiada ani „ładnego” interfejsu WWW, ani nakładki w postaci GUI, jest naprawdę bardzo prosty do opanowania, a po krótkim czasie wdrożenia praca z nim to prawdziwa przyjemność.
Odsyłam oczywiście do strony internetowej projektu, która znajduje się tutaj. Zaprezentowano tam bardziej zaawansowane możliwości tego pakietu. Są naprawdę imponujące.
– OiSiS [oisisk<sekurak>gmail.com]
W następnych częściach sprawozdania z tego projektu opiszę:

@OiSiS
Wow. Respect :)
Nasuwa mi się takie pytanie: czy Twoja architektura będzie przewidywać, że poza typowymi serwerami WWW pojawi się np. serwer aplikacji Java (Apache Tomcat, JBoss czy inny) bądź Node.js?
Jak wtedy planujesz to rozwiązać? Czy poprzez duplikowanie architektur na poziomie każdego serwera (czyli na każdej maszynie zestaw np. Apache WWW + Apache Tomcat + Node.js) czy też osobne maszyny na każdy serwer i ruch odpowiednio kierowany na poziomie loadbalancerów?
Jak zarządasz ciasteczkami? Dany user trafi zawsze na ten sam frontend? Co w przypadku przeskoku na inny (failover, itp.) ?
Firewall u Ciebie jest SPOF, wiec go też możesz sklastrować na poziomie samej aplikacji. Są do tego rozwiązania Open Source.
@bl4de
Z tego co wiem to serwery aplikacyjne dla javy mają swoje mechanizmy klastrowania i tutaj nie jestem pewny czy to by zadziałało ale są szanse. Node.js nie znam ale podejrzewam że też powinno działać. Co do następnego pytania: to będzie w kolejnym artykule. Nie chcę teraz za bardzo tego zdradzać.
@J
O ciasteczkach i sesjach będzie w następnej części artykułu, proszę o cierpliwość. Firewall jest bardziej jako przymus żeby dało się to skonfigurować za pomocą ESXi i dlatego go opisałem, ja akurat nie używam shorewalla jako głównego firewalla. Czy bym chciał klastrować firewalla? Hmm nie wiem są fajne pudełka które takie coś obsłużą, do tego trzeba mieć jeszcze 2 rury do neta, zarządzanie tym itp.
Fajne ćwiczenie, ale umieszczanie wszystkich elementów (serwery aplikacji, bazy danych itd.) w jednym segmencie sieci to bardzo słaby pomysł.
Poza tym w takiej architekturze nadal będziesz miał pojedyncze punkty awarii (firewall, ISP).
to moze jakies how-to poprosze?
@B
Zadaniem ćwiczenia nie jest budowa sieci, rozmieszczenie bloków itp, tu chodzi tylko i wyłącznie o architekturę rozwiązania do serwowania stron www. Firewall, rozmieszczenie i zabezpieczenie bloków nie jest tematem ćwiczenia.
@Norbert z Klanu
Do następnej części będą dołączone pliki konfiguracyjne dla każdego z opisywanych serwerów, ja chcę bardziej przedstawić ogólny sposób na rozwiązania problemu niż schodzić na poziom instalacji i konfiguracji, to można sobie będzie później znaleźć w sieci jak będzie się już wiedziało co chce się odszukać :). Cierpliwości.
Poszukaj w sieci informacji o architekturze wielowarstwowej (lub trójwarstwowej), jest tego sporo. Generalnie każda z warstw (prezentacji/aplikacji/danych) powinna być odseparowana tak, aby w przypadku gdy ktoś dostanie się np. do serwerów prezentacji, nie miał pełnego dostępu do pozostałych elementów systemu.
@B
Dzięki za radę ale jak mówiłem na razie nie zajmuję się firewallem i planowaniem sieci, może w przyszłości do tej architektury coś takiego zaprzęgnę. Na razie kombinuję jak rozwiązać problemy z HA, HP, S :).
@B
Jeszcze jedna sprawa, jeżeli serwery DB dasz do innej strefy a serwery WWW do innej to i tak nie ma przeszkód aby przejąć serwery DB po włamaniu się na stronę www. Jest atak na MySQL do wykonania przez SQLi, który pozwoli na uruchomienie shella na serwerze DB co może prowadzić do zdobycia root’a(robiłem takie coś). Podstawą jest chyba bardziej konfiguracja firewalli na każdy serwer, definicja ruchu wychodzącego i wchodzącego per serwer, dobra konfiguracja serwera DB, włączenie SeLinuxa itp itd :). Same strefy nie wystarczą.
@OiSiS
Zgadza się, że sama segmentacja nie wystarczy, trzeba dbać o aktualność systemów, tak aby nie było można wykorzystać znanych podatności (na 0-day niewiele poradzisz).
Ale segmentacja może pomóc, np. ktoś włamuje się na serwer www, i łamie hasło root-a. Jest duże prawdopodobieństwo, że na serwerze bazy danych hasło będzie takie samo… i wtedy jeżeli mamy sewer DB jednej sieci to SSH na serwerze DB będzie dla niego dostępne, a jeżeli byłby tam firewall, który filtrowałby ruch pozwalając tylko na ruch do bazy danych to masz o jeden problem mniej…
Domyślam się, że Twoim priorytetem jest HA/Scalability i Performance, tylko robiąc taki poradnik trzeba uważać, żeby inny nie powielali “złych” (niebezpiecznych) wzorców :)
@B – pewnie dopiszemy mały przypominacz w tekście :)
@all apropos tej rozmowy, czy ktoś kojarzy coś lepszego / nowszego niż: http://www.amazon.com/Network-Security-Architectures-Networking-Technology/dp/158714297X/
– w temacie budowania bezpiecznych architektur sieci (różne scenariusze – VPN / WiFi / odpowiednia segregacja sieci / kwestie połączeń & integracji DMZ/LAN / itd)?
@B
Jest info żeby nie używać tej konfiguracji firewalla u siebie.
To, że będzie inne hasło na serwerze DB a inne na www to jest dla mnie oczywiste :). To, że przy ataku na serwer nie jest potrzebne żadne hasło, też jest dla mnie oczywiste(po za kilkoma przypadkami). Po prostu serwer www musi mieć dostęp do serwera DB, z serwera WWW włamujesz się przez podatnego MySQL do OS pod spodem, tam odpalasz shella i nawiązujesz połączenie do serwera www lub do swojego serwera na którym słucha już nc albo coś innego. Dzięki takiemu sposobowi firewall i podział na strefy tak jak to opisałeś nic tutaj nie da, chyba że strefę DB bardzo dobrze ograniczysz na firewallu pod względem ruchu wchodzącego z strefy DMZ z serwerami www oraz wchodzącego ale to samo możesz zrobić na każdej maszynie i jej zaporze. Nie mówię ,że Twoje rozwiązanie nie jest dobre, lepsze od mojego ale można je obejść :).
Do wcześniejszego komentarza, poproszę o scalenie :).
Czyli bezpieczeństwa nie załatwi żaden pojedyncze ograniczenie/oprogramowanie. Żeby zabezpieczyć taką architekturę trzeba podjąć wiele kroków, aktualizować wszystko, przeglądać logi itp itd. Temat rzeka dlatego tym się tutaj nie zajmuję bo artykułów było by ze 100 :).
@sekurak – ja widze w pracy sporo architektur ktore zwiekszaja bezpieczenstwo i powiem jedno – kwestia indywidualna, ale to dobra lektura na poczatek.
@OiSiS – Zarzadzasz ryzykiem. W przypadku ryzyk wskazanych przez Ciebie zabezpieczasz konkretne komponenty. Obcinasz dostepy. DBUser nie moze odpalic Shella w DB itp. Dobry podzial na strefy, S/D NAT miedzy strefami, przemyslany ruleset i nic nie zrobisz. Ponadto, tutaj omawiany jest LAMP i tedy oczekiwalbym wjazdu. – L7. Na poczatek WAF i dobrze zaudytowac aplikacje. Nalezy tez zauwazyc, ze takie srodowiska czesto sa polaczone z innymi, wiec podzial na strefy skutecznie utrudnia buszowanie czy infiltracje i ew. zostawienie badziewia.
@J
No to taka architektura webowa jest w miarę rozpoznana i są w miarę standardowe wzorce tutaj – łącznie z integracją z backendem choćby via MQ.
Bardziej się zastanawiam czy nie ma jakiejś literatury ogólnej w tym temacie (przykładowe wzorce architektur z omówieniem plusów / minusów – dla tematów bardziej skomplikowanych niż tylko webowe). Jedyną dobrą książkę jaką znam w temacie to właśnie: http://www.amazon.com/Network-Security-Architectures-Networking-Technology/dp/158714297X/
@J
Dokladnie tak jak piszesz. To nie jest tematem tego artykulu wiec sie tym nie zajmowalem ale cos ciekawego bym poczytal o tym zeby zdobyc dodatkowa wiedze.
a czy nie bedziesz mial nic przeciwko, ze po zakonczeniu calego ‘felietonu’ byc moze postaram sie z tego zrobic how-to?
@Norbert z Klanu
Pewnie ze nie bede mial nic przeciwko temu.
Fajny zarys, czekam na dalsze części. Warto też IMO rozbić sieć na mniejsze elementy (vlan), bo po co serwerowi bazodanowemu dostęp do NFSa albo dostęp z Internetu do DB?
Generalnie temat rzeka, od razu widzę też hardening od strony OS i milion innych rzeczy… ech czekam na kolejną część :P
@OiSiS
> Jest info żeby nie używać tej konfiguracji firewalla u siebie.
Mi nie chodzi o konfigurację firewalla tylko o architekturę rozwiazania
> To, że będzie inne hasło na serwerze DB a inne na www to jest dla mnie oczywiste :)
Uwierz mi, nie dla wszystkich jest to oczywiste :)
> Czyli bezpieczeństwa nie załatwi żaden pojedyncze
> ograniczenie/oprogramowanie. Żeby zabezpieczyć taką
> architekturę trzeba podjąć wiele kroków, aktualizować wszystko, > przeglądać logi itp itd.
zgadza się, dlatego należy mieć wiele elementów, które to bezpieczeństwo zapewniają (defense in depth), ale moim zdaniem jeżeli od początku źle zaprojektujesz system to potem jego zabezpiczenie będzie po pierwsze dużo trudniejsze a po drugie znacznie bardziej kosztowne..
Segmentacja sieci jest jednym z najstarczych sposbów na zwiększenie bezpieczeństwa systemów i o dziwo nadal jest bardzo skuteczna. Co więcej z tego co widzę to po kilku latach zapomnienia wraca do łask :)
Podsumowując: Nie odbieraj mojej wypowiedzi jako negatywną krytykę, starałem się aby była to konstruktywna krytyka. Impulsem do napisania mojego komentarza było to aby uniknąć podobnych sytuacji jak z “programistami” PHP, którzy kopiują kod skąd popadnie i są zadowoleni “bo działa” a jest dziurawy jak terorie Zespołu Parlamentarnego :)
Z drugiej strony dzięki nim mamy później co robić :D
Fajny pomysł na art, widać duże zainteresowanie po komentarzach. Widać też, że głównym celem nie było opisanie bezpieczeństwa, nie zawsze nam na tym w ogóle zależy. Czasem taki najprostszy serwis oparty na LAMP nie jest odwiedzany przez ludzi a np różne automaty. Samemu nie każdy potrafi znaleźć dobre wzorce i dużo czasu zajmie poprawne wyskalowanie rozwiązania aby najlepiej wykorzystać zasoby.
Swoją drogą ciekawe czy zakup takiego LB sprzętowego (np F5), który ma to wszystko “out of the box” i poradzi sobie z tym średnio kumaty z sieci admin na dłuższą metę nie będzie tańsze. (np w ciągu 5 lat?)
Mam nadzieję, że zobaczymy ładne podsumowanie co zyskaliśmy (może wykresy?) kosztem czego (zasoby)? I mam nadzieję, że jako przykład aplikacji będzie coś popularnego jak WordPress?
Daje Wam mojego LAJKA (muszę tu bo nie mam fejsa)
@maciek
Hardening jak najbardziej, optymalizacja OS pod konkretne usługi też.
@maciek
@B
Macie rację ale powtarzam po raz kolejny artykuł nie ma na celu projektowanie całej infrastruktury, DMZ, rozmieszczenia serwerów w DMZ itp itd. Rysunek jest poglądowy, może trochę mylący przez napis “DMZ network” to fakt ale miał tylko na celu przedstawienie co się będzie znajdować w sieci, nie jak ta sieć ma być lub powinna być zbudowana.
@Mad
Dokładnie jak piszesz. Artykuł ma na celu przedstawienie narzędzi, podpowiedzenie w jaki sposób je połączyć i co zyskujemy za pomocą całego “kombajnu”. Co do pudła zamiast tego rozwiązania może i LB to dobry pomysł ale w tym przypadku który ja opisuję większość rzeczy będzie zwirtualizowana, HAProxy i Keepalived zużywają naprawdę niewiele zasobów sprzętowych więc może po prosu nie opłaca się wydawać kasę na “pudło”(zależy ile takie pudło kosztuje). Tak dokładnie, rozwiązanie testowałem na WordPressie i to zamierzam na końcu przedstawić.
Jeszcze raz zaznaczam jest to PoC więc nie wyczerpuje to tematu, nie wskazuje jedynych dobrych narzędzi. Po prostu chcę przedstawić coś co działa i do czego doszedłem w całym tym eksperymencie.
@maciek
>> po co serwerowi bazodanowemu dostęp do NFSa
np. do SANa
@OiSiS
Jak wszystko chcesz zwirtualizować to postaw node’y VM a w nich FW, LB, DB i serwer a sieć zrób na Distributed Switch’ach albo na Nexus.
Pozbywasz się wtedy fizycznych pudełek.
Takie art, to złoto internetu w czystej postaci :)
@J
Dokładnie czasami SAN montowany jest do przetrzymywania plików DB albo do backupów.
Dokładnie chcę tak zrobić, w miarę możliwości postawić jak najwięcej w VM(zresztą tak jest zrobione całe ćwiczenie, na ESXi i na bardzo małym “pudełku” – które swoją drogą polecam do takich rzeczy albo jako kombajn multimedialny(OpenElec), platforma do gier(Windows) podłączona do TV).
1. Jak zarządzasz kontami userów w obrębie całej infrastruktury? Czy używasz np. FreeIPA, samego LDAP, NIS-a czy po prostu ręcznie kopiujesz pliki takie jak passwd?
2. Czy w ramach klastra masz jakiś dedykowany serwer DNS?
@MateuszM
Jeżeli chodzi o userów w OS to nie myślałem nad tym po prostu zrobiłem sobie jednego standardowego i lecę po SSH z kluczami dla prostoty i szybkości, do tego sudoers i temat zamknięty. Zresztą po co dawać userom dostęp do OSów po za NFS? Źródła strony są udostępniane po NFS każdemu z serwerów więc jakakolwiek ingerencja zwykłego usera odbywa się tylko na serwerach NFS. Niech lepiej oni mi się nie kręcą po pozostałych :). Zawsze można pomyśleć też o Puppetach dla tekiego rozwiązania co zamierzam kiedyś dodać.
Serwera DNS nie uwzględniałem, na razie nie ma takiej potrzeby, pewnie użyję DNS od ISP bo po co jeszcze to sobie na głowę zwalać.
… a potem przyszedł Node.js, otworzył sklep, i zaczął obsługiwać klientów, patrząc, jak obóz PHP oddala się w niepamięć ;)
@Robert
No nie tak szybko :).2