Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

VALL-E – Microsoft zaprezentował projekt, który wypowie Twoim głosem cokolwiek. Mając zaledwie kilkusekundowe nagranie Twojego głosu. Zobacz demo.
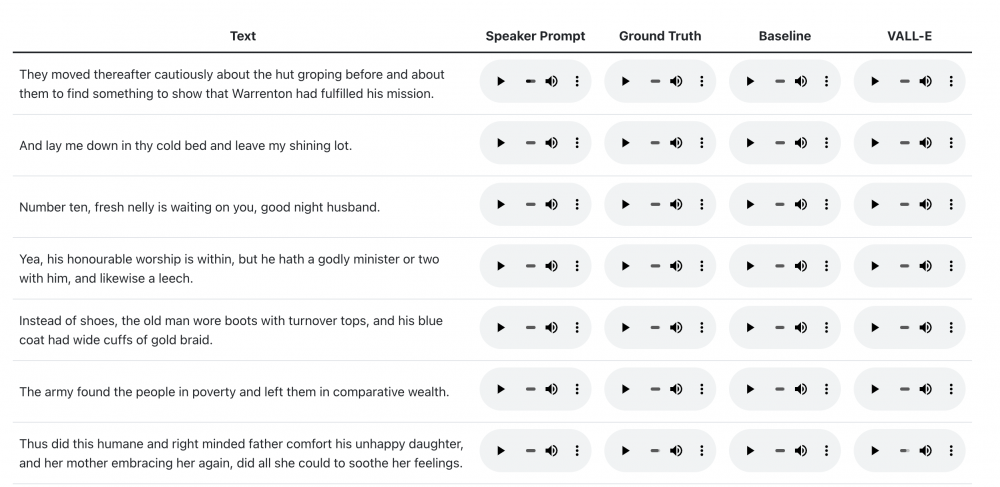
Jeśli chcecie zobaczyć demo – zapraszam tutaj. W pierwszej kolumnie macie nagranie paru sekund głosu prawdziwej osoby (losowa wypowiedziana fraza). W kolumnie VALL-E jest wpisana z klawiatury fraza, którą wypowiada AI – głosem nagranej osoby:
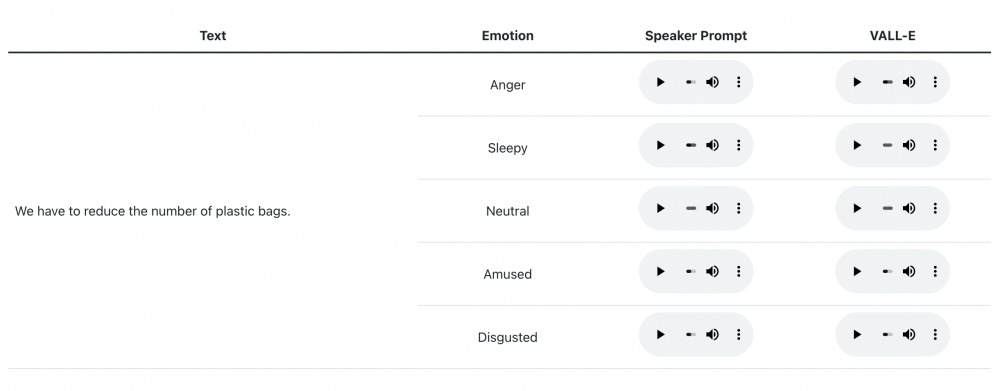
Z ciekawostek, system potrafi też wygenerować głos nacechowany pewnymi emocjami / cechami: np. złość, zdegustowanie, rozbawienie, zaspanie (badacze określają to jako “zachowanie w wymowie emocji mówcy”).
TLDR projektu:
Na etapie przedtreningowym umieszczamy w AI dane treningowe – do 60 000 godzin angielskiej mowy, czyli setki razy więcej niż istniejące systemy. VALL-E (…) może być używany do syntezy wysokiej jakości spersonalizowanej mowy z zaledwie 3-sekundowym zarejestrowanym nagraniem mówcy. Wyniki eksperymentów pokazują, że VALL-E znacznie przewyższa najnowocześniejsze systemy tego typu, pod względem naturalności mowy i podobieństwa mówców. Ponadto stwierdziliśmy, że VALL-E może zachować w syntezie emocje mówcy oraz środowisko akustyczne.
During the pre-training stage, we scale up the TTS training data to 60K hours of English speech which is hundreds of times larger than existing systems. VALL-E emerges in-context learning capabilities and can be used to synthesize high-quality personalized speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt. Experiment results show that VALL-E significantly outperforms the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity. In addition, we find VALL-E could preserve the speaker’s emotion and acoustic environment of the acoustic prompt in synthesis.
Wskazane są też zastrzeżenia natury etycznej:
Since VALL-E could synthesize speech that maintains speaker identity, it may carry potential risks in misuse of the model, such as spoofing voice identification or impersonating a specific speaker. We conducted the experiments under the assumption that the user agree to be the target speaker in speech synthesis. If the model is generalized to unseen speakers in the real world, it should include a protocol to ensure that the speaker approves the use of their voice and a synthesized speech detection model.
Rzeczywiście, istnieje możliwość wykorzystania tego typu narzędzi np. do ataków głosowych – choćby podszywających się pod głos prezesa: Sklonowali głos prezesa (deep fake). I przekonali pracowników żeby zlecili przelewy na równowartość przeszło 100 milionów PLN
~Michał Sajdak

Sami Chinczycy sa autorami.. niedobrze
Od jakiegoś czasu odbierając telefony z nieznanych mi wcześniej numerów najpierw czekam aż ktoś się odezwie zanim odezwe się ja – jeśli w ogóle ;)
To teraz wystarczy jakaś baza z danymi i numerami telefonów + bot dzwoniący pod nie i mamy piękna bazę ludzkich głosów… Także tego 😄
Będą ataki “na wnuczka” z głosem wnuczka.
czasem trudno uwierzyć w to, co się widzi , odtąd już nigdy nie będzie można uwierzyć w to co się słyszy
No to teraz Makaron zadzwoni do dudusia i nasze służby się nie połapią i duduś poodwala jakieś super wtopy.
psia d*pa…i wszystkie podsłuchy można między bajki włożyć ;)
Zastanawia mnie dlaczego te wszystkie opublikowane próbki są tak niskiej jakości.
Czyżby przy wyższej jakości było słychać większe różnice między oryginałem a wygenerowanym głosem i dlatego to jeszcze ukrywają?
@Krzysztof
Nawet na pewno, kompresja ścina niektóre cechy dźwięku i da się zatrzeć różnice
Fatalna wiadomość, 90% użycia tego narzędzia to będą nadużycia.
Strach wyobrażać sobie konsekwencje czegoś takiego. Gdyby to działało po polsku to od razu mamy trolli “przebierających” się za osoby np z rządu , wypowiadających się w kontrowersyjny sposób.
Fajne rozwiązanie, które będziemy mogli wykorzystać w firmie. Z jednej strony duże możliwości, a z drugiej ryzyko użycia głosu w nieautoryzowany sposób.
Przypomina się od razu Kevin McCalister jak zamawiał hotel w NYC udając swojego ojca :)