Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

“Skasowałem proda!” – kto nie miał takiej historii niech pierwszy rzuci kamieniem! ;-)
Tutaj ciekawy wątek, zawierający historię ~adminów, którzy przypadkowo skasowali a to dysk produkcyjny, a to całą bazę.
Na początek klasyka. Zapytanie na bazie (czasem z brakiem WHERE, albo złym WHERE). Niekiedy zdarzają się jeszcze inne błędy, które potrafią uratować sytuację (uffff :)
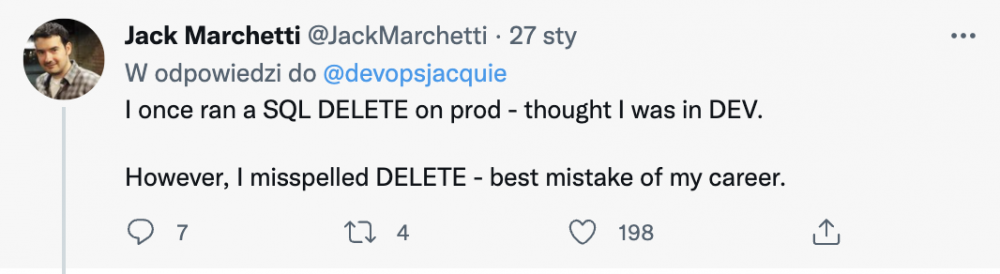
Czasem jednak takich błędów nie ma (oops):
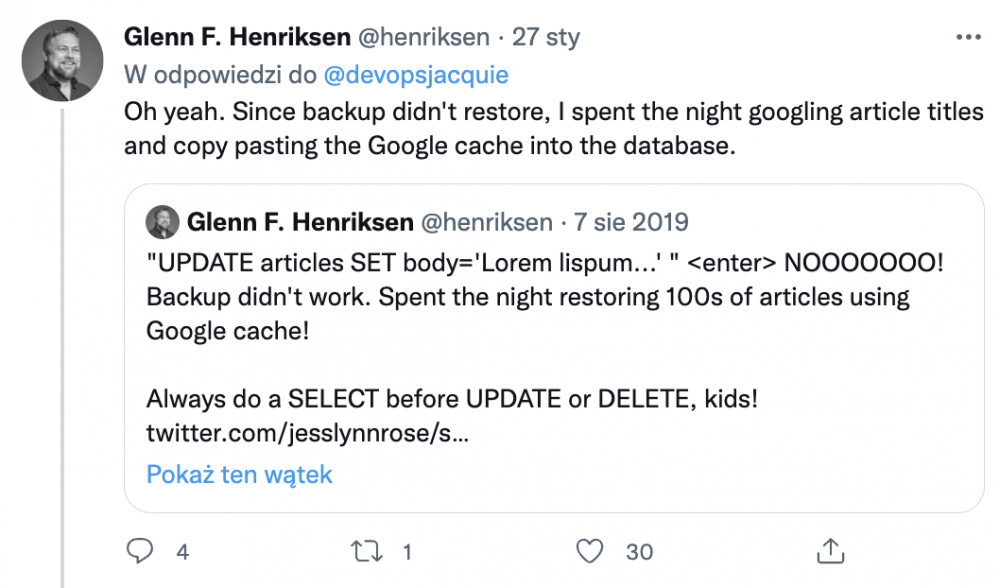
Pamiętajcie, nie przychodźcie na plotki do admina, kiedy ciężko pracuje! ;-)
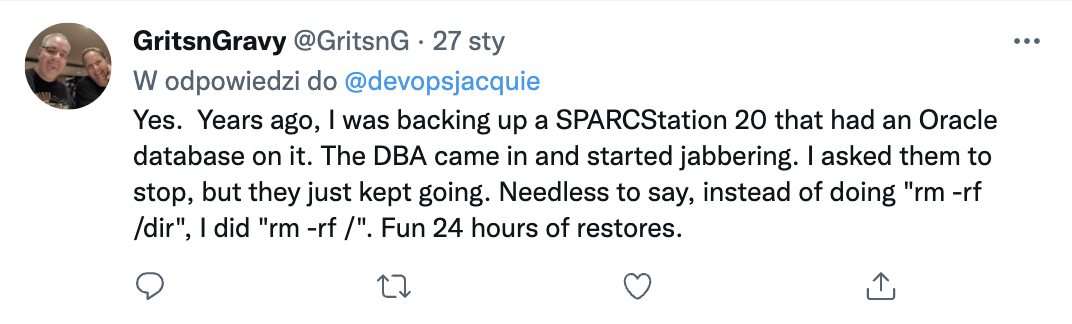
No właśnie, rm -rf * w nieodpowiednim miejscu to klasyka, ale czasem cała akcja nie jest taka oczywista…:
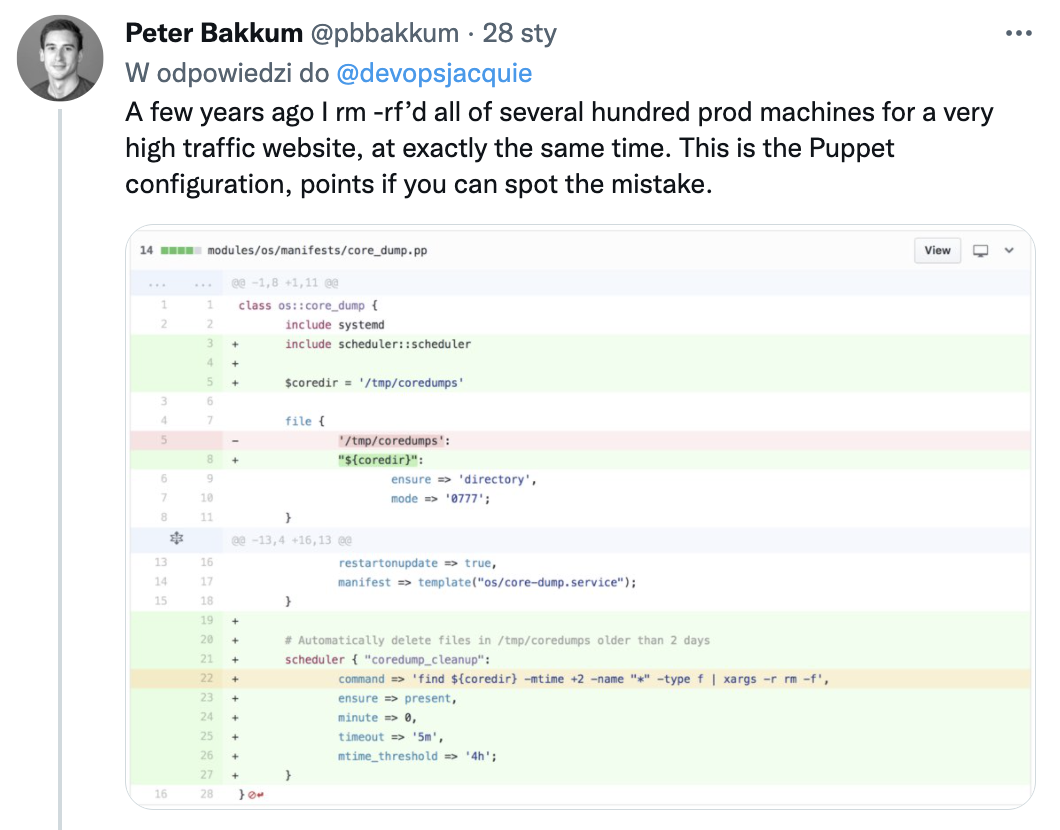
Nieco inna odmiana rm -rf /
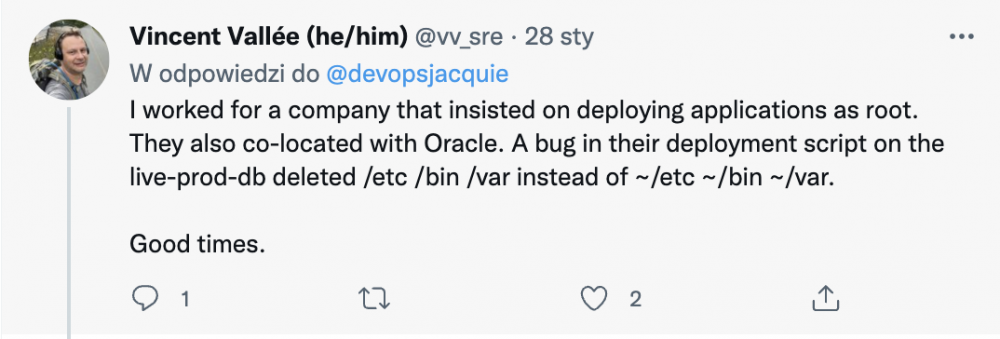
Są też zabawne historie. Tutaj chyba odpowiadający Benowi młodzieniec (bot?) z Nortona nie skumał zupełnie w czym sprawa ;-)
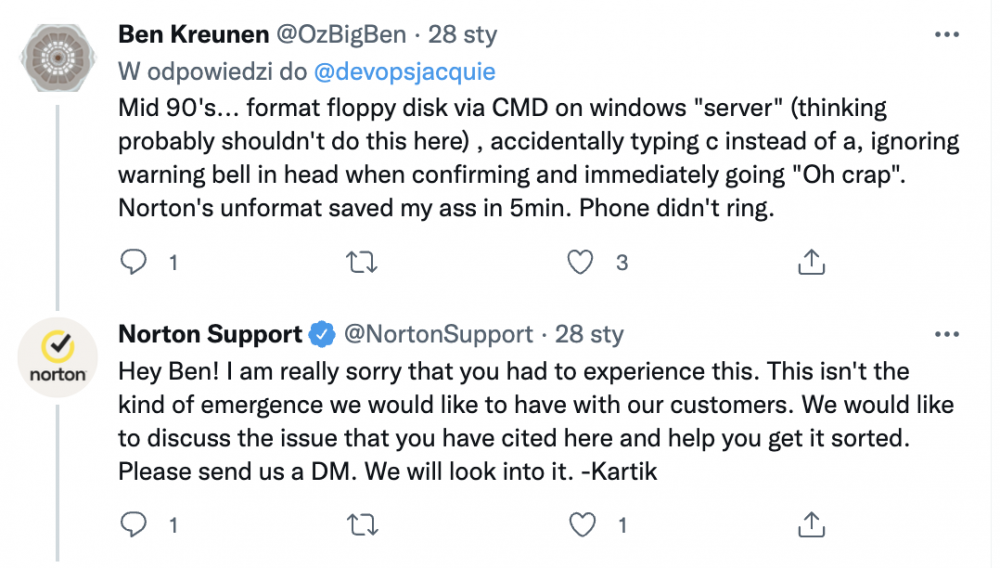
Archiwum e-maili w folderze “skasowane”? Czemu nie :P

Zdarzają się też historie stricte sieciowe:

A czy Wy macie jakieś ciekawe historie do opowiedzenia?
~Michał Sajdak

wielokrotnie czytałem historie o użytkownikach używających windowsowego kosza do przechowywania danych (“no przecież tam był to po co tworzyć nowy folder?”) tylko zawsze mnie to zastanawia, przecież tamtych plików specjalnie nie da się bezpośrednio otworzyć, żeby zniechęcić do takich akrobacji…
Dokładnie. Tak dużo historii tego typu czytałem, aw żadną nie mogę uwierzyć.
Ja też :)
Do pierwszego znalezionego pełnego kosza sądziłem, że to urban legend
Tylko czekałem na wzmianke o terraformie :P
No ja kiedys usunalem dx-connect u klienta bo zaaplikowalem zly plan, dzieki terraform usunalem awarie zanim sie ktos zorientowal.
Nigdy nie dokonałem spektakularnej awarii
“Pięknej katastrofy”
za to jestem sceptykiem, hamulcowym, opóźniam wdrożenia, wstrzymuje rozwój.
Same ze mną problemy bo ściągam “Ikarów” na ziemię.
polecam
chmod -x chmod
Akurat chmod -x chmod da się naprawić sztuczkami z cp i cat (albo leżącym gdzieś busyboksem – zawsze mam w jakimś katalogu statycznie linkowanego z opcjami pizza-ze-wszystkim).
5 minut się gapiłem w screenshot Puppeta… Gdzie jest błąd? (poza “logicznym”, czyli xargs rm, zamiast -delete)
@Pyth0n
${coredir} nie rozwiąże się w Puppecie, bo polecenie jest w pojedynczych cudzysłowach zamiast w podwójnych.
Rozwiążę się natomiast (na pusty łańcuch, bo zmienna środowiskowa nie będzie istnieć) w powłoce, która wykona polecenie…
/lib64/ld-linux-x86-64.so.2 /bin/chmod +x /bin/chmod
Niedziela, mocno rano, jakaś 5-6, alarm o braku miejsca na serwerze, prod oczywiście, więc chciałem logi wyczyścić z jakiegoś jBossa, bo logrotate nie nadążał czyścić i miejsce się przytkało.. i jakoś w porannym otumanieniu zamiast odpalić find /var/log/app/ -type f -mtime +1 -name “*.log” -exec ‘gzip -9 {}’ ‘;’, to z robiłem cd /opt/app; gzip -9v *
bum, wysadziło jednego node’a aplikacyjnego ;)
Zbyt rygorystyczna konfiguracja limits, fork właściwie na każdym poleceniu nawet po reboot.
Puszczalem co noc w cronie
cd /; costam; cd /trash ; rm -rf *
Naszla mnie kiedys zmiana nazwy /trash na /apptemp
O cronie zapomnialem…
dawno temu, w czasach kiedy zasilacze miały więcej molexów niż sata, przekładałem flaki do nowej, większej budy i jakimś cudem podpiąłem przelotkę molex-sata odwrotnie (tak, wiem, że molexa można wpiąć tylko na jeden sposób), widać była mocno wyrobiona, że wlazło bez problemów, potem końcówka sata do dysku, zasilanie, power, dymek….się okazało, że dysk był “raid0 member” ;)
Kiedys dawno temu jak root zrobilem na jednym serwerze chown -R mojuser.mojagrupa / zamiast na folderze w swoim katalogu.
Serwer proxy który odpytywał na zewnątrz miał ustawione w skrypcie hasło typu: “password;”. Zmieniłem hasło do konta w zewnętrznej usłudze no i pozostało tylko przekopiować hasło do skryptu żeby wszystko działało. Niestety nie działało. Okazało się że ten średnik na końcu hasła nie jest częścią hasła (mimo że jest w cudzysłowach) i musi być zawsze, czyli “nowehaslo” to “nowehaslo;”.
Do Pi podpięte 2 dyski 2Tb – bank zdjęć rodzinnych i4 Tb. Mialem clona dd zrobic na większy bo plikow duzo. Odpalone dd, pi padlo bo zona ładowarkę pomylila..
No to jak wstalo to ostatnia komenda.. Po restarcie dyski się zamieniły miejscami – nie sprawdziłem..
Odzysk plikow 2tyg.
Raz padł mi dysk na raspberry pi, miałem na nim nextclouda ze zdjęciami. Chciałem odpakowac archiwum z backupem tych zdjęć na laptopie, i utworzyłem nowe archiwum poprzez błędna literkę. 24GB zdjęć z dzieciństwa poszło się..
No popatrz jak trzeba to kamienia nie ma pod ręką :D
Okolice roku 2010. Slackware na serwerze produkcyjnym.
W tamtych czasach firma cięła koszty, więc wszystko stało na fizycznych blachach, a pojedynczy serwer robił za wszystko (gateway, serwer www, serwer poczty, serwer DNS, serwer proxy i kilkanaście innych mniejszych funkcji).
Nikt nie płacił za pracę w weekend czy po godzinach, więc nie było kiedy robić aktualizacji.
Cóż, aktualizacje systemu robione były w miarę regularnie w godzinach pracy. Zawsze się udawało, ot dzień jak co dzień…
# upgradepkg glibc*.tgz
#
Sukces, paczka zaktualizowana.
10 minut później…
telefon – “wysłałem maila do kolegi, ale nadal do niego nie dotarł”
Luz, pewnie przypchała się kolejka.
Akurat nie wylogowałem się jeszcze z sesji, więc:
# mailq
version `GLIBC_2.12′ not found (required by /lib/libc.so.6)
#less /var/log/maillog
version `GLIBC_2.12′ not found (required by /lib/libc.so.6)
Chwila konsternacji WTF?
# ls -l /var/log
version `GLIBC_2.12′ not found (required by /lib/libc.so.6)
# cp
version `GLIBC_2.12′ not found (required by /lib/libc.so.6)
Kilkanaście poleceń później – efekt ten sam, czegokolwiek bym nie wpisał, to niespełnione zależności dla GLIBC.
Po około 10 minutach załamany stwierdziłem, że działają tylko wewnętrzne polecenia wbudowane w basha.
Presja coraz większa, bo ludzie stracili już dawno nie tylko możliwość wysyłania poczty, ale i dostęp do Internetu.
Pomysł miałem tylko jeden – restart serwera (w sumie z guzika, bo shutdown też nie zadziałałby), uruchomienie z płyty CD systemu i przywrócenie poprzedniej wersji biblioteki. Jednak cały proces spowodowałby całkowitą przerwę w pracy całej firmy na co najmniej kolejne 20-30 minut. A to już było nieakceptowalne. Może jest jakiś inny sposób bez restartu?
W końcu wykorzystując tylko polecenia wbudowane w powłokę udało mi się reanimować system i przywrócić poprzednią wersję libc.so.6. Po zrestartowaniu większości usług, serwer zaczął wracać do życia.
Jednak jak po sprawdzeniu, że system działa usiadłem i zrobiło mi się gorąco, bo dopiero dotarło do mnie co za głupotę zrobiłem i jakie mogły być tego konsekwencje.
Wniosek na przyszłość:
Nie aktualizuj glibc w ciągu dnia! Nigdy!
Wniosek 2:
Nawet jeśli nie chcą płacić za pracę w nocy, to trudno – wolę to zrobić “bezpłatnie”, niż mieć ponownie takie wrażenia.
Tym razem miałem ogromnego farta, ale nie chciałbym ponownie znaleźć się w tej sytuacji.