Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

Rozwiązanie konkursu “Złam sekurakowe hasło i wygraj 1000 zł” – zobaczcie write-up zwycięzcy
Poniżej opis procesu łamania naszego hasła, przesłany przez zwycięzcę konkursu, _secmike. Prosił on również o nagłośnienie tej zbiórki, do wzięcia udziału w której zachęcamy.
****** A teraz writeup:
28 września 2024 roku na portalu sekurak.pl pojawił się ciekawy konkurs związany z odtworzeniem danych wejściowych do funkcji skrótu, dysponując jedynie danymi wyjściowymi, czyli mówiąc kolokwialnie łamaniem haseł. Autorzy konkursu udzielili następujących informacji na temat postaci hasła:
- hasło składa się z 3 słów w języku polskim,
- hasło tworzy logiczne zdanie po polsku,
- literki zastąpione znakami bez ogonków, np. mąka = maka,
- występują tylko małe litery.
Nagrodą za odzyskanie hasła było 1000 zł oraz powszechne uznanie wśród społeczności Sekurak ;).
O konkursie dowiedziałem się z Discorda na kanale Sekurak Academy. Biorąc pod uwagę fakt, iż nie dysponuję profesjonalnym sprzętem do „łamania hashy” atak siłowy (ang. brute-force) nie wchodził w grę. Poza tym oszacowałem, iż hasła składające się z 14 znaków (tylko małe litery), przekształcone przez funkcję skrótu SHA-256 są praktycznie nie do złamania, nawet na profesjonalnym sprzęcie.
Słownik języka polskiego, przechowujący praktycznie wszystkie słowa używane w języku polskim wraz
z odmianami posiada rozmiar ± 47,5 MB. Utworzenie słownika składającego się z kombinacji wszystkich słów w języku polskim jest praktycznie nierealne do przeprowadzenia, głównie z uwagi na zasoby pamięciowe. Powyższe rozwiązanie odrzuciłem, ponieważ nie posiadałem wymaganych zasobów.
Postanowiłem skupić się na budowaniu niedużych, precyzyjnych słowników. Mówiąc niedużych, mam na myśli ± 100 MB. Ponadto, w celu przeprowadzenia ataku kombinacyjnego, przygotowałem zestaw danych zawierający wszystkie słowa z języka polskiego wraz z ich odmianami, usuwając polskie znaki (tzw. pierwsze lub 3 słowo w haśle). Opierając się na analizie częstotliwości występowania słów
w języku polskim, podobnej do tej stosowanej w modelach językowych opartych na łańcuchach Markowa, przekształciłem słownik języka polskiego, umieszczając na początku listy słowa częściej występujące.
Inspiracją do utworzenia dedykowanego słownika, było hasło ujawnione przez organizatorów
z poprzedniego konkursu: mdlawymisiaczektluczeostrookienko. Moją uwagę skupiły następujące słowa: misiaczek oraz okienko. Założyłem, że przynajmniej jednym z wyrazów tworzących hasło będzie zdrobnienie.
Najwięcej zdrobnień występuje w bajkach dla dzieci, dlatego przygotowując słownik skupiłem się na publicznie dostępnych bajkach. W celu sanityzacji danych, napisałem mały program, który na podstawie danych wejściowych, przygotuje unikalną listę słów, a następnie zapisze ją do pliku. Drugą funkcją programu było zapisanie unikalnych podciągów składających się z 3 słów tworzących logiczną całość.
Po przygotowaniu około 1250 unikalnych słów, wykorzystałem oprogramowanie combinator.exe do utworzenia słownika złożonego z kombinacji dwóch słów. Nowo utworzony słownik składał się z 1,5 mln unikalnych słów i zajmował ± 30 MB. Słownik złożony z podciągów 3 logicznie powiązanych ze sobą słów był znacznie większy i po wygenerowaniu około 10 GB danych przerwałem operację.
Kolejnym krokiem było użycie oprogramowania hashcat do przeprowadzenia ataku kombinacyjnego:
hashcat –a 1 –m 1400 [hashFile] [Dic] [SlownikJezykaPolskiego] –w 4 -O |
Na wejście do programu hashcat podałem nowo utworzony słownik składający się ze słownika języka polskiego oraz podciągów złożonych z 2 słów.
Czas ataku został oszacowany na ± 12 h. Jednak po upływie połowy wymaganego czasu, udało mi się odzyskać poszukiwane hasło.
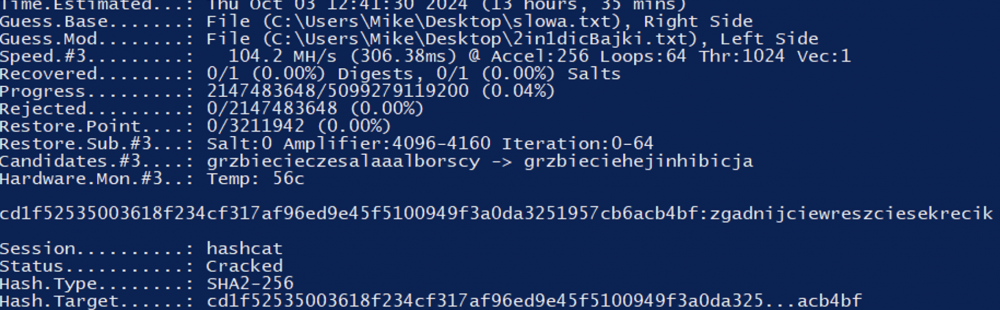
Podsumowując, uważam iż konkurs nie wymagał potężnych zasobów obliczeniowych ani najnowszego oprogramowania łamiącego hashe, co zostało udowodnione na powyższym zrzucie ekranu. Wymagał przede wszystkim sprytu oraz nieszablonowego podejścia do zagadnienia.
_secmike

Brawo. Bardzo pouczający opis. Nieraz zastanawiałem się, na ile i jak ktoś może wykorzystać schemat, na podstawie którego dana osoba tworzy hasła. Teraz już widzę :)
Brawa dla zwycięzcy, super pomysł z tym słownikiem na podstawie bajek!
Ja skupiłem się na rozdzieleniu części mowy, wiedząc że zdanie musi zawierać przynajmniejj jeden czasownik i zakładając że nie będzie ich więcej. Założyłem też że nie-czasowniki będą w bazowej formie, a tylko czasowniki odmienione – dostałem w ten sposób słowniki około 70 tys. nie-czasowników i miliona czasowników z odmianami. Kombinacji 3 słów było wciąż o wiele za dużo, więc tutaj przyjąłem niestety błędne założenie uciąłem słowa do długości od 4 do 9 znaków – więc pokonało mnie 10 literowe “zgadnijcie”, które nie załapało się do okrojonego słownika, a sprawdziłem że było w nieokrojonym.
Mimo wszystko super konkurs, nauczyłem się hashcata w końcu :D
@sekurak skoro konkurs zakończony, to możecie podać odpowiedź z drugiej edycji (4 losowe słowa, nie tworzące zdania)? Jestem ciekaw co tam było.
tak: piekniutkiwynalazkiokropienstwazaczadzilo
Z jakiej bajki/bajek zczytałeś wszystkie słowa?
To były różne bajki/wierszyki dla dzieci.
Julian Tuwim (Mój dzionek – słowo sekrecik)
Jan Brzechwa (Czerwony kapturek – słowo zgadnijcie)
Dorota Głośnicka (Zajączek, z serii bajek Zwierzaki Wierszaki – słowo wreszcie)
…
było jeszcze wiele innych bajek, Reksio, Tupcio Chrupcio, itd ;)
A jakie było hasło z 4 słów za 5000 zł ?
piekniutkiwynalazkiokropienstwazaczadzilo
Gratulacje dla zwycięzcy!
U mnie bazowo korzystałem ze słownika mofrosynktatycznego Marcina Miłkowskiego. Bazowo słownik ma 331 MB (odmiana + słowo + znaczniki synktatyczne) Ten przefiltrowałem przez:
* słownik SJP 2024 -> Wyjściowo 223 MB (67% oryginału)
* wordlistę ze wszystkich lektur projektu Wolne Lektury (a przynajmniej tych które były udostępnione jako plik .txt) -> Wyjściowo 89 MB (26% oryginału)
Ten pierwszy, przefiltrowany przez SJP, choć nadal duży uważam za lepszy bo drugi był mocno zbiasowany ze względu na dobór lektur (np. brak w nim słowa misiaczek) – tu przydałoby się założenie zwycięzcy co do zdrobnień i odpowiednie dobranie lektur do ekstrakcji wordlist :) Ostatecznie skorzystałem z morfologika przefiltrowanego przez SJP2024.
Myślałem nad zliczaniem częstotliwości słów z lektur, ale ostatecznie machnąłem na to ręką.
Aspektem nad którym skupiłem się najbardziej – słowa mają mieć logiczny sens. Liczba kombinacji losowych słów będzie ogromna, ale liczba kombinacji “szablonów” 3-wyrazowych zdań jest względnie mała. Zamiast tworzyć jeden mały konkursowy słownik zacząłem generować dziesiatki/setki małych słowników – 1, 2 i 3 (odpowiednio dla każdego wyrazu zdania). Słowniki 1 i 2 łączyłem w jeden (nie konktatenując :) ale generując kombinacje z 1 i 2), tak jak autor, ponieważ hashcat przyjmuje tylko 2 słowniki wejściowo do ataku z kombinacjami.
Oczywiście przy okazji dochodziła sanityzacja, mapowałem wszystkie znaki polskie na odpowiedniki alfabetu łacińskiego i lowercase-owałem.
Żadnych założeń co do długości wyrazów, brałem wszystkie.
No ale – jak generować logiczne zdania?
Tu pomaga właśnie słownik morfologiczny, bo nie jest zwykłą wordlistą, ale wygląda następująco:
“`
head ./dicts/polimorfologik.cross.sjp2024.txt
aa aa interj
aa ad acta
aaronowa aaronowy adj:sg:nom.voc:f:pos
aaronow─à aaronowy adj:sg:acc:f:pos+adj:sg:inst:f:pos
aaronowe aaronowy adj:pl:acc:m2.m3.f.n1.n2.p2.p3:pos+adj:pl:nom.voc:m2.m3.f.n1.n2.p2.p3:pos+adj:sg:acc:n1.n2:pos+adj:sg:nom.voc:n1.n2:pos
aaronowego aaronowy adj:sg:acc:m1.m2:pos+adj:sg:gen:m1.m2.m3.n1.n2:pos
aaronowej aaronowy adj:sg:dat:f:pos+adj:sg:gen:f:pos+adj:sg:loc:f:pos
aaronowemu aaronowy adj:sg:dat:m1.m2.m3.n1.n2:pos
aaronowi aaronowy adj:pl:nom.voc:m1.p1:pos
aaronowy aaronowy adj:sg:acc:m3:pos+adj:sg:nom.voc:m1.m2.m3:pos
“`
Każdy z tych znaczników (trzecia kolumna) precyzyjnie opisuje każdy wyraz. Dla przykładu “aaronowemu” to:
adj -> przymiotnik
sg -> liczba pojedyńcza
dat -> celownik
m1/m2/m3 -> rodzaj(e) męskie
n1/n2 -> rodzaje nijakie
pos -> stopień równy
A więc – można rozpisać sobie szablony od bardzo ogólnych (ale tworzących duże słowniki z tylko częściowo logicznymi zdaniami), dla przykładu:
misiaczek -> subst
tuli -> verb
okienko -> subst
Do bardzo precyzyjnych:
misiaczek -> subst:sg:nom:m2
tuli -> verb:fin:sg:ter:imperf:refl.nonrefl
okienko -> subst:sg:acc:n2+subst:sg:nom:n2+subst:sg:voc:n2
Rozpisałem całkiem sporo, bardzo precyzyjnych szablonów (biorąc pod uwagę nie tylko ogólny szyk zdania ale także liczbę pojedyńczą/mnogą podmiotu, czas przeszły/teraźniejszy/przyszły, odmianę i inne).
Wyszło z tego ponad tysiąc słowników które zajmowały 5-10 minut każdy do przejścia.
Obliczeniowo – korzystałem z 2x RTX3090, wychodziło coś w przedziale 14000/15000 MH/s.
Przykładowe szablony:
“`
sentences/batch-1/1-jestem-bardzo-fajny.txt
sentences/batch-1/11-warsztat-samochodowy-naprawia.txt
sentences/batch-1/15-przestan-duzo-jesc.txt
sentences/batch-1/16-izraelski-turysta-zwiedza.txt
sentences/batch-1/2-mam-fajnego-psa.txt
sentences/batch-1/20-naprawiam-samochod-lomem.txt
sentences/batch-1/3-mam-fajna-kotke.txt
sentences/batch-1/4-mam-fajne-pieczywo.txt
sentences/batch-1/5-bede-miec-psa.txt
sentences/batch-1/6-misiaczek-tuli-okienko.txt
sentences/batch-1/7-czerwone-auto-jedzie.txt
…
“`
Zawartość szablonu (częściowo):
“`
cat ./sentences/batch-1/6-misiaczek-tuli-okienko.txt
@ subst verb subst
### n(s) + n(s)
okienko tuli okienko
okienko tuliło okienko
okienko przytuli okienko
### n(p) + n(p)
okienka tulą okienka
okienka tuliły okienka
okienka przyutlą okienka
#
…
“`
Szablony więc grepowałem po morfologiku, stąd dla każdego szablonu miałem 3 słowniki z których już generowałem 2, które z kolei masowo szły do hashcata.
Co mnie pokonało? Nie wpadłem na
zgadnijcie -> verb:impt:pl:sec:perf:refl.nonrefl
wreszcie -> adv:pos+qub
sekrecik -> subst:sg:acc:m3+subst:sg:nom:m3
…;)
Aha, chciałem jeszcze dodać – to że zdanie ma mieć logiczny sens (przynajmniej składniowo) to jest największa podpowiedź jaka może być. Setki małych słowników nie mogą się mylić :) Trochę więcej szablonów i można przejść przez wszystko co się da w języku polskim dla 3 wyrazów.
Czytam, rozumiem i dalej wydaje mi się niemożliwe :D
“Drugą funkcją programu było zapisanie unikalnych podciągów składających się z 3 słów tworzących logiczną całość.”
Najciekawsza część, powiedz więcej.
Łańcuch markowa? Nlp toolkit?
💪
W dwóch słowach: szybki hajs.
Celem nie był szybki hajs. A zamiast nagrody pieniężnej poprosiłem o wsparcie zbiórki 🙂
Na powodzian?
Nie, dla dziecka w potrzebie https://www.siepomaga.pl/antoni-malinowski
Ja zbudowałem słownik wg popularności 350 tys słów, przerobiłem 70tys w 2 dni na 4060 z prędkością 26 000 MH/s i nici. Teraz patrzę bym musiał przerobić 140tys słów i dopiero bym złamał a czas poświęcony na to pewnie by oscylował na ok miesiąca.
Gratulacje dla zwyciezcy. Ciekawi mnie, na ile odgadywanie zostaloby skomplikowane, gdyby haslo wzbogacic znakami specjalnymi, czy cyframi?
104.2 MH/s… chyba niedużo, prawda? Jaki to był sprzęt? Obstawiam jakiegoś GTX-a.
Mi na M1 łamał z prędkością 100-200 MH/s także spodziewam się że to był macbook z serii M
Trzeba mieć łeb na tranzystorach.
Ja bym po prostu przekupił pracownika sekuraka i podzielił się zyskiem, ale to ja jestem czystym złem :]
masz aspirację do stanowiska na Wiejskiej;)