Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Adminie… Czy znamy Twoje grzechy? ;-) Sprawdź!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Adminie… Czy znamy Twoje grzechy? ;-) Sprawdź!

Kodowanie znaków mówi, najogólniej rzecz ujmując, w jaki sposób przekształcać bajty na znaki. Typowym kodowaniem, które stanowi podstawę do większości często używanych kodowań, jest ASCII. ASCII to kod 7-bitowy, który liczbom z zakresu 0-127 przyporządkowuje znaki sterujące, interpunkcyjne, cyfry, litery oraz inne symbole. Na przykład spacja jest kodowana liczbą 32 (0x20), zaś litera “A” ma kod 65 (0x41). Z racji faktu, iż ASCII to kod 7-bitowy, a w komputerach zwykle używa się 8-bitowych bajtów, utworzono wiele stron kodowych, rozwijających go o dodatkowe 128 znaków. Przykładem takich kodowań są używane w Polsce ISO-8859-2 bądź Windows-1250. Strony kodowe zwykle opierały się na pojedynczych bajtach, tj. każdy znak zajmował dokładnie jeden bajt. W jednym bajcie można jednak zmieścić tylko 256 różnych wartości, co uniemożliwiało utworzenie uniwersalnej strony kodowej zawierającej znaki z wszystkich możliwych języków świata. Prowadziło to dawniej do częstych problemów z poprawnym wyświetlaniem znaków ze względu na wybór niewłaściwej strony kodowej – najczęściej objawiające się wyświetlaniem “krzaczków” zamiast “ogonków” w polskojęzycznych tekstach, gdy zamiast kodowania ISO-8859-2 wybrano ISO-8859-1.
Aby rozwiązać ten problem wymyślono Unicode. Założeniem Unicode’u jest utworzenie zestawu znaków składającego się z wszystkich możliwych znaków występujących w dowolnych językach świata. Unicode różni się od dotychczas wspomnianych stron kodowych tym, że definiuje wyłącznie zestaw znaków, a nie sposób jego kodowania za pomocą bajtów. Dlatego zaistniała potrzeba utworzenia kodowań, takich jak UTF-8, UTF-16 czy UTF-32, które określają w jaki sposób zamienić znak z Unicode’u w strumień bajtów. Na stronach internetowych najczęściej spotkamy się z kodowaniem UTF-8, które swoją popularność z całą pewnością zawdzięcza temu, że jest zgodne z ASCII, bowiem znaki o numerach 0-127 są takie same jak w ASCII. Oznacza to, że tekst pisany alfabetem łacińskim (czyli np. tekst w języku angielskim) nie wymaga przekodowania go do UTF-8. W przypadku potrzeby zapisania innych znaków, UTF-8 może używać więcej niż jednego bajtu do zapisania pojedynczego znaku. Przykładowo, weźmy polską literę “Ł” (w przestrzeni Unicode jej kod to U+0141):
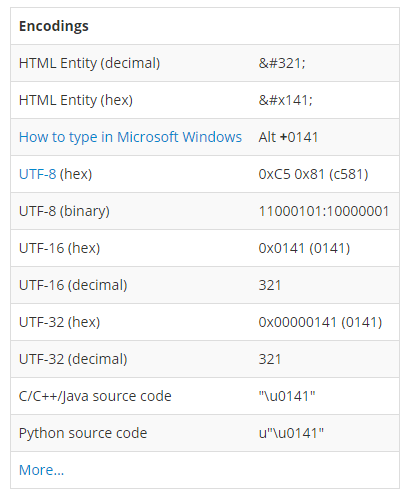
Różne sposoby kodowania znaku “Ł”
Jak widzimy, litera “Ł” w UTF-8 jest kodowana za pomocą dwóch bajtów 0xC5 0x81, z kolei w UTF-16 za pomocą kodu 0x0141 – czyli takiego samego jak kod w Unicode.
Potrzeba rozwiązania problemu kodowania dla bardzo wielu znaków zaistniała jeszcze wcześniej w krajach azjatyckich. Jednobajtowa przestrzeń znaków zupełnie nie wystarczała do pokrycia wszystkich symboli z takich języków jak japoński czy chiński, więc radzono sobie w inny sposób. Przyjrzyjmy się kodowaniu ISO-2022-JP. Kodowanie domyślnie działa w trybie ASCII, zaś zmiana trybu odbywa się poprzez specjalne sekwencje znaków (znak ESC to znak o kodzie 0x1B):
Zobaczmy na prostym przykładzie jak to kodowanie działa w praktyce. Utworzyłem plik o następującej treści:

Plik w kodowaniu ISO-2022-JP
Zobaczmy jak tekst będzie wyglądał, gdy zostanie zinterpretowany jako ISO-2022-JP:
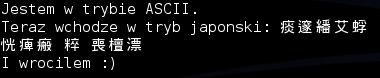
Plik zinterpretowany “po japońsku”
Jak widać, tekst, który wcześniej wyglądał jak zwykły tekst w alfabecie łacińskim (np. “Wracam do ASCII”), po interpretacji pliku w kodowaniu ISO-2022-JP zamienił się w symbole z alfabetu japońskiego. Prowadzi to do bardzo istotnego wniosku związanego z tym kodowaniem, mianowicie: gdy weźmiemy dowolny bajt z pliku zakodowanego w ISO-2022-JP nie jesteśmy w stanie stwierdzić, czy ten bajt zostanie zinterpretowany jako znak ASCII, czy jako znak jednego z kodowań japońskich, jeżeli nie przeanalizujemy pliku od początku. Może to prowadzić do różnych problemów związanych z interpretacją źródeł HTML-a, co pokażę w dalszej części artykułu.
Istnieją też inne kodowania działające na podobnej zasadzie. Na przykład HZ-GB-2312, służące do kodowania znaków języka chińskiego; do wejścia w “tryb chiński” wystarczą znaki ~{ oraz ~}.

Przykład HZ-GB-2312
Kolejnym kodowaniem, które może sprawiać problem jest Shift JIS. Jest to kodowanie jedno- lub dwubajtowe, a problematyczny jest znak \ (backslash, 0x5C), jeżeli występuje jako drugi bajt sekwencji dwubajtowej. Weźmy prosty plik HTML:

Niegroźny HTML…
Zobaczmy, że w tym przykładzie alert(1) nie wykona się, bowiem znajduje się wewnątrz ciągu znaków. Znajdujący się wewnątrz tego ciągu znak cudzysłowu jest escape’owany przez backslash. Widoczny znak  ma kod 0x81. Zobaczmy co się stanie, gdy zinterpretujemy ten plik jako Shift JIS:

… chyba że w Shift JIS
Znak backslasha zupełnie zniknął z wyjścia, gdyż 0x5C to część dwubajtowej sekwencji 0x81 0x5C. Zatem cudzysłów znajdujący się w środku źródła nie jest już escape’owany, co oznacza, że wykona się alert(1).
Poznaliśmy kilka przykładów kodowań, które mogą być groźne, bowiem mogą prowadzić do XSS-ów. Przeanalizujmy teraz w jaki sposób przeglądarki wybierają kodowanie dla strony.
W dalszej części tekstu pokażę różne ciekawe zachowania przeglądarek, które wynikają wprost z opisanego powyżej toku postępowania jak również z interpretacji poszczególnych kodowań.
Przywołajmy punkt czwarty z poprzedniego akapitu:Skanowanie pierwszych 1024 bajtów treści HTML-a w poszukiwaniu tagów np. <meta charset=utf-8> lub <meta http-equiv=Content-type content=”text/html; charset=utf-8″>. Jeśli zostaną znalezione, ustawiane jest kodowanie z tagów.
Skanowanie pierwszych 1024 bajtów treści HTML-a w poszukiwaniu tagów np. <meta charset=utf-8> lub <meta http-equiv=Content-type content=”text/html; charset=utf-8″>. Jeśli zostaną znalezione, ustawiane jest kodowanie z tagów.
Zauważmy, że nie zostało wyszczególnione gdzie konkretnie ma znajdować się tag <meta> poza tym, że w pierwszych 1024 bajtach. Okazuje się, że rzeczywiście w Firefoksie możliwe jest ustawienie kodowania wewnątrz dowolnego innego tagu, pomimo że dokumentacja Mozilli mówi wyraźnie coś innego. Możemy nawet zdefiniować to kodowanie w dowolnym miejscu tagu <script>, np.
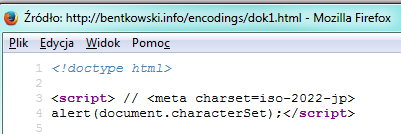
Definicja kodowania w tagu script
Po wyświetleniu strony w Firefoksie, przekonamy się, że w istocie ustawione zostało kodowanie ISO-2022-JP. W innych przeglądarkach taka sztuczka nie zadziała.
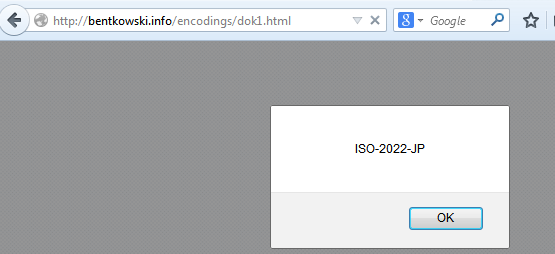
Firefox wziął pod uwagę definicje kodowania z tagu script
Ten trick może być przydatny, gdy mamy możliwość wstrzyknięcia czegoś bezpośrednio w źródle JS (ale nie jesteśmy w stanie uciec z tagu <script> bądź ze stringa).
Pod adresem http://bentkowski.info/encodings/dok2.php?name=NAME&title=TITLE uruchomiłem przykładową stronę działającą w kodowaniu ISO-2022-JP.
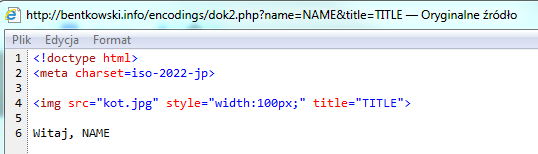
Źródło html dok2.pkp
Z poziomu URL mamy kontrolę nad dwoma parametrami, które są umieszczane w miejscu TITLE oraz NAME. Parametr TITLE nie pozwala wpisywać znaków “<>&, z kolei parametr NAME jedynie enkoduje znak < do <. W normalnych warunkach podatność prawdopodobnie byłaby nie do wyexploitowania, jednak kodowanie ISO-2022-JP wprowadza pewną możliwość ataku. Mianowicie: w parametrze title wejdziemy w “tryb japoński”, który spowoduje, że kolejne znaki nie będą interpretowane jako ASCII (co oznacza, że “połknięte” zostaną znaki “>), a następnie w parametrze name zamkniemy atrybut title i dopiszemy kod JS, np. atrybut onload. Zobaczmy efekt: http://bentkowski.info/encodings/dok2.php?name=%1B%28J%22%20onload=alert%281%29%3E&title=%1B$@x (link powinien działać pod każdą przeglądarką):
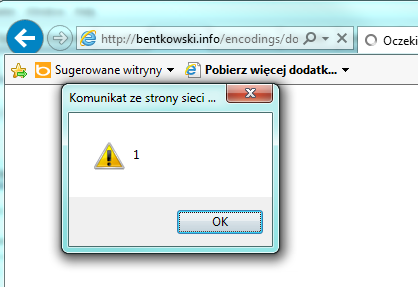
Wykonanie XSS w dok2.php
Spójrzmy w źródła…

Źródła XSS-a w dok2.php
W atrybucie title znalazło się trochę symboli japońskich, dzięki czemu ze źródła zniknęło oryginalne zamknięcie tagu img, zaś potem, poprzez parametr name, dostarczyliśmy swoje własne zamknięcie atrybutu title i dopisaliśmy zdarzenie onload powodując tym samym wyświetlenie XSS-a.
Przywołajmy pierwszy punkt z procesu ustalania kodowania przez przeglądarki:
Jeśli użytkownik wybrał ręcznie kodowanie strony korzystając z menu przeglądarki, to strona (jak i wszystkie ramki znajdujące się w niej) są interpretowane w tym kodowaniu.
Szczególnie warty podkreślenia jest fragment, że w wybranym przez użytkownika kodowaniu zostaną zinterpretowane także wszystkie ramki znajdujące się w ramach danej strony. Jeśli więc na stronie znajduje się iframe z innej domeny – w nim również zostanie wymuszone inne kodowanie. Ciekawy przypadek podatności tego typu pokazał niedawno nolze na swoim blogu (niestety PoC podany przez autora już nie działa, dlatego skopiowałem go na swoją domenę z drobną poprawką). nolze wykorzystuje cechę kodowania Shift JIS, o której pisałem wcześniej, mianowicie sprawia, że znak backslash nie zostanie zinterpretowany jako backslash ale jako część dwubajtowego znaku. W efekcie uda się uciec ze stringa i wykonać dowolny kod JS w domenie google.com. Aby zwiększyć prawdopodobieństwo ataku, umieszcza na niepozornie wyglądającej stronie niewidocznego iframe’a, w którym znajduje się odniesienie do google.com. Na samej stronie zaś celowo wyświetla krzaki w kodowaniu i zachęca użytkownika do zmiany kodowania na Shift JIS w przeglądarce. Gdy użytkownik zmienia kodowanie, zostaje ono zmienione także w iframe odwołującym się do google.com i XSS się wykonuje. Możecie całość przetestować pod adresem http://bentkowski.info/encodings/xss_google.html, poniżej filmik pokazujący, że payload rzeczywiście działa. [youtube_sc url=”https://www.youtube.com/watch?v=yZWAAx4H0ws&feature=youtu.be”] Wyjaśnienie, dlaczego atak działa:
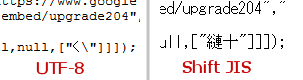
Niegroźny UTF-8 po lewej, i groźny Shift JIS po prawej
Z lewej strony widzimy interpretację fragmentu skryptu w kodowaniu UTF-8 gdzie znak cudzysłowu jest escape’owany przez backslash. Gdy to samo źródło zostaje zinterpretowane w Shift JIS, znak backslasha “znika”, w związku z czym cudzysłów zamyka stringa i wykonywany jest dalszy kod JS. Co ciekawe, nolze zgłosił oczywiście problem do Google w ramach programu bug bounty, tam jednak uznano, że błąd nie zostanie naprawiony, bo użytkownicy nie powinni manualnie zmieniać swojego kodowania. Inną ciekawostką jest fakt, że Michał Zalewski na swoim blogu pisał o problemie już trzy lata temu.
Jako ostatni przykład, odwołamy się do tytułu artykułu i pokażemy, że można utworzyć taką stronę, która będzie wywoływała XSS-a tylko wtedy, gdy język przeglądarki zostanie ustawiony na japoński. Wynika to wprost z ostatniego punktu toku zgadywania kodowania przez przeglądarki:
Wybranie domyślnego kodowania w zależności od lokalizacji użytkownika, np. ISO-8859-2 dla Polski bądź Windows-1252 dla Stanów Zjednoczonych.
Pod adresem http://bentkowski.info/encodings/japanese_xss.html wystawiłem przykładową stronę, w której XSS wykona się po ustawieniu kodowania ISO-2022-JP. To kodowanie zostanie ustawione automatycznie (przynajmniej w Firefoksie) w przypadku wejścia na stronę z japońskiej wersji przeglądarki; w polskiej wersji Firefoksa nie stanie się nic. Poniżej demo. [youtube_sc url=”https://www.youtube.com/watch?v=0exmFTSd82I&feature=youtu.be”]
Przede wszystkim w każdej podstronie należy jawnie ustawiać kodowanie. Biorąc pod uwagę uniwersalność i powszechność kodowania UTF-8, wydaje się ono w tym momencie najlepszym wyborem. W serwerze Apache można dodać dyrektywę
AddDefaultCharset utf-8
i wszystkie strony, które nie mają zdefiniowanego kodowania, będą miały dopisywane charset=utf-8 w nagłówku Content-Type. Ponadto należy wystrzegać się ręcznego ustawiania kodowania na jakiejkolwiek stronie, bowiem może prowadzić do wykonania XSS-ów.
W atrykule pokazałem, w jaki sposób niezdefiniowanie kodowania na stronie oraz wykorzystanie odpowiednich kodowań może pozwolić wykonywać XSS-y w miejscach, w których normalnie nie byłoby to wykonalne. Najlepszą metodą zabezpieczenia się przed tymi ryzykami jest jawne ustawianie kodowania na każdej podstronie.
Artykuł w żadnym wypadku nie wyczerpuje możliwych problemów związanych z kodowaniem w przeglądarce. Istnieją jeszcze między innymi ciekawe kodowania typu cp1025 (niezgodne z ASCII, wspierane przez Internet Explorer). Liczne są również błędy w samych przeglądarkach, które źle interpretują pewne kodowania bądź pozwalają w sposób niewłaściwy wymuszać kodowania inne niż deklarowane.

> Przykładowo, weźmy polską literę “Ł” (w przestrzeni Unicode jej kod to U+0142):
U+0141*
Artykul ciekawy, ale ja lubie sie czepiac. Ja wiem, ze teoretycznie bajt nie musi byc 8-bitowy, ale pokazcie mi seryjnie produkowany procesor/komputer/urzadzenie w ktorym bajt nie jest 8-bitowy. Tym samym stwierdzenie “w komputerach zwykle używa się 8-bitowych bajtów” powinno raczej brzmiec “jednak komputery uzywaja 8-bitowych bajtow”. Czyz nie? :-P
A jak kodujemy spację w UTF-8?
spacje kodujemy takim długim klawiszem na środku w najniższym rzędzie klawiatury ;-)