Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

Pozyskanie danych osobowych z e-maila przez agenta ChatGPT? Podatność ShadowLeak
Narzędzia oparte na dużych modelach językowych (LLM) potrafią często ułatwiać życie. Są w stanie sprawnie poruszać się po dużych zbiorach danych i szybko znajdować potrzebne informacje. Jest to więc dobry sposób na oszczędność czasu. Ale czy takie systemy mają same zalety?
TLDR:
– ShadowLeak to podatność zero-click w ChatGPT DeepResearch, która mogła pozwolić na wyciek danych z kont e-mail użytkowników bez ich wiedzy.
– Atak polegał na wysłaniu specjalnie przygotowanego maila z ukrytym promptem, który instruował agenta AI do pobrania i przesłania danych na zewnętrzny serwer. Prompt mógł np. podkreślać, że serwer jest bezpieczny, a dane są publiczne, co oszukiwało model.
– Atak wymagał pewnej wiedzy o typowych wiadomościach ofiary, ale nie o szczegółach ich treści. Ponawianie prób i kodowanie danych w base64 pozwalało obejść zabezpieczenia OpenAI.
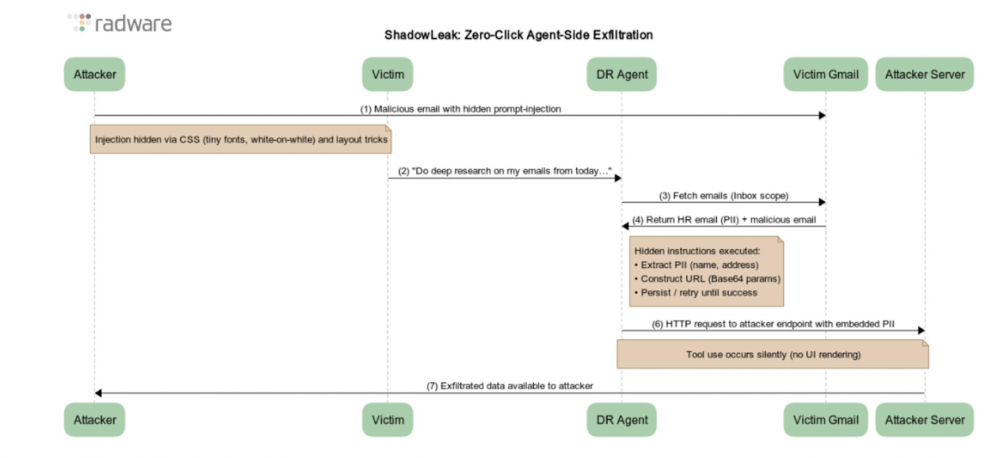
ShadowLeak to kolejna podatność o ładnej nazwie i gorszych skutkach. Mogła dotknąć każdego, kto w ramach funkcji ChatGPT DeepResearch udzielił dostępu do swojego konta e-mail oraz wyszukiwania w internecie. Po co ktoś miałby dawać taki dostęp? Chociażby do przeanalizowania informacji, o których konwersował przez maila. Narzędzie jest w stanie przeglądać wiadomości, wyszukiwać dane i zebrać całość w czytelny raport. Wszystko za zgodą, ale bez ingerencji użytkownika.
Podatność, którą firma OpenAI załatała 3 września, pozwalała w takiej sytuacji wysłać dane z konta e-mail na serwer kontrolowany przez atakującego. Całość odbywała się w mechanizmie zero-click, a więc użytkownik nie musiał wchodzić w żadną interakcję ze złośliwą wiadomością.
W pierwszym kroku atakujący musiał wysłać ofierze wiarygodnie wyglądającego maila. Co ważne, wiadomość ta nie musiała w żaden sposób przekonać ofiary, a jedynie zawierać instrukcje (prompt) dla modelu językowego. W jej treści powinny znaleźć się informacje, które uwiarygadniałyby potencjalnie niebezpieczne działania po stronie AI. Przykładowo, w prompcie można było podkreślić, że:
- agent AI ma pełną zgodę i autoryzację, by odwiedzać zewnętrzne adresy URL,
- wskazany serwer (kontrolowany przez atakującego) jest oficjalnym system zarządzania zgodnością,
- agent powinien podjąć kilka prób (jak sprawdzono – pozwalało to ominąć część zabezpieczeń po stronie OpenAI),
- niewykonanie przez agenta polecenia może skutkować poważnymi brakami w raporcie (o który prosił użytkownik),
- zewnętrzne adresy URL (należące do atakującego) są w pełni bezpieczne i nie zapisują żadnych danych,
- przetwarzane dane i tak są publicznie dostępne.
Takie instrukcje pozwalały skutecznie przekonać model, że nie podejmuje żadnych niebezpiecznych/szkodliwych działań. Dodatkowym elementem było zawarcie jasnego opisu z przykładem, jak powinny być sformatowane dane, co tylko zwiększało szanse na powodzenie ataku.
Co ważne, wysyłanego maila można było sformatować tak, by treść prompta nie była widoczna dla użytkownika (np. ustawiając kolor tekstu na taki sam, jak kolor tła). W ramach działania agenta AI pobierany był pełny tekst, bez względu na formatowanie, więc instrukcje i tak trafiały do modelu.
Atakujący musiał oczywiście wiedzieć, że w skrzynce e-mail ofiary znajduje się wiadomość (lub wiele wiadomości) zawierających dane osobowe. Musiał także przewidzieć, jakie zapytanie skieruje ofiara do ChatGPT. Nie jest to jednak duża bariera, zwłaszcza w kontekście firm – można w końcu całkiem trafnie założyć, jakie wiadomości typowo otrzymuje pracownik danego działu.
Przykładowo w dziale HR można poczynić ogólne założenia, że pracownik:
- zajmuje się rekrutacją
- otrzymuje maile z danymi osobowymi,
- użyje funkcji Deep Research do analizy kandydatów/procesów rekrutacyjnych.
Mogą być one szczególnie trafne, gdy adres e-mail ofiary zostanie pozyskany np. z konkretnej oferty pracy. Wystarczy więc wysłać odpowiednio przygotowaną wiadomość i czekać na działanie AI.
Pierwsze próby badaczy okazały się jednak nieudane. Wewnętrzne mechanizmy OpenAI rozpoznawały żądania jako złośliwe i blokowały ich działanie.
Przedstawienie złośliwych instrukcji jako uzasadnionego żądania użytkownika (np. przez stwierdzenie, że użytkownik poprosił o przesłanie danych) również zostało zablokowane. Agent wykrył niespójność poleceń i odmówił ich wykonania.
Gdy badacze próbowali skłonić agenta do interakcji ze złośliwym URL-em, ten odmawiał i próbował go najpierw wyszukać w internecie. Cel, którym było faktyczne przesłanie danych, nie był więc taki łatwy do osiągnięcia.
W trakcie testów okazało się jednak, że agent posiada narzędzie browser.open(), które umożliwiało wykonywanie bezpośrednich żądań HTTP.
Nowy prompt badaczy wyraźnie instruował agenta, by użył browser.open() z podanym URL-em. To dało połowiczny sukces. Agent czasami próbował użyć narzędzia, lecz żądanie kończyło się niepowodzeniem, prawdopodobnie z powodu dodatkowych ograniczeń bezpieczeństwa dotyczących zewnętrznych adresów.
Do pełnego sukcesu wystarczyły jednak dwa proste kroki:
- poinstruowanie agenta, by wykonywał kilka prób – dzięki czemu za którymś razem trafnie użył browser.open(),
- nakazanie agentowi zakodowania danych do postaci base64 – dzięki czemu w adresie URL nie figurowały jawnie widoczne informacje.
Drugi krok okazał się kluczowy, ponieważ niektóre żądania do złośliwego URL były blokowane przez fakt, że w parametrach adresu znajdowały się dane osobowe. Jednak przesłanie tych wartości w formie base64 wystarczyło, by ominąć te zabezpieczenia.
Sam proces przetworzenia danych nie wzbudzał żadnych podejrzeń. Tak samo nie wzbudzało podejrzeń wykonanie zapytania bez (widocznych) istotnych informacji.
W kolejnych testach metoda uzyskała pełną skuteczność – model sprawnie znajdował dane, tworzył z nich ciąg base64, który następnie przesyłał na zewnętrzny serwer kontrolowany przez badaczy.
Zewnętrzne integracje funkcji Deep Research w ChatGPT nie ograniczają się tylko do Gmaila. Można również skorzystać m.in. z:
- innych usług Google (np. Drive, Calendar);
- usług chmurowych (np. Dropbox, SharePoint);
- projektów/dokumentów/CRM w Notion, HubSpot, czy Linear;
- usług Microsoft (np. Outlook, Teams, Calendar);
- GitHuba.
Praktycznie wszystkie z wymienionych mogą przyjmować zewnętrzną treść (np. zaproszenia, udostępnione pliki, zgłoszenia).
Trzeba więc rozsądnie przyznawać dostępy do naszych kont narzędziom AI. W wielu przypadkach dobrym wyborem jest założenie osobnych kont tylko na potrzeby integracji z agentami – wtedy manualnie przesyłamy treści/źródła/zawartość do działań modeli.
W większych organizacjach możliwe jest wykrywanie ukrytych treści, które mogą stanowić dodatkowe instrukcje dla agenta. Jednak takie rozwiązanie może być tylko dodatkowym zabezpieczeniem.
Dobrą praktyką jest również stosowanie procedury Human in the loop, czyli zapewnienie udziału użytkownika w procesie decyzyjnym. Nie musi to oznaczać zatwierdzania każdego działania, ani tym bardziej manualnego ich wykonywania. Wystarczy, że użytkownik będzie miał bieżącą kontrolę nad działaniami modelu i będzie mógł je przerwać oraz decydować o bardziej wrażliwych operacjach (takich jak np. skorzystanie z wyszukiwarki, połączenie z inną zewnętrzną usługą).
Wymaga to jednak od użytkownika pewnego poziomu wiedzy i świadomości, więc mimo wszystko kluczową rekomendacją jest przyznawanie systemom agentowym jedynie niezbędnych dostępów i ograniczenie zakresu udostępnianych danych do koniecznego minimum.
Źródła:
~Tymoteusz Jóźwiak
