Tryb łącza zapasowego (failover backup)
Powiedzmy, że jako użytkownik domowy (lub małe przedsiębiorstwo) potrzebujemy maksymalnie niezawodnego dostępu do Internetu.
Nie jest problemem znalezienie dostawcy dysponującego handlowcem, który obieca nam wszystko, ze stuprocentową dostępnością włącznie. Przecież to jest światłowód/radiolinia/najnowsza technologia (niepotrzebne skreślić) i to się „praktycznie nigdy nie psuje”. A tak w ogóle to „tu się nie ma co psuć”.
Niestety, w praktyce ma co się psuć – i czasem się psuje.
Inne teksty o MikroTiku na Sekuraku:
Czy na pewno potrzebujemy łącza zapasowego?
Średnia usterkowość dla dobrych łącz to ok. 2 usterki w ciągu roku (mniej więcej kilka godzin rocznej niedostępności[1]). Jeśli jednak będziemy mieli pecha, to może być tego kilka/kilkanaście razy więcej i to się zdarza także dla łącz biznesowych zakupionych w poważnych telekomach.
1. Gwarancje SLA
A co z umową i gwarancjami dostępności?
Tutaj zwykle przychodzi rozczarowanie – jeśli nie zapoznaliśmy się wcześniej z warunkami świadczenia usługi. W przypadku typowych usług dla domu lub małych firm standardem jest gwarancja usunięcia usterki w przeciągu 24h, a minimalny poziom szybkości łącza jest… minimalny w dosłownym znaczeniu (np. 64 kb/s). Wydaje się to mieć na celu wyłącznie spełnienie obowiązku informacyjnego nałożonego przez Prawo Telekomunikacyjne, bo trudno rozpatrywać prędkość 64 kb/s (0.064 Mb/s) jako realną gwarancję dostępności dla łącza o nominalnej przepustowości rzędu np. 10 Mb/s.
Jeśli wyłożyliśmy większe pieniądze i dysponujemy łączem biznesowym z prawdziwego zdarzenia, to najpewniej mamy gwarancję poziomu jakości usługi SLA (ang. Service Level Agreement). Takie łącza zwykle mają gwarancję przepustowości na odpowiednim poziomie (nierzadko prędkość gwarantowana jest równa maksymalnej). Mamy też gwarancję rocznej dostępności usługi (typowe wartości 99.5% do 99.9%) oraz gwarancję usunięcia usterki (na ogół od 4h do 16h).
Spójrzmy jednak na to z dystansem.
Po pierwsze, te kilka godzin niedostępności usługi to nadal może być dla nas zbyt długo, jeśli w tym czasie nasz biznes jest unieruchomiony. Po drugie, gwarancja, wbrew temu, co sugeruje nazwa, nie gwarantuje, że dłuższa usterka nigdy się nie wydarzy. Oznacza to tyle, że gdy taka usterka się wydarzy, to mamy prawo do złożenia reklamacji i wnioskowania o odszkodowanie. Standardowo przysługuje nam odszkodowanie w wysokości abonamentu (lub jego dwukrotności) odpowiadającego czasowi niedostępności usługi. Będzie zatem to kwota zwykle nijak się mająca do rzeczywiście poniesionych strat.
Reasumując, jeśli myśl o kilku godzinach bez Internetu przyprawia nas o ból głowy, lepiej pomyśleć o dostępie zapasowym.
Łącze zapasowe – wybór operatora
Rozpatrzmy dwa warianty:
- Łącze zapasowe jako dodatkowa usługa operatora naszego głównego dostępu do Internetu. Z jednej strony, opcja ta może być godna uwagi ze względu na koszty oraz fakt, że operator, realizując dostęp do łącza zapasowego po swojej stronie, prawdopodobnie zapewni automatyczny mechanizm przełączania i przezroczystość rozwiązania. Nie będziemy musieli więc zmieniać konfiguracji naszej sieci. Z drugiej strony, pozostaje pytanie, na ile skuteczny będzie taki backup. Jeśli, przykładowo, łącze zapasowe będzie tylko w obszarze sieci dostępowej, natomiast połączenie nadal będzie przechodziło przez te same węzły sieci dystrybucyjnej czy szkieletowej, to w przypadku poważnej awarii w sieci operatora usługa i tak będzie niedostępna. Może się i tak zdarzyć, że automatyczny mechanizm nie wykryje usterki łącza lub sam w sobie ulegnie awarii, co spowoduje niedostępność usługi, pomimo że oba łącza będą sprawne.
- Niezależne łącze od innego operatora. Ze względu na niezawodność jest to rozwiązanie preferowane, jednak trzeba zwrócić uwagę, czy sieci operatorów są rzeczywiście niezależne. Może się bowiem okazać, że obaj operatorzy dzierżawią te same linie światłowodowe i w przypadku ich uszkodzenia usterka będzie dotyczyła obu łącz.
Rozwiązanie drugie wymaga mechanizmów obsługi wielu łącz po stronie klienta i na tym skupimy się w dalszej części tekstu.
Trudności wynikające z obsługi wielu łącz
W niniejszym opracowaniu skupiamy się na przypadku użytkownika domowego lub małej firmy. Do dyspozycji mamy zatem dwa tanie (nie-biznesowe) łącza internetowe lub ewentualnie jedno łącze klasy biznesowej (główne) i drugie niższej klasy (zapasowe).
Przypominam nasze wstępne założenie, żeby podkreślić, że problem redundancji łącz internetowych w większych jednostkach rozwiązywany jest inaczej – i gdy nasza firma będzie się rozrastać to w kierunku takiego rozwiązania warto się kierować.
Optymalne mianowicie jest posiadanie własnego systemu autonomicznego (ang. Autonomous System – AS) i rozgłaszanie własnej adresacji do operatorów poprzez protokół BGP. Taki scenariusz niweluje niektóre z niżej opisanych problemów, ale jest dostępny tylko w przypadku dostępu typowo biznesowego.
Do wyboru mamy dwa warianty obsługi łącza zapasowego: czysty failover oraz failover z load balancingiem.
- Pierwszy z nich, failover, oznacza, że w normalnej sytuacji używane jest tylko łącze główne, a w przypadku usterki cały ruch przechodzi na łącze zapasowe.
- Load balancing natomiast zapewnia równoważenie ruchu, gdy oba łącza są sprawne. Dalej skupiamy się tylko na pierwszym wariancie, który jest nieco prostszy w implementacji. W przypadku load balancingu poniższa lista problemów byłaby nieco dłuższa.
1. Zmiana adresacji
Główny kłopot wynika z faktu, że łącza posiadają różne adresacje IP, w związku z czym po przełączeniu naszego ruchu na inne łącze internetowe zmieni się adres źródłowy w nagłówku IP pakietów wysyłanych przez nas do Internetu. To z kolei spowoduje zerwanie nawiązanych sesji, ponieważ aplikacja gdzieś w Internecie, z którą byliśmy połączeni, nie będzie wiedziała (w przypadku znakomitej większości obecnie używanych protokołów, z TCP na czele), że pakiety przychodzące od hosta Y.Y.Y.Y należą do sesji nawiązanej wcześniej przez hosta X.X.X.X.
Efekt praktyczny będzie taki, że jeśli np. pobieramy plik lub oglądamy materiał wideo online, to pobieranie zostanie przerwane, możemy zostać wylogowani przy połączeniu z bankiem, w trakcie rozmowy VoIP stracimy fonię itp. To, na ile przerwa będzie dotkliwa i czy połączenie wznowi się automatycznie, zależy od konkretnej aplikacji. Niektóre (np. Skype) sprawnie wykrywają problemy w komunikacji i nawiązują nowe połączenie automatycznie. W przypadku wielu aplikacji konieczne jednak będzie ręczne odświeżenie połączenia (np. przeładowanie strony, uruchomienie pobierania pliku od nowa). Co ważne, przyczyny tego problemu są dość fundamentalne i (bez własnej adresacji i AS, o czym pisałem wcześniej) obecnie tego problemu rozwiązać się nie da.
2. Kryterium wykrycia usterki
Drugi problem to identyfikacja stanu łącza, czyli wiarygodne wykrycie momentu, kiedy łącze przestaje działać.
Standardowe podejście polega na odpytywaniu bramy domyślnej operatora narzędziem ping. Dopóki brama odpowiada, uznajemy, że łącze jest sprawne.
Niestety lista zalet tego rozwiązania kończy się na prostocie. Przede wszystkim, możliwa jest sytuacja, że brama operatora będzie odpowiadać pomimo tego, że łącze nie będzie działać (np. gdy usterka wydarzy się gdzieś głębiej w sieci operatora). Wtedy mechanizm po prostu nie zadziała i nie zmieni łącza. Z drugiej strony router operatora może nie odpowiadać na pakiety ICMP ze względu na politykę zastosowaną w firewallu. Nasuwa się tu oczywiste rozwiązanie, aby zamiast bramy operatora odpytywać jakiś publicznie dostępny w Internecie serwer, np. popularny portal czy serwer DNS. To podejście rozwiąże z reguły problem niewykrycia usterki, ale kosztem ryzyka wystąpienia odwrotnego problemu – fałszywego wykrycia usterki w sytuacji, gdy awarii ulegnie odpytywany przez nas host (lub z innych powodów przestanie odpowiadać na zapytania ICMP), a samo łącze będzie działało prawidłowo.
Inny problem związany z wykryciem usterki łącza dotyczy kryterium jakościowego. Jeśli odpowiedzi na nasze zapytania ICMP będą przychodzić z większym opóźnieniem niż jest to wymagane dla działania naszych aplikacji w stopniu użytecznym, to podstawowy mechanizm tej usterki także nie wykryje. Podobnie należałoby rozważyć aspekt progowej wartości strat pakietów rozstrzygający, czy łącze klasyfikujemy jako sprawne.
3. Częste zmiany stanu
Trzeci podstawowy problem, to częste zmiany stanu łącza (działa – nie działa – działa…) zwane też flapowaniem. Problem ten wiąże się z dwoma poprzednimi. Ponieważ każda zmiana łącza powoduje zerwanie sesji, to bardzo częste zmiany (np. co kilka sekund) mogą postawić nas w sytuacji de facto gorszej, niż gdybyśmy ciągle byli podłączeni do usterkowego łącza. Od tego jednak, jak czułe ustalimy kryterium usterki, zależy częstość przełączeń.
Konfiguracja
Spróbujemy teraz ustawić MikroTika do pracy z dwoma łączami w wariancie failover. Zbudujemy do tego celu topologię sieciową jak na rysunku:
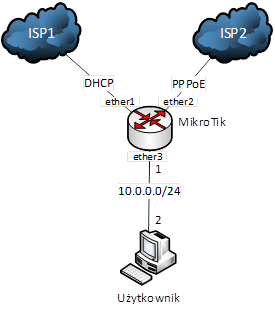
Mikrotik – dwa łącza
Dysponujemy dwoma łączami: do ISP1 (dostęp główny) i do ISP2 (dostęp zapasowy). Łącze główne działa na adresie IP otrzymanym z serwera DHCP, łącze zapasowe zrealizowane jest w technice PPPoE. Są to dwie najczęściej stosowane przez operatorów techniki. Nasz przykład jest adekwatny także do dość typowej sytuacji, gdy jako łącza zapasowego używamy połączenia PPP zestawionego za pośrednictwem modemu 3G/4G podłączonego bezpośrednio do płyty RouterBoard. Tutaj są dostępne listy wspieranych modemów 3G i 4G.
Do routera podłączony jest komputer użytkownika przy użyciu adresacji statycznej. Adres IP użytkownika to 10.0.0.2/24, jego brama to 10.0.0.1 (MikroTik).
Zacznijmy od skonfigurowania klientów DHCP oraz PPPoE oraz zaadresowania interfejsu dla sieci lokalnej.
Dodanie klienta DHCP:
[admin@MikroTik] > ip dhcp-client add interface=ether1 disabled=no
Zweryfikujemy jego działanie:
[admin@MikroTik] > ip dhcp-client print
Flags: X - disabled, I - invalid
# INTERFACE USE-PEER-DNS ADD-DEFAULT-ROUTE STATUS ADDRESS
0 ether1 yes yes bound 192.168.39.102/24
Jak widać, klient DHCP działa poprawnie i otrzymaliśmy adres 192.168.39.102/24.
Dodanie klienta PPPoE (login: user, hasło: password):
[admin@MikroTik] > interface pppoe-client add interface=ether2 user=user password=password disabled=no
Weryfikacja:
[admin@MikroTik] > interface pppoe-client print
Flags: X - disabled, R - running
0 R name="pppoe-out1" max-mtu=1480 max-mru=1480 mrru=disabled interface=ether2 user="user" password="password" profile=default keepalive-timeout=60 service-name="" ac-name="" add-default-route=no dial-on-demand=no use-peer-dns=no allow=pap,chap,mschap1,mschap2[admin@MikroTik] > interface pppoe-client monitor 0
status: connected
uptime: 44s
active-links: 1
encoding:
service-name: service1
ac-name: host
ac-mac: 02:DF:C4:6B:9E:94
mtu: 1480
mru: 1480
local-address: 172.16.0.2
remote-address: 172.16.0.1
Klient PPPoE również działa poprawnie, otrzymaliśmy adres 172.16.0.2.
Ustawienie adresu statycznego dla ether3:
[admin@MikroTik] > ip address add address=10.0.0.1/24 interface=ether3
Zweryfikujemy tabelę adresów IP:
[admin@MikroTik] > ip address print
Flags: X - disabled, I - invalid, D - dynamic
# ADDRESS NETWORK INTERFACE
0 D 192.168.39.102/24 192.168.39.0 ether1
1 D 172.16.0.2/32 172.16.0.1 pppoe-out1
2 10.0.0.1/24 10.0.0.0 ether3
Aby w sieci lokalnej był dostęp do Internetu, potrzebujemy jeszcze skonfigurować NAT dla obu łącz:
[admin@MikroTik] > ip firewall nat add chain=srcnat out-interface=ether1 action=masquerade
[admin@MikroTik] > ip firewall nat add chain=srcnat out-interface=pppoe-out1 action=masquerade
Na komputerze ustawiamy statycznie adresację 10.0.0.2/24 i bramę 10.0.0.1. Sprawdźmy połączenie z Internetem, pingując do publicznego serwera DNS Googla:
C:\Users\bart>ping 8.8.8.8
Pinging 8.8.8.8 with 32 bytes of data:
Reply from 8.8.8.8: bytes=32 time=74ms TTL=45
Reply from 8.8.8.8: bytes=32 time=77ms TTL=45
Reply from 8.8.8.8: bytes=32 time=74ms TTL=45
Reply from 8.8.8.8: bytes=32 time=75ms TTL=45
1. Sposób prosty
W tej chwili mamy dostęp do Internetu przez łącze ISP1, ponieważ MikroTik domyślnie dodaje domyślną trasę routingu dla klienta DHCP, a nie dodaje dla klienta PPPoE (zachowanie to dla obu klientów można zmienić poprzez atrybut add-default-route).
Potrzebujemy włączyć sprawdzanie dostępności bramy domyślnej od ISP1. Mamy tu dwie opcje do wyboru: ping lub ARP. Jeśli brama operatora odpowiada na zapytania ICMP, to zalecana jest opcja ping, ponieważ zapytania ping są przesyłane unicastowo. Przy opcji ARP MikroTik będzie wysyłał pod adres broadcastowy pakiet ARP request.
Ponieważ domyślnie dla dodanej trasy nie ma zaznaczonej opcji check-gateway, a tras dodanych dynamicznie nie możemy edytować bezpośrednio, to skorzystamy z funkcji filtrowania tras routingu:
[admin@MikroTik] > routing filter add action=passthrough chain=dynamic-in disabled=no set-check-gateway=ping
Reguła ta będzie ustawiać opcję check-gateway także dla innych dynamicznych tras w tablicy routingu (z wyjątkiem tras bezpośrednio podłączonych i dodanych przez protokoły routingu). W niektórych sytuacjach takie rozwiązanie może nam nie odpowiadać, więc ograniczmy zakres reguły filtrującej trasy routingu:
[admin@MikroTik] > ip dhcp-client set 0 default-route-distance=254
[admin@MikroTik] > routing filter set 0 distance=254 set-distance=1
Zmieniamy dystans administracyjny (na 254) dla trasy tworzonej przez klienta DHCP, aby użyć tego parametru jako wyróżnika. Dla wcześniej utworzonej reguły filtrowania trasy routingu dodajemy warunek, aby przechwytywał tylko trasy z dystansem 254 i zmieniał go na pierwotną wartość, czyli 1.
Jeżeli główne łącze jest zestawione przy użyciu techniki PPPoE lub adresacji statycznej, to powyższe kombinacje nie są potrzebne. Wystarczy wtedy dodać statyczną trasę domyślną, ustawiając jej opcję check-gateway w analogiczny sposób, w jaki teraz dodamy trasę zapasową przez łącze PPPoE:
[admin@MikroTik] > ip route add gateway=pppoe-out1 distance=2
Dystans administracyjny (distance) dla trasy zapasowej ustawiliśmy na 2, czyli wyższy niż dla trasy głównej (1). Jeśli router ma w tablicy routingu dwie trasy do tej samej sieci docelowej (np. dwie trasy domyślne), to aktywna będzie trasa z niższym dystansem administracyjnym. Trasa zapasowa (z wyższym dystansem) stanie się aktywna dopiero wtedy, gdy trasa główna stanie się niedostępna.
W tej chwili mamy już działający, prosty mechanizm typu failover. Jego główna wada polega na tym, że odpytywana jest tylko adres IP bramy, czego konsekwencje zostały wcześniej opisane.
Kolejna wada, to że nie mamy wpływu na czułość/szybkość wykrycia usterki. Przy opcji check-gateway MikroTik wysyła zapytanie co 10 sekund, a po dwóch kolejnych brakach odpowiedzi określi trasę jako nieosiągalną. Do przywrócenia aktywnego stanu trasy wystarczy jedna odpowiedź, zatem mechanizm będzie podatny na flapowanie łącza.
Dalej, nie mamy możliwości ustawić maksymalnego dopuszczalnego opóźnienia.
Pewną wadą jest też to, że MT zmienia łącza w sposób cichy – bez żadnego powiadomienia ani śladu w historii. Możemy włączyć debugowanie:
[admin@MikroTik] > system logging add topics=route,debug,!calc
Niestety, zapisywane logi są mało precyzyjne i mało czytelne.
2. Sposób zaawansowany
Wykorzystując możliwości, jakie daje użycie skryptów na MikroTiku, możemy zbudować znacznie lepszy mechanizm, który skutecznie adresuje wyżej wspomniane braki. Poniższe podejście ma ograniczenie dotyczące sytuacji, gdy jedno z łącz (tak jak w naszym przykładzie) opiera się na DHCP. Potrzebujemy dodać trasy domyślne dla łącz do kilku tablic routingu, a MT nie ma funkcji, która by to pozwoliła zrobić w przypadku klienta DHCP (i nie pomogą też reguły filtrowania tras routingu). Przyjmiemy w tym momencie założenie, że brama domyślna, jaką otrzymujemy od operatora przez DHCP, jest zawsze taka sama (często tak jest) i możemy ją ustawić wpisem statycznym. (Jeśli takiego założenia nie możemy poczynić, to problem da się rozwiązać prostym skryptem, który będzie aktualizował trasy statyczne, jeśli nowa trasa otrzymana z DHCP będzie inna.)
Zasada mechanizmu jest taka, że monitorowana będzie grupa adresów IP należących do hostów publicznie dostępnych w Internecie (w konfiguracji skryptu uzupełniamy listę adresów). Aby łącze zostało zakwalifikowane jako uszkodzone, to dla każdego z adresów z listy muszą wystąpić minimalne określone straty pakietów. Domyślnie dla każdego adresu musi zginąć min. 2/10 pakietów. Dzięki takiemu zachowaniu mechanizm jest odporny na sytuację, gdy jeden z monitorowanych hostów przestanie udzielać (z jakiejkolwiek przyczyny) odpowiedzi na zapytania ICMP. Dopóki przynajmniej jeden host z listy będzie działał prawidłowo, nasz mechanizm nie będzie generował fałszywych przełączeń na łącze zapasowe.
Przejście na łącze główne nastąpi dopiero wtedy, jeśli otrzymamy określoną liczbę odpowiedzi (domyślnie 10/10) od przynajmniej jednego z hostów. Jest to warunek zapobiegający częstym przełączeniom w przypadku dużych strat pakietów na łączu. Tutaj także wystarczy nam jeden działający monitorowany host.
MikroTik nie pozwala na bezpośrednie określenie czasu timeout dla polecenia ping, natomiast maksymalne opóźnienie ustawiamy, wykorzystując parametr interwału pingowania. Domyślnie w skrypcie jest on ustawiony na 300 ms. Jeśli MikroTik w momencie wysyłania kolejnego zapytania ICMP nie ma odpowiedzi na poprzednie zapytanie, to jest to traktowane jako strata.
Mechanizm jest uogólniony na dowolną liczbę łącz. Każde z łącz jest niezależnie testowane i wyłączane w przypadku wykrycia awarii, co jest dobrym punktem wyjścia do wdrożenia load balancingu. W naszym przypadku (czysty failover) monitorowanie łącza zapasowego może wydawać się zbędne, jednak warto je prowadzić, aby uniknąć sytuacji, gdy o tym, że łącza zapasowe (od dawna) nie działa, dowiadujemy się dopiero w momencie awarii głównego.
Parametry mechanizmu są konfigurowalne, więc możemy go dostosować do naszych wymagań, ustalając właściwy kompromis np. pomiędzy szybkością wykrycia usterki a ryzykiem narażenia się na problemy w przypadku flapowania głównego łącza.
W przypadku przełączeń, skrypt zapisuje odpowiednią informację w logach, co pozwala na szybkie wykrycie usterki przez administratora, a także prześledzenie historii.
Pomimo że poniższy skrypt nie wykorzystuje żadnych zaawansowanych funkcji, zalecane jest staranne przetestowanie jego działania w przypadku innej wersji systemu RouterOS niż v6.27 oraz każdorazowo po aktualizacji systemu.
MikroTik w swej historii wielokrotnie dokonywał zmian w składni (czasem bardzo drobnych), zwykle nie wspominając o tym w changelogu. W takiej okoliczności skrypt się nie wykona (ze względu na błąd składni). W razie wystąpienia błędu, skrypt powinien zapisać w logach „wan monitoring: blad wykonania skryptu”
.
Wróćmy teraz do stanu podstawowej konfiguracji routera, tzn. sprzed części „Sposób prosty”. Ponieważ wszystkie trasy będziemy dodawać statycznie, to wyłączymy dodawanie trasy domyślnej przez klienta DHCP. Zanim jednak to zrobimy, sprawdźmy, jaka jest ta brama, aby wiedzieć, co potem dodać:
[admin@MikroTik] > ip route print
Flags: X - disabled, A - active, D - dynamic,
C - connect, S - static, r - rip, b - bgp, o - ospf, m - mme,
B - blackhole, U - unreachable, P - prohibit
# DST-ADDRESS PREF-SRC GATEWAY DISTANCE
0 ADS 0.0.0.0/0 192.168.39.1 1
1 ADC 10.0.0.0/24 10.0.0.1 ether3 0
2 ADC 172.16.0.1/32 172.16.0.2 pppoe-out1 0
3 ADC 192.168.39.0/24 192.168.39.102 ether1 0
Jak widzimy, brama domyślna na łączu głównym to 192.168.39.1. Wyłączmy teraz jej automatyczne dodawanie przez klienta DHCP:
[admin@MikroTik] > ip dhcp-client set 0 add-default-route=no
Dodajemy teraz trasy statyczne. Oprócz domyślnej tablicy routingu, używamy osobnych tablic dla każdego z łącz, które będą służyć do testowania danego łącza. W tablicy głównej do tras dodajemy komentarze. Jest ważne, aby komentarze były dokładnie w formacie „wan monitoring: laczeX” (gdzie X to nr łącza odpowiadający numerowi na liście lacza_interfejsy w skrypcie), ponieważ komentarz ten jest wykorzystywany przez skrypt do wykonywania operacji na trasie.
[admin@MikroTik] > ip route add gateway=192.168.39.1 comment="wan_monitoring: lacze1"
[admin@MikroTik] > ip route add gateway=pppoe-out1 distance=2 comment="wan_monitoring: lacze2"
[admin@MikroTik] > ip route add gateway=192.168.39.1 routing-mark=lacze1
[admin@MikroTik] > ip route add type=blackhole routing-mark=lacze1 distance=2
[admin@MikroTik] > ip route add gateway= pppoe-out1 routing-mark=lacze2
[admin@MikroTik] > ip route add type=blackhole routing-mark=lacze2 distance=2
W tablicach do testowania poszczególnych łącz dodane są też wpisy typu blackhole ze słabszym dystansem. Dzięki tym trasom, w razie niedostępności bramy domyślnej dla wybranego łącza, ruch nie będzie przetwarzany przez główną tablicę routingu (i nie zostanie przekierowany na inne łącze).
Skrypt należy dodać do harmonogramu (System > Scheduler), zalecany interwał powinien być większy o min. 10 s.[2] od iloczynu maksymalnego tolerowanego opóźnienia (ping_interval), liczby łącz (lacza_interfejsy), liczby pingów do sprawdzania danego hosta (ile_pingow) i liczby hostów do monitorowania (adresy_monit). W naszym przykładzie iloczyn będzie miał wartość 300ms*2*10*4 = 24s, zatem zalecana wartość interwału dla harmonogramu to ok. 35 sekund.
:do {
# ---------------------------- tu ustaw parametry ----------------------------
# interfejsy na ktorych dzialaja lacza: {"lacze1";"lacze2"; ...}
:local "lacza_interfejsy" {"ether1";"pppoe-out1"}
# lista adresow ktore beda pingowane do weryfikacji kazdego z lacz
:local "adresy_monit" {"176.31.167.200";"213.180.141.140";"194.204.159.1";"85.232.232.65"}
# maksymalne tolerowane opoznienie
:local "ping_interval" "300ms"
# liczba wysylanych pingow w celu sprawdzenia danego adresu
:local "ile_pingow" 10
# co najmniej ile odpowiedzi musi wrocic aby uznac ze adres nadal dziala
# jesli wroci mniej to nastepuje zmiana stanu up > down
# wartosc nie moze byc wieksza niz ile_pingow
:local "ile_pingow_up" 7
# co najmniej ile pingow musi wrocic aby uznac ze adres zmienil stan down > up
# wartosc powinna byc wieksza niz ile_pingow_updown
# wartosc nie moze byc wieksza niz ile_pingow
:local "ile_pingow_downup" 10
# --------------------------------------------------------------------------
:global "wan_status"
:global aktywne
:local "ile_lacz" [:len $"lacza_interfejsy"]
:local "ile_adresow" [:len $"adresy_monit"]
:local zmiany
:local "log_tresc" ""
:if ([:typeof $"wan_status"] = "nothing") do={
:log debug "inicjalizacja"
:set aktywne 1
:for i from=1 to=$"ile_lacz" do={
:set "wan_status" ($"wan_status","up")
/ip route disable [find comment=("wan_monitoring: lacze" . $i)]
:if ([/ip route get [find comment=("wan_monitoring: lacze" . $i)] distance] < [/ip route get [find comment=("wan_monitoring: lacze" . $aktywne)] distance]) do={
:set aktywne $i
}
}
/ip route enable [find comment=("wan_monitoring: lacze" . $aktywne)]
}
:for i from=1 to=$"ile_lacz" do={
:set zmiany ($zmiany,"bez_zmian")
:local "tab_rut_test" ("lacze" . $i)
:local "ile_dziala" 0
:if (($"wan_status" -> ($i - 1)) = "down") do={
:for j from=1 to=$"ile_adresow" do={
:if ([/ping ($"adresy_monit" -> ($j - 1)) interval=$"ping_interval" routing-table=$"tab_rut_test" count=$"ile_pingow"] >= $"ile_pingow_downup") do={
:set "ile_dziala" ($"ile_dziala" + 1)
}
}
:if ($"ile_dziala" > 0) do={
:set ($zmiany -> ($i - 1)) "downup"
}
} else={
:for j from=1 to=$"ile_adresow" do={
:if ([/ping ($"adresy_monit" -> ($j - 1)) interval=$"ping_interval" routing-table=$"tab_rut_test" count=$"ile_pingow"] >= $"ile_pingow_up") do={
:set "ile_dziala" ($"ile_dziala" + 1)
}
}
:if ($"ile_dziala" = 0) do={
:set ($zmiany -> ($i - 1)) "updown"
}
}
}
:for i from=1 to=$"ile_lacz" do={
:if (($zmiany -> ($i - 1)) = "updown") do={
:set ($"wan_status" -> ($i - 1)) "down"
:if ($"log_tresc" != "") do={
:set $"log_tresc" ($"log_tresc" . ", ")
}
:set $"log_tresc" ($"log_tresc" . "lacze" . $i . " down")
:if ($aktywne = $i) do={
/ip route disable [find comment=("wan_monitoring: lacze" . $i)]
# czyszczenie wpisow connection tracking
:if ([/interface get ($"lacza_interfejsy" -> ($i - 1)) disabled] = no) do={
/interface disable ($"lacza_interfejsy" -> ($i - 1))
/interface enable ($"lacza_interfejsy" -> ($i - 1))
}
# czyszczenie wpisow connection tracking - koniec
:local distance 255
:for j from=1 to=$"ile_lacz" do={
:if (($"wan_status" -> ($j - 1)) = "up" && [/ip route get [find comment=("wan_monitoring: lacze" . $j)] distance] < distance) do={
:set aktywne $j
:set distance [/ip route get [find comment=("wan_monitoring: lacze" . $j)] distance]
}
}
:if ($distance < 255) do={
/ip route enable [find comment=("wan_monitoring: lacze" . $aktywne)]
} else={
:set aktywne 0
}
}
}
:if (($zmiany -> ($i - 1)) = "downup") do={
:set ($"wan_status" -> ($i - 1)) "up"
:if ($"log_tresc" != "") do={
:set $"log_tresc" ($"log_tresc" . ", ")
}
:set $"log_tresc" ($"log_tresc" . "lacze" . $i . " up")
:if ($aktywne = 0) do={
:set aktywne $i
/ip route enable [find comment=("wan_monitoring: lacze" . $i)]
} else={
:if ([/ip route get [find comment=("wan_monitoring: lacze" . $i)] distance] < [/ip route get [find comment=("wan_monitoring: lacze" . $aktywne)] distance]) do={
/ip route disable [find comment=("wan_monitoring: lacze" . $aktywne)]
# czyszczenie wpisow connection tracking
:if ([/interface get ($"lacza_interfejsy" -> ($aktywne - 1)) disabled] = no) do={
/interface disable ($"lacza_interfejsy" -> ($aktywne - 1))
/interface enable ($"lacza_interfejsy" -> ($aktywne - 1))
}
# czyszczenie wpisow connection tracking - koniec
:set aktywne $i
/ip route enable [find comment=("wan_monitoring: lacze" . $i)]
}
}
}
}
if ($"log_tresc" != "") do={
:log error ("wan_monitoring: " . $"log_tresc")
}
} on-error={
:log error "wan_monitoring: blad wykonania skryptu"
}
3. Problem z tablicą Connection Tracking
Na koniec zwróćmy uwagę na fragmenty skryptu następujący po komentarzu „czyszczenie wpisow connection tracking”. O co tutaj chodzi? Historia zaczyna się od tego, że aby udostępnić Internet w sieci lokalnej (z adresacją prywatną), to musimy wykonać NAT wielu adresów lokalnych na jeden adres zewnętrzny przydzielony przez operatora. Ponieważ taki NAT nadpisuje adres źródłowy pakietu, to pakiet nie zawiera dalej już informacji jednoznacznie identyfikującej rzeczywistego nadawcy w naszej sieci. Zatem, aby wiedzieć do kogo skierować dany pakiet przychodzący z Internetu, router z NAT-em utrzymuje tablicę połączeń. W momencie gdy z sieci lokalnej nawiązywane jest nowe połączenie[3], to jest ono rejestrowane w tablicy razem z parametrami opisującymi adres źródłowy (oryginalny i po translacji) i docelowy, protokół i numery portów. Dzięki tym informacjom router przekazuje pakiety przychodzące z Internetu do właściwych hostów, wykonując odwrotną translację.
Sedno problemu tkwi w tym, że podczas zmiany domyślnych tras routingu wpisy w tabeli śledzenia połączeń pozostają bez zmian. Gdy klient wysyła kolejne pakiety będące częścią raz zarejestrowanego połączenia, to router na potrzeby NAT-u korzysta z wcześniej dodanego wpisu tablicy połączeń, nie zwracając uwagi, że przypisany do połączenia adres zewnętrzny uległ zmianie. Zatem router, pomimo że, wysyłając pakiety już na nowe (zapasowe) łącze, będzie wykonywał translację na adres zewnętrzny przydzielony do łącza głównego. Taka komunikacja oczywiście się nie powiedzie.
Dla większości komunikacji problem będzie znikomy, bo nawiązanie nowego połączenia TCP spowoduje dodanie nowego wpisu (z właściwym adresem zewnętrznym) do tablicy. Problem będzie istotny dla protokołów opartych np. o UDP (np. SIP), bo każdy nowy pakiet wysłany przez klienta będzie odświeżał błędny wpis w tablicy śledzenia połączeń. Wtedy czas bezczynności nigdy nie wygaśnie i usługa będzie niedostępna dopóki klient nie wstrzyma się na dłuższy czas od transmisji lub do momentu, gdy zdesperowany administrator zrestartuje router, czyszcząc przy tym tablicę śledzenia połączeń. Problem ten dotyczy także „sposobu prostego”, opisanego wyżej.
Optymalnym rozwiązaniem byłoby przefiltrowanie tablicy połączeń w momencie zmiany łącza i skasowanie nieaktualnych wpisów. Niestety – pomimo że system RouterOS teoretycznie daje taką możliwość, to operacja często kończy się błędem action failed (6). Zgłoszenia błędu na oficjalnym forum nie spotkały ze się specjalnym zainteresowaniem producenta i problem pozostaje nierozwiązany.
W tej sytuacji, skutecznym i prostym (aczkolwiek niezbyt eleganckim) obejściem tego problemu jest wymuszone wyczyszczenie części wpisów z tablicy połączeń poprzez zrestartowanie interfejsu, którym ruch wychodził przed zmianą łącza.
— Bartłomiej Dabiński
Przypisy
[1] Szacunek nie jest poparty badaniami lub statystyką, ale bazuje na doświadczeniu autora z łączami biznesowymi/operatorskimi w różnych regionach Polski. Statystyki dostawców usług, bazujące na zgłoszeniach klientów, mogą istotnie nie doszacować realnej usterkowości, ponieważ czas od wystąpienia usterki do chwili jej zgłoszenia nie jest formalnie zaliczany przez dostawców jako czas usterki. Ponadto, krótkie przerwy często nie są zgłaszane w ogóle, w szczególności gdy klient dysponuje łączem zapasowym.
[2] Zapas jest potrzebny na wykonanie przez router operacji w razie zmiany stanu łącz. Dla większości routerów 10 s. będzie wystarczające, mocno obciążone maszyny mogą potrzebować więcej czasu.
[3] Określenie „połączenie” zostało zastosowane konsekwentnie z nazewnictwem w systemie RouterOS („Connection Tracking”), natomiast jako „połączenia” traktowana jest także komunikacja protokołów bezpołączeniowych jak np. UDP czy ICMP. W takich przypadkach router śledzi strumienie danych i używa czasu wygaśnięcia (w MT parametr konfigurowalny), po którym arbitralnie uznaje, że „połączenie” wygasa.


Bardzo przydatny artykuł. Można by jeszcze w tym przykładzie zaawansowanym dorzucić manipulację routingiem w ten sposób, aby zapasowe łącze traktować jako “krytyczne” i puszczać na nie tylko wybrany ruch, blokując np. Facebooka itp.
To ważne, jeśli zapasowym łączem jest modem 3G, gdzie karta ma wykupiony określony limit transferu, z reguły pomiędzy 1 a 35 GB miesięcznie.
btw. Skoro mowa o MikroTiku, to pozwolę sobie zainteresować czytelników moim artykułem:
http://fajne.it/automatyzacja-backupu-routera-mikrotik.html
Wierzę, że również im się przyda.
fajnie ;-) A może chciałbyś od czasu do czasu coś podrzucić na sekuraka?
Ależ nie ma problemu, natomiast o MikroTiku nie mam póki co już nic w planach.
Głównie planuję kolejne artykuły nt. sieci TOR oraz, nazwijmy to, samoobrony IT – w tym artykule masz wypunktowane, o czym zamierzam pisać w ciągu następnych kilku miesięcy:
http://fajne.it/jak-skutecznie-obronic-swoj-komputer.html
Wszystkie obecne i przyszłe artykuły z ramką na końcu “Ten artykuł jest częścią naszej misji” można bez ograniczeń republikować w dowolnych miejscach, nawet bez linka do Fajne.IT, natomiast bez zmian/skracania i pod warunkiem zamieszczenia ramki z moim biogramem, razem ze zdjęciem i z linkiem do http://tomaszklim.pl/
To nie jest backup, tylko export konfiguracji!
Prawie to samo, a jednak bardzo różne.
Artykuł obszerny, ciekawy i pouczający. Fajnie, że wskazane są też minusy i ograniczenia takiego rozwiązania.
Myśląc jednak poważnie o niezawodności dostępu do Internetu, nie da się jednak uciec od tematu wdrożenia BGP i pozyskania adresacji IPv4, potrzebnej do rozgłoszenia via BGP.
http://lipowski.org/bgp-2/ipv4-lir-ripe-ncc/
Sporo zabawy. Dual Wan ma bardzo dobrze rozwiazany Draytek Vigor. Mozna ustawic dodatkowo wan budget i powiadomienia na mail/sms o awarii lacza. Najlepsze routery.
Draytek jest ok pod warunkiem, że oba łącza mają inną bramę jak masz tego samego dostawcę to wszystko bierze w łeb. Lb nie działa jak należy.
Bardzo dobry artykuł, czekam na więcej wpisów o MT :) Jeśli chodzi o bardziej zaawansowane przełączanie to MikroTik zapewnia mechanizm, który pozwala poradzić sobie bez użycia skryptów: http://wiki.mikrotik.com/wiki/Advanced_Routing_Failover_without_Scripting
+1, jak się zdecyduję na dual home, to wrócę po gotowca, dzięki.
Drobne błędy do przeredagowania
* na pierwszym obrazku wkradła się spacja do “PP PoE”
* na drugim listingu są wydrukowane encje
Może jednak poprawcie błąd ortograficzny w tytule i w tekście: nie “łącz” tylko “łączy”.
Artykuł jest mało przejrzysty, przyjęte założenia są wydumane. W realnym biznesowym świecie operatorzy dostarczają łącza z routerem ze stałym IP po stronie LAN. Kolejny błąd wykorzystanie łącza pewnej francuskiej firmy z uploadem rzędu 512 kb/s lub 1024 kb/s jako łącza zapasowego jest nieporozumieniem do zastosowań biznesowych. Ogólnie artykuł na 3 minus.
Dodam autor, proponuje sporo niepotrzebnej zabawy, która zajmuje sporo cennego czasu admina. Zapytam autora w przypadku, gdy brama ISP odpowiada na pingi a nie działają serwery DNS operatora, albo jest globalna awaria sieci u operatora a brama (gateway) działa? Można oczywiście pingować do serwerów firmy hostingowej, ale firmy hostingowe też mają awarię centrów danych.
Działa fajnie, jeżeli pierwszym łączem jest to z DHCP. A co trzeba zrobić, żeby pierwszym łączem było to z PPPoE? Próbowałem zmienić dystanse w bramach i commenty odpowiednio, ale niestety to nie działa.
Skrypt działa prawidłowo i bardzo sprawnie! POLECAM!!!
A jak wygląda sytuacja przy 2 łączach pppoe ??
Dzień dobry,
w jaki sposób można przerobić w/w skrypt zaawansowany tak, aby po przełączeniu na łącze zapasowe (przy warunku, że jest ono działające) i po powrocie łącza głównego ruch kierowany był wciąż przez zadeklarowany czas (np. 30 min albo 1h) łączem zapasowym?
Oba łącza mam LTE u różnych operatorów. Czasem następuje pogorszenie parametrów sygnału (chwilowe ograniczenie przepustowości) i przy obciążeniu łącza głównego następuje jego wysycenie , co skutkuje przełączeniem na łącze zapasowe (wysokie czasy pingów). Po przełączeniu pasmo łącza głównego staje się nie obciążone, i skrypt szybko znów przełącza na nie routing. Ponownie zostaje ono wysycone, i przełącza na zapasowe, itd…
To teraz mi podpowiedzcie jeszcze jak uzyskać żeby połączenie przychodzące powiedzmy VPN i lub dstnat-owane przychodzące na łącze 2 wyszło przez łącze 2.
Te internety to skomplikowana sprawa ;)
do czyszczenia connetion tracking polecam użyć :
/ip firewall connection remove [find]
Pozdrawiam
U mnie działa od pierwszego “kopa” nie wiem jedynie jak wygląda temat powrotu łącza głównego ,u mnie mimo ze jest łącze główne dostępne ,pozostaje na łączu rezerwowym
Witam, zastosowałem Pana skrypt ale dalej ale działa tylko wtedy gdy podłączę kabel wan bezpośrednio od routera mikrotik. Gdy kabel jest wpięty to cały czas myśli że jest Internet. Czy jest z Panem jakiś kontakt żeby sprawdz ić co jest źle?
Dzięki za artykuł i skrypt.
Proponuję drobną modyfikację, miejsce:
# czyszczenie wpisow connection tracking
:if ([/interface get ($”lacza_interfejsy” -> ($i – 1)) disabled] = no) do={
/interface disable ($”lacza_interfejsy” -> ($i – 1))
/interface enable ($”lacza_interfejsy” -> ($i – 1))
}
# czyszczenie wpisow connection tracking – koniec
zmienić na:
# czyszczenie wpisow connection tracking
:if ([/interface get ($”lacza_interfejsy” -> ($aktywne – 1)) disabled] = no) do={
/ip firewall connection remove [find]
}
# czyszczenie wpisow connection tracking – koniec
wówczas usuniemy zawartość connection tracking bez wł/wył interfejsów.
Super skrypt, działa rewelacyjnie.
Fajnie gdyby była możliwość dodania wpisu który by wysłał meila, że łącze się przełączyło na WAN1 albo WAN2
Głupia sprawa, ale jak dorobić do tego skryptu powiadomienia mailowe, treść wystarczy ta co w logu, ale żeby wyszła na maila.
if ($”log_tresc” != “”) do={
:log error (“wan_monitoring: ” . $”log_tresc”)
}
przed if’em dodajesz sobie linijkę
/tool email send to=myuser@anotherdomain.com subject=”email test” body=”email test” start-tls=yes
lecz wcześniej musisz mieć skonfigurowany email w Routeros. Szczegóły w Wiki Mikrotika Tools/Email :)
Coś nie do końca tak bo wtedy śle komunikat za każdym razem wykonania skryptu, a nie przy zmianie statusu do logów wpisuje tylko zmiany.
ciutke zmieniłem tą linijkę wtedy słał tylko za dużo słał :)
/tool e-mail send from=user@domain.pl server=mail.domain.pl to=user@gmail.com subject=”MikroTik WAN” body=”WAN1 DOWN”
Znalazłem obejście problemu może się komuś przyda, o ile nie macie śmietnika w logach “error”
Wchodzicie System > Logging
zakładka Rules:
topics: error
Action: email
zakładka: Acttion
Nazwa:Dowolna
type: email
Email: maila podać na jakiego wysłać.
Oczywiście wcześniej musicie mieć skonfigurowany email w Tools > Email
Czy ktoś mógłby sprawdzić działanie tego skryptu na nowym firmware?
Miałem go wrzuconego na router i bez żadnej zmiany w skrypcie przestał działać.
Odpalam na RB4011iGS+ i Current Firmware 6.45.9
Message wan_monitoring: blad wykonania skryptu
Witam. Proszę o pomoc w dostosowaniu przełączania połączeń wg 2 sposobu dla 2 WAN o stałym IP, na wersji ROs 7.5 .
Flags: D – DYNAMIC; A – ACTIVE; c, s, y – COPY
Columns: DST-ADDRESS, GATEWAY, DISTANCE
# DST-ADDRESS GATEWAY DISTANCE
0 As 0.0.0.0/0 192.168.0.1 1
DAc 10.10.10.0/24 br_siec_domowa 0
DAc 192.168.0.0/24 WAN1 0
DAc 192.168.2.0/24 WAN2 0
Może nie najtańsze rozwiązanie ale znacznie lepsze od failover to SD-WAN np. Fortigate 60F oraz inne co mają więcej niż jeden port WAN. Osobiście mam tak skonfigurowane dwa łącza które mogę wykorzystywać równocześnie, ustawiać priorytety itd.
Niestety w wersji 7.14 już nie działa. Brak routing-mark.
Znalazłeś może rozwiązanie tego problemu?