Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

Niepokojąca sugestia o błędzie w obsłudze SSL w produktach Apple
Niedawno na blogu Bruce Schneiera znalazł się wpis “Was the iOS SSL Flaw Deliberate?” Zastanawia się w nim, czy poważny błąd dotyczący SSL na pewno pojawił się na skutek pomyłki. Twierdzi, że idealna tylna furtka (backdoor) w oprogramowaniu powinna mieć trzy cechy:
- niskie prawdopodobieństwo wykrycia,
- łatwość wyparcia się jej autorstwa w przypadku ujawnienia,
- małe wymagania odnośnie udziału innych osób w przedsięwzięciu.
Według autora, błąd w obsłudze SSL spełnia te warunki, jeśli założymy iż powstał celowo. Pewna instrukcja w jednym miejscu została wpisana dwukrotnie. Jednak wykonanie pierwszej z nich było opatrzone warunkiem, natomiast druga była bezwarunkowa. Ten fragment kodu zawierał kolejne instrukcje warunkowe, które z powodu wspomnianego błędu już nie były wykonywane i pozwalały na przeprowadzenie ataku na zestawianie szyfrowanego połączenia.
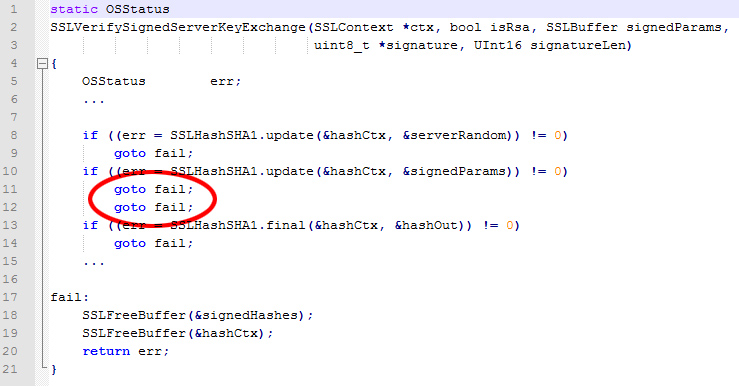
Słynne goto fail;
Pytanie Schneiera musi niepokoić. Łatwo jest się pomylić i wpisać jakąś linijkę dwa razy, szczególnie w dużych i skomplikowanych programach (a nuż ktoś przeklejał kawałek kodu myszką i kliknął dwa razy). Z drugiej strony proste jest również celowe wprowadzenie takiego błędu tak, żeby na tą pomyłkę wyglądał.
Można rozważyć problem od innej strony: czy ktoś mógłby odnieść jakąś korzyść wprowadzając taką wadę do oprogramowania?
Teoretycznie można założyć, że tak – chociażby amerykańska NSA.
Zresztą oprogramowanie Apple’a jest tu tylko przykładem. Łatwo dobrać się do innych systemów i oprogramowania użytkowego, w innych krajach, na korzyść innych osób lub instytucji.
To daje do myślenia. Kto wie, może dawna plotka o osłabieniu obsługi IPSec w systemie OpenBSD miała ziarenko prawdy? Może ktoś przynajmniej próbował zrobić coś takiego?
Zagadnienie do przemyślenia dla paranoików. Powodzenia
–steppe

Tutaj jest nieco lepsza wersja, diff zrobiony z 2 wersji plikow ‘przed’ i ‘po’. Widac wyraznie, ze linijka ‘goto fail;’ zostala dodana swiadomie, kwestia tylko czy miala istniec tylko na czas testow (debug) czy raczej jako przysluga dla kogos ;) Tutaj link: https://gist.github.com/hongrich/9176925
Stawiam na świadomy ‘debug’ i zapominalstwo programisty. Od 7 lat pracuję jako developer i nie takie kwiatki widziałem.
Klasyczna sytuacja, gdy ktoś chce sprawdzić działanie instrukcji występujących PO warunku, ale nie chce mu się doprowadzać do sytuacji, gdy warunek jest spełniony – wtedy robi się taki myk, że zawsze, niezależnie od rezultatu, instrukcja zwraca ‘true’, by zobaczyć, co się dzieje dalej.
Przykład praktyczny:
kod ‘produkcyjny’:
function costam(dane_wejsciowe) {
if (dane_wejsciowe == true) {
return ‘ok’;
} else {
return ‘error’;
}
}
Powiedzmy, że robimy jakąś funkcjonalność, zależną od zwróconego z f-cji costam() rezultatu ‘ok’, ALE aby to uzyskać, musimy spełnić warunek, by ‘dane_wejsciowe’ były równe ‘true’.
Dodajemy sobie więc linijkę:
function costam(dane_wejsciowe) {
/* dodany na sztywno rezultat zwracany przez f-cję, niezalezny od warunku wejsciowego */
return ‘ok’;
if (dane_wejsciowe == true) {
return ‘ok’;
} else {
return ‘error’;
}
}
To powoduje, że f-cja costam() ZAWSZE zwróci nam ‘ok’.
Pracujemy sobie dalej nad naszą funkcjonalnością, po czym commitujemy zmiany. Oczywiście zapominamy usunąć nasze “return ‘ok'”, co powoduje, że aplikacja działa tak, jakby ‘dane_wejsciowe’ zawsze miały wartość ‘true’ w momencie wywołania f-cji costam().
To oczywiście tylko przykład, ale mniej więcej tak to wygląda w praktyce (spróbujcie kiedyś zaimplementować jakąś funkcjonalność w dużej aplikacji, która to funkcjonalność działa w zależności od spełnienia kilku warunków w innych miejscach i ZA KAŻDYM RAZEM być zmuszonym do doprowadzenia aplikacji do takiego stanu, by mógł wykonać się Wasz kod. Szybciutko w waszym kodzie pojawią się takie myki :)
Oczywiście to nie jest zalecany sposób. Można np. próbować mockować dane wejściowe tak, by uzyskać właściwe rezultaty. Ale często gęsto warunki wejściowe zależą np. od odpowiedzi usług zlokalizowanych w zewnętrznych serwisach, do których na przykład nie macie dostępu ze swojej maszyny developerskiej (a przetestowanie jest możliwe jedynie na maszynach mających kontakt ze światem zewnętrznym, np. na serwerach UAT – user acceptance test, czy CIT – continous integration test).
No i co jeszcze bardzo ważne – takie rzeczy powinny wyjść na etapie testów (dlatego właśnie pisanie testów jest tak istotną kwestią, ale jak wiemy, metodologie wytwarzania oprogramowania sobie, a praktyka sobie). Choć to też nie jest regułą, bo testy też mogą być napisane błędnie i nie wychwycić takich niuansów (no bo przecież f-kcja costam() działa ;) )
Jest jeszcze czwarta cecha, data wprowadzenia implementacji tej luki.
Luka wprowadzona została w iOS6: wydano go iOS 6.0 wydano go 24 września 2012, wg. dokumentów od Snowdena, NSA miałaby mieć dostęp do szyfrowanych danych użytkowników iOS od października.
http://daringfireball.net/2014/02/apple_prism
No tak. Na podwójne “wklej” lub kliknięcie myszą to nie wygląda ;)
Trzeba by było kliknąć git – show annotations ;)