Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania

Afera Edwarda Snowdena pokazała, że Internet nie jest już medium, w którym łatwo można dzielić się treścią w sposób anonimowy. Dowiedzmy się, jakie mechanizmy są używane przez Wielkiego Brata – osoby prywatne, firmy czy rząd – aby śledzić aktywność przeglądarek użytkowników Internetu.
Bojąc się technologicznego wykluczenia, coraz chętniej przekazujemy światu coraz więcej informacji o sobie. Z chęcią korzystamy z serwisów społecznościowych, jesteśmy zadowoleni z reklamy behawioralnej dostosowującej się do naszych upodobań, ułatwiamy sobie życie przechowując coraz więcej rzeczy w chmurze. Codziennie zostawiamy za sobą tysiące śladów, które zbierane są przez osoby trzecie i przetwarzane – co napędza mechanizm inwigilacji coraz bardziej i bardziej.
Problem powstaje wtedy, gdy świadomie chcemy zachować anonimowość w Internecie – aby opublikować swoje myśli, które mogą być nieprzychylnie odebrane przez środowisko lub chociażby po to, aby poczuć trochę psychicznego komfortu w globalnej sieci. Jak to zrobić, gdy na każdym kroku patrzy nam się na ręce?
Temat prywatności w Internecie jest niezwykle bogaty. Skupmy się więc na jednym jego aspekcie – na przeglądarce, która jest podstawowym narzędziem każdego internauty. Zastanówmy się, jakie mechanizmy przeglądarek internetowych można użyć, aby profilować zachowania użytkowników w celu ich jednoznacznej identyfikacji między różnymi portalami.
Dowiedzmy się, jak powiązać akcje – wykonane na różnych serwisach, w różnych odstępach czasu – z konkretnym użytkownikiem, który próbuje zachować anonimowość. Wykorzystamy do tego wyłącznie mechanizmy przeglądarek internetowych.

Każde żądanie do serwera oraz otrzymywana z niego odpowiedź posiada adres IP źródła oraz celu – łatwo więc zidentyfikować, pomiędzy którymi węzłami na świecie następuje komunikacja. Adres IP – byt w pewnym sensie unikatowy – można przypisać do konkretnego miejsca na Ziemi. Daje to wrażenie, że adres IP jest idealnym kandydatem do śledzenia poczynań użytkowników – wystarczy przecież powiązać numerki w logach kontrolowanych serwisów, aby wiedzieć, że pod dwoma różnymi tożsamościami ukrywa się ten sam użytkownik.
W większości przypadków adres IP nie jest szczególnie przydatną informacją śledzącą. Owszem – przy odrobinie szczęścia można z jego pomocą poznać przybliżone położenie internauty na mapie świata lub powiązać odwiedziny kilku serwerów z jednym adresem IP. Cóż jednak z tego, jeśli prawdziwy adres IP można łatwo zamaskować, korzystając z web proxy lub węzłów TOR-a. Wtedy ta sama wartość zaczyna wskazywać kilku całkowicie różnych internautów. A to nie jedyny problem.
W związku z tym, że liczba adresów IPv4 jest ograniczona, użytkownicy “ukrywają” swój adres za kolejnymi NAT-ami/PAT-ami, co sprawia, że “unikatowy” adres węzła internetowego przestaje wskazywać na konkretne urządzenie w sieci, identyfikując całe firmy lub osiedla. Reguły gry zmieniają się z IPv6, w którym pula adresów jest na tyle duża, że bez problemu można każdemu urządzeniu przypisać prawdziwie unikatowy adres, jednak ze względu na słabą adaptację nowej wersji standardu wśród ogółu użytkowników, temat śledzenia z wykorzystaniem IPv6 zostanie opisany innym razem.
Kolejnym problemem właściwości śledzących IP jest to, że ostatnimi czasy staliśmy się niezwykle mobilnymi użytkownikami Internetu. Minęły już czasy, w których komputer w salonie był jedynym narzędziem podłączonym do Internetu. Adres sieciowy smartfonu, tabletu czy laptopa ciągle się zmienia w zależności od naszego położenia – co skutecznie utrudnia powiązanie adresu internauty przez osoby trzecie.
Adres IP nie jest więc tak dobrym mechanizmem śledzącym, jak mogłoby się wydawać. Oczywiście adres IP może powiązać akcje konkretnego internauty oraz odkryć jego prawdziwą tożsamość – to jednak trochę inny temat. W kontekście długotrwałego śledzenia przeglądarki użytkownika w sieci adres IP nie może być wprost wykorzystywany jako jedyne źródło danych.
Kolejnym mechanizmem mocno kojarzącym się ze śledzeniem w Internecie są ciasteczka – małe porcje danych zapisywane w przeglądarkach użytkowników, które następnie są automatycznie odsyłane do serwisów. Najczęściej ciasteczka używane są po to, aby obejść problem bezstanowego protokołu HTTP – ciasteczko sesyjne wiąże akcje jednego użytkownika, dzięki czemu może on np. pozostać zalogowany w serwisie.
Ustawienie cookie wykonuje się nie tylko w kontekście odwiedzanej domeny, ale również dowolnie innej. Gdy web aplikacja korzysta z widżetów lub ramek firm trzecich, wtedy serwery “zewnętrznych” domen mogą wystawić swoje ciasteczka w przeglądarce. Dzięki takiemu podejściu po zalogowaniu na konto Facebooka możemy klikać “Lubię to” w kontekście swojego użytkownika na stronach, które nie są w ogóle powiązane z portalem Zuckerberga. Takie ciasteczka pochodzące z “obcych” domen to tzw. “third party cookies”. Third party cookies to najczęściej wykorzystywany mechanizm śledzenia naszego zachowania w Internecie – czy to dla potrzeb deweloperów analizujących swoje strony, czy reklamodawców serwujących przygotowane reklamy kontekstowe i behawioralne.
Zasada śledzenia z wykorzystaniem third party cookies jest bardzo prosta – skrypt lub ramka na stronie A powoduje wysłanie żądania do serwera reklamodawcy R, który odsyła odpowiedź z nagłówkiem Set-Cookie z unikatowym identyfikatorem śledzącym dotyczącym domeny R. Gdy w witrynie B również pojawi się skrypt lub ramka odwołująca się do serwerów reklamodawcy, wtedy przeglądarka doklei do żądania ciasteczko w nagłówku Cookie, co spowoduje, że serwer R powiąże wizytę konkretnego użytkownika na stronach A i B na podstawie wystawionego wcześniej identyfikatora.
Proceder śledzenia użytkowników przez ciasteczka jest ogromny. Trudno znaleźć stronę, która serwuje wyłącznie ciasteczka wspomagające działania samej aplikacji. Popularne strony wystawiają jednorazowo nawet dziesiątki ciastek dla różnych partnerów, co mocno zagraża naszej prywatności. Aby sprawdzić skalę zjawiska, wystarczy podejrzeć listę ciastek ustawionych w przeglądarce – z pewnością są to setki wartości, które pozwalają na profilowanie naszych poczynań w sieci.
Ciekawym projektem pomagającym w pewnym zakresie kontrolować zapisywanie danych przez osoby trzecie jest “Your Online Choices – a guide to online behavioural advertising“. Dzięki tej stronie można poznać firmy, które zbierają o nas informacje. Na stronie Your Online Choices można wypisać się z procederu zbierania danych przez konkretną firmę, która działa w miarę etyczny sposób (udostępniając mechanizm Opt-Out ze swoich kampanii reklamowych). Nie rozwiązuje to jednak problemu śledzenia czy anonimowości – jest to w zasadzie tylko prośba do firm o dobrej renomie, aby nie przetwarzali danych o naszym zachowaniu w sieci.
Super ciasteczka pełnią taką samą funkcję jak ich klasyczne odpowiedniki. To, co je odróżnia, to fakt, że nie są one wystawiane przez strony internetowe, a przez środowisko pluginów przeglądarek.
Najpopularniejszym super ciasteczkiem jest obiekt LSO (Local Shared Object) – odpowiednik webowego ciasteczka w programach flashowych. Takie “super ciasteczko” jest przechowywane całkowicie w innej lokalizacji niż zwykły cookie, więc nie zawsze można je łatwo usunąć. Co gorsza, w odróżnieniu od ciasteczek webowych obiekty LSO nie muszą wygasać automatycznie.
Cała reszta funkcji śledzących może być zaimplementowana w super ciastku dokładnie tak samo, jak w jego webowym odpowiedniku. W związku z tym, że animacje flashowe są często uruchamiane automatycznie na stronach internetowych, możliwość zapisania informacji śledzącej w miejscu, które łatwo przeoczyć podczas czyszczenia przeglądarki, może bardzo ułatwić proces śledzenia internauty.
Wiemy, że identyfikator śledzący łatwo zapisać w ciasteczku webowym i odwoływać się do niego między serwisami. Super ciastko, np. w postaci obiektu LSO, cechuje się większą trwałością, co często jest wykorzystywane do śledzenia użytkowników. Magazyn “ciastek” Flash nie jest jednak jedynym miejscem, gdzie w przeglądarce można zapisać unikatowy identyfikator.
Evercookie jest skryptem, który łączy magazyn ciastek webowych, flashowych, silverlightowych i wielu innych, aby jak najbardziej utrudnić proces niszczenia identyfikatora śledzącego z systemu “zarażonego” użytkownika. O wiecznych ciasteczkach pisaliśmy w artykule opisującym zagrożenia HTML5 – już wtedy mechanizm ten nie był nowością.
Evercookie oprócz zwykłych ciasteczek wykorzystuje również nowe kontenery danych HTML5, obiekty Canvas, znaczniki ETag i wiele innych egzotycznych miejsc, aby zachować w nich wartość konkretnego identyfikatora. Gdy po odwiedzeniu “zarażonej” strony skrypt wykryje, że któryś z używanych przez niego magazynów nie posiada zdefiniowanego identyfikatora, wtedy błyskawicznie zapisze go w tym miejscu, odwołując się do wartości zapisanej w niewyczyszczonej lokalizacji. Aby pozbyć się identyfikatora evercookie trzeba więc za jednym podejściem usunąć go ze wszystkich kontenerów danych – w przeciwnym razie kod śledzący będzie ciągle powracał.
Projekt Evercookie nie jest rozwijany zbyt dynamicznie, jednak od początku swojego istnienia (rok 2010) do dzisiaj działa nadzwyczaj skutecznie. Oczywiście od czasu do czasu implementowany skrypt jest rozszerzany o nowe mechanizmy śledzenia.
Magazyny danych wprowadzonych wraz z technologiami skupionymi wokół HTML5 znacznie ułatwiły śledzenie użytkowników. Na szczęście twórcy przeglądarek coraz chętniej nie tylko dodają nowe funkcje HTML5, ale również pozwalają na łatwiejsze ich kontrolowanie. Jeszcze niedawno usunięcie chociażby super ciastek czy elementów Offline Application Cache bez wykorzystania dodatkowego oprogramowania było niemożliwe. Obecnie coraz więcej śladów można usunąć używając natywnych funkcji przeglądarek.
Aby nie być gołosłownym, poniżej demonstruję opcje usuwania historii w przeglądarce Google Chrome (wersja 38), które jeszcze rok temu nie były tak rozbudowane:
Usuwanie określonych elementów z danych przeglądarki:
- Pliki cookie oraz dane witryn i wtyczek:
- Pliki cookie: pliki zapisywane na komputerze przez strony internetowe, na które wchodzisz. Pliki te zawierają informacje dotyczące użytkownika, takie jak ustawienia witryn i dane profilu.
- Dane witryny: typy magazynowania z włączoną obsługą HTML5, w tym pamięci podręczne aplikacji, dane Web Storage, dane Web SQL Database i dane Indexed Database.
- Dane wtyczek: wszystkie dane zapisywane po stronie klienta przez wtyczki, które korzystają z interfejsu API NPAPI ClearSiteDataI.
Dzięki tak szczegółowym opcjom czyszczenia przeglądarki ataki rodzaju Offline Application Cache Poisoning (o których pisaliśmy w trzeciej części artykułu o zagrożeniach HTML5) czy śledzenie przez różnego rodzaju “ciasteczka” stają się mniej groźne.
Ciasteczka oraz adresy IP są bardzo znanym mechanizmem śledzącym użytkowników. Jednak osoba dbająca o swoją anonimowość z pewnością zadba, aby przed publikacją np. niewygodnych opinii na różnych serwisach zaciemnić swój adres IP oraz usunąć drobne identyfikatory z różnych magazynów danych. Czy dokładne posprzątanie ciasteczek i wykorzystanie proxy wystarczy, aby czuć się całkowicie anonimowym? Niestety nie.
Współczesne przeglądarki internetowe są bardzo skomplikowanymi aplikacjami, rozszerzanymi przez wiele pluginów i dodatków. Odwiedzając strony internetowe, generujemy bardzo duże ilości metadanych wysyłanych bądź odbieranych przez przeglądarki. Dane te mogą posłużyć do zdekonspirowania naszej “anonimowości” albo przyczynić się do naszego śledzenia.
Zdobycie dobrej jakości metadanych, które jednoznacznie skojarzą nasze zachowanie, nie jest łatwe. Jednak korelacja wielu, pozornie nie znaczących danych może spowodować, że anonimowość stanie się tylko złudnym mirażem. Spójrzmy, w którą stronę oko Wielkiego Brata może zostać skierowane, aby z tłumu tysięcy połączeń, rozpoznawać akcje konkretnego użytkownika.
Przeglądarki, wysyłając oraz odbierając dane, przetwarzają ogromną liczbę nagłówków HTTP. Nagłówki to nic innego jak metadane pomagające w wymianie właściwej treści między klientem HTTP a serwerem. W zależności od typu połączenia (klasyczne połączenie, asynchroniczne pobranie AJAX, CORS…), rodzaju przeglądarki oraz systemu operacyjnego i jego kultury – domyślnie wysyłane są różne zestawy oraz wartości nagłówków.
Najpopularniejszymi nagłówkami HTTP automatycznie dodawanymi przez przeglądarki oraz jej dodatki są:
Do identyfikacji należy brać pod uwagę nie tylko rodzaj wysyłanych nagłówków, ale również ich wartości oraz względne położenie względem siebie. Identyfikacja użytkownika może być wykonana również technikami np. pasywnej enumeracji systemu operacyjnego poprzez analizę metadanych warstw niższych, chociażby z pomocy legendarnego narzędzia p0f.
Liczba danych wymienianych przez wszystkie warstwy modelu ISO/OSI przy odwiedzinach stron WWW jest naprawdę spora. Może się okazać, że wśród internautów odwiedzających obserwowane serwisy, konfiguracja naszego systemu oraz przeglądarki będzie na tyle unikatowa, że sama zawartość nagłówków HTTP, TCP czy IP może nas wyróżnić z tłumu.
Współczesne strony internetowe są naszpikowane wieloma technologiami – różnymi wersjami HTML-a czy CSS, setkami bibliotek Javascript, grafikami SVG czy nawet trójwymiarowymi renderami i tak dalej. Nie dziwi również to, że wiele z hucznie wprowadzanych pomysłów nie do końca działa w niektórych przeglądarkach internetowych. Okazuje się, że sama informacja o wsparciu danego mechanizmu może posłużyć jako element rozbudowanego systemu śledzącego.
Test na obsługę ciasteczek oraz skryptów JS jest najprostszym przykładem powyższego konceptu. Oczywiście sama informacja o akceptowaniu cookie oraz możliwości wykonywania skryptów to za mało, by jednoznacznie rozpoznać tożsamość internauty, jednak okazuje się, że nawet tak z pozoru błahe informacje mogą zaszkodzić anonimowości.
Aby sprawdzić obsługę ciasteczek wystarczy odesłać do klienta nagłówek HTTP Set-Cookie i sprawdzić, czy w kolejnym żądaniu przeglądarka odeśle ciasteczko. Obsługę Javascript można sprawdzić, chociażby tworząc kod wysyłający asynchroniczne żądanie do kontrolowanego serwera. Równie łatwo można wykryć wsparcie pluginów – Flasha, Javy, Microsoft ActiveX lub Silverlighta.
Zacznijmy od technologii Microsoftu. Silverlight jest perfekcyjnym przykładem, które obrazuje niebezpieczeństwo pluginów w kontekście śledzenia lub wykrywania tożsamości danego internauty.
Przeanalizujmy poniższy kod, który po kompilacji trafi jako jeden z elementów strony internetowej. Po załadowaniu aplikacji w środowisku pluginu przeglądarki internauty, osoba śledząca może pobrać takie detale o drugiej stronie, jak chociażby typ procesora czy adres MAC karty sieciowej:
var wmiQuery = "SELECT MACAddress FROM Win32_NetworkAdapterConfiguration where IPEnabled=true";
var queryResults = wmiService.ExecQuery(wmiQuery);
foreach (var o in queryResults)
{
MacAddress = o.MACAddress;
break;
}
Podobne niebezpieczeństwo grozi użytkownikom z włączonymi apletami Javy. Załadowany aplet może wysłać niepowołanej osobie takie informacje jak chociażby nazwa, architektura i kultura systemu operacyjnego internauty, szczegóły dotyczące maszyny jego wirtualnej Javy (a samych maszyn jest sporo) czy liczbie dostępnej pamięci w systemie.
Trzeba przyznać, że obecnie trudno jest znaleźć stronę, która zasypuje swoich użytkowników dodatkami w postaci apletów Javy, Silverlighta czy ActiveX, ale dalej często spotyka się aplikacje flashowe. Twórcy przeglądarek zdają sobie sprawę z niebezpieczeństwa, jakie noszą ze sobą pluginy, dlatego standardem staje się kontrolowanie aktualizacji pluginów przez same przeglądarki, dodatkowe potwierdzenia w postaci Click-To-Play itp. Mimo tego obiekty Flash i tak są bardzo często dodawane do kodu stron i z wielką chęcią uruchamiane przez internautów.
Na szczęście Flash nie jest aż tak gadatliwy jak wcześniej opisane technologie. Z jego pomocą niepowołana osoba nie pozna tak szczegółowych informacji jak np. z pomocą Silverlight, jednak i tak dane zebrane przy pomocy tej technologii umożliwiają zbudowanie bardzo skutecznego kodu śledzącego. Jako że Flash jest dalej bardzo popularny, sprawdźmy, co dokładnie może zobaczyć osoba śledząca wykorzystująca tę technologię do identyfikacji użytkowników na swoich stronach.
Podobnie jak w przypadku innych pluginów, łatwo można wykryć, czy plugin Flash jest zainstalowany w przeglądarce czy też nie. Jeśli istnieje, można też określić, czy przeglądarka używa zaślepek Click-To-Play.
Gdy obiekt flashowy zostanie uruchomiony, wtedy prywatność staje się niemalże fikcją. W przypadku komputera, który został użyty do napisania poniższego artykułu, po załadowaniu apletu flash można było dowiedzieć się m.in. o:
Niektóre z tych informacji są bardzo niebezpieczne – w szczególności te dotyczące systemowych fontów oraz ekranu. Obie te informacje często dają możliwość jednoznacznego śledzenia wizyt użytkownika między różnymi portalami – przyjrzymy się tym danym jeszcze w dalszej części artykułu.
HTML5 coraz bardziej wygryza pluginy z Internetu, jednak Flash czy Java jeszcze długo nie zniknie z przeglądarek internautów. Warto jak najszybciej pozbyć się tych technologii, w szczególności, że mogą one stanowić bardzo dobre źródło tworzonego identyfikatora śledzącego.
HTML5 to przede wszystkich zakręcona specyfikacja, rozwijana równolegle przez dwa stowarzyszenia – WHATWG oraz W3C. Implementacja funkcji nowego standardu w przeglądarkach przebiega topornie. Różnice, które powstały przez wszystkie problemy we wsparciu nowych tagów, atrybutów, selektorów czy API, dają kolejną możliwość identyfikacji przeglądarki użytkownika.
Enumeracja funkcji obsługiwanych przez przeglądarkę nie jest niczym nowym – a tym bardziej szokującym. Istnieje wiele frameworków Javascript wykrywających obsługę nowych funkcji, aby np. emulować działanie niewspieranych funkcji w starszych przeglądarkach. Jednym z nich frameworków jest chociażby Modernizr – Javascript library that detects HTML5 and CSS3 features. Dane zwracane przez tego typu narzędzia może nie zagraża bezpośrednio anonimowości, ale z pewnością może być użyte jako element dużo bardziej złożonego procesu śledzenia. W szczególności, gdy okaże się, że śledzona przeglądarka potrafi rysować animacje HTML5 z użyciu płótna oraz grafiki 3D.
Płótno HTML5 – element canvas oraz API javascript do jego kontroli, służy do wyświetlania obrazków, animacji, fontów lub renderów w określonym miejscu strony. W jaki sposób można wyśledzić konkretnego użytkownika, odwołując się do tego elementu?
Aby to zrobić trzeba użyć kilku nietypowych kombinacji i efektów w tworzonej grafice. Celem jest stworzenie w pamięci przeglądarki “płótna” z wykorzystaniem różnych kształtów, fontów i kolorów, aby następnie wyświetlić te informacje na ekranie użytkownika, oczywiście w formie pikseli. W następnym kroku pobiera się bufor takiego obrazu i przekazuje się go na wejście funkcji skrótu kryptograficznego. Wartość wyliczonego skrótu z takich “surowych pikseli” stanie się właśnie identyfikatorem używanym do rozpoznawania konkretnego użytkownika w sieci.
Ale w jaki sposób reprezentacja obiektów graficznych, które ostatecznie zostają wyświetlane na ekranie, ma jednoznacznie identyfikować konkretną instancję przeglądarkę w sieci? Intuicyjnie mogłoby się wydawać, że np. “koło o promieniu x i kolorze y” powinno wyglądać tak samo u każdego internauty.
Niestety okazuje się, że istnieje tak wiele różnic w silnikach przetwarzających obrazki w przeglądarkach, że ostatecznie wyświetlony element płótna na stronie będzie minimalnie się różnił między osobnymi środowiskami. Na powyższe różnice wpływa nie tylko przeglądarka, ale również system operacyjny – przez to wynikowe obrazki różnią się między użytkownikami poziomami kompresji, opcjami wygładzania oraz próbkowania subpikselowego itd….
Problem z użyciem nowych opcji graficznych HTML5 jeszcze bardziej komplikuje się w przeglądarkach wspierających WebGl – czyli obsługę trójwymiarowej grafiki przez webowy odpowiednik biblioteki OpenGL ES. Rendery i trójwymiarowe animacje WebGL mogą być wyświetlane na opisywanym powyżej elemencie canvas.
Tak jak w przypadku dwuwymiarowych rysunków, tak i w przypadku trzeciego wymiaru istnieje problem niejednoznacznego wyświetlania między płótnami. Drobne różnice w sterownikach kart graficznych oraz implementacjach samego WebGL i jego rozszerzeń może pozwolić na pobranie wielu informacji ułatwiających profilowanie konkretnego użytkownika w sieci.
Przykładem są chociażby metody takie jak np. getParameter() , getSupportedExtension() lub getExtension(). Dane (tekstowe) zwracane przez funkcje tego rodzaju mogą wystarczyć, aby stworzyć kod śledzący. Poniższa tabela prezentuje przykładowe informacje zwracane przez podobne metody wchodzące w skład WebGL API. Na pierwszy rzut oka widać, że testy były przeprowadzane na dwóch różnych przeglądarkach:

Dwie przeglądarki – dwie implementacje WebGl – czyli dwóch różnych użytkowników
Kolejną funkcją nowych przeglądarek, która może zagrozić prywatności jest interfejs Geolocation, pozwalający wskazać lokalizację przeglądarki na mapie świata. Celem tego API jest pobranie koordynatorów (latitude, longtitude) urządzenia wykonującego skrypt na stronie. Specyfikacja W3C nie określa, w jaki sposób przeglądarka ma te dane pozyskać – może to zrobić, odpytując czujnik GPS, wykonując triangulację, kojarząc dane z pobliskich sieci WiFi czy szacując pozycję na podstawie samego adresu IP.
Trzeba przyznać, że poznanie dokładnej lokalizacji (na podstawie GPS lub sieci WiFi) teoretycznie mocno zagraża prywatności – niepowołana osoba może poznać np. dokładne miejsce zamieszkanie śledzonego użytkownika. W praktyce geolocation API nie jest często wykorzystywane do śledzenia, ponieważ przeglądarki mocno ograniczają możliwość odpytywania skryptów o tego rodzaju informacje, wyświetlając użytkownikom czytelne komunikaty.
Skuteczność śledzenia tą metodą jest mała, ponieważ użytkownicy, którym zależy na anonimowości raczej nie odpowiedzą twierdząco na prośbę udostępnienie swojej lokalizacji. Reszta internautów, co ciekawe, również niechętnie zgadza się na tego rodzaju prośby, ale i tak ich zgoda zazwyczaj oznaczałaby zwrócenie danych geolokalizacyjnych na podstawie adresu IP. A dane te i tak zazwyczaj można pozyskać bez użycia tego rodzaju mechanizmów.
Pomijając już fakt włączania geolokalizacji w przeglądarkach, długoterminowe śledzenie po współrzędnych urządzenia (nawet mobilnego) nie daje dobrych efektów (o czym już wspominano w kontekście geolokalizacji IP). Pamiętajmy, że rozważamy tutaj rozpoznawanie przeglądarek użytkowników, a nie szpiegowanie ich życia przez poznawanie harmonogramu odwiedzin w hipermarketach. :-)

Przeglądarkę można również zidentyfikować poprzez analizę wysyłanych przez nią nagłówków (w szczególności User-Agent) lub sprawdzając wsparcie konkretnych technologii. Oczywiście dane tj. wartość User Agent są często podmieniane przez internautów, jednak istnieje kilka sztuczek, które i tak pozwalają dowiedzieć się jaki rodzaj przeglądarki został użyty do odwiedzenia konkretnej strony.
Zacznijmy od interpretacji nietypowych schematów. Poniższy kod pozwoli wykryć, czy użytkownik korzysta z przeglądarki Mozilli:
<img src="about:logo" onload="console.log('Firefox detected')" onerror="console.log('Not in Firefox')" alt="Obrazek wyświetli się użytkownikom przeglądarki Firefox" />
Dlaczego powyższy obrazek wyświetli się wyłącznie osobom korzystającym z Firefoxa? Otóż przeglądarka z logiem liska posiada kilka wbudowanych zasobów – np. about:logo zawierający logo przeglądarki. Do tego zasobu można się odnieść jak do zwykłego URL-a, a następnie, posiłkując się nowymi atrybutami HTML5, stworzyć logikę, informującą czy dany obrazek się wczytał czy też nie.
Oczywiście jedna taka informacja nie może zostać użyta w jakimkolwiek mechanizmie śledzącym, jednak w podobny sposób można odnieść się do innych, wbudowanych zasobów. Zmieniając schemat na chrome:// możemy odwoływać się w ciemno do elementów rozszerzeń przeglądarki Firefox – dodatki przecież też zawierają różne style czy obrazki!
Na szczęście od kilku lat nie można przez URI odwoływać się do zasobów dowolnego rozszerzenia. Jest to możliwe tylko wtedy, gdy twórca świadomie na to pozwoli, dodając atrybut contentaccessible w manifeście rozszerzenia (więcej informacji na stronach Mozilli). Takie podejście bardzo utrudnia enumerację dodatków zainstalowanych przez internautów.
Szacuje się, że kilka procent dodatków z całej bazy rozszerzeń pozwala odwoływać się do swoich zasobów. W związku z tym, że baza rozszerzeń Firefoxa jest ogromna i ogólnie dostępna, to bez problemu można pobrać rozszerzenia i przeanalizować występowanie atrybutu contentaccessible. Później wystarczy spisać ścieżki do zasobów i użyć je w celu wykrywania listy zainstalowanych pluginów, dokładnie w ten sam sposób jak pokazano na przykładzie about:logo.
Lista zainstalowanych dodatków w przeglądarce bardzo silnie łączy przeglądarkę do konkretnego użytkownika, więc warto zwracać uwagę, co instalujemy w naszej przeglądarce. Sztuczka zaprezentowana powyżej doczekała się swojej implementacji – addon_scanner bardzo dobrze demonstruje sposób wykrywania dodatków Firefoxa. Podobnej metody można użyć również w stosunku do schematu chrome-extension:// przeglądarki Google Chrome.
Bardziej agresywną formą śledzenia lub deanonimizacji jest próba odwołania się przez przeglądarkę do nietypowych protokołów.
Niektóre oprogramowanie zainstalowane w systemie dodaje rozszerzenia lub pluginy do przeglądarek, aby rozszerzać jej funkcje, np. przez obsługę dodatkowych protokołów w klikalnych elementach strony. Wywołanie takiej akcji powoduje wtedy uruchomienie programu z określonymi parametrami poza przeglądarką. Na szczęście przed wykonaniem takiej akcji przeglądarka z reguły wyświetla komunikat ostrzegawczy, jednak gdy użytkownik często korzysta np. z funkcji łączenia do kanałów ircowych przez linki stron WWW, będzie przyzwyczajony do zatwierdzenia wyboru (lub wcześniej wybierze opcję “Zapamiętaj ten wybór”).
Uruchomienie zewnętrznego programu może być bardzo niebezpieczne, ponieważ przede wszystkim umożliwia to potencjalnemu agresorowi atakowanie kolejnego zasobu. Użycie nowych handlerów jest dużo bardziej przydatne w kontekście jednorazowego wykrycia tożsamości użytkownika (np. ominąć przeglądarkowe proxy i odkrywać adres IP), jednak teoretycznie też może posłużyć jako element mechanizmu śledzenia – głównie gdy zostanie zaznaczona opcja “Zapamiętaj mój wybór”.
Protokołami, które można wykorzystać w tym celu, są np.:
W kontekście obsługi nietypowych protokołów warto też wspomnieć o banalnej technice wykrywania połączenia przeglądarki z siecią TOR. Aby to zrobić, wystarczy pobrać zawartość jakiejkolwiek strony z domeny .onion .
Fonty są kolejnym elementem, który może pomóc w rozpoznaniu przeglądarki konkretnego użytkownika. Kroje pisma dostępne w systemie bardzo precyzyjnie rozróżniają systemy operacyjne – ich rodzinę oraz wersję. Co gorsza są one dodawane nie tylko podczas instalacji systemu operacyjnego, ale również przez inne oprogramowania, a nawet samych użytkowników. Dzięki temu lista fontów precyzyjnie identyfikuje internautę i stanowi obecnie jedno z największych zagrożeń prywatności. Zastanówmy się, w jaki sposób można pozyskać takie dane.
Najprostsza metoda wymaga obsługi pluginów – z ich pomocą wystarczy odwołać się do odpowiednich funkcji i po prostu pobrać listę fontów w systemie. Jest to kolejny argument, który przemawia za tym, aby pozbyć się pluginów (Flash, Java, Silverlight…). Niestety użytkownicy, którzy wyłączyli wszystkie pluginy dalej nie mogą czuć się bezpieczni. Dzięki kilku sztuczkom wykorzystującym HTML, JS oraz CSS istnieje możliwość wykrycia fontów “w ciemno”.
Aby wykryć krój pisma w przeglądarce śledzonego użytkownika, można wykorzystać właściwość font-family w CSS. Właściwość ta definiuje rodzinę – przeglądarka dla wskazanego elementu użyje pierwszy obsługiwany font z listy (patrząc od lewej). W skomplikowanych rodzinach dobrą praktyką jest umieszczenie na końcu listy tzw. generycznych fontów, jak np. monospace.
<span style="font-family: monospace; font-size: 72px">mmmmmmmmmmlli</span> <span style="font-family: New-Font, monospace; font-size: 72px">mmmmmmmmmmlli</span>
Algorytm wykrywania fontów wykorzystuje fakt przeglądania listy przez przeglądarkę i użycia fontów generycznych w przypadku braku wsparcia danego kroju pisma. Aby wykryć wsparcie fontu o znanej z góry nazwie, osoba śledząca może zaimplementować następujący algorytm w skrypcie JS:

Takie podejście, podobnie jak wszystkie wcześniej opisane, również nie jest niczym nowym. Powyższa metoda została opisana już w 2007 roku przez Lalit Patela i do tej pory cechuje się niemal 100% skutecznością wykrywania fontów. W związku z tym, że lista obsługiwanych krojów pisma w systemie jest dość unikatowa, może ona więc stać się swoistym identyfikatorem śledzącym. Znacznym problemem jest to, że ciężko zabezpieczyć się przeciwko takiemu wykrywaniu fontów “w ciemno” – jedynym pewnym lekarstwem okazuje się chyba tylko wyłączenie przetwarzania skryptów JS.
Odnosząc się do badań organizacji EFF (do których jeszcze wrócimy pod koniec artykułu), warto jeszcze nadmienić, że choć same fonty niosą ze sobą potężną dawkę informacji identyfikujących – to nie wolno polegać na ich wzajemnej pozycji względem siebie (po pobraniu kompletnej listy z systemu). Chociaż podczas enumeracji w ciemno z CSS oraz JS elementy na liście będą pojawiać się w tej samej kolejności, to już nie będzie tak w przypadku Flasha, Javy czy Silverlighta. Gotową listę trzeba posortować i dopiero wtedy zapamiętać, ponieważ okazuje się, że systemy operacyjne mają tendencję do zmiany kolejności zwracanych fontów (z wielu powodów – chociażby po instalacji oprogramowania, nowych aktualizacjach itp.).
Nie jest zaskoczeniem, że działanie kodu Javascript może nie tylko znacznie zwiększyć użyteczność odwiedzanej strony, ale również zagrozić anonimowości – pokazaliśmy to już w wielu przykładach opisanych wcześniej. Wiemy też, że język Javascript może pomóc w enumeracji użytkowników poprzez ciastka, fonty, ładowanie pluginów przeglądarek, wysyłanie informacji o sterowniku przetwarzającym obraz 3D…
Im dalej w las, tym więcej drzew. Poznajmy, w jaki jeszcze sposób można wykorzystać JS, aby skutecznie pobrać zestawy danych identyfikujących internautów odróżniających się od siebie.
Ciekawym sposobem rozpoznawania przeglądarki danego użytkownika jest sprawdzenie wydajności przetwarzania skryptów. Aby zacząć zabawę w enumerację przeglądarek tą metodą, wystarczy przejrzeć kilka benchmarków popularnych silników (V8, SpiderMonkey, SquirrelFish, JScript, Rhino…) i zaimplementować w logice kodu śledzącego wyniki testów wydajności.
Różnice w wykonywaniu funkcji JS są w przeglądarkach na tyle duże, że po paru testach można wyciągnąć wnioski na temat twórcy przeglądarki, a czasem nawet o jej przybliżonej wersji. Oprócz wersji oprogramowania metoda ta daje teoretycznie też okazję to rozpoznania konkretnego użytkownika – ponieważ w zależności od konfiguracji systemu oraz samego sprzętu – czasy wykonania testów zaczną się różnić.
Metoda ta, chociaż ciekawa, nie jest zbyt często wykorzystywana ze względu na swoją niestabilność – w zależności od obciążenia systemu testy będą wykonywane w różnym czasie, co udaremni przypisanie konkretnego przedziału wyników do danego użytkownika.
Metoda zwracająca informacje o strefie czasowej przeglądarki pozwala poznać w przybliżeniu miejsce pobytu danego użytkownika. Wystarczy stworzyć nowy obiekt Date i odczytać różnicę czasu w strefie czasowej systemu użytkownika:
var d = new Date(); var zone = d.getTimezoneOffset();
Takie dane są o wiele gorsze niż chociażby geolokalizacja adresu IP, ale i tak jest to pewna ciekawa informacja identyfikująca, która często trafia jako jeden z trybików do machiny śledzącej, więc warto o niej pamiętać.
Bardzo groźne są również informacje zwracające dane o wielkości okna przeglądarki i głębi palety barw. Zobaczmy jakie właściwości zawiera obiekt screen w przeglądarce Google Chrome:
{
"orientation":{
"onchange":null,
"type":"landscape-primary",
"angle":0
},
"availWidth":1920,
"availHeight":1178,
"availTop":22,
"availLeft":0,
"pixelDepth":24,
"colorDepth":24,
"width":1920,
"height":1200
}
oraz Mozilla Firefox:
{
"availHeight":1178,
"availLeft":0,
"availTop":22,
"availWidth":1920,
"colorDepth":24,
"height":1200
"left":0,
"mozOrientation":"landscape-primary",
"onmozorientationchange":null,
"pixelDepth":24,
"top":0,
"width":1920
}
Pierwsze, co rzuca się w oczy, to różnice między implementacjami tego samego obiektu w różnych przeglądarkach. Już sam ten fakt może być pewnym elementem śledzącym. Przyjrzyjmy się dokładniej właściwościom ekranu widzianego z perspektywy javascript.
Po pierwsze możemy poznać rozdzielczość ekranu użytkownika. Iym bardziej nietypowa rozdzielczość, tym większy problem dla prywatności. W powyższym przykładzie rozdzielczość 1920×1200 może okazać się na tyle nietypowa, że tylko z pomocą tej jednej właściwości będzie można skutecznie śledzić poczynania danego użytkownika w różnych serwisach kontrolowanych przez osobę śledzącą.
Ciekawe wnioski można również uzyskać korelując wartości par właściwości Height-availHeight oraz Width-availWidth. Różnica tych elementów daje informacje o szerokości oraz wysokości paska systemowego – to kolejna, bardzo silna informacja mocno wyróżniająca niektórych użytkowników:
W związku z tym, że użytkownicy systemów Linux mocno ingerują w wygląd swoich systemów, wartości te pozwalają czasem jednoznacznie ich zidentyfikować. Podobnie jest zresztą w systemach OS X, gdzie oprócz górnego paska menu użytkownicy często dostrajają pozycję oraz wielkość docka – a to ułatwia ich identyfikację z poziomu javascriptowego obiektu Screen .
W kontekście rozdzielczości i rozmiarów okna przeglądarki nie sposób zapomnieć o innerHeight oraz innerWidth stanowiących część obiektu window:
var w = window.innerHeight; var h = window.innerWidth;
Dwie powyższe właściwości przechowują informacje o aktualnym rozmiarze strony przeglądarki – konkretnie obszaru, w którym renderowana jest strona (czyli bez pasków przeglądarki, zakładek itp.). Sprawdźmy, jak można wykorzystać te dane, aby stworzyć prosty mechanizm śledzenia.
Załóżmy, że pewien użytkownik włącza przeglądarkę, wchodzi na pewną stronę pod kontrolą podmiotów śledzących (A) i wykonuje na niej pewne akcje. Następnie odchodzi od komputera (lub usypia maszynę wirtualną, w której używa dedykowanej przeglądarki – opcja paranoiczna). Następnie po kilku godzinach (lub w przypadku maszyny wirtualnej nawet dniach czy tygodniach) ponownie używa przeglądarki, aby wykonać całkowicie osobną akcję na innej stronie (B) (używając innej tożsamości), jednak zostawiając okno przeglądarki bez zmian.
Niech na stronach A oraz B osoba śledząca umieści następujący fragment JS:
var resolutionTracingCodeArray = [ window.screen.height, window.screen.width, window.screen.availHeight, window.screen.availWidth, window.innerHeight, window.innerWidth, window.screenLeft, window.screenTop ]; var resolutionTracingCode = CryptoJS.MD5(resolutionTracingCodeArray.join()).toString()
Powyższy skrypt szybko powiąże obie wizyty opisywanego internauty. Gdy np. na stronie B wykona ona akcje wiążące go z jego prawdziwą tożsamością (zakupy, logowanie do skrzynki pocztowej w formacie imie.nazwisko@domena itp.), wtedy akcje wykonane nawet kilka dni wcześniej na stronie A nie będą już anonimowe. Na obu stronach zostanie bowiem wygenerowany kod śledzący, który zostanie potem wysłany do serwera śledzącego:
Gdy okno przeglądarki nie zostanie zmienione (jego wielkość, pozycja), wtedy na stronie B wartość kodu śledzącego będzie taka sama, jednoznacznie korelując akcje użytkownika między różnymi sesjami i tożsamościami.
Poznaliśmy właśnie kilka podstawowych technik, które pozwalają oku Wielkiego Brata jednoznacznie rozpoznać nas w tłumie.
Identyfikator śledzący, który może zostać nam przypisany, jest zlepkiem wielu błahych, pozornie niezagrażających prywatności informacji. Stworzenie dobrego mechanizmu śledzącego na szczęście nie jest proste – podmioty śledzące muszą mocno zbilansować dwa zagadnienia:
W pierwszym przypadku po prostu nie ma sensu śledzić np. “użytkownika przeglądarki Firefox na ekranach w rozdzielczości 1920 x 1080 px”. Z drugiej strony same przeglądarki (oraz nawyki użytkowników) szybko się zmieniają – po aktualizacji oprogramowania nagłówki zwracają inne wartości, doinstalowane są nowe dodatki, a użytkownicy dbający o swoje bezpieczeństwo regularne czyszczą historię lub aktualizują reguły NoScript lub Ghostery.
Efektywne śledzenie internautów z użyciem ich własnych przeglądarek jest więc niemałym wyzwaniem, ale widać, że odpowiednio zmotywowana osoba może skutecznie powiązać ze sobą dane zbierane z kilku stron i użyć je do wyłuskania zachowań konkretnego użytkownika (lub odkryć jego tożsamość, co może być nawet groźniejsze niż możliwość jego śledzenia).
Electronic Frontier Foundation (EFF) jest organizacją non-profit, która obrała sobie za cel zwiększanie bezpieczeństwa w Internecie, głównie w kontekście anonimowości oraz egzekwowania prawa wolności słowa. Jednym z jej projektów jest Panopticlick – narzędzie do sprawdzania unikatowości przeglądarki, na podstawie którego badano skuteczność różnych metod śledzenia.
Aby sprawdzić, jakie informacje w przeglądarce mogą posłużyć do zidentyfikowania nas, wystarczy odwiedzić stronę projektu (obecnie wymagane jest włączenie obsługi javascript do działania):
Po kilku sekundach narzędzie wyświetli informacje, które mogłyby posłużyć podmiotom trzecim do zbudowania kodu śledzącego. Panopticlick pokazuje:
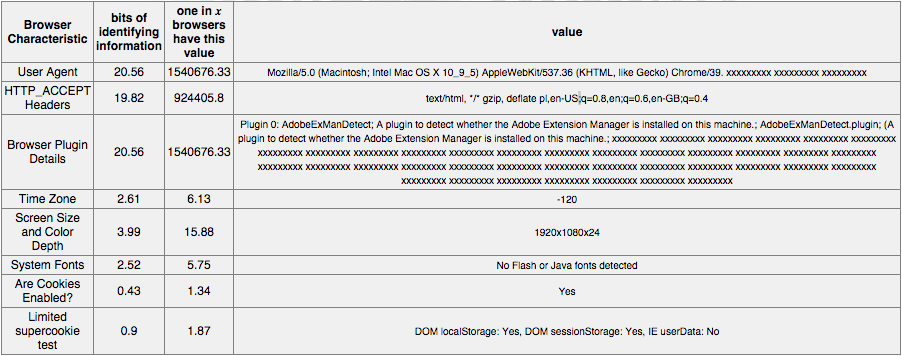
Przykładowy wynik działania narzędzia Panopticlick – testowana przeglądarka może być śledzona z bardzo dużą efektywnością
Powyższy rysunek pokazuje, jak mocno przeglądarki mogę się od siebie różnić. W trakcie pisania artykułu w bazie EFF znajdowało się niemal 5 milionów charakterystyk. Odcisk identyfikujący przeglądarkę używaną podczas pisania artykułu niósł ze sobą grubo powyżej 22 bitów informacji (entropii), co z powodzeniem mogłoby jednoznacznie wyróżnić tą konkretną przeglądarkę z tłumu. W większości przykładów pobranie samej wartości User Agent, nagłówka http-accept lub listy wykrytych pluginów Chrome pozwoliłoby jednoznacznie rozpoznać tę przeglądarkę na dowolnej stronie, która zbierałaby takie informacje.
Trzeba pamiętać, że mało znaczące (czyli popularne) wartości charakterystyk jak np. strefa czasowa, rozmiar ekranu, wsparcie pluginów, przy odrobienie (nie)szczęścia, mogłyby również posłużyć do powiązania przeglądarki między portalami – jeśli tylko nie byłyby one odwiedzane przez wiele osób.
Badania EFF wykorzystujące narzędzie Panopticlick potwierdziły jak niezwykle trudno być anonimowym użytkownikiem internetu. W czasie badań okazało się, że aż 84% pobranych konfiguracji nosiło znamiona unikatowości. Gdy pluginy Flash oraz Java były włączone, wtedy współczynnik ten wyniósł aż 94%! A to wszystko dzięki wykorzystaniu tylko kilku podstawowych technik śledzenia!
Szczegółowe dane dotyczące badań Electronic Frontier Foundation zostały opisane przez samą organizację w artykule “How Unique Is Your Browser?” – jest to bardzo dobry tekst uzupełniający temat poruszany w tym artykule (w szczególności, że jest on często przytaczany w dyskusjach dotyczących prywatności w Internecie, więc tym bardziej warto się z nim zapoznać).
Wyniki prezentowane przez powyższe narzędzie są niezwykle cenne i można na nich polegać podczas budowania bezpieczniejszego ekosystemu przeglądarki. W uproszczeniu można założyć, że jeśli wynik odcisku danych zebranych przez Panopticlick posiada ponad 22 bity entropii, wtedy przeglądarkę w danym środowisku będzie można uznać za unikatową. W takim wypadku istnieje duże zagrożenie wiązania akcji internauty między serwisami.
Pakiet Tor Browser to praktycznie synonim anonimowego surfowania po Internecie. Nic dziwnego – twórcy pakietu wiele energii wkładają w to, aby sieć TOR wraz ze specjalną przeglądarką skutecznie utrudniały powiązania użytkowników do treści, które publikują.
Tor Browser nie tylko ukrywa adres IP, dzięki połączeniu z siecią TOR. Przeglądarka ta posiada też odpowiednio skonfigurowane dodatki oraz niskopoziomowe łatki do kodu Mozilli, które chronią przed wieloma metodami śledzenia opisanymi w tym artykule. Techniki zwiększające anonimowość Tor Browser to m.in.:
Widać, że bez niskopoziomowych zmian w kodzie przeglądarek i ich szczegółowej konfiguracji, nie sposób zapewnić wysokiego poziomu anonimowości. Przyjrzyjmy się, jak wygląda test dwóch różnych instancji Tor Browsera w narzędziu Panopticlick. Poniższy test pokazuje dane Tor Browserów uruchomionych w dwóch, całkowicie odmiennych środowiskach (systemach operacyjnych):
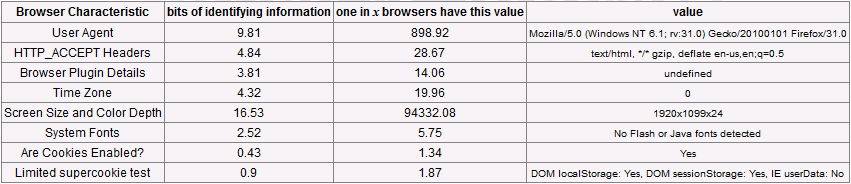
Tor Browser – wersja 4.x uruchomiona na środowisku A

Tor Browser – wersja 3.x uruchomiona na środowisku B
Na pierwszy rzut oka można przypuszczać, że przeglądarka Tor Browser wcale nie jest taka unikatowa, jakby mogło się wydawać! Bo dokładniejszej analizie na szczęście okazuje się, że wyniki nie są złe – jedynymi wartościami, które różnią się między testowanymi instancjami przeglądarek są wartości User Agent (która zmienia się wraz z większymi aktualizacjami Tor Browser) oraz… rozmiar ekranu.
Nagłówek User Agent oraz inne właściwości mimo dość dużej wartości zwracanej przez narzędzie Panopticlick, nie powinny zagrozić anonimowości. Osoba śledząca dzięki temu nagłówkowi oczywiście szybko wykryje, że monitoruje osobę używającą sieci Tor – jednak przeglądarka ta używana jest codzienne przez tysiące innych użytkowników, więc w praktyce nie można powiązać ich akcji ze sobą.
Realne zagrożenie może niestety stanowić wartość raportowana przez obiekt Screen. Uruchomienie przeglądarek w dwóch systemach spowodowało ustawienie mocno unikatowej wielkości okna – dlatego też zaleca się, aby pracować na zmaksymalizowanym ekranie przeglądarki lub często zmieniać jej położenie.
(Sprawne oko może wykryć jeszcze na powyższych zrzutach ekranowych różnicę w fontach oraz palecie kolorów między systemami :-) ).
Potrzeba bardzo dużo energii, aby zapewnić sobie wysoki poziom anonimowości w Internecie. Oto kilka podstawowych rad, które pomogą utrudnić życie internetowym narzędziom (organizacjom? firmom? osobom?) śledzącym.
Nie próbuj “anonimizować” się na siłę – wtapiaj się w tłum. Ustawienie pustej lub nietypowej wartości User Agent może przynieść więcej złego, niż dobrego (ile osób używa pustego nagłówka?). Popularne konfiguracje utrudnią przypisanie Ci unikatowego identyfikatora.
Gdy bardzo zależy Ci na tym, aby nie umożliwiać śledzenia swoich poczynań w sieci, warto zastanowić się nad wyłączeniem tzw. third-party cookies. Osobom, które nie są silnie zinformatyzowane, warto podsyłać dokument polskiej fundacji Panoptykom pt. “Świadomy ciasteczkowicz“, który pokazuje, jak ważne jest kontrolowanie ciasteczek w swojej przeglądarce. Warto też odwiedzić stronę “Your Online Choices – a guide to online behavioural advertising” oraz stronę ustawień Flash Playera.
Kolejny etap, który pomoże chronić nas w sieci dotyczy instalacji pluginów do blokowania reklam, skryptów śledzących oraz ciasteczek (wraz z ich bardziej wrednymi odmianami). Szczególnie warte polecenia są dodatki Adblock, Ghostery (o którym pisaliśmy też wcześniej) oraz Better Privacy.
Można również zastosować kilka z poniższych rad, jeśli chcemy podejść do ochrony przed śledzeniem w bardziej “paranoiczny” sposób:
Niestety powyższe rady mocno ingerują w wygodę używania przeglądarki.

To niesamowite, ile informacji można pozyskać o każdym z nas, po prostu wyciągając je z naszej przeglądarki. Patrząc na wielość sposobów, które mogą zostać użyte, aby śledzić nasze poczynania w sieci, można odnieść wrażenie, że przeglądarki internetowe zostały stworzone tylko po to, aby pogłębiać orwellowską wizję świata.
Całkowita prywatność to w zasadzie fikcja – mówi się, że dopiero śmierć jest w stanie uwolnić nas od inwigilacji. Korzystając z Internetu, oddajmy po prostu część swojej prywatności – czasem mniejszą, czasem większą – ale może po prostu trzeba się z tym pogodzić?
– Adrian “Vizzdoom” Michalczyk dla serwisu Sekurak.pl

Niedawno trafiłem na sekurak’a i jestem pod wrażeniem profesjonalizmu i poziomu artykułów. Nie tylko idzie dowiedzieć się suchej teorii ale i wiele rzeczy poznać w praktyce. Jako wieloletni czytelnik Niebezpiecznika, muszę stwierdzić, że teraz wypada przy was jak IT Pudelek. Tak trzymać!
Niebezpiecznik to taki SuperEkspress albo Fakt na temat IT. Takie wannabe security sprawiajace wrazenie raczej paranoid security. teraz sie chlopcy schowali za cloudflare i puszczaja tylko ruch z polski. czekaja pewnie co sie stanie z GHOSTem.
Sekurak i zaufana trzecia strona to najlepsze strony o bezpieczeństwie. Niebezpiecznik tez jest OK, ale skierowany raczej dla szerszej publiki
“puszczaja tylko ruch z polski” – ciekawe, bo tego nie zauważyłem…
Akurat nie zadziałało, ale i tak to jedna z prostszych do uzyskania informacji. :/
P.S.
“cztery” mi się nie mieści do waszego równania
Trzeba vizzdooma wywołać do tablicy.
A antispam – przetrenujemy inną wtyczkę bo ta zaczyna ogólnie być zawodna (przepuszcza do moderacji sporo auto-spammerów)
Hey – podrzuć trochę więcej info, o który fragment Ci chodzi, bo tekst jest długi i nie wiem jak Ci pomóc :-)
>przeglądaj strony na zmaksymalizowanym ekranie, a gdy używasz niepopularnych rozdzielczości – postaraj się często zmieniać rozmiar i położenie okna przeglądarki.
Moim zdaniem, jeżeli używa się niepopularniej rozdzielczości to lepiej jest wymusić wielkość okna przeglądarki.
W KDE robi się to dość łatwo (Window rules), w innych uniksowych środowiskach/wm też nie powinno być z tym problemu.
Tymczasem panopticlick.eff.org klęknęło i nie odpowiada…
Dobrze, że przypomnieliście mi o tym Evercookie ;->
Z Flash Playera można zrezygnować używając przeglądarki Firefox. Domyślnie ma zainstalowaną wtyczkę “OpenH264 Video Codec”, która zastępuje Flasha.
Problem jest z Javą, po wyłączeniu nie zalogujesz się do banku, na konto mailowe itd. Masz jakiś pomysł “Vizzdoom” jak to obejść.
Przy okazji nie rezygnując z bankowości online, wirtualnej poczty.
Nie myl Java i JavaScript. Nie wierzę, że Twój bank wymaga Javy aby się zalogować do systemu transakcyjnego.
JavaScript możesz włączać/wyłączać selektywnie używająć NoScript.
Niektóre wymagają ;)
Np SGB wersja korporacyjna ;)
Platformy biur maklerskich oparte o oprogramowanie Sidoma
Java dość mocno wżarła się nasze życie i trudno ją wyplenić. Trzeba by mieć osobne maszyny wirtualne do różnych czynności.
Mail i Java – bardzo kiepski pomysł. Forwarduj sobie maile np. na gmaila, albo po prostu używaj programu pocztowego.
Wiem, że niektóra bankowość używa jeszcze Javy – ale chyba po prostu warto poważnie rozważyć przejście do konkurencji. Jeśli po tylu latach bank jeszcze się nie obudził w dobie HTML5 i urządzeń mobilnych – to może nie warto z nim współpracować?
“Forwarduj sobie maile np. na gmaila(…)”
Srsly ? To brzmi trochę jak info o dziurawym TrueCrypt’cie, które kazało ludziom migrować na BitLockera ^__^
“Forwarduj sobie maile np. na gmaila” rewelacyjny pomysl, bedziesz anonimowy jak cholera.
Hoho, no z rozpędu to ładnie dowaliłem tym gmailem :P Najwidoczniej Java w przeglądarce na tyle mnie wystraszyła, że miałem chwilowe zaćmienie.
Ale w sumie to już wolę korzystać z gmaila i oddać część prywatności, niż mieć włączoną obsługę apletów Javy :P
Oczywiście jednym z rozwiązań jest forward maili na swój prywatny serwer pocztowy postawiony na QubeOS. Przed nim postaw proxy na Debianie (lub innym popularnym systemie) z IPSem. Nie zapomnij o szyfrowaniu.
Tak serio — zmień firmę — albo poczekaj, aż ona zmieni technologię. Jeśli faktycznie wymagana jest Java — to już niedługo ;)
JavaScript – Mea Culpa. Można czymś zastąpić JS ?
Konto mailowe na np: yahoo, przy wyłączonym JS jest problem z szyfrowaniem, ot taka ciekawostka.
Tak się jeszcze zastanawiam czy przy włączonym JS można przechwycić sesję szyfrowaną TLS 1.2
Zainstaluj noscript i ustal regule wyjątku dla yahoo.
Muszę Cię zmartwić, ale JS nie da się “zastąpić”, bo jest to integralny mechanizm (tzn. silnik JavaScriptu jest, nie sam język) każdej przeglądarki (obok silnika renderującego, odpowiedzialnego za wyświetlenie strony zgonie ze źródłem HTML oraz informacjami o stylach w CSS).
JavaScript to tylko język programowania, służący do tworzenia interakcji użytkownika ze stroną. Sam język jako taki jest bezpieczny, problemem są różne API, które możesz oprogramować za pomocą JS-a oraz fakt, że masz dostęp do wielu informacji o przeglądarce (poprzez np. obiekty window, navigator, document itd.).
Jeśli interesują Cię detale techniczne, jak działają przglądarki – zapraszam do mojego artykułu na ten temat tutaj na Sekuraku:
http://sekurak.pl/jak-dzialaja-wspolczesne-przegladarki-internetowe/
Jeśli będziesz miał jeszcze jakieś pytania – wal śmiało w komentarzach :)
jak masz konto na yahoo to sie nie martw szyfrowaniem, nsa robi to za ciebie
a gdzie do logowania potrzebna jest java?
Niedawno obejrzałem prezentację z DEFCON21, w której pokazana została metoda identyfikacji silnika przeglądarki na podstawie reakcji na fałszywe kody http.
http://c22.cc/POC/fingerprint.html
Polecam także całą prezentację, ponieważ jest naprawdę ciekawa i humorystyczna ;)
http://youtu.be/I3pNLB3Cq24
Dorzuciłbym jeszcze ten tekst popełniony przez Artura Janca i lcamtufa (Michała Zalewskiego):
http://www.chromium.org/Home/chromium-security/client-identification-mechanisms
Oh, nie trafiłem na to opracowanie wcześniej – jest świetne.
lcamtuf miał link na swoim blogu parę miesięcy temu, warto śledzić jego i innych googlowców z zrh, zawsze się dowiesz czegoś nowego i zawsze wysoki poziom
Wypadałoby poprawić url do panopticlick.
Aktualnie jest taki: https://panopticlick.eff.org/index.php?action=log&js=yes
Przy wyłączonym js test nie odpali.
Za usuwanie moich komentarzy, nagradzam was delejtem z zakładek i RSSa. Bye.
może Cię auto-spamfilter wyłapał? ;)
PS
Twoja strata :-P
Powinniście dawać ostrzeżenie “uwaga długi tekst”, bo wczoraj o 23 czytam i czytam i czytam…przysypiam i czytam… a ja nawet do połowy nie dojechałem!
Brawa dla autora że tak dogłębnie zapodał temat :)
Haha, spoko – następnym razem będzie w częściach ;)
Nieeeee – ten tekst jest zdecydowanie za krótki na szatkowanie i ma wszystkie potrzebne informacje w jednym miejscu. Szatkowanie tekstów to słaby pomysł. Pamiętajcie, że naprawdę wielu czytelników nie ma problemów z czytaniem.
Może za to rozwiązaniem byłoby porobienie wewnętrznych “kotwic” i mini spis treści na górze artykułu?
Nieeee. Nie tnijcie tego :) Sam czytałem na raty, ale temat jest spójny. Szkoda ciąć :)
“Zmieniając schemat na chrome:// możemy odwoływać się w ciemno do elementów rozszerzeń przeglądarki Firefox”
A nie przypadkiem WebKit? :)
Biję się w piersi – nie doczytałem do końca.
Skąd jednak wziął się schemat chrome:// w FF?
https://developer.mozilla.org/en-US/docs/Glossary/Chrome
W TorBrowserze test na stronie https://panopticlick.eff.org/ wychodzi zupełnie inny przy wyłączonym javascripcie w ustawieniach firefoxa.
Sama wtyczka noscript gó… daje.
No, warta zapamiętania uwaga ;)
Warto też wspomnieć o fajnej technice niedawno opisanej w dziale “W biegu”: http://sekurak.pl/jak-w-javascript-poznac-publiczny-oraz-prywatny-adres-ip/
Świetny artykuł !!111
“at least 22.25 bits of identifying information.” To dużo czy mało? :)
Świetny artykuł.
W ogóle dzisiaj coś mnie podkusiło i zwróciłem uwagę na wewnętrzną przeglądarkę aplikacji Facebook pod iOS. Korzysta z cookies i pamięta ustawione. Teraz problem: jak je wyczyścić? Nie znalazłem żadnej takiej opcji w aplikacji. Cache też jest nie do wyczyszczenia. Ponoć są jakieś tam programy na PC, które mogą to zrobić, ale nie zawsze użytkownik siedzi przy komputerze. Odinstalowałem aplikację, zainstalowałem, cookie nadal były zapisane jeśli się nie mylę. Czyli Facebook ułatwia innym śledzenie zgodnie z przyjętą zasadą, że my jesteśmy towarem, a klientami Fb są dostawcy reklam.
Ok, skoro nie da się czyścić ciasteczek, to postanowiłem sprawdzić dalej. Jak duży jest teraz problem śledzenia? Przejrzałem pewną liczbę stron w sieci i kontrolowałem czas ważności ciasteczek. Za każdym razem wpisywałem wynik na Twitterze pod hashtagiem #CookieBandits . Wynik: czasem jest bardzo źle. Rekordzistą została strona firmy D-Link. Założyła mi kilka ciastek z ważnością do 2065. Zapytałem na Twitterze, czy śledzą użytkowników aż do ich śmierci, ale nie odpowiadają. Dość często spotyka się ustawianie na 10 lat…
Z dodatków mogę za to polecić “Vanilla Cookie Manager” do Chromium/Chrome – pozwala ustawić czas po jakim usuwa ciastka, jeśli nie są na białej liście (jest biała lista, jest :) ).
Co do sprawdzania i pisania jako #CookieBandits: może ktoś jeszcze zechce? Samemu trochę długo schodzi ;)
Paranoia mode → activated ;)