Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej

Dzisiaj wchodzimy poziom wyżej. Zobaczysz, jak działają funkcje, poznasz w końcu, co to jest ten stos, no i będzie standardowo mała robota do pyknięcia. Rozpoczynamy od rozwiązania zadania z lekcji 2.
Zadanie rozpoczynasz od linii +28:
<+28>: li v0, 1
<+32>: sw v0, 24(s8)
<+36>: b 0x400404 <main+116>
Ładujemy sobie do rejestru $v0 wartość 1. Naszą jedynkę wrzucamy do pamięci pod adres rejestru “s8” + offset 24 („sw v0, 24(s8)”), a następnie skaczemy pod adres 0x400404 (linia +116), gdzie znajduje się taki oto kod:
<+116>: lw v0, 24(s8)
<+120>: slti v0, v0, 5
<+124>: bnez v0, 0x4003bc <main+44>
Instrukcja „slti” (set on less than immediate (signed)) odnosi się do typów „integer” i działa w ten sposób, że jeśli wartość rejestru $v0 jest mniejsza od 5 to następuje zmiana wartości rejestru $v0 na liczbę 1. W przeciwnym przypadku rejestr $v0 będzie zaktualizowany do wartości 0. Kiedy w rejestrze $v0 znajdzie się wartość 1 to nastąpi skok pod adres 0x4003bc (linia +44). Będzie to możliwe za pomocą kolejnej instrukcji „bnez”. Więcej przykładów tych obu instrukcji znajdziesz w drugiej lekcji.
Rozpocznijmy sobie konstruowanie naszego pseudokodu (kod ten oparty jest na informacjach, które na tą chwilę mamy):
int cnt = 1; // niech nasza zmienna nazywa się „cnt”
while( cnt <= 4 )
{
// tutaj coś się będzie działo
}
return 0;
Lećmy dalej. Co się znajduje pod adresem 0x4003bc i dalej? Zobaczmy:
<+44>: lw v1, 24(s8)
<+48>: li v0, 3
<+52>: bne v1, v0, 0x4003d8 <main+72>
<+56>: nop
<+60>: move v0, zero
<+64>: b 0x400418 <main+136>
Kolejny warunek. Do rejestru $v1 wrzucamy wartość 1 (naszą zmienna „cnt” – linia +52) a następnie porównujemy ją z liczbą 3. Gdy „cnt” będzie równa liczbie 3, nastąpi skok pod adres 0x400418 i tym samym program zakończy działanie. Zaktualizujmy nasz pseudokod:
int cnt = 1; // niech nasza zmienna nazywa się „cnt”
while( cnt <= 4 )
{
if( cnt == 3 )
{
return 0;
}
}
return 0;
W przypadku gdy „cnt” oraz 3 nie są równe – program skoczy pod adres 0x004003d8 i uruchomi funkcję „printf()”, aby coś wypisać. Po wywołaniu funkcji „printf()” program dochodzi do instrukcji…
<+108>: addiu v0, v0, 1
…która zwiększa wartość zmiennej „cnt” o 1. Po tej operacji następuje główny warunek pętli „while()”, który omawialiśmy na samym początku. Kiedy nasza zmienna „cnt” będzie równa wartości 5, program zakończy swoje działanie.
Tak przy okazji – gdybyś miał problem ze zrozumieniem omawianych instrukcji, to zapraszam Cię do drugiej lekcji, gdzie będziesz miał to wszystko wyjaśnione bardziej łopatologicznie.
Preselekcja jest rozdziałem takim trochę buforowym – z jednej strony łączy to, co do tej pory poznałeś, a z drugiej strony to, co będzie za moment. Chciałbym w tym miejscu postawić parę ważnych pytań, zarówno Tobie, jak i sobie zresztą też.
Naprawdę jestem bardzo ciekaw tego, jak sobie do tej pory radziłeś / radzisz. Chociaż może inaczej – czy omawiana tematyka zaciekawiła Cię na tyle, że pomimo braku tematów związanych typowo z security, braku efektów czy napotykaniu kilku/wielu niepowodzeń, jesteś nadal zdeterminowany (i ucieszony), aby dalej zgłębiać temat. A może MIPS nie sprawia Ci większych trudności i już zdążyłeś wyjść poza zakres naszych lekcji poszerzając swoją wiedzę na ten temat?
Jeśli na tym etapie odpuszczasz z jakiejś przyczyny, to rozumiem i szanuję – natomiast jeśli czujesz wewnętrznie, że temat jednak jest dla Ciebie, to zapraszam dalej, bo właśnie od tego momentu zaczyna się prawdziwa zabawa w assembly ;)
Stos jest charakterystycznym obszarem pamięci używanym przez program. Wyobraź sobie, że kładziesz książki na suficie – jedna na drugą. Stos tych książek rośnie z sufitu do dołu. Książki są przykładem dla naszych przechowywanych wartości. Ponadto każda książka położona na nasz stos ma swój adres, który dodatkowo jest zmniejszany od adresu poprzedniej książki o 4 bajty.
Jest też taki specjalny rejestr – wskaźnik stosu (stack pointer – $sp) – który przechowuje adres ostatniego elementu położonego na stosie. Jeśli chcemy położyć znowu jakąś książkę lub zdjąć ostatnią – rejestr $sp będzie odpowiednio aktualizowany tak, aby wskazywał na wierzchołek stosu.
Rozdział ten będzie kontynuacją oraz rozwinięciem poprzedniego. Na początku wywołania funkcji w programie (prologu) – na stosie zostaje zarezerwowana specjalna przestrzeń, w której odkładane są pewne wartości. Do najważniejszych zaliczamy:
Niech poniższy kod posłuży nam do testów:
#include "stdio.h"
int one();
int two();
void main()
{
int x = 3;
int y = 2;
int z = 1;
int m = 7;
one(x, y, z, m);
}
int one(int x, int y, int z, int m)
{
two();
return(x + y + z + m);
}
int two()
{
int f = 4;
return f;
}
Kod programu functions.c. Kompilacja: mipsel-linux-gcc -static -o functions functions.c -fno-omit-frame-pointer -ggdb
Przeanalizujmy w pierwszej kolejności kod, zanim uruchomimy debugger. W programie mamy funkcję główną main() oraz funkcje one() i two(), które coś tam sobie wykonują. Programista zdecydował tak, że funkcja main() wywołuje funkcję one(), a ta na samym końcu uruchamia funkcję two(). Niech będzie.
Zobaczmy teraz, co się dzieje ze stosem podczas wywoływania każdej z tych funkcji:

Trzeba tutaj zaobserwować bardzo ważną rzecz. Dla każdej wywoływanej funkcji alokowana jest na stosie nowa przestrzeń poprzez odjęcie wymaganej wartości od wskaźnika $sp (stack pointer). Widzimy tutaj, jak stos rośnie w dół przesuwając się od adresu 0xFFFFFF do 0x000000. To jest właśnie przykład odkładania książek na suficie z poprzedniego rozdziału :)
Zobaczmy sobie teraz ramkę stosu z bliska na przykładzie funkcji one().
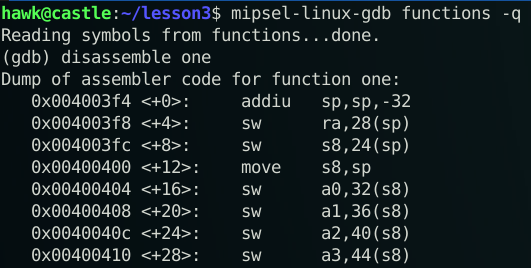
Rzeczywiście! Instrukcja „addiu sp, sp, -32” przesuwa wskaźnik stosu o 32 bajty (czemu 32? kompilator obliczył, że akurat tyle bajtów potrzebował na tę operację i już).
Następnie na stos zostaje wrzucony adres powrotu (sw ra, 28(sp)), a także wskaźnik ramki stosu poprzedniej funkcji (sw s8, 24(sp)). Zauważ, że zarówno adres powrotu, jak i wskaźnik ramki stosu są odmierzane od rejestru $sp – wskaźnika stosu. Jeszcze.
Następnie dzieje się ciekawa rzecz – ten wskaźnik stosu (a raczej jego adres) jest kopiowany do rejestru $s8, czyli wskaźnika ramki stosu (move s8, sp). I tak właśnie ona wygląda. Teraz procesor operując już tylko adresem rejestru $s8 z odpowiednim przesunięciem umieszcza na stosie resztę zmiennych lokalnych, w tym argumenty funkcji.
Tyle z teorii, uruchomimy teraz kod, to sobie pooglądamy, co tam się faktycznie dzieje ;)
(gdb) break 18
(gdb) run
Zatrzymujemy się na funkcji one(), a dokładnie na 18 linii kodu.
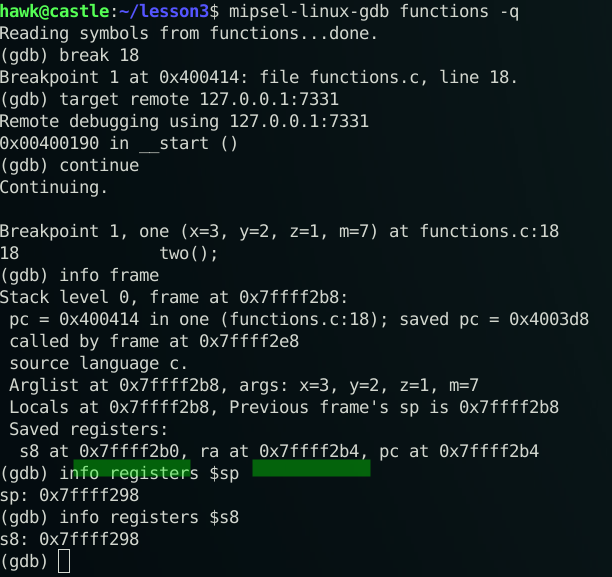
Git. Polecenie „info frame” zwraca informacje dotyczące ramki stosu. „Previous frame’s sp is 0x7ffff2b8” – adres wskaźnika stosu z poprzedniej funkcji. Adres $sp po przesunięciu o 32 bajty to 0x7ffff298. Wykonajmy zatem obliczenia dla instrukcji „addiu sp,sp,-32”, czy wszystko się zgadza:
0x7ffff2b8 – 0x20 (decymalnie 32) = 0x7ffff298
Super! To teraz sprawdźmy, pod jakim adresem został umieszczony adres powrotu (sw ra, 28(sp)):
0x7ffff298 + 0x1c (decymalnie 28) = 0x7ffff2b4
Jest dobrze. Zresztą, dokładnie ten sam adres rejestru $ra znajdziesz na powyższym obrazku w danych ramki stosu.
Jak już będziesz debugował sam dla testów, taki prolog w zależności od wersji MIPSa – czy nawet całej architektury – może wyglądać różnie, natomiast bardzo mi zależy na tym, abyś poznał koncept, szkielet działania konkretnych mechanizmów, bo gdy to ogarniesz, to w przyszłości będzie Ci już dużo łatwiej! :)
PC (program counter) jest takim specjalnym rejestrem przechowującym adres następnej instrukcji wykonywanej przez program. Rejestr ten może być modyfikowany przez niektóre instrukcje, np. „jal / jalr”.
Na sam początek przeróbmy sobie przekazywanie parametrów do funkcji. Taki kod:
#include "stdio.h"
int one();
void main()
{
int a = 3;
int b = 2;
int c = 1;
int d = 4;
int e = 5;
int f = 8;
one(a,b,c,d,e,f);
}
int one(int a, int b, int c, int e, int f)
{
return 0;
}
Kod programu params.c. Kompilacja: mipsel-linux-gcc -static -o params params.c -fno-omit-frame-pointer
Poznając MIPSa od podstaw na pewno dowiedziałeś się, że posiada on specjalne rejestry, które wykorzystywane są do przechowywania argumentów funkcji – $a0, $a1, $a2, $a3. A co w przypadku, kiedy tych argumentów jest więcej niż cztery? Są one wrzucane oczywiście na stos.
To jest całkiem ciekawy proces, który prześledzimy bardziej szczegółowo. Debugując nasz program zapewne zauważyłeś instrukcje takie jak: jal, jarl czy jr. Są to instrukcje skoku, które modyfikują rejestr PC po to, aby program kontynuował swoje działanie pod określonym adresem pamięci.
W momencie wykonywania instrukcji takiej jak jal, jalr („Jump and link”) adres powrotu ($ra) jest zamieniany na adres: PC + 8 bajtów, czyli adres powrotu wskazuje na drugą instrukcję pod instrukcją jump. Dzieje się tak dlatego, że wykonywany zostaje także tzw. „branch delay slot” – program tuż przed skokiem do funkcji wykonuje instrukcję znajdującą się pod instrukcją jump (adres PC + 4 bajty).
Lepiej to będzie zrozumieć analizując obrazek poniżej:

Na początek kod, który posłuży nam do badań:
#include "stdio.h"
int one();
int two();
void main()
{
int a = 3;
int b = 2;
int c = 1;
one(a,b,c);
}
int one(int a, int b, int c)
{
two();
return(a + b + c);
}
int two()
{
int f = 4;
return f;
}
Kod programu functions_two.c. Kompilacja: mipsel-linux-gcc -static -o functions_two functions_two.c -mips2 -fno-omit-frame-pointer -ggdb
Każdą funkcję można podzielić na takie trzy sekcje:
Zarówno prolog, jak i epilog mogą się od siebie różnić w zależności od tego, czy dana funkcja wywołuje kolejną czy też nie.
Porównajmy teraz prolog dla dwóch naszych funkcji. Kod funkcji one():
(gdb) disassemble one
Dump of assembler code for function one:
0x004003e8 <+0>: addiu sp, sp, -32
0x004003ec <+4>: sw ra, 28(sp)
0x004003f0 <+8>: sw s8, 24(sp)
0x004003f4 <+12>: move s8, sp
oraz funkcji two():
(gdb) disassemble two
Dump of assembler code for function two:
0x00400438 <+0>: addiu sp, sp, -24
0x0040043c <+4>: sw s8, 20(sp)
0x00400440 <+8>: move s8, sp
Podstawowa różnica jest taka, że funkcja one() wywołuje inną funkcję, natomiast two() – nie wywołuje żadnej,program po wykonaniu two() wraca do funkcji one(). Skutkuje to tym, że o ile w prologu funkcji one() adres powrotu ($ra) zostaje odłożony na stos, o tyle w prologu funkcji two() nie ma takiej operacji, ponieważ po prostu jest ona niepotrzebna.
Zauważ też to, o czym była mowa wcześniej. Wskaźnik stosu ($sp – stack pointer) jest kolejno zmniejszany o heksadecymalne wartości: 32, a później o 24, aby było miejsce na zmienne lokalne.
Analogiczna sytuacja ma miejsce w przypadku epilogów obu funkcji. Sprawdźmy to:
Epilog funkcji one():
(gdb) disassemble one
…
0x00400420 <+56>: move sp, s8
0x00400424 <+60>: lw ra, 28(sp)
0x00400428 <+64>: lw s8, 24(sp)
0x0040042c <+68>: addiu sp, sp, 32
0x00400430 <+72>: jr ra
0x00400434 <+76>: nop
Epilog funkcji two():
(gdb) disassemble two
…
0x00400450 <+24>: move sp, s8
0x00400454 <+28>: lw s8, 20(sp)
0x00400458 <+32>: addiu sp, sp, 24
0x0040045c <+36>: jr ra
0x00400460 <+40>: nop
Epilog czyści teraz miejsce, które prolog przeznaczył na swoje zmienne lokalne. Robi to dodając wartość heksadecymalną 24 do wskaźnika stosu, czyli tyle, ile chciał prolog na samym początku podczas uruchomienia funkcji. Potem następuje powrót do poprzedniej ramki stosu.
Adresy podczas debugowania zarówno u mnie, jak i u Ciebie mogą się różnić. Prześledzimy sobie teraz razem cały proces życia naszego programu przez gdb krok po kroku. Ustawiamy breakpoint na nasze funkcje:
(gdb) break one
(gdb) break two
(gdb) target remote 127.0.0.1:7331
terminal #1
Teraz odpalamy w drugim terminalu qemu:
~# chroot . ./qemu-mipsel-static -g 7331 functions_two
terminal #2
A następnie wracamy do naszego terminala #1 i kontynuujemy pracę, aby przejść płynnie do naszego breakpointa:
(gdb) continue
Continuing.
Breakpoint 1, one (a=3, b=2, c=1) at functions_two.c:17
17 two();
terminal #1
Polecenie „backtrace” w gdb pozwoli Ci zobaczyć, w jakiej funkcji obecnie się znajdujesz. Jeśli ponownie podejrzysz funkcję poleceniem „disassemble one”, to zobaczysz, przed którą dokładnie instrukcją Twój program został zatrzymany – jest to widoczne dzięki strzałce przy instrukcji. U mnie wygląda to tak:
Okej, będąc w tym miejscu (jeśli nie jesteś, bardzo prosto można przejść do kolejnych instrukcji wykonując polecenie „step”) program odłożył już ramkę stosu dla bieżącej funkcji, więc ją sprawdźmy.
Najpierw wierzchołek stosu, czyli gdzie wskazuje nasz rejestr $sp. Wykonując polecenie „info frame” gdb zwróci nam bardziej szczegółowe dane na temat naszej ramki. Wykonajmy je:
(gdb) info frame
Stack level 0, frame at 0x7ffff2a8:
pc = 0x400404 in one (functions_two.c:17); saved pc = 0x4003cc
called by frame at 0x7ffff2d8
source language c.
Arglist at 0x7ffff2a8, args: a=3, b=2, c=1
Locals at 0x7ffff2a8, Previous frame’s sp is 0x7ffff2a8
Saved registers:
s8 at 0x7ffff2a0, ra at 0x7ffff2a4, pc at 0x7ffff2a4
Git. Adres początkowy ramki stosu badanej funkcji to 0x7ffff2a8. Wskaźnik wierzchołka stosu przesuwa się o 32 bajty względem swojej poprzedniej wartości (także adres 0x7ffff2a8), aby zarezerwować pamięć dla funkcji one() instrukcją „addiu sp,sp,-32″.Obliczmy to:
Teraz sprawdźmy, jaki adres mamy w rejestrze $sp: (gdb) info reg $sp sp: 0x7ffff288 Zgadza się! Przypominam, że stos rośnie w dół, dlatego kolejne wartości dla kolejnych funkcji będą miały coraz niższe adresy. Na stos został odłożony adres powrotu (z rejestru $ra), możemy więc obliczyć, a później sprawdzić, miejsce w pamięci, pod którym się on znajduje: sw ra, 28(sp) 0x7ffff288 + 28 (1C) -> 0x7ffff2a4 #R2 Teraz wróć na chwilę do informacji o ramce („info frame”). Zobaczysz tam informację: „ra at 0x7ffff2a4”, czyli nasze obliczenia się zgadzają. Sprawdźmy jeszcze jedną rzecz. Jaka jest wartość w pamięci pod adresem 0x7ffff2a4 i czy jest ona identyczna z wartością rejestru $ra? (gdb) x/x 0x7ffff2a4 0x7ffff2a4: 0x004003cc (gdb) info reg $ra ra: 0x4003cc Wartość rejestru $ra Wszystko się zgadza. Zobacz, co dzieje się dalej z adresem $sp. Zostaje on skopiowany do rejestru $s8 (move s8,sp), od którego są odmierzane offsety w pamięci do zaalokowania tam wartości zmiennych (argumentów funkcji) w naszym programie ($a0, $a1, $a2). Powrócimy do naszego adresu powrotu trochę później, tymczasem kontynuujemy pracę programu (gdb: „continue”) i przechodzimy do kolejnego breakpointa ustawionego na funkcję two(). Okej, znajdujemy się teraz w ostatniej wywoływanej funkcji. Zwróć uwagę na ostatnie jej instrukcje: 0x00400454 <+28>: lw s8, 20(sp) 0x00400458 <+32>: addiu sp, sp, 24 0x0040045c <+36>: jr ra 0x00400460 <+40>: nop Jest to epilog funkcji, w którym program zdejmuje wartości ze stosu umieszczając je w odpowiednich rejestrach, zdejmuje także adres powrotu (rejestr $ra), żeby wiedział gdzie ma wrócić oraz wykonuje skok pod ten adres. Zaraz, zaraz… dlaczego więc funkcja ta nie posiada instrukcji zdejmującej adres powrotu ze stosu? Wyjaśnienie jest proste: jest to funkcja typu „leaf”, wykonuje ona pewne operacje, po czym następuje powrót do funkcji wywołującej (czyli w naszym przypadku one()). Przypominasz sobie może z poprzedniego rozdziału, jak działa instrukcja jalr? „W rejestrze $ra umieść instrukcję spod adresu PC + 8 bajtów, a potem sobie skocz, gdzie masz skoczyć”. Rejestr $ra został zaktualizowany, a program wykonał skok do funkcji two(). Teraz zobacz, czy tak jest na pewno: (gdb) i r $ra ra: 0x40040c Adres 0x40040c wskazuje na instrukcję „lw v1,32(s8)” w funkcji one() – czyli wszystko się zgadza. Po wykonaniu funkcji two() program skoczy pod adres 0x40040c. Idziemy dalej (gdb: step 3): Jesteśmy znowu w funkcji one(). W epilogu analogicznie do poprzedniego przypadku pojawia się skok do instrukcji zawartej w rejestrze $ra („jr $ra”). I w tym miejscu pojawia nam się problem, ponieważ rejestr $ra dalej wskazuje na adres, pod który wróciliśmy z funkcji two(). Aby program powrócił do kolejnej instrukcji funkcji main() – musi zdjąć ze stosu adres tej instrukcji, a następnie wrzucić go do rejestru $ra: 0x00400424 <+60>: lw ra, 28(sp) 0x00400430 <+72>: jr ra Przejdźmy do instrukcji „jr ra” w epilogu funkcji one() (poprzez polecenie step 2 w gdb). Zerknij teraz na chwilę wyżej do ramki podpisanej „Wartość rejestru $ra” i sprawdź empirycznie, jaki adres posiada teraz rejestr po wykonaniu instrukcji „lw ra,28(sp)”: (gdb) i r $ra ra: 0x4003cc I znowu wszystko się zgadza ;) W funkcji main() nastąpi analogiczna operacja. Teraz widzisz, że odkładanie adresu powrotu na stos jest jedną z głównych różnic pomiędzy funkcjami typu „non-leaf” – tymi, co wywołują po drodze inne – a funkcjami typu „leaf”, które nie wywołują żadnych innych. W różnych wersjach MIPSa, zarówno prolog, jak i epilog, jak już wcześniej wspominałem mogą się od siebie lekko różnić. Nam tutaj chodzi bardziej o zasadę działania wspomnianych mechanizmów. Zachęcam Cię mocno do prześledzenia tego procesu jeszcze raz, ale po swojemu. Na spokojnie, ale praktycznie – używając do tego gdb czy innego narzędzia. Dobrze jest też zaznajomić się bardziej ze swoim debuggerem, aby móc usprawniać i przyspieszać swoją pracę. Jeśli jesteś typem wzrokowca i umiesz pisać/malować, to rozrysowanie sobie bardziej zawiłych zagadnień na kartce papieru może pomóc Tobie w zrozumieniu niektórych, skomplikowanych rzeczy. I nie chodzi tutaj o robienie obszernych notatek – bardziej o rozłożenie na czynniki pierwsze jakiejś zawiłej dla Ciebie operacji. Wreszcie coś konkretnego. Zadanie jest proste – musisz uruchomić funkcję „flag()” ;) Kod programu hw.c. Kompilacja: mipsel-linux-gcc -static -o hw hw.c Tipy: To tyle. Działaj i nie poddawaj się! :) –Mateusz Wójcik, grupa Squadron31
=> 0x00400444 <+12>: li v0,4
Kilka słów na koniec
Zadanie domowe
#include <string.h>
#include <stdio.h>
int main(int argc, char **argv[])
{
char buf[200] ="\0";
strcpy(buf, argv[1]);
printf("Niet.\r\n");
return 0;
}
int flag(){
printf("Wygrales!\r\n");
return 0;
}

{kind=link}
## Odpowiedź na pytanie z początku artykułu:
MIPS jest super, jestem przyzwyczajony do trochę innej konwencji, ale przyzwyczajenia w RE nie są dobre… Więc tym bardziej poradnik mi się podoba! W dodatku jest super zrobiony ;) uważam, że to, że jest napisany tak jakby komuś to wprost opowiadać jest super ;)
##UWAGA SPOILERS, CZYTASZ NA WŁASNĄ ODPOWIEDZIALNOŚĆ##
## bugs:
– Wskaźnik wierzchołka stosu przesuwa się o 32 BITY -> (o 32 bajty)
– (…)jak działa instrukcja jalr? „Umieść instrukcję spod adresu PC + 2 bajtyjak działa instrukcja jalr? „Umieść instrukcję spod adresu PC + 2 bajty -> +2 bajty? na pewno musi być coś podzielnego przez 4, w końcu tylko takiej długości są instrukcje w MIPSie :D swoją drogą do tej parafrazy można by dodać, że ta instrukcja spod adresu jest umieszczana w $ra :)
##solution?
A co do zadanka na koniec:
send(“A”*200 + b”\x67\x45\x23\x01”) #gdy 01234567 to adres funkcji flag (? coś takiego)
A samo zadanko oczywiście super :D a na jakieś następne proponuję małego ROPa.. ale oczywiście nie chcę psuć planów :)
Znowu czujne oko Wójta, nie mam pytań ;)
Poprawiamy ;)
Btw, dzięki Stary za odpowiedź, generalnie chodziło o to, by ten kurs był przyjazny i napisany w przystępny sposób tak aby łatwiej można było maksymalnie przyswoić sobie z niego wiedzę.
A co do zadanka to narazie cisza w eterze – rozwiązanie niebawem
Tymczasem kombinuj ;)
Masz rację, oczywiście, jeszcze s8 jest na stosie… :D
# qemu-mipsel-static -g 7331 hw $(printf “A%.0s” {1..200})BCDE$(echo -en “\x4c\x04\x40”)
Wójt o masz, no i shakowałeś!
Mam nadzieję, że reszta nie czyta Twoich spoilerów tylko działa sama ;)
A tak bardziej poważnie – miałeś problemy z postawieniem buildroota, kompilacją, gdb itp?
Widzę, że Ci to super idzie :)
Zdaje się, że akurat jak próbowałem instalować buildroota, to
jakieś paczki nie były chwilowo dostępne (albo mój internet był aż tak słaby..), ale jak po jakimś czasie do tego podszedłem, to już bez żadnych przygód się udało :)
Próbowałem jeszcze zainstalować “qemu-user-static” lokalnie na dedykowanym użytkowniku, żebym nie musiał pamiętać o odinstalowywaniu pakietu po usunięciu użytkownika, ale to już bez sukcesu..
Ogólnie instrukcja instalacji środowiska z pierwszej lekcji według mnie wystarczająca, bardzo dobrze opisana i jak najbardziej bardzo pomocna :)
A co do kontynuacji tematu – będą jeszcze co najmniej dwie publikacje.
stay tuned! ;)
Polecam narzędzie IDA do tego typu eksperymentów. Jest tam bardzo duża baza rdzeni różnych procesorów i mikrokontrolerów do wyboru.
Upload-ujecie bin albo hex i IDA robi disasemblacje z fajnym grafem. Można tez wczytać zawartość RAM z danego momentu. Generalnie super narzędzie do reverse eng.