Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

Jak pomogłem zabezpieczyć DOMPurify
DOMPurify jest bardzo popularną biblioteką typu HTML Sanitizer, która jest używana przez autorów stron www, gdy chcą dać użytkownikowi możliwość wpisywania własnego kodu HTML (np. przez edytory WYSIWYG), ale nie chcą dopuścić kodu, który mógłby wywołać XSS-a. Wówczas sanitizer przychodzi z pomocą i usuwa z HTML-a wszystkie te elementy, które mogą posłużyć do ataku.
W ciągu ostatniego roku udało mi się znaleźć kilka obejść zabezpieczeń oferowanych przez tę bibliotekę; opisywałem je na naszym anglojęzycznym blogu:
- Write-up of DOMPurify 2.0.0 bypass using mutation XSS
- Mutation XSS via namespace confusion – DOMPurify < 2.0.17 bypass
O ile na co dzień zajmuję się obchodzeniem zabezpieczeń w różnorakich systemach, o tyle w ostatnim czasie zaczyna się we mnie budzić coraz większa chęć pomagania w zabezpieczeniu pewnych systemów. Dlatego też pod koniec zeszłego roku wysłałem do DOMPurify pull request, w którym zaproponowałem kompleksowe zabezpieczenie przed obejściami znajdowanymi w ciągu ostatniego roku.
W tym artykule przybliżę, jak działały te obejścia oraz jakie zmiany zaproponowałem, żeby je unieszkodliwić raz na zawsze :)
Podstawy przetwarzania HTML
Zanim przejdziemy do obchodzenia DOMPurify, musimy zacząć od podstaw. Będziemy omawiać dwa procesy związane z HTML-em i drzewem DOM:
- Parsowanie – tj. zamianę znaczników HTML na drzewo DOM.
- Serializacja – operacja odwrotna, tj. zamiana drzewa DOM na tekst HTML.
Jeśli więc mamy prosty fragment HTML, np.
<div id=x>Hello!</div>Zostanie on sparsowany do następującej postaci drzewa DOM:

Jeśli spróbujemy z powrotem zserializować element <div>, otrzymamy:
<div id="x">Hello!</div>Zauważmy, że postać zserializowana nie jest identyczna jak pierwotny HTML (choć jest równoważna); początkowo wartość atrybutu id nie znajdowała się w cudzysłowiu.
Kolejnym istotnym aspektem elementów w drzewie DOM, o którym prawdopodobnie na co dzień nie myślimy, jest fakt, że każdy z nich ma ustaloną przestrzeń nazw (ang. namespace). Domyślnie wszystkie elementy są w przestrzeni HTML, ale istnieje możliwość zmiany na SVG lub MathML. Można to uczynić tagami <svg> oraz <math>.
Spróbujmy więc sparsować prosty fragment HTML:
<div>Hello!</div>
<svg>Hello!</svg>
<math>Hello!</math>Otrzymamy w efekcie:
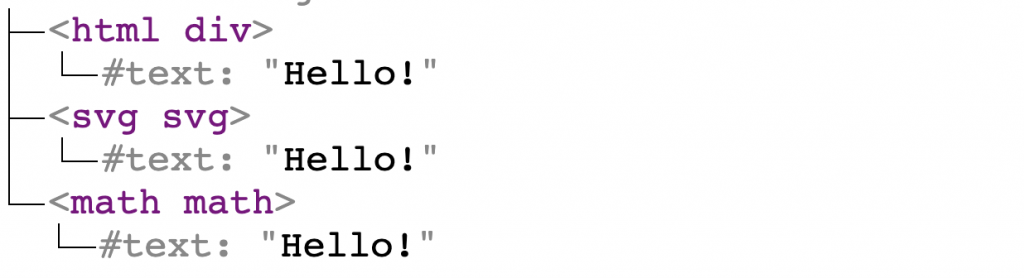
Wszystkie kolejne drzewa DOM, które będę pokazywał w tym artykule będą używały konwencji, w której nazwa tagu jest poprzedzona jego przestrzenią nazw. Zatem <html div> oznacza, że jest to element <div> w przestrzeni nazw HTML, zaś np. <svg svg> oznacza element <svg> w przestrzeni nazw SVG.
Przestrzeń nazw danego elementu wpływa na jego parsowanie oraz na ewentualne specjalne zachowanie, jeśli takowe posiada. Przykładowo element <canvas> pozwala na rysowanie grafik i animacji, ale tylko jeśli jest w przestrzeni HTML. W przestrzeniach SVG i MathML jest “zwykłym” elementem.
Ponadto pewne elementy w HTML-u są parsowane w specyficzny sposób. Dobrym przykładem jest tutaj <style>, który nie może zawierać żadnych elementów potomnych za wyjątkiem tekstu. Inaczej jest jednak w SVG/MathML, gdzie jest parsowany “zwyczajnie”. Zobaczmy przykład:
<div><style><a>am I a new tag?</a></style></div>
<math><style><a>am I a new tag?</a></style></math>Oraz drzewo DOM:

Zauważmy, że <html style> zawiera tylko tekst, a <math style> zawiera element potomny <math a>.
Ta różnica w parsowaniu tagu <style> jest najpowszechniejszym sposobem obchodzenia sanitizerów HTML. Rozważmy następujący fragment:
<math><style><a style="</style><img src onerror=alert(1)>">Zostaje on sparsowany do postaci:

Zauważmy, że to drzewo DOM jest zupełnie niegroźne; ten malutki fragment kodu, który przypomina kod XSS-owy znajduje się wewnątrz atrybutu style.
Jeśli jednak znajdziemy sposób na to, by przekonać parser, by ten <style> został przetworzony w HTML-owej przestrzeni nazw, dostaniemy w odpowiedzi zupełnie inne drzewo DOM:

Ze względu na fakt, że w przestrzeni HTML-a <style> nie może zawierać elementów potomnych, ciąg znaków </style> natychmiast go kończy – i wszystko co jest dalej jest traktowane jako nowy element.
Zmiany przestrzeni nazw
Zastanówmy się teraz w jaki sposób możemy dokonać zmiany przestrzeni nazw w HTML-u. Domyślnie większość element po prostu dziedziczy przestrzeń nazw po elemencie nadrzędnym. Ale istnieją pewne wyjątki, które sprawiają, że dochodzi do zmiany przestrzeni nazw.
Już poznaliśmy dwa z nich: gdy jesteśmy w przestrzeni HTML, wówczas <svg> i <math> powoduję zmianę przestrzeni nazw. Możemy więc zadać sobie pytanie: czy jest możliwe, żeby w środku elementu w SVG/MathML umieścić inny element w przestrzeni HTML? Odpowiedź brzmi: tak.
Prawdopodobnie najbardziej znanym przykładem jest element z SVG zwany <foreignObject>, którego celem jest właśnie osadzanie elementów spoza SVG wewnątrz SVG. Weźmy za przykład poniższy fragment HTML:
<svg><foreignobject><div>Hello!Zostanie on przetworzony do następującego drzewa DOM:

Zauważmy, że <div> jest w przestrzeni HTML pomimo faktu, że element nadrzędny jest w SVG.
Jeśli zerkniemy na specyfikację HTML, okaże się, że <foreignObject> jest tylko jednym z kilku tzw. punktów integracji HTML, tj. elementów, które sprawiają, że elementy potomne zmieniają przestrzeń nazw. Pełna lista tych elementów to:
<math annotation-xml>ale tylko jeśli ma atrybutencodingo wartościtext/htmlalboapplication/xhtml+xml<svg foreignObject><svg desc><svg title>
Ale to jeszcze nie wszystko! Istnieje jeszcze jedna lista elementów, znana jako punkty integracji tekstu MathML, które pozwalają na zmianę przestrzeni nazw. Te elementy to z kolei:
<math mi><math mo><math mn><math ms><math mtext>
Lecz w tym przypadku jest pewien haczyk: wszystkie elementy potomne punktów integracji tekstu MathML zmieniają przestrzeń nazw z wyjątkiem dwóch elementów: <mglyph> i <malignmark> – one wciąż będą w przestrzeni MathML. Sprawdźmy to:
<math>
<mtext>
<mglyph></mglyph>
<div></div>
</mtext>
</math>Powstanie drzewo DOM:

Jak widać, <div> jest w przestrzeni HTML, zaś <mglyph> w przestrzeni MathML pomimo faktu, że oba te elementy są bezpośrednimi elementami potomnymi punktu integracji tekstu MathML. Warto tutaj również dodać, że <mglyph> będzie w przestrzeni MathML tylko wtedy, gdy jest bezpośrednim elementem potomnym punktu integracji tekstu MathML. Weźmy więc następujący fragment:
<math>
<mtext>
<div>
<mglyph></mglyph>
</div>
</mtext>
</math>I dostaniemy <mglyph> w przestrzeni HTML:

Ostatnią istotną kwestią jest fakt, że pewne elementy kończą przestrzeń nazw MathML/SVG natychmiastowo; tj. nie mogą być elementami potomnymi wewnątrz przestrzeni MathML/SVG chyba że są albo wewnątrz punktów integracji HTML lub punktów integracji tekstu MathML.
Jednym z takich elementów jest <s>. Zobaczmy:
<svg>
<s></s>
</svg>Na pierwszy rzut oka może nam się wydawać, że <s> będzie elementem potomnym <svg>, ale tak nie jest:

W specyfikacji HTML znajduje się lista elementów, zachowujących się tak samo jak <s>, obejmująca też m.in. <p>, <span> czy <div>.
Główna przyczyna obejść DOMPurify
Znamy już podstawy jeśli chodzi o parsowanie HTML i jak działają nie-HTML-owe przestrzenie nazw. Teraz bardzo krótko opiszę te dwa obejścia DOMPurify, które wspomniałem na początku artykułu.
Pierwszy problem wynikał z parsowania tagu kończącego </p> w Safari i Chromium. Weźmy przykład:
<svg></p>który niespodziewanie był parsowany do następującego drzewa DOM:

<p> jest jednym z tych elementów, które nie mogą znajdować się bezpośrednio w przestrzeniach nie-HTML-owych. Więc gdy to drzewo DOM zostanie zserializowane, dostaniemy HTML:
<svg><p></p></svg>A gdy sparsujemy je ponownie, dostaniemy już inne drzewo DOM:
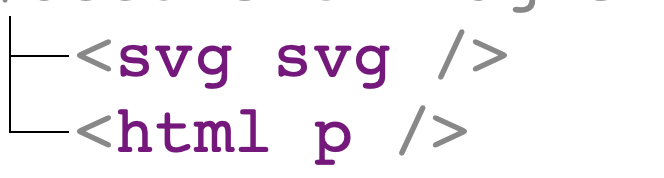
Mamy tutaj do czynienia z tzw. mutacją, tj. mamy drzewo DOM, które serializujemy, a następnie parsujemy ponownie – i dostajemy kolejne drzewo DOM, które nie jest równoważne temu pierwotnemu.
Z punktu widzenia takiej biblioteki jak DOMPurify jest to bardzo złe zachowanie przeglądarki, bo nie jest w stanie podjąć odpowiedniej decyzji, czy dane drzewo DOM jest bezpieczne.
Weźmy taki przykład:
<svg></p><style><a title="</style><img src onerror=alert(1)>">Zostanie sparsowany do postaci:

DOMPurify uzna, że to drzewo DOM jest niegroźne i niczego z niego nie usunie – bo wszystkie elementy i atrybuty znajdują się na liście dopuszczonych.
Jednak w przypadku serializacji i kolejnego parsowania, <html p> “ucieknie” z <svg svg>, co wpłynie na wszystkie następne tagi, skutkując zupełnie innym drzewem DOM, w którym znajdzie się atrybut onerror:

Zauważmy, że główną przyczyną tego obejścia był fakt, że w początkowym drzewie DOM udało się umieścić element <html p> wewnątrz <svg svg> co – zgodnie ze specyfikacją – nie powinno być dopuszczone. Gdyby tego nie udało się zrobić, cały exploit nie działałby.
Spójrzmy na kolejne obejście DOMPurify. Użyję tutaj kodu payloadu zamieszczonego przez użytkownika Sapra na Twitterze bo jest łatwiejszy do zrozumienia niż ten, który sam wymyśliłem.
Najpierw jednak przyjrzyjmy się pewnej dziwnostce w parsowaniu elementu <table>. Weźmy bardzo prosty fragment HTML:
<table>
I AM INSIDE TABLE
</table>Wynikowe drzewo DOM może zaskoczyć:

Pomimo że w oryginalnym HTML-u wydawało się, że tekst I AM INSIDE TABLE znajduje się wyraźnie wewnątrz tabeli; po przeparsowaniu znalazł się on przed tabelą. Wyjaśnienie dlaczego dokładnie tak się dzieje nie jest proste do wytłumaczenia, ale nie jest specjalnie istotne. Na razie uprośćmy ten temat i zapamiętajmy, że jeśli <table> nie zawiera tagów, które powinien zawierać (takich jak <tr> czy <td>), to wnętrze tego elementu zostanie wyrzucone przed element.
Weźmy więc już kod exploita:
<math><mtext><table><mglyph><style><s><img src onerror=alert(1)>Który skutkuje drzewem DOM:

W oryginalnym HTML-u mieliśmy <mglyph> wewnątrz <table>, jednak w wyniku specyfiki parsowania tabel w HTML-u, <mglyph> został wyniesiony przed <table> – i pozostał w przestrzeni nazw HTML-owej, co oznacza, że wszystkie jego elementy potomne są też w HTML-u.
Takie drzewo DOM zostanie zserializowane do postaci:
<math><mtext><mglyph><style><s><img src onerror=alert(1)></style></mglyph><table></table></mtext></math>Zauważmy, że teraz <mglyph> jest już bezpośrednim elementem potomnym dla <mtext>, więc wszystkie następujące elementy będą w przestrzeni nazw MathML. W takim wypadku element <s> spowoduje natychmiastowe zamknięcie tej przestrzeni nazw i otwarcie HTML-owej, co z kolei spowoduje, że zostanie utworzony element <img> z payloadem XSS:

Przyjrzyjmy się zatem tym dwóm obejściom DOMPurify, które opisałem i postarajmy się znaleźć wspólną przyczynę.
W pierwszym przypadku, przyczyną był element <html p>, który znalazł się wewnątrz <svg svg>, co normalnie nie jest dopuszczalne. W drugim przypadku, mieliśmy element <mglyph> który zmienił przestrzeń nazw po ponownym parsowaniu. Pomimo faktu, że <mglyph> jest na liście dopuszczalnych tagów DOMPurify, powinien mieć przestrzeń nazw MathML; jeżeli będzie w przestrzeni HTML – powinien zostać od razu odrzucony.
Łatka na DOMPurify
Na podstawie powyższych rozważań przyszło mi więc do głowy, że jeżeli rozbudujemy DOMPurify o dokładną weryfikację przestrzeni nazw elementów, to będziemy mogli załatać powyższe obejścia DOMPurify oraz inne znalezione w międzyczasie – przez @PewGrand i @bananabr.
Ogólny pomysł jest następujący:
- Potrzebujemy listy elementów zdefiniowanych w specyfikacji SVG i MathML. Te elementy powinny być dopuszczone tylko w swoich własnych przestrzeniach nazw. To ubije obejścia polegające na tworzeniu elementów w nieoczekiwanych przestrzeniach nazw, np.
<svg p>. - Usuwamy elementy, które znajdują się w przestrzeni nazw HTML, a są charakterystyczne dla MathML/SVG. Więc np.
<mglyph>w przestrzeni HTML zostanie usunięty. - Dokładnie sprawdzamy wszystkie punkty, gdy element zmienia przestrzeń nazw; zmiany są dopuszczalne tylko w następujących sytuacjach:
- Jedyny sposób na przejście z HTML na SVG/MathML to
<svg>/<math> - Jedyny sposób na przejście z SVG do HTML jest przez punkty integracji HTML.
- Jedyny sposób na przejścia z SVG na MathML jest przez
<math>lub punkty integracji HTML - Jedyny sposób na przejście z MathML na SVG jest przez
<svg>wewnątrz<annotation-xml>lub punktu integracji tekstu MathML. - Jedyny sposób na przejście z MathML na HTML jest przez punkty integracji tekstu MathML.
- Jeśli element zmieni przestrzeń nazw niezgodnie z powyższymi zasadami, jest usuwany.
- Jedyny sposób na przejście z HTML na SVG/MathML to
Jeśli macie ochotę przyjrzeć się dokładnie jak działa to zabezpieczenie, zachęcam do przejrzenia kodu metody _checkValidNamespace na GitHubie.
Podsumowanie
W artykule opisałem swoje niedawne przygody z łataniem biblioteki DOMPurify. Pomimo że zwykle wolę być po stronie “ofensywnej”, ciekawie było pomóc także stronie “defensywnej” i wprowadzić zabezpieczenie, które powinno unieszkodliwić całą serię potencjalnych ataków :)
Jeśli chcecie żeby i wasze oprogramowanie przetestować pod kątem bezpieczeństwa lub chcecie sami się nauczyć szukać błędów bezpieczeństwa – zapraszamy do kontaktu z Securitum.
— Michał Bentkowski (@SecurityMB) – haker z Securitum

Szacun, Michale B.!
I super, ze pomagasz jasnej stronie mocy :-).
Witam; bardzo ciekawy opis działań;
pozdrawiam.
Dzięki Michal.
Czy nie lepiej byłoby nie dopuszczać do użycia
svg i math? Nie każdy ma potrzebę by ich używać/ dopuszczać.
Wprawdzie domyślna konfiguracja DOMPurify pozwala na svg i math (i wyłączenie tego spowodowałoby złamanie kompatybilności wstecznej, co mogłoby wywołać negatywne reakcje), ale spodziewam się, że dobrych 90% aplikacji może spokojnie je wyłączyć, bo prawdopodobnie nie są potrzebne w tym kontekście, w którym używany jest DOMPurify.
Więc tak, sugerowałbym ustawić konfigurację DOMPurify w taki sposób, żeby odrzucić math i svg.
Prosba o przekazanie informacji dla Michala Sajdaka.
Przepraszam nie Macka.