Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

Jak działają współczesne przeglądarki internetowe
Jak działają współczesne przeglądarki internetowe

Wstęp
Przeglądarki internetowe należą do grupy najbardziej złożonych rodzajów oprogramowania użytkowego, z jakim styka się na co dzień przeciętny użytkownik komputera. Ewolucja, jaka dokonała się w ich “wnętrzach” to temat na książkę i trudno w tak krótkim opracowaniu przedstawić zagadnienie szczegółowo. W artykule postaram się zatem przybliżyć najważniejsze składniki oraz sposób działania tych najczęściej spotykanych przeglądarek internetowych (Firefox, Chrome, IE, Opera i Safari). Tam, gdzie będzie to możliwe zwrócę uwagę na aspekty szczególnie istotne dla tematyki bezpieczeństwa informatycznego.
Czym tak naprawdę jest przeglądarka internetowa?
Gdyby zadać to pytanie statystycznemu internaucie, odpowiedziałby, że programem do wyświetlania stron WWW. Miałby rację, gdyż ta funkcja nadal pozostaje najważniejszą cechą tych programów, ale nie byłaby to pełna odpowiedź. Dzisiejsza przeglądarka to kompozycja wielu elementów, zajmujących się generowaniem zarówno statycznej, jak i dynamicznej oraz multimedialnej treści. Bez problemu jest w stanie wyświetlić dokumenty w wielu popularnych formatach (np. pdf) czy posłużyć za klienta poczty elektronicznej, komunikator bądź interfejs do edycji dokumentów przechowywanych w chmurze.
Uniwersalność zastosowań doprowadziła do powstania całych systemów operacyjnych zbudowanych wokół przeglądarki (ChromeOS, FirefoxOS).
Z drugiej strony, przeglądarka, będąc swoistym oknem na świat i punktem “wejścia” do sieci, stanowi jednocześnie najczęstsze źródło wszelkich “infekcji” naszego komputera. To przez nią do naszego systemu przedostają się trojany, malware i inne złośliwe oprogramowanie. Znajomość budowy i działania przeglądarki może nam pomóc bronić się przed nimi (choćby poprzez świadomość, w jaki sposób interpretowany jest element <iframe> lub jak przeglądarka obsługuje ciasteczka).
Współczesne aplikacje internetowe
Czym jest aplikacja internetowa (aplikacja webowa, webaplikacja)? Jest to oprogramowanie stworzone przy użyciu kilku technologii (opis poniżej), działające w architekturze klient-serwer (gdzie przeglądarka występuje w roli klienta), mogące komunikować się z innymi aplikacjami bądź serwerami, wykonująca określone operacje i działania w odpowiedzi na akcje użytkownika. Przykładami typowych aplikacji webowych są:
- webowe interfejsy portali społecznościowych (FB, Google+, Twitter, LinkedIn) – celowo wymieniam je w tym miejscu, jako osobny rodzaj aplikacji, gdyż obecnie portale te posiadają także interfejsy klienckie w postaci np. natywnych aplikacji na urządzenia mobilne działające pod kontrolą systemów Android czy iOS),
- klient poczty (GMail, Outlook Web Access, interfejsy poczty WP, Onet, O2 itp.),
- sklepy internetowe, transakcyjne systemy bankowe,
- webowe interfejsy komunikatorów, IRC, gry MMORPG.
Do ich stworzenia używa się obecnie trzech najważniejszych technologii:
- HTML5 – jest to język znaczników, za pomocą którego opisuje się strukturę strony, będącą elementem aplikacji widocznym w oknie przeglądarki. To HTML odpowiada za podział strony na paragrafy, nagłówki, listy, tabelki. Pozwala też na wyświetlanie elementów formularzy oraz hiperłączy (linków) do innych dokumentów bądź elementów aplikacji webowej.
- CSS – technologia służy do opisu, jak poszczególne elementy strony WWW mają wyglądać (m.in. jaki mają mieć kolor czy też jak mają być położone na stronie względem innych elementów).
- JavaScript – interpretowany przez jeden z mechanizmów przeglądarki (o czym więcej w dalszej części) język programowania służący do definiowania zachowania elementów strony w reakcji na akcje podejmowane przez użytkownika (np. kliknięcie elementu bądź wysłanie formularza). Drugim popularnym zastosowaniem JavaScriptu jest implementacja części logiki biznesowej aplikacji po stronie klienta (od niedawna także w całości po stronie serwerowej w przypadku wykorzystania serwera Node.js).
Oczywiście lista ta nie wyczerpuje zagadnienia. Często wykorzystywanym językiem jest XML oraz standardy implementowane w XML (np. grafika wektorowa w SVG). JSON (JavaScript Object Notation) jest sposobem zapisu danych w postaci obiektów języka JavaScript i jest wykorzystywany do wymiany danych pomiędzy aplikacją a serwerem. Pamiętajmy, że cały czas mówimy o technologiach obsługiwanych przez przeglądarkę, czyli część kliencką (nie zagłębiamy się w szczegóły strony serwerowej
Przyjrzyjmy się wymienionym wyżej technologiom nieco dokładniej.
1. HTML5, czyli hipertekstowy język znaczników w swojej najnowszej odsłonie
HTML5 (Hypertext Markup Language 5), który pojawił się kilka lat temu, a obecnie staje się standardem nie tylko, jeśli chodzi o aplikacje typowo webowe, czyli działające jedynie w przeglądarkach. Poza dobrze znanym językiem hipertekstowym HTML, HTML5 to tak naprawdę zbiór wielu, często nowych, technologii służących do budowy tzw. RIA (Rich Internet Application). Skrót ten oznacza aplikacje, które mogą komunikować się z użytkownikiem, wyświetlać elementy multimedialne, odtwarzać filmy czy umożliwiać ich nagrywanie. Służą do tego m.in. nowe elementy, takie jak <video> i <audio>; obsługa kamer i mikrofonów (UserMedia API), zdalna komunikacja pomiędzy przeglądarkami (WebRTC), geolokalizacja (Geolocation API), obsługa systemu plików (File API), obsługa gniazd sieciowych (Web Sockets) i wiele, wiele innych. Część z nich wymaga użycia języka JavaScript.
2. JavaScript
Język JavaScript, a właściwie ECMAScript wersja 5 (a wkrótce wersja 6, nad którą prace właśnie dobiegają końca), szturmem wdarł się na podium współczesnych języków programowania. Jego niesamowita popularność nie kończy się jedynie na stronach i aplikacjach internetowych. W ostatnich latach bardzo dynamicznie rozwijają się projekty, które albo wykorzystują JavaScript bezpośrednio, albo stanowią dla niego platformę do tworzenia aplikacji natywnych: Node.js, FirefoxOS, PhoneGAP, interfejs Metro w Windows 8, Gnome Shell w systemach linuksowych, Cinnamon w systemie Mint – to tylko część zastosowań tego niezwykle elastycznego, niesamowicie szybkiego i pozornie łatwego do opanowania języka.
Język, którego zastosowanie jeszcze do niedawna ograniczało się do prostego dodawania do przycisków czy linków niezbyt skomplikowanych efektów, tworzenia zegarków czy też walidacji pól formularza po stronie klienta, obecnie jest pełnoprawnym, zorientowanym obiektowo i opartym na dziedziczeniu prototypowym, skryptowym językiem o ogromnych możliwościach, na które składają się chociażby: frameworki wykorzystujące wzorce MVC czy MVVM, dzięki którym bez większych problemów można zaimplementować praktycznie dowolną aplikację (Backbone.js, AngularJS), biblioteki do testów jednostkowych czy end-to-end (QUnit, Jasmine, Mocca), systemy buildujące (Grunt), biblioteki do obsługi baz NoSQL (MongoDB) czy też relacyjnych, jak MySQL czy grafiki 3D (WebGL). Doczekał się nawet własnego serwera WWW wraz z całym systemem pakietów (Node.js oraz npm – Node Packaged Modules). Przykładem dużej aplikacji zbudowanej z wykorzystaniem jedynie wymienionych technologii (Node.js, Express.js) jest nowa wersja serwisu społecznościowego MySpace (http://expressjs.com/applications.html).
3. CSS3
Najnowsza wersja tzw. kaskadowych arkuszy stylów (Cascading Style Sheet) pełna jest nowych rozwiązań, które przenoszą współczesne aplikacje internetowe w zupełnie inny wymiar. Animacje, transformacje i dowolne przemieszczanie elementów drzewa DOM, cienie, gradienty, zaokrąglenia, możliwość dołączania własnych fontów to tylko wycinek możliwości, jakie dają nowe rozszerzenia CSS.
Kto za to wszystko odpowiada…
Jeszcze pod koniec lat 90-tych oraz na początku XXI wieku na rynku przeglądarek internetowych panował dość duży bałagan. Dwaj dominujący wtedy producenci przeglądarek (Microsoft oraz Netscape) dość swobodnie podchodzili do kwestii zgodności swoich produktów. Doszło do sytuacji, w którym każdy z nich posiadał własną implementację języka JavaScript (W przeglądarce Internet Explorer było to VB Script, który zresztą jest przez IE obsługiwany do dzisiaj ze względu na tzw. kompatybilność wsteczną). Każdy z producentów implementował również swoje własne elementy języka HTML czy też CSS, nie obsługiwane przez konkurencyjną przeglądarkę.
Życie webdevelopera, czyli programisty aplikacji internetowych (a raczej stron WWW, bo pojęcie aplikacji internetowej w takim rozumieniu jak dzisiaj, w tamtych czasach jeszcze nie istniało), było wyjątkowo trudne, bo wymagało często opracowywania dwóch różnych wersji tej samej strony i ręcznej detekcji przeglądarki. Tylko w ten sposób można było osiągnąć względnie jednakowy wygląd strony w każdej przeglądarce. Ci z Czytelników, którzy mieli styczność z tematyką webdevelopingu, na pewno znają uczucie towarzyszące np. zagadnieniu zgodności strony z przeglądarką IE 6.
Obecnie sytuacja wygląda zupełnie inaczej. Najwięksi producenci przeglądarek (Mozilla, Google, Microsoft, Opera i Apple) nadal opracowują własne rozszerzenia, ale każde z nich jest implementowane, prędzej bądź później, w każdej z pozostałych. Organizacja W3C (World Wide Web Consortium), stojąca obecnie na straży standardów przygotowuje propozycje, tzw. drafty, nowych rozwiązań i technologii, a następnie koordynuje pracę nad nimi przy współpracy wymienionych firm. W3C jest zorganizowana w tak zwane grupy robocze (Working groups), pracujące nad standardami, które następnie są rekomendowane i implementowane w przeglądarkach. Proces wdrażania nowej technologii, zanim stanie się właśnie takim standardem i znajdzie się oficjalnie w dokumentacji HTML5, CSS czy JavaScript, trwa często nawet kilka lat. Do tego należy doliczyć kilkumiesięczne opóźnienie w jego pełnej implementacji we wszystkich przeglądarkach (co wynika z ich cyklu wydawniczego oraz postępu prac nad silnikami renderującymi, o których za moment).
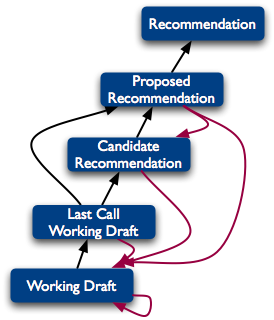
1. Proces powstawania i zatwierdzania standardu (W3C).
Oprócz W3C do czołowych kreatorów współczesnych technologii webowych należą Mozilla, Google oraz Apple. To te cztery wymienione firmy (dwie z nich to właściwie organizacje, a nie typowe korporacje: Mozilla i W3C) odpowiadają za to, co widzą miliardy internautów w swoich przeglądarkach.
1. Słowo o silnikach
Po tym dość długim wprowadzeniu pora przyjrzeć się działaniu samej przeglądarki. Wbrew pozorom za wyświetlenie strony internetowej nie jest odpowiedzialna sama przeglądarka, a zespół współpracujących ze sobą komponentów znanych pod nazwą “silnika renderującego” (rendering engine). To on odpowiada za przetworzenie kodu HTML/XML w drzewo DOM, nadanie elementom odpowiedniego wyglądu przy pomocy arkuszy CSS, dołączenie zdjęć i grafiki wektorowej (SVG) i wreszcie przekazania do oprogramowania graficznego systemu, który ostatecznie wyświetla stronę na ekranie komputera (nie zajmuje się tym bezpośrednio sama przeglądarka).
Zupełnie osobny komponent parsuje i wykonuje kod JavaScript. To silnik-interpreter JavaScript. To on, wraz z silnikiem renderującym, generuje całość – kompletną, interaktywną aplikację internetową, którą użytkownik widzi i może obsługiwać w oknie przeglądarki.
| nazwa | wersja (lipiec 2013) | producent | silnik renderujący | silnik JavaScript |
| Firefox | 22 | Mozilla | Gecko | SpiderMonkey; od FF 22 OdinMonkey ze wsparciem dla asm.js |
| Chrome | 27 | WebKit (do wersji 27), Blink (od wersji 28) | V8 | |
| Internet Explorer | 10 | Microsoft | Trident | Chakra |
| Opera | 15.0 | Opera | Presto (do wersji 12.15), Blink (od wersji Opera Next/Opera 15.0) | Carakan |
| Safari | 6.0.5 | Apple | WebKit | JavaScriptCore (Nitro) |
1. Zestawienie silników renderujących oraz JavaScript w najpopularniejszych przeglądarkach.
2. Proces renderowania strony WWW
Proces renderingu strony WWW prześledzimy od momentu kliknięcia przez użytkownika w link, bądź wpisania adresu strony w pasku adresu i naciśnięcia przycisku ‘Enter’.
Pierwszym etapem jest tzw. zdarzenie “unload” (“wyładuj” stronę). Polega ono na usunięciu z aktywnej karty (okna przeglądarki) aktualnie wygenerowanego tam dokumentu (strony) WWW. Następnie przeglądarka odczytuje URL z paska adresu bądź klikniętego odsyłacza (linku).
Jeśli dokument nie zostanie znaleziony w pamięci cache przeglądarki (pamięci podręcznej – przechowywane są tam wygenerowane wcześniej, czyli odwiedzone dokumenty WWW. Ma to na celu przyspieszenie ich ponownego wyświetlenia, bez udziału serwera), ta nawiązuje połączenie z serwerem DNS, aby rozwiązać nazwę domenową. Następnie dokonywane jest połączenie TCP z uzyskanym adresem IP. Po pomyślnym nawiązaniu połączenia, zostaje wykonana odpowiednia metoda protokołu HTTP (najczęściej wykorzystywanymi są GET, POST, PUT oraz DELETE, pozostałych w zasadzie nie spotyka się w produkcyjnych aplikacjach. O pozostałych metodach HTTP, a także więcej informacji na temat samego protokołu można znaleźć w dokumencie RFC 2616, będącym jego oficjalną specyfikacją. O protokole HTTP będę jeszcze wspominał nie raz w kolejnych artykułach.).
Jest to tzw. wysyłanie żądania, czyli ‘request’ (żądanie). Po tej fazie następuje pobranie odpowiedzi od zdalnego zasobu (serwera WWW) – czyli faza ‘response’ (odpowiedź). Cały proces trwa, w zależności od przepustowości sieci, od kilkudziesięciu do kilkuset milisekund.

2. Schemat pojedynczego żądania wywołanego w przeglądarce.
Do przeglądarki zaczynają napływać pierwsze bajty odpowiedzi. Kod HTML jest parsowany na bieżąco, tak samo traktowany jest kod JavaScript (z tego powodu powinien on znaleźć się na końcu dokumentu, tuż przed zamykającym znacznikiem <body>. Ma to na celu jego wczytanie i wykonanie dopiero, gdy cały dokument HTML zostanie już pobrany, bo z reguły kod JavaScrit dokonuje manipulacji na gotowym drzewie DOM), natomiast kod CSS – dopiero po zakończeniu ładowania całego dokumentu HTML. Proces rozwiązywania nazwy domenowej, nawiązywania połączenia TCP i wysyłania żądania powielany jest dla każdego pojedynczego zasobu, wchodzącego w skład strony WWW – plików HTML, CSS, JavaScript, grafik itp. Dlatego im więcej takich zasobów, tym wczytywanie strony i jej renderowanie w oknie przeglądarki trwa dłużej, ale jest to tylko i wyłącznie wina wielu następujących po sobie cykli pełnego nawiązywania połączenia (faza DNS, TCP, żądania i odpowiedzi) z całym wynikającym z nich narzutem czasowym.
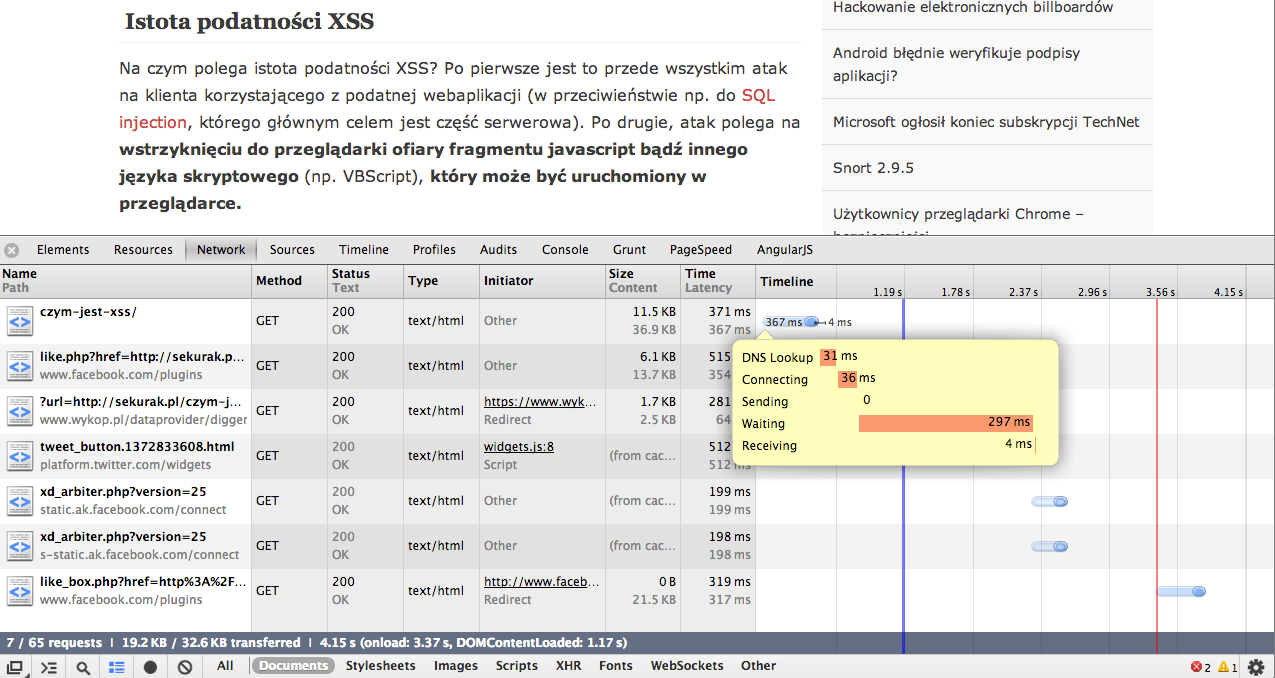
3. Realne czasy wykonania przykładowego żądania na przykładzie dokumentu http://sekurak.pl/czym-jest-xss/. Od 1,19 sek. rozpoczyna się generowanie strony WWW (pionowa niebieska linia na wykresie), po nieco ponad 2 sekundach kod HTML jest już w pełni załadowany (pionowa czerwona linia – wraz z poprzednią wyznaczają tzw. DOM Content Loading, czyli czas ładowania kodu HTML i budowania z niego drzewa DOM strony internetowej). 31 milisekund zajęła faza DNS, łączenie ze zdalnym serwerem kolejne 36 milisekund. 297 milisekund trwało oczekiwanie na odpowiedź serwera.
Parsowanie kodu HTML składa się z kilku faz: dekodowania kodu bajtowego, analizy tokenowej (rozpoznanie typu elementu HTML) i składniowej, które kończą się zbudowaniem drzewa DOM elementów strony.
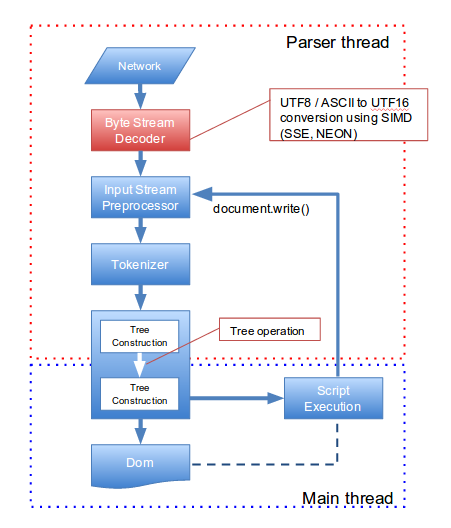
3. Proces parsowania kodu HTML.
Drzewo DOM (Document Object Model) to struktura drzewiasta symbolizująca układ elementów strony. Elementem głównym (root) jest <html>, wszystkie kolejne elementy tworzą zależności dzieci-rodzic (np. element <table> jest rodzicem dla kilku wierszy tabeli, czyli elementów <tr>. Z kolei w każdym wierszu istnieje wiele dzieci nadrzędnych elementów <tr>, czyli komórki tabeli – elementy <td>).
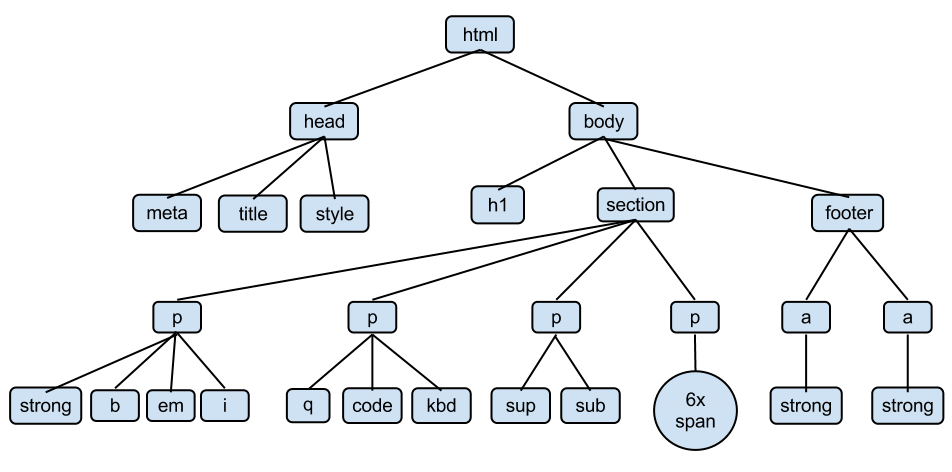
4. Przykład struktury drzewiastej DOM strony WWW w HTML.
Po analizie i parsowaniu kodu CSS elementom drzewa DOM jest nadawany wygląd, zgodnie z regułami zawartymi w arkuszach stylów, oraz są one rozmieszczane względem siebie. Całość tworzy tzw. “render tree” (drzewo renderingu), które ostatecznie jest wyświetlane w oknie przeglądarki (tzw. faza “painting”, czyli “odmalowywania”, bądź po prostu rysowania strony w oknie przeglądarki).
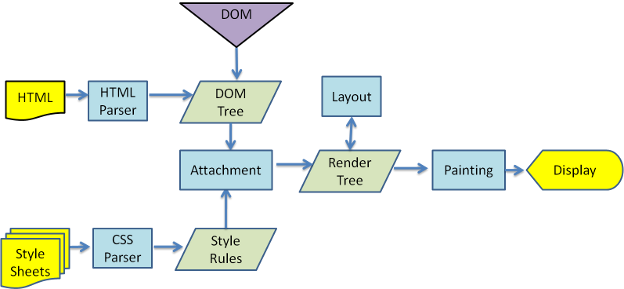
5. Proces generowania dokumentu w przeglądarce opartej na silniku WebKit (Google Chrome, Chromium, Safari).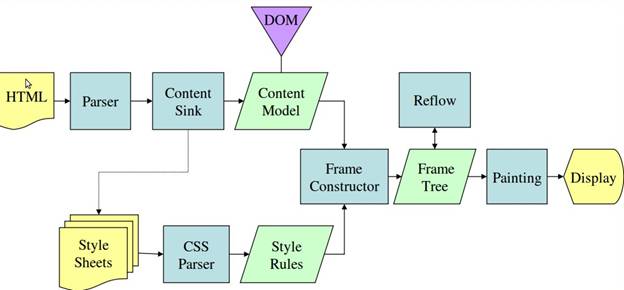
6. Proces generowania dokumentu w przeglądarce opartej na silniku Gecko (Mozilla Firefox, Iceweasel).
Cały opisany proces w optymalnych warunkach, przy założeniu prawidłowo skonstruowanego dokumentu, powinien wykonać się w maksymalnie 1000 ms (1 sekunda). Jest to czas, po którym statystyczny internauta zauważa już tzw. opóźnienie w ładowaniu strony i zaczyna wykazywać pierwsze oznaki zniecierpliwienia. :)
3. Nowe elementy przeglądarek
Wraz z HTML5 w przeglądarkach pojawiło się sporo nowości. W obszarze zainteresowania specjalistów od bezpieczeństwa oraz wszelkiej maści intruzów znalazły się głównie nowe mechanizmy przechowywania danych po stronie klienta: LocalStorage, SessionStorage czy WebSQL. O niebezpieczeństwach z nimi związanych dość obszernie napisał na łamach portalu Sekurak.pl Adrian “Vizzdom” Michalczyk. Zainteresowanych odsyłam jeszcze raz do tego doskonałego, 3-częściowego opracowania: Bezpieczeństwo HTML5 – podstawy.
Co dalej
Celem niniejszego artykułu było wprowadzenie Czytelników Sekuraka w bardzo obszerny zakres zagadnień, z jakimi współcześnie codziennie stykają się programiści aplikacji internetowych (w tym autor niniejszego cyklu). W szczególności dotyczy to tzw. aplikacji SPA (Single Page Application) opartych w całości na JavaScript (zarówno po stronie klienckiej, jak i serwerowej).
W kolejnych artykułach postaram się przybliżyć następujące zagadnienia:
- bezpieczeństwo aplikacji opartych na serwerze Node.js,
- problemy z bezpieczeństwem pakietów npm (Node Packaged Modules),
- bezpieczeństwo aplikacji server-side wykorzystujących framework Express.js,
- bezpieczeństwo aplikacji korzystających z baz NoSQL, zbudowanych w oparciu o Node.js,
- niebezpieczeństwa związane z aplikacjami RESTful zbudowanymi w oparciu o frameworki Backbone.js i AngularJS.
Ponieważ tematyka związana z bezpieczeństwem aplikacji w całości zbudowanych na technologiach wykorzystujących JavaScript (czyli wymienionych powyżej) jest zupełnie nowa, liczę na to, że wraz z Czytelnikami portalu Sekurak.pl uda się w toku dyskusji w kolejnych artykułach opracować wiele nowych metod zapobiegania atakom na takie aplikacje czy zabezpieczania ich przed najczęściej występującymi zagrożeniami.
Wbrew pozorom problemy dotykające te aplikacje są nie tylko stricte webowe – oprogramowanie RESTful (i nie tylko), napisane jedynie w JavaScript z wykorzystaniem stosu technologicznego HTML5 można dziś spotkać między innymi:
- w środowiskach graficznych systemów Linuksowych, np. Gnome (Shell) oraz Cinnamon,
- w aplikacjach dla Metro systemu Windows 8,
- w aplikacjach na urządzenia mobilne,
- w systemach operacyjnych (ChromeOS, FirefoxOS),
- w telewizorach (SmartTV),
- w urządzeniach AGD, samochodach i wielu, wielu innych, w których coraz częściej pojawiają się ekrany LCD oraz możliwość tworzenia aplikacji na te urządzenia.
Era informacji, której narodzin jesteśmy świadkami, oraz era urządzeń połączonych ze sobą w jedną, wielką sieć, stawia nowe wyzwania, kto wie, czy nie największe od czasu powstania komputerów, także przed osobami dbającymi o bezpieczeństwo. To, czego jesteśmy świadkami w ostatnich dwóch latach (wzrost popularności HTML5 i JavaScript) to zapewne preludium do prawdziwej cyfrowej rewolucji, która czeka nas w perspektywie kolejnych kilku bądź kilkunastu lat. Dobrze, byśmy zdawali sobie sprawę z czyhających zagrożeń oraz potrafili sobie z nimi radzić. A o szczegółach już w kolejnych opracowaniach.
Źródła
- Opera
- Google Chrome
- Mozilla Firefox
- Apple Safari
- “How Browsers Work: Behind the scenes of modern web browsers” – bardzo szczegółowa analiza procesu renderowania strony WWW (Tali Garsiel, Paul Irish)
- http://www.webkit.org/ – strona domowa projektu WebKit
- How WebKit Loads a Web Page – jak WebKit ładuje stronę WWW
- How WebKit works – Adam Barth (abarth)
- system operacyjny Chrome OS
- specyfikacja protokołu HTTP
–Rafał ‘bl4de’ Janicki (bloorq[at]gmail.com)

Zarąbisty.
Jak zwykle świetny tekst. Boli mnie tylko to, że w Polsce (na zachodzie jest lepiej) panuje ogromna ignorancja co do wiedzy nt. działania internetu. Najwięcej wśród dziewczyn niestety , raz delikatnie powiedziałem kilku paniom, że skoro siedzi się po 10h w sieci to wypadałoby poznać jej podstawy i wiedzieć jak dbać o swoje dane zostałem określony baranem i pewnie nie mam przyjaciół skoro mnie to interesuje [ :-) ]
@dll: akurat na zachodzie jest o wiele gorzej niż w Polsce pod tym względem, tam dla wielu ludzi Internet Explorer, wciąż znaczy “internet”. Za to dość sporą wiedzę mają ludzie (nawet dziewczyny) z Rosji czy Turcji – głównie dzięki… panującej tam cenzurze.
@dll
Dziękuję za miłe słowa :)
Niestety, ale masz całkowitą rację: bardzo niewiele osób ma jakiekolwiek pojęcie o działaniu sieci. W sumie nie ma co się dziwić, bo pojęcie zasad, na jakich opiera się internet, wymaga jednak sporo wiedzy (choćby protokół HTTP, ale do tego potrzebna jest wiedza o tym, co to jest “protokół” itd.)
czapki z głów, za ten art i całokształt sekuraka!
—
Przemek Skowron
:D Zachęcam do czytelników do podrzucania swoich tekstów :-)
–ms
bl4de, art naprawę fajnie napisany i dopracowany merytorycznie.
Poleciłem go kilku kolegom, dzięki czemu sekurak ma więcej czytelników ;).
Czekam na arty dot. Node.js! :)
:-D
Jest dobrze :)
Fajnie, że komuś się chce pisać takie rzeczy.
Tylko – poprawcie literówki, np. znalazły się __gównie__ nowe mechanizmy…
Pozdrawiam!!
Tekst już był po małej korekcie językowej, ale coś się jeszcze prześlizgnęło – dzięki!
–ms
Dziękuję wszystkim za lekturę :)
Postaram się, by w kolejnych tekstach literówki czy inne błędy się nie zdarzały :)
Temat stron internetowych i wszystkich technologii tym związanych świetnie nadaje się na artykuł opisujący co się dzieje gdy podejmiemy błędne decyzje projektowe na samym początku ;-) Praktycznie wszystko co związane z tematem stron internetowych to jest seria pomyłek. Mamy HTML który miał być językiem opisującym dokumenty tekstowe niczym DOC z Worda a teraz stał się dziwnym tworem opisującym interfejsy użytkownika. JavaScript miał być lekkim i prostym w implementacji językiem do drobnych głupot a nie poważnych zastosowań i w efekcie mamy dziś jeden z gorszych języków programowania z którym musimy się użerać. HTML miał być prostym sztandarem dostępnym dla każdego a dziś jego dokumentacja do tysiące stron a napisanie silnika od podstaw przerasta praktycznie każdą firmę :-/
Wow. Trafiłam tu z winy coders lab, ale z sekuraka już chyba nie wyjdę. Świetny artykuł, merytoryczny, choć krótki (a szkoda). Czekam na więcej :)
Ja też ;)
Przydała by się aktualizacja tekstu – chociaż o wersje silników i przeglądarek w tabelce.
bardzo fajny tekst, ale z 2013
Gdybyś dzis miał dopisać dwa zdania, jak brzmiałyby?
WOW!!! tekst mega konkret, merytoryczny, nawet czytany w 2022 robi duże pozytywne wrażenie !!!