W niniejszym artykule opisuję trzy XSS-y, które zgłaszałem do Google w tym roku w ramach ich programu
bug bounty. Wszystkie z nich miały swoje źródło w możliwości wyjścia z sandboksa w narzędziu Google Caja.
Wstęp
Na początku tego roku jako swój cel dla bug bounty postawiłem sobie znane wszystkim aplikacje z Google Docs. Jedną z wielu możliwości, które one oferują, jest możliwość definiowania skryptów za pomocą Google Apps Script. Te skrypty mogą być traktowane jaki swoisty odpowiednik makr z Microsoft Office’a. Możemy więc zdefiniować dodatkowe funkcje w naszych dokumentach, np. dodanie nowych funkcji w arkuszu kalkulacyjnym czy też nowych pozycji w menu procesora tekstu, które zautomatyzują najczęściej wykonywane przez nas operacje. Za pomocą Apps Script możemy też wyświetlać dodatkowe okna lub dodać pasek boczny (sidebar) ze swoimi funkcjami. Google ma na swoich stronach całkiem dobry wstęp do tego, co można zrobić.
Gdy dodajemy własne okna w aplikacji (niezależnie od tego czy jest to okno na pierwszym planie czy po prostu pasek boczny), mamy możliwość zdefiniowania własnego kodu HTML. Oczywiście, gdyby nadać twórcom skryptów możliwość dodawania całkowicie dowolnego HTML-a to możliwość zrobienia XSS-a byłaby oczywista, więc dodano też sandboksowanie. Obecnie programista może zdefiniować jeden z dwóch trybów sandboksowania w Apps Scripts:
- IFRAME – kod HTML wyświetlany jest w elemencie <iframe> w losowo wygenerowanej subdomenie domeny googleusercontent.com,
- NATIVE – kod HTML jest sandboksowany za pomocą funkcji oferowanych przez projekt Google Caja.
Google Caja (nazwa pochodzi od hiszpańskiego słowa oznaczającego pudełko, czyta się /kaha/) jest ogólnodostępnym projektem, który stara się zmierzyć z tym samym problemem, który pojawia się na Google Docsach: umożliwienie użytkownikom umieszczania na stronie własnego kodu HTML, JavaScript czy CSS, ale w taki sposób, żeby nie wpływać na bezpieczeństwo strony nadrzędnej. Krótko mówiąc: użytkownik z poziomu własnego skryptu nie powinien móc:
- Czytać ciasteczek z domeny, w której skrypt jest umieszczony,
- Uzyskać dostępu do drzewa DOM z nadrzędnej strony,
- Wykonywać zapytań http w kontekście swojej nadrzędnej domeny.
Tym samym wprowadzana jest ochrona przed najgroźniejszymi skutkami ataków XSS.
Caja wyglądała jak wdzięczny cel do analizy, bowiem jakiekolwiek wyjście z jej sandboksa oznaczało od razu XSS-a w domenie docs.google.com.
Twórcy tego narzędzia udostępnili stronę Caja Playground, na której można wpisać dowolny kod HTML i zobaczyć, w jaki sposób zostanie on przetworzony przez Caję. Właśnie w tym miejscu można było wygodnie sprawdzać i testować różne sposoby wychodzenia z sandboksa.
Co Caja robiła źle, rozdział I
Jedną z bardzo wielu rzeczy, które Caja robiła tuż przed uruchomieniem kodu JavaScript pochodzącego od użytkownika, była analiza tego kodu pod kątem występowania w nich ciągów znaków, które mogą być nazwami zmiennych. Następnie wszystkie te nazwy były usuwane z globalnej przestrzeni nazw JavaScriptu lub były podmieniane na obiekty odpowiednio zmodyfikowane przez Caję. Gdy więc próbowaliśmy się dostać do window, to nie otrzymywaliśmy prawdziwego obiektu window, a pewien obiekt typu proxy, w którym wywołanie każdy obiekt i każda metoda była zastąpiona przez odpowiednie właściwości dostarczane przez Caję. Dzięki temu nie mieliśmy dostępu do prawdziwego drzewa DOM strony.
Naturalnym pomysłem, który pojawia się przy stwierdzeniu, że Caja analizuje kod kątem występowania ciągów znaków, jest próba obfuskacji tego ciągu. Czyli na przykład nie piszmy window, ale np. Function(“win”+”dow”) (celowo nie użyłem eval, ponieważ w przestrzeni nazw Cajy nie ma tej funkcji). Okazuje się jednak, że kod odpowiedzialny za wyszukiwanie tych ciągów znaków jest uruchamiany w każdym miejscu, w którym istnieje możliwość podania własnego kodu HTML/JavaScript jako string. Czyli wszystkie innerHTML czy konstruktory Function() czy też jakiekolwiek inne metody – odpadają.
Okazało się jednak, że twórcy Cajy przeoczyli możliwość wykorzystania innej, dość prostej cechy JavaScriptu… W każdym języku programowania istnieją sposoby na escape’owanie znaków w ciągu znaków. W JavaScripcie możemy używać albo sposobu odnoszącego się do bajtów, czyli np. “Tutaj jest cudzysłów: \x22” albo też sposobu odnoszącego się do znaków Unicode’u: “Tutaj jest cudzysłów: \u0022”. Specyficzną cechą JavaScriptu jest to, że tego drugiego sposobu można używać także w identyfikatorach. A więc zamiast window możemy napisać \u0077indow. I tylko tyle wystarczyło, by ominąć zabezpieczenia Cajy! Kod odpowiedzialny za wyszukiwanie identyfikatorów nie brał pod uwagę różnych sposobów zapisania tego samego identyfikatora, w związku z czym użycie \u0077indow dawało dostęp do prawdziwego obiektu window, a w konsekwencji można było uciec z sandboksa.
Zobaczmy więc jak wyglądało wykorzystanie tego w Google Docs. Po pierwsze należało stworzyć nowy dokument, a następnie przejść do opcji: Tools->Script Editor. Tam wkleić następujący kod skryptu:
function onOpen(e) { showSidebar(); }
function onInstall(e) { showSidebar(); }
function showSidebar() {
var payload = '<script>\\u0077indow.top.eval("alert(document.domain)")</script>';
var ui = HtmlService.createHtmlOutput(payload)
.setSandboxMode(HtmlService.SandboxMode.NATIVE)
.setTitle('XSS');
DocumentApp.getUi().showSidebar(ui);
}
W linii szóstej widzimy zmienną payload, w której zastosowana została sztuczka opisana powyżej. Po zapisaniu skryptu i odświeżeniu strony z dokumentem zobaczyliśmy to co na rysunku 1.
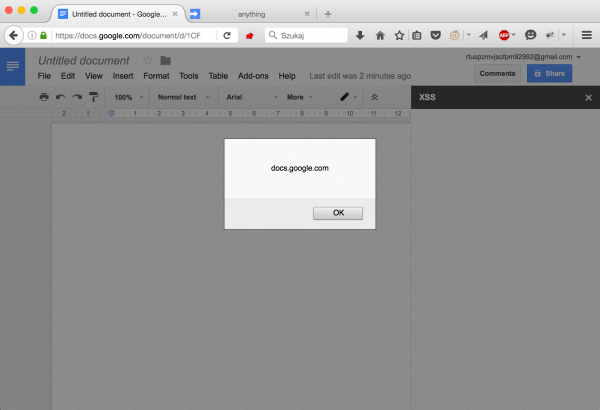
Rys 1. XSS w docs.google.com
Voila! Jest XSS w domenie docs.google.com, który można było zgłosić do Google’a i zgarnąć za to bounty.
Co Caja robiła źle, rodział II
Po jakichś dwóch tygodniach Google naniosło poprawkę na zgłoszony przeze mnie błąd. Poprawka ta robiła tylko tyle, że brała pod uwagę również fakt, że w identyfikatorach mogą się pojawić encje \uXXXX i dekodowała je przed próbą “usunięcia” ich z globalnej przestrzeni nazw. To rzeczywiście dobre rozwiązanie. Ale czy wystarczające?
Niedawno wprowadzony standard ECMAScript 6 wprowadził jeszcze jeden sposób escape’owania znaków specjalnych w identyfikatorach i ciągach znaków, wyglądający tak: \u{XXX…}. Jaki w ogóle był sens wprowadzania takiego udziwnienia? W starym sposobie nie wszystkie znaki dało się zapisać za pomocą jednej sekwencji UTF-16. Na przykład znak Emoji z uśmiechniętą mordką (?) należało zapisać jako “\ud83d\ude00” (może się więc wydawać, że są to dwa znaki). Teraz wystarczy tylko “\u{1f600}”.
Polecam świetną prezentację Mathiasa Bynensa pt.
Hacking with Unicode, w której autor pokazuje rozmaite problemy, jakie wynikają z niewłaściwego rozumienia Unicode’u przez programistów.
Podobnie jak sekwencją znaków \uXXXX, tak i \u{XXX…} może być również używana w identyfikatorach (z nowoczesnych przeglądarek nie wspiera tego jeszcze tylko Firefox). Zatem uzyskujemy jeszcze jeden sposób na dostanie się do głównego obiektu w przeglądarkowym JavaScripcie, mianowicie: \u{77}indow. Mogłoby się więc wydawać, że wystarczy zmodyfikować trochę mój poprzedni przykład, zamienić \u0077indow na \u{77}indow i będzie kolejny XSS. Rzeczywistość jednak nie okazała się aż tak prosta, bo Caja ma wbudowany swój własny parser JavaScriptu, działający w oparciu o standard ECMAScript 5. Dla niej więc zapis \u{77}indow był błędem składniowym, co zresztą potwierdzał błąd wyświetlany przy próbie wpisania takiego kodu.
Uncaught script error: 'Uncaught SyntaxError: Failed to parse program: SyntaxError: Bad character escape sequence (2:2)' in source: 'https:/' at line: -1
Parserem, którego używała Caja był acorn. I na całe szczęście, okazało się, że w parserze jest błąd, który umożliwia przemycenie dowolnego kodu zgodnego z ECMAScript 6. A było to możliwe dzięki… komentarzom.
Zasadniczo w JavaScripcie istnieją dwa sposoby na dodawanie komentarzy do kodu. Oba sposoby są znane z C/C++ i pojawiają się w licznych językach programowania. Mamy więc komentarz liniowy (// komentarz do końca linii…) i komentarz blokowy (/* to jest komentarz */). JavaScript przeglądarkowy dodaje jednak dwa kolejne sposoby komentowania, które nadal działają ze względu na kompatybilność wsteczną. Oba wyglądają jak komentarze rodem z HTML-a czy XML-a, bowiem są to: <!– i –>. Różnica jest taka, że o ile z HTML-a i XML-a kojarzymy, że komentarz zaczynający się od <!– musi zostać później zamknięty przez –>, tak w JavaScripcie oba komentarza są komentarzami liniowymi! Co ciekawe, by sekwencja znaków –> zadziałała jako komentarz, to przed nimi w linii mogą się znajdować wyłącznie białe znaki. Podsumowując, poniżej przedstawiono kod, który jest poprawny w kontekście JavaScriptu w przeglądarkach.
alert(1) <!-- komentarz liniowy
--> to również jest komentarz liniowy, bo wcześniej występują tylko białe znaki
Wspomniany wcześniej parser JavaScriptu – acorn – brał pod uwagę możliwość występowania w kodzie takich komentarzy. Spójrzmy na jego fragment kodu:
if (next == 33 && code == 60 && input.charCodeAt(tokPos + 2) == 45 &&
input.charCodeAt(tokPos + 3) == 45) {
// `<!--`, an XML-style comment that should be interpreted as a line comment
tokPos += 4;
skipLineComment();
skipSpace();
return readToken();
}
Mamy fragment kodu odpowiedzialnego za wykrywanie komentarzy <!–. Zmienna tokPos, w skrócie mówiąc, zawiera aktualną pozycję kodu JS, która jest przetwarzana. Widzimy w linii 628, że wartość tej zmiennej jest zwiększana o cztery. Ma to sens, bo pomijane są cztery znaki rozpoczynające komentarz (czyli <!–). Następnie zaś wywoływana jest metoda skipLineComment.
function skipLineComment() {
var start = tokPos;
var startLoc = options.onComment && options.locations && new line_loc_t;
var ch = input.charCodeAt(tokPos+=2);
while (tokPos < inputLen && ch !== 10 && ch !== 13 && ch !== 8232 && ch !== 8233) {
++tokPos;
ch = input.charCodeAt(tokPos);
}
if (options.onComment)
options.onComment(false, input.slice(start + 2, tokPos), start, tokPos,
startLoc, options.locations && new line_loc_t);
}
Problem widzimy w zaznaczonej linii 502. Autor parsera implementując metodę skipLineComment najprawdopodobniej założył, że jedynym komentarzem liniowym w JavaScripcie jest // dlatego znów zwiększa wartość zmiennej tokPos o dwa. I dopiero potem szuka wystąpienia znaku nowej linii, która zakończy komentarz. Jaki jest tutaj problem? Jeżeli jednym z dwóch znaków znajdujących się bezpośrednio za <!– będzie znak nowej linii, to parser nie “zauważy” go, w efekcie będzie myślał, że cała następna linia jest komentarzem.
Jeśli więc zapodamy następujący kod JavaScript:
<!--
\u{77}indow.top.eval('alert(document.domain)')
To z punktu widzenia parsera będzie to wyglądało tak, że cała ta druga linia znajduje się w komentarzu. Dzięki temu możemy tam wrzucić kod zgodny z ECMAScript6, na którym parser nie wyświetli błędu w składni i w ten sposób zdobywamy kolejnego XSS-a w Google Docs. Oto nowy payload:
function onOpen(e) { showSidebar(); }
function onInstall(e) { showSidebar(); }
function showSidebar() {
var payload = '<script><!--\n\\u{77}indow.top.eval("alert(document.domain)")</script>';
var ui = HtmlService.createHtmlOutput(payload)
.setSandboxMode(HtmlService.SandboxMode.NATIVE)
.setTitle('XSS');
DocumentApp.getUi().showSidebar(ui);
}
Zmieniona została tylko linia nr 6. Na samym początku mamy komentarz <!–, za którym znajduje się znak nowej linii, a następnie mamy wykorzystaną tę sztuczkę z \u{77}indow. XSS znowu się wykonał, wpadło kolejne bounty.
Po dwóch tygodniach Google znowu wprowadziło poprawkę do Cajy, tym razem już bardziej uniwersalną, chroniącą przed dalszymi atakami polegającymi na zapisywaniu tego samego identyfikatora na różne sposoby. Wydawało się, że studnia błędów z Cajy już się wyczerpała.
Co Google zrobiło źle
Gdy minęły jakieś dwa miesiące od wdrożenia tej poprawki, jeszcze raz przyjrzałem się różnym miejscom, w których Google korzysta z Cajy. Jednym z nich jest strona Google Developers, na której znajdują się wskazówki dla programistów o tym, w jaki sposób należy korzystać z Cajy. Google umieściło też kilka aplikacji demo z przykładami. Ciekawie wyglądającym przykładem był ten: https://developers.google.com/caja/demos/runningjavascript/host.html. Na tej stronie mogliśmy podać swój własny adres URL do skryptu JS, który był pobierany i uruchamiany w środowisku Cajy. Problem w tym, że ta strona nadal odnosiła się do starej wersji Cajy – tej, w której działały jeszcze te wyjścia z sandboksa, o których pisałem w poprzednich akapitach! Jeśli więc wpisałem w polu tekstowym po prostu data:,\u0077indow.top.alert(1) to wykonał się XSS w kontekście domeny developers.google.com (Rys 2.).
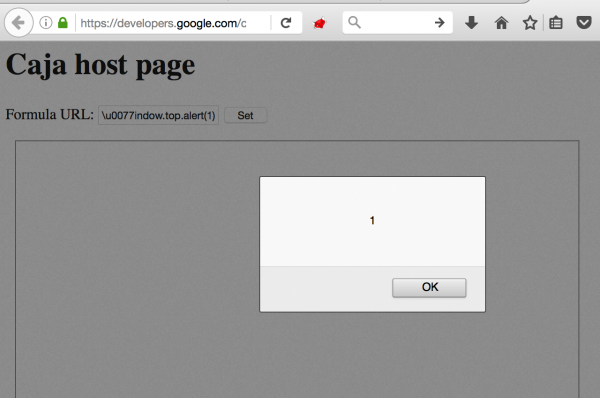
Rys 2. “Self-XSS” w developers.google.com
Nie mogłem jednak jeszcze na tym etapie zgłosić tego problemu do Google. Żeby wykorzystać tego XSS-a, użytkownik musiałby sam w polu Formula URL wpisać złośliwy kod JS, który miałby następnie zostać wykonany. Jako że jest to dość mało prawdopodobna interakcja użytkownika, trzeba było tutaj wymyślić lepszy sposób.
Z dużą pomocą przyszedł fakt, że na wyżej wymienionej stronie nie był stosowany nagłówek X-Frame-Options. Dzięki temu istniała możliwość umieszczenia tej strony w elemencie <iframe> i skorzystania z mechanizmu drag-n-drop, by niczego nieświadomy użytkownik sam przeciągnął payload XSS-owy na stronę developers.google.com, a następnie go wykonał.
Taka sztuczka działa tylko w Firefoksie i przypomina ataki clickjackingowe. Zacznijmy jednak od początku. W HTML5 możemy zdefiniować element jako “przeciągalny” dodając do niego atrybut draggable=true. W drugiej kolejności musimy obsłużyć przeciąganie przypisując funkcję do zdarzenia ondragstart. W moim przypadku obsługa tego zdarzenia wyglądało następująco:
<script>
function drag(ev) {
ev.dataTransfer.setData("text", "data:,\\u0077indow.eval('alert(document.domain)')//");
}
</script>
W ten sposób sprawiamy, że po upuszczeniu tego elementu na innej stronie lub w innej aplikacji, w miejscu upuszczenia zostanie umieszczony tekst data:,\u0077indow.eval(‘alert(document.domain)’)//.
Przekonanie użytkownika, by przeciągnął nasz element w pożądane miejsce też nie jest trudne. Wystarczy stworzyć odpowiedni opis, np. że może wygrać miliony dolarów, a w rzeczywistości umieścić pod stroną niewidzialnego iframe’a, gdzie użytkownik przeniesie payload XSS-owy, a następnie go wykona.
Cały kod HTML-owy wyglądał następująco:
<script>
function drag(ev) {
ev.dataTransfer.setData("text", "data:,\\u0077indow.eval('alert(document.domain)')//");
}
</script>
<div id=target1 style="background-color:blue;width:10px;height:60px;position:fixed;left:322px;top:117px;"></div>
<div id=target2 style="background-color:green;width:120px;height:60px;position:fixed;left:325px;top:194px;"></div>
<div style="font-size:60px;background-color:red;color:green;width:10px;height:60px" draggable=true ondragstart=drag(event) id=paldpals>.</div>
<br><br>
<iframe src="https://developers.google.com/caja/demos/runningjavascript/host.html?" style="width:150px; height:500px; transform: scale(4); position:fixed; left:500px; top:350px; opacity: 0; z-index: 100"></iframe>
Zaś poniżej pokazano, że atak w rzeczywistości działał.
[youtube_sc url=”https://www.youtube.com/watch?v=8pexfeElNCM”]
Kaboom! Dzięki temu wpada kolejne bounty :)
Podsumowanie
Google Caja to projekt, którego zadaniem jest pozwolenie użytkownikom na używanie własnego kodu HTML/JS/CSS w kontekście innej witryny. W założeniu ten kod powinien być odpowiednio izolowany od oryginalnego drzewa DOM. Dzięki znalezieniu sposobów na wyjście z sandboksa, a także błędu w parserze JS używanego przez Caję, udało się wykonać dwa XSS-y w domenie docs.google.com. Później, ze względu na przeoczenie Google’a i niezaktualizowanie Cajy na wszystkich stronach, które z niej korzystają, możliwe było wykonanie XSS-a w domenie developers.google.com, korzystając ze sztuczki z nadużyciem drag-n-drop, która działa tylko w Firefoksie. Summa summarum właściwie jeden błąd w Google Caja dostarczył trzech oddzielnych bounty za XSS-y.
– Michał Bentkowski, pentester w Securitum


Wszystkie z nich miały swoje źródło w możliwości wyjścia z [sanboksa -> sanDboxa] zapewne autocorrect :]
Naprawione.
To jeszcze “wyglądać miliony dolarów” :)
Tak czy tak, dzięki za świetny artykuł. Napiszesz też wersję anglojęzyczną? Byłoby przydatne u mnie w pracy.
Poprawiłem ;)
Angielska wersja na pewno będzie, ale jeszcze nie wiem kiedy. Wrzucę ją na swojego bloga.
Z ciekawości – możesz się pochwalić, ile wyniosły poszczególne nagrody? ?
Zapewne 3* $5000
Za domenę docs.google.com było po $5000, a za developer.google.com: $3133,7.
A teraz powiedz ile zarobiles.
Łebski z Ciebie gość Panie Michale. :D
Wielkie propsy za te bugi ;-)
‘Ile zarobiłeś’ – cóż za małostkowość!
Wlaściwe pytanie powinno brzmieć ‘ile satysfakcji z tego wyniosłeś’, ewentualnie ‘jak wpiszesz to do CV’ ;)
Gratulacje, takie informacje od rodaków są budujące.
Racja @lisu! :D I to w każdym zdaniu.
Pozdrawiam