Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej

Translacja poleceń CLI na operacje w interfejsie graficznym nie powinna stanowić problemu, ponieważ ścieżki w drzewie konfiguracji oraz nazwy pól są prawie zawsze niemal identyczne. Przykładowo, gałąź /ip firewall filter odpowiada oknu IP > Firewall > Filter Rules w interfejsie graficznym. Częstą praktyką jest dodanie reguł (np. ze skryptu lub kopii zapasowej) przez terminal i dalsza praca nad nimi przez WinBoxa.
Reguły filtrowania dodajemy w drzewie konfiguracji /ip firewall filter. Domyślną polityką w RouterOS jest akceptowanie pakietów, zatem przy pustej konfiguracji żadne pakiety nie są blokowane. Pusta konfiguracja nie oznacza domyślnej konfiguracji, bo dla większości routerów domyślny jest zestaw reguł blokujących dostęp z sieci WAN (szczegółowe informacje o domyślnej konfiguracji w zależności od płyty RouterBoard znajdują się na stronie z dokumentacją MikroTika). W niniejszym tekście za punkt wyjścia przyjmujemy pustą listę reguł. W razie potrzeby domyślnie dodane reguły możemy wyczyścić poleceniem:
[admin@MikroTik] > ip firewall filter remove [find]
Dodając nową regułę, możemy określić szereg (około 50) jej właściwości. Podzielmy te pola na trzy kategorie:
Pełna lista pól wraz z ich opisem dostępna jest w Wiki MT:
Wybór łańcucha (pole chain) to pole obligatoryjne. Odpowiada za to, jakiego rodzaju ruchu i na którym etapie przetwarzania może dotyczyć reguła. Mamy do wyboru trzy łańcuchy predefiniowane:
Zakres działania łańcuchów predefiniowanych jest rozłączny. Innymi słowy, dany pakiet może być przetwarzany tylko w obrębie jednego z ww. łańcuchów.
System pozwala na definiowanie własnych łańcuchów. Używane są one do zwiększenia efektywności oraz czytelności firewalla.
Pól warunkowych w konfiguracji reguły jest zdecydowanie najwięcej, natomiast żadne z nich nie jest obligatoryjne. Pola te określają warunki, jakie musi spełniać pakiet, aby podlegać zdefiniowanej przez regułę akcji. Najczęściej używane pola określają źródłowy/docelowy adres w nagłówku pakietu IP (src-address, dst-address), protokół i porty (protocol, src-port, dst-port), stan połączenia (connection-state).
Podstawowe pole tej grupy to action (domyślnie accept). Określa ono, co ma się stać z pakietem, który należy do wybranego łańcucha i spełnia określone pola warunkowe. Podstawowe akcje to:
Akcje add-src-to-address-list i add-dst-to-address-list powodują dynamiczne dodanie adresu (źródłowego – src, lub docelowego – dst) zapisanego w nagłówku przetwarzanego pakietu IP do listy adresów o nazwie określonej dodatkowym parametrem (address-list). Dodatkowo, możemy określić czas timeout, przez jaki wpis do listy adresów ma być aktywny. Jest to dość praktyczny mechanizm, dalej w tekście przedstawiamy przykład jego użycia.
Pozostałe pola tej grupy mają zastosowanie tylko do konkretnych akcji, np. pole address-list jest stosowne tylko dla akcji add-src-to-address-list oraz add-dst-to-address-list.
Reguły są przetwarzane sekwencyjnie. Pakiet najpierw jest przetwarzany przez pierwszą (od góry) regułę na liście. Jeżeli należy do określonego łańcucha oraz spełnia kryteria ustawione w polach warunkowych, to aplikowana jest przypisana do reguły akcja i pakiet nie jest już przetwarzany przez kolejne reguły (chyba, że ustawiona akcja to passthrough lub jump). Warunki ustawione w regule rozpatrywane są łącznie, więc jeśli pakiet nie spełnia przynajmniej jednego z nich, to akcja nie jest stosowana i pakiet jest przekazywany do rozpatrzenia przez kolejną regułę. Jeżeli żadna z reguł nie złapie pakietu, to stosowana jest akcja domyślna, czyli accept.
Wiemy już jak działają reguły filtrowania i jak je dodawać. Zastanówmy się teraz, jak zbudować dobry zestaw reguł. Dobry – czyli realizujący zakładaną politykę, optymalizujący wykorzystanie procesora oraz przejrzysty i wygodny w zarządzaniu.
Poniżej przedstawiamy zestaw wskazówek, które pomogą ten cel osiągnąć.
Jeśli nie zostało to wcześniej wykonane, budowanie firewalla zacznij od ustalenia i przemyślenia polityki, jaką firewall powinien realizować. Można ją zapisać w postaci np. listy zasad lub macierzy, która obrazuje, jaka komunikacja pomiędzy jakimi sieciami jest dozwolona (przykład poniżej).

Wszystko należy upraszczać jak tylko można, ale nie bardziej.
– genialna wskazówka Alberta Einsteina uchroni nas od wielu błędów i ułatwi pracę nad regułami w przyszłości.
Są dwa standardowe podejścia do konstrukcji reguł. Pierwsze polega na tym, że tworzymy zestaw reguł blokujących niepożądany ruch, pozwalając pakietom autoryzowanym na dojście do końca listy, gdzie czeka na nie zdefiniowana (lub domyślna, niejawna) reguła typu accept.
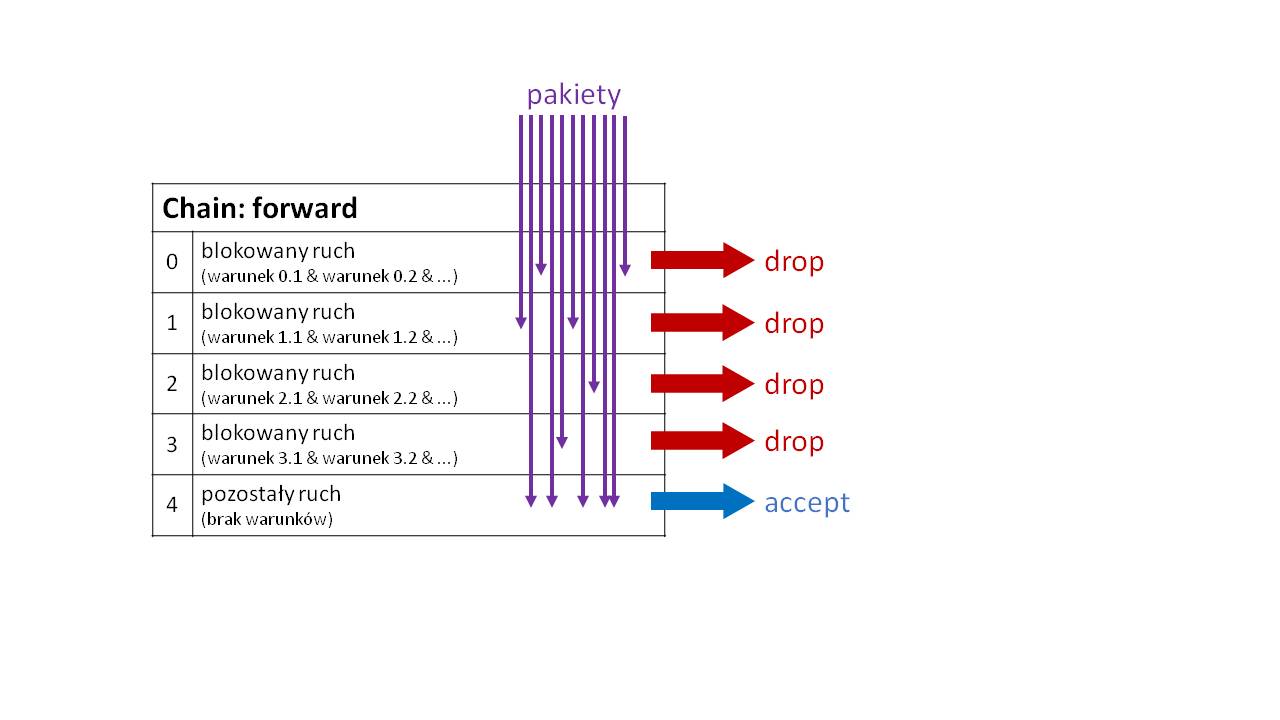
Drugie podejście jest odwrotne: definiujemy reguły określające autoryzowany ruch, a pozostały blokujemy.
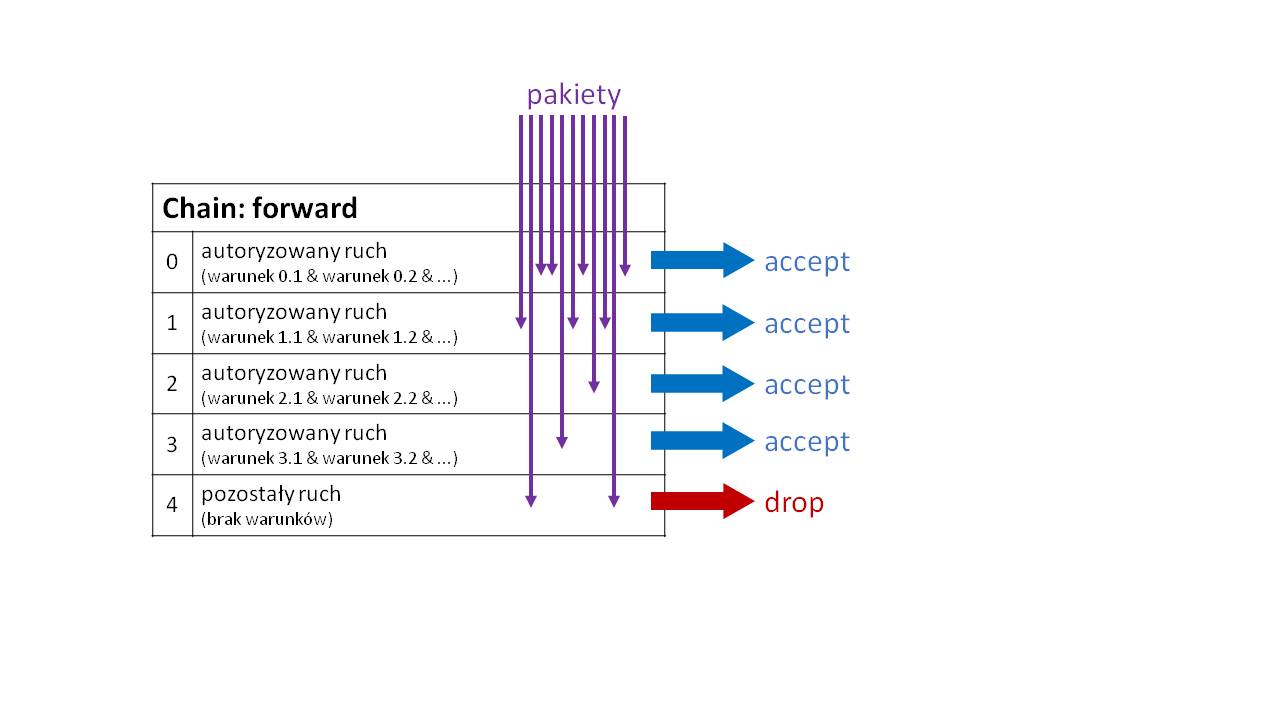
Podejście drugie jest zalecane z dwóch powodów.
Po pierwsze, konstrukcja, w której jawnie określamy dozwolony, prawidłowy ruch, ma tendencję do bycia bardziej bezpieczną. Określając ruch do zablokowania (potencjalnie szkodliwy), łatwiej o przeoczenie nietypowych zagrożeń.
Po drugie, z reguły znacznie więcej ruchu przepuszczamy przez firewall niż odrzucamy. Zatem struktura pokazana na drugim rysunku jest bardziej wydajna (mniej obciąża procesor). W przypadku pierwszej, większość pakietów musi przejść przez wszystkie reguły. W przypadku drugiej, tylko nieliczne.
Jeżeli pewna część ruchu, którą da się łatwo wyodrębnić (np. pakiety wychodzące z określonej podsieci IP), wymaga specjalnego potraktowania, to przekieruj ten ruch do własnego łańcucha i wewnątrz niego zastosuj filtrowanie. Zwiększy to czytelność i efektywność firewalla, gdyż pozostałe pakiety (niewymagające specjalnego traktowania) będą przetwarzane przez pojedynczą regułę typu jump. Ilustruje to poniższy przykład, w którym dla części ruchu potrzebujemy wyodrębnić dodatkowe 4 reguły blokujące.
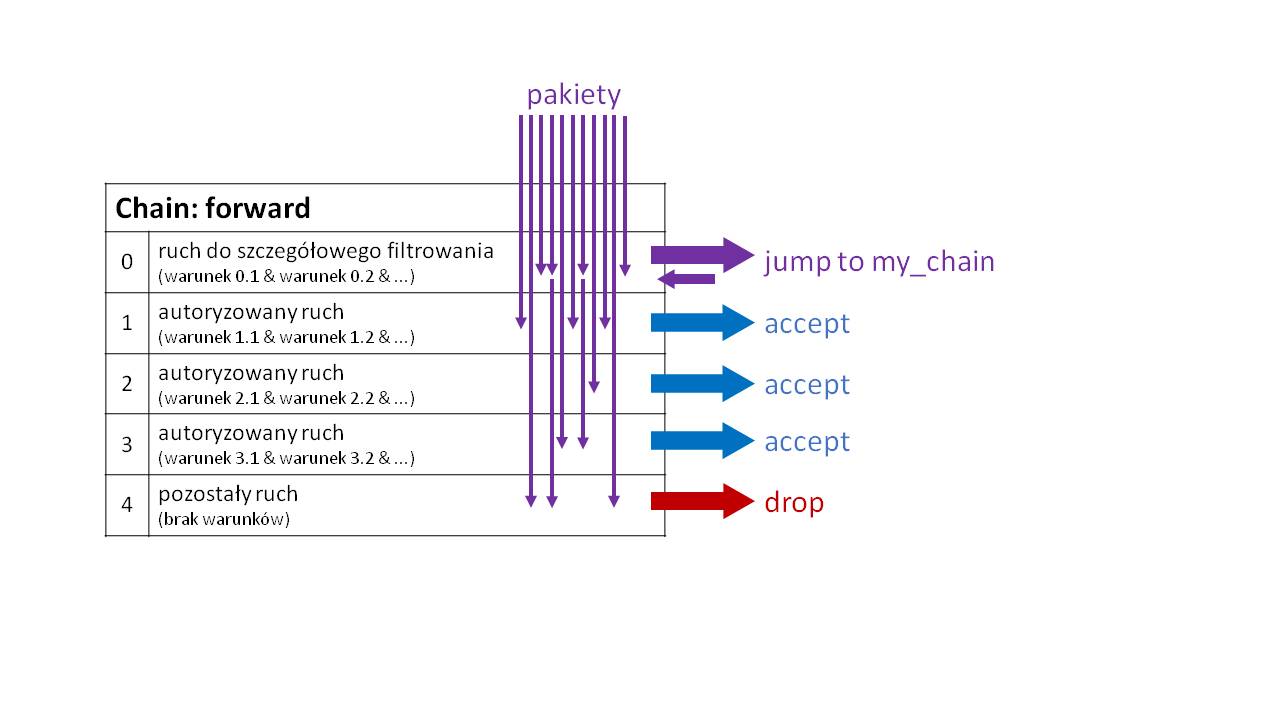

Jak widać, tylko część pakietów w tej sytuacji jest przetwarzana przez reguły 5-8. Pakiety, które zostały przechwycone przez regułę return (istniejącą domyślnie na końcu łańcucha zdefiniowanego przez użytkownika), wracają do głównego łańcucha, do reguły nr 1.
Dodając reguły filtrowania, opisuj w komentarzu, jaki jest jej cel. Znacznie ułatwi to diagnostykę problemów oraz modyfikację reguł w przyszłości.
Zamiast dodawać wiele analogicznych reguł dla różnych adresów IP – użyj listy (/ip firewall address-list).
Spośród reguł wykonujących tę samą akcję, te, które przechwytują najwięcej ruchu, umieszczaj na początku. Dzięki temu zmniejszy się średnia liczba reguł, przez które jest przetwarzany pakiet.
Zarówno po implementacji firewalla, jak i po każdej jego modyfikacji, sprawdź, czy firewall działa zgodnie z założeniami. Nieprzetestowane modyfikacje firewalla są niezwykle częstą przyczyną problemów.
Poniżej zestaw poleceń dodających przykładowe reguły zabezpieczające dostęp do routera.
/ip firewall filter add chain=input action=accept protocol=icmp comment="akceptuj ICMP" /ip firewall filter add chain=input action=accept protocol=tcp dst-port=22 comment="akceptuj SSH" /ip firewall filter add chain=input action=accept protocol=tcp dst-port=8291 comment="akceptuj WinBox" /ip firewall filter add chain=input action=accept protocol=udp dst-port=53 in-interface=bridge_lan comment="akceptuj zapytania DNS (UDP)" /ip firewall filter add chain=input action=accept protocol=tcp dst-port=53 in-interface=bridge_lan comment="akceptuj zapytania DNS (TCP)" /ip firewall filter add chain=input action=accept connection-state=established comment="akceptuj polaczenia zestawione" /ip firewall filter add chain=input action=accept connection-state=related comment="akceptuj polaczenia powiazane" /ip firewall filter add chain=input action=drop comment="blokuj wszystko inne"
Wszystkie reguły dotyczą wbudowanego łańcucha input, czyli ruchu kierowanego do routera (ale nieprzechodzącego przez router).
Pierwsze trzy reguły pozwalają na działanie protokołu ICMP do celów diagnostycznych oraz usług SSH i WinBox do zarządzania. Reguła SSH akceptuje pakiety na porcie 22 (standardowy SSH), ale w przypadku, gdy router jest podłączony do Internetu, zalecana jest zmiana tego portu (w /ip service) – jeżeli nie chcemy oglądać w logach natłoku informacji o próbach włamania do naszego routera przez grasujące po Internecie boty.
Kolejne dwie reguły to zezwolenie na zapytania DNS. Zakładamy tu, że nasz router pełni funkcję serwera DNS dla sieci lokalnej, która znajduje się na interfejsie bridge_lan.
Następna para reguł pozwala na połączenia zestawione i powiązane z nimi. Pozwala to routerowi na wykonywanie połączeń do innych hostów, w szczególności na dostęp do Internetu (np. w celu synchronizacji czasu przez NTP). Ponieważ nie definiowaliśmy reguł dla łańcucha output, pakiety generowane przez router wychodzą bez żadnego filtrowania, natomiast nawiązywane połączenia są rejestrowane (/ip firewall connection). Pakiety przychodzące w ramach tych połączeń (poniekąd „wracające” z Internetu) trafiają do łańcucha input i są akceptowane przez reguły, o których właśnie mówimy.
Ostatnia reguła blokuje pakiety, które nie załapały się na żadną z ww. reguł.
Zabezpieczymy teraz komunikację w ramach przykładowej sieci firmowej. Poniższa tabela przedstawia macierz akceptowanych połączeń:

Oto konfiguracja reguł: oprócz typowego filtrowania pakietów, zastosujemy podstawową ochronę przed atakami DoS (Denial of Service) dla serwerów w strefie DMZ, aby pokazać w praktyce szerszy wachlarz możliwości firewalla.
/ip firewall filter add chain=forward comment="akceptuj dmz do * polaczenia zestawione" connection-state=established src-address=10.0.1.0/24 /ip firewall filter add chain=forward comment="akceptuj dmz do * polaczenia powiazane" connection-state=related src-address=10.0.1.0/24 /ip firewall filter add action=jump chain=forward comment="chron dmz" dst-address=10.0.1.0/24 dst-port=80 jump-target=dmz protocol=tcp /ip firewall filter add chain=forward comment="akceptuj * do pracownicy polaczenia zestawione" connection-state=established dst-address=10.0.0.0/24 /ip firewall filter add chain=forward comment="akceptuj * do pracownicy polaczenia powiazane" connection-state=related dst-address=10.0.0.0/24 in-interface=ether1_wan /ip firewall filter add chain=forward comment="akceptuj pracownicy do internet" in-interface=bridge_lan out-interface=ether1_wan src-address=10.0.0.0/24 /ip firewall filter add action=drop chain=forward comment="blokuj wszystko inne" /ip firewall filter add action=drop chain=dmz comment="blokuj z listy atak_dos_blokada" src-address-list=atak_dos_blokada /ip firewall filter add action=add-src-to-address-list address-list=atak_dos_blokada address-list-timeout=1d chain=dmz comment="dodaj do listy atak_dos_blokada" connection-limit=100,32 log=yes log-prefix="atak dos" /ip firewall filter add chain=dmz comment="akceptuj * do dmz"
Pierwsze dwie reguły (0 i 1) akceptują ruch wychodzący z sieci DMZ, będący częścią ustanowionych połączeń. Załatwia nam to środkową kolumnę tabelki. Komunikacja pomiędzy maszynami w DMZ (tak samo jak pomiędzy pracownikami) odbywa się w obrębie danej domeny rozgłoszeniowej (nie przechodzi przez router), stąd nie są potrzebne dodatkowe reguły firewalla zezwalające na ten ruch. Reguły 0 i 1 nie określają adresu docelowego, gdyż zgodnie z tabelą, wszystkie zestawione połączenia wychodzące z DMZ powinny być akceptowane. W ten sposób mamy nieco prostszy (o 2 reguły krótszy) firewall.
Kolejna reguła (2) przekierowuje ruch kierowany na port TCP 80 (protokół HTTP) do nowego łańcucha: dmz. W łańcuchu tym mamy 3 reguły stanowiące proste zabezpieczenie przed atakami DoS polegającymi na zestawianiu dużej liczby połączeń TCP. Pierwsza z tych reguł (7) blokuje ruch z adresów wpisanych na listę atak_dos_blokada. Druga reguła dodaje na tę listę (na czas 24 godzin) adresy hostów, które próbowały zestawić jednocześnie ponad 100 połączeń do hostów w sieci DMZ. Dodatkowo, reguła ta zapisuje do logów informację z prefixem „atak dos”. Trzecia reguła akceptuje pozostały ruch w łańcuchu dmz (wyłączając go z dalszego przetwarzania).
Wracając do głównego łańcucha (forward), kolejne reguły (3 i 4) akceptują ruch przychodzący do pracowników w ramach zestawionych połączeń. Załatwia nam to pierwszy wiersz macierzy. Analogicznie jak w przypadku reguł 0 i 1, nie jest potrzebny warunek określający adres źródłowy, dzięki czemu oszczędzamy kolejne 2 reguły.
Reguła nr 5 akceptuje ruch wychodzący od pracowników do Internetu. Użyte są dwa warunki określające źródło (interfejs oraz źródłowy adres IP), co dodatkowo zabezpiecza przed wysyłaniem pakietów ze zmodyfikowanym źródłowym adresem IP z innej sieci (IP spoofing), np. ze skompromitowanego serwera w strefie DMZ.
Ostatnia reguła łańcucha forward (6), blokuje pozostały ruch.
Tworząc konfigurację firewalla, należy pamiętać o zależnościach pomiędzy różnymi mechanizmami.
Po pierwsze, aby działały funkcje związane ze stanem połączeń, funkcja śledzenia połączeń nie może być wyłączona. Domyślna wartość przełącznika (auto) powoduje, że śledzenie połączeń jest włączone, gdy istnieje przynajmniej jedna reguła firewalla. Z drugiej strony, jeśli w firewallu nie używamy żadnych reguł wymagających śledzenia połączeń, wyłączając tę funkcję, osiągniemy znaczną oszczędność mocy obliczeniowej procesora. Można tego dokonać poleceniem:
/ip firewall connection tracking set enabled=no
Druga ważna zależność dotyczy kolejności przetwarzania przez różne mechanizmy. Kompletny graf dostępny jest na Wiki MikroTika.
Wróćmy na chwilę do drugiego przykładu. Rutynowo w takich sytuacjach router wykonuje SRC-NAT na pakietach wychodzących do sieci Internet i DST-NAT na pakietach przychodzących z Internetu do sieci lokalnej. W takiej sytuacji, pakiety przychodzące do routera z Internetu są kierowane de facto na adres IP przypisany do routera. W świetle tego co pisaliśmy wcześniej o łańcuchach, pakiety te powinny trafić do łańcucha input (a nie forward). DST-NAT (część bloku Prerouting) wykonuje się jednak przed blokiem Routing Decision, który odpowiada za kierowanie pakietu do łańcucha Input lub Forward. Ponieważ translacja została wykonana wcześniej, to pakiet trafia do łańcucha Forward i na tym poziomie widzimy go już z adresem lokalnym.
–Bartłomiej Dabiński

Bardzo pożyteczna lektura. Tylko prosze, skupcie sie na tym z czym ludzie szczegolnie na poczatku przygody z mikrotkiem maja najwieksze problemy… PACKET FLOW. wiekszosc pytan na forach mikrotikowych obija sie o brak dobrego zrozumienia przeplywu pakietow. Wiem, sa grafy, niezmienia to jednak faktu ze dla wielu poczatkujacych sa niezrozumiale. Tym bardziej ze nie jest nigdzie lopatologicznie wytlumaczone ‘jak to praktycznie dziala’.
A rozumiejac packet flow, markowanie, shapeing, routing, staja sie niewiarygodnie latwiejsze do konfiguracji.
Dajmy wedke a nie rybke ;)
Artykuł sam w sobie dobry. Jednak nie zgadzam się z kolegą jancyk, nie widzę potrzeby aby opisywać podstawy (zdaje się, że jest to miejsce dla bardziej zaawansowanych użytkowników) przepływu pakietów. Patrząc w ten sposób należy rozpocząć od przepisania wikipedi odnośnie protokołu TCP później tłumaczyć jak się wkomponowuje tam IP. Bardzo dobrym pomysłem jest rozwal.to oraz artykuł “Wprowadzenie do ids”, które aby “umieć odczytać/wykonać” trzeba mieć wiedzę dalece większą niż przysłowiowy PACKET FLOW, że nie wspomnę o routingu klasach IP itp
Wydaje mi się, że jak idziesz do szkoły gotowania to nikt Cie nie uczy obierania ziemniaków.
Dajmy im silnik do łodzi rybackiej, bo tego im brakuje, to zarobią na swoje rodziny, siebie i podszkolą pozostałych ;-)
i nauczyli cie już obierać te ziemniaki?
Masz racje, tylko nie każdy używał IP tables, a sformułowania postrouting i prerouting mogą być dla niego nie do końca zrozumiałe. Pamiętajmy że są różne sposoby łowienia , różne rodzaje wędek, różnymi łodziami też można pływać na łowiska. I nie ma takich osób co znają każdy sposób łowienia i każdy sprzęt do tego a wbrew pozorom potrafią bardzo dobrze łowić i nadal chcą poznawać nowe sposoby choćby wiązało się to z przejściem szkolenia od początku z racji innego uchwytu na wędce :D
Świetny tekst, bardzo mi się przydał bo rozjaśnił kilka spraw. Poproszę więcej na temat RouterOS :)
Dzień dobry,
Proszę o podpowiedź czy takie dwie reguły powinny się znajdować w konfiguracji:
;;; default configuration
chain=forward action=accept connection-state=established log=no log-prefix=””
;;; default configuration
chain=forward action=accept connection-state=related log=no log-prefix=””
Czy nie wystarczą takie reguły w łańcuchu input do wyjścia na świat? Proszę o wyrozumiałość, dopiero zaczynam przygodę z RouterOS
Będzie coś o mikrotiku, jeszcze?
Pewna firma od lat działa na tych skryptach co na stronie. Działają.
W imieniu klientów dziękuję :-)