Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej

W świecie IT pojawiła się powszechna praktyka, w której kryptografia jest opracowywana przez grupę badaczy posiadających silne zaplecze matematyczne, podczas gdy programiści wdrażają gotowe rozwiązania i zapewniają, że są one aktualne i spełniają najlepsze praktyki bezpieczeństwa.
Biorąc to pod uwagę i dodając fakt, że testowanie aplikacji desktopowych jest często przeprowadzane przez pentesterów, którzy mogą przeoczyć kwestie związane z szyfrowaniem lub hashowaniem, skupiając się na wyszukiwaniu znanych luk, należy spodziewać się, że może dojść do nieoczekiwanego. Jak udowodni poniższy tekst, głębsze zrozumienie tego tematu może przynieść zaskakujące rezultaty i ostatecznie doprowadzić do kradzieży kont wszystkich użytkowników aplikacji desktopowych.
Niedawno, podczas testowania prawdziwej aplikacji desktopowej, natknąłem się na niestandardowy algorytm hashowania haseł bazy danych oparty na algorytmie szyfrowania 3DES. Chociaż na pierwszy rzut oka wydaje się to szaleństwem, ponieważ funkcja skrótu powinna być z definicji jednokierunkowa, bez możliwości odszyfrowania. W rzeczywistości istnieje wiele algorytmów hashujących, które wykorzystują szyfrowanie symetryczne, na przykład:
· Davies–Meyer,
· i inne.
Jednak badany algorytm miał niewiele wspólnego z cytowanymi powyżej. Pokażę więc technikę ataku na takie algorytmy, które zostały zastosowane w prawdziwej aplikacji. Na wstępie warto zacząć od tego, że aplikacja została napisana w środowisku .NET, a dodatkowo kod nie był zaciemniony (obfuskowany). Użyłem narzędzia ILSpy, które pozwala na dekompilację kodu źródłowego. Aplikacja i baza danych są ze sobą bezpośrednio połączone (architektura 2-tier) oraz zaimplementowano uwierzytelnianie po stronie klienta, które z góry nie powinno być możliwe, ponieważ użytkownik może wpływać na jego przebieg. Po dokładnym przeszukaniu kodu aplikacji, znalazłem klasę C#, która implementowała obliczanie hasha.
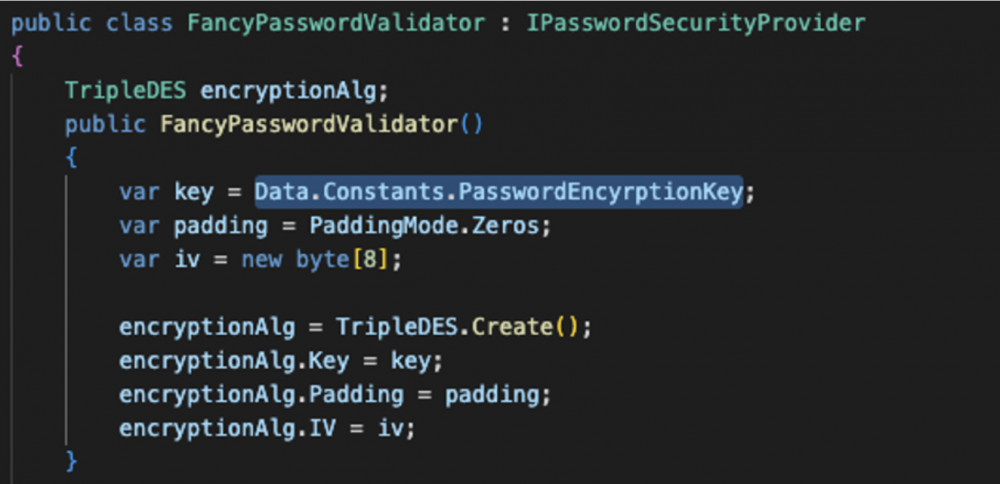
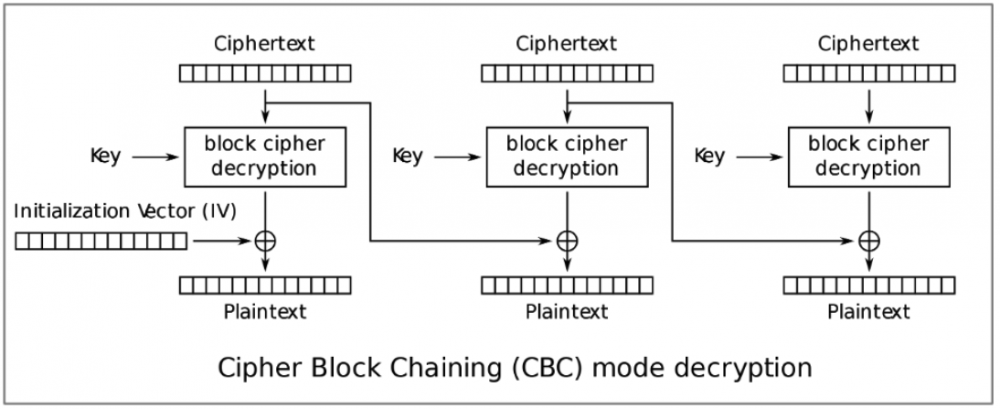
Jak pokazuje kod źródłowy, widzimy, że instancja klasy TripleDES jest tworzona w metodzie Create z wektorem inicjalizacyjnym o długości ośmiu bajtów i wartości 0x00000000000000000000. Wypełnienie jest ustawione na zero, a klucz szyfrowania jest przekazywany jako argument do funkcji. Jeśli nie ustawiono trybu szyfrowania, domyślnym trybem jest CBC (Cipher Block Chaining). Klucz do szyfrowania należał do innej klasy i miał długość 192 bitów.
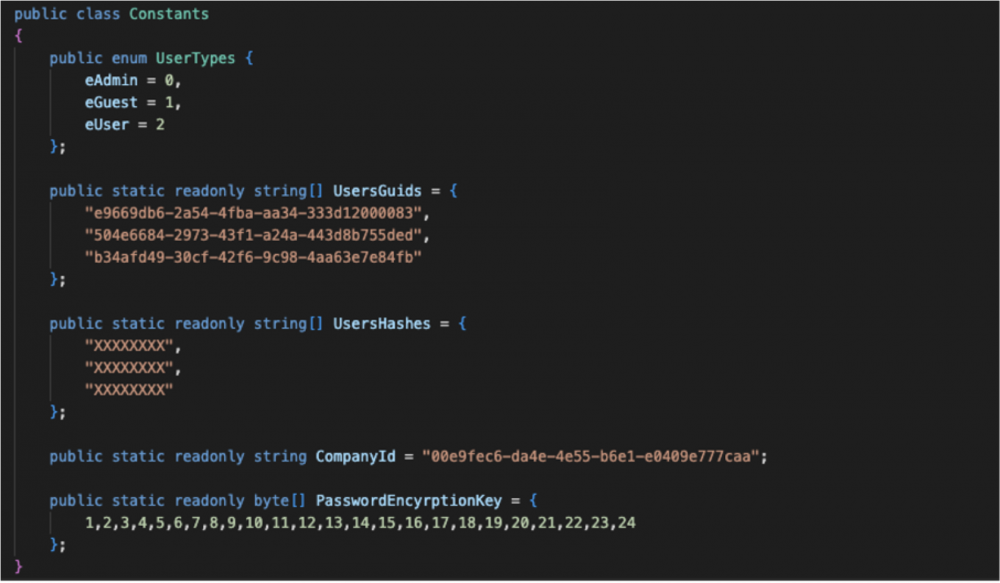
Zgodnie z kodem źródłowym, aplikacja szyfruje hasło w funkcji GenerateHash, a następnie zwraca tylko osiem ostatnich bajtów. Jest to dokładnie to samo, co hash przechowywany w bazie danych – ostatnie osiem bajtów całego szyfrogramu.
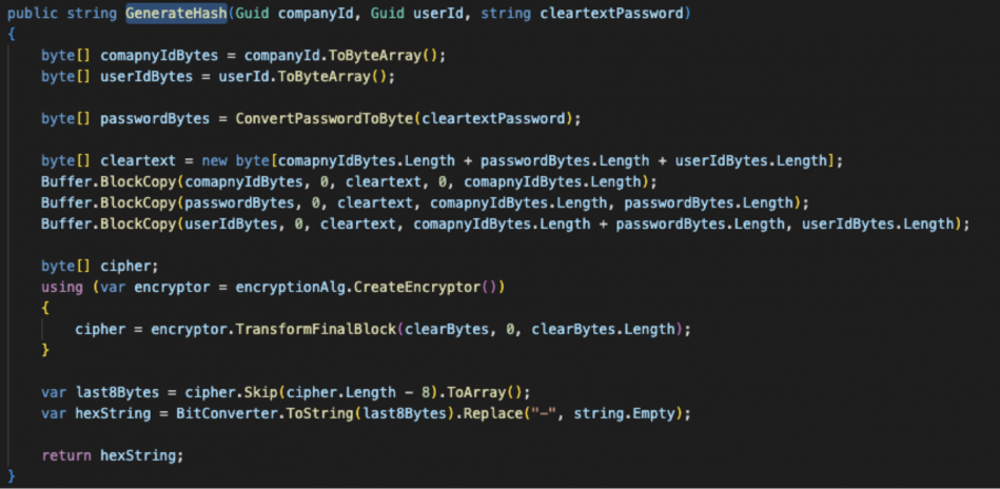
Podsumowując zdobyte informacje, kod zawiera:
· klucz i wektor inicjalizacyjny szyfru,
· strukturę zwykłego tekstu – identyfikator firmy (companyID) + hasło + identyfikator użytkownika (userID),
· hash hasła to osiem ostatnich bajtów szyfrogramu – osiem bajtów to 16 znaków zapisanych szesnastkowo.
Wartość identyfikatora companyID, userID i hash można znaleźć w bazie danych. Długość każdego identyfikatora GUID jest równa 16 bajtom, a hasło jest zakodowane w Unicode, więc każdy znak zajmuje dokładnie 2 bajty pamięci. Na przykład, tak wyglądałby zwykły tekst dla każdego pola:
· companyID – a5b440d3-ec2c-4da3-b85f-a6bd10033ac8 (podświetlony na żółto),
· userID – e945ff16-c29d-4eaa-a680-ece95af45cb6 (podświetlony na zielono),
· hasło – AAAA (podświetlone na fioletowo).

Szyfrogram zostanie przedstawiony w następującej formie:

Hash będzie zawierał ostatnie 16 znaków (8 bajtów):
ABDFE0E400476EB9
TripleDES przy użyciu CBC dzieli tekst jawny na bloki po 8 bajtów, które najpierw koduje za pomocą operacji XOR z wykorzystaniem wektora inicjalizacyjnego, a dopiero potem szyfruje. W przypadku pierwszego bloku wektor inicjujący jest z góry określony przez programistę (w tym przypadku 0x0000000000000000), podczas gdy każdy kolejny wektor inicjujący jest już zaszyfrowany jako iloczyn poprzedniego bloku:
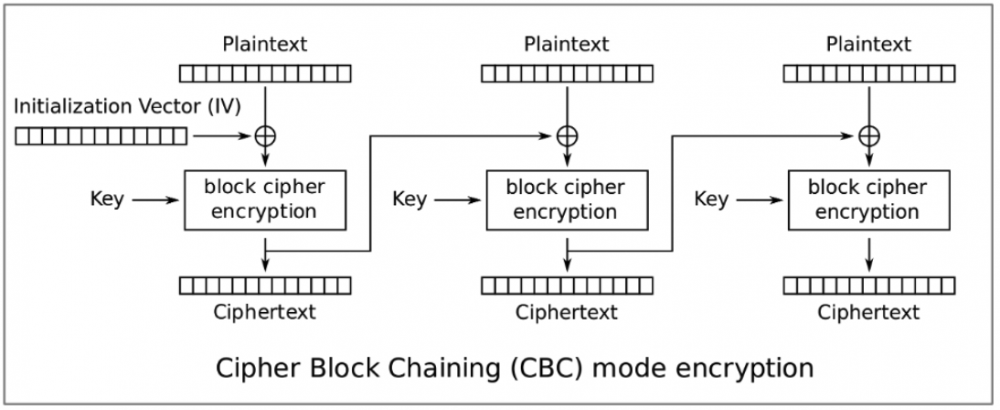
W przypadku deszyfrowania kolejność jest odwrócona – deszyfrowanie rozpoczyna się od ostatniego bloku, a następnie jest dekodowane za pomocą operacji XOR przy użyciu zaszyfrowanego poprzedniego bloku:
Prawdopodobnie zastanawiasz się, w jaki sposób możesz uzyskać dostęp do userId i comapnyId. W tabeli użytkownika baza danych zawierała wszystkie dane niezbędne do skonstruowania zwykłego tekstu. Do samej bazy danych można było uzyskać dostęp za pośrednictwem aplikacji, która posiadała poświadczenia bazy danych w kodzie źródłowym. Każdy użytkownik miał przypisany identyfikator (userId), identyfikator firmy (companyId) oraz hash hasła, który jest naszym celem.
Aby pomyślnie odzyskać hasło, szyfrogram musi najpierw zostać odtworzony przez hash, który już posiadamy. W algorytmie Cipher Block Chaining używamy klucza i wektora inicjalizacyjnego do szyfrowania każdego bloku. Klucz pozostaje stały dla każdego bloku, ale wektor inicjujący jest po prostu wartością poprzedniego zaszyfrowanego bloku, stąd słowo “chaining” w nazwie algorytmu.
Szyfrowanie danych odbywa się od pierwszego do ostatniego bloku, a deszyfrowanie od ostatniego do pierwszego. Opisana tutaj metoda opiera się na odgadywaniu wektora inicjalizacyjnego bajt po bajcie w taki sposób, że po odszyfrowaniu bloku otrzymujemy oczekiwany wynik, w tym przypadku identyfikator użytkownika.
Wykonanie poniższych kroków pozwala atakującemu odzyskać dowolne hasło z bazy danych. Hash, userId i companyId użyte w tym przykładzie zostały znalezione w bazie danych, jak wspomniałem w poprzedniej sekcji.
1. Atakujący posiada wszystkie niezbędne dane. Znaleziony hash ma następującą postać:

2. Wie również, że userId to:

3. Teraz zadaniem atakującego jest znalezienie takiego wektora inicjalizującego, aby po odszyfrowaniu otrzymać hash:

4. Atakujący bierze najprostszy wektor inicjalizacyjny 0x000000000000000000000000 i zaczyna wyliczać bajt po bajcie od 0x000000000000000000000000 aż do naszego trafienia, czyli 0x0000000000000053, po odszyfrowaniu daje ostatni bajt userID, więc wiemy, że to poprawna wartość:

5. Następnie atakujący powtarza tę operację dla kolejnych bajtów, aż do uzyskania wektora w postaci 0xA6C8E54AD97E2553, który jest przedostatnim blokiem szyfrogramu. Na tym etapie odzyskany szyfrogram to:

6. Następnie wszystkie kroki należy powtórzyć dla wykrytego bloku i kolejnych 8 bajtów userId.
7. Po tych krokach atakujący ma już ostatnie trzy bloki szyfrogramu, jak wspomniałem wcześniej, ostatnie dwa bloki to identyfikator użytkownika, a trzeci to hasło:

8. Teraz dodajemy comapnyId na początek szyfrogramu:

9. Ostatnim krokiem jest odszyfrowanie wiadomości i odzyskanie hasła:

Kolizja haseł to sytuacja, w której dwa różne hasła generują ten sam skrót. Dla atakującego taka sytuacja jest wygodna, ponieważ nie wymaga złamania hasła, co wymaga czasu, sprzętu i odpowiedniego przygotowania. Zaletą ataku poprzez kolizję jest czas i wydajność. Atakujący może więc w krótkim czasie wygenerować inne hasło, które daje ten sam hash i użyć go do zalogowania się na konto użytkownika.
Podobnie jak w pierwszym przypadku, powinien on opierać się na odnajdywaniu kolejnych bloków szyfrogramu, ale przy założeniu, że prawdziwe hasło nie zostanie odnalezione. Dla ułatwienia obliczeń warto przyjąć, że długość poszukiwanego hasła jest wielokrotnością liczby cztery. W ten sposób hasło zajmie cały blok szyfrogramu.
W tym ataku wykorzystuję fakt, że język C# koduje ciąg znaków w Unicode. W rezultacie atakujący musi pobrać tylko trzy bloki szyfrogramu, a następnie dodać identyfikator firmy na początku. W tym przykładzie wykorzystane zostaną następujące dane:
· companyID – a5b440d3-ec2c-4da3-b85f-a6bd10033ac8 (podświetlony na żółto),
· userID – e945ff16-c29d-4eaa-a680-ece95af45cb6 (podświetlony na zielono),
· hasło – hash-test-very-secure-password1! (podświetlone na fioletowo).

Szyfrogram będzie miał następującą postać:

Hash będzie składał się z ostatnich 16 znaków (8 bajtów):

Mając wszystkie dane poza oryginalnym szyfrogramem, atakujący może użyć metody opisanej w pierwszym przypadku i uzyskać jeden potencjalny szyfrogram:

Po odszyfrowaniu tej wiadomości otrzymujemy następującą treść:

Jak się okazuje, hash dla hasła 4dc1f98e556996fb (w reprezentacji szesnastkowej) jest taki sam jak dla hasła:

Teraz pozostaje tylko przenieść tę wartość na rzeczywiste znaki Unicode, do czego można użyć https://unicode-table.com/pl/. Należy pamiętać, że w reprezentacji szesnastkowej kolejność bajtów jest odwrócona, więc na przykład a5e6 należy zapisać jako e6a5. Ze względu na ogromną liczbę języków i alfabetów, wymagana jest odpowiednia reprezentacja każdego z nich. Z tego powodu stworzono tablicę Unicode, która wykorzystuje dwa bajty (65536 możliwych znaków), więc na przykład wielka litera A to 0041, podczas gdy B to 0042, natomiast reprezentacja 4141 to 䅁. Poniżej znajduje się ciąg kolizyjny zamieniony na Unicode:

Załóżmy jednak, że nie możemy utworzyć prawidłowego ciągu znaków. Z tego powodu należy zwiększyć długość hasła do ośmiu znaków i wygenerować nowy szyfrogram:

Algorytm zakłada, że licząc każdy kolejny blok, wartość poprzedniego wynosi 0x414141414141414141, aby móc uzyskać znaki w dostępnym zakresie, więc po odszyfrowaniu otrzymujemy następującą propozycję:

Operację tę należy powtarzać do momentu uzyskania znaków, które można skopiować. Jeśli po zwiększeniu długości hasła do ośmiu znaków nie uzyskamy znaków w podanym zakresie, można zmienić zakładany ciąg 0x414141414141414141 na 0x424242424242424242 lub inny. Potencjalnie możliwe jest również dalsze zwiększanie długości.
Dla danego, domniemanego ciągu znaków i poprzedniego hasha istnieje również hasło składające się z 12 znaków, które daje identyczny hash:

Teraz, gdy mam już wygenerowany ciąg znaków, możemy go użyć do zalogowania się na konto ofiary. Po wprowadzeniu hasła w polu formularza logowania aplikacja obliczy hash hasła przy użyciu tego samego algorytmu, co w przypadku uwierzytelniania. Następnie porówna go z hashem przechowywanym w bazie danych. Ze względu na lukę w algorytmie, skróty te zostaną uznane za identyczne, mimo że hasła są różne. W rezultacie atakujący uzyska dostęp do konta ofiary.
~Mateusz Lewczak
Zamówienie można zrealizować tutaj: ksiazka.sekurak.pl

Fajny błąd, ale jakie on ma znaczenie skoro głównym problemem jest 2 warstwowość systemu? Równie dobrze można wziąć credentiale do bazy, zalogować się i podmienić hasha.
Hej, jasne, architektura samej aplikacji w znacznym stopniu przekreśla jej dalsze losy i gdyby nam zależało na samym skompromitowaniu aplikacji to na tym można byłoby poprzestać. Natomiast, trzeba pamiętać, że pentest ma na celu wykrycie jak największej ilości podatności :)
Pewne rzeczy takie jak id ostatniego usera mogą być zapisane w localstorage przeglądarki. W teorii wystarczy wejść po użytkowniku. Takie dywagacje :-)
W tym artykule nie stworzono własnej kryptografii.
Niepoprawnie użyto istniejących cywilnych algorytmów.
Osobiście przez stworzenie własnej kryptografii rozumiem na przykład zaprojektowanie nowego algorytmu DES/AES.
To jest już wyższa szkoła jazdy wymagająca zagłębienia się w zaawansowaną matematykę z kryptologii.
To skrot myslowy, ktory oznacza, ze samodzielnie implementujemy dobrze znane i powszechnie uzywane algorytmy. Wlasna imlementacja istniejacych algorytmow zazwyczaj sie nie sprawdza. Dodatkowo kryptografia != algorytm. To jest wlasnie dobry przyklad zlego zrozumienia.
Po części tak, ale trzeba pamiętać, że kryptografia to nie tylko szyfrowanie, które ma nam zapewnić poufność danych. Hash, czyli kryptograficzna funkcja skrótu również wchodzi w skład kryptografii i ma za zadanie zapewnić integralność przetwarzanych danych.
Programy tak zaprojektowane, nawet potraktowane obfuscatorem to jest Security through obscurity. Podstawowym błędem nie jest opisana w tekście kryptografia. Błędem był już sam pomysł, żeby w ten sposób projektować program. Threat actors też swoje malware zaciemniają (ang. obfuscation) na miliony sposobów, a analitycy i tak w końcu rozpracują jak działa próbka. Ponieważ kod programu (choć zaciemniony czy spakowany) jest uruchamiany lokalnie. Kwestia czasu i środków, które ktoś posiada na analizę i łamanie takiego zabezpieczenia. Oczywiście nie krytykuję tego, że Sekurak znakomicie rozpracował kryptografię tego przypadku, ponieważ jest to nauczka dla programistów.
Istnieją przypadki bardzo fajnego wykorzystania architektury 2-Tier aplikacji desktopowych, np. poprzez wykorzystanie użytkowników bazodanowych z drobną granulacją uprawnień. A co do obfuskacji to zazwyczaj w przypadku takich aplikacji jest rekomendacja, która ma na celu zwiększenie ogólnego bezpieczeństwa.
Tylko, że to podajecie przykład hashowania a nie szyfrowania
Tak, to jest przykład zastosowania algorytmu szyfrowania na potrzeby stworzenia własnego algorytmu skrótu. I jedno i drugie wchodzi w zakres kryptografii :)