Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej

Monitoring infrastruktury IT jest w dzisiejszych czasach dużym wyzwaniem. Od takich oczywistości, jak dostępność serwerów czy infrastruktury sieciowej, a kończąc na poziomie naładowania UPS lub czy drzwi są otwarte w szafach rackowych. Mnogość urządzeń i sposobów ich monitorowania często prowadzi do sytuacji, że wdrażamy kilka niezależnych rozwiązań monitoringu, co po pewnym czasie jest bardzo kłopotliwe. Rozwiązaniem takiego stanu rzeczy jest oczywiście Zabbix.
Artykuł omawia absolutne początki z tym oprogramowaniem – od wyjaśnienia, czym jest zabbix, do wstępnego planowania zasobów na jego potrzeby. Zaczynamy!
Zabbix to rozwiązanie (nie bójmy się tego powiedzieć) klasy enterprise obsługi problemów z monitoringiem. Służy do zbierania, analizowania i wizualizacji danych. Oprogramowanie potrafi również wykryć wszelkie anomalie w naszej infrastrukturze i powiadomić o tym odpowiednio użytkownika.
Twórca zabbixa, Alexei Vladishev, stworzył pierwszy zarys aplikacji, gdy w 1998 potrzebował narzędzie do monitoringu w firmie, gdzie pracował. Na początku były to proste skrypty napisane w perlu, jednak twórca szybko zmienił język programowania na C. Dodatkowo napisał front-end w języku PHP i w roku 2004 wypuścił pierwszą stabilną wersję – 1.0. Twórca w jednym z wywiadów opowiada również skąd się wzięła nazwa – wymyślał losowe słowa i sprawdzał w wyszukiwarce, czy są już zarezerwowane. Niestety słowo “Zabbix” nie kryje żadnego większego znaczenia.
Rysunek 1. Zabbix 1.1.6 Alpha6 – GUI źródło: wikimedia.org.
W 2005 roku Alexei założył firmę Zabbix SIA, która, oprócz tworzenia nowych wersji oprogramowania, zajmuje się też wsparciem komercyjnym oraz szkoleniami.
Jest to bardzo często zadawane pytanie przez nowych użytkowników. Powodów jest co najmniej kilka:
Rysunek 2. Przykład mapy źródło: secretwafflelabs.com.
By móc dobrze zaplanować potrzeby naszego środowiska monitoringu, musimy znać podstawowe pojęcia związane z zabbixem. Na początku zacznijmy od tzw. “trójpodziału władzy”:
Schemat połączeń przedstawia Rysunek nr 3. Warto wspomnieć, że połączenie pomiędzy front-endem a zabbix-serverem jest wykorzystywane sporadycznie np. przy wyświetlaniu aktualnego stanu usługi zabbix-server czy przy wyświetlaniu aktualnego stanu kolejki sprawdzeń. Na schemacie wszystkie 3 usługi są uruchomione na tym samym hoście, jednak nic nie stoi na przeszkodzie, by każdą z nich uruchomić na osobnych serwerach.

Rysunek 3. Schemat połączeń.
Innymi ważnymi podczas planowania definicjami są:
Przy planowaniu środowiska zabbix musimy znać odpowiedzi na kilka pytań:
Jaka wersję zabbix powinienem wybrać?
Na to pytanie są tylko dwie poprawne odpowiedzi:
Wszelkie dodatkowe informacje odnośnie wersjonowania można znaleźć na oficjalnej stronie.
Jaką bazę danych powinienem wybrać?
Twórcy zabbixa promują bazę MySQL wraz z silnikiem InnoDB (oczywiście nic nie stoi na przeszkodzie, by wykorzystać MariaDB), przez co ten typ bazy jest najlepiej udokumentowany, jak i również posiada wiele wskazówek na optymalizację (co w kwestii zabbixa jest bardzo ważne). Jednakże można zastosować również bazę PostgreSQL czy Oracle.
Jaki front-end powinienem wybrać?
W większości przypadków wystarczy proponowane przez twórców Apache. Możemy również wybrać nginx lub Lighttpd, jednak należy brać pod uwagę że, tak samo jak w przypadku bazy PostgreSQL czy Oracle, nie są to przypadki tak dobrze udokumentowane.
Czy myśleć o rozdzieleniu usług na 3 serwery?
Nie – rozdzielenie usług jest jedną z ostateczności jeżeli chodzi o brak wydajności. Bazę danych warto rozdzielić, gdzie przy dużej ilości danych baza działa coraz wolniej (mimo prób jej optymalizacji!). Wtedy można pomyśleć o osobnym serwerze z szybkimi dyskami SSD (stare przysłowie mówi – “źle zoptymalizowana baza danych nawet na SSD będzie mulić”).
Jeżeli planujemy ponad 100 użytkowników, z czego w najbardziej krytycznym momencie będzie ponad połowa zalogowana, można pomyśleć również nad osobnym serwerem dla GUI.
Jaki system operacyjny wybrać?
Linux. Są gotowe paczki (repo) dla systemów z rodziny RedHat (RHEL, CentOS, Fedora) oraz Debian i Ubuntu, ale nic nie stoi na przeszkodzie, by samemu na innym systemie skompilować Zabbixa ze źródeł. Zabbix wspiera również inne systemy UNIX np. FreeBSD. Niestety, ale zabbix-server nie zainstalujemy na Windowsie (ale agenta do monitorowania pracy tego serwera już tak!).
Jakie zasoby dobrać do serwera?
Jest to najczęstsze pytanie podczas planowania środowiska. Spójrzmy najpierw na część tabelki zaproponowaną przez twórców:
Tabela 1. Część rekomendacji zaproponowanej przez twórców źródło: zabbix.com.
| Wielkość | CPU/RAM | Ilość monitorowanych hostów |
|---|---|---|
| Małe | Virtual Appliance | 100 |
| Średnie | 2 rdzenie CPU/2GB | 500 |
| Duże | 4 rdzenie CPU/8GB | >1000 |
| Bardzo duże | 8 rdzeni CPU /16GB | >10000 |
Według powyższej tabeli głównym czynnikiem decydującym o wielkości środowiska zabbix to ilość monitorowanych hostów. Nie jest to efektywne podejście do planowania środowiska zabbix, ponieważ host hostowi nie równy. Przykładowo w konfiguracji jednego hosta możemy tylko sprawdzać co 30 minut, czy żyje (ICMP ping), natomiast inny host to produkcyjna baza danych, gdzie musimy zbierać mnóstwo statystyk o jego działaniu, najlepiej co 5-10 sekund. Dlatego lepszym pomysłem jest planowanie po wartości NVPS.
Warto przy planowaniu oszacować, jaka będzie wartość nowych wartości na sekundę. Przykładowo, przy 300 sprawdzeniach z interwałem 1 minuty otrzymamy – 300/60 = 5nvps.
Odświeżona tabelka powinna wyglądać następująco:
Tabela 2. Rekomendacje uwzględniające parametr NVPS.
| Wielkość | CPU/RAM | Wartość NVPS |
|---|---|---|
| Małe | Virtual Appliance | Do 50 |
| Średnie | 2 rdzenie CPU/2GB | 100 |
| Duże | 4 rdzenie CPU/8GB | 500 |
| Bardzo duże | 8 rdzeni CPU /16GB | 1000 |
Ile miejsca potrzebuje na środowisko zabbix?
Przy planowaniu miejsca na dysku należy pamiętać, że głównie musimy brać pod uwagę bazę danych ze względu na agregację danych. Reszta plików (zabbix-server i GUI w php) ważą bardzo mało (około 10-20 MB w zależności od wersji i systemu operacyjnego).
Przy obliczaniu przewidywanego miejsca bierze się wartości liczbowe (wartości tekstowe są teoretycznie nie do zaprognozowania, ponieważ ciągi znaków mogą być różnej długości i zajmować różną ilość bajtów). Przy liczeniu estymowanego miejsca bierze się największe tabele:
Ogólne estymowane miejsce można obliczyć za pomocą wzoru:
Miejsce = H*tH+T*tT</+Z*tZ
Gdzie:
tH – ilość dni w których chcemy trzymać historię,
tT – ilość lat w których chcemy trzymać trend,
tZ – ilość dni w których chcemy trzymać informację o zdarzeniach.
Warto nadmienić że baza będzie rosła z czasem – zawsze można założyć mniejszy dysk, a po pewnym czasie zwiększyć przestrzeń dla bazy. Dodatkowo należy przypomnieć, żeby nie trzymać się kurczowo wyżej wymienionych wzorów – jest to tylko podpowiedź, ile nasza baza danych może ważyć i przy ostatecznych obliczeniach zawsze przyjmuj nadwyżkę miejsca (około 20-30% powinno być ok).
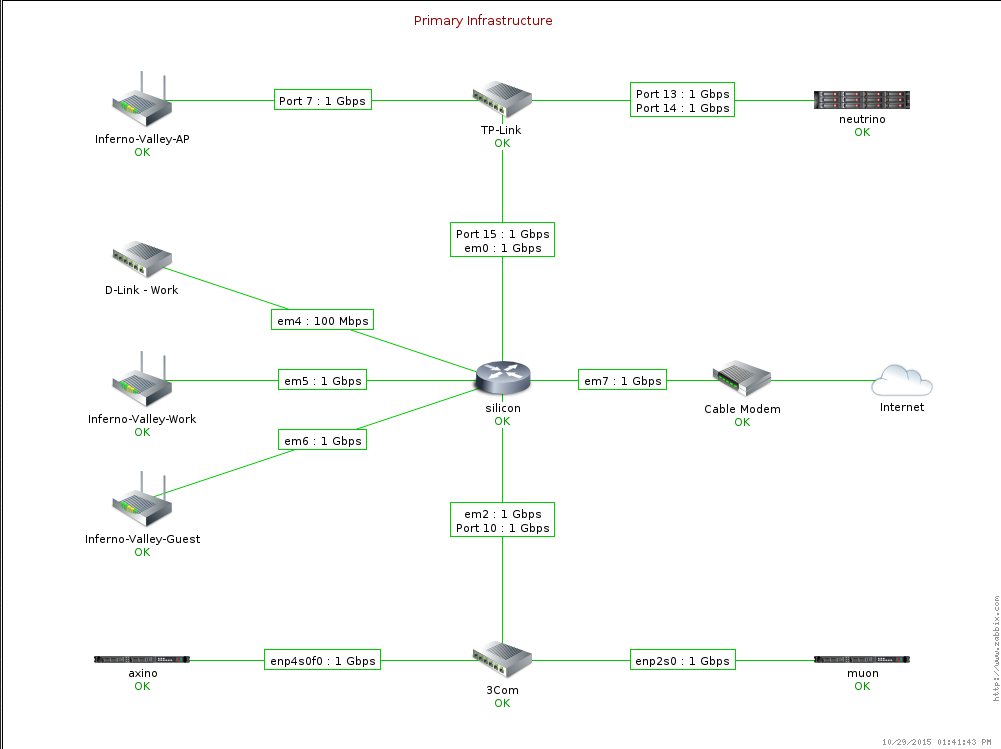
Warto wyżej wymienione porady pokazać na przykładzie. Załóżmy, że posiadamy środowisko przedstawione na rysunku nr 4.

Rysunek 4. Przykładowe środowisko.
Potrzebujemy zrobić analizę całego naszego środowiska krok po kroku. Na początku musimy wiedzieć, ile przewidujemy wartości oraz jak często będziemy je sprawdzać (by obliczyć NVPS):
Przy takich założeniach po dodaniu wszystkich wartości mamy około 1780 wartości oraz 50 nowych wartości na sekundę. Patrząc na tabelę nr 2 będziemy musieli założyć serwer już z procesorem dwurdzeniowym oraz 2GB pamięci RAM.
Nadszedł teraz czas na obliczenie spodziewanego zajętego miejsca. Do tego musimy dodatkowo założyć, ile dni będziemy trzymać historię, trend, oraz zdarzenia. Przy naszych obliczeniach wykorzystamy standardowe wartości przyjęte przez programistów Zabbix:
Mając już wszystkie potrzebne informacje, możemy w łatwy sposób obliczyć przewidywaną zajętość miejsca:
Miejsce = 50*7.5*90+1780*0,75*1+14*365=33750 + 1335 + 5110 = 40195 [MB]
Dodatkowo zakładając nadwyżkę miejsca (około 20-30%) powinniśmy spodziewać się, że zabbix zajmie około 50GB miejsca po roku.
Warto tutaj zwrócić uwagę na jeszcze jeden ważny czynnik, jakim jest wielkość poszczególnych tabel z danymi. Spostrzegawczy czytelnik zauważy, że najwięcej miejsca na dysku zajmuje tabela z historią, która jest zależna od nowych wartości na sekundę oraz ilości dni, w których chcemy ją trzymać. Gdybyśmy dla przykładu zmniejszyli ilość dni z 90 do 7, to tabela historyczna zmniejszy się z 34 do około 3GB! Natomiast po zwiększeniu częstotliwość wszystkich sprawdzeń w naszej analizie do 1 min (pozostawiając 90 dni trzymania historii), uzyskalibyśmy około 31NVPS, co daje nam oszczędność około 13GB na dysku. Warto zatem zastanowić się (nie tylko na etapie projektowania, ale również dla istniejącego środowiska!) czy nie warto zmniejszyć tych dwóch parametrów, by znacząco zmniejszyć potrzebną ilość miejsca na dysku oraz odciążyć sam serwer zabbixa (mniej NVPS = mniej sprawdzeń = mniejsze zużycie zasobów).
Tabela z trendami jest zupełnym przeciwieństwem – tutaj możemy pokusić się o wydłużenie dni, w których będziemy trzymali trend, ponieważ w naszym przykładzie 1 rok trendu zajmuje tylko 1,3GB.
Analiza potrzeb pod środowisko zabbix nie jest łatwym zadaniem. Najlepiej jest zrobić analizę całej infrastruktury. Autor celowo w czasie zestawienia środowiska nie wchodził w szczegóły – nie jesteśmy w stanie oszacować potrzeb serwera zabbix w 100%, dlatego analiza nie powinna być za bardzo wnikliwa. Pamiętaj jednak, by zawsze przygotowywać się na najgorszy scenariusz i zawsze zakładać nadwyżkę (szczególnie jeżeli chodzi o miejsce na dysku!).
— Albert Przybylski, fanatyk Zabbixa, pełnoprawny admin 24/7

{kind=link}
{kind=link}
Super artykuł, dzięki.
W odniesieniu do systemu check_mk (aka OMD), co przemawia na korzyść korzystania z Zabbixa?
Można się spodziewać kolejnych wpisów z serii?
Tak, ale nawet już kilka mamy:
https://sekurak.pl/ladne-wykresy-w-zabbiksie-wykorzystajmy-grafane/
https://sekurak.pl/ulatwianie-pracy-w-zabbix-uzywamy-makr/
Dzięki za artykuł,
będziemy w najbliższym czasie wdrażać
Jakie informacje potrafi zbierać agent?
“The general rule of thumb is this: If it returns a value, Zabbix can monitor it, whether through the native agent, SNMP, JMX, shell scripts, web monitoring, etc.”
https://www.zabbix.com/forum/showthread.php?t=42311
Część z grafaną już lekko nieaktualna, w Zabbix 3.4 są daszbordy podobne do tych w grafanie.
W grafiane dane ładniej się prezentują.
W czym zabbix jest lepszy od Nagios Core?
Również dziękuję, za powyższy artykuł. Przyda się na pewno! ;)
tego wlasnie bylo mi trzeba, dzieki kuraku!
Ja długo nie mogłam opanować tego narzędzia, choć wiedziałam, że jest przydatne. Przeczytałam ten artykuł https://blog.askomputer.pl/architektura-systemu-zabbix/ i dołączyłam do newslettera i teraz już ogarniam Zabbixa.
co za nachalna reklama Panie Arkadiuszu…
Arek, nie spamuj!
Dokumentacja jest spierniczona. Chcę np. zainstalować język polski. Nie można tego zrobić przez interfejs. Trzeba z linii poleceń. Loguję się:
locale -a :same angielskie (ok)
vi /etc/locale.gen :nowy plik chce tworzyć
locale-gen :nieznane polecenie
make …. :nieznane polecenie. Noż KURDE!
Niby fajny, ale nie działa! Mnie taka dokumentacja odrzuca od samego narzędzia i nie chcę się w takie coś bawić. Wolę kupić coś, co będzie działać ad hoc i nie będę musiał dziergać i googlać. Szkoda czasu.
jednego nie mogę pojąc w wzorze jak rozumieć </ a tym bardziej za dzieleniem tego +