Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej

Artykuł będziemy opierać na prostej funkcjonalności w aplikacji webowej, tj. mamy formularz, w którym użytkownik może podać adres URL do zewnętrznego zasobu, a następnie aplikacja sama ten plik pobierze i wyświetli jakąś informacją zwrotną (np. treść pliku czy też informację, że pliku nie udało się z jakiegoś powodu pobrać). Przykład na Rysunku 1. Wprawdzie może się wydawać, że w większości prawdziwych aplikacji wyłączone jest wyświetlanie błędów, jednak ciągle jest to zaskakująco częsta przypadłość (także w przypadku aplikacji napisanych w Javie), która pozwala poznać nieco więcej informacji o procesie wgrywania plików.

Rysunek 1. Przykładowa funkcjonalność w aplikacji
Zacznijmy od najprostszego błędu, jaki można popełnić przy tego typu funkcjonalności. Dotyczy on większości mechanizmów pozwalających pobierać pliki z zewnętrznych źródeł, niezależnie od języka programowania, więc można go spotkać w PHP, Pythonie, Javie itp. Chodzi mianowicie o adresy prowadzące do plików na lokalnym dysku twardym, tj. np. file:///etc/passwd. Jeśli aplikacja nie zabezpieczy się w żaden sposób przed wykonywaniem tego typu żądań i pozwala na wyświetlanie zawartości pobranego pliku, ze strony atakującego jest to „easy-win”, bo zyskuje w ten sposób podatność pozwalającą na pobieranie dowolnych plików z dysku, na którym zahostowana jest aplikacja. W zależności od użytej technologii mogą być też dostępne inne schematy URL-i, które pozwolą na osiągnięcie tego samego efektu. W przypadku Javy, na przykład, pliki z dysku można też pobrać URL-em: netdoc://etc/passwd.
Dlatego właśnie podstawową metodą zabezpieczenia się przed tego typu atakami jest sprawdzanie, czy podany przez użytkownika URL zaczyna się od http: lub https: (ewentualnie jeszcze ftp:). Na tym jednak możliwe problemy bezpieczeństwa się nie kończą.
Często spotykanym modelem wdrożenia aplikacji webowych jest umieszczenie serwera aplikacyjnego w sieci lokalnej, zaś serwer dostępny z Internetu pełni tylko rolę reverse-proxy i przekierowuje przesyłanego do niego żądania do serwera w LAN-ie. Często zakłada się (niesłusznie), że włamywacze próbujący przeprowadzać ataku z sieci zewnętrznych nie mają żadnego dostępu do hostów w LAN-ie i wiele usług jest dostępnych z łatwymi hasłami lub bez jakiegokolwiek dodatkowego uwierzytelnienia. Przykładem popularnej usługi, która jeszcze do niedawna nie miała żadnych zabezpieczeń na warstwie aplikacyjnej, jest Solr.
Zatem, jeśli w webaplikacji nie przewidziano dodatkowych zabezpieczeń przed odwoływaniem się do dowolnych URL-i, złośliwy użytkownik może to wykorzystać do skanowania sieci lokalnej. Zobaczmy przykład na Rysunku 2. Użytkownik próbował odwołać się do portu 12345 na localhoście i otrzymał w odpowiedzi komunikat „Connection refused”. W przypadku portu otwartego nie są wyświetlane żadne błędy.

Rysunek 2. Komunikat „Connection refused” przy próbie dostępu do zamkniętego portu
Oczywiście nie każda aplikacja wyświetla tak szczegółowe błędy. W takich sytuacjach atakujący muszą polegać na innych czynnikach, by określić otwartość portu np. na czasie odpowiedzi (czas odpowiedzi na port filtrowany na firewallu może być znacząco dłuższy od czasu odpowiedzi na port otwarty).
Można wyróżnić kilka typowych metod, jeśli chodzi o próby ochrony przed tego typu atakami, tj. przed skanowaniem sieci lokalnej.
Najczęściej wprowadzana są czarne listy takich wartości adresów URL, które nie są dopuszczalne. Na przykład, chcąc uniemożliwić skanowanie localhosta, twórca webaplikacji mógł pomyśleć o odrzucaniu prób żądań do URL-i zaczynających się od:
Takie zabezpieczenie jest niestety ze wszech miar niewystarczające. Możemy je obejść na co najmniej kilka sposobów:
1. Autor aplikacji przewidział tylko, że początek URL-a nie może zaczynać się od localhost/127.0.0.1. Zapomniał jednak, że w URL-ach istnieje możliwość definiowania nazwy użytkownika, dlatego do tych samych zasobów można się odwołać np. w następujący sposób: http://nazwa@localhost.
2. Adres IP localhosta, czyli 127.0.0.1, można zapisać w wielu innych równoważnych sposobach. Oto przykłady:
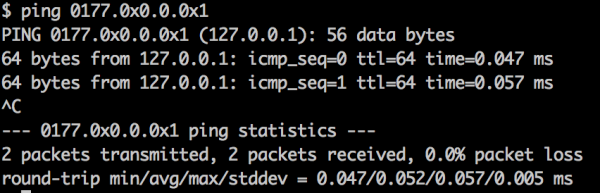
Rys 3. Dowód na to, że zapis 0177.0×0.0.0x1 jest równoważny 127.0.0.1
3. Atakujący może uruchomić w sieci swój własny serwer DNS lub skorzystać z jednego z istniejących, by skonfigurować dowolną domenę, tak aby po rozwiązaniu wskazywała na 127.0.0.1. Istnieje zresztą ogólnie dostępna domena vcap.me, w której dowolnie wybrana subdomena zawsze wskazuje na 127.0.0.1. Można to zweryfikować np. adresem test.vcap.me.
Powyższe przykłady wskazują wyraźnie na to, że przygotowanie filtru w aplikacji, który ochroni przed dostępem do niechcianych zasobów, jest bardzo trudne, bowiem atakujący mogą w różnoraki sposób zapisywać URL wskazujący de facto do tego samego zasobu. Stąd wypływa wniosek, że jedyną prawdziwie skuteczną metodą ochrony przed skanowaniem sieci lokalnej jest ustawienie odpowiednich reguł na firewallach. Host, z którego będą wykonywane żądania, powinien mieć zablokowaną możliwość wykonywania połączeń wychodzących do innych maszyn w LAN-ie.
Innym często stosowanym filtrem przez twórców aplikacji webowych jest sprawdzanie rozszerzenia plików. Często w takich wypadkach nie ma żadnych obostrzeń, jeśli chodzi o hosty, do których możemy się odwoływać. Twórca aplikacji webowej uznaje jednak, że jeśli dana funkcjonalność służy do pobierania obrazków, to sprawdza, czy URL wskazuje do pliku z obrazkiem. Niestety, zwykle nie idzie to w parze ze sprawdzaniem zawartości pliku, tj. pobierany jest dowolny plik, jeśli tylko ma właściwe rozszerzenie, niezależnie od tego, jaka jest jego zawartość.
Najczęstszym sposobem implementacji tego typu filtru jest po prostu sprawdzanie ostatnich znaków w URL-u. Jeśli URL kończy się np. na „.png”, uznajemy, że wskazuje on do pliku z obrazkiem. Takie zabezpieczenie jest jednak bardzo łatwe do obejścia, bowiem wystarczy dopisać odpowiednie rozszerzenie pliku po znaku zapytania lub hasza. Oznacza to, że według tak zaimplementowanego filtru URL: „http://localhost/tajny-zasob/?.png”, jest obrazkiem.
Aby zabezpieczyć się przed tego typu atakami, należy parsować adres URL i sprawdzać rzeczywistą nazwę pliku. Poza tym należy również sprawdzać zawartość pobranego pliku, tj. nie polegać wyłącznie na jego rozszerzeniu, a weryfikować, czy plik, wobec którego oczekujemy, że jest obrazkiem, faktycznie nim jest. Zazwyczaj można do tego użyć bibliotek wbudowanych do najpopularniejszych języków programowania. Tego typu sprawdzenia należy oczywiście przeprowadzać nie tylko do obrazków, ale również do innych typów plików, które są oczekiwane przez naszą aplikację.
Podatność Server-Side Request Forgery (SSRF) pozwala osobom przeprowadzającym ataki z Internetu na wykonywanie skanowania lub pobierania zasobów z sieci lokalnej. Ochrona przed tego typu atakami nie jest prosta. Przede wszystkim nie należy pozwalać na pobieranie zasobów ze schematów innych niż http/https. Ponadto, najlepiej posiadać w sieci lokalnej specjalny host, z którego będą wykonywane zapytania do zewnętrznych serwerów, i w konfiguracji firewalla uniemożliwić temu hostowi wykonywanie połączeń wychodzących do innych hostów w sieci lokalnej.
Jeśli oczekujemy pliku o konkretnym typie, należy sprawdzać jego rozszerzenie przez parsowanie URL-a oraz weryfikować zawartość pliku (np. biblioteką służącą do przetwarzania tego typu plików).
–Michał Bentkowski

Nie zapominajmy o IPv6, taki adres tez można podać (czy to numerycznie czy domenowo) a firewalle praktycznie tego tematu nie dotykają.
świetny artykuł, szapoba :)
Świetny to może i byłby, gdyby obok listy podatności podano proste sposoby jej eliminacji ;o)
No nie przesadzajmy ;) Core problemu poznane, każdy sprytny wykombin(googl)uje metody ochrony.
nie rozumiem, przecież podane są sugerowane sposoby profilaktyki :)
Localhost to cała podsieć 127.0.0.0/8, nie tylko 127.0.0.1
scislej mowiac 127.0.0.0/24
No właśnie chyba jednak 127.0.0.0/8 (jak napisał Krzysiek):
https://en.wikipedia.org/wiki/Localhost
A tak przy okazji – ciekawe jakby się zachowała opisywana aplikacja pobierająca plik z podanego adresu URL, jeśliby podano jakiś zewnętrzny adres http (na naszym “hakerskim” serwerze), który by przekierowywał (kodem 304) na inny zasób (np. http://localhost:12345 albo file:///etc/passwd)?