Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Adminie… Czy znamy Twoje grzechy? ;-) Sprawdź!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Adminie… Czy znamy Twoje grzechy? ;-) Sprawdź!

Witam Cię serdecznie Czytelniku i z góry dziękuję za zainteresowanie tematem artykułu. Od dłuższego czasu śledzę informacje/ monitoruję trzy główne serwisy opisujące problemy cyberbezpieczeństwa w Polsce (których nazw nie trzeba wymieniać). Moją uwagę zwrócił fakt, iż większość dostępnych tam artykułów, dotyczy wycieków danych, wykonanych ataków, nowych i znanych podatności oraz krótką i zgrabną informacją o tym, jak się przed nimi zabezpieczyć. W tekstach tych brakowało mnie – developerowi – konkretnego mięsa, tj. przykładów, które jasno i konkretnie wyjaśniłyby, jak podejść nie tyle do pisania bezpiecznego kodu w konkretnej technologii, co do wykonania projektu z wystarczającym (lub satysfakcjonującym) poziomem bezpieczeństwa.
Byłbym niesprawiedliwy, gdybym napisał, że nie ma takiego artykułu w ogóle, nie wykonując zawczasu krótkiego researchu w poszukiwaniu gotowego artykułu, który spełniałby moje potrzeby. Nie było to zadanie łatwe, gdyż słowo kluczowe .Net kojarzy się wyszukiwarkom przede wszystkim z końcówkami nazw domen. Na szczęście słowo Asp.Net jest już lepiej traktowane.
Mimo wszystko, tematyka bezpieczeństwa technologii .Net wydaje się być ekstremalnie pomijana albo też cieszy się niskim zainteresowaniem. Finalnie, na podstawie wyników wyszukiwarek artykułów wyżej wspomnianych serwisów, mamy przykładowo serię ogólnych artykułów o incydentach z 2010 roku [1], [2] i 2011 roku [3]. W drugim serwisie nie znalazłem nic. Natomiast na sekuraku udało mi się znaleźć jeden artykuł [4] z 2013 roku. Krótki, zwięzły, konkretny i – niestety – nieco nieaktualny.
Niejeden pentester pewnie by się teraz skrzywił, przecież niejednokrotnie przyszło nam sprawdzać legacy system napisany z wykorzystaniem technologii .aspx. I słusznie. Potwierdza to chociażby zawartość książki The Web Application Hacker’s Handbook [5], w której twórca narzędzia Burpsuite [6] Dafydd Stuttard kompleksowo opisał problem ViewState pomimo jego przestarzałości. Niestety, dziś przy rozwiązaniach typu Asp.Net MVC, czy Web API 2 może co szósty kandydat na junior lub medium dewelopera gdzieś, kiedyś słyszał czy też czytał, że jest jakieś .aspx… ale to legacy i “on i tak nie będzie w tym pisał”. Tylko czy w związku z tym umie pisać bezpiecznie w nowych technologiach? Nawiążę do tego w dalszej części artykułu.
Wracając do tematu – mamy jeszcze wyniki wyszukiwania Google, wśród których możemy znaleźć polsko- i obcojęzyczne teksty programistów-blogerów (i chwała im za to!), którzy dotknęli pojedynczych problemów. Google bardzo szybko zacznie też podpowiadać bezpośrednio strony dokumentacji Microsoftu [7] czy [8], które oczywiście serdecznie polecam studiować w pierwszej kolejności. Na zakończenie wspomnę jeszcze krótko o Troyu Huntcie (postaci, której nie muszę chyba przedstawiać). W 2011 roku napisał OWASP TOP 10 for .NET developers [9] i jest to bardzo dobry e-book, ale ma tę samą wadę, co wcześniej wspomniany artykuł. Jest nieco przestarzały.
W poniższym artykule chciałem kompleksowo opisać podstawowe mechanizmy bezpieczeństwa, które powinny być świadomie zaimplementowane przez developerów w każdym projekcie webowym zrealizowanym w technologii .Net.
Rysunek 1. GIODO odliczające czas do wejścia w życie ustawy RODO.
Uważam, że pierwszy sprint projektu powinien być przeznaczony w dużej części na ustalenie zasad wdrożenia mechanizmów bezpieczeństwa w aplikacji przez cały zespół. I nie jest to łatwe, kiedy wszystkie zaangażowane strony nie są potencjalnie tym zainteresowane. Z jednym wyjątkiem – Klienta – ten zawsze chce, żeby ”aplikacja była zabezpieczona” (a winą za wszystkie potencjalne incydenty najchętniej obarczyłby dostawcę). Miałem przyjemność widzieć dokumentację projektu stworzoną przez Analityka, która w istocie zakładała, że aplikacja ma być: skalowalna, modularna i łatwa w utrzymaniu. (Rozmarzyłem się). Brak jakiejkolwiek wzmianki na temat bezpieczeństwa. Nie zdziwi też pewnie fakt, że Product Owner, Analityk czy ktokolwiek odpowiedzialny za scope projektu nie będzie szczęśliwy, gdy zespół zacznie mu dokładać kolejne story w Jirze na implementacje zabezpieczeń, co przekładając się na deadline projektu również nie jest mile widziane przez PM-a. Na początku pierwszego sprintu naszpikowany adrenaliną i podnieceniem zespół deweloperski nie może się doczekać krwiożerczego wyścigu po zaklepanie pierwszych tasków z Jiry i jak najszybszego rozpoczęcia prac, tak by na jego koniec dowieść kawałek lśniącej, działającej funkcjonalności. Jak w prawdziwym, książkowym Scrumie przystało. Stąd rzeczy, o których napisałem poniżej, wymagają wcześniejszego uwzględnienia w wycenie projektu, by nikt nie był później zdziwiony, że chcesz dokładać kolejne nudne spotkania do kalendarza.
Zanim przejdziemy dalej, podsumujmy, co się dzieje na początku realizacji projektu z punktu widzenia developera.
Dodatkowe i niezbędne spotkania/czynności, są zawarte w dokumencie Microsoft Security Development Lifecycle [15], o których (z radością informuję że) wspominały już polskie portale [16], [17]. Zdaniem niektórych czołowych polskich ekspertów SDL autorstwa Microsoftu jest najlepszym na rynku. Na Rysunku 2 przedstawione zostały fazy implementacji SDL. Najbardziej interesujące mnie w tej chwili punkty to: 4, 6 i 7.

Rysunek 2. Microsoft Security Development LifeCycle.
Dlaczego jest to takie ważne? Nie mogę zaproponować oraz zaimplementować mechanizmów bezpieczeństwa na ślepo, nie wiedząc, co w zasadzie mam chronić i na jakim zasobie mam skupić się w szczególności. A do analizy świetnie nadadzą się tu dokumenty: analiza ryzyk, analiza powierzchni ataku oraz Threat Modeling, czyli modelowanie zagrożeń, z których ten ostatni wydaje mi się najistotniejszy. Pytanie: kto ma te procesy i dokumenty w zasadzie przygotować? Jeśli wyobrażasz sobie, że jest to Najjaśniejszy Pan i Wszystkowiedzący Władca Architekt – to jest to duże nieporozumienie.
Wielu z Was wyobraża sobie pewnie, że zespoły deweloperskie to grupa elitarnie dobranych specjalistów, starych wyg, która zawsze, ale to zawsze – skutecznie porozumiewa się między sobą kodem dwójkowym. W rzeczywistości, zespół scrumowy dość często przypomina świąteczną choinkę, gdzie gwiazdeczką jest architekt, bombeczkami jest 1-2 middlerów czy seniorów, a resztę zespołu uzupełnia parę wiotkich gałązek w postaci obiecujących juniorów. I w Scrumie siła. W realizacji Threat Modelingu powinien wziąć udział cały zespół z wszystkimi zaangażowanymi technicznymi jego członkami. I warto zawczasu przeznaczyć na to czas w sprincie. Po pierwsze, najistotniejszy jest tu proces wymiany doświadczeń. Na co dzień pracujemy z różnymi ludźmi, z różnymi kompetencjami, a każdy z nich może mieć inny i wartościowy pogląd na implementacje. Po drugie, transparentność. Istotne jest, by wszyscy członkowie zespołu mieli jasność i zgodność nie tylko co do tego, jak mają formatować wspólny kod, ale także: na co mają zwracać uwagę, pisząc go oraz jakie mechanizmy bezpieczeństwa są przewidziane w aplikacji. Byłoby to nieco dziwne, gdyby wszyscy polegali tylko na pomysłach architekta i na oczekiwaniu, czym może nas zaskoczyć w połowie projektu. Po trzecie, jest to ogromna wartość dodana dla najmniej doświadczonych członków zespołu. Zyskają oni poczucie misji, by czegoś nie spaprać, ale także, co ważniejsze, okazję do rozwoju i poszerzania swojej wiedzy. Dodatkowo, bardziej doświadczeni koledzy będą wspierać architekta w trakcie Code Review, wyłapując co poważniejsze, potencjalne błędy.
Czym w zasadzie jest Threat Modeling? W dużym skrócie jest to proces wyznaczania potencjalnych zagrożeń w aplikacji oraz proponowania bezpośrednich metod mitygacji. Znając swojego wroga, jesteśmy w stanie przygotować odpowiednią taktykę obronną. Dla wielu z was wykonanie takiego procesu w swoich aplikacjach może wydawać się zbyt złożonym i trudnym zadaniem. Stąd rekomenduję, by zacząć od identyfikacji ogólnych zagrożeń, a wraz z czasem i rosnącym doświadczeniem, rozbijać je na bardziej szczegółowe przypadki. W końcu nikt nie powiedział, że Threat Modeling może być wykonany tylko jednorazowo. Spokojnie można przyjąć podejście iteracyjne – co kilka sprintów spotkać się i wspólnie ponownie rozpatrzyć nowe obszary zagrożeń.
Mając ustalone w zespole transparentne zasady dbania o bezpieczeństwo, możemy przystąpić do implementacji. Mówi się, że .Net Framework jest domyślnie bardzo dobrze zabezpieczony. Sprawdźmy to w praktyce.
Jedną z pierwszych rzeczy, jaką widzimy w nowo utworzonym projekcie, jest możliwość uruchomienia projektu w konfiguracjach Debug i Release (Rysunek 3). T to jedno z najważniejszych i najpotężniejszych narzędzi bezpieczeństwa oferowanych przez framework. Stąd jedną z pierwszych rzeczy, które wykonamy w pierwszym sprincie, jest przygotowanie i poprawne skonfigurowanie wersji produkcyjnej aplikacji, czyli Release.
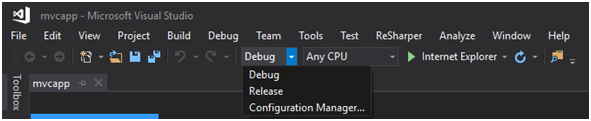
Rysunek 3. Domyślne konfiguracje projektu zawarte w templacie.
¡Hola! ¡hola!, ¡amigo! Ktoś tu mógłby się skrzywić – przecież nie mamy napisanej żadnej funkcjonalności, więc po co szykować się na produkcję? To prawda. Ale praktyka pokazuje, że przygotowywanie aplikacji do wyjścia na produkcję kilka dni przed deadline to zły pomysł, wiąże się to z dużym stresem i niezliczoną liczbą niekoniecznie przewidzianych nadgodzin. Poza tym, równocześnie z tym zadaniem inni członkowie zespołu będą prawdopodobnie przygotowywać warstwę/moduł dostępu do bazy danych, połączenie z zewnętrznym webservicem, czy połączenie do zewnętrznego SSO, a także konfigurację Continous Integration, a to wszystko jest ze sobą powiązane.
O braku takiego podejścia boleśnie przekonała się bohaterka skandalu z Kalkulatorem Wyborczym – Pani Agnieszka – o czym można było przeczytać tu [18], [19], tu [20], [21], czy też tu [22] i tu [23] – która wykonała release aplikacji w konfiguracji Debug, zostawiając pliki PDB w publicznie dostępnej instalce. Community wystarczająco osądziło i skomentowało ten temat, w związku z czym nie będę dodawał więcej od siebie.
Każda konfiguracja może mieć swoje własne symbole kompilacyjne. Na Rysunku 4 widać domyślne ustawienia dla konfiguracji Debug, która ma obydwa symbole DEBUG i TRACE. Dla odmiany Release ma tylko symbol TRACE.
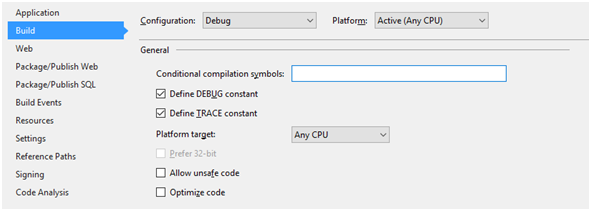
Rysunek 4. Domyślne ustawienia konfiguracji Debug.
Nic nie stoi na przeszkodzie, by dodać kolejne konfiguracje, np. dla środowiska Stage czy UAT i zdefiniować dla nich własne symbole, tak jak na Rysunku 5. Wszystko zależy od Twojego środowiska deweloperskiego. Sam zdecydujesz, ile konfiguracji projektu wymaga Twoje Continuous Integration czy Continuous Delivery.
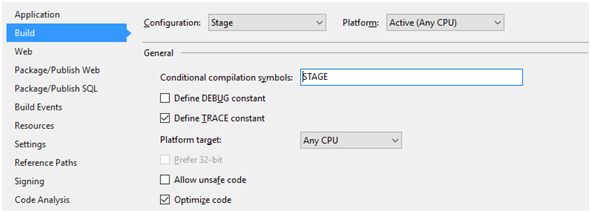
Rysunek 5. Ustawienia konfiguracji customowej konfiguracji Stage.
Dyrektywy [24] są bardzo proste w użyciu. Na Rysunku 6 został pokazany przykład obrazujący konfigurację Stage, dla której wykona się tylko kod zawarty w dyrektywie z symbolem STAGE. Ot i cała filozofia. Mamy pierwsze narzędzie, które pozwala nam decydować o tym, który kod jest na produkcji, a który nie. Dodam tylko, że w aplikacjach webowych nie korzysta się z dyrektyw tak często, jak to się robi w aplikacjach mobilnych pisanych w technologii Xamarin [25]. W Xamarinie nie mamy niestety pod ręką odpowiednika pliku web.config, stąd tam też dyrektywy namiętnie się wykorzystuje. A jeśli o pliku web.config mowa…
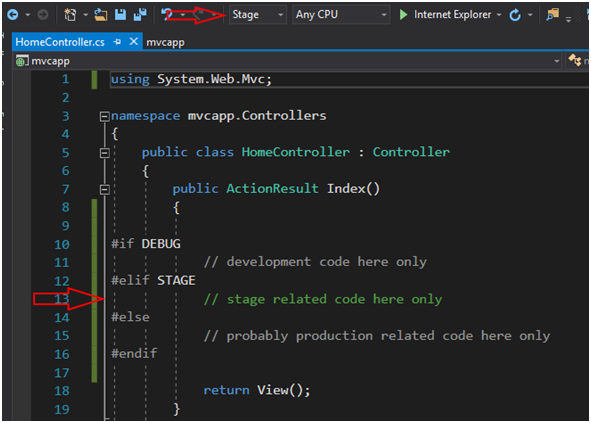
Rysunek 6. Przykład użycia dyrektyw.
Plik web.config [26] jest głównym plikiem konfiguracyjnym projektu o formacie xml. Oprócz mnóstwa mniej lub bardziej zrozumiałych treści konfiguracyjnych lądują tutaj connection stringi do bazy danych, adresy url zewnętrznych webservisów, zmienne aplikacyjne [27], a takżę konfiguracje filtrów anty XSS-owych czy konfiguracje nagłówków i flag HTTP. Słowem – mózg całego projektu.
.Net zapewnia idealne narzędzie do zarządzania tym plikiem dla różnych konfiguracji projektu – transformacje [28]. Domyślnie utworzony projekt posiada już w swoim szablonie dwie transformacje dla Debug i Release (Rysunek 7).
Rysunek 7. Domyślne transformacje pliku web.config.
Plik Web.Debug.config jest raczej niepotrzebny – przyjęło się, że plik Web.config zawiera konfiguracje dla maszyny deweloperskiej. Potwierdza to w zasadzie podejście Microsoftu, gdyż w pliku Web.Release.config dostajemy przykład użycia pierwszej transformacji. Na Rysunku 7 widać, że domyślnie aplikacja ma się kompilować z możliwością debugowania [29], natomiast na Rysunku 8 – że transformacja usuwa tę możliwość. Wartość tego atrybutu, o dziwo, nie wpływa na generowanie pliku z symbolami (.pdb), lecz w dużej mierze na wydajność aplikacji i jej zachowanie, o czym można dalej poczytać między innymi tu [30].
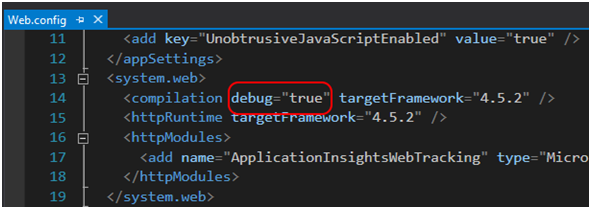
Rysunek 7. Domyślne konfiguracja web.config.

Rysunek 8. Transformacja pliku z regułą usunięcia atrybutu debug.
Jest tylko jeden zabawny haczyk. Transformacje nie działają, gdy ręcznie wykonamy Build aplikacji z poziomu VS (sic!). Stąd, kopiowanie aplikacji z folderu /bin/Release/ jest złym pomysłem, ponieważ technicznie dostaniemy ten sam web.config, co w folderze /bin/Debug. Aby poprawnie wykonać transformację, należy wykonać Publish aplikacji. W ramach testów proponuje wykonać Publish do folderu. Kolejność wymaganych czynności jest wystarczająco opisana tutaj [31]. Na Rysunku 9 możemy zobaczyć zawartość folderu aplikacji po publikacji. Widać, że wszystkie pliki .pdb i .xml dotyczące bibliotek frameworka zostały usunięte, a web.config nie zawiera już atrybutu debug.
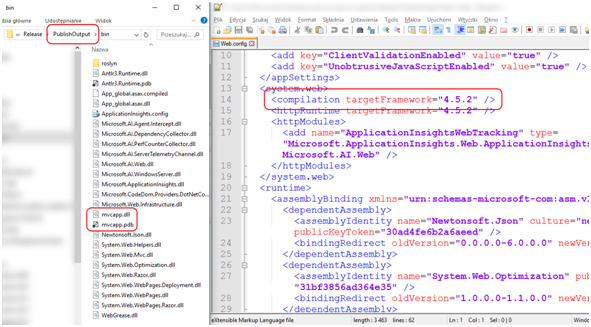
Rysunek 9. Zawartość folderu z opublikowaną aplikacją.
Ciekawą dyskusję na temat plików .pdb można podejrzeć tutaj [32]. Aby ostatecznie wyłączyć generowanie plików .pdb, trzeba dostać się się do odpowiedniej konfiguracji projektu, schowanej pod przyciskiem Advanced Build Settings i wybrać opcję “none” w Debugging information (Rysunek 10). Decyzję o tym, czy pliki generować czy nie, zostawiam Czytelniku Tobie. Jak słusznie zwrócił uwagę jeden z dyskutujących [32] – bez tego pliku nie będziemy w stanie wykonać tzw. Remote debugging na zdalnym serwerze. Ta sama osoba zwróciła też uwagę na to, by odłożyć sobie te pliki na tzw. “czarną godzinę”.
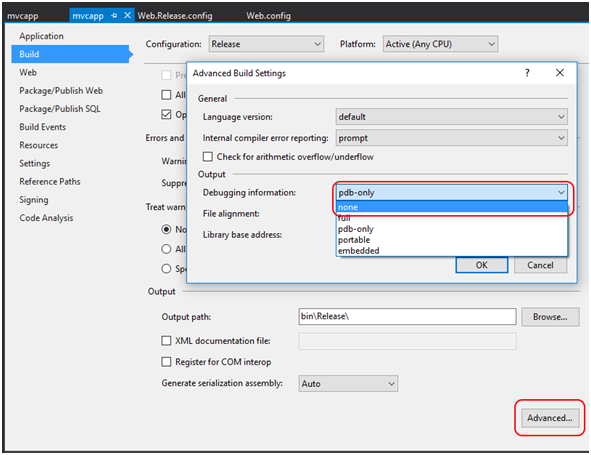
Rysunek 10. Wyłączenie generowania plików .pdb.
Do tematu dyrektyw i transformacji obiecuję wracać jeszcze nie raz w dalszych częściach artykułu.
Logi aplikacji to Twoi przyjaciele. Wie to każdy developer, który choć raz poświęcił pełny tydzień na znalezienie tego jednego błędu, przez który:
Poza tym, są też ponoć przydatne przy forensicu, gdy trzeba zidentyfikować źródło incydentu bezpieczeństwa. Dlatego jest to kolejny temat na sprint numer jeden.
W bibliotece nugetów jest wiele doskonałych i gotowych rozwiązań. Osobiście, polecam wykorzystanie popularnego NLoga [34]. Jego zaletą jest przede wszystkim dojrzałość. Oferuje między innymi zapis do pliku, bazy danych, eventloga, na określony port hosta, do webservisu czy wysłanie na adres e-mail. Poza licznymi opcjami konfiguracyjnymi oferuje też poprawny zakres poziomów logowań: debug, info, warning, error oraz fatal.
Z drugiej strony, korzystanie z takiego pakietu może być czasem bronią obosieczną. Słyszałem kiedyś o projekcie, w którym produkcja stanęła – nie działała żadna funkcjonalność systemu, a logi przechowywane w plikach oraz w bazie danych przestały się zapisywać. Okazało się, że w wyniku jakiegoś błędu w systemie, bardzo szybko wyczerpywała się pula dostępnych połączeń do bazy MS Sql. NLog w pierwszej kolejności próbował wykonać zapis logu do bazy danych, ale w wyniku błędu z połączeniem crashował się i nie próbował nawet wykonać zapisu do pliku. Dość niefortunny przypadek (błąd występował w starszych wersjach NLoga).
Jeśli chodzi o to, co należy logować, jest to indywidualna decyzja każdego zespołu. Na pewno warto rejestrować wszystkie zdarzenia związane z autoryzacją i statusem kont użytkowników (logowanie, wylogowanie, rejestracja, aktywowanie, zablokowanie, zmiana hasła, uśpienie, usunięcie, itp. itd.). Do tego dochodzą wszystkie funkcjonalności uznane za krytyczne oraz istotne, a to bardzo zależy od biznesu, który chcemy zinformatyzować.
Przechodząc do konkretów, dokumentacja NLoga jest dość wyczerpująca jeśli chodzi o metody konfiguracji pakietu [35]. Skorzystajmy więc z możliwości wrzucenia konfiguracji do pliku web.config, gdzie mamy przygotowane już transformacje. Przykładowa konfiguracja pokazana jest na Rysunku 11 – wszystkie logi wyświetlamy w konsoli Output, do poszczególnych plików i do jednego wspólnego. Dzięki temu znacznie łatwiej będzie nam te pliki analizować – szukając konkretnych zdarzeń lub weryfikować ich kolejność.
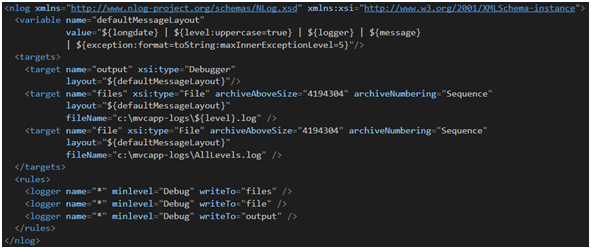
Rysunek 11. Przykładowa konfiguracja NLoga dla środowiska deweloperskiego.
Na Rysunku 12 pokazany został efekt składowania logów na dysku, a na Rysunku 13 logi wyświetlone w konsoli.
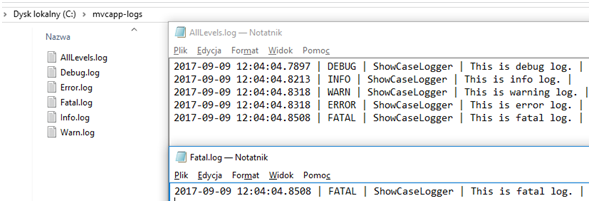
Rysunek 12. Efekt składowania logów na dysku.

Rysunek 13. Logi wyświetlone w konsoli.
Oczywiście nie chcemy, by wszystkie poziomy logów były dostępne na produkcji. Nie chcemy też wysyłać ich na niepożądane outputy, stąd niezbędna jest modyfikacja pliku web.Release.config (Rysunek 14).
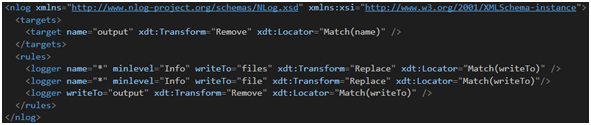
Rysunek 14. Transformacja sekcji NLog dla konfiguracji Release.
Wynik transformacji przedstawia Rysunek 15. Dzięki temu podejściu możemy mieć pewność, że logi na produkcji istnieją i nie będą zawierać informacji debugowych.
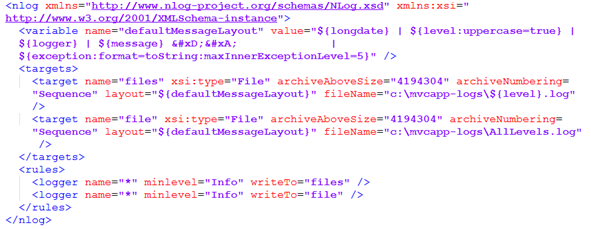
Rysunek 15. Wynik transformacji konfiguracji Release.
Dobrze, a co jeżeli chcemy logować absolutnie wszystko (czyli każdy poszczególny Request i Response)? Da się to zrobić, ale ostrzegam, to nie jest zabawa dla amatorów. Tego typu implementacje trzeba wykonywać cierpliwie, rozsądnie, powoli i z uwagą. Implementacje będą się też różnić zależnie od tego, czy pracujemy z aplikacją MVC czy Web API.
Proponowane tu podejście jest opozycyjne do pisania kodu odpowiedzialnego za logowanie we wszystkich możliwych Controller-ach i Action-ach czy ActionFilters, które de facto mają inne przeznaczenie. Nie mówię, że poszczególne logi nie powinny być wykonywane dokładnie w tych miejscach, ale jeśli chcemy logować absolutnie wszystko, są na to lepsze sposoby. Mój główny zarzut wobec ActionFilterów, to to, że są wykonywane w kolejności ich zarejestrowania. Gdyby zarejestrować filtr do logów zbyt późno w kolejce, mógłby nigdy nie zostać wywołany w sytuacji, gdy np. inny filtr wyłapie exception.
W przypadku Web API, w pierwszej kolejności należy zapoznać się z dokumentacją cyklu życia Requestu i Response’a zobrazowaną na plakacie [36]. Została ona również szczegółowo opisana przez Matthew P. Jonesa w pozycji [37]. Jak widać, wszystkie Message przechodzą przez byt .Netowy zwany DelegatingHandler (Rysunek 16).
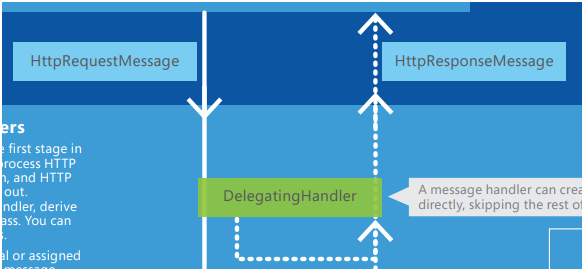
Rysunek 16. DelegatingHandler w ASP.NET WEB API 2: HTTP MESSAGE LIFECYLE.
Poprawny opis wykorzystania DelegatingHandlera można znaleźć też w artykule Fredrik Norména [38]. Zainteresowanym również polecam. Gdybym chciał opisać implementację tego rozwiązania, musiałbym zacytować prawie całą treść z polecanego artykułu; zachęcam do przyjrzenia się implementacji klas MessageHandler i MessageLoggingHandler w wykonaniu Norména.
Sytuacja wygląda nieco inaczej w przypadku MVC. Tutaj również mamy dostępny plakat prezentujący cykl życia aplikacji [39], choć jest on mniej czytelny (czytaj: mniej marketingowy). (Jeżeli plakat komuś nie wystarcza, Chetan Vihite opisał w miarę precyzyjnie cały proces w [40]). Wynika z niego, że jeśli chcemy mieć wpływ na wszystkie Requesty i Response’y, w aplikacji musimy zaimplementować i użyć IHttpModule [41], a w nim podpiąć się do eventów BeginRequest oraz EndRequest (Rysunek 17).
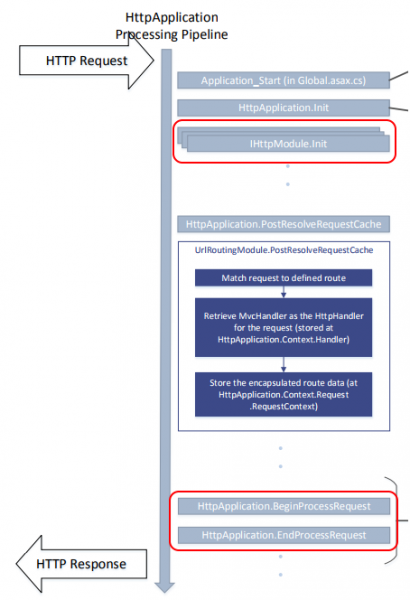
Rysunek 17. HttpModule w ASP.NET MVC 5 APPLICATION LIFECYCLE.
Na Rysunku 18 przedstawiona została prymitywna implementacja modułu IHttpModule. Pamiętajmy, że trzeba go jeszcze zarejestrować w pliku web.config, by móc za pomocą transformacji sterować modułami i decydować, które z nich mają się znaleźć na produkcji, a które nie.
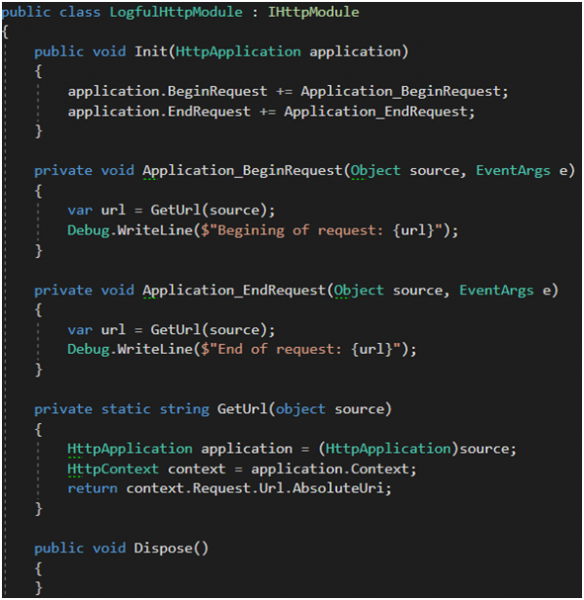
Rysunek 18. Prymitywna implementacja interfejsu IHttpModule.
Wynik działania implementacji można podejrzeć na Rysunku 19.
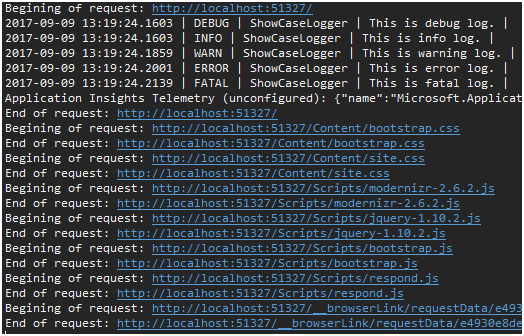
Rysunek 19. Wynik logowania w konsoli przy pomocy własnego IHttpModule.
Jak widać, logowanie w frameworku .Net to pestka.
Może się wydawać, że minifikacja kodów javascript i css [42] podchodzi bardziej pod temat optymalizacyjny niż security. W końcu wszystkie reguły walidacyjne pisane client-side mają swój odpowiednik w kodzie serwerowym, prawda? Niemniej, okazuje się, że utrudnienie czytania kodów javascript pentesterowi może powodować wydłużenie jego pracy. (O ile jest tak cierpliwy, by czytać zminifikowany kod).
Weźmy na warsztat taki z pozoru banalny przykład – co robi poniższy kod (Listing 1)?
$(document).ready(function(){var n=$("#clicableButton");n.click(function(){var n=$("#textInput"),t=n.val(),i=$("#dangerousDiv");i.html(t)})})
Listing 1. Przykład zunifikowanego kodu.
W tej sytuacji użytkownik może z-XSS-ować samego siebie. Wszystko przez wykorzystanie potencjalnie niebezpiecznej funkcji jQuery .html(). Nietrudno wyobrazić sobie, że dane do tej funkcji trafiają nie z inputu wprowadzanego bezpośrednio przez użytkownika, lecz np. z odpowiedzi calla webservice’u, który akurat przekazuje dane wcześniej wprowadzone do systemu w innym jego punkcie. Pentester, który przeklikał już całą aplikację, wykorzystał wszystkie możliwe skanery, wykonał fuzzing wszystkich formularzy zawsze może zerknąć do kodu źródłowego client-side w poszukiwaniu nietypowych użyć właśnie takich funkcji jak .html().
Nie ma wątpliwości, który przypadek (z minifikacją czy bez) ułatwia znalezienie potencjalnego miejsca do wstrzyknięcia XSS-a.
$(document).ready(function() {
var button = $("#clicableButton");
button.click(function () {
var input = $("#textInput");
var text = input.val();
var div = $("#dangerousDiv");
div.html(text);
});
});
Listing 2. Przykład kodu bez minifkacji.
O minifikacje kodów trzeba zadbać również na początku projektu, sprintu. Spotkałem się z przypadkami, w których zespół dostał w spadku legacy kod, lub potężny framework napisany przez innych developerów i wiele miesięcy później, tuż przed releasem, okazywało się, że minifikacja nie działa. Zminifikowane kody css i/lub javascript były źle interpretowane przez przeglądarkę (czytaj: napotkały kod, którego nie rozumiały i wyrzucały w konsoli wyjątek). Zdarzało się to przy bardziej wymyślnych css-ach oraz błędnie przeparsowanych kodach z TypeScript [43] na javascript. Gdyby QA zespołu co sprint mógł zweryfikować aplikację na środowisku Stagingowym, problem mógłby zostać wykryty wcześniej, nie bezpośrednio przed releasem. Zespół miał już sięgać po świętego Gralla developmentu, a więc wyjść na produkcję. Myślicie, że poświęcili wówczas dodatkowy czas na naprawę wszystkich błędów? Pomidor.
Jeśli chodzi o konfigurację, teoretycznie nie trzeba nic robić. Minifikacją steruje atrybut debug w pliku web.config, o którym już wspominałem, natomiast przypomnę go raz jeszcze (Rysunek 20). Jedyne o czym trzeba pamiętać, to o poprawne wykorzystanie tzw. Bundli. I tu się okazuje, że to nie taka prosta sprawa.
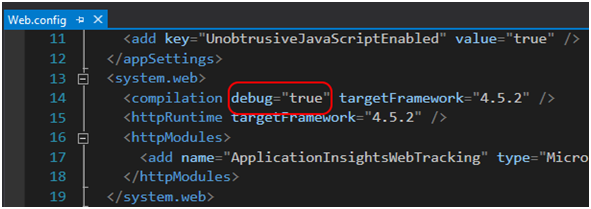
Rysunek 20. Atrybut debug steruje minifikacją.
Jeżeli chcemy dodać nowy plik css lub javascript do projektu musimy dodać go do folderów Content lub Script i zarejestrować go w pliku BundleConfig (Rysunek 21). Technicznie rejestracja nie jest wymagana do tego, by skorzystać ze skryptów, ale jej pominięcie to szybka droga do błędu, o czym za chwilę.
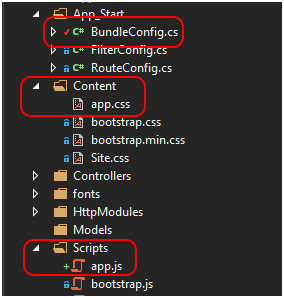
Rysunek 21. BundleConfig oraz foldery Content i Script.
Rejestracja skryptów jako bundle pokazana została na Rysunku 22.
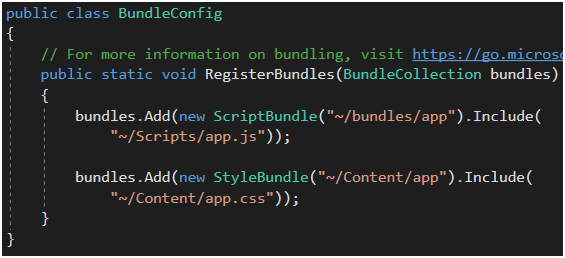
Rysunek 22. BundleConfig oraz foldery Content i Script.
Finalnie z plików trzeba jakoś skorzystać (Rysunek 23). Wrzucamy je w .cshtml zależnie od naszych potrzeb, tutaj zostały one wrzucone do _Layout.cshtml, dzięki czemu są dostępne na każdej podstronie aplikacji.
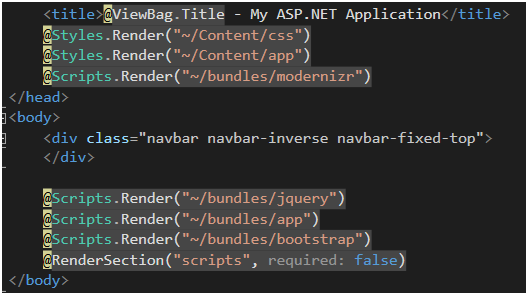
Rysunek 23. Użycie Bundli w pliku _Layout.cshtml.
Jak widać, nie korzystamy tutaj z kodu podobnego do tego z Listingu 3. Choć technicznie moglibyśmy to zrobić, aplikacja dalej będzie działać poprawnie. Omijamy wtedy jednak cały mechanizm Bundle, a co za tym idzie, minifikację. Co ciekawe, za pomocą wykorzystania funkcji statycznych Render klas Styles i Scripts wynikowy html będzie zawierał kod dokładnie taki sam jak w Listingu 3.
<link rel="stylesheet" type="text/css" href="/Content/app.css"> <script src="/Scripts/app.js"></script>
Listing 3. Przykład zunifikowanego kodu.
Największym grzechem wszystkich developerów .Netowych jest inline-owanie skryptów w plikach .cshtml, tak jak to pokazano na Rysunku 24. Dlaczego? Po pierwsze, nigdy nie zostaną one zminifikowane. Po drugie, często potrzebują innych bibliotek, np. jQuery, by działać. Zazwyczaj w takim przypadku linijka odpowiadająca za dodanie jQuery w _Layout.cshtml zaczyna swoją ekscytującą podróż po pliku – z dołu na jego górę. (By ominąć problem skorzystałem tutaj z CDN jQuery, tak jak widać). Po trzecie, osłabia to wykorzystanie Content Security Policy [44], w sytuacji gdy ktoś potencjalnie chciałby sobie CSP wdrożyć w swój projekt. (Do czego jeszcze wrócę).
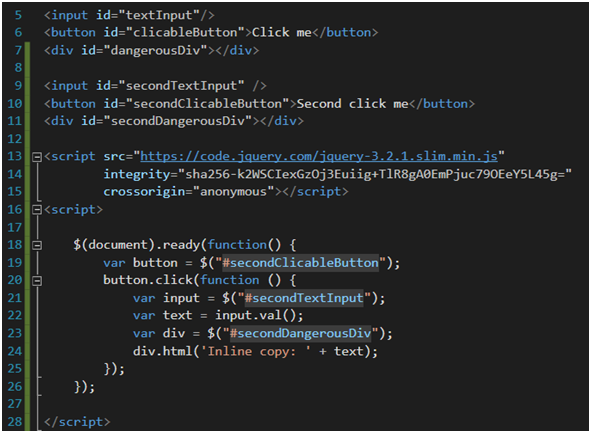
Rysunek 24. Użycie inline javascript w pliku .cshtml.
O ile taki przypadek kodu można jeszcze naprawić, to kodu przedstawionego na Rysunku 25 już nie. Załóżmy, że mamy zadeklarowany model Person (Rysunek 24), który użyjemy w widoku. Własności modelu, jakiekolwiek by nie były, wstawiamy następnie w kod html oraz… w kod javascript. Podany tutaj przykład wydaje się nie mieć sensu. Widziałem takie implementacje, w których bardzo skomplikowany model był mieszany w plikach .cshtml z kodem javascriptowym i w efekcie, po kilku iteracjach, nie była możliwa jego refaktoryzacja. Stąd, moja najszczersza rekomendacja: od samego początku starajmy się nie pisać kodu w ten sposób.
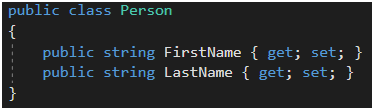
Rysunek 24. Model jako klasa Person.
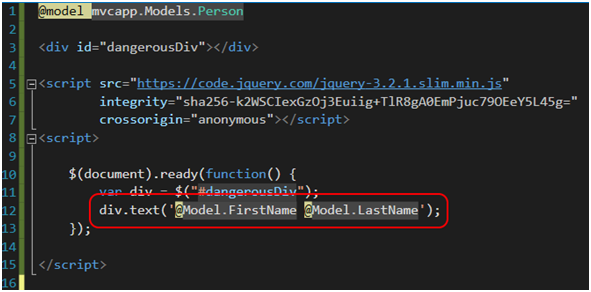
Rysunek 25. Wymieszanie właściwości modelu z kodem javascript w pliku .cshtml.
Wracając do problemu CSP… Załóżmy, że chcemy wdrożyć regułę jak pokazano na Listingu 4. Mając kod podobny do tego z Rysunku 25, nie będziemy w stanie tego zrobić. Konsola posypie się błędami (Rysunek 26) i skończymy na tym że: a) nie wdrożymy CSP, b) wdrożymy CSP z ‘unsafe-inline’, czyli zrezygnujemy z podstawowego mechanizmu obrony CSP przed XSS-ami.
Content-Security-Policy:script-src 'self'; style-src 'self'; img-src 'self';
Listing 4. Przykład podstawowej reguły CSP.
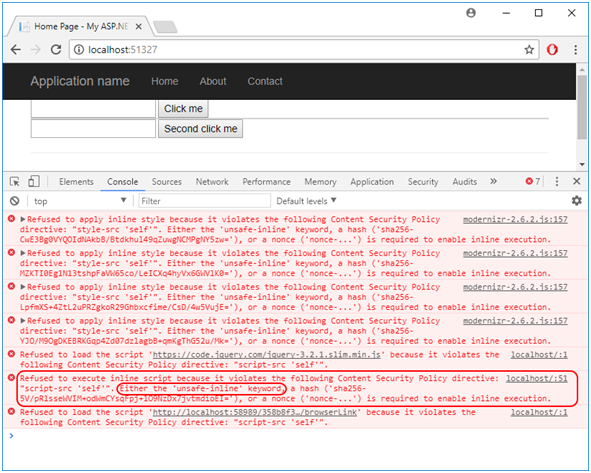
Rysunek 26. Chrome reagujący na reguły CSP.
Kończąc ten wątek dodam, że istnieje dodatkowa metoda na sterowanie minifikacją w .Net. Tak jak pisałem wyżej, mechanizm jest kontrolowany przez atrybut debug w pliku web.config (Rysunek 20), ale można zachowanie tego atrybutu nadpisać. Wystarczy w pliku BundleConfig zmienić wartość parametru EnableOptimizations tak jak na Rysunku 27. Wyobrażam sobie, że ktoś mógłby chcieć w celach testowych włączyć lub wyłączyć mechanizm pozostawiając przy tym możliwość debugowania aplikacji. Aby uniknąć jednak wpadki na produkcji, czyli momencie, gdy jesteśmy już po testach deweloperskich, osadźmy ten kawałek kodu w dyrektywę DEBUG, żeby nie miało to wpływu na inne konfiguracje projektu.
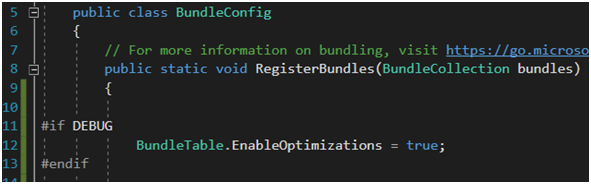
Rysunek 27. Sterowanie minifikacją bundli poza plikiem web.config.
Gdy myślę o tym, jak czasami developerzy zaniedbują temat obsługi błędów w projektach komercyjnych, przychodzi mi na myśl anegdotka ze sklepu ze sprzętem motocyklowym. Sprzedawca, opowiedział mi historię pewnej klientki, która kupując kurtkę czy rękawice ochronne wymagała, by towar był przede wszystkim “ładny”. Nie miało znaczenia, czy w zestawie były protektory (wzmocnienia na rękawach czy rękawicach chroniące kierowcę przed uszkodzeniami skóry przy ewentualnych upadkach) czy nie, gdyż głównym kryterium wyboru dla przyszłej użytkowniczki były wzory i desenie na odzieży (kwiaty, różowe motylki). Właściciel sklepu początkowo próbował zwrócić uwagę na kwestie bezpieczeństwa i związane z nią elementy odzieży, jednakże poddał się, gdy patrząca na niego z góry kobieta odpowiedziała, że ”nie potrzebuje protektorów, ponieważ ona nie będzie się wywracać”. Podobnie jak bohaterka anegdoty, również wielu developerów sprawia wrażenie przekonanych, że ich aplikacja nie będzie mieć błędów.
Jedno jest pewne: nie chcemy dać absolutnie żadnej wiedzy o “bebechach” aplikacji potencjalnemu atakującemu. Dlatego też, nie informujemy go o tym, jaki wyjątek nastąpił w aplikacji. Nie informujemy go także, czy posiada uprawnienia do danego zasobu czy też nie. Nie dajemy mu znać, czy obiekt o takim id istnieje czy nie istnieje w systemie. Nie zawracamy mu głowy tym, czy podany url jest poprawny czy niepoprawny. W każdym przypadku, bezdyskusyjnie, informujemy go tym samym komunikatem: “Bardzo nam przykro, wystąpił błąd”.
Podstawowy template projektu webowego w VS (Visual Studio), nie posiada włączonej obsługi błędów. Gdy wystąpi wyjątek zobaczymy więc stronę przygotowaną przez serwer IIS [45] (Rysunek 28). Nie panikujmy! Tak szczegółowy komunikat o błędzie jest wyświetlany tylko na localhoście lub w przeglądarce włączonej bezpośrednio na serwerze hostującym IIS. Tzw. Remote Host zobaczy nieco inną stronę z informacją o napotkanym przez serwer błędzie oraz zwrotką kodu HTTP 500: Internal Server Error, której wygląd jest mało elegancki.
Rysunek 28. Domyślna strona błędu w IIS.
Byłoby idealnie posiadać scentralizowane narzędzie do zarządzania błędami – i takie narzędzie w .Net istnieje. Ze względu na różnicę cykli życia message’y w MVC i Web API, tak jak w logowaniu, tak i tutaj musimy zaimplementować dwa różne mechanizmy zależnie od technologii. W przypadku MVC będzie to interfejs IExceptionFilter, w przypadku Web API będzie to IExceptionHandler oraz klasa ExceptionFilterAttribute.
Pokaże poniżej podstawową implementację interfejsu IExceptionFilter w nieco uproszczonej wersji. Pamiętajmy, że każdy zespół może mieć inne potrzeby logowania błędów, stąd to, co będzie zalogowane oraz w jaki sposób może być bardzo indywidualną kwestią.
W pierwszej kolejności sprawdźmy, jaki typ requestu zakończył się błędem. Może to być zwykły request lub AJAX (Rysunek 29). AJAX rozpoznamy po nagłówku HTTP XMLHttpRequest. Następnie obsługujemy błąd, a na zakończenie logujemy go np. za pomocą NLoga.
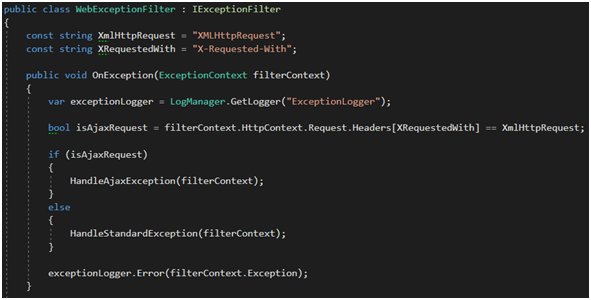
Rysunek 29. Implementacja IExceptionFilter.
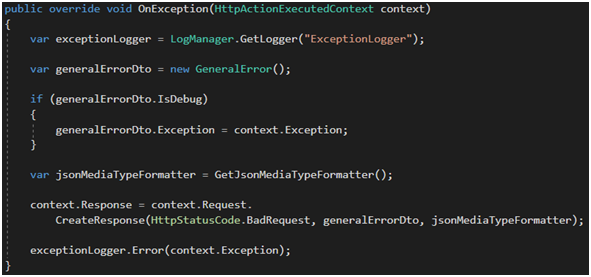
Jeśli chodzi o obsługę błędu, trzeba przygotować odpowiedni widok do wyrenderowania przyjaznej strony z błędem (Rysunek 30). Klasa GeneralError jest moim uproszczonym modelem reprezentującym informacje o nim (Rysunek 31). Zwróćmy tu uwagę na propertę IsDebug – wykorzystam ją na widoku w celu wyrenderowania informacji o błędzie. Takie podejście znacznie uprości życie QA, który będzie raportował błąd. W zasadzie uprości to też moje życie, bowiem w raporcie błędu zawsze będę miał informację o wyjątku, który wystąpił.
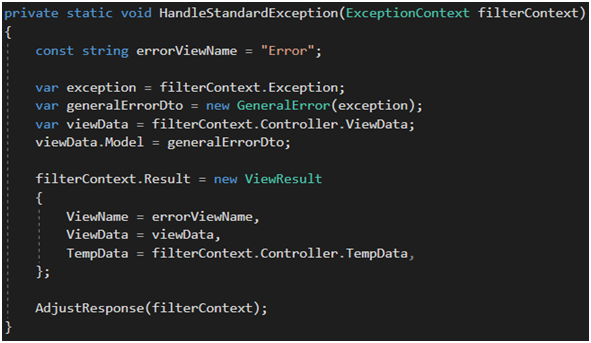
Rysunek 30. Implementacja IExceptionFilter c.d.
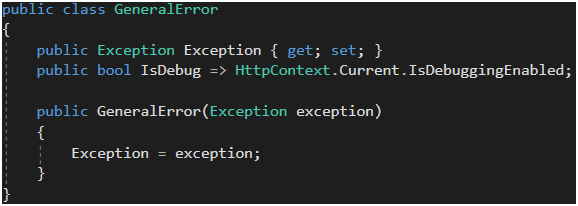
Rysunek 31. Implementacja IExceptionFilter c.d.
Jeśli chodzi o metodę AdjustResponse, (Rysunek 32) musimy poinformować framework że obsłużyliśmy wyjątek. Dodatkowo warto zdecydować, czy nadpisujemy legacy zachowanie IIS w wersji 7.0 [46].
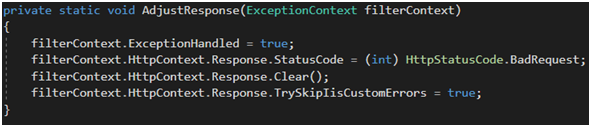
Rysunek 32. Implementacja IExceptionFilter c.d.
W mojej przykładowej implementacji skorzystałem z defaultowej strony błędu znajdującej się w /Views/Shared/Error.cshtml. Dokonałem tylko drobnej modyfikacji, by zależnie od konfiguracji wyświetlić jeszcze dodatkowe informacje o błędzie.
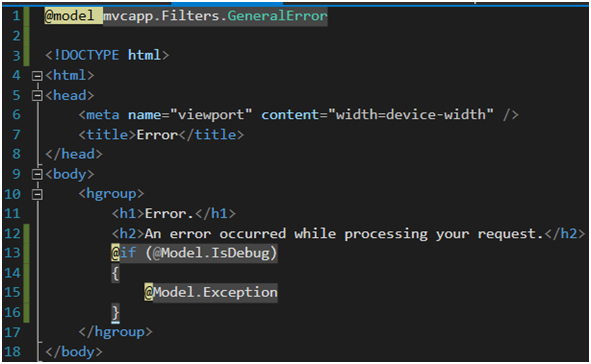
Rysunek 33. Implementacja IExceptionFilter c.d.
Metoda HandleAjaxException będzie zachowywała się trochę inaczej. Musimy zwrócić tutaj nie widok, lecz obiekt json. Nie będziemy mogli w tym wypadku swobodnie sterować widokiem za pomocą modelu. Żeby mieć kontrolę nad tym, jak obiekt będzie serializowany do jsona, możemy skorzystać z customowych atrybutów, (które wpłyną na serializację) lub np. dyrektyw. Sam poszedłem na łatwiznę z wykorzystaniem dyrektyw (realnie trzeba by było jeszcze zapewnić, by nieużywane i puste właściwości obiektu pominąć w serializacji do jsona!). Dodatkowo konieczne jest ręczne skopiowanie propert klasy Exception do własnego obiektu (Rysunek 35), gdyż ten nie serializuje się tak łatwo do jsona [47].
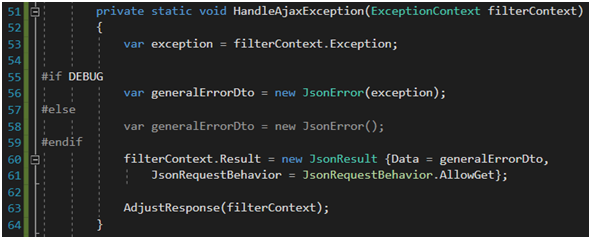
Rysunek 34. Implementacja IExceptionFilter c.d.
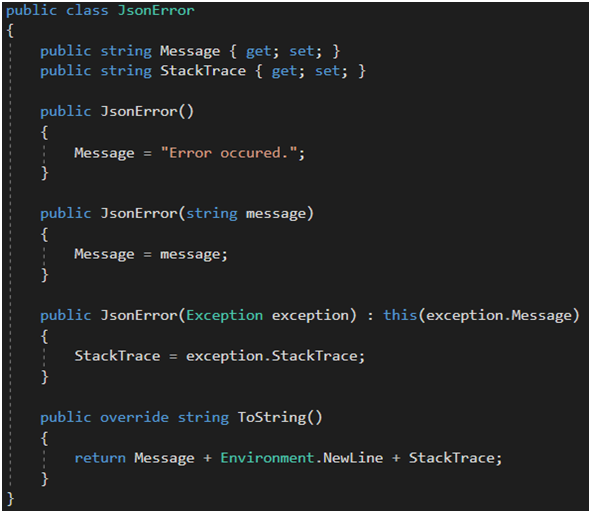
Rysunek 35. Implementacja IExceptionFilter c.d.
Gdy implementacja jest już gotowa, musimy zarejestrować filtr w pliku Global.asax.cs (Rysunek 36). Kolejność rejestracji ActionFilterów w przypadku interfejsu IExceptionFilter nie ma znaczenia – gdy tylko wystąpi wyjątek, framework będzie wiedział, który filtr uruchomić. Rysunki 37 i 38 przedstawiają zachowanie aplikacji w praktyce na środowisku deweloperskim.
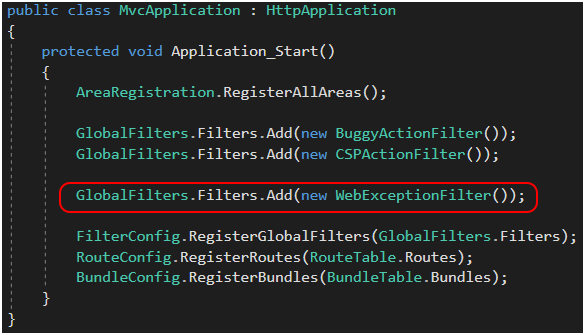
Rysunek 36. Rejestracja filtrów w pliku Global.asax.cs.
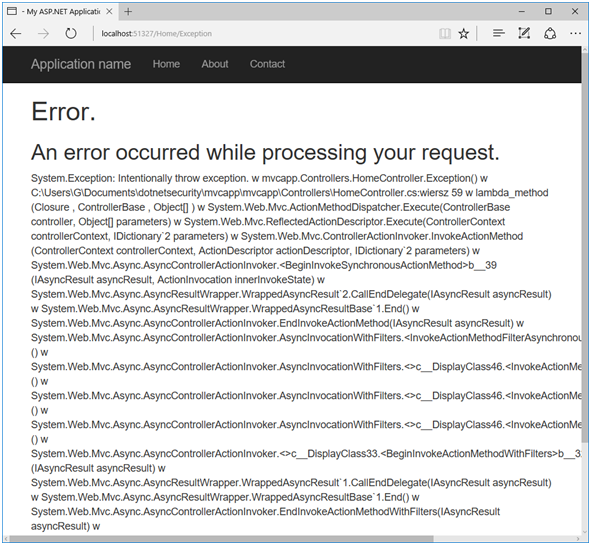
Rysunek 37. Przyjazna strona błędu z szczegółami dla QA.
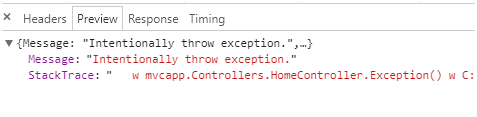
Rysunek 38. Serializowany błąd w konsoli Chrome z szczegółami dla QA.
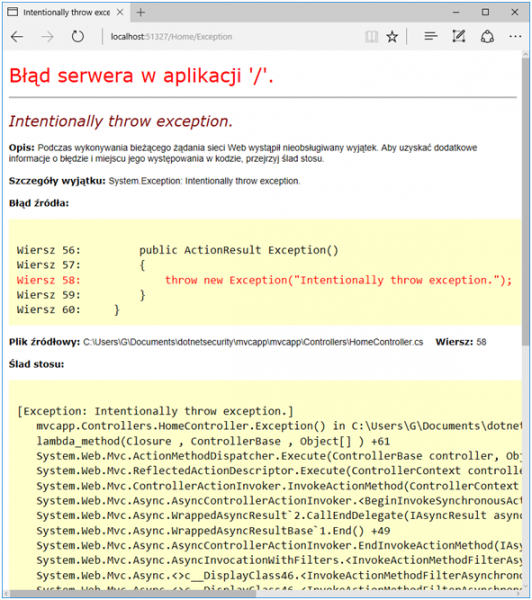
W zasadzie prawie wszystko jest już gotowe do tego, aby zacząć obsługiwać błędy które wystąpią w aplikacji. Pozostała jeszcze jedna rzecz: jeżeli użytkownik wpisze w url jakieś niedorzeczności, obecny mechanizm tego nie wyłapie. Pokazuje to Rysunek 39.
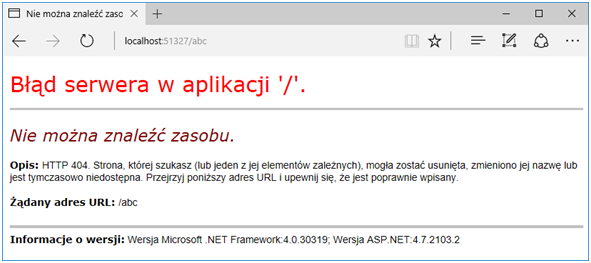
Rysunek 39. Domyślna strona błędu dla statusu 404 HTTP.
Problem możemy rozwiązać, dodając obsługę customowych błędów w pliku web.config (Rysunek 40). Nie będę już wchodził tutaj w szczegóły, gdyż wszystko zostało dobrze opisane w [48]. Mechanizm ten pozwala na dowolne reagowanie na konkretne statusy błędów HTTP (404, 403, 500, etc.) za pomocą elementów error. Dodatkowo możemy skonfigurować stronę (kontroler, akcję), która ma się wyświetlić użytkownikowi w przypadku wystąpienia błędu. Przykładowo, sam przekierowuję użytkownika na główną stronę aplikacji /Home (z czystego lenistwa). Rekomenduję także dodnie w tym miejscu kolejnych kontrolerów do obsługi błędów HTTP i rejestrowanie wszystkich zdarzeń.

Rysunek 40. customErrors w pliku web.config.
W przypadku Web API sytuacja jest, z jednej strony prostsza – tutaj zawsze i tylko – będziemy zwracać obiekt json, z drugiej – nieco trudniejsza – aby pokryć wszystkie przypadki, musimy zaimplementować własny ExceptionFilterAttribute [49] oraz ExceptionHandler [50]. Na Rysunku 41 zobaczymy, co się dzieje, gdy serwer zwróci wyjątek. Jak widać, został on zwrócony domyślnie w formacie XML (sic!).
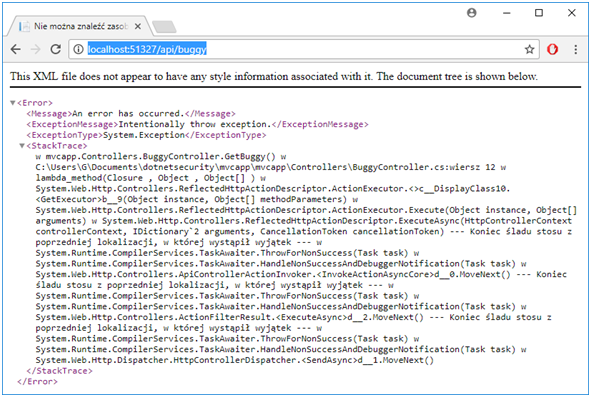
Rysunek 41. Domyślna obsługa błędu w Web API.
Gdy zmienimy konfigurację aplikacji, aby jednak zwracała json zamiast XML oraz dodamy – tak jak wcześniej- obsługę customErrors w web.config, dostaniemy w odpowiedzi spójną informację o błędzie (Rysunek 42). Nie pomoże to jednak w sytuacji chęci logowania wszystkich wyjątków, ani źle utworzonego urla (Rysunek 43).
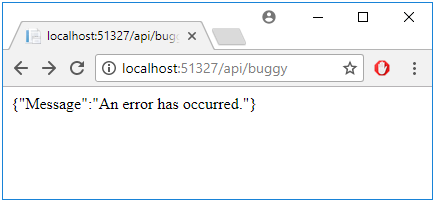
Rysunek 42. Obsługa błędu w Web API z włączonym customErrors.
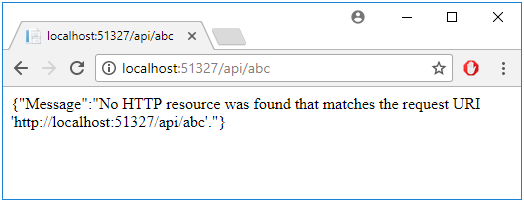
Rysunek 43. Obsługa nieznalezionej ścieżki w Web API z włączonym customErrors.
Przykładowa implementacja ExceptionFilterAttribute została pokazana na Rysunku 44. Skorzystałem tutaj z wcześniej zadeklarowanej klasy GeneralError, tak samo jak wcześniej stworzyłem też obiekt, który wypełniłem odpowiednimi danymi zależnie od tego, czy pracujemy na środowisku deweloperskim czy produkcyjnym. Następnie przygotowana została odpowiedź serwera z informacją o błędzie oraz sam błąd został zalogowany. To rozwiązanie jest poprawne i w pełni działa dla wszystkich błędów, które wystąpiły bezpośrednio w akcjach kontrolera. Niestety, nie sprawdza się, gdy czynnik, który powoduje błąd występuje poza kontekstem akcji, czyli przykładowo w konstruktorze kontrolera, w trakcie parsowania parametrów lub w trakcie serializacji podczas przygotowywania odpowiedzi serwera. Z pomocą przychodzi nam ExceptionHandler (Rysunek 45).
Rysunek 44. Przykładowa implementacja ExceptionFilterAttribute.
Technicznie, implementacja handlera wygląda mniej więcej identycznie jak w przypadku implementacji filtru. Pojawia się więc pytanie: po co inwestować w obydwa? I słusznie Odpowiedź brzmi: to zależy od sytuacji. Trzeba pamiętać, że obydwa mechanizmy nie zostały wdrożone jednocześnie. ExceptionHandler został wprowadzony, gdy zauważono, że filtry i MessageHandlery (o których była mowa przy logowaniu zdarzeń) nie są wystarczające, aby w pełni obsłużyć wszystkie statusy HTTP. Co za tym idzie ExceptionHandler może nie być dostępny w legacy kodzie. Poza tym, sama dokumentacja Microsoftu wspomina, że obydwa byty mają inny obszar wykorzystania oraz inne przeznaczenie. Najważniejsze by pamiętać, że takie mechanizmy istnieją i są pod ręką .Net developera. Na koniec dodam jeszcze, że oprócz interfejsu IExceptionHandler, zostały dodany jeszcze interfejs IExceptionLogger, który poprawnie obsłużony ma wspomóc logowanie błędów, warto się z tym zaznajomić tu [50].
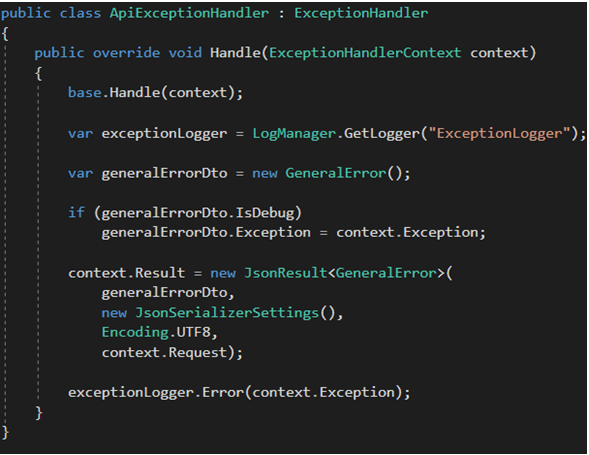
Rysunek 44. Przykładowa implementacja ExceptionHandler.
Wyżej wymienione implementacje należy oczywiście zarejestrować w Global.asax.cs (Rysunek 45).
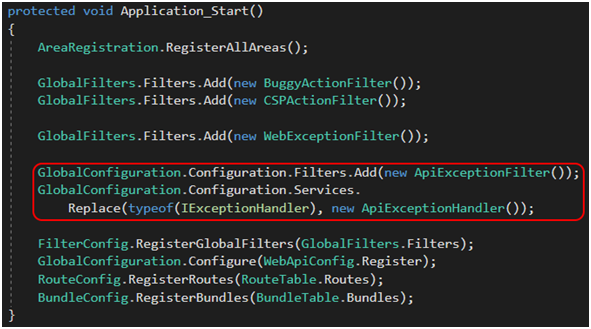
Rysunek 45. Rejestracja własnych ExceptionFilterAttribute i ExceptionHandler w pliku Global.asax.cs
A co z odgadywaniem, które ścieżki api są poprawne, a które nie? Okazuje się, że tak prosty przypadek nie ma prostego rozwiązania, które jest bezpośrednio zapewnione przez framework (a przynajmniej ja takiego nie znalazłem). Musiałbym też znów skopiować czyjś kod, dlatego podrzucę tylko odnośniki. Jedna z opisywanych tam propozycji zakłada obsługę dodatkowego routingu oraz wyłapywania, czy w trakcie próby wykonywania akcji został rzucony wyjątek z statusem 404 [51]. Inna opisuje implementację bazowego kontrolera dla wszystkich pozostałych w celu dodania akcji, która wyłapuje wszystkie możliwe i nieobsłużone routingi [52]. I na tym zakończmy.
Czy pamiętacie jeszcze moją anegdotę na temat developerów, którzy chaotycznie zaczynają dodawać logowania we wszystkie miejsca aplikacji? Zakładam, że równie łatwo wyobrazić sobie sytuację, gdy tuż przed releasem w popłochu zaczynają dodawać obsługę tokenów anty-CSRF, ponieważ jeden z testerów zespołu właśnie wrócił z szkolenia z bezpieczeństwa i chciał sprawdzić w praktyce nowo nabyte umiejętności. Mam nadzieję, że nie brzmi to znajomo.
Jeśli chodzi o obsługę anty-CSRF, wszystko, co jest potrzebne, znajduje się na wyciągnięcie ręki we frameworku [53] oraz, technicznie rzecz biorąc, zależy od dwóch linijek kodu. Wystarczy skorzystać z HtmlHelpera i do formularza dodać linijkę @Html.AntiForgeryToken() (Rysunek 46). Wyrenderuje to ukryte pole z wartością tokenu. Po stronie serwera akcja, która obsługuje metodę POST, musi być opisana atrybutem ValidateAntiForgeryToken. I to wszystko.
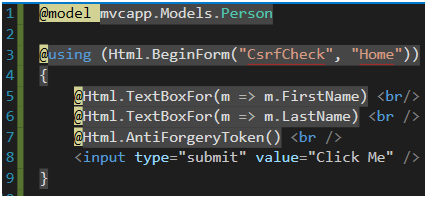
Rysunek 46. Dodanie tokenu anty-CSRF do formularza.
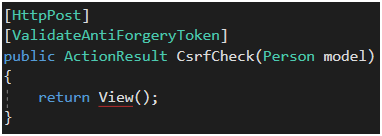
Rysunek 47. Weryfikacja tokenu anty-CSRF za pomocą atrybutu ValidateAntiForgeryToken.
W przypadku modyfikacji tokenu lub jego braku, framework wyrzuci wyjątek bezpieczeństwa HttpAntiForgeryException, który można zobaczyć na naszej stronie błędu (Rysunek 48). Oczywiście możliwe jest to tylko na środowisku deweloperskim.
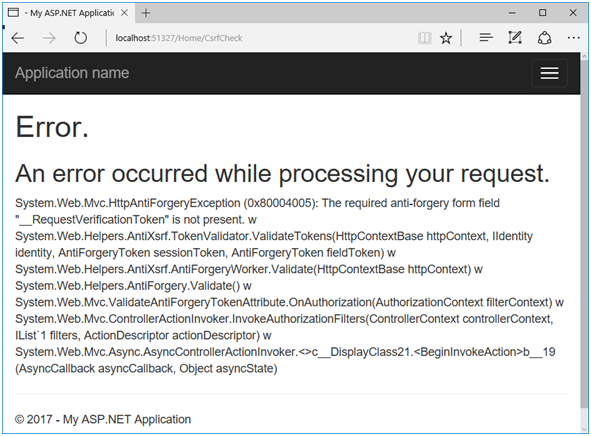
Rysunek 48. Błąd aplikacji wywołany brakiem tokenu anty-CSRF.
Warto przyjrzeć się temu, jak to wygląda w praktyce. .Net framework zapewnia dodanie tokenu nie tylko do formularza (Rysunek 49), ale także do ciasteczka (Rysunek 50). Są to oczywiście dwie różne wartości. Takie podejście znacząco zmniejsza szanse na to, że token zostanie wykradziony i użyty przeciwko użytkownikowi. Serwer obowiązkowo weryfikuje obydwa naraz, a w przypadku braku jednego z nich lub braku poprawnej weryfikacji rzuca wyjątek. Atakujący musiałby się całkiem sporo powyginać, żeby jednocześnie wykraść oba tokeny.
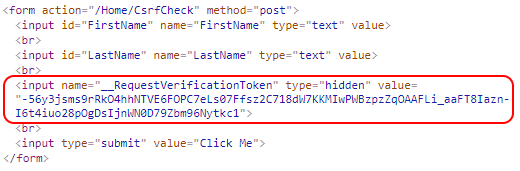
Rysunek 49. Anty-CSRF token w formularzu.
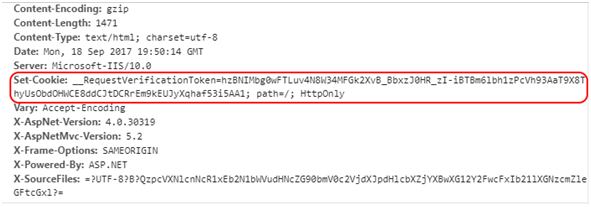
Rysunek 50. Anty-CSRF token w ciasteczku.
W wcześniej wspomnianym odnośniku [53] znajduje się też przykład implementacji dla calli AJAX-owych, stąd nie będę zamieszczał tu przykładu.
Może się zdarzyć, że zamiast tradycyjnej aplikacji budujemy tzw. Single Page Application, które wspieramy od strony backendu za pomocą Web API. W teorii Web API powinno być bezstanowe, ale w praktyce jest to narzędzie, które możemy wykorzystać w dowolnym celu. Nie widzę więc problemu, żeby na wszystkich GET-ach dodawać token, a na POST-ach, PUT-ach i DELETE-ach go zweryfikować. Tylko jak miałoby to wyglądać, kiedy api nie zwraca stron z formularzem tylko obiekty json?
Weźmy na przykład jeden z najpopularniejszych frameworków typu SPA – Angular. Jeżeli ktoś korzysta z Angulara, zapewne korzysta z modułu $http, a ten natywnie wspiera ochronę przed CSRF [54].
Na Rysunku 51 widzimy przykładową implementację metody OnActionExecuted, w której korzystamy ze statycznej metody GetTokens klasy AntiForgery udostępnionej bezpośrednio przez framework. Metoda ta przygotuje nam identyczne tokeny, jakie są ustawiane dla formularzy w MVC. Następnie tworzymy dwa ciasteczka (oczywiście zgodnie z RFC 2109 [55]), które dodamy do response’a. Jedno z nich będzie wykorzystane przez moduł $http w celu umieszczenia wartości w headerze HTTP, stąd nie może mieć flagi httpOnly. Drugie będzie użyte do walidacji, tak samo jak ma to miejsce przy tokenach w formularzach MVC.
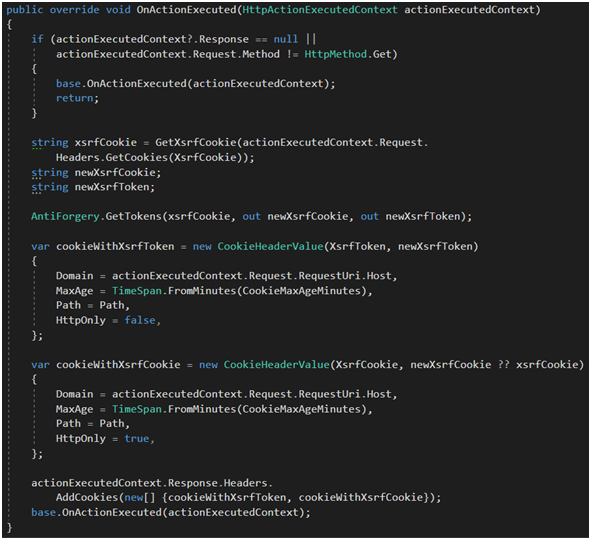
Rysunek 51. Przygotowanie tokenów anty-CSRF dla requęstów typu GET w ActionFilter dla Web API.
Na Rysunku 52 widzimy przykładową implementację metody OnActionExecuting. Jest ona istotna, gdyż nie chcemy, by request był dalej procesowany, jeśli nie przejdzie walidacji tokenów. Dla metody HTTP GET weryfikacje pomijamy. Ostatecznie, gdy weryfikacja się nie powiedzie, musimy przygotować odpowiedź serwera z błędem.
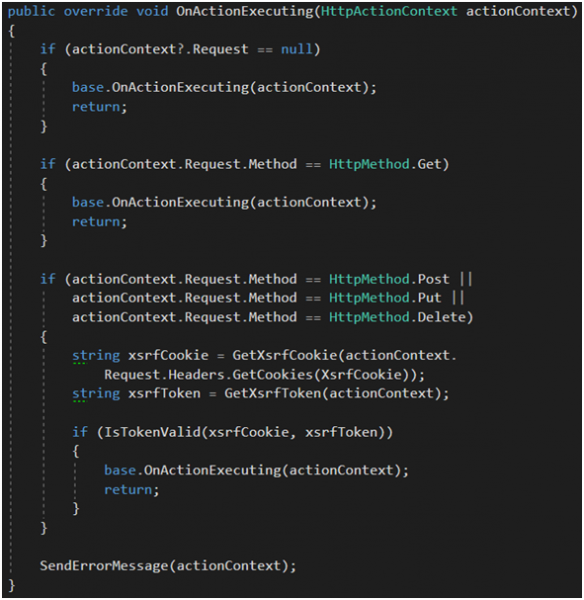
Rysunek 52. Weryfikacja tokenów anty-CSRF dla requestów typu POST, PUT i DELETE w ActionFilter dla Web API.
Klasa AntiForgery nie tylko wygeneruje nam tokeny, ale także je zweryfikuje (Rysunek 53). W przypadku niepowodzenia framework rzuci wyjątkiem HttpAntiForgeryException. W takim przypadku błąd oczywiście logujemy. Tutaj założyłem, że użytkownik jest zalogowany i logujemy także nazwę użytkownika, który został zaatakowany. Jak widać wszystko, co jest potrzebne do obsługi CSRF znajduje się za darmo we frameworku.
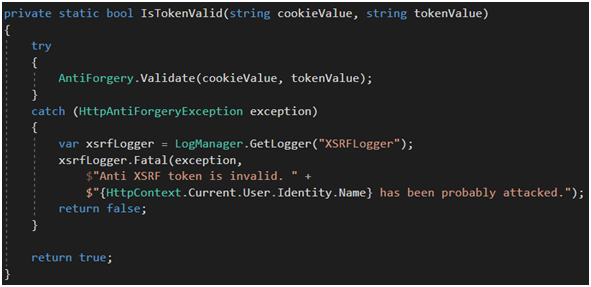
Rysunek 53. Ręczna weryfikacja tokenów anty-CSRF za pomocą metod dostępnych w frameworku.
Na zakończenie trzeba przygotować odpowiedź serwera (Rysunek 54). Na środowisku deweloperskim informujemy testera (że trochę przesadził z testami i manipulacją requestu) o niepoprawnym tokenie. Na innych środowiskach oraz tym produkcyjnym nie dajemy potencjalnemu atakującemu żadnej istotnej informacji, oprócz takiej, że wystąpił błąd. I kropka.
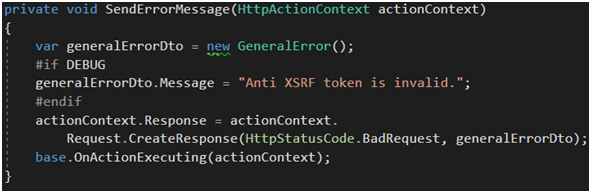
Rysunek 54. Przygotowanie odpowiedzi serwera z informacją o błędzie.
XSS to w zasadzie temat rzeka, ale jak w każdym szanującym się tekście, muszę napisać, że jeśli chcemy się przed tym zagrożeniem zabezpieczyć, to na wejściu wszystkie dane użytkownika musimy filtrować, a na wyjściu musimy je escape-ować. Ot cała filozofia, więc co może pójść nie tak?
Można by powiedzieć, że .Net domyślnie jest świetnie przygotowany na ataki typu XSS, a za jego osłabienie winę ponosi zazwyczaj mniej lub bardziej świadomy developer. Nie pokażę tutaj remedium na tą przypadłość, ale postaram się opisać najważniejsze elementy frameworka, które bywają często przez developerów pomijane, wyłączane lub używane niepoprawnie, co skutkuje wystąpieniem błędu w aplikacji.
Przede wszystkim .Net posiada własny filtr anty-XSS [56] zwany Request Validation. Nie jest raczej zaskakujące, że jeśli coś jest za darmo i jest zrobione przez Microsoft, to musiało zostać poddane ogniu krytyki ze strony społecznosci. Ujawniono wówczas mniejsze oraz większe błędy [57], [58], [59], [60] lub [61], związane głównie z kodowaniem UTF lub starymi wersjami IE. Pomimo tego jest to wciąż pierwsza linia obrony zapewniona przez framework, więc jedynie od developera będzie zależeć, czy tą obronę wykorzysta i wzmocni czy osłabi.
Filtr ten jest domyślnie włączony. Aby sprawdzić jego działanie wystarczy przygotować dowolny model (Rysunek 55), akcję która z niego korzysta (Rysunek 56) oraz widok, który go wyrenderuje (Rysunek 57). W tym przypadku właściwości modelu są przekazywane jako parametry query stringa. Czyli są idealnym miejscem do wklejenia XSS-a.
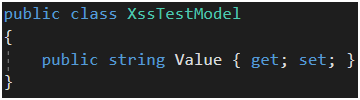
Rysunek 55. Przykładowy model.
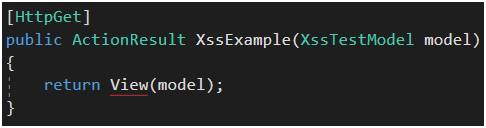
Rysunek 56. Przykładowa akcja w kontrolerze.
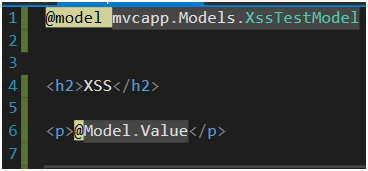
Rysunek 57. Przykładowy widok
Jeśli w przeglądarce spróbujemy wstrzyknąć dowolny javascript, na środowisku deweloperskim zobaczymy błąd HttpRequestValidationException z informacją o wykryciu potencjalnie niebezpiecznej wartości (Rysunek 58). Framework chroni więc niejako developera oraz użytkownika aplikacji przed potencjalną wpadką. Microsoft nie bawi się w żadne filtrowanie treści. Jeśli coś jest nie tak, kończymy przetwarzać request i zwracamy informację o błędzie. To, de facto najlepsze rozwiązanie w tej sytuacji.
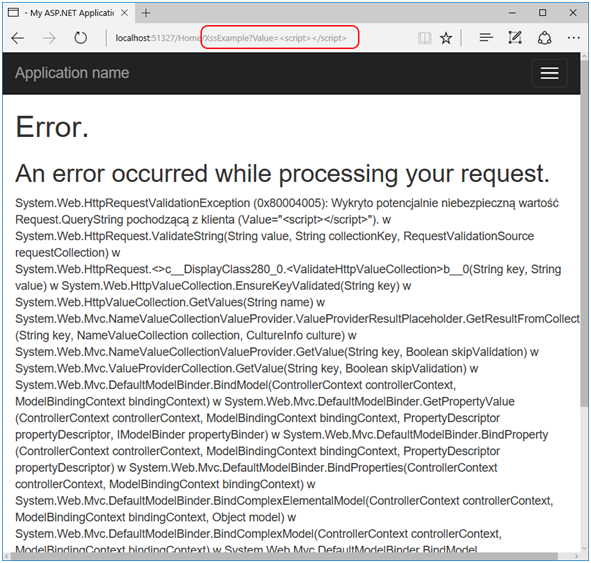
Rysunek 58. Przykład wyjątku HttpRequestValidationException.
Request Validation jest sterowane za pomocą pliku web.config (Rysunek 59). Na dzień dzisiejszy przyjmuje on trzy wartości: 4.5, 4.0 oraz 2.0 [62], z czego co przy braku wpisu requestValidationMode w httpRuntime domyślnie przyjmuje wartość 4.5. Szczerze mówiąc, dokumentacja Microsoftu jest bardzo mglista i nie do końca precyzuje, jak działają poszczególne wartości tego parametru. Spróbuje to jednak przytoczyć. Dla lepszego zrozumienia tematu polecam też przypomnienie sobie cyklu życia aplikacji MVC [39] .
Między dwiema pierwszymi wartościami parametru (4.0 oraz 4.5) w zasadzie nie ma większej różnicy – walidacja jest wykonywana dla wszystkich zasobów serwera, które są requestowane za pomocą protokołu HTTP [56], [62] i to zanim dojdzie do fazy BeginRequest w cyklu życiu aplikacji [63]. Czyli pokrywa też między innymi Handlery oraz Moduły.
Dla wartości 2.0 mechanizm różni się tym, że jest wykonywany tylko dla Page’y (Asp.Net Web Pages, pliki .aspx), a nie dla wszystkich requestów HTTP, oraz że moment walidacji jest przesunięty w cyklu do fazy BeginRequest.
Jeżeli dobrze rozumieć dokumentację, wartości 4.5, 4.0 i 2.0 nie mają większego wpływu na technologię MVC. Poza tym, moje doświadczenia potwierdzają, że niezależnie od wartości parametru requestValidationMode zawsze dostawałem exception HttpRequestValidationException przy próbie użycia modelu z niebezpiecznymi wartościami. Nie zmienia to faktu, że zawsze i wszędzie rekomenduję używanie domyślnie najwyższej wartości 4.5, jeśli tylko nie ma potrzeby jej obniżać do 2.0.
Zanim obniżymy wartość do 2.0, zastanówmy się dobrze, czy chcemy to zrobić. Przeprowadźmy sobie szybki eksperyment myślowy dotyczący wyimaginowanego threat modelingu. Bardzo łatwo wyobrazić sobie przykład aplikacji, w której znajduje się implementacja IHttpHandler czy IHttpModule, która za zadanie ma logować wszystkie requesty i responsy aplikacji. Dalej, takie logi zapisane np. w pliku, mają później być wyświetlane w innej aplikacji webowej dla pracujących po nocach członków supportu. Prawo Murphego jest bezlitosne, więc oczywistym jest, że programiści aplikacji do wyświetlania logów zapomnieli o implementacji poprawnego escapowania danych, co potencjalnie prowadzić może do XSS-a. Być może taki przykład jest trochę zbyt nieprawdopodobny, ale w świecie IT Security nie można być zbytnio optymistycznym. Stąd rozważyć należy wszystkie scenariusze.
Na zakończenie istotna uwaga – requestValidationMode nie ma wpływu na technologię Web API!
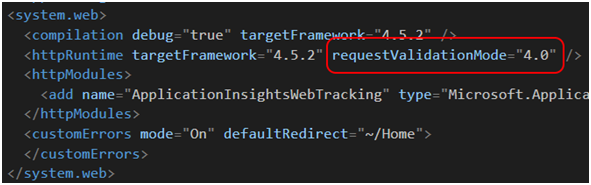
Rysunek 59. RequestValidationMode konfigurowane w pliku web.config.
Wracając do tematu MVC… Domyślny filtr .Netowy można wyłączyć. W praktyce spotkałem się z tym, że był on wyłączany nieświadomie lub niepotrzebnie. Dlatego też treści poniżej mają charakter raczej ostrzeżenia niż rekomendacji.
W pierwszej kolejności możemy wyłączyć mechanizm walidacji dla całej akcji lub kontrolera za pomocą atrybutu ValidateInput z wartością false (Rysunek 60). Dzieje się tak niezależnie od wartości parametru requestValidationMode.

Rysunek 60. ValidateInput wyłącza filtr XSS dla akcji.
Kolejny sposób na wyłączenie mechanizmu walidacji, tym razem tylko dla konkretnej właściwości modelu, to atrybut AllowHtml (Rysunek 61). W jakich sytuacjach moglibyśmy chcieć korzystać z tego atrybutu? Cóż, jest kilka przypadków biznesowych. Po pierwsze, wszędzie tam, gdzie chcielibyśmy pozwolić użytkownikowi na zapisywanie własnego kodu html lub javascript, np. w aplikacji typu CMS. Po drugie, w sytuacji gdy chcemy umożliwić użytkownikowi przekazywanie jakiegoś xmla, np. serializowany skomplikowany obiekt, który po stronie serwera deserializujemy i dalej procesujemy. W obu przykładach pojawia się problem pewnego zaufania do użytkownika. Nigdy nie możemy być pewni, że ktoś nieumyślnie nie wklei w takie miejsca XSS-a (lub nie zostanie zwyczajnie zhackowany i ktoś przejmie mu konto). W przypadku deserializacji obiektu z xmla, nie możemy mieć pewności, że wartości właściwości powstałego obiektu nie zawierają potencjalnie niebezpiecznego kodu.
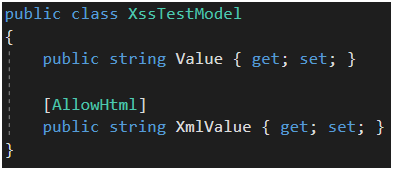
Rysunek 61. AllowHtml wyłącza filtr XSS dla właściwości.
Osobiście nie zalecam używać tych dwóch metod i zalecam, by za wszelką cenę rozważyć inne rozwiązanie. A gdy nie ma już innej opcji, to najważniejsze jest być świadomym użytkownikiem tych mechanizmów.
W temacie XSS-a bardzo często zwracam uwagę na kwestię świadomości korzystania z mechanizmów bezpieczeństwa, i mam ku temu uzasadnienie. Jako argumenty podam kilka bohaterskich wpisów znalezionych na StackOverflow. W [64] użytkownik IT Captain miał problem z przekazaniem wartości typu xml do web service’u. W zaproponowanym rozwiązaniu (Rysunek 62) inny użytkownik zasugerował obniżenie wartości requestValiationMode do 2.0. Odpowiedź ma zielonego ptaszka, krótką notkę o osłabieniu security oraz najszczersze podziękowania użytkownika IT Captain.
Nie miałbym nic do tego, gdyby nie to, że inni użytkownicy będą wzorować się na tej odpowiedzi. Włączając w to nowo nabytych członków mojego/twojego zespołu deweloperskiego z rangą Junior Software Developer. W tej odpowiedzi definitywnie zabrakło szerszego wyjaśnienia konsekwencji zmiany tej wartości, a także informacji na temat tego, co w zasadzie było przyczyną wspomnianego issue. A pamiętajmy, że XSS w aplikacji to z reguły ciąg niefortunnych i połączonych ze sobą zdarzeń, w którym pierwszym krokiem może być wprowadzenie wstrzyknięcia do wartości pola z xmla.
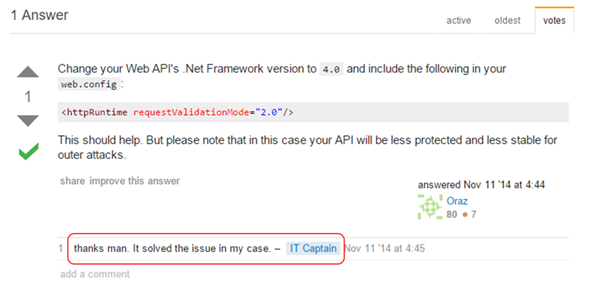
Rysunek 62. Najlepsza odpowiedź StackOverflow to obniżenie requestValidationMode do 2.0.
Inny przykład [65], który rzucił mi się w oczy, jest przedstawiony na Rysunku 63. O dziwo pojawiło się przy tej okazji słowo sanitization, a w zasadzie “my own sanitization”. Nie żebym wątpił w czyjeś umiejętności, ale pisanie własnego filtra na XSS-y, to jak pisanie własnej implementacji algorytmu kryptograficznego AES. Takich rzeczy lepiej po prostu nie robić. Poza tym, jeśli ktoś zadaje takie pytanie, to znaczy, że nie zrobił odpowiedniego researchu wcześniej, nie zapoznał się z dokumentacją techniczną i chce tylko jak najszybciej rozwiązać swoje issue. Nie spodziewałbym się po takiej osobie jakiejś niesamowitej implementacji metody sanityzacji danych.
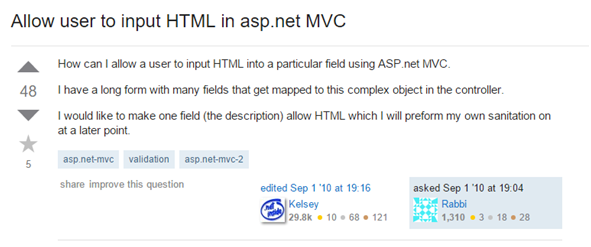
Rysunek 63. Pytanie na StackOverflow jak pozwolić użytkownikowi na wprowadzenie HTML.
Idąc dalej, na Rysunku 64 możemy zobaczyć najlepszą odpowiedź w tym wątku, w której inny użytkownik zaproponował całkowite rozbrojenie i demilitaryzację frameworka .Net. Może nieco się czepiam, ale to właśnie odpowiedzi z zielonymi ptaszkami są z reguły traktowane jako ostateczna wyrocznia, z której korzysta, często bezrefleksyjnie, wielu developerów.
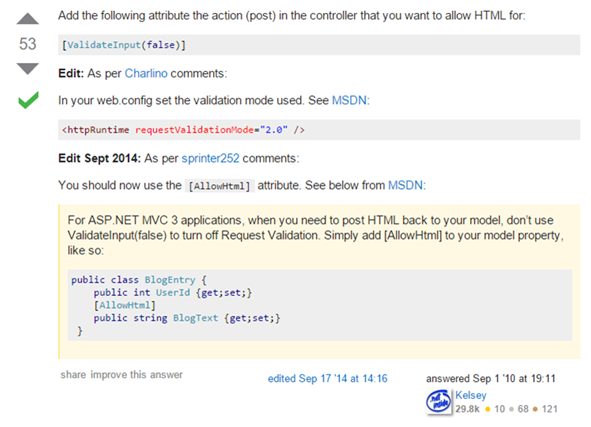
Rysunek 64. Najlepsza odpowiedź StackOverflow to wyłączenie walidacji XSS.
Na całe szczęście okazuje się, że skorzystanie z atrybutu AllowHtml nie powoduje od razu całkowitego dramatu. Pokazuje to Rysunek 65 – wszystkie dane użyte w pliku .cshtml są domyślnie escapowane, dlatego też kod javascript się nie wykona. Ale nie martwmy się! I ten domyślny mechanizm bezpieczeństwa da się ominąć!
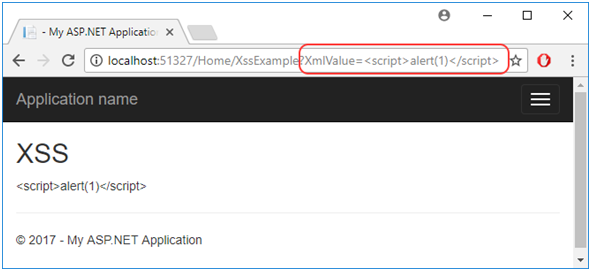
Rysunek 65. Wyrenderowanie właściwości z atrybutem AllowHtml w pliku .cshtml.
Wystarczy skorzystać z funkcji helpera Html.Raw() (Rysunek 66), który spowoduje, że dana wartość zostanie wyrenderowna bez escapowania, a przeglądarka wykona każdy kawałek html lub javascript, który znajdzie się w tym miejscu.
Dodam, że w tym miejscu filtr XSS przeglądarki niewiele pomoże. W zasadzie tylko Chrome zaprotestował i zablokował renderowanie strony dla podstawowego alert(1);. Edge wyświetlił alert, a Firefox… Firefox i tak nie ma własnego filtru… Poza tym filtry XSS można wyłączyć za pomocą X-XSS-Protection: 0;. Spotkałem się takim pomysłem przy pewnym projekcie, w którym podjęto próbę wdrożenia CORS, niestety niepoprawnie rozumianego przez developerów, w którym format, ilość oraz typ danych był nieadekwatny do wymiany międzydomenowej.
Podsumowując, [AllowHtml] oraz @Html.Raw() to bardzo niebezpieczna oraz nie zalecana kombinacja.
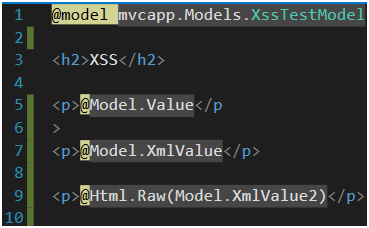
Rysunek 66. Przykład użycia funkcji Html.Raw().
Jeśli kogoś spotkała w projekcie konieczność wykonania ręcznej sanityzacji danych od użytkownika to mogę zaproponować bibliotekę AntiXss (dostępna w frameworku od wersji 4.5 lub jako nuget [66]), która została przygotowana przez Microsoft.) Ma ona rekomendacje twórców, a także organizacji OWASP [67]. Jedyny problem jest taki, że to encoder i nie wykonuje żadnej sanityzacji.
Drugą biblioteką, którą można się zainteresować, to HtmlSanitizer [68]. Zapoznawszy się z repozytorium kodu na githubie, stwierdzam, że jest całkiem nieźle zarządzana. Chwali się możliwością wycinania niebezpiecznych fragmentów htmla na zasadzie konfigurowanej whitelisty. Wygląda nieźle, aczkolwiek poprawna konfiguracja może trochę zająć. Zresztą i tak nie miałbym pewności, czy wszystko, co niedobre, zostałoby wycięte.
Temat XSS w technologii .Net to raczej nie jest kwestia dotycząca tylko pierwszych sprintów projektu, podczas których możemy ułożyć kilka reguł i trzymać się ich dozgonnie. Tutaj znaczenia nabiera doświadczenie i wieloletnia praktyka oraz wiedza, z jakich mechanizmów możemy skorzystać i na co sobie pozwolić zależnie od kontekstu sytuacji. Do tego dochodzi wątek niezależny od technologii, czyli jQuery i HTML5, które są przestrzenią wspólną dla wszystkich obecnie używanych frameworków. Żaden domyślny mechanizm bezpieczeństwa nie uchroni, jeśli developer będzie namiętnie wrzucał wszystkie dane do potencjalnie niebezpiecznej funkcji .html() [69] lub jej podobnych. Choć temat kontekstów client side wychodzi poza ramy tego tekstu, muszę tu wspomnieć o szkoleniu Michała Bentkowskiego, w którym uczestniczyłem i które serdecznie polecam wszystkim tym, którzy jeszcze nie czują się zbyt dobrze z XSS-em i kontekstami kodu.
Na zakończenie dodajmy trochę kodu, który będzie nam wstrzykiwał nagłówki HTTP odpowiedzialne za zwiększenie bezpieczeństwa aplikacji po stronie przeglądarki. Domyślnie framework nie dodaje za wiele od siebie w tym temacie (Rysunek 67), a nawet dorzuca parę zbędnych rzeczy. Wspominał już o tym Troy Hunt w swoim artykule Shhh… don’t let your response headers talk too loudly [70].
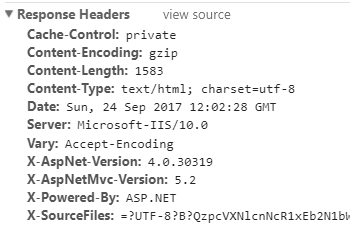
Rysunek 67. Domyślne nagłówki HTTP serwera.
Nagłówek X-AspNet-Version wyłączymy, dodając enableVersionHeader=”false” do elementu httpRuntime w pliku web.config (Rysunek 68).
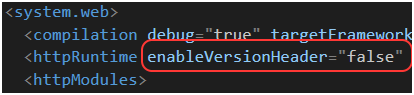
Rysunek 68. Wyłączenie dodawania nagłówka X-AspNet-Version.
Nagłówek X-AspNetMvc-Version wyłączymy, ustawiając MvcHandler.DisableMvcResponseHeader na true w pliku Global.asax.cs (Rysunek 69).
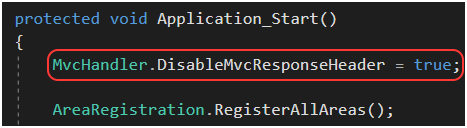
Rysunek 69. Wyłączenie dodawania nagłówka X-AspNetMvc-Version.
Nagłówek X-Powered-By wyłączymy, konfigurując customHeaders [71] w pliku web.config (Rysunek 70). Pamiętajmy by httpProtocol dodać w elemencie system.webServer. (Co ciekawe, tym sposobem nie usuniemy nagłówka Server).
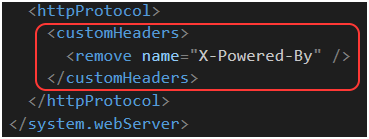
Rysunek 70. Wyłączenie dodawania nagłówka X-Powered-By.
Ostatni header usuniemy za pomocą metody Application_PreSendRequestHeaders() w pliku Global.asax.cs (Rysunek 71). Trochę zabawne, że do usunięcia każdego z nagłówków musimy użyć innej metody, czyż nie? Aczkolwiek, prawdopodobnie ostatni sposób pozwoliłby usunąć wszystkie nagłówki w jednym miejscu. Jak widać nie potrzebujemy edytować nic w konfiguracji IIS lub Windows Servera (a takie propozycje można znaleźć w Internecie [72]). Wszystko możemy skonfigurować bezpośrednio w aplikacji.
Nagłówek X-SourceFiles jest dodawany tylko na localhoscie, a więc nie ma co się nim przejmować.
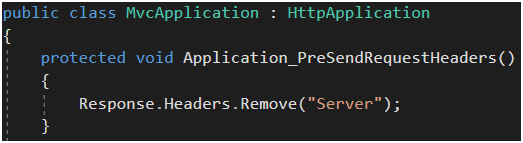
Rysunek 71. Wyłączenie dodawania nagłówka Server.
Posprzątaliśmy. Teraz chcielibyśmy dodać kilka nagłówków. Mamy na to co najmniej kilka sposobów, a ich wybór zależy od tego, co chcemy osiągnąć. Własne nagłówki możemy dodać w tym samym miejscu, w którym usunęliśmy nagłówek Server (Rysunek 72). W pliku web.config obok usuniętego X-Powered-By (Rysunek 73). Ten sposób pozwala nam edytować listę nagłówków na produkcji bez konieczności rekompilacji aplikacji. Możemy zaimplementować własny IHttpHandler lub IHttpModule, aczkolwiek byłaby to armata nieadekwatna dla osiągniętego celu. Ostatecznie możemy stworzyć własny ActionFilterAttribute (Rysunek 74) i to jest podejście, które będę dalej promował. Filtry są na tyle elastyczne, że możemy je, zależnie od potrzeb, zarejestrować globalnie lub udekorować nimi pojedynczy kontroler czy pojedynczą akcję,
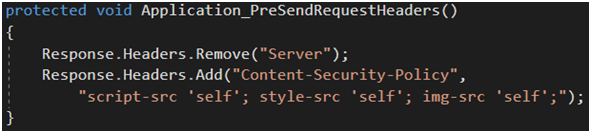
Rysunek 72. Dodanie własnego nagłówka w pliku Global.asax.cs.
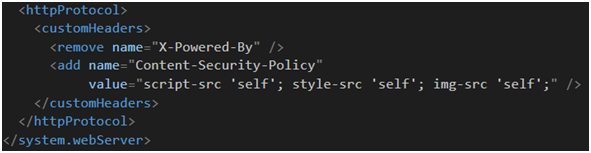
Rysunek 73. Dodanie własnego nagłówka w pliku web.config.
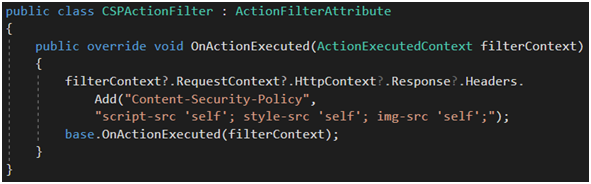
Rysunek 74. Dodanie własnego nagłówka za pomocą ActionFilterAttribute.
Rysunek 74 przedstawia dodanie nagłówka CSP [44], o którym wspominałem przy okazji minifikacji. Jeśli myślimy poważnie o wdrożeniu tego mechanizmu, najlepiej jest to zrobić na samym początku, aby uzależnić developerów w zespole od jego używania, a co za tym idzie – zakazać inline’owana jakichkolwiek skryptów. Odwrócenie kolejności implementacji funkcjonalności mogłoby skutkować tym, że na koniec projekt mógłby być niepoprawnie napisany w tak zaawansowanym stopniu, że CSP moglibyśmy wdrożyć ewentualnie tylko w trybie raportowania.
Na Rysunku 75 pokazałem zbiorczy ActionFilter zarejestrowany globalnie, który dodaje wszystkie najistotniejsze nagłówki bezpieczeństwa HTTP [73], [74]. (Zrobiłem to z czystego lenistwa, w realnym przypadku stworzyłbym raczej jeden filtr per jeden header). Pominąłem tylko header HPKP [75] ze względu na jego małą popularność. Jak widać, wszystkie flagi nagłówków są ustawione jako maksymalnie restrykcyjne. I dobrze jest zacząć projekt z takimi restrykcjami, a wraz z rozwojem funkcjonalności (i change requestami klienta), dostosować je do potrzeb lub poluźnić niektóre flagi na poszczególnych akcjach. Należy przy tym kierować się zasadą: od ogółu do szczegółu. Czyli ogólnie jesteśmy uzbrojeni po zęby, ale jeśli jakaś konkretna funkcjonalność tego wymaga, zamiast wyłączać mechanizm całkowicie, wyłączmy go tylko dla danej akcji kontrolera.
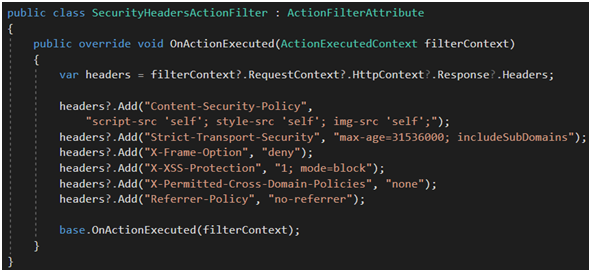
Rysunek 74. Dodanie własnego nagłówka za pomocą ActionFilterAttribute.
Rysunek 75 przedstawia nagłówki serwera już po usunięciu tych niepotrzebnych i dodaniu tych niezbędnych. Wydaje mi się. że teraz wygląda to dużo lepiej.
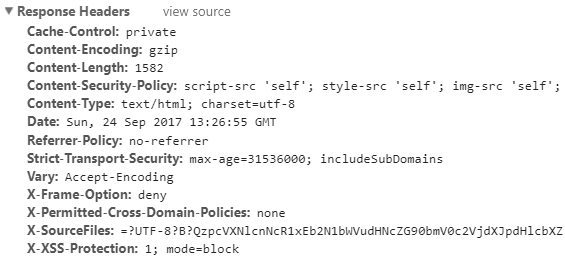
Rysunek 75. Zmodyfikowane nagłówki HTTP serwera z zabezpieczającymi wartościami.
Ostatnia rzecz związana z nagłówkami serwera to oczywiście implementacja bezpiecznego ciasteczka (RFC 2109 [55]). Zrobimy to za pomocą elementu httpCookies [76] w pliku web.config (Rysunek 76). Atrybut requireSSL dodaje flagę secure. Warto dodać tu transformację, przecież na środowisku deweloperskim, a niekiedy i stage’owym, rzadko używa się HTTPS (i zakładam, że te środowiską są dostępne tylko w intranecie).
Flaga httpOnly jest dodawana zawsze by design i nie jest łatwo tą flagę usunąć (jeśli ktokolwiek w ogóle miałby taką potrzebę). Potwierdza to wpis na forum [77] Marka Berrymana w odpowiedzi na pytanie o to, w jaki sposób tę flagę wyłączyć: “A security conscious decision was made regarding setting HttpOnly to “true” for all forms auth cookies issued under ASP.NET 2.0”. Niezależnie od tego, co jest napisane w dokumentacji, flagi tej nie da się usunąć za pomocą wpisów w pliku web.config.
Parametr domain w elemencie HttpCookie pozwala nam zdefiniować zakres domen, dla jakich ciasteczko jest ważne. Jest to istotne, gdybyśmy chcieli wziąć pod uwagę subdomeny.
Ostatni parametr to czas ważności ciasteczka. Dla customowego ciasteczka ustawimy to przy jego tworzeniu za pomocą właściwości Expires [78]. Dla ciasteczka sesyjnego utworzonego przez Forms Authentication ustawimy go za pomocą atrybutu timeout w elemencie forms [79]. Niezależnie od tego, z jakim frameworkiem pracujemy, zawsze pamiętajmy o jednostce czasu w jakiej zmienna pracuje. W tych dwóch przypadkach będą to minuty.
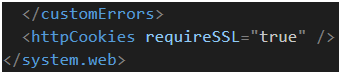
Rysunek 76. Globalna konfiguracja flagi secure dla ciasteczek używanych w aplikacji.
Myślę, że implementacja nagłówków HTTP w .Net została pokryta wystarczająco. Można tu zarzucić, że nie poświęciłem nic nagłówkom związanym z CORS [80], ale wtedy czułbym się zobowiązany napisać także o Window.postMessage() [81], a obydwa te zagadnienia wychodzą moim zdaniem poza zakres tematu standardowych nagłówków bezpieczeństwa.
Z punktu widzenia developmentu najważniejsze jest to, aby w ogóle wiedzieć, że takie nagłówki istnieją i można z nich za darmo skorzystać.
Mówi się że .Net framework jest domyślnie bardzo dobrze zabezpieczony. I podatności, takie jak Path Traversal [82] w nim nie występują. Widziałem takie rozwiązanie napisane w .Net, które ścieżkę do pliku ze zdjęciem zalogowanego użytkownika przechowywało w ciasteczku i przekazywało między stronami, imitując sesję. Parametr ten był pod pełną kontrolą atakującego, co dało mu potencjalnie możliwość przejrzeć wszystkie pliki serwera, jeśli tylko zgadłby poprawną ścieżkę. Gratisowo mógł wykonać DoSa, próbując odpytywać dowolne ścieżki sieciowe (a te mają domyślnie bardzo długi timeout).
… mówi się że .Net framework jest domyślnie bardzo dobrze zabezpieczony. I jest to prawda, o ile wie się, jak z niego skorzystać i jak go nie odbezpieczyć. Przeszedłem w tym tekście przez wszystkie najistotniejsze i najbardziej podstawowe mechanizmy bezpieczeństwa, jakie powinny znajdować się w nowo tworzonym projekcie w technologii MVC czy Web API. A i tak mam wrażenie, że liznąłem tylko wierzchołek góry lodowej. W końcu nie dotknąłem nawet tematu autentykacji i autoryzacji czy sql injection.
Skala przedstawionych zagadnień pokazuje, jak bardzo skomplikowanym procesem jest utrzymanie wystarczająco dobrego poziomu bezpieczeństwa w aplikacji. Starałem się zaznaczyć, jak bardzo dużo rzeczy trzeba wiedzieć i o nich pamiętać; a jeszcze więcej czasu trzeba poświęcić na to, by pamiętali o tym inni członkowie zespołu. Co w obecnym dynamicznym środowisku scrumowych zespołów jest niemałym wyzwaniem. Do tego nie można zapomnieć o poprawnej implementacji architektury aplikacji, wzorcach projektowych, optymalizacji, performansie, UI, dostępie do bazy danych, wsparciu CSS-ów dla wszystkich przeglądarek (tak, mam na myśli też Was Opero i IE), workaroundach dla wszystkich dziwnie zachowujących się implementacji frameworka czy zewnętrznych bibliotek… I nagle okazuje się, że temat security w perspektywie całej aplikacji jest marginalnym problemem i jak wiele innych czynników wpływa na obecny stan rzeczy i liczbę błędów bezpieczeństwa znajdowanych w aplikacjach przez pentesterów oraz mniej etyczne towarzystwo.
Mam nadzieje, że tekst czytało się przyjemnie i posłuży on komuś w realizacji swoich celów. Dzięki za poświęcony czas.
[1] https://niebezpiecznik.pl/post/asp-net-wszystkie-webaplikacje-podatne-na-atak/
[2] https://niebezpiecznik.pl/post/jak-zabezpieczyc-swoja-webaplikacje-w-asp-net/
[3] https://niebezpiecznik.pl/post/1-000-000-stron-w-asp-net-zhackowanych/
[4] https://sekurak.pl/zabezpieczanie-aplikacji-w-asp-net-z-poziomu-konfiguracji/
[5] http://eu.wiley.com/WileyCDA/WileyTitle/productCd-1118026470.html
[6] https://portswigger.net/burp
[7] https://msdn.microsoft.com/en-us/library/ff649432.aspx
[8] https://docs.microsoft.com/en-us/dotnet/standard/security/
[9] https://www.troyhunt.com/free-ebook-owasp-top-10-for-net/
[10] https://www.pcisecuritystandards.org/
[11] http://rodo2018.pl
[12] http://www.giodo.gov.pl/
[13] https://github.com/ggggtttt/dotnetsecurity
[14] https://www.visualstudio.com/pl/downloads/
[15] https://www.microsoft.com/en-us/SDL/process/training.aspx
[16] https://sekurak.pl/statyczna-analiza-bezpieczenstwa-kodu-aplikacji-czesc-1-wprowadzenie/
[17] https://niebezpiecznik.pl/post/programujesz-rob-to-bezpiecznie-czyli-praktyczne-wskazowki-od-microsoftu/
[18] https://niebezpiecznik.pl/post/caly-swiat-oglada-i-komentuje-kod-zrodlowy-obslugujacy-polskie-wybory/
[19] https://what.thedailywtf.com/topic/13836/polish-electorial-calculator/2
[20] https://www.reddit.com/r/programming/comments/2ml27h/source_code_of_polish_electoral_calculator_big/
[21] https://zaufanatrzeciastrona.pl/post/wersja-testowa-systemu-pkw-dostepna-publicznie-w-trybie-debug/
[22] https://wpolityce.pl/polityka/222594-szok-kazdy-moze-wejsc-w-kalkulator-wyborczy-dokonac-zmian-i-przeslac-protokol-do-centralnej-komisji
[23] https://www.wykop.pl/link/2248080/kod-zrodlowy-kalkulatora-wyborczego/strona/2/
[24] https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/preprocessor-directives/
[25] https://www.xamarin.com/
[26] https://msdn.microsoft.com/en-us/library/ff400235.aspx
[27] https://msdn.microsoft.com/en-us/library/610xe886.aspx
[28] https://msdn.microsoft.com/en-us/library/dd465326(v=vs.110).aspx
[29] https://msdn.microsoft.com/en-us/library/e8z01xdh.aspx
[30] https://blogs.msdn.microsoft.com/prashant_upadhyay/2011/07/14/why-debugfalse-in-asp-net-applications-in-production-environment/
[31] https://msdn.microsoft.com/en-us/library/31kztyey.aspx
[32] https://stackoverflow.com/questions/2453841/how-to-turn-off-pdb-generation-and-vshost-for-all-release-builds
[33] https://docs.microsoft.com/en-us/dotnet/framework/app-domains/how-to-sign-an-assembly-with-a-strong-name
[34] http://nlog-project.org/
[35] https://github.com/nlog/NLog/wiki/Configuration-file#configuration-file-format
[36] https://www.asp.net/media/4071077/aspnet-web-api-poster.pdf
[37] https://www.exceptionnotfound.net/the-asp-net-web-api-2-http-message-lifecycle-in-43-easy-steps-2/
[38] https://weblogs.asp.net/fredriknormen/log-message-request-and-response-in-asp-net-webapi
[39] https://docs.microsoft.com/en-us/aspnet/mvc/overview/getting-started/lifecycle-of-an-aspnet-mvc-5-application/_static/lifecycle-of-an-aspnet-mvc-5-application1.pdf
[40] http://blog.thedigitalgroup.com/chetanv/2015/06/30/a-detailed-walkthrough-of-asp-net-mvc-request-life-cycle/
[41] https://msdn.microsoft.com/pl-pl/library/ms227673.aspx
[42] https://docs.microsoft.com/en-us/aspnet/mvc/overview/performance/bundling-and-minification
[43] https://www.typescriptlang.org/
[44] https://content-security-policy.com/
[45] https://www.iis.net/
[46] https://msdn.microsoft.com/en-gb/library/system.web.httpresponse.suppressformsauthenticationredirect(v=vs.110).aspx
[47] https://docs.microsoft.com/en-us/dotnet/framework/wcf/feature-details/interoperable-object-references
[48] https://msdn.microsoft.com/pl-pl/library/h0hfz6fc(v=vs.85).aspx
[49] https://docs.microsoft.com/en-us/aspnet/web-api/overview/error-handling/exception-handling
[50] https://docs.microsoft.com/en-us/aspnet/web-api/overview/error-handling/web-api-global-error-handling
[51] https://weblogs.asp.net/imranbaloch/handling-http-404-error-in-asp-net-web-api
[52] https://stackoverflow.com/questions/28719326/web-api-2-2-return-custom-404-when-resource-url-not-found
[53] https://docs.microsoft.com/en-us/aspnet/web-api/overview/security/preventing-cross-site-request-forgery-csrf-attacks
[54] https://docs.angularjs.org/api/ng/service/$http
[55] https://www.ietf.org/rfc/rfc2109.txt
[56] https://msdn.microsoft.com/en-us/library/hh882339(v=vs.110).aspx
[57] http://blog.diniscruz.com/2014/06/bypassing-aspnet-request-validation.html
[58] https://infosecauditor.wordpress.com/2013/05/27/bypassing-asp-net-validaterequest-for-script-injection-attacks/
[59] http://gosecure.net/2016/03/22/xss-for-asp-net-developers/
[60] https://www.whitehatsec.com/blog/by-the-website-vuln-numbers-net-xss-request-validation-bypass/
[61] http://michaeldaw.org/news/news-030407
[62] https://msdn.microsoft.com/en-us/library/system.web.configuration.httpruntimesection.requestvalidationmode.aspx
[63] https://docs.microsoft.com/en-us/aspnet/whitepapers/aspnet4/breaking-changes#0.1__Toc256770147
[64] https://stackoverflow.com/questions/26786380/http-request-validation-exception-in-asp-net-web-service-on-ubuntu-with-mono
[65] https://stackoverflow.com/questions/3621272/allow-user-to-input-html-in-asp-net-mvc-validateinput-or-allowhtml
[66] https://www.nuget.org/packages/AntiXSS/
[67] https://www.owasp.org/index.php/.NET_AntiXSS_Library
[68] https://github.com/mganss/HtmlSanitizer
[69] http://api.jquery.com/html/
[70] http://www.troyhunt.com/2012/02/shhh-dont-let-your-response-headers.html
[71] https://docs.microsoft.com/en-us/iis/configuration/system.webserver/httpprotocol/
[72] https://blogs.msdn.microsoft.com/varunm/2013/04/23/remove-unwanted-http-response-headers/
[73] https://www.owasp.org/index.php/OWASP_Secure_Headers_Project#tab=Headers
[74] https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers
[75] https://developer.mozilla.org/en-US/docs/Web/HTTP/Public_Key_Pinning
[76] https://msdn.microsoft.com/pl-pl/library/ms228262(v=vs.85).aspx
[77] https://forums.asp.net/t/976773.aspx?How+to+turn+off+httpOnly+in+Forms+Auth+ASP+Net+2+0+
[78] https://msdn.microsoft.com/en-us/library/system.web.httpcookie.expires(v=vs.110).aspx
[79] https://msdn.microsoft.com/library/1d3t3c61(v=vs.100).aspx
[80] https://developer.mozilla.org/en-US/docs/Web/HTTP/Access_control_CORS
[81] https://developer.mozilla.org/en-US/docs/Web/API/Window/postMessage
[82] https://www.owasp.org/index.php/Path_Traversal

Jesteście genialni! Dzięki za super wskazówki!
Z tego wpisu spokojnie moglibyście wydać książkę :)
Książkę planujemy tak swoją drogą – na ten rok.
Świetny i mega przydatny artykuł – z serii tych do których z pewnością się wraca.
Książka super pomysł – zamawiam przedpremierowy :)
Jest opcja pobrania artykułu w pdf ?
w książce będą nowe teksty, czy to będzie papierowe wydanie sekuraka? :D
Będzie trochę nowych (już jest :) i trochę starych.
Czepialstwo: rysunki 24 i 74 występują dwukrotnie
Super artykuł!
Planuję rozpocząć pracę nad hobbystycznym projektem. Na pewno w trakcie rozpoczęcia projektu będę korzystał z artykułu na bieżąco.
Przypisy też są super, na pewno się przydadzą!
Dzięki!
Czepialstwo:
Nie jestem deweloperem .NET ani stałym użytkownikiem VS (bardzo krótkie doświadczenie ‘kiedyśtam’, ale… czy tłumaczenie angielskiego ‘solution na polskie ‘solucja’ tylko mi nie pasuje?Zdaje się, że słownikowo, powinno się to tłumaczyć jako ‘rozwiązanie’, a tłumaczeniem polskiego ‘solucja’ jest angielskie ‘walkthrough’. Podobna sytuacja, jak przy confident!=konfident i corruption!=korupcja, brzmią podobnie, ale znaczą co innego.
Pierwszy wynik z wyszukiwarki sugeruje, że nie tylko ja to tak bym przetłumaczył: https://www.dobreprogramy.pl/djfoxer/Spolszczenie-do-Visual-Studio-Pimp-My-Visual-Studio,35148.html
Jako dev .Net i stały użytkownik VS powiem tak:
– z tego co widzę to “solucja” jest przyjetym tłumaczeniem w środowisku (przynajmniej na śląsku)
– jak powiesz “w moim rozwiązaniu mam problem z […]” gwarantuję że większość programistów .Net nie załapie od razu o co ci chodzi.
Ok dzięki za wyjaśnienie. Będę musiał przeboleć, że źle brzmi ;)
Jako inzynier programista pracujacy na codzien w .NET, potwierdzam to co napisal juz Michal – slowo “solucja” jest przyjetym w Polsce tlumaczeniem tego co VS nazywa “solution”.
A jako osoba mieszkajaca kiedys przez ladnych kilka lat w Stanach, musze zaprotestowac – bo slowo “corruption” jako jedno ze znaczen wlasnie ma “korupcja” i w tym kontekscie rowniez (choc nie tylko) jest uzywane przez Amerykanow.
Fantastyczny artykuł. :-)
Gdyby wszystkie te reguły były przestrzegane i brane pod uwagę w każdym projekcie to świat byłby piękniejszy ;-)
Wszystkie poruszone zagadnienia bardzo ważne i potrzebne :-)
Z pewnością nie jeden raz powróce do tego artykułu przy rozmyślaniach o danych zagadnianiach.
Artykuł fajny, tylko że dla starszych developerów .Net nic nowego – 80% rzeczy wymienionych jest przyjęte jako dobra praktyka tak czy inaczej.
Odnośnie rysunku 25. Rozumiem, że tak się nie powinno robić ale jaka jest alternatywa? Czy jest jakiś best practice jak łączyć js z widokami? Przykładowy projekt?
Podbijam pytanie.
Mamy wskazany problem ale jakie jest (w miarę uniwersalne) rozwiązanie :)? Podejrzewam, że mogłoby tutaj chodzić o to aby zawsze mapować sobie razorowy model na obiekt javascript. Widzę w tym sens w przypadku używania dodatkowych bibliotek MVVM, czyli np. Knockout.js (https://stackoverflow.com/questions/28282043/asp-net-mvc-pass-model-to-knockoutjs-external-file). Jaki jednak jest z tego zysk w scenariuszach bez używania dodatkowych bibliotek?
Dodatkowo, oprócz modelu dochodzi jeszcze temat i18l czyli jak skorzystać ze stringowych resource w takim odizolowanym kodzie js.
Odpowiedź jest taka sama. To zależy :) (na co wpadnie autor).
Jeżeli chcesz korzystać z .NETowych plików Resource, to widziałem takie rozwiązane, mocno ozdobione generycznością i refleksją, w którym było jedno miejsce (lub kilka miejsc, jeśli chcemy to optymalizować) w kodzie gdzie wszystkie potrzebne teksty były wrzucane do zmiennej javascript (jakiś obiekt na zasadzie dictionary {key0:value0, key1:value1, …}) właśnie w elemencie script htmla. Takim miejscem może być na początek _Layout.cshtml. Potem uzywasz w javascriptcie tego obiektu za pomoca kluczy.
Rozwiązanie skupia się na tym żeby napisać sobie dobry automat w C#, który skorzysta z poprawnego pliku Resource, pobierze wszystkie interesujące Cię client side resourcey (wszystkie z wskazanego z pliku, wszystkie o danym przedrostku, etc.) i wrzuci w var clientSideResources = { };. Zadanie z gwiazdką to zamiast wrzucać to w _Layout.cshtml to wygenerować dynamicznie plik js z takim samym contentem na życzenie przeglądarki.
W angularze dla odmiany, alternatywne rozwiązanie polega na tym że mamy pliki json z zlokalizowanymi resourcsami, a modul angular-translate wstrzyknie już odpowiedni tekst na podstawie klucza. Więcej tutaj: https://angular-translate.github.io/docs/#/guide/02_getting-started
Hej,
Myślę sobie że uniwersalnego rozwiązania czy best practice jako takiego bezpośrednio nie ma. Jedyna słuszna odpowiedź to jak zwykle: to zależy. I to zależy od sytuacji. Do głowy przychodzi mi parę konkretnych przykładów:
– wyrenderowany formularz z dołączonym jQuery (walidacja, fancy kontrolki, etc.),
– wyrenderowana lista obiektów z dołączonym jQuery/frameworkiem MVVM takim jak Knockout (dynamiczne zarządzanie listą, zliczanie obiektów zależnych, guziki, etc.),
– Single Page Application z Angular,
I w każdym z tych przypadków można zaproponować inne rozwiązanie. Prawda jest taka że jakoś musimy przekazać obiekt do kontekstu javascript. I albo to zrobimy bezpośrednio albo zmusimy javascript by pobrało sobie ten obiekt samodzielnie. Stąd możemy:
– wrzucić nasz obiekt w elementy HTML w pola hidden, w customowe attrybuty i pofetchować to korzystając z IDków elementów (bardzo stara szkoła, (szybko przestanie działać dla bardziej skomplikowanych obiektów)),
– wrzucić nasz obiekt bezpośrednio w obiekt javasciprt, jak sugerują stackoverflowy (to wymaga użycia Html.Raw(), co może być krzywdzące):
var property = Model.Property;
var object = @(Html.Raw(Json.Encode(Model))); // Pytanie jak często będziesz musiał przekazać tu dane z innego inputa pod kontrolą użytkownika?
– pobrać obiekt za pomocą calla AJAXowego ($.get(), this.http.get()), no bo czemu nie? :)
Szybkie POC na boku pokazuje że:
test
var data = 1234;
window[‘otherData’] = 5678;
localStorage.setItem(‘lsData’, 666);
alert(data);
alert(window[‘otherData’]);
alert(localStorage[‘lsData’]);
oraz jstest.js:
alert(‘I can also see data: ‘ + data);
Że opcja druga z listy powyżej zadziała bez problemu.
Pytanie tylko, co chcesz osiągnąć?
Pozdrawiam,
G
Kawał dobrego tekstu.
Teraz zauważyłem, że macie również PDF swojego magazynu do pobrania ?
Gratulacje :D
Właśnie się dowiedziałem, że nic nie wiem. Wiele nauki mnie czeka. Bardzo dziękuję za rewelacyjny tekst !
świetny artykuł, polecam każdemu !