Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Adminie… Czy znamy Twoje grzechy? ;-) Sprawdź!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Adminie… Czy znamy Twoje grzechy? ;-) Sprawdź!

Do tej pory poznaliśmy HTML5 przede wszystkim jako doskonałe narzędzie do omijania różnych filtrów w webaplikacjach. Nowy język pomaga atakującym na łatwiejsze przeprowadzenie klasycznego ataku na strony internetowe, przede wszystkim te z rodzaju XSS. Oczywiście bezpieczeństwo HTML5 nie dotyczy wyłącznie tematyki wstrzyknięć – czas poznać nowe wektory ataku.
Tak jak kiedyś AJAX, również HTML5 chce jeszcze bardziej zatrzeć granicę między webaplikacjami a klasycznymi aplikacjami desktopowymi. HTML5 wprowadza szereg mechanizmów, które pozwalają działać webaplikacji nawet, gdy użytkownik jest offline. Programiści dostali potężne narzędzia, dzięki którym można nie tylko synchronizować stan zasobów webaplikacji (obrazki, style, kod HTML…), ale również dostali technologię do przetwarzania logiki biznesowej. Od tej pory możemy na przykład operować na rekordach bazy danych SQL, która będzie przechowywana po stronie użytkownika, nawet gdy ten nie będzie miał dostępu do Internetu.
Nowe technologie, o których tu mowa, to:
Pierwsze cztery interfejsy są kontenerami na różnego rodzaju dane – klucze tekstowe, dane relacyjne (SQL), obiekty (noSQL) czy nawet całe pliki (BLOB). Offline Application Cache pozwala kontrolować kontener cache webaplikacji – bezpieczeństwo tego interfejsu poznamy w jednym z następnych paragrafów, tu przeanalizujmy bezpieczeństwo reszty kontenerów.
Zanim jednak zaczniemy, kilka słów na temat wsparcia HTML5 Offline Technologies w przeglądarkach.
WebStorege, Indexed Database oraz File Access API jest zaimplementowanie w większości przeglądarek. Gorzej sprawa wygląda z Web SQL. Wokół tej specyfikacji było bardzo gorąco i niechętnie ją wprowadzano. Obecnie Web SQL jest raczej ciekawostką – technologia powoli umiera i prawdopodobnie nie będzie rozwijana. Gwoździem do jej trumny była decyzja Mozilli, która odrzuciła WebSQL w swojej przeglądarce. Nic straconego – WebSQL może być zastąpiony przez IndexedDB.
Zasady bezpieczeństwa programowania każdego z wymienionych wyżej kontenerów i przełamywania ich zabezpieczeń są podobne. Bardzo dobry poradnik wprowadzający w programowanie każdego z wyżej wymienionych interfejsów został opisany na stronie z materiałami z konferencji Sencha Conference 2010.
Web Storage, WebSQL, Indexed Database oraz File Access API to kontenery bardzo podobne do kontenera ciasteczek. Wszystkie z nich różnią się rodzajem i maksymalną ilością przechowywanych danych, ale działają w podobny sposób – lokalnie w przeglądarce użytkownika.
Najważniejsze jest więc to, aby w kontenerach tych nie przechowywać wrażliwych danych. Tak jak w ciasteczkach nie powinniśmy przechowywać np. hasła użytkownika, tak samo nie powinniśmy przechowywać takiej wartości w Web Storage.
Szczególną uwagę należy zwrócić na kontener WebSQL. Narażony jest on na klasyczne ataki SQL Injection. Niebezpieczeństwo jest tym większe, że atakujący ma pełną wiedzę na temat bazy oraz zapytań – znajdują się one bezpośrednio w kodzie Javascript webaplikacji. Może się zdarzyć, że w bazie WebSQL webdeveloperzy będą chcieli zapisać wiele informacji z bazy online. Trzeba przy tym bardzo uważać – zamiast konkretnego rekordu z danymi użytkownika nieroztropny programista może przekopiować dane wszystkich użytkowników. Oczywiście atakujący będzie w stanie wyświetlić te dane, ponieważ znajdą się one w jego przeglądarce.
Na szczęście WebSQL nie będzie już rozwijany, ale pomijając czysty SQL, zasady bezpieczeństwa programowania w tym interfejsie są podobne do tych obowiązujących dla pozostałych kontenerów.
Programując kontenery danych HTML5, pamiętaj, że:
Oczywiście dalej największym niebezpieczeństwem okazuje się błąd z rodzaju XSS. Nawet proste wstrzyknięcie może spowodować zmianę przetwarzania logiki biznesowej u użytkowników lub nawet pobrać ich pliki z lokalnego systemu plików File API.
Testowanie kontenerów danych polega na audycie kodu Javascript oraz na analizie samych danych. Dane można przeanalizować na przykład w narzędziach developerskich Google Chrome w zakładce Zasoby:
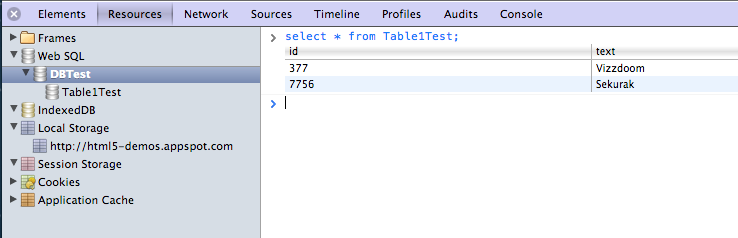
Nowe kontenery danych okazały się doskonałą przestrzenią dla cyberprzestępców chcących budować nowe, jeszcze trudniejsze do usunięcia złośliwe ciasteczka, tzw. Evercookie.
Evercookie, zwane też „Nieśmiertelnymi ciastkami”, to biblioteka Javascript, której celem jest stworzenie informacji ID jednoznacznie identyfikującej konkretnego internautę. Informacje te przechowywane są w wielu miejscach przeglądarki. Gdy Evercookie wykryje próbę usunięcia „ciastka” (np. przez wyczyszczenie klasycznych cookie w przeglądarce), wtedy na nowo wrzuca informację identyfikującą do wszystkich możliwych kontenerów danych w przeglądarce.
Jedynym wyjściem z sytuacji jest usunięcie złośliwej informacji ze wszystkich zasobów przeglądarki w jednym momencie. Jest to niestety nad wyraz trudne, ponieważ przeglądarki domyślnie nie usuwają informacji ze wszystkich kontenerów, nawet po wymuszeniu usuwania prywatnych danych!
Tak jak wspomniano, Evercookie korzysta z wielu zasobów – wszędzie tam, gdzie można w przeglądarce zapamiętać informacje, Evercookie próbuje zamieścić tam swój identyfikator:
Mechanizm Evercookie może zostać użyty jako element blokowania np. zbanowanych użytkowników w zależnych od siebie serwisach. Oczywiście, jak łatwo się domyśleć, Evercookie wykorzystywane jest w całkowicie inny sposób.
Zamieszczenie interfejsu Nieśmiertelnych Ciastek na kilku witrynach umożliwia profilowanie internautów i śledzenie ich poczynań w Internecie. Są to bezcenne informacje dla różnego rodzaju spamerów czy nieuczciwych banków/agencji ubezpieczeniowych.
Zasadę działania Evercookie można przetestować na stronie projektu tego API. Można tam również pobrać kod źródłowy JS w celu zaimplementowania i testowania tej metody przechowywania danych.
I tu HTML5 znowu rozszerza znane ataki, które stają się jeszcze bardziej szkodliwe.
Interfejsy należące do kategorii HTML5 Offline Application Cache pozwalają korzystać z pewnych elementów web-aplikacji, nawet, gdy użytkownik straci połączenie z Internetem. Tak jak już wspomniano, możliwe jest przechowywanie nie tylko takich informacji jak obrazki czy style, ale również skryptów i dowolnych innych plików. Mamy więc de facto interfejs do kontroli cache w przeglądarce użytkownika.
Mechanizm Application Cache, gdyż tak też nazywa się ten zbiór interfejsów, pozwala cachować nie tylko media strony internetowej, ale umożliwia również przetwarzanie logiki biznesowej (dzięki cachowaniu dowolnych plików, w tym skryptów JS).
Poznajmy podstawowe elementy charakteryzujące Application Cache.
Pierwszym krokiem mającym na celu stworzenie webaplikacji mogącej działać offline, jest przygotowanie pliku manifestu. Jest to prosty plik tekstowy o dowolnej nazwie, który definiuje, które zasoby powinny być przechowywane w cache przeglądarki użytkownika, a które powinny być dostępne wyłącznie online.
Struktura przykładowego pliku manifestu może być następująca:

Plik manifestu rozpoczyna się od frazy CACHE MANIFEST. Do sekcji CACHE dopisujemy dowolne pliki, które mają zostać zapisane w pamięci podręcznej przeglądarki użytkownika. Oczywiście nie wszystkie skrypty powinny być wykonywane po stronie użytkownika, dlatego w sekcji NETWORK możemy dodać pliki, które nie mogą być przetwarzane offline. Przy próbie odwiedzenia takiego adresu zostanie wyświetlona strona, którą definiujemy w sekcji FALLBACK.
Aby włączyć mechanizm Application Cache w naszej webaplikacji, wystarczy dodać atrybut manifest w znaczniku <html>, który będzie wskazywał na plik manifestu:
<!DOCTYPE HTML> <html manifest="/offlinecache.manifest"> <head>...</head> <body>...</body> </html>
Utworzenie pliku manifestu oraz wskazanie go w atrybucie manifest wystarczy, aby uaktywnić Offline Application Cache w przeglądarce użytkownika.
Od tego momentu w sytuacji gdy użytkownik odwiedzi webaplikację, jego przeglądarka pobierze kod strony, po czym zinterpretuje atrybut manifest. W tej chwili w przeglądarce nie będzie jeszcze pliku manifestu, więc zostanie on pobrany ze wskazanej ścieżki do lokalnego cache. Reszta plików webaplikacji (style, obrazki, skrypty itd.) zostanie pobrana w typowy sposób, jednak te, które zostały wymienione w sekcji CACHE, trafią również do lokalnego cache.
Przy wszystkich następnych odwiedzinach webaplikacji, czyli wtedy gdy użytkownik będzie online, jego przeglądarka będzie interpretować atrybut manifest. Plik manifestu będzie cały czas znajdować się w pamięci przeglądarki, więc nie zostanie on na nowo zinterpretowany. Jedyną rzeczą jaką zrobi przeglądarka będzie sprawdzenie, czy manifest online różni się od wersji lokalnej. Jeśli manifest na stronie się zmieni, wtedy zostanie pobrany i zinterpretowany na nowo.
Podsumowując, plik manifestu:
W sytuacji gdy użytkownik będzie chciał odwiedzić stronę, do której nie ma dostępu z powodu niedostępności, strona zostanie wczytana z cache. Oczywiście nowy manifest nie zostanie pobrany.
Zagrożenie pojawia się w nazwie pliku manifestu. Przypominam, że plik ten może mieć dowolną nazwę (czyli też rozszerzenie) – co może być wykorzystane przez agresora w celu zwiększenia zasięgu ataków z rodziny Man In the Middle.
Załóżmy, że agresor stawia złośliwe proxy, z którego zaczynają korzystać jego ofiary. Agresor może wymusić używanie takiego proxy poprzez udostępnienie darmowego hotspota wifi na uczelni, hotelu czy kawiarni lub wykorzystywać inne metody wykorzustuwane podczas ataków Man In the Middle. Grunt, aby użytkownicy przez krótką chwilę odwiedzali strony internetowe przez urządzenie pośredniczące będące pod kontrolą atakującego.
W momencie, gdy użytkownicy przechodzą przez wrogie proxy, agresor modyfikuje w locie żądania do stron internetowych i dodaje do kodu HTML deklarację manifestu Application Cache, plik manifestu oraz złośliwy plik javascript, np. evil.js. Atakujący w tym skrypcie może wykonywać dowolne akcje – może dodawać malware, nasłuchiwać klawiaturę użytkownika itp.
Od tego momentu przeglądarka każdej ofiary będzie zawsze serwować złośliwy skrypt dodany przez atakującego. I nie byłoby w tym nic nadzwyczajnego (klasyczny atak MITM), gdyby nie mechanizm HTML5 Application Cache, który powoduje, że skrypt będzie wykonywany nawet wtedy, kiedy agresor nie będzie już posiadał kontroli nad łączem ofiary.
Zobaczmy to na przykładzie. Niech atakujący postawi transparentne proxy, którego zadaniem będzie dodanie pliku manifestu Application Cache w przypadku odwiedzenia strony (np. Wirtualnej Polski). Agresor nakłania ofiarę, aby skorzystała z proxy:

W momencie używania Evil Proxy, ofiara wykonuje złośliwy skrypt script.js. Po kilku godzinach ofiara przestaje używać proxy (kończąc klasyczny atak Man In The Middle). Po powrocie do domu ofiara odwiedza jeszcze raz stronę wp.pl. Jej przeglądarka interpretuje zasady wczytanego wcześniej pliku manifestu, więc elementy z sekcji CACHE zostaną wczytane z lokalnego cache przeglądarki:

Cache wraz ze złośliwym skryptem agresora zostanie aktywny do momentu, gdy nie zmieni się plik manifestu (strony online) lub gdy ofiara nie wyczyści cache ręcznie w przeglądarce. Na domiar złego wyczyszczenie Application Cache nie jest łatwe – w niektórych przeglądarkach trzeba używać dodatkowych rozszerzeń (np. w Google Chrome).
Problemem, z którym musi się zmierzyć atakujący, jest istniejący plik manifestu po stronie webaplikacji online. Gdy tego pliku nie będzie (a ofiara też będzie online), przeglądarka wykryje ten fakt i przestanie używać mechanizm Application Cache.
Czy agresor jest więc ograniczony tylko do stron, które używają ten mechanizm (czyli takich, które posiadają plik manifestu)? Niestety nie. Manifest może być dowolnym plikiem – agresor podczas zatruwania może wskazać np. plik readme, changelog, robots.txt, rules lub dowolny inny istniejący w webaplikacji online plik, który nie będzie przez dłuższy czas modyfikowany.
Właśnie ta właściwość – dowolna nazwa pliku manifestu Application Cache – sprawia, że interfejs webaplikacji offline jest niebezpieczny, gdyż przez to atak Application Cache Poisoning ma duży zasięg i może być użyty w ataku na dowolną stronę internetową.
W celu lepszego zrozumienia ataku Application Cache Poisoning przeanalizujmy hipotetyczny atak Man In The Middle na konto ofiary, która używa serwisu facebook.com.
W tym przykładzie atakujący posłuży się programem Squid Imposter, który jest rozszerzeniem popularnego Squid proxy. Można jednak użyć innego programu – zmodyfikowanej wersji sslstrip lub innych technik MITM.
Oto kroki, które musi wykonać agresor:
Oto kroki, które musi wykonać ofiara:
Poniżej znajduje się film prezentujący złośliwe wykonywanie skryptów po stronie ofiary przez atakującego w serwisie facebook:
Witryna caniuse.com wskazuje, że wsparcie mechanizmu HTML5 Application Cache zostało wdrożone w każdej współczesnej przeglądarce internetowej. Dane z lutego 2013 roku prezentuje poniższa tabela:
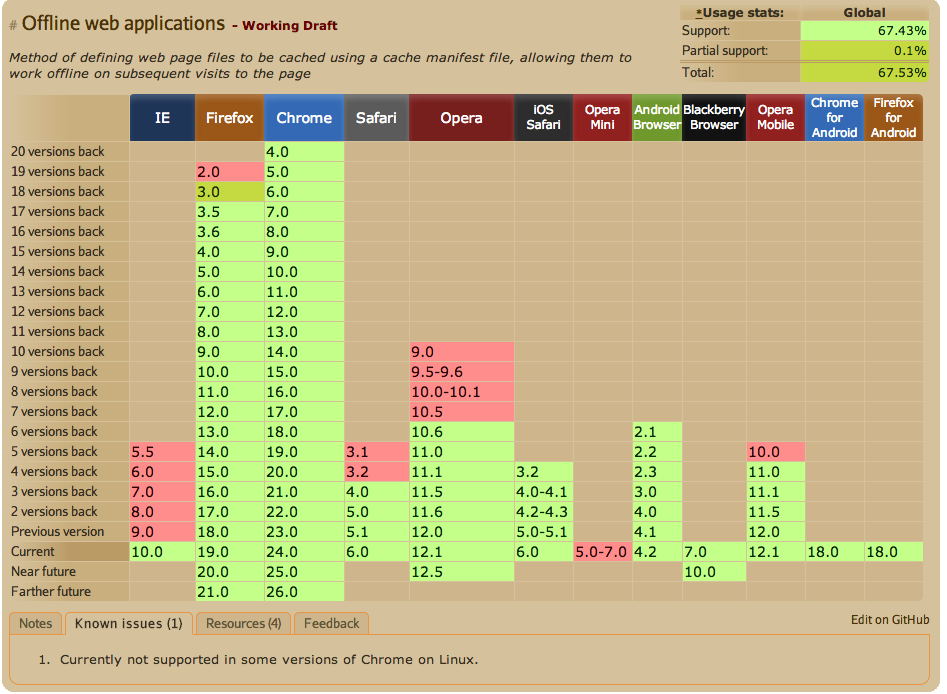
Widać, że zasięg ataku jest bardzo duży – praktycznie każdy internauta jest narażony na niebezpieczeństwo zatrucia magazynu Application Cache.
Jak bronić się przed tego typu atakiem?
Niestety nie jest to wcale proste.
Ochrona po stronie kodu webaplikacji jest w zasadzie niemożliwa. Jedynym wyjściem byłoby zmienianie co kilka sekund (minut?) wszystkich plików na serwerze, aby zainfekowana przeglądarka ofiary wykrywała nowszą wersję pliku, który został wskazany jako manifest. Niestety jest to praktycznie niewykonalne ze względu na obciążenie maszyny oraz na ewentualne problemy z różnego rodzaju skryptami administratorów operującymi na plikach strony.
Na szczęście mogą się chronić sami użytkownicy.
Przede wszystkim należy pamiętać, że nie można ufać obcym łączom – w szczególności darmowym hot spotom. Gdy podłączamy się do obcych sieci, zawsze jesteśmy narażeni na niebezpieczeństwa. Jeżeli już to robimy, używajmy VPN do enkapsulowania ruchu przez szyfrowany protokół, który będzie kierowany do zaufanej sieci.
Aby ustrzec się przed tego rodzaju atakami, można również wyłączyć mechanizm Application Cache w samej przeglądarce. Jest to generalna zasada bezpieczeństwa: nieużywana rzecz powinna zostać wyłączona. Google Chrome umożliwia to przez uruchomienie przeglądarki z flagą –disable-application-cache, w Firefoxie można to zrobić przez zmianę właściwości dom.storage.enabled na false w oknie about:config.
Podsumowując, Offline Application Cache jest bardzo ciekawą technologią, która potrafi nie tylko zmniejszyć ilość danych pobieranych z webaplikacji, ale również potrafiącą znacznie zwiększyć jej dostępność. Niestety mechanizm ten posiada błędy bezpieczeństwa, które istnieją w samym projekcie specyfikacji – plik manifestu może być dowolnym plikiem, a jego mimetype może być ignorowane przez przeglądarkę. Dzięki tym dwóm właściwościom agresor może na długo utrwalić atak MITM u swoich ofiar.
Zagrożenie jest więc bardzo poważne i dotyczy obecnie użytkowników wszystkich przeglądarek – nie tylko w wersji stacjonarnej, ale również mobilnej.
– Adrian Vizzdoom Michalczyk
Adrian Vizzdoom Michalczyk: pasjonat bezpieczeństwa teleinformatycznego od najmłodszych lat, obecnie student wydziału Informatyki Politechniki Śląskiej w Gliwicach.
Czasem programista, czasem gracz papierkowych gier RPG, ale zawsze fascynat klimatów post-apokaliptycznych. W swoim życiu nosił zarówno czarny, jak i biały kapelusz, teraz w wolnym czasie próbuje rozwijać swój kąt Internetu: http://vizzdoom.net.

{kind=link}
Świetny tekst, jak zwykle :)
Generalnie, poza typowymi podatnościami aplikacji webowych doszedł nam cały wachlarz nowych wektorów ataku. Wróżę świetlaną przyszłość przed wszelkiej maści specjalistami od bezpieczeństwa aplikacji internetowych :)
W chrome nie powinno być:
–disable-application-cache
(z dwoma -)?
Problem by nie występował gdyby przeglądarki robiły wyjątek dla pliku manifestu: pobierały i interpretowały go zawsze, niezależnie od ustawień cachu czy to w przeglądarce czy serwerze wysyłającym plik, racja?
Pliki manifestu, jak się domyślam, nie będą duże. Cachowanie tego nie da jakiś wielkich oszczędności jeżeli chodzi o transfer, a brak cachu zwiększyłby bezpieczeństwo. Moim zdaniem warto poświęcić te parędziesiąt/set bajtów.
Jest jakiś inny haczyk? Czy może to wykluczanie jest takie skompilowane w implementacji? Czy może źle zrozumiałem i namieszałem? :p
@pskosinski: No właśnie.
Bo czy nie jest przypadkiem tak, że manifest za każdym requestem jest pobierany i interpretowany od nowa? Więc jak ofiara “wróci do domu” i odwiedzi jakąś stronę to wstrzyknięty wcześniej manifest zostanie nadpisany nowym (lub brakiem) i będzie stosowana nowa polityka?
Jak wyłączyć mechanizm Application Cache w operze?