Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej

Załóżmy hipotetyczną sytuację: jesteś administratorem ds. monitoringu w firmie. Wdrożyłeś środowisko Zabbix, a po lekturze artykułów na sekuraku dotyczących Grafany postanowiłeś wdrożyć ją również u siebie. Po pewnym czasie z powodzeniem uruchomiłeś kilka dashboardów wykorzystujących oficjalny plugin do Zabbixa. Koledzy patrzą z uznaniem, zarząd chwali Twoje działania, a prezes sam ściska Ci rękę na korytarzu. Nawet Twój pies częściej chce się z Tobą bawić. Jednym słowem – sielanka.
Pewnego dnia dostajesz jednak następujący email:
„W związku z ostatnimi problemami z usługą SSH po aktualizacji, odnotowujemy znaczący przyrost liczby użytkowników zalogowanych w systemie – jeden użytkownik może utrzymywać wiele aktywnych sesji SSH.
Prosimy o przygotowanie w Grafanie panelu, który pokaże maksymalną liczbę zalogowanych użytkowników w wybranym przedziale czasu.
Prosimy również o zawężenie danych tylko do hostów z systemem Ubuntu, ponieważ tylko tam występuje problem.”
Myślisz sobie: „Prościzna! W oficjalnym szablonie Zabbixa jest metryka dotycząca liczby użytkowników, wartość maksymalną uzyskam przy pomocy transformacji (pobierzemy wszystkie wartości i z nich uzyskamy wartość maksymalną), a informację o systemie operacyjnym znajdę przecież w inwentarzu hosta…”
Powtarzasz te słowa jeszcze raz, aż w końcu dociera do Ciebie – oficjalny plugin Zabbixa nie pozwala pobierać danych z inwentarza hosta!
Zaczynasz przeczuwać, że Twój pies znowu będzie wolał wychodzić na spacery sam…
Czy Tobie też zdarzyła się podobna sytuacja?
Masz dość ograniczeń oficjalnego pluginu Zabbixa?
A może zarządzasz dużym środowiskiem i zauważyłeś, że plugin potrafi być ociężały, bo „pod spodem” pobiera zbyt wiele danych?
Jeśli tak – ten artykuł jest dla Ciebie!
W poprzednim >artykule pokazaliśmy dość nieoczywiste wizualizacje danych. Dzisiaj skupimy się na wyciąganiu danych z Zabbix w mniej oczywisty sposób – za pomocą bezpośredniego połączenia się z bazą danych Zabbixa.
Zaczynamy!
1. Zabbix + Grafana – część 1 – instalacja
2. Zabbix + Grafana – część 2 – Przedstawianie danych
3. Zabbix + Grafana – część 3 – Przedstawianie danych – przykłady zaawansowane
4. Zabbix + Grafana – część 4 – Pobieranie danych z DB
5. Zabbix + Grafana – część 5 – Własne zapytania do API
Architektura środowiska nie uległa znaczącym zmianom – wciąż bazujemy na tej samej konfiguracji. Zmianie podlega tylko sposób komunikacji z środowiskiem Zabbix, gdyż tym razem będziemy łączyć się bezpośrednio do bazy danych:

Rysunek 1. Środowisko testowe wraz z oznaczoną komunikacją.
W tym miejscu część czytelników może poczuć lekkie rozczarowanie – środowisko testowe korzysta z bazy PostgreSQL w wersji 17.5.
Użytkowników, którzy wykorzystują MySQL lub MariaDB, zachęcam jednak do samodzielnego połączenia Grafany z własnym silnikiem bazy danych, zgodnie z >dokumentacją producenta. Przykłady opisane w dalszej części artykułu mogą stanowić inspiracje do przerobienia ich na swój silnik bazy danych.
Wracając do naszego przykładu – upewnij się, że serwer Grafany ma dostęp sieciowy do bazy danych Zabbixa na domyślnym porcie TCP 5432.
Na potrzeby tego artykułu przyjmujemy standardową instalację Zabbixa, gdzie:
Pierwszym krokiem jest upewnienie się, że serwer Postgresql nasłuchuje na odpowiednim adresie IP oraz porcie 5432. Możemy to prosto sprawdzić za pomocą polecenia:
# ss -ntlp sport = 5432 |
Jeżeli adres w kolumnie Local address wskazuje na localhost (np. 127.0.0.1) lub też komenda nie pokazała żadnego wyniku, będziemy musieli zmienić konfigurację naszego silnika bazy danych.
W tym celu otwieramy plik konfiguracyjny naszego serwera (postgresql.conf). Nie wiesz, gdzie się znajduje? Możesz to łatwo sprawdzić, wyświetlając proces PostgreSQL i podglądając ścieżkę do aktywnego pliku konfiguracyjnego:
# ps aux | grep postgresql | grep-v grep |
Alternatywnie, możesz sprawdzić to bezpośrednio z poziomu bazy danych:
postgres=# SHOW config_file; config_file |
Po zlokalizowaniu pliku, otwieramy go i modyfikujemy następujące parametry:
# - Connection Settings - |
Zgodnie z komentarzami przy parametrze listen_addresses, należy wskazać adresy IP, na których serwer bazy danych ma nasłuchiwać. Domyślnie PostgreSQL akceptuje połączenia tylko z localhost.
W naszym przykładzie dodajemy drugi adres jako adres IP serwera zabbix-7-0 (192.168.88.240), z którego Grafana będzie łączyła się do bazy.
Uwaga dotycząca bezpieczeństwa
Można wpisać ‘*’, aby PostgreSQL nasłuchiwał na wszystkich interfejsach — ale takie ustawienie spowoduje, że silnik bazy danych nasłuchuje na wszystkich interfejsach sieciowych, co w niektórych środowiskach może niepotrzebnie wystawiać bazę na dostęp z nieautoryzowanych sieci.
Lepszym rozwiązaniem jest podanie tylko tych adresów, które faktycznie potrzebują dostępu.
Pozostawienie 127.0.0.1 zwykle jest dobrym pomysłem (wiele narzędzi łączy się lokalnie), ale jeśli w Twoim środowisku nie jest to wymagane — możesz go oczywiście usunąć.
Sprawdź również, na jakim porcie PostgreSQL przyjmuje połączenia — w naszym przykładzie pozostajemy przy domyślnym 5432.
Zapisz plik – jeżeli coś zmieniłeś, musisz zrestartować usługę bazy danych (zaleca się najpierw zatrzymanie usług, które łączą się do bazy bezpośrednio, a w szczególności – zabbix-server):
# systemctl stop zabbix-server |
Na koniec upewnij się, że serwer rzeczywiście nasłuchuje na właściwym adresie (zakładając domyślny port):
# ss -ntlp sport = 5432 |
Gdy mamy już poprawnie ustawione nasłuchiwanie bazy danych, możemy przejść do utworzenia użytkownika read-only, którego Grafana będzie używać do łączenia się z bazą.
Istnieje kilka sposobów, aby to osiągnąć — poniżej autor wyróżnia dwie metody:
Jeśli korzystasz z serwera PostgreSQL w wersji co najmniej 14 (jeżeli nie – pomyśl o aktualizacji, bo najprawdopodobniej masz niewspieraną już wersję!) możesz skorzystać z >predefiniowanej roli pg_read_all_data.
Ta rola automatycznie przyznaje prawo SELECT do wszystkich tabel, widoków i sekwencji oraz USAGE do wszystkich schematów — również tych, które zostaną utworzone w przyszłości (np. w trakcie aktualizacji środowiska Zabbix).
Autor kieruje się tutaj zasadą “prostota jest najlepsza”, ale jeszcze raz przypomina – nadajemy uprawnienia do odczytu do wszystkich danych znajdujących się w instancji PostgreSQL. Jeżeli masz wiele baz danych w klastrze PostgreSQL lub gdy trzymasz bazę Zabbix w innym schemacie niż domyślny public, warto rozważyć drugą – bezpieczniejszą – opcję.
Na potrzeby tego artykułu utworzymy użytkownika grafana_db_ro (pamiętaj, by ustawić długie i silne hasło):
postgres=# CREATE USER grafana_db_ro WITH PASSWORD 'wpisz_dlugie_i_skomplikowane_haslo!'; |
Jeżeli nie możesz skorzystać z predefiniowanej roli, warto stworzyć własną — dzięki temu możesz nadać uprawnienia dokładnie takie, jakie są wymagane, zgodnie z zasadą najmniejszego wymaganego uprzywilejowania.
Pamiętaj, że poniższe przykłady bazują na podstawowej instalacji Zabbixa (schemat public, baza zabbix, użytkownik zabbix).
Na początku tworzymy nową rolę “read_only_users”:
postgres=# create role read_only_users; |
Następnie przyznajemy jej uprawnienia do korzystania ze schematu public oraz dostęp read-only do wybranych elementów bazy danych.
Jeśli wiesz dokładnie, które dane chcesz odczytywać, nadaj uprawnienia tylko do konkretnych tabel — na przykład dla tabeli items (pamiętaj, aby polecenia wykonywać będąc połączonym z bazą zabbix):
zabbix=# GRANT USAGE ON SCHEMA public TO read_only_users; |
Jeżeli jednak nie masz pewności, które tabele będą Ci potrzebne, możesz przyznać uprawnienia read-only dla wszystkich tabel w schemacie public (w tym przypadku nie musisz być zalogowany bezpośrednio do bazy zabbix):
postgres=# GRANT USAGE ON SCHEMA public TO read_only_users; |
Warto również zadbać o to, aby rola automatycznie otrzymywała uprawnienia SELECT dla nowych tabel tworzonych w przyszłości (np. podczas aktualizacji środowiska Zabbix).
To ustawienie może być jednak mylące — działa tylko dla tabel utworzonych przez użytkownika, który wydał polecenie GRANT.
Przykładowo: jeśli poniższe polecenie wykona użytkownik admin:
ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO przykladowy_user; |
to przykladowy_user otrzyma dostęp SELECT wyłącznie do tabel utworzonych przez użytkownika admin. Nie będzie miał dostępu do tabel utworzonych przez innego użytkownika, np. user2.
Wiedząc już o powyższej zasadzie, musimy nadać odpowiednie uprawnienia jako użytkownik zabbix:
zabbix=> ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO read_only_users; |
Jedynym wyjątkiem od powyższej reguły jest użytkownik postgres — może on nadawać domyślne uprawnienia w imieniu innych użytkowników.
Dlatego możemy przypisać te same uprawnienia w imieniu użytkownika zabbix, wykonując poniższe polecenie jako postgres:
postgres=# ALTER DEFAULT PRIVILEGES FOR USER zabbix IN SCHEMA public GRANT SELECT ON TABLES TO read_only_users; |
Kiedy mamy już utworzoną rolę read_only_users, pozostaje stworzyć użytkownika i przypisać mu tę rolę:
postgres=# CREATE USER grafana_db_ro WITH PASSWORD 'wpisz_dlugie_i_skomplikowane_haslo!'; |
Dzięki temu rozwiązaniu możesz tworzyć wielu użytkowników read-only, przypisując ich do tej samej roli. Jeżeli w przyszłości będziesz musiał zmienić uprawnienia, wystarczy wprowadzić je na poziomie roli — nie musisz edytować każdego użytkownika osobno.
Uwaga dotycząca bezpieczeństwa
Przyznanie SELECT do wszystkich tabel w schemacie public jest wygodne, ale nie zawsze potrzebne ani wskazane.
Jeśli pracujesz w środowisku produkcyjnym lub masz bardziej restrykcyjne wymagania, ograniczaj uprawnienia do absolutnego minimum — czyli tylko do tych tabel, które rzeczywiście będą używane przez Grafanę.
Rola read-only i tak znacząco ogranicza ryzyko (nie pozwala nic zmieniać), ale im węższy zakres dostępu, tym lepiej.
W naszym przykładzie przyznajemy szersze uprawnienia, by uprościć cały proces i uniknąć problemów typu „dlaczego panel nagle przestał działać?”, ale nic nie stoi na przeszkodzie, by w Twoim środowisku zrobić to bardziej precyzyjnie.
Załóżmy, że masz już utworzonego użytkownika read-only (niezależnie od tego, którą metodą). Ostatnim krokiem jest umożliwienie połączenia z serwera Grafany do bazy danych Zabbixa. W tym celu należy zaktualizować plik pg_hba.conf, który odpowiada za reguły uwierzytelniania w PostgreSQL.
Jeśli nie wiesz, gdzie znajduje się ten plik, możesz to łatwo sprawdzić z poziomu bazy danych:
postgres=# SHOW hba_file; |
Edytuj ten plik i dodaj poniższą linijkę:
(...) |
Gdzie:
Jeżeli chcesz dowiedzieć się więcej na temat pliku pg_hba.conf, zapoznaj się z >oficjalną dokumentacją producenta.
Po zapisaniu pliku musimy wymusić wczytanie zmian.
Na szczęście nie trzeba restartować całego klastra PostgreSQL – wystarczy przeładować konfigurację (jako użytkownik postgres):
postgres=# SELECT pg_reload_conf(); ; |
Jeśli wszystko zostało wykonane poprawnie, z serwera grafana-12-1 powinieneś być w stanie połączyć się z bazą Zabbixa przy użyciu użytkownika grafana_db_ro:
# psql -h 192.168.88.240 -U grafana_db_ro -d zabbix |
Natomiast próba połączenia przy użyciu innego użytkownika lub innej bazy zakończy się błędem:
# psql -h 192.168.88.240 -U test1 -d zabbix |
Jeżeli coś nie działa, przyjrzyj się dokładnie zawartości pliku pg_hba.conf. PostgreSQL sprawdza reguły sekwencyjnie – linia po linii. Może się więc zdarzyć, że Twoje połączenie „wpada” w wcześniejszą regułę.
W razie problemów możesz również zwiększyć poziom logowania połączeń, włączając opcję:
log_connections = on |
w pliku postgresql.conf. Pamiętaj tylko, by po tej zmianie ponownie przeładować konfigurację:
SELECT pg_reload_conf(); |
Kiedy mamy już utworzonego użytkownika read-only oraz zapewnioną możliwość połączenia z bazy danych z serwera grafana-12-1, możemy przejść do konfiguracji oficjalnego pluginu PostgreSQL.
W tym celu wybieramy z menu “Connections” – “Data sources”, a następnie “Add new data source”:
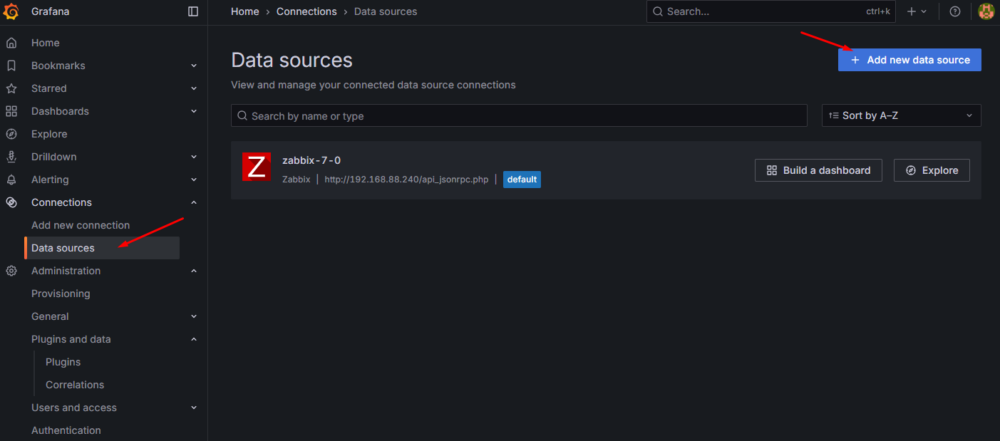
Rysunek 2. Dodanie nowego źródła danych.
W wyszukiwarce źródeł danych wpisujemy PostgreSQL i klikamy w wynik:
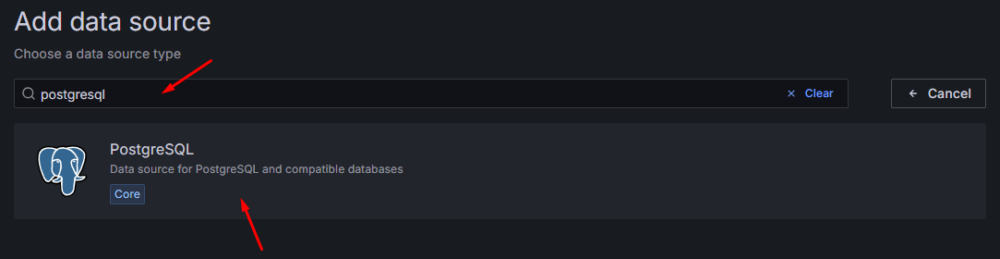
Rysunek 3. Wyszukanie pluginu PostgreSQL jako źródło danych.
Omówmy teraz poszczególne pola w konfiguracji:
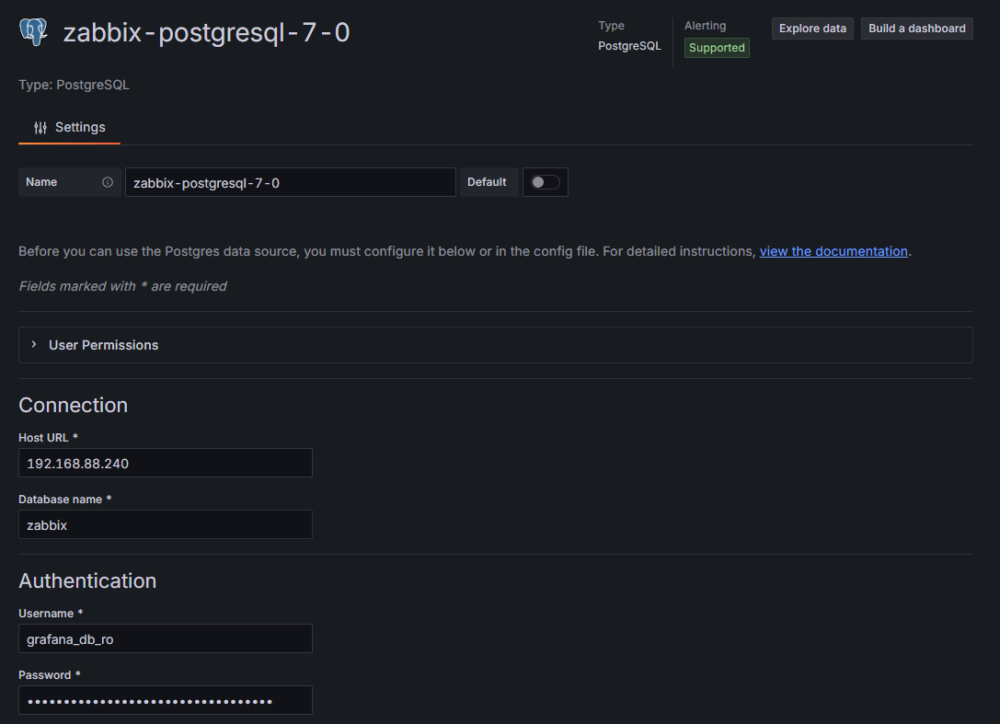
Rysunek 4. Konfiguracja połączenia Grafany z bazą danych PostgreSQL cz. 1
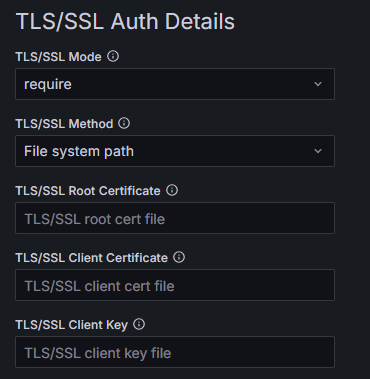
Jeśli jednak chcesz podnieść poziom bezpieczeństwa, możesz wybrać:
Po wybraniu wyższego poziomu niż require musisz podać certyfikat CA (Root Certificate), oraz certyfikat i klucz klienta (odpowiednio Client Certificate oraz Client Key). Masz dwie metody określenia certyfikatów:
Więcej szczegółów znajdziesz w >oficjalnej dokumentacji PostgreSQL, a w szczególności – znajdującą się tam tabelę “SSL Mode Descriptions”.
W naszym przykładzie zakładamy, że jesteśmy pewni, że za podanym adresem IP stoi baza danych dla Zabbixa i nikt nigdy nie będzie próbował się podszyć pod nią, więc zostawiamy require.
Rysunek 5. Konfiguracja połączenia Grafany z bazą danych PostgreSQL cz. 2
Dlatego w naszym przykładzie zmniejszamy tę wartość do 10 minut (600 sekund). Dzięki temu baza danych nie będzie utrzymywać niepotrzebnych, bezczynnych połączeń przez długi czas, a zasoby zostaną szybciej zwolnione.
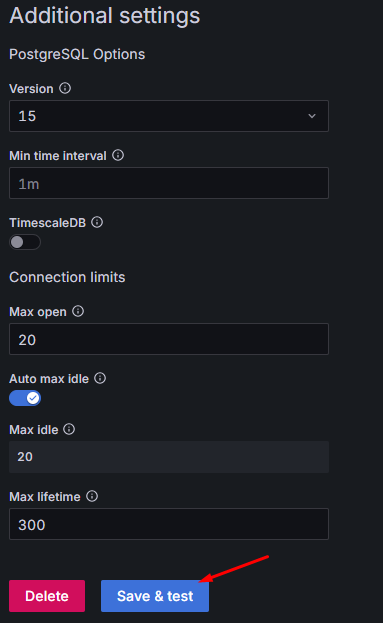
Rysunek 6. Konfiguracja połączenia Grafany z bazą danych PostgreSQL cz. 3
Po wprowadzeniu wszystkich danych klikamy “Save & test”.
Jeżeli wszystko jest skonfigurowane poprawnie, Grafana wyświetli komunikat potwierdzający udane połączenie:
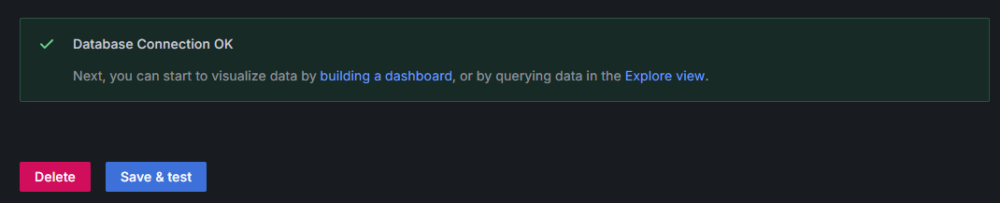
Rysunek 7. Sukces połączenia z bazą danych Zabbix.
Aby zweryfikować, czy połączenie działa poprawnie, otwórz sekcję Explore i sprawdź, czy Grafana prawidłowo pobiera dane z bazy Zabbixa (np. poprzez wyświetlenie przykładowych wartości znajdujących się w tabelach). Opcję tę znajdziesz w menu po lewej stronie:
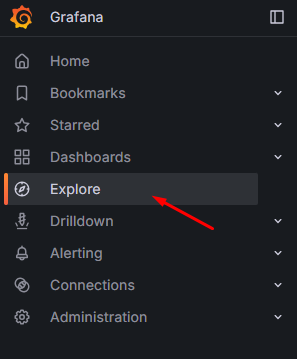
Rysunek 8. Wejście w zakładkę “Explore”
Upewnij się, że jako źródło danych wybrane jest wcześniej skonfigurowane połączenie „zabbix-postgresql-7-0”. Po jego wybraniu pojawi się tzw. kreator zapytań, w którym możesz wskazywać tabele, kolumny, dodawać filtry itp. – wszystko z poziomu list rozwijanych:
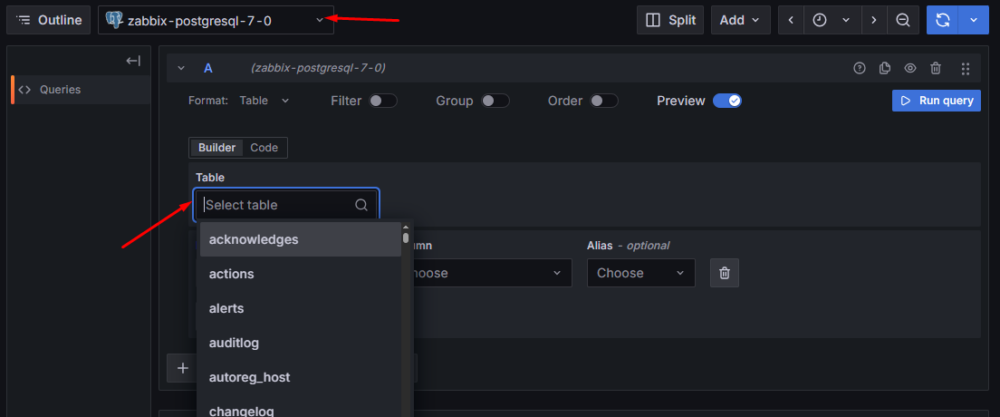
Rysunek 9. Zakładka “Explore” – kreator zapytań
Jeżeli jednak wolisz pisać zapytania samodzielnie, możesz przełączyć się na klasyczny edytor SQL. W tym celu kliknij przycisk “Code”, znajdujący się nad kreatorem:
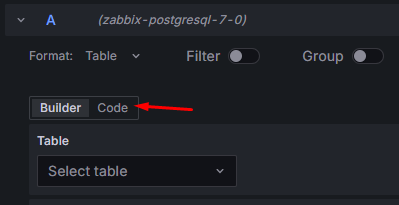
Rysunek 10. Zakładka “Explore” – zmiana na zwykły edytor
Wprowadźmy teraz proste zapytanie, które zwróci liczbę wszystkich hostów w systemie:
SELECT COUNT(*) FROM hosts WHERE status IN (0,1) AND flags IN (0,4); |
Po kliknięciu “Run query” powinniśmy otrzymać liczbę hostów widocznych w naszym środowisku:
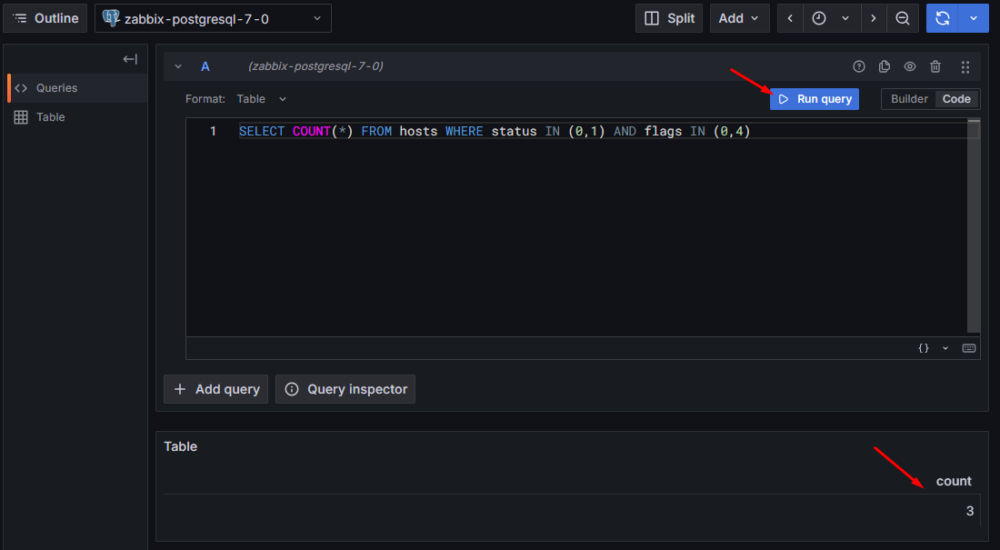
Rysunek 11. Zakładka “Explore” – uruchomienie zapytania i potwierdzenie działania
Przejdźmy teraz do GUI Zabbix i otwórzmy zakładkę “Reports” – “System information”. Możesz zauważyć, że liczba hostów zgadza się z tą, którą zwróciła Grafana – czyli wszystko działa prawidłowo i dane są spójne!
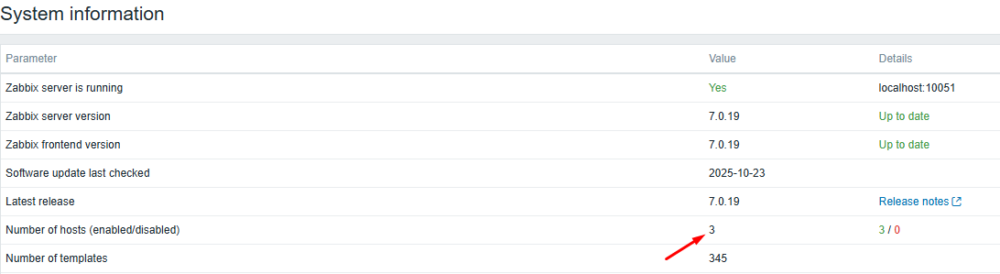
Rysunek 12. Zabbix GUI – System information – potwierdzenie działania.
Aby w praktyce przedstawić przykłady wykorzystania zapytań SQL do bazy PostgreSQL Zabbixa, utwórzmy nowy dashboard o nazwie “Przykładowy dashboard 2”:
Rysunek 13. Ustawienia nowego dashboardu “Przykładowy dashboard 2”
Jeżeli nie wiesz gdzie tworzy się nowy dashboard lub panel, odsyłam Cię do >poprzedniego artykułu, gdzie zostały wyjaśnione podstawowe czynności krok po kroku.
Pierwszy panel będzie przedstawiał liczbę wystąpień każdego użytkownika w logach audytu z wybranego okresu. Dzięki temu możemy wychwycić sytuacje potencjalnie niepożądane, takie jak:
Uwaga: przykład został celowo uproszczony, by skupić się na konfiguracji zapytania w Grafanie, a nie na samym SQL-u. Po zapoznaniu się z artykułem możesz przygotować bardziej zaawansowane zapytania, np.:
„Podlicz wszystkie wpisy w auditlog dla akcji ‘Failed login’, aby wykrywać próby nieautoryzowanego dostępu do środowiska Zabbix”.
W tym celu utwórz nowy panel, w sekcji Queries (na dole strony) ustaw źródło danych na wcześniej skonfigurowane zabbix-postgresql-7-0, a następnie przełącz widok z kreatora zapytań na kod SQL, klikając przycisk Code:
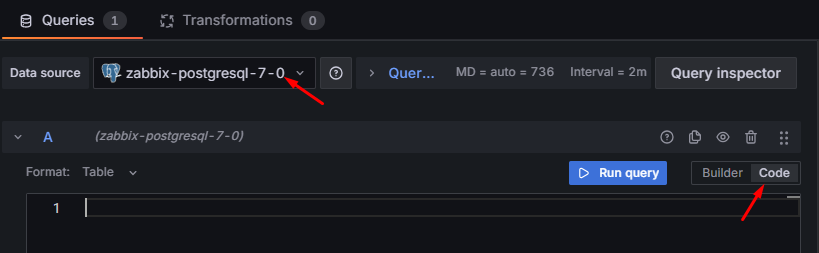
Rysunek 14. Ustawienia zapytania oraz przełączenie na widok wpisywania kodu
Wpisujemy poniższe zapytanie:
SELECT |
Zatrzymajmy się na chwile i przeanalizujmy powyższe zapytanie krok po kroku:
SELECT username AS "użytkownik", COUNT(*) AS "suma" |
Pobiera nazwę użytkownika i zlicza liczbę wszystkich jego wpisów w logach audytu. Alias AS “suma” nadaje kolumnie bardziej czytelny nagłówek w Grafanie.
FROM auditlog |
Wskazuje źródłową tabelę — w Zabbixie tabela auditlog przechowuje informacje o wszystkich akcjach użytkowników (dane z zakładki “Reports” – “Auditlog”).
WHERE $__unixEpochFilter(clock) |
To wbudowana zmienna Grafany — automatycznie ogranicza dane do przedziału czasu wybranego na panelu. Grafana w tle podmienia ją na coś w rodzaju:
WHERE clock BETWEEN 1730000000 AND 1730086400 |
co odpowiada dokładnie zakresowi czasu ustawionemu przez użytkownika na dashboardzie w Grafanie.
GROUP BY username |
Grupuje dane po użytkowniku, aby można było policzyć liczbę akcji przypisaną do każdej osoby.
ORDER BY "suma" DESC |
Sortuje wynik od najbardziej aktywnego użytkownika do najmniej aktywnego.
Zmień teraz typ wizualizacji na Table, a po prawej stronie nadaj odpowiedni tytuł i opis panelu:
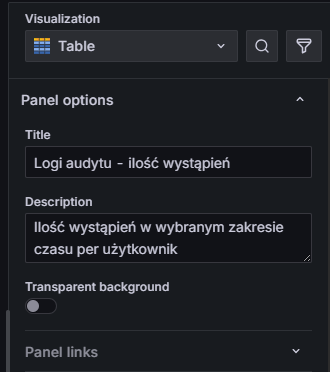
Rysunek 15. Ustawienia panelu – typ “Table” wraz z nazwą i opisem
Klikamy teraz na przycisk “Run query” by wykonać zapytanie. Po chwili będziemy mogli zobaczyć wynik w formie tabeli. Zwróć szczególną uwagę na wybrany czas – aktualnie są to dane z ostatnich 24h:
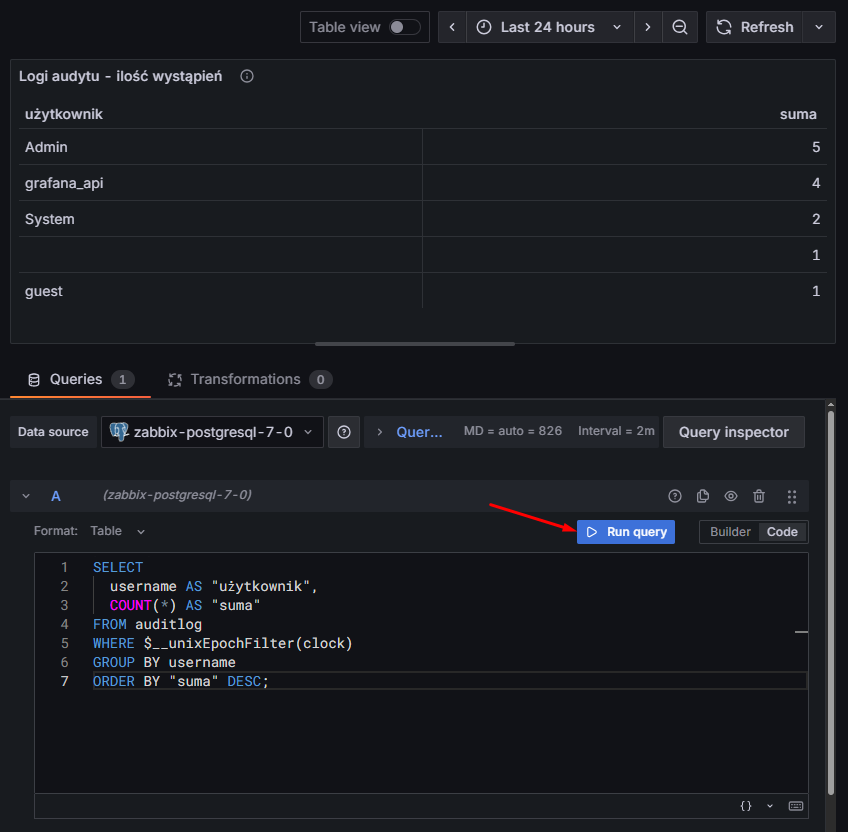
Rysunek 16. Uruchamianie zapytania i wynik z auditlog z ostatnich 24h
Jeżeli teraz zmienimy zakres czasu (np. na ostatnie 7 dni), to dane automatycznie zostaną przeliczone zgodnie z zakresem:
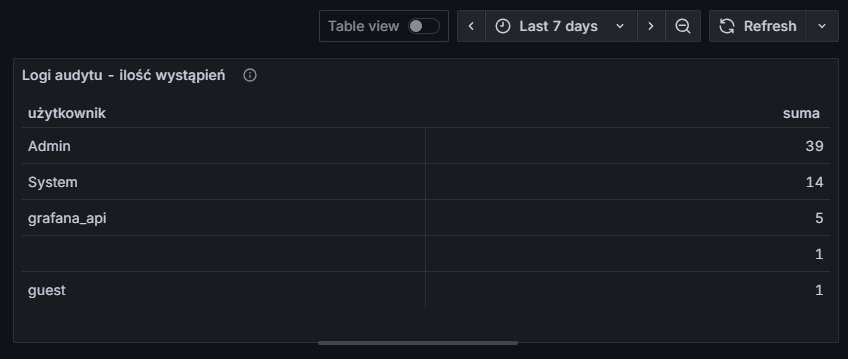
Rysunek 17. Wynik z auditlog z ostatnich 7 dni
Wyjdź z edycji dashboardu i nie zapomnij o jego zapisaniu.
A może jesteś już ekspertem od Grafany i SQL-a, i ten przykład był dla Ciebie zbyt prosty?
W takim razie przejdźmy do czegoś bardziej zaawansowanego.
Tym razem przejdźmy do trudniejszego scenariusza. Chcemy sprawdzić ciągłość działania monitoringu konkretnej pozycji z ostatnich 24 godzin – czyli sprawdzić, czy w tym czasie wystąpiły tzw. dziury w danych.
Czym jest „dziura” w monitoringu? Przyjmijmy następującą definicję:
Dziura występuje wtedy, gdy odstęp pomiędzy kolejnymi pomiarami danej pozycji przekracza jej interwał sprawdzania + 5 sekund.
Przykładowo:
jeśli pozycja ma interwał ustawiony na 1m (1 minuta), to dziurę wykrywamy, gdy pomiędzy kolejnymi pomiarami upłynęło ponad 65 sekund.
Dlaczego dodajemy bufor 5 sekund? Czasami może zdarzyć się, że powyższa pozycja zapisze dane z niewielkim opóźnieniem – np. po 61 sekundach – i nie oznacza to żadnego problemu. Aby uniknąć fałszywych alarmów (false positive), stosujemy więc stały bufor 5 sekund.Nie stosujemy bufora procentowego, ponieważ przy długich interwałach taki procentowy margines mógłby dać zbyt duży czas, nieadekwatny do rzeczywistego opóźnienia.
Aby nie komplikować już i tak dość złożonego zapytania (to jeden z tych przypadków, które brzmią prosto „na papierze”, ale trudniej je odwzorować w SQL-u), przyjmijmy kilka praktycznych założeń:
| Typ informacji | Nazwa tabeli |
| Liczba całkowita bez znaku | history_uint |
| Liczba zmiennoprzecinkowa | history |
| Znak | history_str |
| Tekst | history_text |
| Log | history_log |
| Dane binarne | history_bin |
„Zgłaszam autora na policję, bo ustawiłem 30 dni i moja baza się zawiesiła.”
Zakres 24 godzin to bezpieczny kompromis.
Zanim przejdziemy do właściwej konfiguracji w Grafanie, musimy przeanalizować jeszcze jeden przypadek.
Wyobraźmy sobie, że pozycja ma interwał odpytywania co 4 godziny. Analizujemy ostatnie 24 godziny i wykrywamy jedną dziurę — pozycja nie zebrała się 8 godzin temu.
Na wykresie taka sytuacja mogłaby wyglądać następująco:
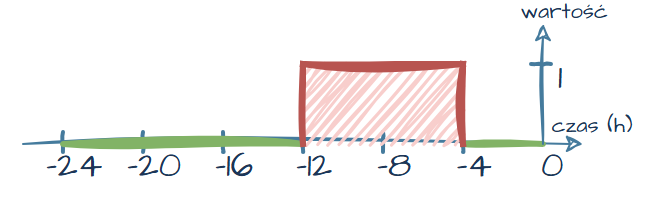
Rysunek 18. Wizualizacja przykładowej „dziury” w ciągłości pomiarów
Pobrane dane prezentują się następująco (dla czytelności uproszczono kolumnę z czasem):
| Czas (ile godzin temu) | Wartość (czy jest dziura) |
| -24 | 0 |
| -20 | 0 |
| -16 | 0 |
| –12 | 1 |
| -4 | 0 |
| 0 | 0 |
Można zauważyć, że w tabeli dla wartości „8 godzin temu” brakuje danych. To zachowanie jest prawidłowe — Grafana „przeciąga” ostatnią znaną wartość dla brakujących punktów na wykresie.
Ten przykład to scenariusz idealny — mieliśmy szczęście, że punkt „24 godziny temu” znalazł się dokładnie w analizowanym przedziale. W rzeczywistości jednak dane zwykle wyglądają mniej „książkowo”:
| Czas (ile godzin temu) | Wartość (czy jest dziura) |
| -22 | 0 |
| -18 | 0 |
| -14 | 1 |
| -6 | 0 |
| -2 | 0 |
Wtedy nasz wykres wyglądałby następująco:

Rysunek 19. Przykład wykresu z przesunięciem czasowym
W tym przypadku na początku wykresu pojawia się pusty obszar. Dzieje się tak dlatego, że Grafana nie ma wcześniejszej wartości, którą mogłaby „przeciągnąć”. Rysuje więc dane dopiero od pierwszego znanego punktu.
Ktoś mógłby uznać, że to drobiazg — niewielki fragment, którego po prostu „nie ma”. Spójrzmy jednak na inny przypadek:
| Czas (ile godzin temu) | Wartość (czy jest dziura) |
| -10 | 0 |
| -6 | 0 |
| -2 | 1 |
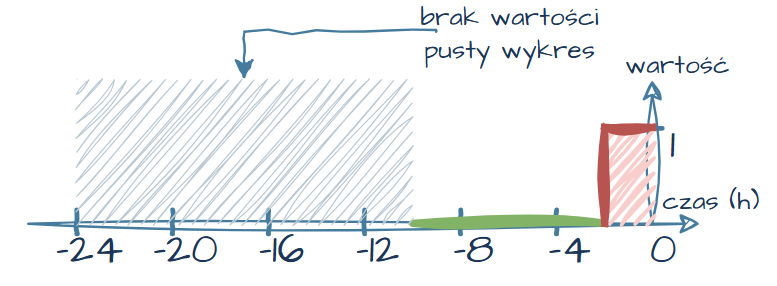
Rysunek 20. Wykres z większym brakiem danych na początku przedziału
Tym razem brak danych na wykresie jest już znacznie bardziej widoczny. Osoba patrząca na taki wykres może błędnie założyć, że po prostu „nie było danych do wyświetlenia, więc na pewno była wtedy dziura”. Ale czy na pewno?
Spójrz jeszcze raz na wykres przedstawiony na Rysunku 19. Skąd możemy wiedzieć, czy zaznaczony na wykresie “brak wartości, pusty wykres” oznacza dziurę? Może dane zostały zebrane bez problemu “26 godzin temu”?
Aby uniknąć takich niejednoznaczności, musimy rozszerzyć zakres wyszukiwania danych o długość interwału danej pozycji. Dzięki temu — nawet jeśli pierwszy punkt znajduje się poza aktualnym 24-godzinnym przedziałem (tylko ten 24-godzinny przedział będzie widoczny) — Grafana będzie mogła „przeciągnąć” jego wartość i zachować ciągłość wykresu.
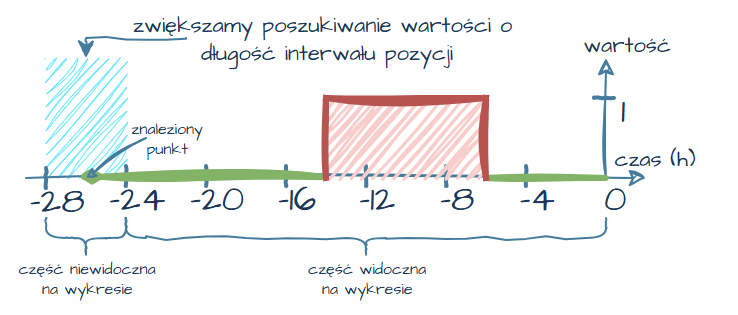
Rysunek 21. Rozszerzenie zakresu wyszukiwania o długość interwału pozycji
Co jednak w sytuacji, gdy nie znajdziemy takiego punktu?
Musimy jeszcze dodać kolejne zabezpieczenie — na samym początku zakresu danych wstawiamy dodatkowy punkt występujący przed wyszukiwanym zakresem czasu z wartością 1, która oznacza wystąpienie „dziury”. Dzięki temu, jeśli w danych faktycznie występuje luka, Grafana „przeciągnie” właśnie tę wartość, co jednoznacznie zasygnalizuje brak pomiarów. Wartość tą będziemy wstawiać zawsze sekundę przed okresem poszukiwania dodatkowego punktu (długość interwału pozycji).
Dzięki temu, jeśli dodatkowy punkt zostanie znaleziony, wykres pozostanie bez zmian (dotyczy to części widocznej na wykresie):

Rysunek 22. Przykład wykresu po dodaniu sztucznego punktu – znaleziony punkt
Jeśli natomiast nie znajdziemy dodatkowego punktu, Grafana przeciągnie wartość 1. Wracając do wykresu z Rysunku 20 — w takiej sytuacji wykres wyglądałby następująco:

Rysunek 23. Przykład wykresu po dodaniu sztucznego punktu – brak punktu
Dzięki temu zabiegowi mamy pewność, że wykres w Grafanie zawsze rozpoczyna się od poprawnej, logicznej wartości — niezależnie od przesunięcia czasowego danych.
Skoro mamy już teorię za sobą, przejdźmy do praktyki.
W tym przykładzie sprawdzimy stabilność pozycji CPU iowait time na hoście zabbix-7-0. Wiemy, że pozycja trzyma dane jako liczba zmiennoprzecinkowa (czyli dane znajdują się w tabeli history), a jej itemID to 42258.
Wróćmy teraz do Grafany i utwórzmy nowy panel. Pamiętaj, aby jako źródło danych wybrać wcześniej skonfigurowany zabbix-postgresql-7-0.
W obszarze zapytania SQL wklej poniższy kod:
SELECT |
Przeanalizujmy nasze zapytanie krok po kroku:
SELECT to_timestamp(h.clock) AS czas |
Zabbix trzyma czas pobrania danej wartości z pozycji (kolumna clock) jako timestamp, jednak Grafana odczytuje tą wartość jako zwykłą wartość liczbową .Dlatego rzutujemy tę wartość przy pomocy to_timestamp, aby Grafana poprawnie ją interpretowała jako czas.
CASE (……) THEN 1 ELSE 0 END AS dziura |
To klasyczna logika warunkowa: jeśli warunek jest spełniony → zwróć 1 (wykryto dziurę), w przeciwnym razie → 0 (ciągłość zachowana). Warunek:
WHEN LEAD(h.clock) OVER (PARTITION BY h.itemid ORDER BY h.clock) - h.clock |
Funkcja LEAD umożliwia odczytanie wartości z następnego wiersza (kolejnego pomiaru) bez konieczności łączenia tabeli z samą sobą. Porównujemy więc czas następnego pomiaru z bieżącym.
> EXTRACT(epoch FROM i.delay::interval) + 5 |
Różnicę porównujemy z interwałem pozycji (delay) przekonwertowanym na sekundy. Dodatkowe +5 to nasz bufor bezpieczeństwa — 5 sekund.
FROM history h JOIN items i ON h.itemid = i.itemid |
Dane pomiarowe pochodzą z tabeli history (dla liczb zmiennoprzecinkowych zgodnie z naszym przykładem). Łączymy je z tabelą items, aby pobrać interwał delay dla danej pozycji — dzięki temu próg jest dynamiczny i nie trzeba go wpisywać ręcznie.
WHERE h.itemid = 42258 |
Filtrujemy dane tylko dla interesującej nas pozycji (w tym przykładzie: 42258).
AND h.clock >= EXTRACT(EPOCH FROM NOW()) - (86400 + EXTRACT(epoch FROM i.delay::interval)) |
Ograniczamy zakres zapytania do ostatnich 24 godzin, ale dodajemy dodatkowy margines równy interwałowi pozycji — to pozwala znaleźć ewentualny punkt sprzed analizowanego okresu.
UNION ALL |
Doklejamy dodatkowe dane do naszego zapytania — UNION ALL zachowuje wszystkie wiersze (bez eliminowania duplikatów).
SELECT NOW() - interval '24 hours' - i.delay::interval - interval '1 second' AS czas, 1 AS dziura FROM items i WHERE i.itemid = 42258 |
Tworzymy sztuczny punkt na wykresie: czas ustawiony na moment 24h + delay + 1s temu (czyli sekundę przed rozpatrywanym okresem czasu) z wartością 1. W tym zapytaniu również musimy odnieść się do tabeli items, skąd musimy pobrać interwał pozycji dla podanego itemid (w naszym przykładzie to 42258).
ORDER by czas; |
Na końcu sortujemy dane rosnąco po czasie — nie jest to niezbędne, ale ułatwia analizę danych.
Po wklejeniu zapytania i dopasowaniu go do swojego środowiska (odpowiednia tabela history_*, itemid), przejdź do Query options i ustaw:
Relative time – 24h — dzięki temu wykres zawsze będzie obejmował dokładnie 24 godziny, niezależnie od ustawień dashboardu.
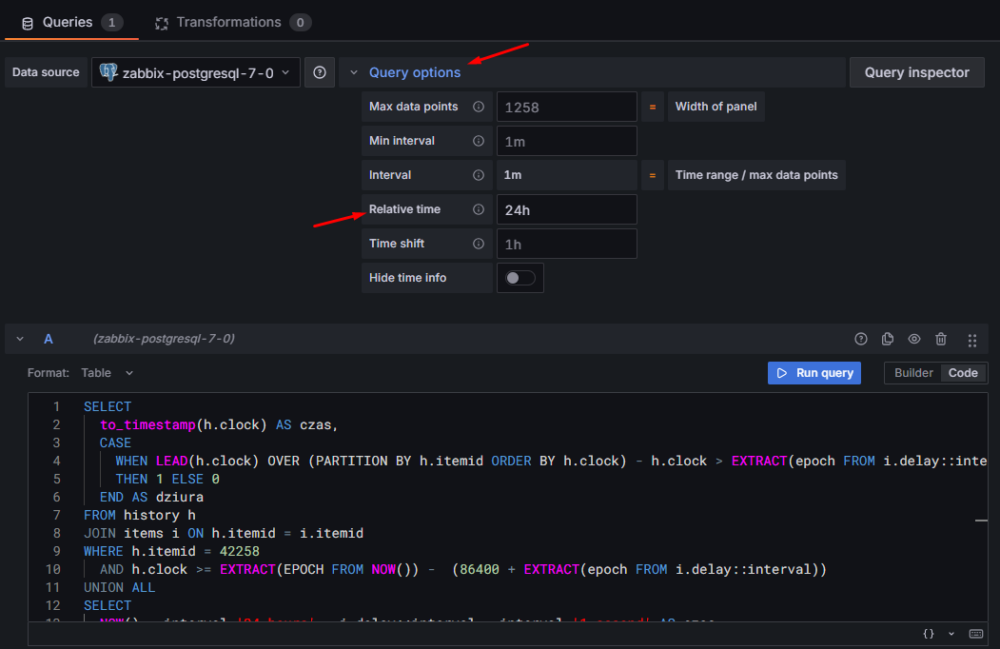
Rysunek 24. Ustawienie szerokości wykresu na wartość 24h
Ostatnim krokiem jest odpowiednie skonfigurowanie sposobu wyświetlania danych. W tym przypadku Autor uważa, że nie ma lepszej wizualizacji niż State timeline — jest czytelna, intuicyjna i idealnie pokazuje przerwy w ciągłości pomiarów. Wybierz więc tę wizualizację z listy po prawej stronie i dostosuj ustawienia według własnych preferencji.
Poniżej kilka opcji, które Autor szczególnie zaleca zmienić:
W tym miejscu definiujemy przedziały i odpowiadające im kolory. Aby uzyskać pożądaną kolorystykę, ustaw je zgodnie z poniższym przykładem:
Rysunek 25. Ustawienie kolorowania wykresu w zależności od wartości
To wszystko!
Możemy wyjść z konfiguracji panelu i zapisać cały dashboard.
Od teraz możemy cieszyć oko nowym, czytelnym panelem — choć wygląda na to, że trzeba będzie sprawdzić, dlaczego nasza pozycja nagle przestała zbierać dane…
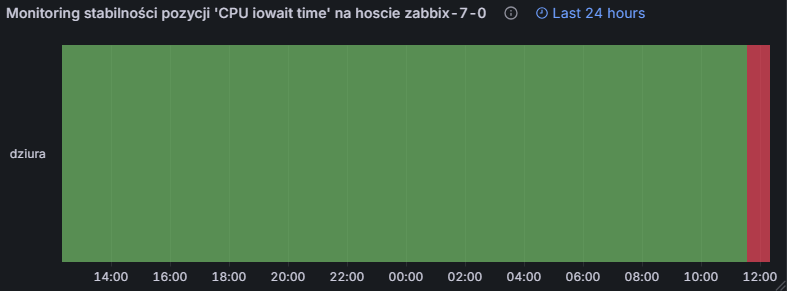
Rysunek 26. Wynik końcowy – wykres stabilności pozycji
Jeżeli gdzieś się pogubiłeś lub nie wiesz dokładnie “gdzie kliknąć”, Autor udostępnia cały “Przykładowy dashboard 2” >do pobrania w formacie JSON. Pamiętaj tylko, by podczas importu wybrać odpowiednie źródło danych, czyli nasze połączenie do bazy danych.
Jednocześnie zapraszamy na nasze nowe duże szkolenie Zabbix Expert z ponad 50% rabatem! Zapisy tutaj: https://zabbix.sekurak.pl
Celem tego artykułu było pokazanie, że integracja Zabbixa z Grafaną to nie tylko oficjalny plugin.
Prędzej czy później większość użytkowników trafia na moment, w którym „czegoś się po prostu nie da” zrobić za pomocą standardowego pluginu. Bezpośrednie połączenie z bazą danych otwiera przed nami znacznie większe możliwości — możemy tworzyć własne zapytania, wykonywać część obliczeń już po stronie silnika bazy, a co najważniejsze — uzyskać dane, których w inny sposób nie dałoby się wyciągnąć.
Na koniec wróćmy do naszej historii z początku artykułu.
Udało Ci się podłączyć Grafanę bezpośrednio do bazy danych. Wiesz już, że w pozycji o kluczu system.users.num przechowywana jest liczba zalogowanych użytkowników, a w polu inventory OS powinien wystąpić ciąg znaków “Ubuntu”. Dlatego za pomocą chatGPT samodzielnie napisałeś następujące zapytanie:
SELECT |
To zapytanie pozwoliło Ci stworzyć elegancką tabelę w Grafanie:
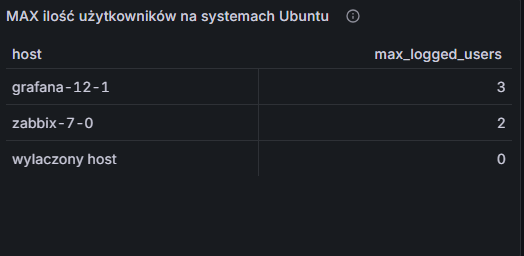
Rysunek 27. Wizualizacja maksymalnej liczbie zalogowanych użytkowników na systemach Ubuntu
Jesteś z siebie zadowolony… dopóki po pewnym czasie nie dostajesz wiadomości z informacją:
“Hej, ta tabelka pokazuje często rzeczy, których nie powinna…”
Jeśli nie domyśliłeś się jeszcze, co poszło nie tak — mimo dość oczywistej podpowiedzi w przykładowych danych — następny artykuł jest właśnie dla Ciebie.
W kolejnej części wyjaśnimy, dlaczego bezpośrednie zapytania SQL do bazy Zabbixa potrafią być zdradliwe i naprawimy powyższy problem “nadmiarowych danych”. Pokażemy też prostszą, bardziej elastyczną alternatywę — własne zapytania API, które pozwalają na wydobywanie tych samych danych bez konieczności „grzebania” w bazie.
Już teraz Autor zaprasza do kolejnego artykułu, jeżeli jednak artykuł otworzył Ci nowe możliwości prezentacji danych to pomyśl o wsparciu autora >dobrą kawką!
~ Albert Przybylski, zawodowo: Architekt ds. Monitoringu w firmie Aplitt, prywatnie: pełnoprawny fanatyk Zabbixa zasilany kawą
