Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Netflow, firewalle i segmentacja bez zgadywania

Od pewnego czasu na łamach sekuraka pojawia się coraz więcej informacji łączących bezpieczeństwo IT oraz sztuczną inteligencję (najczęściej mowa o generatywnej SI, a dokładniej dużych modelach językowych). Boom, a właściwie bańka AI zdaje się rosnąć w zatrważającym tempie. Jednak patrząc na rzeczywiste zdolności modeli w działaniach ofensywnych – jak na razie nam nie imponują. I o ile w naszej branży, najnowsze modele zintegrowane z narzędziami, stają się wygodnym sposobem na realizację mniej wymagających zadań, o tyle mogą stać się realnym mechanizmem automatyzacji ataków dla scriptkiddies i przestępców. Informację o wykrytej kampanii cybeprzestępczej o charakterze szpiegowskim (co jest oczywiste przy takiej atrybucji) podała firma Anthropic, udostępniająca asystenta AI – Claude.
Produkt tej firmy o nazwie Claude Code – to programistyczny asystent w wersji CLI. Pozwala na integrację modelu językowego ze środowiskiem programistycznym, a szerzej z szeregiem narzędzi programistycznych. Integrację wspomaga fakt implementacji standardu MCP, który pozwala rozszerzyć możliwości asystenta o dostęp do zewnętrznych systemów, zasobów (np. baz danych) i narzędzi – jak wiersz poleceń.
Według informacji, które dostarczył Anthropic, w połowie września 2025, miało dojść do wysoce zaawansowanego ataku – operacji wywiadowczej, przeprowadzonej przez grupę ludzi, którzy zostali zidentyfikowani jako działający na rzecz (i sponsorowani) przez Chiny. Nie jest absolutnie nowością fakt, że podobne grupy cyberprzestępców, wykonują różne zadania w cyberprzestrzeni, służące interesowi Chińskiej Republiki Ludowej. W totalnym bałaganie nomenklaturowym, również Anthropic musiał wprowadzić swoje własne oznaczenie (obrazek XKCD o standardach jest aktualny również w nazewnictwie grup APT) – adwersarz został określony kodem GTG-1002 (chociaż musimy pochwalić za beznamiętny wydźwięk tego oznaczenia – atakowanie systemów obcego państwa pod szyldem gwałtownego zjawiska pogodowego lub dzikiego zwierzęcia może dużo lepiej wpływać na samopoczucie napastników). Niestety brak usystematyzowanej konwencji nazewniczej oraz forma raportu (o tym dalej) nie pozwala skorelować tej grupy z innymi APT skatalogowanymi przez inne firmy zajmujące się bezpieczeństwem.
W odpowiedzi na incydent, Anthropic zablokował działania atakujących i zbanował konta powiązane z nielegalną działalnością. Na podstawie zebranych informacji, część ofiar została powiadomiona o incydencie. A ponieważ dowody, którymi dysponuje dostawca Claude mogły zostać wykorzystane do podjęcia kroków prawnych – zawiadomione zostały również organy państwowe, co jest standardową praktyką w tego typu incydentach. Zwłaszcza jeśli chodzi o działania prowadzone przez kraj otwarcie rywalizujący z USA na wielu płaszczyznach technologicznych (i na tym stwierdzeniu zakończymy opis geopolityczny – nie ukończyliśmy dziesięciominutowego szkolenia z geopolityki na Uniwersytecie Youtube oraz nie mamy czasu na czytanie pięciu losowych nagłówków z gazet, dlatego po opinię ekspertów kierujemy na X’a).
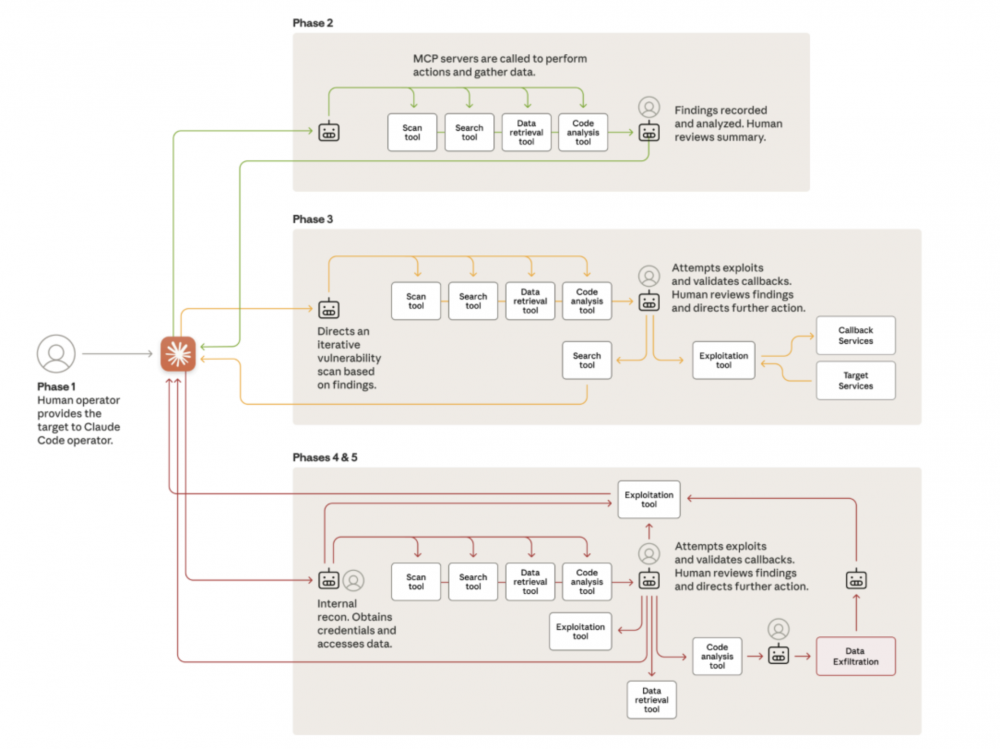
W kampanii realizowanej przy pomocy Claude Code próbowano zaatakować około 30 organizacji. W realizacji operacji wykorzystano wiele agentowych systemów, które miały być nadzorowane przez człowieka. Agenty były programowane do przeprowadzenia wszystkich etapów ataku, co można określić pełnym przejściem cyber kill chain. Powierzone zadania miały być realizowane w sposób autonomiczny i równoległy przez wiele instancji agentów. Dużą zaletą tak zorganizowanego ataku, jest wysoka szybkość realizacji poszczególnych zadań. Co warto zauważyć (i to akurat – w przypadku osiągnięcia przez lokalne modele podobnej skuteczności może być przydatny use case podczas prowadzenia operacji red team) – analiza pozyskanych informacji również była przeprowadzana w sposób zautomatyzowany. Zaangażowanie człowieka, oceniane jest od 10% do 20% całej pracy wymaganej do przeprowadzenia kampanii. Białkowi operatorzy mieli się skupiać głównie na podejmowaniu kluczowych decyzji, wyciąganiu wniosków z szerszego obrazu sytuacyjnego oraz akceptowaniu (i pewnie korygowaniu) następnych kroków podejmowanych przez agenty.
Pierwszym krokiem cyberprzestępców było nakłonienie modelu do wykonania czynności, które mogły aktywować mechanizmy bezpieczeństwa modelu – w tym celu konieczny był tzw. jailbreak, czyli obejście zabezpieczeń modelu, np. przez takie sformułowanie promptu, aby LLM wygenerował odpowiedź zgodną z oczekiwaniami użytkownika ale niezgodną z wewnętrznymi politykami (bo np. niebezpieczną). Jailbreak taki często przypomina (chociaż nie zawsze) przeprowadzenie ataku. Tutaj dochodzimy do pierwszego zgrzytu, który powoduje, że mamy wrażenie iż przedstawiony materiał jest raczej opisem stworzonym przez departament PR/marketingu niż zespół threat intelligence.
“At this point they had to convince Claude—which is extensively trained to avoid
harmful behaviors—to engage in the attack.”
Wykorzystując LLMy (w tym omawiany Claude) do codziennych zadań związanych z bezpieczeństwem (np. do wygenerowania podstawowych harnessów dla fuzzerów czy rozwiązania trywialnych zadań CTF) niejednokrotnie udało nam się skłonić model do wykonania legalnego działania, które początkowo były odrzucane jako potencjalnie szkodliwe i niebezpieczne. Pytanie jakie się nasuwa (bo bez dostarczonych szczegółów, technik przeprowadzonych ataków) jako pierwsze – to czy atakujący rzeczywiście musieli się natrudzić już w pierwszej fazie ataku aby wykorzystać model do działań potencjalnie nielegalnych. Patrząc na zbiory jailbreaków różnych publicznie dostępnych modeli – trudność tego kroku budzi nasze wątpliwości.
W kolejnym kroku model miał dokonać aktywnego rekonesansu przez zestaw połączonych serwerów MCP dostarczających funkcjonalności takich jak skanowanie portów (i identyfikacja usług). Znów – jesteśmy sobie w stanie wyobrazić całkiem złożony system orkiestrowany przez LLM, który jednak nie jest technologią rakietową. Rozbudowane systemy mapowania powierzchni ataku, lub wręcz przeprowadzania aktywnego i pasywnego rekonesansu z wykorzystaniem pętli zwrotnej są w użytku pentesterów od lat (pierwszy przykład z brzegu – autorecon).
W kolejnym kroku, modele LLM identyfikowały potencjalne cele ataku oraz ścieżki wykorzystania podatności. W odpowiedzi operator akceptował rekomendacje zwrócone przez model, dając zielone światło do wykonania ataku. Na docenienie zasługuje fakt automatyzacji przeglądarki internetowej przez MCP.
Co warto podkreślić – następujące po sobie kroki wynikały z zależności przyczynowo skutkowej. Jeśli atakujący, uzyskiwał dostęp do systemu takiego jak baza danych, to instruował model do wyciągnięcia potrzebnych informacji – np. nazw użytkowników i hashy haseł. W następnej iteracji agent mógł spróbować uruchomić oprogramowanie do łamania kryptograficznych skrótów haseł. Jeśli te działania zakończyły się powodzeniem, agenty mogły próbować wykorzystać np. wystawione na świat porty RPD do uzyskania zalogowanej sesji użytkownika i kradzieży danych Niestety przedstawiony opis skupia się jedynie na “autonomii” i “automatyzacji” oraz małym udziale człowieka. Narzędzia pozwalające na zautomatyzowane pozyskiwanie danych z systemów np. bazodanowych nie są nowością ;) a podpięcie ich pod MCP nie stanowi szczególnej trudności. Udało nam się przetestować taką integrację z lokalnym modelem i musimy powiedzieć, że najprostsze maszyny na HTB mogą się bać :) (za to dużo prościej takie zadania realizuje się ręcznie).
Pozyskane w ten sposób dane były przetwarzane przez model w celu zdobycia wartościowych informacji takich jak poświadczenia czy struktury baz danych. Agenty były też instruowane do pozostawienia kont (np. w bazach danych), które mogły posłużyć do późniejszego dostępu (tzw. backdoory). Jak stwierdzają autorzy raportu, problematyczny dla operatorów był fakt halucynacji modelu, które wymagały interwencji człowieka.
Infrastruktura zarządzana przez Claude Code (agenturalna? :P) do przeprowadzenia ataku wykorzystywała w głównej mierze otwartoźródłowe narzędzia do przeprowadzania testów bezpieczeństwa. Ich integracja przebiegała z wykorzystaniem koncepcji MCP, co pozwoliło ujednolicić i uprościć sposób wykonywania poleceń przez model językowy. Przestępcy skupili się na stworzeniu frameworka, który zintegrował i połączył narzędzia w taki sposób, aby wyniki i analiza każdego etapu ataku, mogła być wykorzystana do przeprowadzenia kolejnego.
Firma zareagowała prawidłowo, blokując dostęp atakujących do infrastruktury oraz przeprowadziła śledztwo mające na celu zbadanie metod ich działania. Na ten moment za wyjątkiem wielokrotnie powtarzanych fraz o skomplikowaniu kampanii, nowatorskich metod ataku oraz podkreślających proces automatyzacji, próżno jest w “raporcie” szukać konkretnych taktyk, technik i procedur wykorzystywanych przez atakującego. Informacja o tym, że w głównej mierze wykorzystywane były otwartoźródłowe narzędzia, które i tak służą do automatyzacji, a model zajmował się głównie przetwarzaniem wyników, ich analizowaniem i składaniem propozycji co do dalszych kroków – które to dalsze kroki były następnie weryfikowane przez atakujących i korygowane, może sugerować fakt, że sam atak nie był zbyt skomplikowany – w znaczeniu zastosowania wysublimowanych technik ataku.
Zdecydowanie zgadzamy się z twierdzeniem, że dostęp do takich narzędzi obniża trochę próg wejścia mniej doświadczonym graczom na arenie grup cyberprzestępczych. Z drugiej strony stworzenie frameworka pozwalającego na integrację wielu narzędzi bezpieczeństwa, ciągły nadzór nad agentami oraz korygowanie wyników działań wciąż wymaga rozbudowanej wiedzy technicznej nie tylko z zakresu znajomości narzędzi CLI czy programowania ale też bezpieczeństwa i ograniczeń usług oferowanych przez duże modele językowe. Zaprezentowany raport nie prezentuje żadnych dowodów, legitymizujących “zaawansowanie” ataku i momentami przypomina raczej materiał marketingowy, mający na celu pokazanie skuteczności modelu w zastosowaniach z zakresu ofensywnych testów bezpieczeństwa. Anthropic podkreśla konieczność zastosowania AI w defensywnym bezpieczeństwie. I oczywiście jesteśmy świadomi, że pewien proces automatyzacji z wykorzystaniem szeroko pojętej sztucznej inteligencji oraz algorytmów uczenia maszynowego poprawi krajobraz bezpieczeństwa wielu organizacji. Z drugiej strony należy pamiętać o zagrożeniach płynących z tego typu narzędzi. Sam fakt, że Anthropic wykrył ofensywne wykorzystanie swojego modelu (i zdobył dane, które mogły być przedstawione organom ścigania) powinien dać do myślenia osobom, które chciałyby wykorzystać tego typu rozwiązania do przeprowadzania legalnych testów bezpieczeństwa – mogłoby tutaj dojść do złamania między innymi umów NDA i przetwarzania danych klientów na infrastrukturze, co do której bezpieczeństwa testerzy nie dysponują odpowiednią wiedzą.
To samo tyczy się defensywnego wykorzystania AI, które nie jest modelem lokalnym (a nawet wtedy, rozwiązania oparte o LLMy poszerzają w pewien sposób spektrum ataku). Dlatego do tego typu rewelacji (zwłaszcza w kontekście pompowania balonika AI) należy podchodzić z dużą dozą rozsądku i dystansu. Mamy nadzieję, że firma dążąc do przejrzystej komunikacji ujawni dokładne szczegóły ataku, zastosowane taktyki, techniki i procedury. Dopiero wtedy będziemy mogli stwierdzić jak bardzo był to proces zautomatyzowany i autonomiczny. A na ile automatyzował to, co było już dawno zautomatyzowane, tylko poprawił wyniki dzięki dysponowaniem kontekstem. Jak na razie, widzimy duży stopień automatyzacji w tworzeniu raportów :)
~Black Hat Logan

Bardzo ciekawy artykuł, jedyny fragment, który mnie zdziwił: “Boom, a właściwie bańka AI zdaje się rosnąć w zatrważającym tempie. “. Dlaczego “bańka AI”? Patrząc po wynikach firm, wycenach spółek, które nie odbiegają drastycznie od długoletnich średnich, rozwoju i implementacji rozwiązań w wielu branżach. Mówienie o bańce w sytuacji gdy spółki nie odrywają się od wycen i fundamentów to nie bańka – a dynamiczny wzrost. Bańka jest jak wyceny spółek rosną bez wzrostu innych fundamentalnych wskaźników np. przychodów, marży, dochodów etc. A raporty wprost pokazują, że za wzrostem ceny, idą wzrosty przychodów etc…. Nie wiem dlaczego niby bańka, poza tym, że ludzie powtarzają ten frazes, dla samego powtarzania. Ja to odebrałem jako bańka w rozumieniu finansowym, ale może chodzi o coś innego autorowi.