Ten tekst został przygotowany dla Zabbix 7.0 oraz Grafana 12.1.
Wstęp
W poprzednim >artykule udało nam się stworzyć dwa nieoczywiste, ale w miarę łatwe do przygotowania wykresy. Dzisiaj weźmiemy na warsztat trochę bardziej skomplikowane przykłady, wykorzystujące transformację oraz funkcje zapytań.
Jednocześnie zapraszamy na nasze nowe duże szkolenie Zabbix Expert z 50% rabatem! Zapisy tutaj: https://zabbix.sekurak.pl/
Zaczynamy!
Ten artykuł to część serii przybliżającej integrację Grafany oraz Zabbixa przygotowanej przez Alberta Przybylskiego. Zachęcamy do zapoznania się ze wszystkimi tekstami dotyczącymi tego zagadnienia!
Na początek przypomnijmy sobie testowe środowisko:
Rysunek 1. Środowisko testowe wraz z oznaczoną komunikacją.
Warto też przypomnieć założenia przy tworzeniu kolejnych paneli:
Nazwy hostów w Zabbix są zgodne z tymi skonfigurowanymi w systemie operacyjnym,
Obydwa hosty należą do grupy “Linux servers”,
Host “zabbix-7-0” jest dodatkowo w grupie “Zabbix servers”,
Oba hosty korzystają z domyślnego szablonu “Linux by Zabbix agent” – przykłady dalej będziemy opierać właśnie na tych danych.
Serwer zabbix-7-0 posiada 2 CPU, natomiast serwer grafana-12-1 – 1 CPU.
każdy serwer posiada pojedynczy interfejs sieciowy.
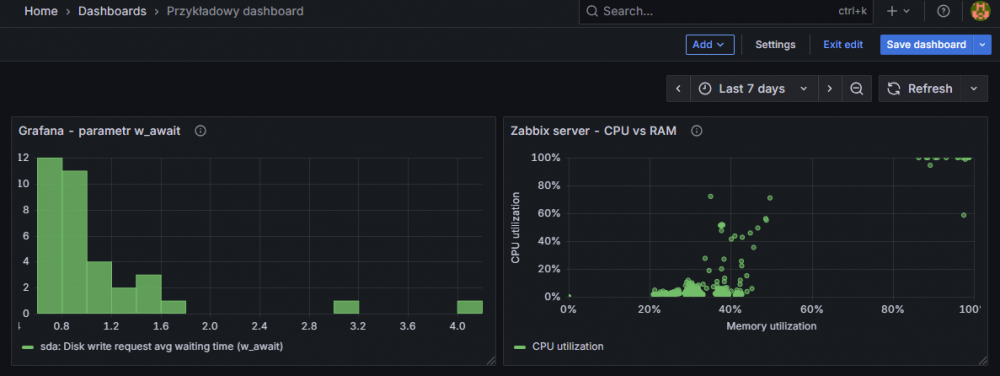
W poprzednim artykule stworzyliśmy dashboard o nazwie “Przykładowy dashboard”, gdzie stworzyliśmy histogram oraz wykres punktowy:
Rysunek 2. Wygląd dashboardu z poprzedniego artykułu.
Wykres osi czasu
W tym punkcie stworzymy wykres pokazujący stan systemu w zależności od czasu (ang. state timeline). Skupimy się na parametrach CPU Load na serwerze. Zamiast zwykłego wykresu liniowego chcemy zobaczyć, kiedy obciążenie było w normie, a kiedy przekraczało dopuszczalne wartości.
Poniżej znajduje się lista pozycji związanych z LOAD w Zabbix, które będziemy wykorzystywać:
Rysunek 3. Lista pozycji CPU LOAD w Zabbix.
Wróćmy jednak do teorii – srednie obciążenie (ang. load average) podawane jest w postaci trzech wartości:
z ostatniej 1 minuty,
z ostatnich 5 minut,
z ostatnich 15 minut.
Aby prawidłowo je ocenić, trzeba porównać te liczby z liczbą dostępnych jednostek obliczeniowych (rdzeni). Najprostsza zasada jest taka: load average powinno być mniejsze od liczby rdzeni.
Wynika to z faktu, że load average reprezentuje średnią liczbę procesów gotowych do uruchomienia (lub oczekujących na I/O). Jeśli jej wartość przez dłuższy czas znacząco przekracza liczbę rdzeni, może to oznaczać, że system ma więcej zadań do wykonania, niż jest w stanie obsłużyć równolegle.
W Grafanie odwzorujemy to w prosty sposób:
Jeśli wartość jest mniejsza – system działa prawidłowo (oznaczymy to kolorem zielonym).
Jeśli jest większa – oznacza to przeciążenie (oznaczymy kolorem czerwonym).
Aby to osiągnąć, tworzymy nowy panel na naszym dashboardzie. Upewniamy się, że źródłem danych jest skonfigurowany wcześniej Zabbix, i uzupełniamy następujące pola w zapytaniu:
Query type – wybieramy “metrics” (wyświetlamy dane liczbowe),
Group – grupa hostów, do której należą obydwa serwery, w naszym przykładzie “Linux servers”,
Host – nazwa hosta – “zabbix-7-0”,
Item tag – nie jest wymagany, więc zostawiamy pusty,
Item – tym razem chcemy pobrać trzy metryki na raz, więc znowu wykorzystamy wyrażenie regularne: /Load average .*/ Oznacza ono nazwy pozycji zaczynające się od „Load average ” (razem ze spacją). Składnia jest uproszczona, ale jeśli chcesz, możesz użyć bardziej restrykcyjnej składni, np.: np. /^Load average \((?:1m|5m|15m) avg\)$/
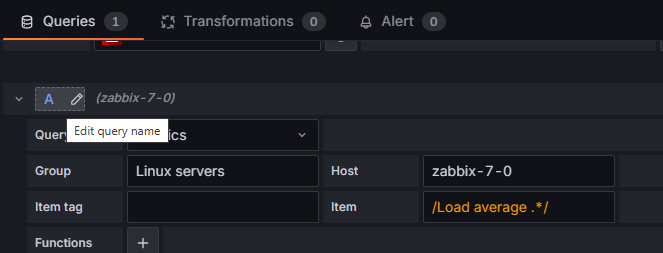
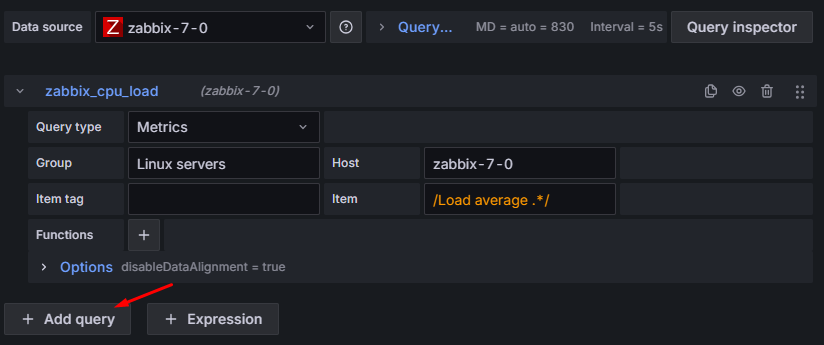
Dla porządku nazwijmy też nasze zapytanie. Klikamy na niebieskie „A” przy zapytaniu (aktualnie jego nazwa to domyślne „A”) i nadajmy mu czytelną nazwę, np. “zabbix_cpu_load”.
Rysunek 4. Zmiana nazwy zapytania.
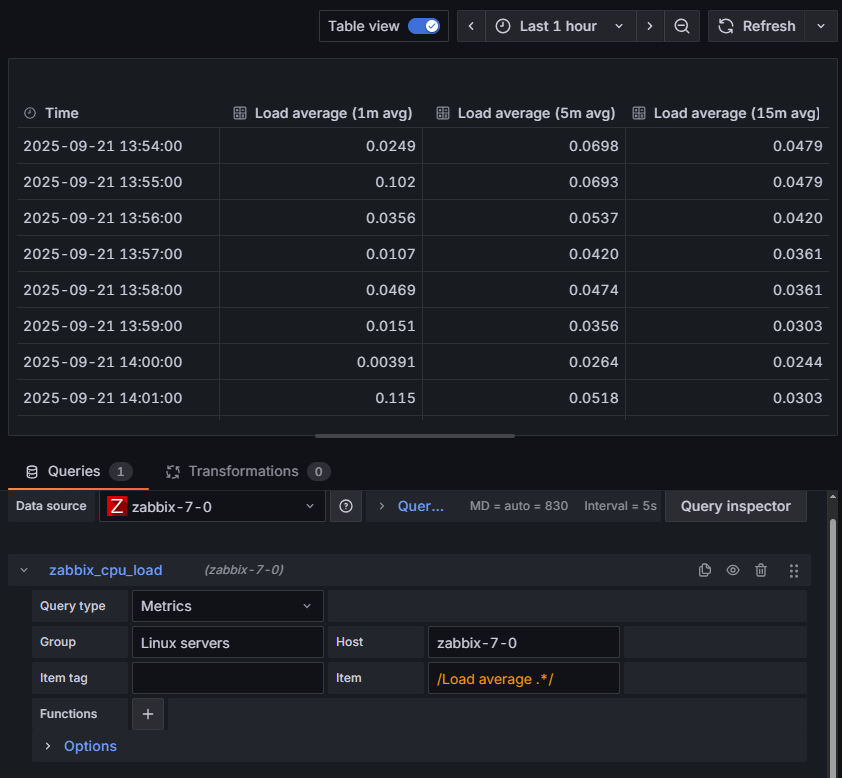
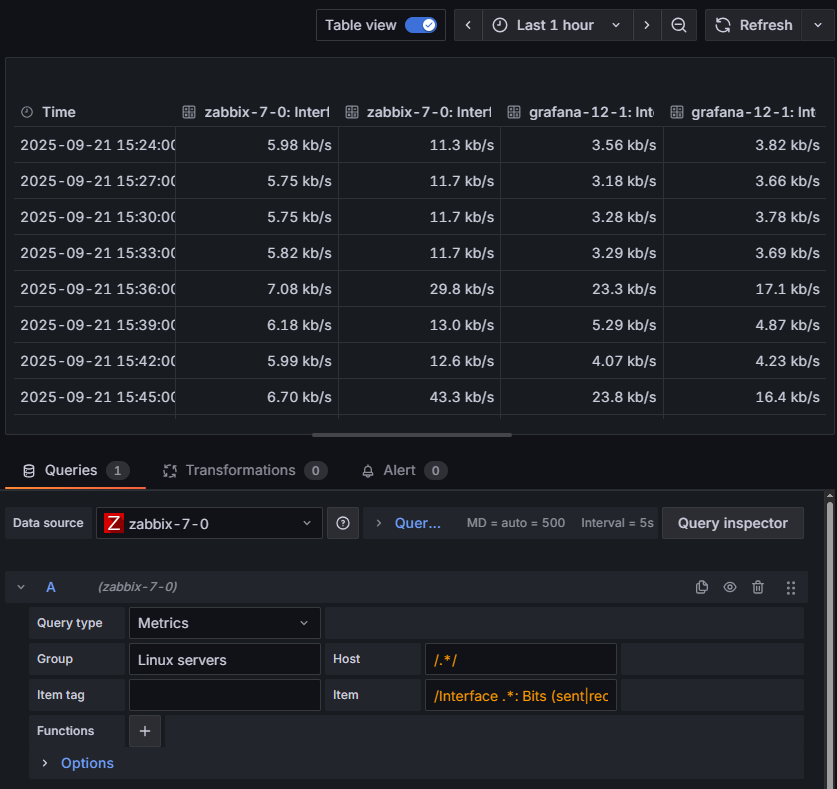
Całość konfiguracji wraz z przykładowymi danymi (w trybie “Table view”) przedstawiono poniżej:
Rysunek 5. Ustawienia pobierania danych na temat CPU LOAD na serwerze zabbix-7-0.
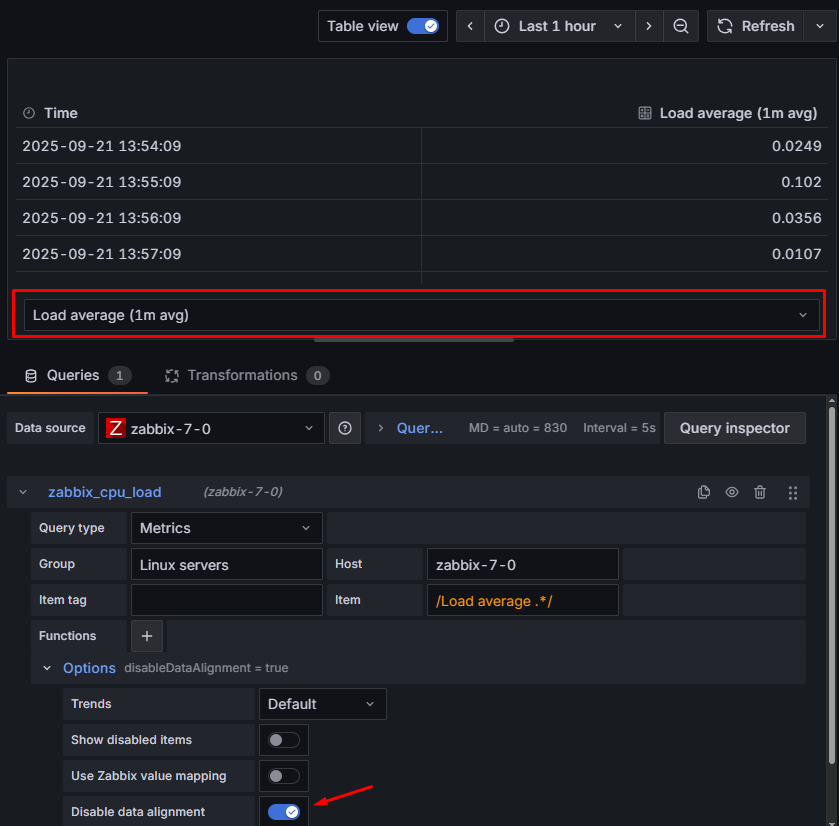
Dodatkowo zaleca się wyłączyć wyrównywanie czasu w zapytaniu – chcemy dokładnie wiedzieć, kiedy nastąpiło przekroczenie wartości LOAD. Ponadto powinno to rozbić zapytanie na 3 osobne serie danych, które łatwo rozpoznasz dzięki liście rozwijanej pojawiającej się przy podglądzie danych. Aby wyłączyć wyrównywanie czasu, w sekcji “Options” włączamy opcję “Disable data alignment”:
Rysunek 6. Wyłączenie wyrównywania czasu oraz rozbicie serii danych
Ze względu na możliwość różnej liczby jednostek CPU na serwerach, dodamy kolejne zapytanie o liczbę jednostek CPU. Tworzymy je przyciskiem “+ Add query”:
Rysunek 7. Dodanie kolejnego zapytania
Uzupełniamy pola w nowym zapytaniu:
Nazwa – zmień domyślną nazwę na “zabbix_cpu_num”
Query type – wybieramy “metrics” (bo znowu chcemy wyświetlić dane liczbowe)
Group – ta sama grupa hostów “Linux servers”,
Host – ta sama nazwa hosta – “zabbix-7-0”,
Item tag – nie jest wymagany, więc zostawiamy pusty,
Item – wskażemy konkretną pozycję – “Number of CPUs”
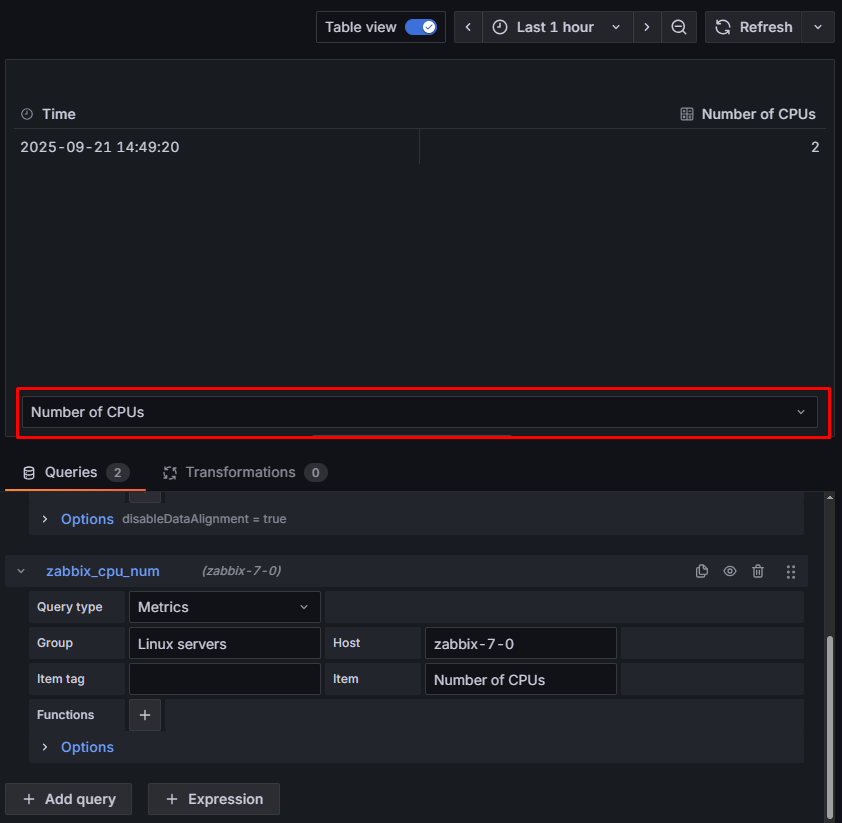
Konfiguracja i przykładowe dane pobrane za pomocą drugiego zapytania przedstawiono poniżej. Zauważ, że na listy pojawił się nowy zbiór danych – nie musimy się tym przejmować, ponieważ tej wartości nie będziemy rysować na wykresie.
Rysunek 8. Ustawienia pobierania danych na temat ilości CPU na serwerze zabbix-7-0.
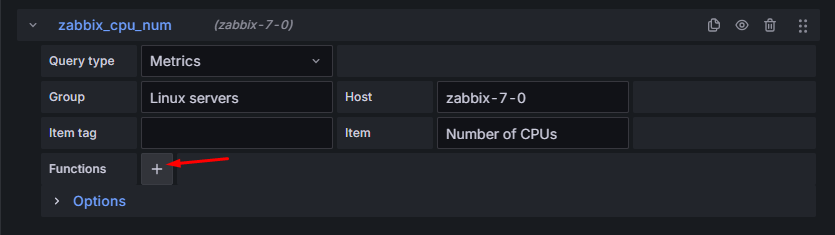
Autor zaleca pobieranie tylko ostatniej wartości liczby jednostek CPU, ponieważ będziemy brać pod uwagę wyłącznie najnowszą wartość z wybranego przedziału czasu. Aby to osiągnąć, dodamy dodatkową funkcję:
Rysunek 9. Dodawanie funkcji do zapytania.
W nowym okienku wybieramy “Transform” – “GroupBy”. W funkcji zmieniamy następujące wartości (klikając na nie):
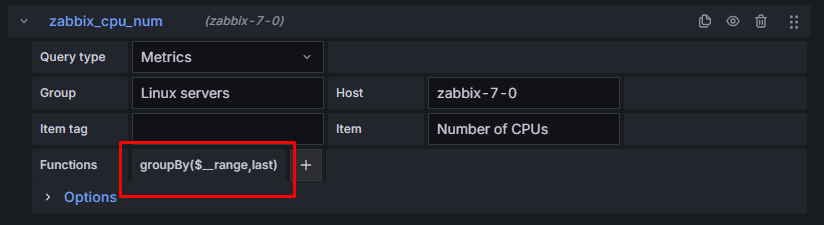
Pierwszą wartość zmieniamy na $__range – jest to wewnętrzna zmienna, która wskazuje na wybrany przez nas zakres czasowy. Na przykład, jeśli wybierzemy przedział „Last 6 hours”, funkcja będzie brała pod uwagę wartości z ostatnich 6 godzin.
Drugą wartość zmieniamy na last – czyli wybieramy ostatnią pobraną wartość.
Rysunek 10. Ustawienia funkcji “groupBy”.
Uwaga – czasami funkcja ta zamiast jeden, pobierze dwie wartości, ale nie wpływa to na wynik – zawsze będziemy uwzględniać ostatnią wartość.
Mając już wszystkie potrzebne dane, możemy zmienić wygląd naszego wykresu. W tym przykładzie wykorzystamy wykres pokazujący status w czasie. W okienku “Visualization” wybieramy opcję “State timeline”:
Rysunek 11. Zmiana panelu na “State timeline”.
Po wybraniu typu wykresu powinniśmy zobaczyć wykres z czterema wartościami, w tym ilością procesorów, wraz z „zielonymi” wartościami. Domyślne progi są ustawione na sztywną wartość 80 (no chyba, że twój serwer przekroczył wartość LOAD powyżej 80, co oczywiście nie jest rzeczą niemożliwą).
Oczywiście autor zachęca do samodzielnego eksplorowania opcji w okienku “Visualization”, ale na tym etapie zmieńmy tylko nazwę panelu (np. “CPU LOAD”) oraz krótki opis (np. „Status wartości LOAD w zależności od liczby jednostek CPU”).
Na koniec zajmiemy się transformacjami – to moment, w którym Grafana pokazuje swój prawdziwy pazur. Transformacje pozwalają w elastyczny sposób manipulować danymi zwróconymi przez zapytanie, zanim zostaną wyświetlone w panelu. Transformacji jest całkiem sporo, a pełną ich listę razem z wyjaśnieniem znajdziesz w >oficjalnej dokumentacji.
W naszym przykładzie wykorzystamy transformację, która umożliwiającą dynamiczną konfigurację wizualizacji na podstawie wartości pobranych z konkretnego zapytania. Aby dodać transformację:
Przechodzimy do zakładki “Transformations” (obok zakładki z zapytaniami),
Klikamy “+ Add transformation”:
Rysunek 12. Dodanie transformacji.
Z nowego okienka wybieramy “Config from query results”:
Rysunek 13. Wybór transformacji “Config from query results”.
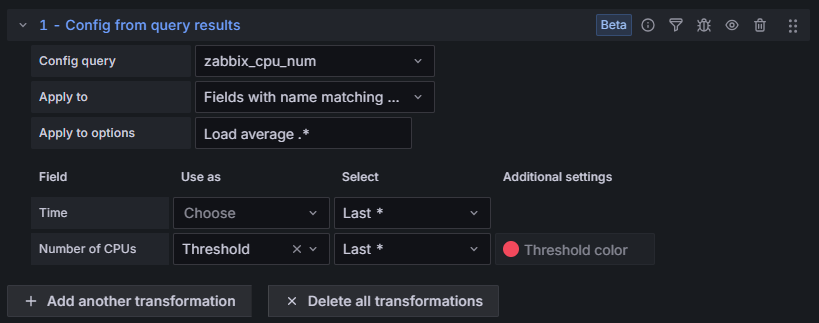
Teraz w okienku “Transformations” ustawiamy opcje:
Config query – wybieramy zapytanie, z którego chcemy pobrać wartość konfiguracyjną. Dzięki wcześniejszej zmianie nazw, łatwo znajdziemy liczbę CPU – zabbix_cpu_num,
Apply to – określamy, do których pól ma zostać zastosowana pobrana wartość. W naszym przypadku chcemy objąć wszystkie trzy wartości LOAD, więc wybieramy Fields with name matching regex,
Apply to options – wpisujemy ten sam regex, który wykorzystaliśmy w zapytaniu o LOAD – “Load average .*”(tym razem nie musimy zamykać wyrażenia regularnego w “/ /”),
Field – wskazujemy pozycję dotyczącą liczby CPU: “Number of CPUs”; w kolumnie “Use as” wybieramy “Threshold”, w kolumnie “Select” wybieramy “Last *”, a w kolumnie “Additional settings” możemy zmienić kolor progu;w naszym przykładzie zostawiamy czerwony
Rysunek 14. Ustawienia transformacji “Config from query results”.
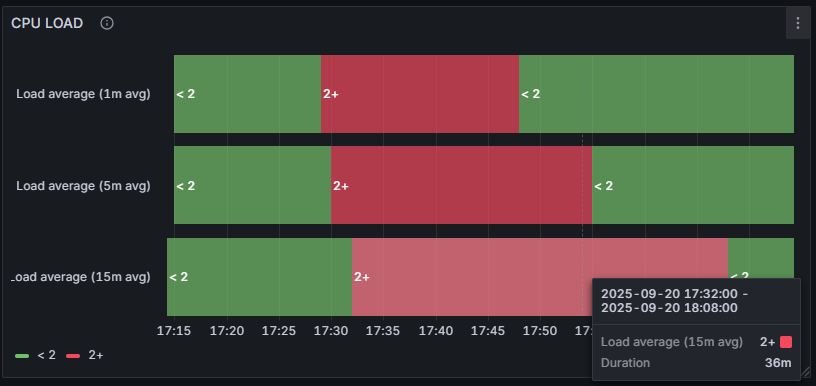
Po wyjściu z konfiguracji i zapisaniu zmian zobaczymy wykres pokazany poniżej. Najedź kursorem na dowolną wartość, aby sprawdzić, jak długo trwał dany okres (np. przekroczenie LOAD):
Rysunek 15. Przykładowy wykres “State timeline” dla serwera Zabbix.
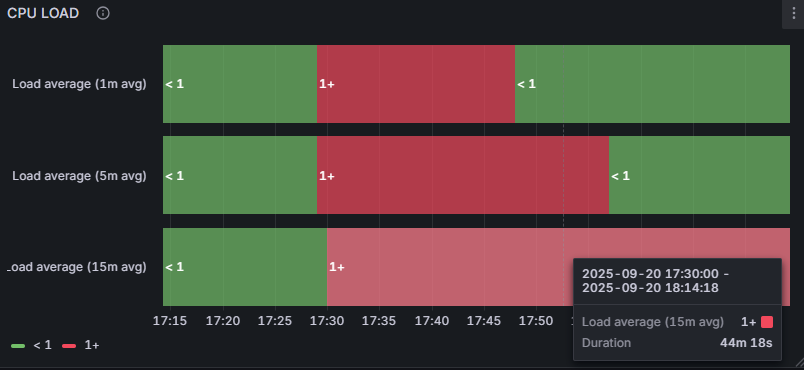
By mieć pewność, że wykres działa poprawnie, możemy zmienić serwer w obu zapytaniach z zabbix-7-0 na grafana-12-1. Przypomnijmy – serwer ten posiada tylko jedną jednostkę CPU:
Rysunek 16. Przykładowy wykres “State timeline” dla serwera Grafana.
Na szczęście długie okresy wysokiego LOAD były efektem symulacji obciążenia na serwerach, ale dzięki temu wykresowi możemy od razu zobaczyć, czy coś złego nie dzieje się na naszych hostach pod kątem obciążenia.
Uwaga: w niektórych przypadkach progi mogą nie zadziałać, ponieważ pozycja Number of CPUs jest domyślnie zapisywana do bazy danych raz dziennie. Jeśli tak się stanie, zwiększ przedział czasowy wyświetlanego wykresu lub częstotliwość zapisywania tej pozycji.
A może potrzebujesz czegoś “dla zarządu”? Nie ma problemu, weźmiemy coś jeszcze bardziej skomplikowanego!
Wykres strumieniowy
W tym przykładzie spróbujemy przedstawić wielkość ruchu sieciowego na serwerach “grafana-12-1” oraz “zabbix-7-0” z rozdzieleniem na ruch wchodzący oraz wychodzący. Autor przypomina, że obydwa serwery posiadają pojedyncze interfejsy sieciowe (dla czytelności), ale nie jest to przeszkoda – rozwiązanie powinno działać również w przypadku serwerów z wieloma interfejsami, ponieważ wartości zostaną zsumowane.
Dla lepszego zobrazowania, z poziomu Zabbix pozycje dotyczące ruchu sieciowego wyglądają następująco:
Rysunek 17. Lista pozycji dotyczących ruchu sieciowego w Zabbix.
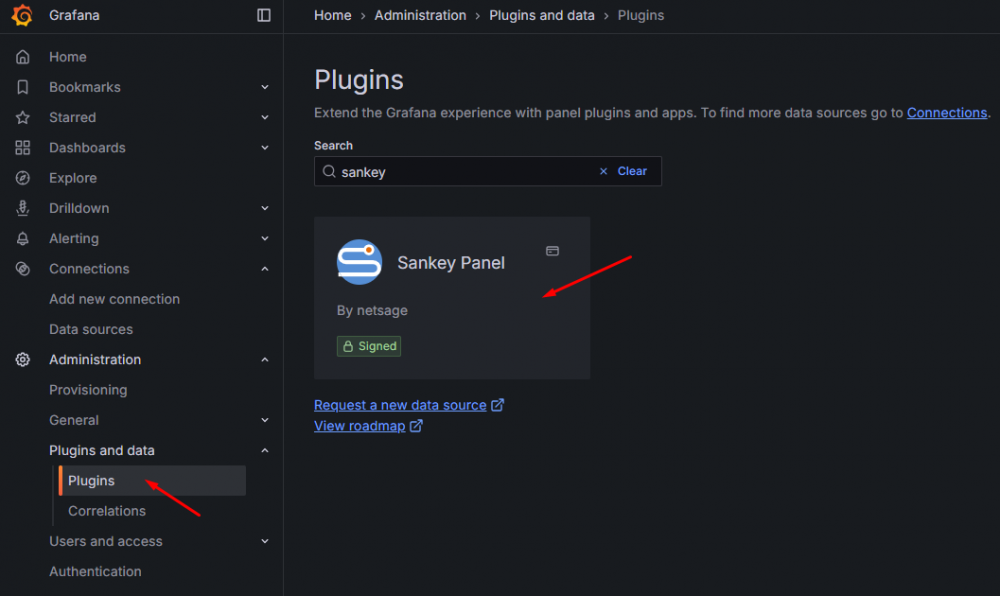
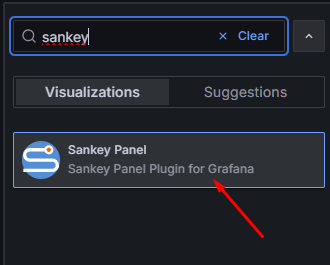
Na początek musimy upewnić się, że mamy zainstalowany plugin do wykresów strumieniowych. W menu głównym Grafany klikamy na “Administration” – “Plugins and data” – “Plugins” i wyszukujemy “Sankey panel”:
Rysunek 18. Wyszukanie pluginu “Sankey panel”.
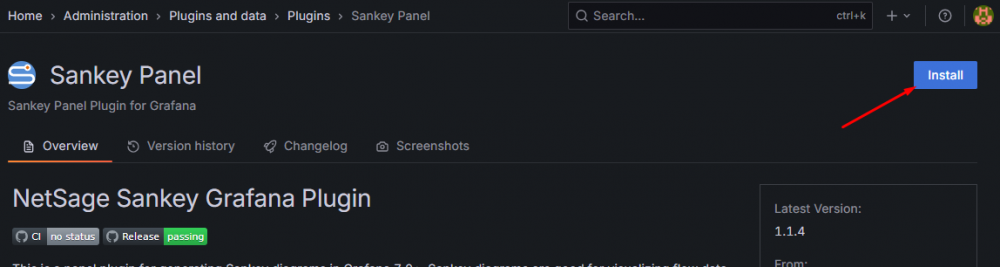
Jeżeli plugin nie jest dostępny w systemie, należy go zainstalować:
Rysunek 19. Instalacja pluginu “Sankey panel”.
Po zainstalowaniu pluginu wracamy do naszego dashboardu i tworzymy nowy panel. Upewniamy się, że w polu „Data source” wskazany jest skonfigurowany wcześniej Zabbix, a następnie wypełniamy pola zapytania:
Query type – wybieramy “metrics” (bo znowu chcemy wyświetlić dane liczbowe)
Group – grupa hostów obejmującą oba serwery, czyli “Linux servers”,
Host – aby uwzględnić wszystkie hosty z grupy, używamy wyrażenia regularnego: /.*/,
Item tag – nie jest wymagany, pozostawiamy puste,
Item – dla przypomnienia – pobieramy metryki dotyczące ruchu sieciowego: Interface {#IFNAME}: Bits sent Interface {#IFNAME}: Bits received Gdzie “{#IFNAME}” to nazwy interfejsów wykryte przez Zabbix. Do wybrania tych pozycji wykorzystujemy następujące wyrażenie regularne: /Interface .*: Bits (sent|received)/
Konfiguracja oraz przykładowe dane przedstawiono poniżej:
Rysunek 20. Ustawienia pobierania danych o ruchu na interfejsach sieciowych.
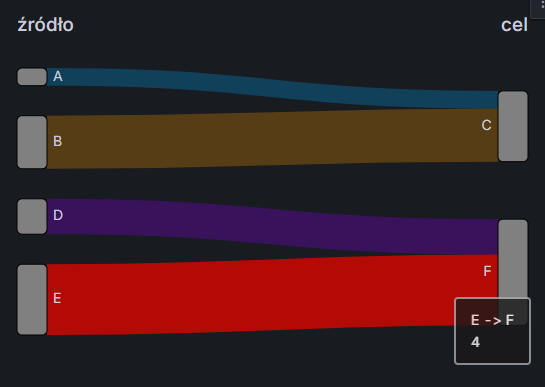
Musimy teraz na chwilę zboczyć z tematu i przyjrzeć się formatowi danych, jakiego oczekuje wykres strumieniowy. Najprostszy wykres potrzebuje tabeli z dwoma kolumnami: źródło oraz cel. Można dodatkowo dodać trzecią kolumnę z wartościami, aby wskazać “szerokość strumienia” np. wolumen zapytań, liczbę użytkowników lub natężenie ruchu). To właśnie ta wartość decyduje o tym, jak szeroka będzie linia na wykresie. Przykładowe dane mogą wyglądać tak:
źródło
cel
wartość
A
C
1
B
C
3
D
F
2
E
F
4
Spowoduje to wygenerowanie wykresu przedstawionego poniżej (z zaznaczeniem ostatniego strumienia):
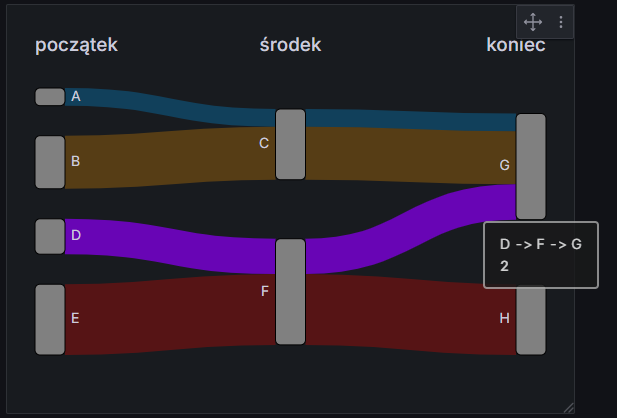
Mając już jasność, w jaki sposób należy przygotować dane do wykresu strumieniowego, możemy teraz zastanowić się, jak przekształcić nasze dane o ruchu sieciowym. W dalszych rozważaniach przyjmiemy następujące założenia:
wykres będzie miał trzy poziomy: kierunek (IN/OUT), serwery (z grupy Linux Servers) oraz logiczny byt „całość”; Dzięki temu będziemy mogli łatwo sprawdzić całkowity ruch wchodzący i wychodzący, a także sumaryczny ruch dla wszystkich serwerów,
na wykresie zawsze będziemy przedstawiać ostatnio pobrane wartości.
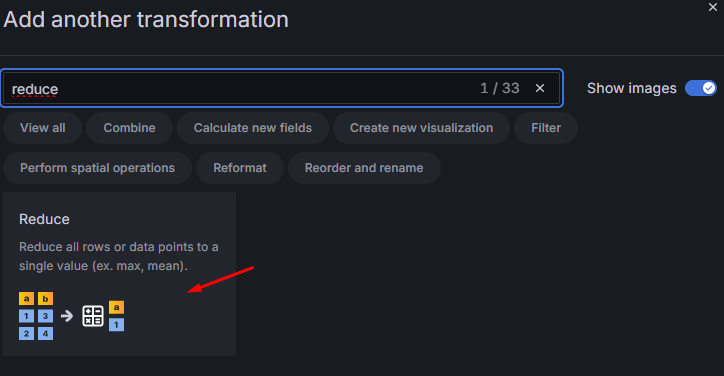
Łatwiej powiedzieć niż zrobić. Na szczęście transformacje w Grafana nam w tym pomogą. Przejdź do zakładki “Transformations” – “+ AddTransformation” i dodaj transformację “Reduce”:
Rysunek 23. Wybór transformacji “Reduce”.
Konfiguracja:
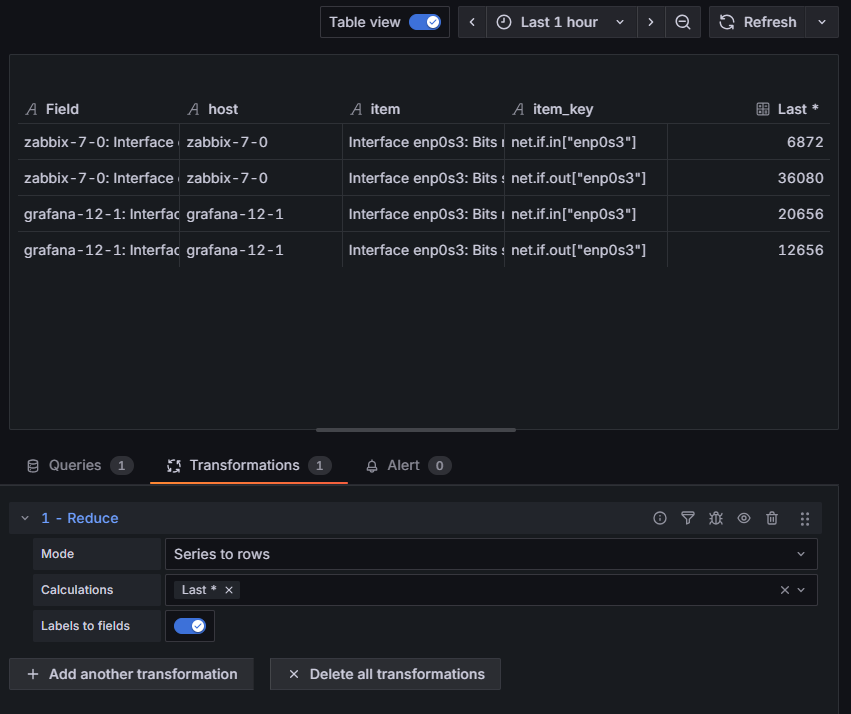
Mode – pozostawiamy Series to rows,
Calculations – usuń Max i wybierz “Last *” (jeżeli interesują Cię inne wartości, np. maksymalne lub minimalne z wybranego przedziału czasu, możesz tu wybrać odpowiedni tryb),
Label to fields – zaznacz tę opcję, aby wyświetlić dodatkowe etykiety (ang. labels), które są pobierane razem z danymi z Zabbix, takie jak nazwa hosta z Zabbix oraz nazwę i klucz pozycji.
Rysunek 24. Ustawienia transformacji “Reduce” wraz z przedstawieniem danych po transformacji
Wprawne oko zauważy, że udało nam się uzyskać jedną z wymaganych kolumn do naszego założenia – “Host”. Potrzebujemy jeszcze kolumny odpowiadającej za kierunek ruchu oraz kolumny reprezentującej całość. Do tego posłuży nam item_key, który zawiera klucz pozycji.
Dla przypomnienia, klucze pozycji wyglądają następująco:
W nazwie mamy już informację o kierunku (IN/OUT, zaznaczone kolorem zielonym), więc pozostaje tylko stworzyć logiczny byt zbierający całość. Wartość ta musi być jednolita dla wszystkich wierszy – możemy do tego wykorzystać początek klucza pozycji (zaznaczone kolorem niebieskim “net”).
Aby to osiągnąć, dodajemy kolejną transformację – Extract fields:
Rysunek 25. Wybór transformacji “Extract fields”.
Konfiguracja transformacji:
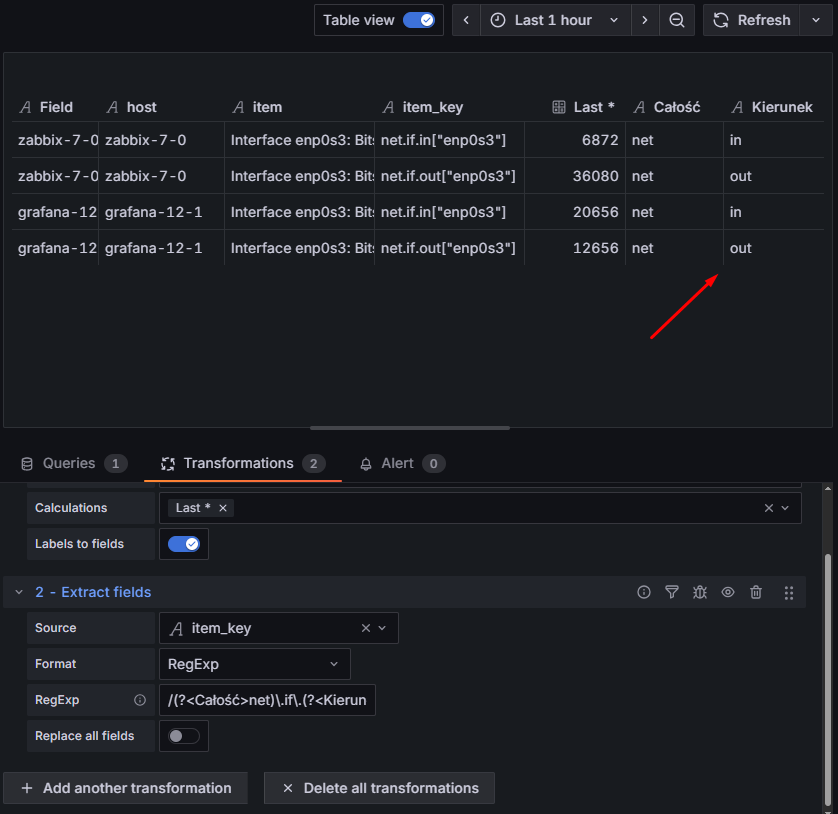
Source – wybieramy kolumnę zawierającą klucze pozycji, czyli item_key,
Format – wskazujemy sposób wyciągania wartości z całej nazwy, wybieramy RegExp (wyrażenia regularne),
RegExp – definiujemy grupy, które zostaną przekształcone w nowe kolumny, dodatkowo możemy nadać im własne nazwy (na podstawie “/(?<NAZWA>regex)/”); wykorzystamy następujący regex: /(?net)\.if\.(?.+)\[/ , gdzie:
(?<Całość>net) – tworzymy grupę o nazwie “Całość”, wyciągając dosłownie wartość “net”,
\.if\. – jawne wskazanie ciągu znaków “.if.” (nie jest objęty grupą, więc pomijany),
(?<Kierunek>.+) – grupa “Kierunek”, wyciąga wartość in lub out,
\[ – jawne wskazanie początku nawiasu kwadratowego “[“; wszystko, co dalej, pomijamy.
Replace all fields – pozostawiamy wyłączone, ponieważ potrzebujemy kolumny host.
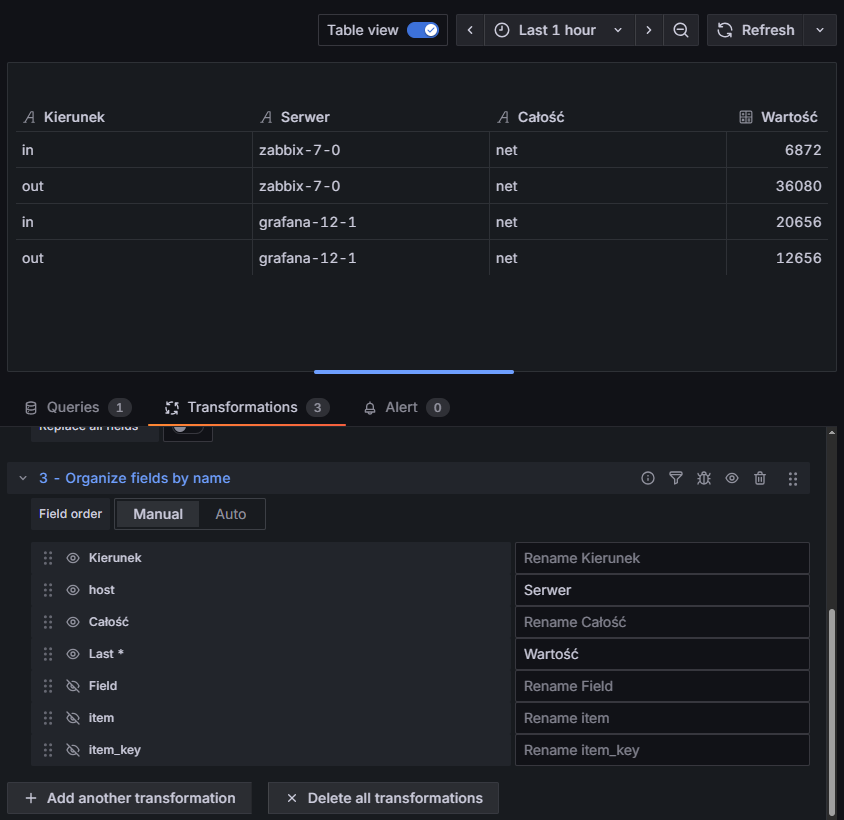
Całą konfigurację oraz wynik po transformacji przedstawiono poniżej. Zwróć uwagę, że pojawiły się nowe kolumny Całość i Kierunek z pożądanymi wartościami:
Rysunek 26. Ustawienia transformacji “Extract fields” wraz z przedstawieniem danych po transformacji
Jesteśmy już coraz bliżej celu. Pozostał nam tylko nadmiar kolumn oraz odpowiednia kolejność (która jest ważna!). Dodamy więc ostatnią transformację odpowiedzialną za porządki – “Organize fields by name”:
Rysunek 27. Wybór transformacji “Organize fields by name”.
Teraz
wyłączamy nadmiarowe kolumny, klikając w ikonę “oka”,
ustawiamy odpowiednią kolejność kolumn metodą drag & drop (klikając i przytrzymując “6 kropek”),
możemy zmienić nazwy kolumn: np. host → Serwer, Last * → Wartość.
Wynik (wraz z końcową tabelą) powinien wyglądać następująco:
Rysunek 28. Ustawienia transformacji “Organize fields by name” wraz z przedstawieniem danych po transformacji
Skoro mamy już przygotowane dane, zmieniamy wizualizację na “Sankey Panel” w okienku “Visualization”:
Rysunek 29. Zmiana panelu na “Sankey Panel”.
W tym okienku zmieniamy następujące parametry:
Panel options – Title – tytuł np. “Ruch sieciowy”,
Panel options – Description – dodatkowy opis np. “Wykres przedstawiający ruch sieciowy na serwerach zabbix-7-0 oraz grafana-12-1”,
Sankey Panel – Value Field – wskazujemy kolumnę zawierającą wartości “grubości” połączeń, czyli Wartość,
Standard options – Unit – wartości z Zabbix pobierane są w surowej formie, dlatego musimy wskazać, że jest to wielkość ruchu sieciowego – wskazujemy “Data rate / bits/sec(SI)”
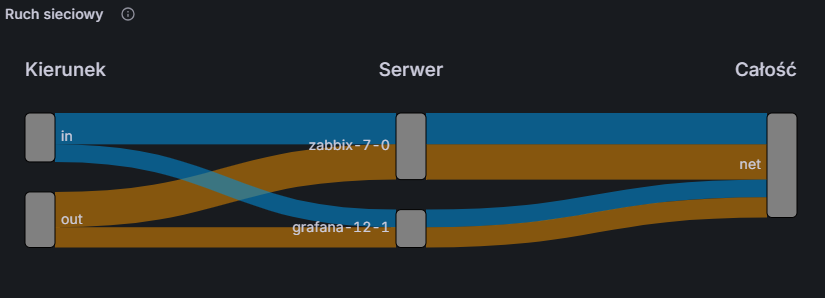
Koniec konfiguracji – możemy wyjść z panelu i zapisać dashboard. Pracy było sporo, ale efekt końcowy powinien wynagrodzić wysiłek:
Rysunek 30. Wykres strumieniowy – wynik końcowy.
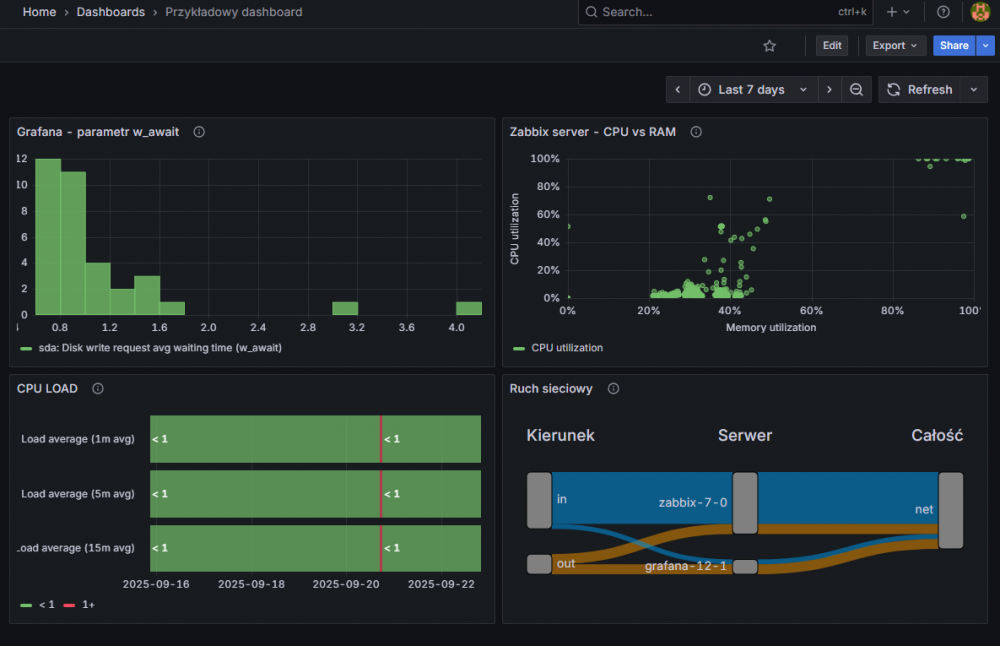
Po rozmieszczeniu nowo utworzonych paneli wraz z tymi z poprzedniego artykułu, cały dashboard powinien wyglądać mniej więcej tak (nie zapomnij o zapisaniu zmian!):
Rysunek 31. Ostateczny wygląd dashboardu.
Bonus
Jeżeli gdzieś się pogubiłeś lub nie wiesz “gdzie kliknąć”, Autor udostępnia cały “Przykładowy dashboard”>do pobrania w formacie JSON.
Po pobraniu pliku wystarczy wejść w zakładkę “Dashboards”, i z prawego górnego rogu wybrać “New” – “Import”:
Rysunek 32. Import dashboardu.
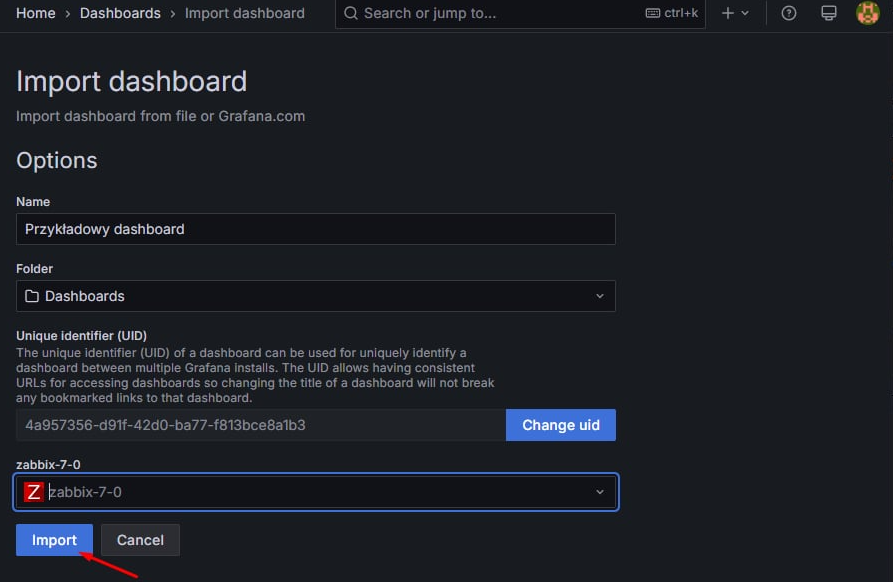
Następnie wybieramy pobrany plik JSON, a w formularzu wskazujemy źródło danych – nasze wcześniej skonfigurowane połączenie z Zabbix – i klikamy “Import”:
Rysunek 33. Ustawienia podczas importu dashboardu.
To wszystko! Od teraz możesz zobaczyć cały dashboard i dokładnie prześledzić, jak został zbudowany.
Podsumowanie
Niniejszy artykuł jest kolejnym potwierdzeniem, że konfiguracja dashboardów w Grafana nie jest trudna. Autor jak zwykle gorąco zachęca do dalszych testów, w szczególności do podpinania innych systemów, instalowania >nowych paneli lub też sprawdzenia >innych gotowych projektów dashboardów udostępnionych przez Grafana. A może Wy stworzyliście ciekawy panel lub cały dashboard? Pochwalcie się nimi w komentarzach!
Jednocześnie zapraszamy na nasze nowe duże szkolenie Zabbix Expert z ponad 50% rabatem! Zapisy tutaj: https://zabbix.sekurak.pl
Jeżeli oficjalny plugin do połączenia z Zabbix jest dla Ciebie niewystarczający, w kolejnym artykule pokażemy, jak wyciągać dane bezpośrednio z bazy danych. Jeżeli natomiast ten artykuł pomógł Ci sprawić, że „twój zarząd był zadowolony”, to pomyśl o wsparciu autora >dobrą kawką!
~ Albert Przybylski, zawodowo: Architekt ds. Monitoringu w firmie Aplitt, prywatnie: pełnoprawny fanatyk Zabbixa zasilany kawą
Spodobał Ci się wpis? Podziel się nim ze znajomymi: