Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Adminie… Czy znamy Twoje grzechy? ;-) Sprawdź!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Adminie… Czy znamy Twoje grzechy? ;-) Sprawdź!

OpenAI w końcu udostępniło dwa modele do wykorzystania lokalnie: gpt-oss-120b i gpt-oss20b. Najnowsze modele językowe z otwartymi wagami (pierwsze od czasu GPT-2) zapewniają wysoką wydajność podczas rzeczywistego wykorzystania przy niskich kosztach mocy obliczeniowych. Architektura ww. modeli składa się z wielu tzw. ekspertów (ang. mixture of experts, MoE), czyli mniejszych sieci neuronowych, wyspecjalizowanych do obsługi określonego typu danych, zamiast jednego dużego modelu, co zwiększa wydajność i obniża wymagania sprzętowe.
Warto zaznaczyć, że modele z otwartymi wagami (ang. open-weight models) nie są tym samym co open source. W tym przypadku twórcy udostępniają gotowy, wytrenowany model – czyli gotowe parametry sieci neuronowej. Pozwala to na: pobranie i uruchomienie modelu lokalnie, fine-tuning i wykorzystanie w aplikacjach bez konieczności przechodzenia przez API twórcy. Nie mamy jednak dostępu do kodu i oryginalnych danych treningowych.
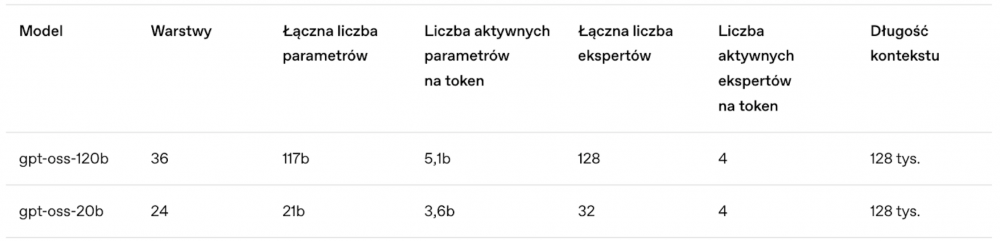
Trenowanie odbywało się przy użyciu zestawu danych zawierającego wyłącznie tekst, głównie w języku angielskim, który przede wszystkim dotyczył nauk ścisłych, technologii, inżynierii i matematyki (STEM), programowania oraz wiedzy ogólnej.
gpt-oss-120b
Opisywany jako duży model (klasa o4-mini) do uruchamiania w centrach danych oraz na bardzo wydajnych komputerach. Działa na jednym układzie GPU 80GB VRAM. Najlepiej sprawdzi się do budowy agentów i systemów wsparcia, analizy danych złożonych i wieloetapowej pracy z kodem np. przy audytach, optymalizacjach.
gpt-oss-20b
Według opisu od Open AI jest średniej wielkości model (klasa o3-mini), który można uruchamiać na większości komputerów i laptopów. Wymagania zalecane to układ GPU z 16GB VRAM.
Sugerowane zastosowania: asystenci, komunikacja, automatyzacja, streszczenia, raporty, przetwarzanie treści, klasyfikacja i organizacja informacji.
Najważniejsze cechy obu modeli:
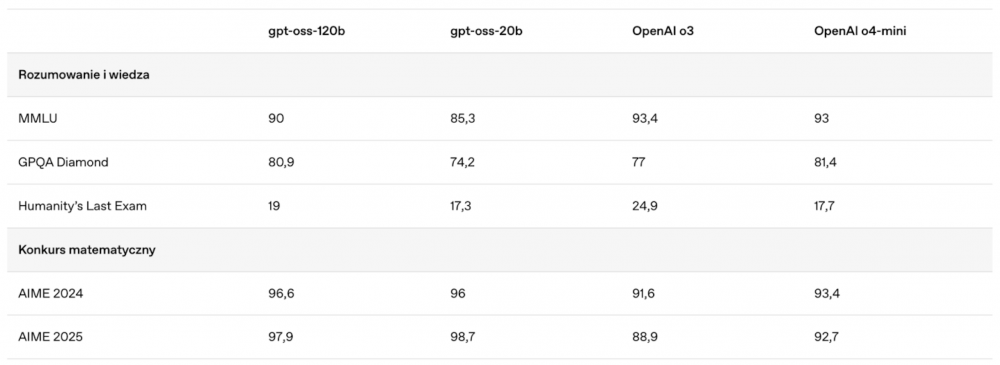
OpenAI przedstawiło benchmarki obu modeli:
Jest też możliwość wypróbowania modeli za pomocą interaktywnego demo dostępnego na stronie.
OpenAI pochwaliło się też współpracą z pierwszymi partnerami, takimi jak AI Sweden, Orange i Snowflake, w celu rozpoznania rzeczywistych zastosowań modeli open, od ich udostępniania lokalnego ze względu na ochronę danych (ograniczenie ekspozycji do chmury), po umiejętną budowę prompta systemowego przy użyciu specjalistycznych zestawów danych.
Firma podkreśla, że modele zaprojektowano tak, aby były elastyczne i aby można je było uruchomić w dowolnym miejscu — lokalnie lub za pośrednictwem zewnętrznych dostawców. W tym celu OpenAI nawiązało współpracę z platformami wdrożeniowymi, takimi jak Hugging Face, Azure, vLLM, Ollama, llama.cpp, LM Studio, AWS, Fireworks, Together AI, Baseten, Databricks, Vercel, Cloudflare i OpenRouter, aby modele były powszechnie dostępne dla programistów. W zakresie sprzętu nawiązano współpracę z firmami takimi jak: NVIDIA, AMD, Cerebras i Groq.
~Natalia Idźkowska

Tekst ciekawy, ale “wyszukiwanie w sieci i wykonywanie kodu w języku Python (tak jak w modelach dostępnych online)” to nie są cechy modelu.