Mam wrażenie, że mało kto słyszał o open-source’owym projekcie secureCodeBox, spod znaku OWASP. W sumie to się nie dziwię, bo ja pierwszy raz usłyszałem o nim kilka miesięcy temu, kiedy aplikowałem na stanowisko związane z obszarem Application Security, które akurat miało w dodatkowych wymaganiach znajomość tego narzędzia.
W rezultacie poznałem niszowe, ale bardzo ciekawe rozwiązanie z zakresu bezpieczeństwa aplikacji i przy okazji sporo dowiedziałem się o Kubernetesie. Dziś chciałbym podzielić się zdobytą wiedzą.
W ramach tego artykułu postaram się wyjaśnić:
Jak działa OWASP secureCodeBox(sCB) i do czego jest wykorzystywany.
Jak uruchomić nieduży i lokalny klaster Kubernetes (K8s) za pomocą rozwiązania Minikube.
Jak zbudować w klastrze niewielkie środowisko testowe, w którym znajdzie się przykładowa aplikacja WordPress.
W jaki sposób zbadać aplikację pod kątem podatności, za pomocą narzędzia WPScan (WordPress Security Scanner), zintegrowanego z sCB.
Czy automatyczne testy bezpieczeństwa są niezbędne?
Nie ma co się oszukiwać, że w większości organizacji bezpieczeństwo jest stawiane na pierwszym miejscu. W zasadzie to jest odwrotnie: większość firm traktuje bezpieczeństwo aplikacji tylko jako koszt (często zbędny z punktu widzenia kadry kierowniczej).
Trudno się dziwić: przecież to głównie rozwój oprogramowania i nowe funkcjonalności przynoszą pożądane zyski. Nie pomaga również rynkowy niedobór wyszkolonych specjalistów od cyberbezpieczeństwa.
Niestety, bardzo często refleksja następuje dopiero po poważnym incydencie. Porównałbym to z dbaniem o zdrowie. Większość ludzi jest świadoma, że dobre zdrowie wynika w dużej mierze z profilaktyki, a mimo to nie chce ponosić jej kosztów.
Załóżmy jednak, że mamy do czynienia z odpowiedzialną organizacją, która dba o bezpieczny rozwój oprogramowania (SSDLC = Secure Software Development Lifecycle) i regularnie (np. co pół roku) zleca przeprowadzanie testów penetracyjnych wydanej aplikacji zewnętrznej firmie.
Przyjrzyjmy się temu, co się dzieje w tzw. międzyczasie: kod aplikacji stale się rozrasta, pojawiają się nowe funkcjonalności, kolejne wersje są wydawane. Groźna podatność może pojawić się w każdej chwili, a do kolejnego planowanego audytu zostało jeszcze kilka miesięcy.
No dobrze, ale nie mamy swojego zespołu pentesterów, a nie będziemy przecież zamawiać zewnętrznych testów po każdorazowym wdrożeniu na produkcji nowej wersji aplikacji? Jest inne rozwiązanie: automatyczne i regularne testy bezpieczeństwa, zintegrowane z cyklem SSDLC (tzw. continuous testing).
Czym jest secureCodeBox?
OWASP secureCodeBox (sCB)tonarzędzie open-source wspomagające automatyzację testów bezpieczeństwa, przystosowane do działania w klastrze Kubernetes. Z powodzeniem można je dodać do procesów CI/CD (Continuous Integration/Continuous Delivery). Dzięki temu zespoły mogą otrzymać natychmiastowy feedback w postaci raportu zawierającego potencjalne podatności i od razu je zweryfikować.
W chwili pisania tego artykułu, sCB obsługuje ponad 20 popularnych narzędzi testujących, które pozwolą oszacować stan bezpieczeństwa różnych warstw badanego systemu (od testowanie pojedynczych aplikacji po skanowanie sieci). Mamy tutaj do wyboru takie instrumenty jak OWASP ZAP, Nmap, ffuf czy Semgrep. Pełną listę aktualnie wspieranych rozwiązań można znaleźć w oficjalnej dokumentacji.
Nic nie stoi na przeszkodzie, żeby wybrane narzędzia skanujące instalować natywnie oraz integrować bezpośrednio, jednak sCB umożliwia zarządzanie nimi za pośrednictwem jednego interfejsu. Mówiąc krótko: dzięki sCB mamy ujednolicony proces instalacji i konfiguracji każdego z obsługiwanych skanerów.
Wyniki skanowania mogą trafić do wybranego narzędzia, służącego do monitorowania stanu systemu i analizy zgromadzonych logów, dzięki wbudowanej integracji z takimi rozwiązaniami jak Azure Monitor, Elasticsearch czy DefectDojo.
Integracja jest możliwa dzięki mechanizmom hooks, stosowanych powszechnie przez twórców oprogramowania i pozwalających na zmianę działania aplikacji, w miejscach do tego przeznaczonych. Mówiąc bardziej obrazowo: programista zostawia w kodzie haczyki, na których możemy doczepić naszą funkcjonalność. Nie inaczej jest z twórcami secureCodeBox, którzy również pozwalają użytkownikom na zdecydowanie, co dokładnie należy zrobić z wynikami skanowania.
Miejmy świadomość, że głównym celem autorów rozwiązania było stworzenie platformy do testów bezpieczeństwa, umożliwiającej łatwą integrację wielu różnych narzędzi testujących z procesami CI/CD, a nie całkowite wyeliminowanie pełnoprawnych audytów bezpieczeństwa przeprowadzanych przez profesjonalnych pentesterów.
Krótkie wprowadzenie do Kubernetesa (K8s)
Jeśli jesteś już zaznajomiony(-a) z koncepcją kontenerów oraz ich orkiestracją z użyciem Kubernetesa, możesz śmiało pominąć ten rozdział.
Narzędzie OWASP secureCodeBox (sCB) zostało zaprojektowane z myślą o działaniu na platformie Kubernetes (K8s). O samej platformie można znaleźć mnóstwo materiałów, zarówno darmowych, jak i płatnych, więc nie będziemy wchodzić w szczegóły. Mimo wszystko, w ramach krótkiego przypomnienia, chcę przedstawić podstawowe zagadnienia związane z K8s, które pomogą zrozumieć, w jaki sposób działa samo narzędzie sCB.
Konteneryzacja
Dzisiejsze systemy, nawet te najprostsze, składają się z przynajmniej kilku komponentów. Nawet prosty blog to przeważnie aplikacja webowa, która komunikuje się z zewnętrzną bazą danych. Mamy więc przynajmniej dwa komponenty. Jeśli aplikację webową rozbijemy jeszcze na back-end w postaci serwera API, z którym komunikuje się front-end, to nasz system ma już trzy składowe.
Ten przykład pokazuje, że w nawet tak prostym rozwiązaniu musimy zarządzać kilkoma elementami i upewnić się, że ze sobą współgrają. Każdy programista pracujący nad aplikacją musi przygotować sobie środowisko, żeby móc skonfigurować cały system lokalnie. Wiąże się to m.in. z instalacją odpowiedniego środowiska uruchomieniowego oraz uruchomieniem lokalnego serwera bazodanowego.
Oprócz lokalnych środowisk deweloperskich warto jeszcze przygotować środowisko testowe, żeby zespół QA (Quality Assurance) mógł zweryfikować działanie całego systemu, zanim trafi do środowiska produkcyjnego. Każde z tych środowisk trzeba wcześniej przygotować i skonfigurować, co samo w sobie może być dosyć czasochłonne.
Należy również zadbać o to, żeby wszystkie środowiska, od lokalnego programisty po produkcyjne, były niemalże identyczne. W przeciwnym razie niejednokrotnie natrafimy na problem, który występuje tylko na określonym serwerze (np. w środowisku lokalnym i testowym wszystko działa jak należy, a na serwerze produkcyjnym pojawiają się niespotykane wcześniej błędy), co dodatkowo utrudnia diagnozę.
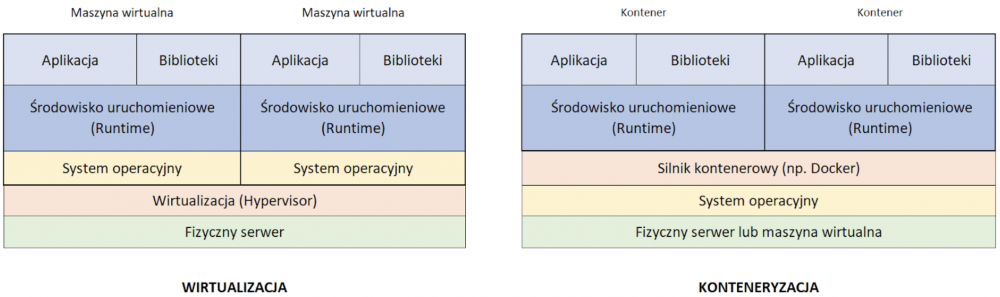
Lekarstwem na opisane wyżej bolączki może być konteneryzacja (ang. containerization), czyli specjalny rodzaj izolacji (wykorzystujący w tym celu odpowiednie mechanizmy jądra systemu), polegający na tym, że wszystkie niezbędne komponenty wymagane do działania aplikacji (i nic ponadto) są spakowane do pojedynczego obrazu kontenera (ang. container). Każdy z takich kontenerów może zostać uruchomiony w ramach tego samego systemu operacyjnego, w odizolowanej przestrzeni użytkownika. Mówiąc prościej: wyobraźmy sobie kontener jako paczkę zawierającą aplikację w komplecie z wymaganymi przez nią bibliotekami oraz niezbędnym dla niej środowiskiem uruchomieniowym.
W przypadku standardowej wirtualizacji mamy do czynienia z abstrakcyjną warstwą zapewniającą bezpośrednią interakcję z hardwarem, na którym instalujemy pełny system operacyjny (type-1 hypervisor).
Warto wspomnieć, że istnieje jeszcze drugi typ wirtualizacji, w którym hipernadzorca ma dostęp do sprzętu jedynie za pośrednictwem systemu operacyjnego, na którym jest zainstalowany (type-2 hypervisor lub hosted hypervisor).
Konteneryzacja idzie o poziom wyżej i w jej przypadku warstwą abstrakcyjną jest system operacyjny, w którym instalujemy i uruchamiamy aplikacje.
Rys. 1. Różnica pomiędzy wirtualizacją (type-1 hypervisor) i konteneryzacją.
Oznacza to, że kiedy pracujemy nad systemami składającymi się z wielu komponentów, wystarczy przygotować odpowiedni obraz kontenera (ang. container image) dla każdego z tych komponentów i wszędzie (tzn. tam gdzie działa konteneryzacja) mamy identyczne środowisko. Dobrym przykładem jest architektura oparta na mikroserwisach (ang. microservices), gdzie kontenery są często stosowane.
Konteneryzacja jest ogólnym konceptem, ale często jest kojarzona z Dockerem. Trudno się temu dziwić, gdyż to właśnie za sprawą Dockera rozwiązania oparte o kontenery stały się tak popularne. Dobrze jest jednak pamiętać, że istnieją inne produkty tego typu, jak choćby Podman, LXD czy containerd.
Orkiestracja
Kontenery eliminują trudności wynikające z różnorodnych środowisk na serwerach, ułatwiają skalowanie oraz przenoszenie komponentów między systemami, a także zapewniają izolację aplikacji od reszty systemu.
Pozostał jednak jeszcze jeden problem. W przypadku rozwiązania składającego się z wielu elementów (różne mikrousługi, serwery bazodanowe, serwery HTTP itp.) należy to wszystko jakoś ze sobą połączyć i zapewnić ciągłość działania.
Nawet jeśli komponenty będą rozmieszczone w osobnych kontenerach, to i tak należy każdy z nich uruchomić. Później trzeba zadbać o komunikację między nimi. Jeśli okaże się, że aktualne zasoby są niewystarczające do prawidłowego działania w przypadku dużego obciążenia, to nie obejdzie się bez skalowania.
Innymi słowy, potrzebujemy czegoś do automatycznego zarządzania kontenerami, żebyśmy nie musieli robić tego wszystkiego ręcznie. Mówiąc bardziej dosadnie, potrzebujemy czegoś do orkiestracji (ang. orchestration) i Kubernetes doskonale się w tej roli sprawdza.
Kubernetes (K8s)
Uwaga! Opisane poniżej komponenty to tylko część tego co oferuje Kubernetes. Niemniej jednak, powinno to wystarczyć do zrozumienia zasady działania rozwiązania OWASP secureCodeBox i nie tylko.
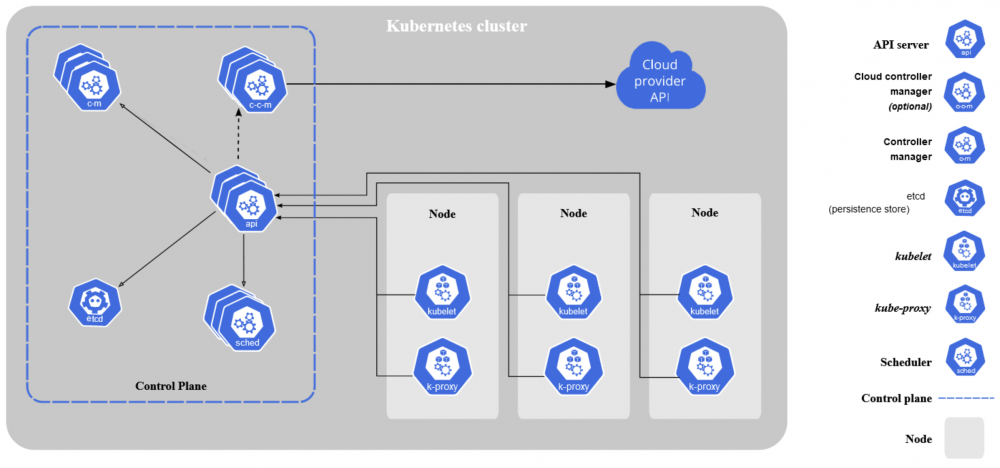
Powyższy schemat pochodzi z oficjalnej dokumentacji i pokazuje ogólną budowę klastra K8s. Omówmy sobie kolejno poszczególne elementy.
Klaster
Najbardziej ogólną jednostką w ekosystemie Kubernetesa jest klaster (ang. cluster). Kiedy dla uproszczenia mówimy, że nasz system działa w Kubernetesie, to tak naprawdę mamy na myśli to, że działa w klastrze, utworzonym po instalacji niezbędnych komponentów K8s.
W zależności od potrzeb, w skład klastra K8s może wchodzić jedna lub (co jest bardziej pożądane w środowiskach produkcyjnych) wiele maszyn roboczych. To właśnie na tych maszynach roboczych uruchamiane są zarówno kontenery z naszymi aplikacjami, jak i wszystkie komponenty samego Kubernetesa.
Węzły
Każdy klaster składa się z przynajmniej jednego węzła (ang. node), ale zazwyczaj jest ich dużo więcej. W tym przypadku węzłem nazywamy abstrakcyjną maszynę roboczą z określonymi zasobami, takimi jak CPU czy pamięć RAM. Węzłem wcale nie musi być fizyczny serwer. Oznacza to, że na jednej maszynie fizycznej możemy mieć kilka węzłów w postaci maszyn wirtualnych.
To w węzłach jest wykonywana cała praca i to właśnie tam funkcjonują Pody, w ramach których działają kontenery z naszymi aplikacjami. Dlatego nazywane są węzłami roboczymi (ang. worker nodes).
Podstawowe elementy (procesy) każdego węzła K8s:
kubelet– agent dbający o to, żeby kontenery były uruchamiane w Podach, którymi zarządza na podstawie określonej specyfikacji. Inaczej mówiąc, odpowiada za to, żeby ilość uruchomionych Podów i ich stan był zgodny z oczekiwaniami.
kube-proxy – odpowiada za sterowanie ruchem sieciowym w danym węźle.
Container runtime – środowisko uruchomieniowe dla kontenerów, czyli de facto najważniejszy komponent każdego węzła, gdzie działają nasze aplikacje. Najpopularniejszym rozwiązaniem służącym do konteneryzacji i wspieranym przez K8s jest oczywiście Docker, ale może to być też Podman czy containerd.
Workload
Nie jest to nazwa konkretnego elementu, a pewien abstrakcyjny koncept aplikacji/zadania działającego w ramach węzła K8s. Reprezentuje zbiór Podów (może być jednoelementowy), który realizuje określone zadanie bądź funkcjonalność.
Pod tę kategorię zaliczamy zarówno mikrousługi działające w ramach Podów, jak i krótkotrwałe zadania wykonywane na żądanie (np. Job lub CronJob).
Pod
Jest to najmniejsza i najbardziej podstawowa jednostka, która może być wdrożona (ang. deployable) i zarządzana przez K8s. Składa się z jednego lub wielu kontenerów, które są ze sobą ściśle powiązane oraz współdzielą zasoby dyskowe i sieciowe. Pod stanowi logiczny host, więc kontenery działające w ramach jednego Poda można wyobrazić sobie jako aplikacje uruchomione na tym samym serwerze.
Warto przy okazji wspomnieć, że Pody są z natury nietrwałe. Jeśli wystąpi poważna awaria węzła, to wszystkie znajdujące się na nim Pody również przestaną działać i będziemy musieli utworzyć je na nowo. Na szczęście K8s oferuje pewien zestaw funkcjonalności, które zdejmują z nas obowiązek zarządzania Podami bezpośrednio.
ReplicaSet
Zadaniem tego komponentu jest utrzymanie określonej liczby replik (identycznych kopii) wybranego Poda w danym czasie.
Czasami wiemy, że pojedynczy Pod z aplikacją jest niewystarczający, żeby zapewnić wysoką dostępność (ang. high availability), więc potrzebujemy przynajmniej kilku instancji. Do tego celu służy element ReplicaSet, który dba o to, żeby zawsze działała określona liczba replik danego Poda, bez naszej ingerencji (np. kiedy ten ulegnie awarii i się wyłączy, K8s na podstawie konfiguracji ReplicaSet sam zadba o to, żeby stworzyć nową replikę na jego miejsce).
Deployment
Jeden z najczęściej używanych komponentów w K8s, który służy do wygodnego zarządzania elementami niższego poziomu, takimi jak Pod oraz ReplicaSet (tak naprawdę nawet nie powinniśmy nimi zarządzać bezpośrednio).
Za pomocą konfiguracji Deployment opisujemy pożądany stan docelowy naszego systemu, a o całą resztę dba już Kubernetes (od uruchomienia Podów, przez utrzymanie ich liczby na odpowiednim poziomie, po ich usunięcie). Jest to szczególnie wygodne podczas wdrażania aktualizacji (np. kodu aplikacji z nową funkcjonalnością).
Bez komponentu Deployment musielibyśmy ręcznie usunąć działające Pody ze starą wersją aplikacji i tworzyć nowe z aktualną wersją. Jeśli mielibyśmy ułożyć kolejno różne warstwy abstrakcji dla komponentów K8s, zaczynając od najwyższego poziomu, wyglądałoby to w ten sposób: Deployment -> ReplicaSet -> Pod -> Container.
Job & CronJob
Większość komponentów typu Workload to aplikacje uruchomione na Podach, których czas życia jest raczej długi. W przypadku Job jest inaczej. Określone zadanie wykonuje się na jednym lub wielu Podach, które są następnie usuwane po jego zakończeniu.
Jeśli mielibyśmy porównać Pody z uruchomioną aplikacją do długo działającego procesu systemie, to Job można porównać do skryptu, który ma się bezproblemowo skończyć po wykonaniu wszystkich instrukcji.
Jeżeli chcielibyśmy jakieś zadanie wykonywać cyklicznie i/lub o określonej porze, powinniśmy skorzystać z dedykowanego komponentu CronJob.
Komponenty sieciowe
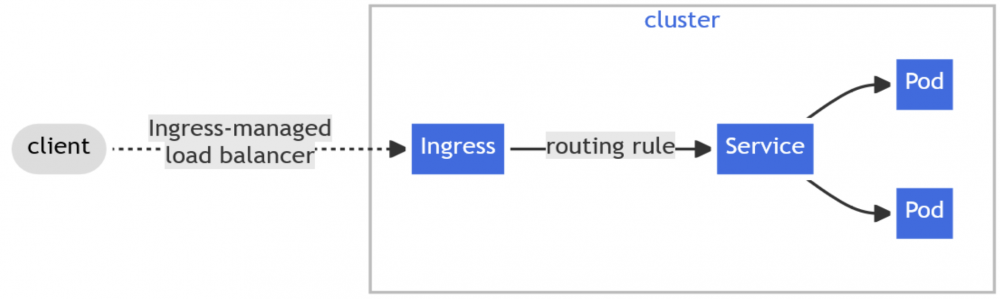
Service
Umożliwia ekspozycję aplikacji sieciowej (działającej w ramach jednego lub wielu Podów) na świat. Innymi słowy, komponentu Service używamy w celu udostępnieniu Podów w sieci, żeby aplikacje klienckie mogły się z nimi połączyć.
Pamiętajmy, że Pod jest bardzo ulotnym elementem systemu – w każdej chwili może zostać zniszczony, a w jego miejsce pojawi się kolejny z nową instancją tej samej aplikacji. Adres IP nowego Poda prawdopodobnie będzie tym razem inny, co stanowi poważny problem, jeśli spróbowalibyśmy łączyć się z Podami bezpośrednio. Jednakże czas życia komponentu Service nie jest w żaden sposób związany z czasem życia Podów i oferuje stały, niezmienny adres IP pozwalający na komunikację z nimi.
Ingress
O ile Service jest często używany w zapewnieniu łączności sieciowej wewnątrz klastra (choć niektóre typy Service umożliwiają również dostęp z zewnątrz), to komponent Ingress pozwala na połączenia przychodzące ze świata zewnętrznego, w szczególności oparte na protokole HTTP(S).
Dodatkowo, zapewnia takie funkcjonalności jak load balancing, SSL termination czy też nazwane hosty wirtualne (ang. name-based virtual hosts).
Centralne komponenty K8s sterujące całym klastrem i wszystkimi węzłami roboczymi znajdują się w tzw. warstwie sterowania (ang. control plane), choć w niektórych materiałach możemy się jeszcze spotkać z określeniem węzła nadrzędnego (ang. master node).
Procesy wchodzące w skład Control Plane:
API Server(kube-apiserver) – punkt wejściowy warstwy sterowania udostępniający Kubernetes API, czyli interfejs umożliwiający zarządzanie danym klastrem K8s. Można oczywiście komunikować się z serwerem bezpośrednio przez REST API, za pośrednictwem protokołu HTTP(S), jednakże znacznie wygodniej jest użyć dedykowanego klienta, jak np. kubectl, który oferuje pokaźne możliwości z poziomu CLI (Command Line Interface).
etcd – jest to wydajna baza danych typu klucz-wartość (ang. key-value store), która przechowuje wszystkie niezbędne informacje wymagane do działania klastra. Znajdują się tutaj m.in. informacje o aktualnym stanie klastra, a także o pożądanym stanie, który wynika z naszej konfiguracji.
Scheduler (kube-scheduler) – proces odpowiedzialny za optymalne przydzielanie zasobów. Wykrywa nowo utworzone Pody, które nie zostały jeszcze przydzielone do żadnego węzła, a następnie wybiera im odpowiedni węzeł na podstawie różnych czynników, takich jak zapotrzebowanie na zasoby, konfiguracja itp.
Controller Manager (kube-controller-manager) – proces odpowiedzialny za uruchamianie i działanie poszczególnych kontrolerów (ang. controllers). Dba o to, żeby aktualny stan klastra (i naszego systemu działającego w K8s) był jak najbardziej zbliżony do stanu pożądanego. Warto zaznaczyć, że każdy kontroler jest osobnym procesem logicznym, ale wszystkie kontrolery są uruchomione w ramach jednego fizycznego procesu w systemie operacyjnym (żeby zredukować poziom skomplikowania).
Controller – proces logiczny, który dba o prawidłowe działanie określonego fragmentu klastra. Działa na zasadzie pętli kontrolnej (ang. control loop) stosowanej w m.in. w urządzeniach codziennego użytku. Weźmy klimatyzator dla przykładu. My ustawiamy pożądaną temperaturę pomieszczenia, a wbudowany układ kontrolny mierzy rzeczywistą temperaturę – jeśli aktualna wartość jest identyczna (lub bardzo zbliżona) do tej ustawionej przez nas, urządzenie przestaje chłodzić. Włącza się ponownie jeśli rzeczywista temperatura znowu odbiegnie od pożądanej. Podobnie jest w K8s. Oto kilka przykładowych wbudowanych kontrolerów: node controller – reaguje kiedy jakiś węzeł przestanie nagle działać; job controller – dba o uruchomienie krótkotrwałych zadań i tworzenie/usuwanie dedykowanych im Podów; deployment controller – pilnuje, żeby wdrożone przez nas aplikacje były w pożądanym stanie (np. działały na określonej liczbie Podów).
Cloud Controller Manager (cloud-controller-manager) – jest to opcjonalny komponent zarządzający kontrolerami, które potrafią komunikować się z API określonych rozwiązań chmurowych (np. kiedy nasze węzły działają w chmurze).
CustomResourceDefinition (CRD)
Szeroka gama wbudowanych komponentów K8s jest wystarczająca do obsłużenia najczęstszych scenariuszy, jednakże mogą czasami pojawić się przypadki użycia, które wykraczają poza zakres typowej instalacji Kubernetesa.
Twórcy narzędzia przewidzieli taką potrzebę i dzięki temu mamy możliwość rozszerzenia standardowego Kubernetes API poprzez CRD (CustomResourceDefinition), czyli wycinek API umożliwiający definiowanie własnych zasobów (ang. custom resources).
Przy okazji warto wspomnieć o operatorach (Operator), czyli specjalnego typu kontrolerach, które służą przede wszystkim do zarządzania zasobami zdefiniowanymi przez użytkownika (ang. custom defined resources).
Wbudowane kontrolery omówione powyżej nadzorują działanie standardowych komponentów K8s w sposób generyczny (np. kontroler odpowiedzialny za Deploymenty pilnuje wszystkich Deploymentów w klastrze). Natomiast Operator, który również musi zostać zdefiniowany przez użytkownika, skupia się jedynie na wskazanych zasobach własnych.
secureCodeBox
Architektura
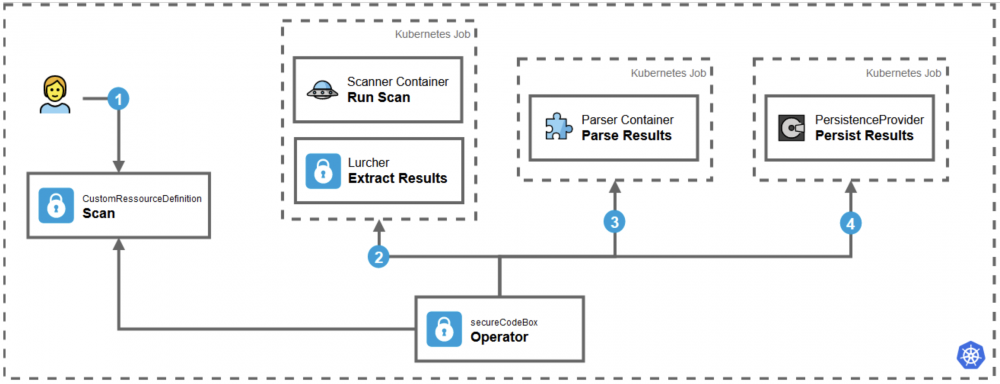
Rys. 4. Architektura rozwiązania sCB działającego w klastrze K8s. Źródło: OWASP secureCodeBox.
Jak widać na powyższym schemacie, architektura rozwiązania OWASP secureCodeBox opiera się przede wszystkim na zdefiniowanych w Kubernetesie zasobach własnych CRD (Custom Resource Definition) i przyjmuje postać łańcucha powiązanych ze sobą narzędzi (ang. toolchain):
Użytkownik zleca skanowanie w czasie rzeczywistym lub ustawia harmonogram wykonania testów. Komponent typu Scan jest zasobem własnym (CRD), służącym do uruchamiania i planowania skanów bezpieczeństwa.
Operator, czyli customowy kontroler, odpowiada za koordynowanie działań i uruchamia wybrane skanery bezpieczeństwa na podstawie Scanów, zdefiniowanych przez użytkownika.
Wyniki działania skanerów są zbierane i parsowane.
Sparsowane wyniki są zapisywane w wybranym przez użytkownika miejscu.
Na powyższym schemacie widać, że Operator sCB uruchamia zaplanowane skanowania (na podstawie konfiguracji Scan) oraz pozostałe operacje jako krótkotrwałe zadania – Kubernetes Jobs.
Taki schemat działania możemy porównać do kategorii Function as a Service (FaaS), znanej z popularnych rozwiązań chmurowych. To podejście pozwala zaoszczędzić dostępne zasoby, które są wykorzystywane tylko wtedy, kiedy do wykonania jest jakaś praca.
Jako ciekawostkę warto wspomnieć, że starsza wersja sCB działała na zasadzie mikroserwisu, który był w ciągłej gotowości (sale działający Pod), co wiązało się z niepotrzebnym zużywaniem zasobów klastra K8s.
Proof of Concept
Nadszedł czas na działanie! W ramach poniższego tutoriala uruchomimy mini-klaster Kubernetesa w środowisku lokalnym; zainstalujemy na nim przykładową aplikację WordPress (z podatnościami), a następnie przeprowadzimy skanowanie z użyciem środowiska secureCodeBox, żeby sprawdzić, ile podatności uda nam się wykryć.
Krok 1: Maszyna wirtualna (VM) Ubuntu
Aby upewnić się, że pracujemy w podobnym środowisku (celem uniknięcia dziwnych, nieprzewidzianych trudności), zachęcam do przetestowania omawianego rozwiązania na maszynie wirtualnej z wykorzystaniem tej samej wersji systemu operacyjnego. Nie daje to gwarancji, że środowisko będzie identyczne, ale wystarczy, że będzie odpowiednio zbliżone.
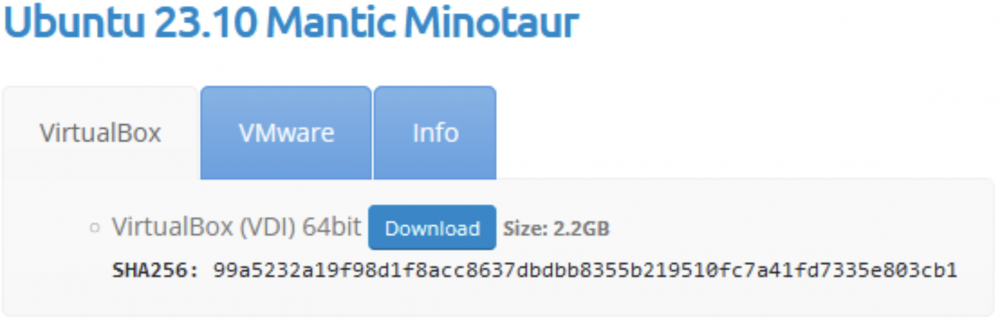
1. Pierwszym krokiem jest instalacja środowiska do wirtualizacji VirtualBox (moja wersja to 7.0.12). 2. Zamiast instalować cały system od zera, możemy zaoszczędzić trochę czasu i skorzystać z przygotowanego wcześniej obrazu VDI (Virtual Disk Image – plik obrazu dysku wirtualnego VirtualBox), dostępnego na OSBoxes. Ja zdecydowałem się na Ubuntu 23.10 Mantic Minotaur ze względu na prostotę użytkowania tej dystrybucji Linuksa. Ściągnijmy więc odpowiedni plik VDI, który zajmuje około 2.2 GB:
3. Rys. 5. Obraz VDI systemu Ubuntu 23.10 na osboxes.org.
3. Po ściągnięciu i rozpakowaniu archiwum 7z, powinniśmy mieć na dysku plik o nazwie Ubuntu 23.10 (64bit).vdi. Teraz musimy dodać nową (New) maszynę wirtualną w VirtualBox.
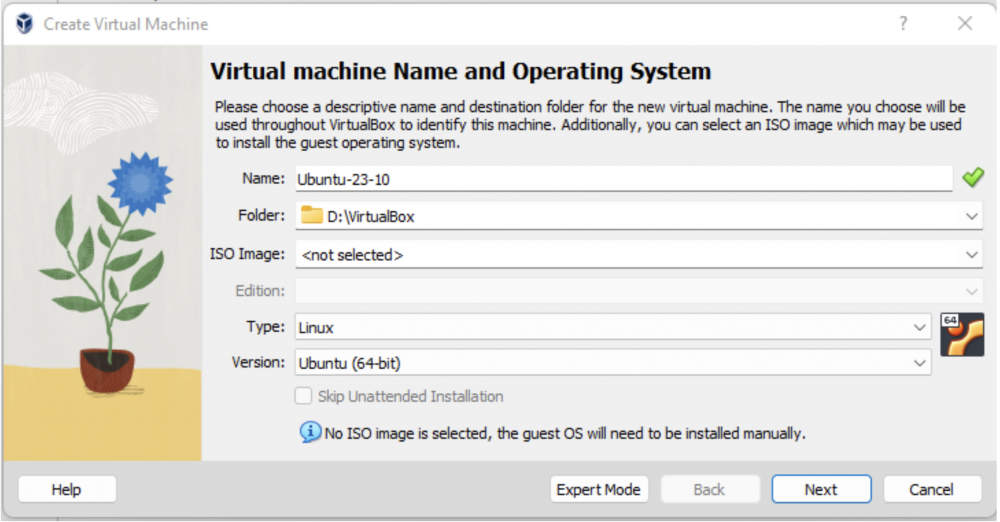
4. W pierwszym oknie kreatora podajemy dowolną nazwę maszyny wirtualnej; lokalizację docelową tej maszyny; typ oraz wersję. Ścieżkę do obrazu ISO zostawiamy pustą, ponieważ system jest już zainstalowany na ściągniętym wcześniej dysku wirtualnym.
Rys. 6. Podstawowa konfiguracja maszyny wirtualnej.
5. Na następnym ekranie określamy dostępne zasoby. 4GB pamięci RAM oraz 2 procesory CPU powinny wystarczyć na nasze potrzeby. Po wybraniu odpowiedniej konfiguracji, przechodzimy dalej.
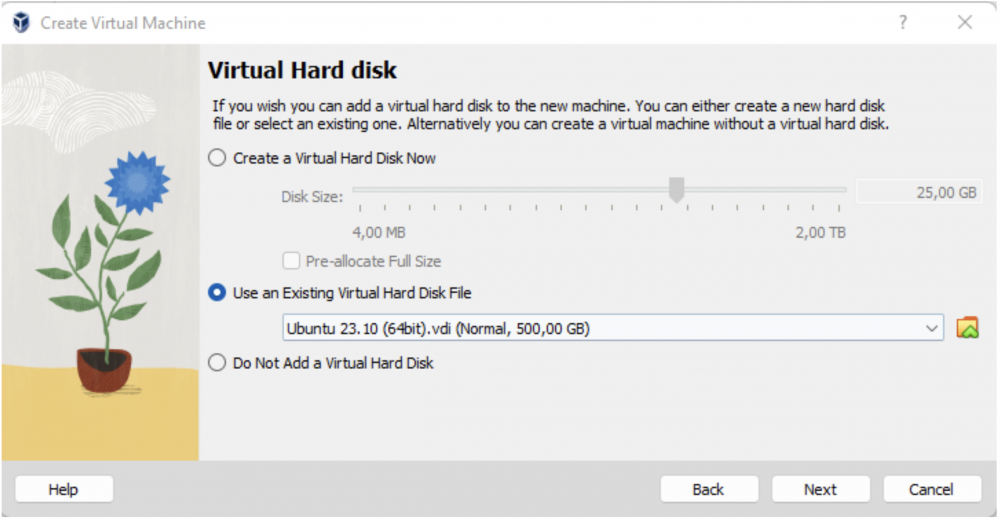
6. Teraz najważniejsze: nie tworzymy nowego dysku wirtualnego, tylko wybieramy plik VDI, który wcześniej ściągnęliśmy i klikamy Next.
Rys. 7. Jako wirtualny dysk twardy nowej maszyny, wybieramy ściągnięty wcześniej obraz VDI.
7. Jeśli na ekranie podsumowania wszystko wygląda OK, możemy zakończyć tworzenie maszyny wirtualnej (Finish) i w końcu ją uruchomić. Dane dostępowe:
Użytkownik (sudoer): osboxes
Hasło: osboxes.org
Krok 2: Lokalny klaster K8s (Minikube)
Wiemy już, że secureCodeBox działa tylko w klastrze Kubernetes. Jednak nie będziemy teraz stawiać i uruchamiać pełnoprawnego klastra K8s, składającego się z wielu węzłów, działających na różnych maszynach, bo o tym można byłoby napisać kilka kolejnych artykułów.
Na szczęście mamy do naszej dyspozycji narzędzie Minikube. Jest to lekkie i proste w użytkowaniu rozwiązanie, które pozwala na uruchomienie mini-klastra K8s lokalnie, w ramach naszego systemu operacyjnego.
Oczywiście pamiętajmy, że Minikube doskonale sprawdza się w testowaniu naszych pomysłów, ale niekoniecznie nadaje się do działania w środowisku produkcyjnym. Głównie dlatego, że taki klaster jest ograniczony tylko do jednego węzła, a poza tym nie jest to zamysł autorów.
Instalacja mini-klastra jest dobrze opisana w oficjalnej dokumentacji, ale przejdźmy razem przez jej najważniejsze elementy.
Docker
Minikube wymaga do działania środowiska konteneryzacji (zresztą, jak każdy klaster K8s), więc my użyjemy popularnego Dockera. Dla uproszczenia instalujemy wersję dostępną w repozytorium pakietów Snap (u mnie zainstalowała się wersja 24.0.5).
sudo snap install docker
Jeśli po wydaniu komendy docker version pojawi się błąd podobny do tego:
Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Get "http:///var/run/docker.sock/v1.24/version": dial unix /var/run/docker.sock: connect: permission denied
to znaczy, że musimy jeszcze nadać naszemu użytkownikowi uprawnienia do usługi Docker. Inaczej nie damy rady uruchomić klastra.
Najprostszym wyjściem jest utworzenie dedykowanej grupy docker z odpowiednimi uprawnieniami i dodanie naszego użytkownika do tej grupy:
sudo groupadd docker
sudo usermod -aG docker $USER
newgrp docker – polecenie powinno teoretycznie zastąpić konieczność ponownego zalogowania się, ale u mnie to nie zadziałało, więc i tak musiałem się wylogować i zalogować ponownie, żeby zmiany weszły w życie.
Warto przy okazji wspomnieć, że dodawanie do grupy docker użytkownika, który nie ma uprawnień administracyjnych, nie jest najlepszym pomysłem. Okazuje się bowiem, że nieograniczony dostęp do poleceń Dockera może doprowadzić do eskalacji uprawnień (ang. privilege escalation).
Aby sprawdzić czy Docker działa już jak należy, możemy uruchomić testowy kontener:
docker run hello-world
Minikube
Kiedy mamy pewność, że Docker jest już zainstalowany w naszym systemie (i działa), możemy przystąpić do instalacji mini-klastra Kubernetes. Proces jest bardzo prosty i sprowadza się do wydania kilku poleceń z dokumentacji:
Rys. 8. Wybór odpowiedniego pakietu Minikube.
sudo snap install curl – instalujemy narzędzie cURL, jeśli jeszcze go nie mamy.
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube_latest_amd64.deb – ściągamy oficjalny pakiet instalacyjny Debiana (przypominam, że Ubuntu opiera się na Debianie).
Nadszedł czas na uruchomienie naszego lokalnego klastra:
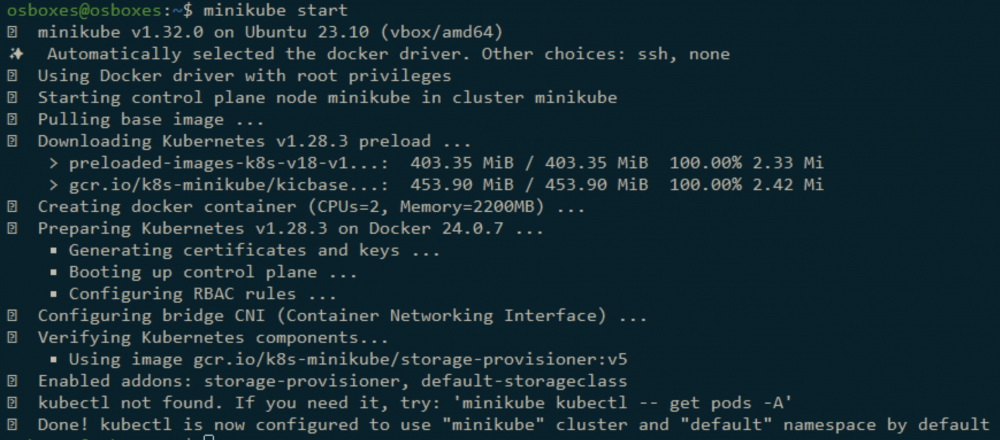
minikube start
Pierwsze uruchomienie może chwilę potrwać, ponieważ Minikube najpierw musi ściągnąć niezbędne zależności. Jeśli wszystko pójdzie dobrze, powinniśmy zobaczyć na wyjściu informacje podobne do tych poniżej:
Rys. 9. Pierwsze uruchomienie mini-klastra K8s (Minikube).
Warto przy okazji zaznaczyć, że po restarcie naszego systemu musimy pamiętać o ponownym uruchomieniu klastra (minikube start). Jeśli nie chcemy tego robić za każdym razem, możemy to zautomatyzować, na przykład w ten sposób: How to start up minikube automatically via systemd | by Jonhnatha Trigueiro.
Za pomocą polecenia minikube dashboard, możemy uruchomić graficzny interfejs, dostępny z poziomu przeglądarki, który pokazuje aktualny stan klastra Kubernetes.
kubectl
Pomimo istnienia graficznego interfejsu, z API klastra K8s najlepiej jest komunikować się za pomocą dedykowanego klienta CLI o nazwie kubectl. Dzięki temu, oprócz pełnej kontroli, mamy możliwość łatwej automatyzacji za pomocą skryptów.
Wspomnianego klienta możemy zainstalować oddzielnie, jednakże warto poprosić o to Minikube’a. Wystarczy wydać poniższe polecenie:
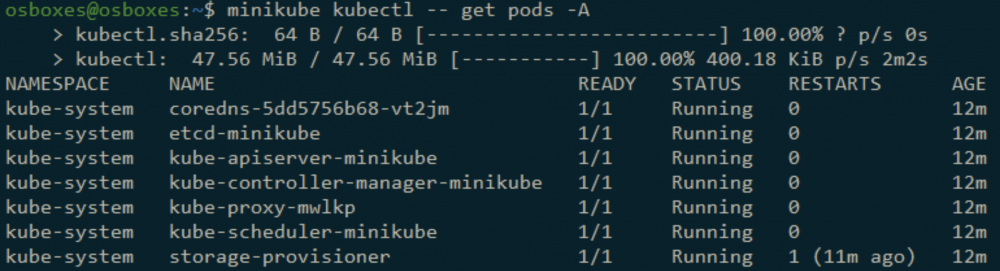
minikube kubectl -- get pods -A
Polecenie samo w sobie służy do wyświetlenia wszystkich Podów w klastrze, ale Minikube widząc, że kubectl jeszcze nie został zainstalowany, automatycznie zrobi to za nas i dopiero wtedy wyświetli dostępne Pody.
Rys. 10. Automatyczne pobranie i instalacja klienta kubectl.
Wadą takiego rozwiązanie jest fakt, że za każdym razem kiedy chcemy wydać polecenie kubectl, musimy pisać pełną wersję, charakterystyczną dla Minikube: minikube kubectl -- <COMMAND>.
Na szczęście możemy temu zaradzić, definiując odpowiedni alias w ~/.bashrc:
alias kubectl="minikube kubectl --"
Po przeładowaniu konfiguracji terminala (source ~/.bashrc) możemy już wydawać komendy tak, jakbyśmy to robili w przypadku standardowego klienta, czyli: kubectl <COMMAND>.
Jak zostało wcześniej wspomniane, kubectl jest dosyć potężnym narzędziem o wielu możliwościach, dlatego warto zapoznać się przynajmniej z oficjalną ściągą: kubectl Quick Reference | Kubernetes.
Konfiguracja kubectl domyślnie znajduje się w pliku ~/.kube/config.
Pliki manifestów
Klaster działa! Zanim przejdziemy dalej, zastanówmy się przez chwilę, jakich komponentów wymaga podstawowa instancja WordPressa? Na pewno potrzebujemy Poda z kontenerem, w którym działa aplikacja (z środowiskiem uruchomieniowym PHP oraz serwerem HTTP). WordPress musi gdzieś przechowywać dane, więc wymagany jest Pod z serwerem bazodanowym MySQL.
Jak już wiemy, Pody są ulotne, więc potrzebujemy kolejnego dedykowanego komponentu, który będzie trwale przechowywał zapisane informacje, niezależnie od czasu życia Podów (Persistent Volumes | Kubernetes).
No i naturalnie musimy zapewnić komunikację sieciową między aplikacją WordPress i serwerem MySQL, czyli potrzebujemy przynajmniej dwóch komponentów typu Service. Poza tym warto byłoby zapewnić dostęp do serwera HTTP z zewnątrz klastra, więc jeśli chcemy to osiągnąć z użyciem Ingressa, to do zestawu dochodzi nam kolejny element.
Kubernetes trochę nam sprawę ułatwia, ponieważ jeśli poszczególne podzespoły są przygotowane do działania w kontenerach (a wiele z nich ma już swoje ogólnodostępne obrazy), to instalacja na klastrze wymaga przygotowania odpowiednich manifestów, czyli konfiguracyjnych plików YAML opisujących każdy komponent. Celem głębszego zrozumienia tego procesu, zachęcam do zapoznania się z tym tutorialem: Example: Deploying WordPress and MySQL with Persistent Volumes | Kubernetes.
Podsumowując, jeśli instalujemy w klastrze rozwiązanie składające się z 5 komponentów, to musimy przygotować 5 manifestów z konfiguracją. Można to uczynić zarówno w osobnych plikach, jak i w jednym pliku zbiorczym (poszczególne manifesty są wtedy oddzielone separatorem —).
Helm
Większość aplikacji działających w klastrze K8s składa się z przynajmniej kilku komponentów i każdy z nich musi zostać odpowiednio skonfigurowany z użyciem manifestu. Okazuje się, że Kubernetes ma dedykowanego menadżera pakietów o nazwie Helm, który umożliwia automatyczną instalację wszystkich niezbędnych komponentów danego rozwiązania.
Pojedyncza paczka repozytorium (tzw. Helm Chart) to po prostu kolekcja plików YAML niezbędnych do pełnej instalacji oraz uruchomienia danego produktu w klastrze Kubernetes.
Helm nie jest zintegrowany z K8s, więc musimy go zainstalować osobno. Na szczęście proces nie jest zbyt skomplikowany, o czym możemy się przekonać w oficjalnej dokumentacji: Installing Helm. Poniżej lista najważniejszych kroków:
Poszczególne Charty są dostępne w różnych, dedykowanych repozytoriach. Aby móc zainstalować określone paczki, najpierw musimy dodać odpowiednie repozytorium. Na razie nasza lista jest pusta (helm repo list), ale zaraz się to zmieni.
Krok 3: secureCodeBox
Czas na instalację OWASP secureCodeBox w naszym klastrze. Może trochę dziwić fakt, że zaczynamy od narzędzia do testów automatycznych, zamiast od aplikacji WordPress, od której prawdopodobnie byśmy zaczęli w realnych warunkach.
Taka kolei rzeczy jest spowodowana tym, że twórcy secureCodeBox, oprócz narzędzi skanujących, udostępniają w swoich repozytoriach Helm szereg przykładowych aplikacji, celowo zawierających różne podatności. Jedną z takich aplikacji jest stara wersja WordPress, na której przeprowadzimy testy.
Zacznijmy od dodania odpowiedniego repozytorium Helm, zawierającego Charty (paczki) przygotowane przez autorów sCB:
Po dodaniu repozytorium do listy, możemy zobaczyć jakie Charty są w nim dostępne. Znajdziemy tutaj zarówno najważniejsze komponenty sCB, jak i wszystkie skanery oraz przykładowe aplikacje testowe:
helm search repo secureCodeBox
Zanim zainstalujemy sCB, warto stworzyć przestrzeń nazw (ang. namespace) w naszym klastrze. Można to zrobić poleceniem:
kubectl create namespace securecodebox
gdzie securecodebox (możemy wybrać dowolną nazwę) to nasz nowy namespace.
Przestrzenie nazw służą do umownego grupowania zasobów w ramach pojedynczego klastra. Aby wyświetlić wszystkie dostępne namespace’y, możemy użyć polecenia kubectl get namespaces. Oprócz nowej przestrzeni nazw, ujrzymy również te standardowe, włącznie z domyślną (default).
Sercem rozwiązania secureCodeBox jest wspomniany już wcześniej Operator, więc od niego zaczniemy. Instalacja (lub upgrade, jeśli paczka została wcześniej zainstalowana) odbywa się przez polecenie:
--namespace securecodebox – gdybyśmy nie podali tego parametru, Operator trafiłby do domyślnej przestrzeni nazw default.
--install securecodebox-operator – zainstalowany pakiet Helm będzie widoczny pod nazwą securecodebox-operator, po wydaniu polecenia: helm ls -a –namespace securecodebox.
--set="telemetryEnabled=false" – domyślna instalacja operatora wysyła anonimowe dane telemetryczne do centralnej usługi (na zewnątrz). Pierwszy ping pojawia się godzinę po instalacji, a każdy kolejny jest wykonywany co 24 godziny. My jednak tego nie chcemy, więc wyłączamy tę opcję za pomocą podanej flagi.
Zobaczmy, co się zainstalowało:
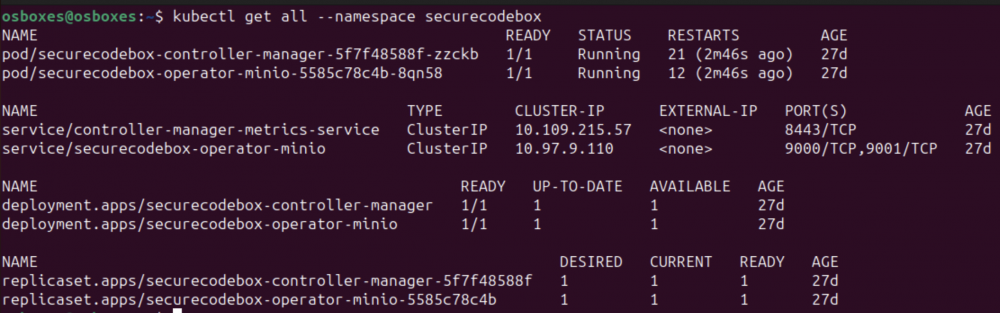
kubectl get all --namespace securecodebox
Rys. 11. Lista komponentów K8s w przestrzeni nazw “securecodebox”.
Widzimy tutaj omówione wcześniej zasoby K8s, składające się na rozwiązanie OWASP secureCodeBox, czyli: Deployment, ReplicaSet, Pod oraz Service typu ClusterIP (usługa jest dostępna tylko wewnątrz klastra).
Oprócz samego Operatora (securecodebox-controller-manager), automatycznie zainstalowały się komponenty usługi MInIO (securecodebox-operator-minio), którą secureCodeBox domyślnie wykorzystuje do przechowywania danych.
MinIO
Jest to wydajne narzędzie (udostępnione na licencji GNU AGPLv3) do przechowywania danych w postaci obiektów, zaprojektowane do działania jako lokalna wersja usług chmurowych typu storage (API serwera jest kompatybilne z Amazon S3).
MinIO posiada również przystępny interfejs UI, dostępny przez przeglądarkę. Tutaj znajdziemy krótką instrukcję, jak się do niego dostać: Accessing the included MinIO Instance. W skrócie:
Udostępniamy w ten sposób usługę MinIO na zewnątrz klastra K8s, poprzez przekierowanie portów. Teraz powinniśmy mieć dostęp do dashboarda MinIO pod adresem http://localhost:9000.
Port forwarding jest stosunkowo prostą techniką udostępniania usług na zewnątrz klastra w celach testowych, więc tylko dla przypomnienia: w środowisku produkcyjnym powinniśmy użyć czegoś bardziej rozbudowanego (np. Ingress).
Dane dostępowe są zapisane w specjalnym komponencie Secret służącym do przechowywania wrażliwych danych w klastrze Kubernetes.
Poszczególne parametry zostały omówione wcześniej, przy okazji instalowania Operatora sCB, więc nie powinno być tutaj niespodzianek.
Jeśli chcemy skonfigurować instalację (za pomocą parametru –set), listę dostępnych opcji znajdziemy w dokumentacji: old-wordpress · securecodebox/securecodebox (w chwili pisania artykułu dostępna wersja to 4.4.1).
Po wydaniu poniższego polecenia możemy zobaczyć, jakie komponenty się zainstalowały:
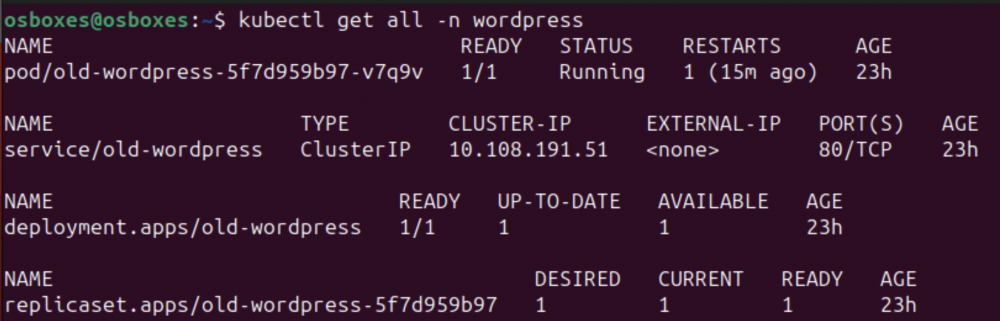
kubectl get all -n wordpress
Rys. 12. Lista komponentów K8s w przestrzeni nazw “wordpress”.
Możliwe, że będziemy musieli chwilę poczekać aż Deployment będzie gotowy oraz Pod zostanie uruchomiony (READY 1/1).
Jak widać, domyślny typ usługi Service to ClusterIP, czyli nasza aplikacja WordPress jest na razie dostępna jedynie wewnątrz klastra K8s, pod adresem http://10.108.191.51, na porcie 80 (należy pamiętać, że ten adres może być różny na każdej instancji). Możemy to sprawdzić z poziomu Poda z zainstalowanym WordPressem:
Tutaj mała uwaga: sama aplikacja WordPress bądź zainstalowany na tym samym Podzie server Apache, po wejściu na stronę główną, automatycznie przekierowuje żądanie HTTP na adres zawarty w nagłówku Host.
W związku z tym, kiedy spróbujemy połączyć się z adresem http://localhost:8080, nastąpi przekierowanie na adres localhost:80 (wartość nagłówka Host to w tym przypadku localhost), co oczywiście zakończy się niepowodzeniem, ponieważ pod naszym adresem lokalnym, na porcie 80, nie działa żadna usługa.
Możemy jednak sami ustawić odpowiednią wartość nagłówka:
Jest to oczywiście tymczasowe obejście problemu niepełnej konfiguracji, ale w ramach tego przewodnika chcemy skupić się na skanowaniu aplikacji, a nie na jej pełnym wdrożeniu.
Krok 5: WPScan ScanType
Jeśli badamy aplikację WordPress, to naturalnym wyborem wydaje się być wykorzystanie skanera WPScan, który jest obsługiwany przez sCB.
Z WPScan możemy korzystać za darmo, jeśli nie używamy go komercyjnie, jednakże do wykorzystania pełni jego możliwości musimy założyć konto na https://wpscan.com/ i pobrać z niego nasz API token. Bez tego, skaner wykryje jedynie wersje oprogramowania, ale nie zwróci listę potencjalnych podatności.
Zacznijmy od standardowej instalacji (z repozytorium Helm):
Wg dokumentacji sCB, skanery powinny być zainstalowane w tej samej przestrzeni nazw, gdzie znajduje się cel, czyli w naszym przypadku będzie to wordpress. Jedynie Operator powinien znajdować się w wydzielonej przestrzeni nazw (u nas securecodebox).
Zweryfikujmy instalację. Sprawdźmy najpierw ile pakietów Helm mamy już zainstalowanych, z uwzględnieniem wszystkich namespace’ów (przełącznik -A):
helm ls -A
Rys. 13. Lista zainstalowanych pakietów Helm.
A teraz sprawdźmy listę zainstalowanych skanerów (komponent ScanType jest zdefiniowanym zasobem własnym CRD):
kubectl -n wordpress get scantypes
Rys. 14. Lista zainstalowanych skanerów.
Konkretny ScanType instruuje Operatora sCB, w jaki sposób należy przeprowadzić skanowanie za pomocą wybranego narzędzia oraz jak sparsować dane wyjściowe, żeby pasowały do ujednoliconego modelu.
Na tym właśnie polega siła rozwiązania secureCodeBox: dzięki definicjom ScanType, które stanowią dodatkową warstwę abstrakcji na konkretne narzędzia skanujące, uzyskujemy jednolity interfejs do uruchamiania skanowania oraz znormalizowany format otrzymanych wyników.
Więcej informacji dotyczących instalacji oraz używania zintegrowanego skanera WPScan znajdziemy w oficjalnej dokumentacji : WPScan | secureCodeBox
Krok 6: Pierwsze skanowanie
Czas na wielki finał, czyli nasze pierwsze skanowanie pod kątem podatności za pośrednictwem secureCodeBox. Proces ten, tak jak większość rzeczy w Kubernetes, definiujemy za pomocą opisanego w drugim kroku (Lokalny klaster K8s) pliku z manifestem, a następnie aplikujemy go za pomocą polecenia kubectl -f apply <manifest.yml>.
Przygotowanie konfiguracji
Stwórzmy więc odpowiedni plik z definicją skanowania (nazwijmy go wp-first-scan.yml) i rozłóżmy go na czynniki pierwsze:
apiVersion – określa wersję API, która jest używana do definiowania danego zasobu.
kind – rodzaj zasobu K8s. W tym przypadku jest to Scan, czyli zasób własny CRD.
metadata.name – dowolna nazwa naszego zasobu.
spec – sekcja będąca specyfikacją tworzonego przez nas komponentu, czyli zestaw informacji o tym, jaki jest jego pożądany stan (konfiguracja oraz jak powinien działać).
scanType – tutaj chyba nie ma wątpliwości :).
parameters – parametry przekazywane do skanera WPScan w formie listy.
Krótko omówmy użyte wyżej parametry. Definicja w pliku jest równoznaczna z uruchomieniem polecenia:
--plugins-detection mixed – wybranie pośredniego trybu skanowania, pomiędzy pasywnym (passive), a agresywnym (aggresive).
--api-token <API_TOKEN> – API token, który możemy uzyskać w podglądzie naszego profilu, po zalogowaniu się do serwisu WPScan. Bez tego nasz skaner nie będzie w stanie zbadać aplikacji pod kątem podatności – wylistuje jedynie wszystkie znalezione wtyczki. Uwaga! W darmowej wersji jesteśmy ograniczeni dziennym limitem zapytań do API (maksymalnie 25). Jeśli go przekroczymy, skanowanie zakończy się błędem.
Skanowanie i monitorowanie
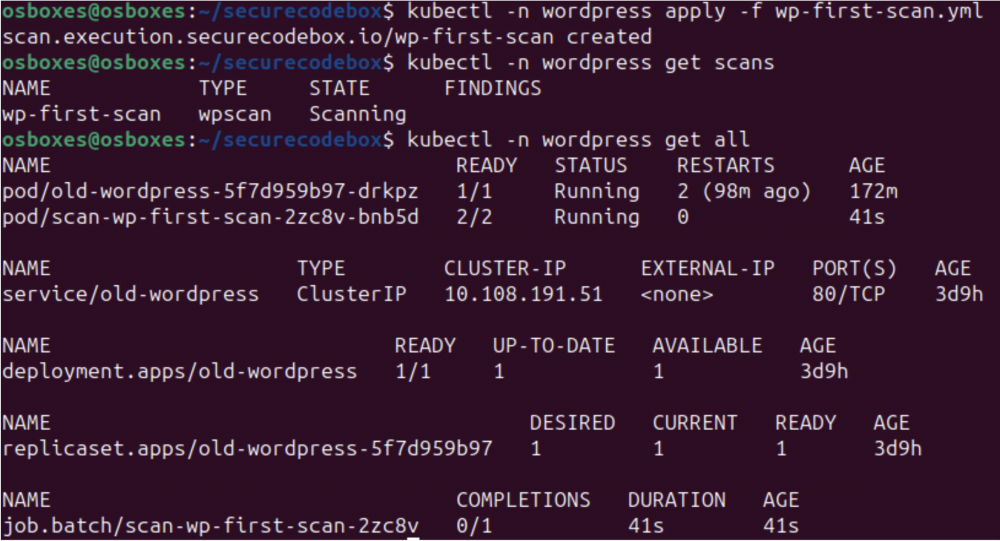
Rozpoczynamy operację skanowania:
kubectl -n wordpress apply -f wp-first-scan.yml
Aby sprawdzić aktualny stan procesu skanowania:
kubectl -n wordpress get scans
W momencie, w którym zaaplikowaliśmy plik YAML z konfiguracją skanowania, Operator sCB uruchomił zadanie Kubernetes Job. To zadanie utworzyło też dedykowany Pod, w ramach którego działają 2 kontenery:
wpscan – odpowiada za skanowanie aplikacji i uzyskanie wyników.
lurker – odpowiada za zebranie i parsowanie wyników.
Możemy to oczywiście zweryfikować za pomocą polecenia: kubectl -n wordpress get all. W wyniku ujrzymy nowy zasób typu Job oraz nowy Pod, o nazwie scan-wp-first-scan-*.
Rys. 15. Uruchomienie skanowania oraz podgląd aktualnego statusu operacji. Źródło: opracowanie własne.
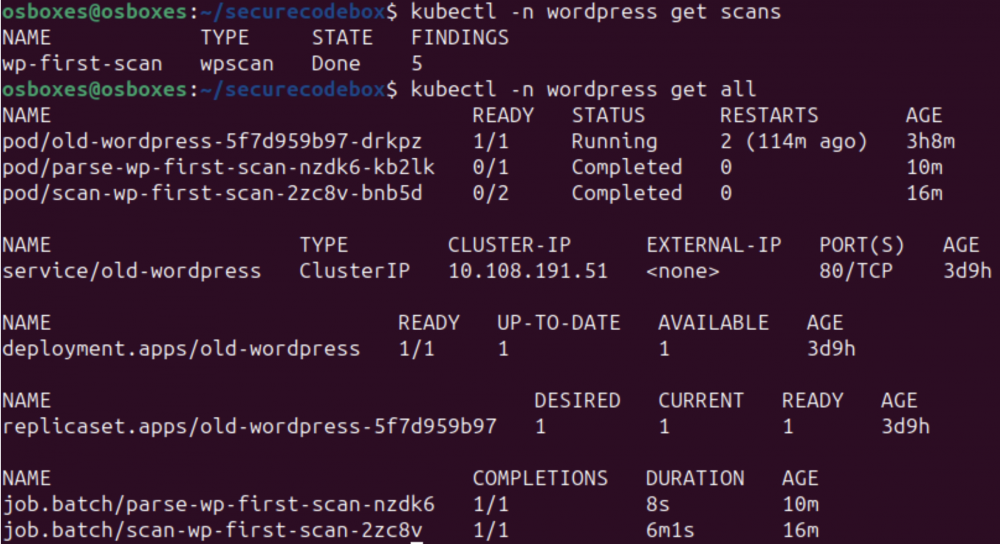
Widać, że skanowanie jest w toku i może to trochę potrwać. Kiedy proces dobiegnie końca, zobaczymy, że pojawił się nowy Job (oraz Pod), którego zadaniem było sparsowanie zebranych wyników:
Rys. 16. Stan poszczególnych komponentów K8s po zakończeniu skanowania. Źródło: opracowanie własne.
Możemy sprawdzić logi wygenerowane przez skaner za pomocą polecenia:
Dzieje się tak, ponieważ aplikacja wpscan (w kontenerze) została uruchomiona z parametrem -o <FILE>, który powoduje, że wyniki trafiają do pliku, zamiast na standardowe wyjście STDOUT.
Można się o tym przekonać, jeśli wystarczająco szybko (zanim skanowanie dobiegnie końca), sprawdzimy co dzieje się na Podzie skanującym:
kubectl -n wordpress exec -it scan-wp-first-scan-2zc8v-bnb5d -c wpscan -- top
Powinniśmy ujrzeć informację o poleceniu, które uruchomiło proces skanera wpscan w tym kontenerze:
Informacja o znaczeniu kodów wyjściowych jest zawarta w skrypcie /wrapper.sh. Szkoda tylko, że nie jest to wyraźnie zaznaczone w oficjalnej dokumentacji…
Wyniki i wnioski
Ogólne informacje o skanowaniu uzyskamy po wydaniu polecenia:
kubectl -n wordpress describe scan wp-first-scan
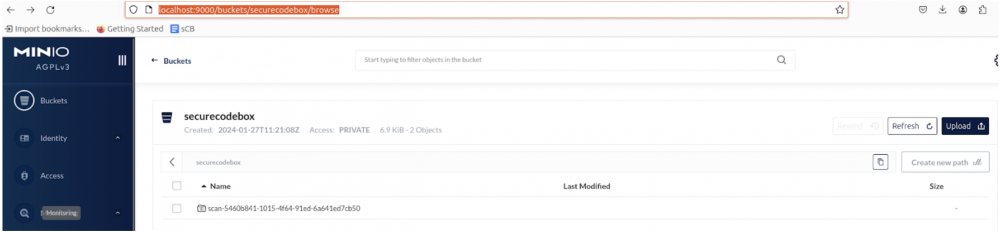
Pliki z szczegółowymi wynikami, w surowej formie (JSON), są dostępne na serwerze MinIO, który sobie już wcześniej z grubsza omówiliśmy. Jeśli mamy do niego dostęp z zewnątrz klastra (np. przez wspomniany port forwarding), to wyniki znajdziemy pod tym adresem: http://localhost:9000/buckets/securecodebox/browse.
Rys. 17. Wyniki skanowania, dostępne przez webowy dashboard MinIO.
Rezultatem skanowania są dwa pliki JSON:
wpscan-results.json – plik wygenerowany przez WPScan (nazwa pliku była podana jako wartość parametru -o), zawierający informacje zarówno o procesie skanowania, jak i listę potencjalnych problemów.
findings.json – ten plik został natomiast wygenerowany przez parser sCB i zawiera dokładnie te same podatności opisane w poprzednim pliku, ale już w formacie charakterystycznym dla sCB (ujednolicony format wyjściowy dla wszystkich skanerów).
Nie będziemy teraz się zagłębiać w znalezione podatności, ponieważ nie to jest celem tego opracowania. Zwróćmy natomiast uwagę na to, jakie możliwości daje nam ustandaryzowany format rezultatów skanowania dla wszystkich skanerów dostępnych w sCB.
Kiedy zachodzi potrzeba zastosowaniu różnych narzędzi testujących jednocześnie, sCB umożliwia przetworzenie wielu wyników w jednakowy sposób. Gdybyśmy chcieli wszystko wysłać do wybranego narzędzia analitycznego (np. DefectDojo, który również jest obsługiwany przez sCB), mamy ułatwione zadanie. Inaczej musielibyśmy zadbać o integrację każdego narzędzia testującego z osobna.
Na razie wykonaliśmy tylko pojedyncze skanowanie i zapisaliśmy wyniki w pliku JSON, co może nie jest zbyt imponujące, ale jest to pierwszy krok w kierunku implementowania automatycznych testów bezpieczeństwa. Dzięki sCB będziemy w stanie uruchamiać cykliczne skanowania kilku skanerów jednocześnie, a zagregowane wyniki prezentować w wybranym narzędziu do analizy, bez konieczności wcześniejszego ich przeformatowania.
Podsumowanie
W ramach artykułu dowiedzieliśmy się czym jest OWASP secureCodeBox i w jaki sposób to niszowe rozwiązanie może zostać wykorzystane do automatyzacji podstawowych testów bezpieczeństwa aplikacji bądź systemu.
Ponieważ narzędzie sCB zostało zaprojektowane z myślą o działaniu w klastrze Kubernetes, zapoznaliśmy się przy okazji z podstawami działania tej popularnej platformy do orkiestracji kontenerów.
Przeprowadziliśmy również pierwsze skanowanie przykładowej aplikacji WordPress, uruchomionej na zbudowanym przez nas mini-klastrze Minikube, posługując się narzędziem WPScan. Podobnie jak wiele innych popularnych narzędzi testujących, WPScan ma gotową integrację z secureCodeBox.
Oczywiście jest to dopiero pierwszy krok procesu wdrażania automatycznych testów bezpieczeństwa. Na razie wykonaliśmy tylko pojedyncze skanowanie i zapisaliśmy wyniki w pliku JSON.
W rzeczywistych warunkach jest to mało opłacalne, ponieważ znacznie łatwiej byłoby po prostu ręcznie uruchomić skaner WPScan i przeanalizować wyniki, ale miejmy na uwadze możliwości, jakie nam daje użycie sCB: wykorzystanie wielu narzędzi testujących jednocześnie, wykonywanie cyklicznych skanowań czy też agregowanie i prezentowanie wyników w jednym miejscu.
Niewykluczone, że ten artykuł jest dopiero pierwszą publikacją z cyklu OWASP secureCodeBox w akcji (nazwa robocza), w ramach którego zbudujemy automatyzację testów bezpieczeństwa, wnoszącą rzeczywistą wartość do procesu CI/CD. Oczywiście jeśli tylko pojawi się zainteresowanie tą tematyką.